AI Native Daily Paper Digest – 20260320
1. Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
🔑 Keywords: VEGA-3D, Latent World Simulator, spatiotemporal features, 3D structural priors, video diffusion model
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enhance Multimodal Large Language Models (MLLMs) by incorporating implicit 3D structural priors and physical laws using a video diffusion model repurposed as a Latent World Simulator.
🛠️ Research Methods:
– The approach involves extracting spatiotemporal features from video diffusion models and integrating them with semantic representations via a token-level adaptive gated fusion mechanism to provide geometric cues without explicit 3D supervision.
💬 Research Conclusions:
– The paper concludes that the proposed VEGA-3D framework improves 3D scene understanding, spatial reasoning, and embodied manipulation benchmarks, outperforming state-of-the-art baselines. It demonstrates that generative priors are scalable for physical-world understanding.
👉 Paper link: https://huggingface.co/papers/2603.19235

2. FASTER: Rethinking Real-Time Flow VLAs
🔑 Keywords: Fast Action Sampling for ImmediaTE Reaction (FASTER), Vision-Language-Action models, reaction time, Horizon-Aware Schedule, real-time responsiveness
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The main objective is to reduce real-time reaction latency in Vision-Language-Action models by prioritizing immediate actions while preserving long-horizon trajectory quality.
🛠️ Research Methods:
– Introduce the Fast Action Sampling for ImmediaTE Reaction (FASTER) approach, which uses a Horizon-Aware Schedule to adaptively prioritize near-term actions during flow sampling.
– Implement a streaming client-server pipeline to enhance the real-time execution of VLA models on consumer-grade GPUs.
💬 Research Conclusions:
– The FASTER approach significantly compresses the denoising of immediate reactions and reduces effective reaction latency, enhancing real-time responsiveness and enabling rapid generation of accurate and smooth trajectories in real-world tasks, such as dynamic table tennis with robots.
👉 Paper link: https://huggingface.co/papers/2603.19199

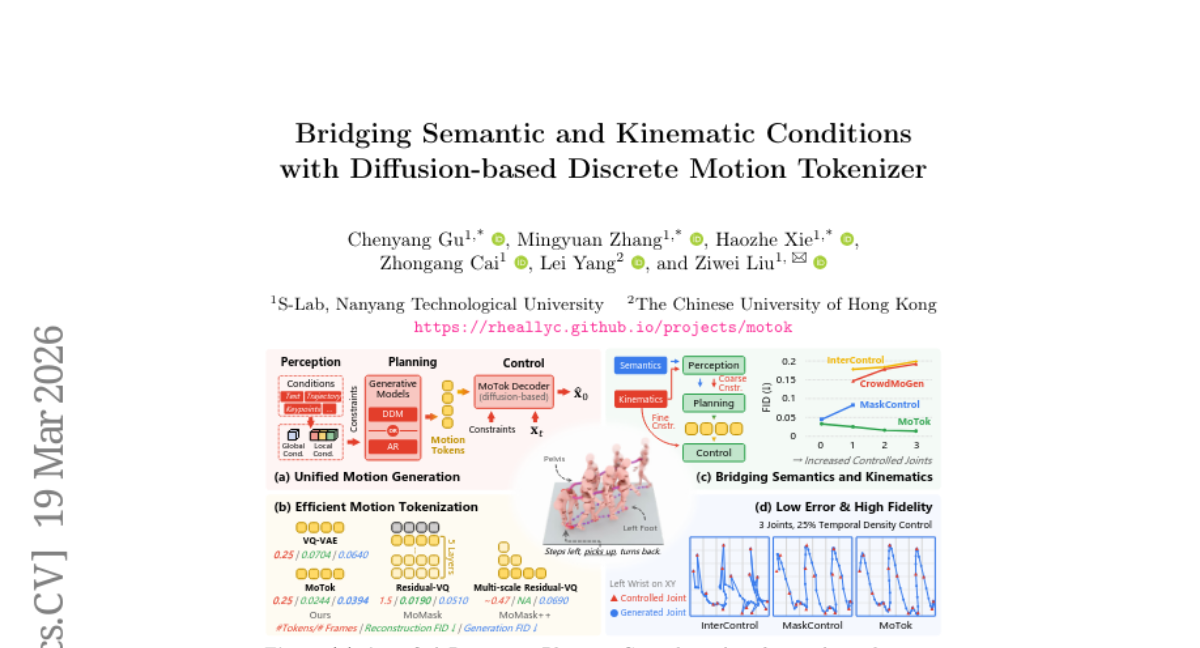
3. Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
🔑 Keywords: motion generation, diffusion-based synthesis, discrete tokenization, kinematic control, semantic conditioning
💡 Category: Generative Models
🌟 Research Objective:
– To combine the strengths of continuous diffusion models and discrete token-based generators to improve controllability and fidelity in motion generation.
🛠️ Research Methods:
– A three-stage framework is proposed, comprising condition feature extraction (Perception), discrete token generation (Planning), and diffusion-based motion synthesis (Control). Central to this is the MoTok diffusion-based discrete motion tokenizer.
💬 Research Conclusions:
– The proposed method enhances controllability and fidelity while drastically reducing token usage and computational requirements, demonstrated on the HumanML3D dataset with significant improvements in fidelity and trajectory error measurement.
👉 Paper link: https://huggingface.co/papers/2603.19227
4. Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
🔑 Keywords: Nemotron-Cascade 2, Mixture-of-Experts model, reasoning, agentic capabilities, Cascade RL
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Nemotron-Cascade 2, a compact 30B parameter Mixture-of-Experts model achieving high reasoning and agentic capabilities.
🛠️ Research Methods:
– Utilize SFT with a curated dataset and expand Cascade RL to broaden the scope of reasoning and agentic domains.
– Implement multi-domain on-policy distillation from intermediate teacher models to maintain strong performance.
💬 Research Conclusions:
– Achieves Gold Medal-level performance in major mathematical competitions with a high intelligence density using significantly fewer parameters compared to its predecessors.
👉 Paper link: https://huggingface.co/papers/2603.19220

5. LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs
🔑 Keywords: Omnimodal Large Language Models, LVOmniBench, Cross-modal Comprehension, Long-term Memory, Temporal Localization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce LVOmniBench, a benchmark for evaluating cross-modal comprehension of long-form audio and video content.
🛠️ Research Methods:
– Compiled a dataset of 275 videos (10-90 minutes long) and 1,014 question-answer pairs to evaluate existing large language models’ capabilities.
💬 Research Conclusions:
– Current omnimodal large language models face significant challenges in handling extended audio-visual inputs, with accuracies below 35% for most open-source models, while Gemini 3 Pro achieves around 65%.
👉 Paper link: https://huggingface.co/papers/2603.19217

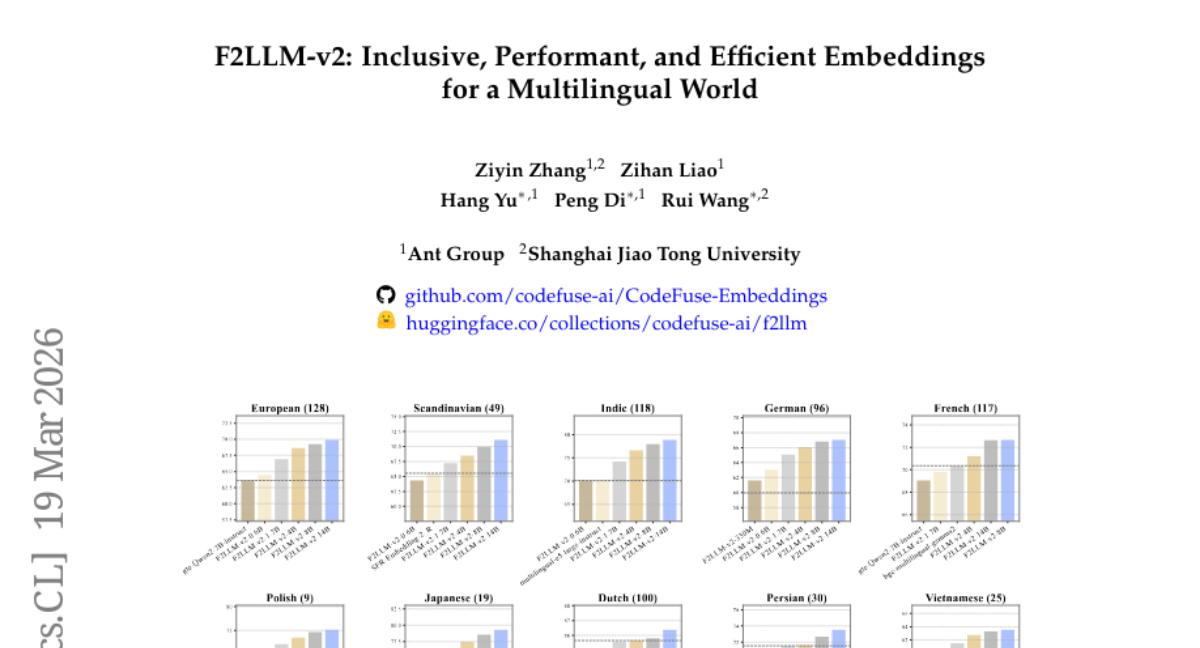
6. F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
🔑 Keywords: multilingual embedding models, LLM-based training, matryoshka learning, model pruning, knowledge distillation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce F2LLM-v2, a new family of multilingual embedding models designed for general-purpose applications across 200+ languages, focusing on mid- and low-resource languages.
🛠️ Research Methods:
– Employ a two-stage LLM-based embedding training pipeline combined with matryoshka learning, model pruning, and knowledge distillation techniques.
💬 Research Conclusions:
– F2LLM-v2 models demonstrate superior efficiency and competitive performance compared to previous models, with the 14B model achieving top ranks on 11 MTEB benchmarks. Smaller models also excel in resource-constrained environments. All models, data, and code are made available to support open-source research.
👉 Paper link: https://huggingface.co/papers/2603.19223
7. Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
🔑 Keywords: MLLMs, discrete symbols, cognitive mismatch, visual perception, symbolic understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate the capability of top-tier Multimodal Large Language Models (MLLMs) in processing discrete symbols across different domains.
🛠️ Research Methods:
– Introduction of a comprehensive benchmark assessing MLLMs’ navigation through discrete semantic spaces in language, culture, mathematics, physics, and chemistry.
💬 Research Conclusions:
– There is a cognitive mismatch as models struggle with basic symbol recognition but excel in complex reasoning, indicating reliance on linguistic probability over true visual perception. The study provides a roadmap for developing more human-aligned intelligent systems.
👉 Paper link: https://huggingface.co/papers/2603.18472

8. EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing
🔑 Keywords: Video Object Removal, VOR, EffectErase, Reciprocal Learning, Task-Aware Guidance
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce a large-scale dataset, VOR, for effective video object removal and to develop the EffectErase method to eliminate dynamic objects and their visual effects in videos.
🛠️ Research Methods:
– Use of a large-scale dataset VOR consisting of 60K high-quality video pairs showcasing a range of effects and dynamic scenes. The method incorporates reciprocal learning and task-aware guidance to focus on effect regions.
💬 Research Conclusions:
– EffectErase outperforms other methods by accurately erasing object effects and synthesizing coherent backgrounds across various scenarios, thanks to the robust dataset and innovative approach.
👉 Paper link: https://huggingface.co/papers/2603.19224

9. SimulU: Training-free Policy for Long-form Simultaneous Speech-to-Speech Translation
🔑 Keywords: SimulS2S, training-free, history management, cross-attention, end-to-end models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research introduces SimulU, a training-free approach for long-form simultaneous speech-to-speech translation, aiming to overcome limitations in current solutions that require extensive training and struggle with continuous speech.
🛠️ Research Methods:
– Utilizes history management and cross-attention mechanisms in pre-trained end-to-end models to manage input history and output generation effectively.
💬 Research Conclusions:
– SimulU achieves a quality-latency trade-off that is better or comparable to existing strong cascaded models across 8 languages evaluated on MuST-C. It offers a promising path for end-to-end simultaneous speech-to-speech translation in long-form scenarios without the need for additional training.
👉 Paper link: https://huggingface.co/papers/2603.16924

10. MOSS-TTS Technical Report
🔑 Keywords: speech generation, discrete audio tokens, autoregressive modeling, multilingual, voice cloning
💡 Category: Generative Models
🌟 Research Objective:
– To introduce MOSS-TTS, a speech generation model with capabilities like voice cloning, pronunciation control, and multilingual support.
🛠️ Research Methods:
– Utilization of discrete audio tokens and autoregressive modeling.
– Deployment of a causal Transformer tokenizer for efficient audio compression and representation.
💬 Research Conclusions:
– The MOSS-TTS model emphasizes structural simplicity and scalability, supporting functionalities such as zero-shot voice cloning and smooth code-switching across multi-lingual settings.
– MOSS-TTS-Local-Transformer enhances modeling efficiency and speaker preservation, achieving a quicker time to first audio.
👉 Paper link: https://huggingface.co/papers/2603.18090

