AI Native Daily Paper Digest – 20260226

1. HyTRec: A Hybrid Temporal-Aware Attention Architecture for Long Behavior Sequential Recommendation
🔑 Keywords: Hybrid Attention, Linear Attention, Softmax Attention, Temporal-Aware Delta Network, Hit Rate
💡 Category: Generative Models
🌟 Research Objective:
– Overcome the limitations of modeling long user behavior sequences, balancing efficiency and retrieval precision using a hybrid attention mechanism.
🛠️ Research Methods:
– Proposes HyTRec, a model leveraging both linear and softmax attention mechanisms, decoupling long-term preferences from short-term intents, and incorporating a Temporal-Aware Delta Network to dynamically highlight recent user behavior.
💬 Research Conclusions:
– HyTRec demonstrates superiority in handling ultra-long user sequences with over 8% improvement in Hit Rate, maintaining linear inference speed, and excelling in industrial-scale datasets.
👉 Paper link: https://huggingface.co/papers/2602.18283

2. DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation
🔑 Keywords: Controllable Human-Centric Audio-Video Generation, Symmetric Conditional Diffusion Transformer, Dual-Level Disentanglement, Multi-Task Progressive Training, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– The research introduces DreamID-Omni, a unified framework for controllable human-centric audio-video generation using innovative techniques to achieve state-of-the-art performance.
🛠️ Research Methods:
– A Symmetric Conditional Diffusion Transformer is employed to integrate conditioning signals, along with Dual-Level Disentanglement to address identity-timbre binding issues and a Multi-Task Progressive Training scheme to balance varied task objectives.
💬 Research Conclusions:
– DreamID-Omni achieves superior performance in video, audio, and audio-visual consistency, outperforming existing commercial models, with planned code release to enhance the connection between research and commercial applications.
👉 Paper link: https://huggingface.co/papers/2602.12160
3. ARLArena: A Unified Framework for Stable Agentic Reinforcement Learning
🔑 Keywords: Agentic reinforcement learning, ARLArena, Training stability, SAMPO, Policy optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To analyze training stability in agentic reinforcement learning and propose a method for stable policy optimization across diverse tasks.
🛠️ Research Methods:
– Introduction of ARLArena, a framework for systematic analysis of training stability, and the decomposition of policy gradient into four core dimensions to assess performance and stability.
💬 Research Conclusions:
– The study provides a unified policy gradient perspective for agentic reinforcement learning, offering practical guidance for building stable and reproducible agent training pipelines through the SAMPO method, achieving consistently stable training and strong performance across diverse tasks.
👉 Paper link: https://huggingface.co/papers/2602.21534

4. Solaris: Building a Multiplayer Video World Model in Minecraft
🔑 Keywords: Solaris, multiplayer, video world model, multi-agent interactions, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– Solaris aims to simulate consistent multi-view observations by developing a novel multiplayer video world model.
🛠️ Research Methods:
– The research introduces a multiplayer data collection system built for robust and automated data capture from video games, progressing from single-player to multiplayer modeling using a staged pipeline.
💬 Research Conclusions:
– The architecture and training design of Solaris outperform existing baselines, setting the foundation for future advancements in multi-agent world models.
👉 Paper link: https://huggingface.co/papers/2602.22208
5. JavisDiT++: Unified Modeling and Optimization for Joint Audio-Video Generation
🔑 Keywords: AI Native, Multimodal Synthesis, Joint Audio-Video Generation, Modality-Specific Mixture-of-Experts, Temporal-Aligned RoPE
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance the quality, temporal synchrony, and alignment preferences of joint audio-video generation (JAVG) through a unified framework named JavisDiT++.
🛠️ Research Methods:
– Implementation of modality-specific mixture-of-experts (MS-MoE) to boost cross-modal interactions.
– Proposal of a temporal-aligned RoPE strategy to achieve frame-level synchronization between audio and video tokens.
– Development of audio-video direct preference optimization (AV-DPO) to align model outputs with human preferences across various dimensions.
💬 Research Conclusions:
– JavisDiT++ achieves state-of-the-art performance using only approximately 1M public training entries, surpassing previous methods in both quality and quantitative evaluations.
– Comprehensive ablation studies support the effectiveness of the proposed modules.
👉 Paper link: https://huggingface.co/papers/2602.19163
6. World Guidance: World Modeling in Condition Space for Action Generation
🔑 Keywords: Vision-Language-Action models, World Guidance framework, action generation, future observation modeling, condition space
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research introduces the World Guidance (WoG) framework to enhance Vision-Language-Action (VLA) models by mapping future observations into compact conditions for improved action generation and generalization.
🛠️ Research Methods:
– The WoG framework maps future observations into conditions embedded within the action inference pipeline, allowing VLA models to predict these compressed conditions alongside future actions, enhancing effective world modeling.
💬 Research Conclusions:
– The study demonstrates that the condition space modeling not only facilitates precise action generation but also significantly improves generalization capabilities, outperforming traditional future prediction methods. Experiments in simulation and real-world settings validate these findings.
👉 Paper link: https://huggingface.co/papers/2602.22010