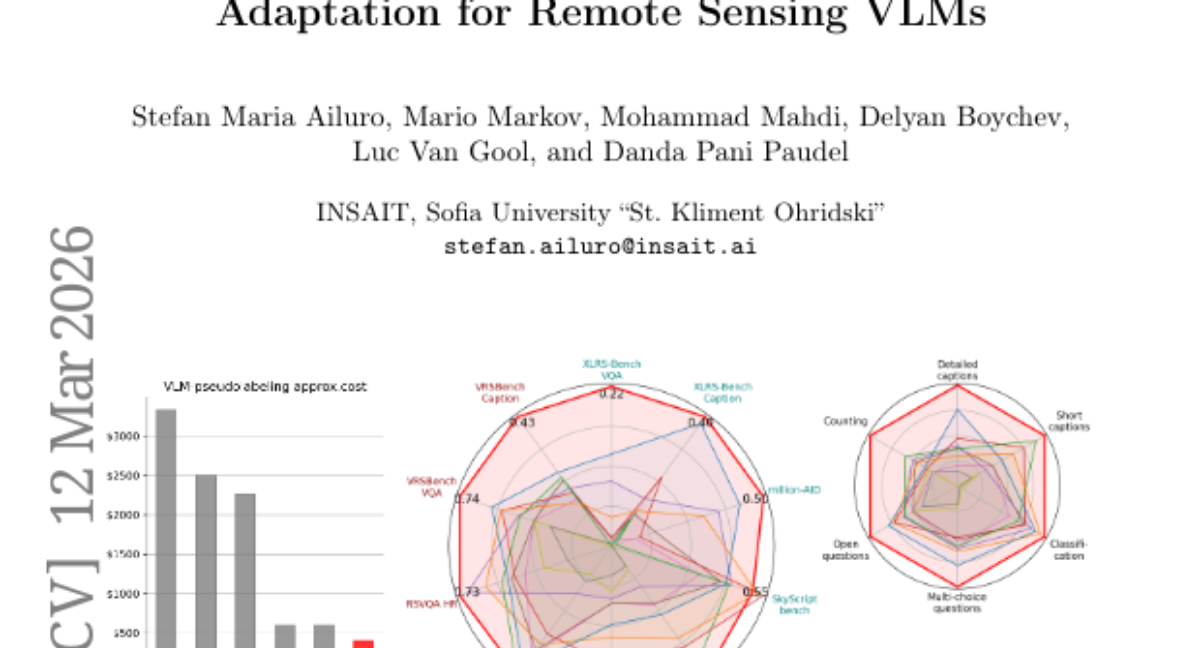
11. OSM-based Domain Adaptation for Remote Sensing VLMs
🔑 Keywords: Vision-Language Models, domain adaptation, OpenStreetMap, optical character recognition, pseudo-labeling
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a self-contained domain adaptation framework for vision-language models in remote sensing using OpenStreetMap data and optical character recognition, minimizing reliance on external teachers or manual labeling.
🛠️ Research Methods:
– Utilizing a base vision-language model as its own annotation engine by pairing aerial images with rendered OpenStreetMap tiles, leveraging optical character recognition and chart comprehension.
💬 Research Conclusions:
– Achieves state-of-the-art results across 10 benchmarks, proving to be significantly cheaper than teacher-dependent methods while enabling scalability with crowd-sourced geographic data, with dataset and model weights to be publicly available.
👉 Paper link: https://huggingface.co/papers/2603.11804
12. MHPO: Modulated Hazard-aware Policy Optimization for Stable Reinforcement Learning
🔑 Keywords: Modulated Hazard-aware Policy Optimization, Reinforcement Learning, Log-Fidelity Modulator, Decoupled Hazard Penalty
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces Modulated Hazard-aware Policy Optimization (MHPO), aiming to enhance the stability and robustness of reinforcement learning by managing importance ratios and controlling policy shifts.
🛠️ Research Methods:
– The implementation involves a Log-Fidelity Modulator which maps unbounded importance ratios to a bounded domain, and a Decoupled Hazard Penalty to regulate policy shifts using cumulative hazard functions.
💬 Research Conclusions:
– MHPO achieves superior performance and enhanced training stability over existing methods, as demonstrated in various reasoning benchmarks across text-based and vision-language tasks.
👉 Paper link: https://huggingface.co/papers/2603.16929

13. Prompt-Free Universal Region Proposal Network
🔑 Keywords: Prompt-Free, Region Proposal Network, Sparse Image-Aware Adapter, Cascade Self-Prompt, Computer Vision
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a Prompt-Free Universal Region Proposal Network (PF-RPN) to identify potential objects without relying on external prompts across various computer vision applications.
🛠️ Research Methods:
– Utilized Sparse Image-Aware Adapter (SIA) module for initial object localization with learnable query embedding dynamically updated with visual features.
– Employed Cascade Self-Prompt (CSP) module to autonomously aggregate visual features in a cascading manner to identify remaining potential objects.
– Implemented Centerness-Guided Query Selection (CG-QS) module for selecting high-quality query embeddings using a centerness scoring network.
💬 Research Conclusions:
– The method can perform robust object identification across diverse domains (e.g., underwater, industrial, remote sensing) with minimal data requirement (5% of MS COCO data) and does not need fine-tuning, verified by testing on 19 datasets.
👉 Paper link: https://huggingface.co/papers/2603.17554

14. Matryoshka Gaussian Splatting
🔑 Keywords: Matryoshka Gaussian Splatting, level of detail, 3D Gaussian Splatting, stochastic budget training, rendering quality
💡 Category: Computer Vision
🌟 Research Objective:
– To develop Matryoshka Gaussian Splatting (MGS) for continuous level of detail rendering that maintains full-capacity quality in 3D Gaussian Splatting systems.
🛠️ Research Methods:
– Introduced stochastic budget training that involves sampling a random splat budget and optimizing both the prefix and the full set in each iteration.
– Conducted experiments across four benchmarks and six baselines to validate the framework’s performance.
💬 Research Conclusions:
– MGS enables a continuous speed-quality trade-off from a single model without sacrificing full-capacity rendering quality and matches the performance of its backbone in full-capacity scenarios.
👉 Paper link: https://huggingface.co/papers/2603.19234

15. Mending the Holes: Mitigating Reward Hacking in Reinforcement Learning for Multilingual Translation
🔑 Keywords: Large Language Models, Low-resource translation, Reinforcement Learning, Monolingual text, Multilingual LLMs
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance the translation capabilities of Large Language Models (LLMs) on low-resource languages while maintaining their performance on high-resource languages using a method called WALAR.
🛠️ Research Methods:
– The study introduces WALAR, a reinforcement training method that leverages monolingual text and addresses the “holes” in existing multilingual quality estimation (QE) models through techniques like word alignment and language alignment.
💬 Research Conclusions:
– The WALAR-enhanced LLM significantly outperforms the strong multilingual LLaMAX model on 1400 language directions in the Flores-101 dataset, improving translation for 101 languages.
👉 Paper link: https://huggingface.co/papers/2603.13045

16. VID-AD: A Dataset for Image-Level Logical Anomaly Detection under Vision-Induced Distraction
🔑 Keywords: logical anomaly detection, AI-generated summary, contrastive learning, text descriptions
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to address challenges in logical anomaly detection within industrial inspection by introducing a dataset called VID-AD that accounts for visual distractions.
🛠️ Research Methods:
– The approach leverages a language-based anomaly detection framework relying on contrastive learning with text descriptions generated from normal images.
💬 Research Conclusions:
– The new method shows consistent improvements over baseline methods across various evaluated settings, helping to better identify rule-level violations in visually distracting environments.
👉 Paper link: https://huggingface.co/papers/2603.13964

17.