7. From Statics to Dynamics: Physics-Aware Image Editing with Latent Transition Priors
🔑 Keywords: PhysicEdit, physical state transitions, transition queries, diffusion framework, Qwen2.5-VL
💡 Category: Generative Models
🌟 Research Objective:
– To enhance image editing by incorporating physically realistic state transitions through a novel dual-thinking mechanism.
🛠️ Research Methods:
– Introduction of PhysicTran38K, a comprehensive video-based dataset, and development of PhysicEdit, an end-to-end framework combining frozen vision-language models and learnable transition queries within a diffusion framework.
💬 Research Conclusions:
– PhysicEdit advances physical realism by 5.9% and knowledge-grounded editing by 10.1% compared to previous models, establishing a new benchmark for open-source methods while staying competitive with proprietary models.
👉 Paper link: https://huggingface.co/papers/2602.21778

8. NoLan: Mitigating Object Hallucinations in Large Vision-Language Models via Dynamic Suppression of Language Priors
🔑 Keywords: Object hallucination, Large Vision-Language Models, Vision encoder, Language decoder, NoLan
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To identify which component, the vision encoder or language decoder, contributes primarily to object hallucinations in Large Vision-Language Models (LVLMs).
🛠️ Research Methods:
– Conducted systematic experiments to analyze the roles of the vision encoder and the language decoder in generating hallucinations.
💬 Research Conclusions:
– Object hallucinations are mainly associated with strong priors from the language decoder.
– Introduced a training-free framework, NoLan, which suppresses language priors to reduce these hallucinations, showing effectiveness across various LVLMs on different tasks.
👉 Paper link: https://huggingface.co/papers/2602.22144

9. Revisiting Text Ranking in Deep Research
🔑 Keywords: AI-generated summary, large language model, web search APIs, text ranking methods, agent-issued queries
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address hard queries in deep research tasks by evaluating the effectiveness of text ranking methods when integrated with large language model-based agents using web search APIs.
🛠️ Research Methods:
– Evaluations are conducted using a fixed-corpus dataset with multiple agents, retrievers, and re-rankers to explore retrieval units, pipeline configurations, and query characteristics.
💬 Research Conclusions:
– The study finds that agent-issued queries, following web-search-style syntax, favor lexical, learned sparse, and multi-vector retrievers. Passage-level units are shown to be more efficient, and re-ranking proves highly effective. Translating agent-issued queries into natural-language questions effectively bridges query mismatches.
👉 Paper link: https://huggingface.co/papers/2602.21456

10. The Design Space of Tri-Modal Masked Diffusion Models
🔑 Keywords: Discrete diffusion models, Tri-modal, Multimodal scaling laws, Stochastic differential equation, Text-to-image
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce and analyze a novel tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data.
🛠️ Research Methods:
– Systematic analysis of multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, leading to a novel SDE-based reparameterization.
💬 Research Conclusions:
– Demonstrated that the proposed tri-modal model achieves strong results in text, image, and speech generation tasks and provides insights into scaling behaviors across multiple modalities.
👉 Paper link: https://huggingface.co/papers/2602.21472

11. The Truthfulness Spectrum Hypothesis
🔑 Keywords: Large Language Models, Domain-General, Domain-Specific, Linear Probes, Truthfulness Spectrum
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the existence and characteristics of truth directions in large language models, comparing domain-general and domain-specific capabilities.
🛠️ Research Methods:
– Systematic evaluation of probe generalization across various truth types using linear probes and concept-erasure methods. Analysis of the geometry of probe directions using Mahalanobis cosine similarity, and causal interventions to examine domain-specific direction effectiveness.
💬 Research Conclusions:
– The study supports the truthfulness spectrum hypothesis, showing that different truth directions coexist in the representational space of large language models. While domain-general directions exist, domain-specific directions prove more effective in certain contexts, and post-training can reshape these truth geometries.
👉 Paper link: https://huggingface.co/papers/2602.20273

12. Small Language Models for Privacy-Preserving Clinical Information Extraction in Low-Resource Languages
🔑 Keywords: AI Native, Sensitive Healthcare Applications, Persian Medical Transcripts, Bilingual Approaches, Open-source Small Language Models
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to explore clinical information extraction from Persian medical transcripts using a two-step pipeline, evaluating the effectiveness of translation and small language models in low-resource NLP.
🛠️ Research Methods:
– A two-step pipeline approach combines Aya-expanse-8B for Persian-to-English translation with five open-source small language models, assessed using metrics like macro-averaged F1-score, MCC, sensitivity, and specificity on 1,221 Persian transcripts.
💬 Research Conclusions:
– Larger models demonstrated superior performance, especially in sensitivity and MCC. Translating Persian to English improved sensitivity and provided a robust framework for multilingual clinical NLP, although it slightly reduced specificity and precision. Highlighted is the significance of optimizing model scale and input language for sensitive healthcare applications.
👉 Paper link: https://huggingface.co/papers/2602.21374

13. JAEGER: Joint 3D Audio-Visual Grounding and Reasoning in Simulated Physical Environments
🔑 Keywords: AI-generated summary, 3D space, spatial reasoning, RGB-D observations, neural intensity vector
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Extend audio-visual large language models (AV-LLMs) to 3D environments to improve spatial reasoning and source localization.
🛠️ Research Methods:
– Integrate RGB-D observations with multi-channel first-order ambisonics to support joint spatial grounding and reasoning.
– Develop a neural intensity vector (Neural IV) for robust spatial audio representation, enhancing direction-of-arrival estimation.
💬 Research Conclusions:
– JAEGER outperforms 2D-centric baselines across various spatial perception and reasoning tasks, highlighting the importance of explicit 3D modeling.
– Introduces SpatialSceneQA, a benchmark for large-scale training and evaluation in simulated environments.
👉 Paper link: https://huggingface.co/papers/2602.18527

14. MoBind: Motion Binding for Fine-Grained IMU-Video Pose Alignment
🔑 Keywords: hierarchical contrastive learning, cross-modal retrieval, temporal synchronization, action recognition, IMU signals
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary aim is to learn joint representations between inertial measurement unit (IMU) signals and 2D pose sequences to facilitate accurate cross-modal retrieval, temporal synchronization, body-part localization, and action recognition.
🛠️ Research Methods:
– MoBind employs a hierarchical contrastive learning framework, focusing on filtering irrelevant visual background, modeling structured multi-sensor IMU configurations, and achieving fine-grained temporal alignment by aligning IMU signals with skeletal motion sequences, and decomposing full-body motion into local body-part trajectories.
💬 Research Conclusions:
– MoBind consistently outperforms strong baselines in mRi, TotalCapture, and EgoHumans datasets across all tasks, demonstrating robust fine-grained temporal alignment while maintaining semantic consistency across modalities.
👉 Paper link: https://huggingface.co/papers/2602.19004

15. DM4CT: Benchmarking Diffusion Models for Computed Tomography Reconstruction
🔑 Keywords: Diffusion models, computed tomography, inverse problems, DM4CT, AI-generated
💡 Category: Generative Models
🌟 Research Objective:
– Evaluate the performance of Diffusion models for CT reconstruction, addressing practical challenges like correlated noise and artifact structures.
🛠️ Research Methods:
– Introduced DM4CT, a comprehensive benchmark utilizing datasets from medical and industrial domains, and acquiring a high-resolution CT dataset under real experimental conditions.
– Benchmarked ten diffusion-based methods alongside seven strong baselines, including model-based, unsupervised, and supervised approaches.
💬 Research Conclusions:
– Provided insights into the behavior, strengths, and limitations of diffusion models for CT reconstruction.
– Offered a publicly available real-world dataset and open-sourced codebase for further research.
👉 Paper link: https://huggingface.co/papers/2602.18589

16.