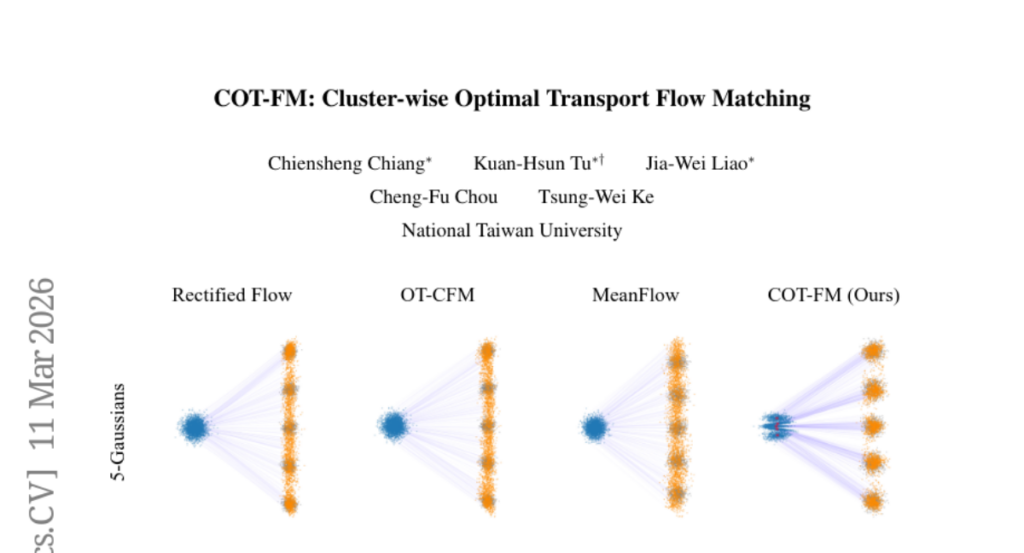
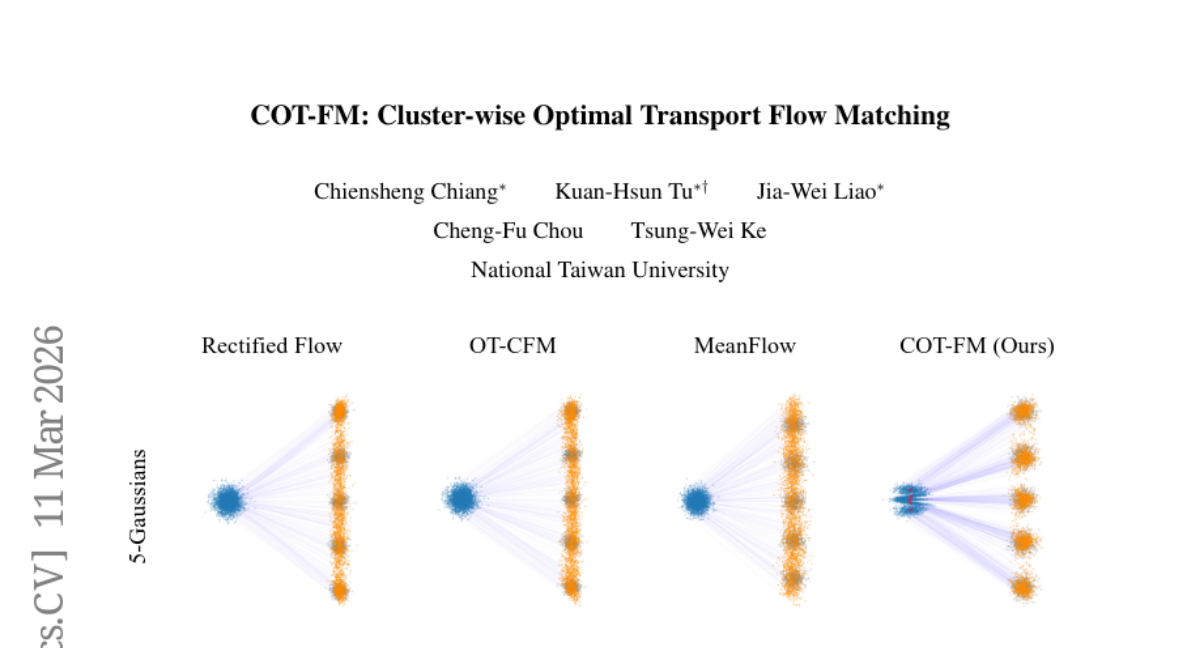
18. COT-FM: Cluster-wise Optimal Transport Flow Matching
🔑 Keywords: COT-FM, Flow Matching, clustering, sampling, generation quality
💡 Category: Generative Models
🌟 Research Objective:
– Introduce COT-FM, a general framework to enhance Flow Matching by reshaping probability paths for faster and more reliable generation.
🛠️ Research Methods:
– Utilizes clustering to group target samples and assigns dedicated source distributions using reversed pretrained FM models to improve sampling accuracy and quality.
💬 Research Conclusions:
– COT-FM improves local transport accuracy and straightens vector fields, accelerating sampling and enhancing generation quality across various tasks without altering existing model architectures.
👉 Paper link: https://huggingface.co/papers/2603.13395
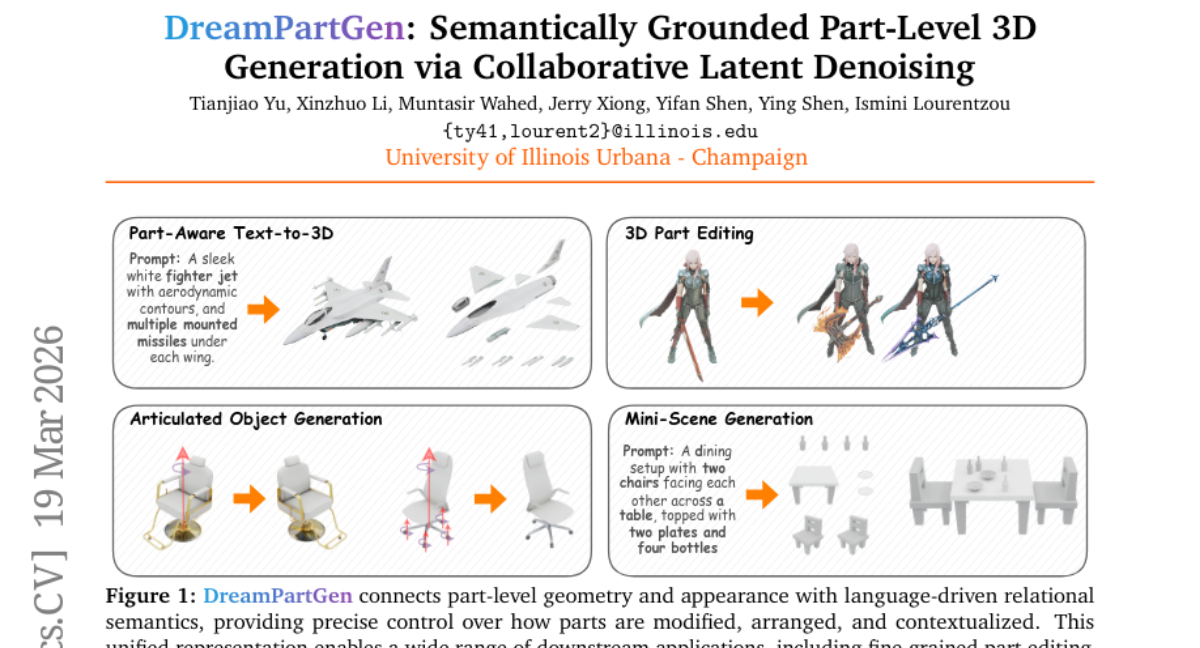
19. DreamPartGen: Semantically Grounded Part-Level 3D Generation via Collaborative Latent Denoising
🔑 Keywords: DreamPartGen, Text-to-3D, Duplex Part Latents, Relational Semantic Latents, Semantic Grounding
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal is to develop DreamPartGen, a framework that achieves semantically grounded, part-aware text-to-3D generation, aiming for improved text-shape alignment.
🛠️ Research Methods:
– Introduces Duplex Part Latents (DPLs) for modeling geometry and appearance and Relational Semantic Latents (RSLs) to capture language-derived inter-part dependencies.
– Utilizes a synchronized co-denoising process to ensure mutual geometric and semantic consistency.
💬 Research Conclusions:
– DreamPartGen demonstrates state-of-the-art performance in geometric fidelity and text-shape alignment across multiple benchmarks, achieving coherent and interpretable 3D synthesis.
👉 Paper link: https://huggingface.co/papers/2603.19216
20. PARSA-Bench: A Comprehensive Persian Audio-Language Model Benchmark
🔑 Keywords: PARSA-Bench, Persian language, audio-language models, speech understanding, cultural audio understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce PARSA-Bench, the first benchmark for evaluating large audio-language models on Persian language and culture with 16 tasks and over 8,000 samples.
🛠️ Research Methods:
– Evaluate models on tasks including speech understanding, paralinguistic analysis, poetry meter and style detection, traditional Persian music understanding, and code-switching detection.
💬 Research Conclusions:
– Text-only baselines outperform audio counterparts, indicating limitations in current models’ ability to leverage audio-specific information.
– Culturally-grounded tasks, like vazn detection, show models performing near random chance, highlighting challenges in prosodic perception.
👉 Paper link: https://huggingface.co/papers/2603.14456