17. Yor-Sarc: A gold-standard dataset for sarcasm detection in a low-resource African language
🔑 Keywords: Sarcasm detection, Yorùbá, annotation protocol, inter-annotator agreement, low-resource language
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Yor-Sarc, a gold-standard dataset for sarcasm detection in Yorùbá, to address the challenges in computational semantics for low-resource languages.
🛠️ Research Methods:
– The dataset consists of 436 instances annotated by native speakers using a culture-sensitive annotation protocol and provides both high inter-annotator agreement metrics and soft labels for further uncertainty modeling.
💬 Research Conclusions:
– Achieved substantial to almost perfect inter-annotator agreement, with protocols and findings potentially aiding replication in other African languages and advancing semantic interpretation for low-resource NLP.
👉 Paper link: https://huggingface.co/papers/2602.18964

18. Intent Laundering: AI Safety Datasets Are Not What They Seem
🔑 Keywords: AI safety datasets, triggering cues, intent laundering, adversarial attacks, black-box access
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To evaluate the quality and realism of AI safety datasets in representing real-world adversarial behavior.
🛠️ Research Methods:
– Systematic evaluation from two perspectives: in isolation and in practice. Introduction of “intent laundering” as a technique to remove triggering cues while preserving malicious intent.
💬 Research Conclusions:
– Current AI safety datasets fail to accurately represent real-world adversarial behavior due to reliance on triggering cues. Models deemed “reasonably safe” become unsafe when these cues are removed. Intent laundering, when used as a jailbreaking technique, achieves high success rates, highlighting discrepancies in model safety evaluation.
👉 Paper link: https://huggingface.co/papers/2602.16729

19. ISO-Bench: Can Coding Agents Optimize Real-World Inference Workloads?
🔑 Keywords: ISO-Bench, coding agents, LLM inference optimization, LLM serving frameworks, optimization patch
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce ISO-Bench, a benchmark for evaluating coding agents on real-world inference optimization tasks derived from popular LLM serving frameworks.
🛠️ Research Methods:
– Tasks are curated from vLLM and SGLang with a combination of execution-based and LLM-based metrics to assess the agents’ optimization patches against human expert solutions.
💬 Research Conclusions:
– No single coding agent consistently dominates across different codebases, and identical models can perform differently, highlighting the importance of task scaffolding.
👉 Paper link: https://huggingface.co/papers/2602.19594

20. Functional Continuous Decomposition
🔑 Keywords: Functional Continuous Decomposition, time-series data, parametric optimization, feature extraction, CNN
💡 Category: Machine Learning
🌟 Research Objective:
– The paper introduces Functional Continuous Decomposition (FCD) for continuous optimization of time-series data to capture local and global patterns and improve feature extraction.
🛠️ Research Methods:
– Utilized a JAX-accelerated framework with Levenberg-Marquardt optimization to achieve C^1 continuous fitting, transforming time-series data into multiple modes for analysis.
💬 Research Conclusions:
– FCD applications span fields like physics, medicine, and finance, enhancing signal temporal pattern analysis. When integrated with a CNN, FCD features result in 16.8% faster convergence and 2.5% higher accuracy.
👉 Paper link: https://huggingface.co/papers/2602.20857

21. UniVBench: Towards Unified Evaluation for Video Foundation Models
🔑 Keywords: Video foundation models, video understanding, video generation, video reconstruction, Unified evaluation system
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce UniVBench, a comprehensive benchmark for evaluating video foundation models across multiple capabilities such as understanding, generation, editing, and reconstruction.
🛠️ Research Methods:
– Development of a unified agentic evaluation system, UniV-Eval, and the use of 200 high-quality, diverse videos for complex evaluation tasks.
💬 Research Conclusions:
– UniVBench provides a framework for measuring the integrated capabilities of video foundation models, with extensive human annotations ensuring alignment with human judgment, thereby accelerating progress toward robust video intelligence.
👉 Paper link: https://huggingface.co/papers/2602.21835

22. Model Context Protocol (MCP) Tool Descriptions Are Smelly! Towards Improving AI Agent Efficiency with Augmented MCP Tool Descriptions
🔑 Keywords: Foundation Model, tool descriptions, agent performance, task success rates, execution cost
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to assess the quality of natural language tool descriptions used by Foundation Model-based agents and their impact on performance and efficiency within the Model Context Protocol ecosystem.
🛠️ Research Methods:
– Examination of 856 tools across 103 MCP servers, development of a scoring rubric to identify description quality, and analysis of performance outcomes using an FM-based scanner.
💬 Research Conclusions:
– 97.1% of tool descriptions contain at least one defect; improving description quality enhances task success by 5.85 percentage points but increases execution steps by 67.46%. Optimal performance and efficiency require balancing execution cost and context.
👉 Paper link: https://huggingface.co/papers/2602.14878

23. SeaCache: Spectral-Evolution-Aware Cache for Accelerating Diffusion Models
🔑 Keywords: Diffusion models, Spectral-evolution, SeaCache, Latency-quality trade-offs
💡 Category: Generative Models
🌟 Research Objective:
– To improve inference speed in diffusion models by optimizing intermediate output reuse through a spectrally aligned representation, achieving superior latency-quality trade-offs.
🛠️ Research Methods:
– Introduction of Spectral-Evolution-Aware Cache (SeaCache) and a Spectral-Evolution-Aware (SEA) filter based on theoretical and empirical analysis to preserve content-relevant components while suppressing noise.
💬 Research Conclusions:
– SeaCache demonstrates state-of-the-art performance in latency-quality trade-offs on diverse visual generative models, surpassing previous methods by employing a dynamic schedule adapted to spectral priors.
👉 Paper link: https://huggingface.co/papers/2602.18993
24. NanoKnow: How to Know What Your Language Model Knows
🔑 Keywords: NanoKnow benchmark, LLMs, pre-training data, parametric knowledge, external knowledge
💡 Category: Natural Language Processing
🌟 Research Objective:
– Evaluate and understand how large language models (LLMs) encode and source their knowledge, particularly by analyzing the interactions between parametric and external knowledge.
🛠️ Research Methods:
– Deploying NanoKnow, a benchmark dataset that partitions questions from widely-used datasets (Natural Questions and SQuAD) to analyze their pre-training data presence in the nanochat LLMs, allowing to disentangle knowledge sources.
💬 Research Conclusions:
– Accuracy of models is significantly influenced by how frequently answers appear in pre-training data.
– External evidence mitigates frequency dependence but parametric knowledge still enhances accuracy.
– Non-relevant information decreases accuracy, affected by both its position and quantity.
👉 Paper link: https://huggingface.co/papers/2602.20122

25. DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference
🔑 Keywords: DualPath, KV-Cache, Prefill Engines, Decode Engines, RDMA
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address KV-cache storage I/O bottlenecks in multi-turn LLM inference by introducing DualPath for optimized loading and dynamic load balancing.
🛠️ Research Methods:
– Implementation of dual-path KV-Cache loading using a novel storage-to-decode path, integrated with RDMA for efficient data transfer and a global scheduler for dynamic load balancing.
💬 Research Conclusions:
– DualPath significantly improves offline inference throughput by up to 1.87 times and online serving by an average factor of 1.96 times without violating service level objectives (SLO).
👉 Paper link: https://huggingface.co/papers/2602.21548

26. Image Generation with a Sphere Encoder
🔑 Keywords: Sphere Encoder, efficient generative model, spherical latent space, conditional generation, inference cost
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to introduce the Sphere Encoder, a generative model that efficiently produces high-quality images with minimal computational cost.
🛠️ Research Methods:
– The method involves mapping images onto a spherical latent space and decoding from random points on the sphere to generate images. Training is based solely on image reconstruction losses.
💬 Research Conclusions:
– The Sphere Encoder achieves image quality comparable to state-of-the-art diffusion models but with significantly lower inference costs. It also supports conditional generation and can improve image quality through additional encoder/decoder iterations.
👉 Paper link: https://huggingface.co/papers/2602.15030

27. VecGlypher: Unified Vector Glyph Generation with Language Models
🔑 Keywords: VecGlypher, Multimodal Language Model, Vector Glyphs, SVG Path Generation, Font Creation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop VecGlypher, a multimodal language model aimed at generating high-fidelity vector glyphs directly from text or image inputs, eliminating the need for raster-to-vector processes.
🛠️ Research Methods:
– Utilizes a typography-aware training method, involving a two-stage process with a large-scale continuation on noisy Envato fonts and post-training on expert-annotated Google Fonts to align language and imagery with geometry.
💬 Research Conclusions:
– VecGlypher outperforms existing models in cross-family OOD evaluation for text-only generation and achieves state-of-the-art performance in image-referenced generation, demonstrating its potential to lower the barrier to font creation and serve as a foundation for future multimodal design tools.
👉 Paper link: https://huggingface.co/papers/2602.21461

28. GUI-Libra: Training Native GUI Agents to Reason and Act with Action-aware Supervision and Partially Verifiable RL
🔑 Keywords: GUI agents, action-aligned reasoning data, SFT, RLVR, data curation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To address open-source GUI agents’ limitations through improved reasoning-grounding alignment and specialized reinforcement learning strategies.
🛠️ Research Methods:
– Introduction of a data construction and filtering pipeline to create an 81K GUI reasoning dataset.
– Development of action-aware SFT that emphasizes action and grounding.
– Implementation of KL regularization in RLVR to enhance offline-to-online predictability, along with success-adaptive scaling.
💬 Research Conclusions:
– GUI-Libra enhances task completion and accuracy across web and mobile platforms, demonstrating that effective post-training and data curation can greatly improve GUI agents’ performance without expensive online data collection.
👉 Paper link: https://huggingface.co/papers/2602.22190

29. SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
🔑 Keywords: SkyReels V4, Multimodal Diffusion Transformer, video audio generation, inpainting, super-resolution
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop a unified multimodal model for simultaneous video and audio generation, editing, and inpainting using SkyReels V4’s advanced architecture.
🛠️ Research Methods:
– Utilize a dual-stream Multimodal Diffusion Transformer (MMDiT) that integrates a shared text encoder and supports rich multimodal inputs for efficient high-resolution processing.
💬 Research Conclusions:
– SkyReels V4 is the first foundation model to effectively support multimodal inputs across different tasks such as generation, inpainting, and editing, achieving high-quality, cinema-level outputs with synchronized audio and innovative efficiency strategies.
👉 Paper link: https://huggingface.co/papers/2602.21818

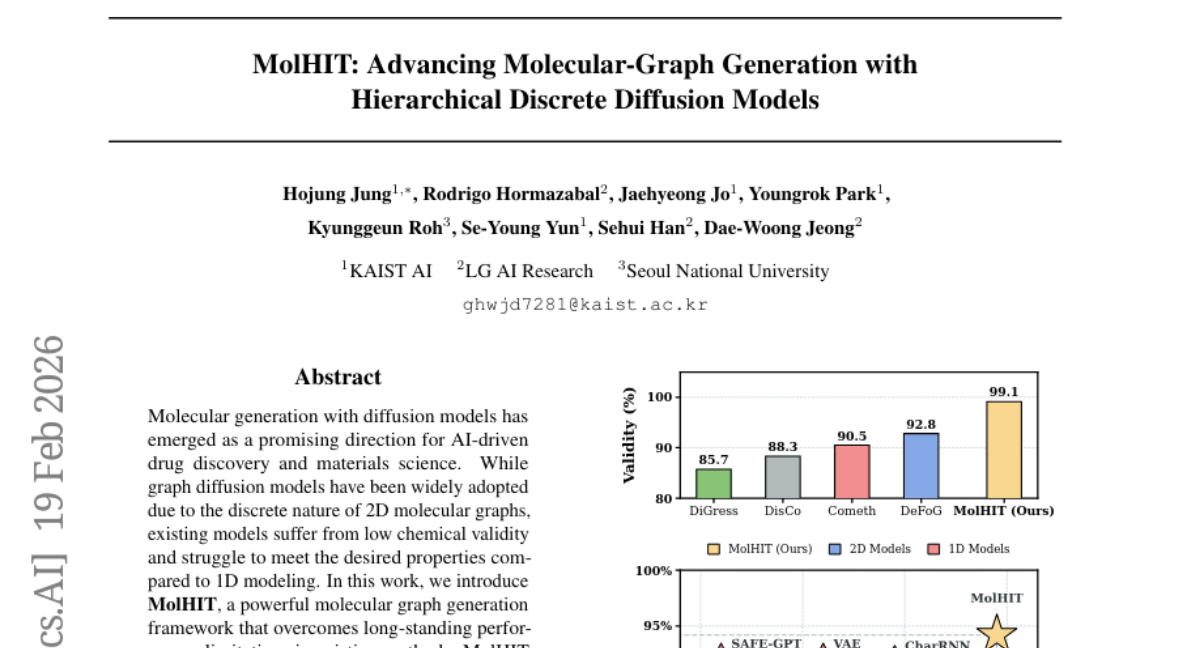
30. MolHIT: Advancing Molecular-Graph Generation with Hierarchical Discrete Diffusion Models
🔑 Keywords: Molecular generation, Discrete diffusion model, Chemical validity, Multi-property guided generation, Scaffold extension
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to present MolHIT, a hierarchical discrete diffusion model, to enhance chemical validity and property-guided synthesis in molecular graph generation.
🛠️ Research Methods:
– Introduction of a Hierarchical Discrete Diffusion Model for molecular graphs, utilizing chemistry-based categories and decoupled atom encoding to improve performance.
💬 Research Conclusions:
– MolHIT achieves state-of-the-art performance with near-perfect chemical validity on the MOSES dataset, outperforming existing models in multi-property guided generation and scaffold extension tasks.
👉 Paper link: https://huggingface.co/papers/2602.17602