21. What Really Controls Temporal Reasoning in Large Language Models: Tokenisation or Representation of Time?
🔑 Keywords: MultiTempBench, multilingual temporal reasoning, tokenization quality, Date Fragmentation Ratio (mDFR), temporal linearity
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study introduces MultiTempBench to evaluate the multilingual temporal reasoning capabilities of LLMs across various languages and calendar systems.
🛠️ Research Methods:
– The researchers created a benchmark with tasks like date arithmetic, time zone conversion, and temporal relation extraction in five languages. They evaluated 20 LLMs using the multilingual Date Fragmentation Ratio (mDFR) and performed geometric-probing analyses.
💬 Research Conclusions:
– Tokenization quality is a crucial bottleneck in low-resource languages, significantly affecting accuracy. Temporal linearity is the strongest predictor of temporal reasoning in high-resource languages, while fragmentation influences low-resource language outcomes.
👉 Paper link: https://huggingface.co/papers/2603.19017

22. Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
🔑 Keywords: LLM judges, mathematical objects, cross-format generalization, on-policy training, STEM applications
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to enhance the derivation capabilities for mathematical objects, a critical component for various STEM applications like mathematics, physics, and chemistry.
🛠️ Research Methods:
– Develops training recipes using strong LLM judges and verifiers, implementing on-policy judge training to improve performance.
– Builds and releases the Principia dataset and benchmarks for deriving mathematical objects.
💬 Research Conclusions:
– The study shows strong LLMs struggle with Principia benchmarks, but the proposed training recipes significantly improve performance and demonstrate cross-format generalization of reasoning abilities.
👉 Paper link: https://huggingface.co/papers/2603.18886

23. Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
🔑 Keywords: 3D understanding, Vision-Language Models, monocular video input, language-based localization, spatial supervision
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Enhance 2D Vision-Language Models with 3D understanding capabilities through spatial supervision derived from monocular video input.
🛠️ Research Methods:
– Utilize global layout reconstruction and explicit situation modeling to provide spatial supervision anchoring perception and language in a 3D context.
💬 Research Conclusions:
– Loc3R-VLM achieves state-of-the-art performance in language-based localization and surpasses existing methods in 3D question-answering benchmarks, proving its robust 3D understanding.
👉 Paper link: https://huggingface.co/papers/2603.18002

24. ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
🔑 Keywords: Multi-turn LLM agents, Reinforcement Learning, Sandboxed Rollout Trajectories, ProRL Agent, API Service
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To present a scalable infrastructure, ProRL Agent, for multi-turn LLM agents that enhances their long-horizon behavior through the use of reinforcement learning.
🛠️ Research Methods:
– Development of scalable rollout services and standardized sandbox environments to support diverse agentic tasks, validated with RL training across software engineering, math, STEM, and coding tasks.
💬 Research Conclusions:
– The ProRL Agent infrastructure facilitates migration and maintenance of systems by separating rollout orchestration from the training loop and is integrated into NVIDIA NeMo Gym providing an open-sourced solution.
👉 Paper link: https://huggingface.co/papers/2603.18815

25. VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
🔑 Keywords: Multimodal Large Language Models, VisualToolChain-Bench, tool-use proficiency, multi-tool composition, visual agentic capabilities
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VisualToolChain-Bench to evaluate the tool-use capabilities of multimodal large language models in complex visual tasks.
🛠️ Research Methods:
– The benchmark includes 32 diverse OpenCV-based visual operations to assess multi-tool composition and long-horizon multi-step planning through 680 curated problems across a cognitive hierarchy.
💬 Research Conclusions:
– Current models, including Gemini-3.0-Pro, demonstrate significant limitations in adapting to diverse tool-sets and generalizing to unseen operations, achieving only 51% on the benchmark. Multi-tool composition remains challenging, with models often relying on a narrow set of familiar functions instead of optimal tools.
👉 Paper link: https://huggingface.co/papers/2603.15030

26. Tinted Frames: Question Framing Blinds Vision-Language Models
🔑 Keywords: Vision-Language Models, linguistic framing, visual attention, prompt-tuning, learnable tokens
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate the selective blindness of Vision-Language Models and how linguistic framing affects their visual reasoning capabilities.
🛠️ Research Methods:
– Utilizing visual attention as a probe to measure changes in attention patterns across different linguistic framings.
– Introducing a lightweight prompt-tuning method with learnable tokens to improve visual grounding.
💬 Research Conclusions:
– Constrained framings lead to misallocated attention, reducing accuracy and consistency.
– The proposed prompt-tuning approach enhances performance by promoting robust, visually grounded attention patterns.
👉 Paper link: https://huggingface.co/papers/2603.19203

27. AndroTMem: From Interaction Trajectories to Anchored Memory in Long-Horizon GUI Agents
🔑 Keywords: GUI agents, interaction memory, anchored memory, Task Complete Rate, Anchored State Memory
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address the interaction memory challenges of long-horizon GUI agents using a diagnostic framework and anchored memory approach.
🛠️ Research Methods:
– Developed and utilized the AndroTMem diagnostic framework, including the AndroTMem-Bench benchmark with 1,069 tasks and 34,473 interaction steps, focusing on causal dependencies and task completion rate (TCR).
💬 Research Conclusions:
– Anchored State Memory (ASM) significantly improves task completion rates and mitigates interaction-memory bottlenecks, outperforming baseline methods by improving TCR by 5%-30.16% and AMS by 4.93%-24.66%.
👉 Paper link: https://huggingface.co/papers/2603.18429

28. ReactMotion: Generating Reactive Listener Motions from Speaker Utterance
🔑 Keywords: Reactive Listener Motion Generation, ReactMotionNet, generative framework, preference-oriented evaluation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces a new task called Reactive Listener Motion Generation, aiming to generate naturalistic listener body motions in response to speaker utterances.
🛠️ Research Methods:
– The authors propose ReactMotionNet, a large-scale dataset designed to pair speaker utterances with multiple listener motions, and develop preference-oriented evaluation protocols.
– They also present ReactMotion, a unified generative framework that incorporates text, audio, emotion, and motion.
💬 Research Conclusions:
– Experiments demonstrate that ReactMotion outperforms existing retrieval baselines and LLM-based pipelines, generating more natural, diverse, and appropriate listener motions.
👉 Paper link: https://huggingface.co/papers/2603.15083

29. Memento-Skills: Let Agents Design Agents
🔑 Keywords: Generalist Language Model, Memory-based Reinforcement Learning, Stateful Prompts, Continual Learning, AI-generated Summary
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce Memento-Skills, a generalist language model system that autonomously designs and improves task-specific agents using memory-based reinforcement learning with stateful prompts and skill libraries.
🛠️ Research Methods:
– Utilizes a memory-based reinforcement learning framework with stateful prompts and reusable skills, encoded as structured markdown files, to serve as evolving memory and facilitate continual learning.
💬 Research Conclusions:
– Memento-Skills enables the progressive improvement of agent design through iterative skill generation and refinement, achieving significant accuracy improvements in benchmark tests.
👉 Paper link: https://huggingface.co/papers/2603.18743

30. Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
🔑 Keywords: CubiD, discrete generation, high-dimensional representations, multimodal architectures, fine-grained masking
💡 Category: Generative Models
🌟 Research Objective:
– Introduce CubiD, a discrete generation model for high-dimensional representations, improving semantic richness.
🛠️ Research Methods:
– Implementation of fine-grained masking to predict masked dimensions from partial observations, maintaining fixed generation steps across feature dimensionalities.
💬 Research Conclusions:
– CubiD achieves state-of-the-art discrete generation on ImageNet-256, maintaining original representation capabilities and supporting both understanding and generation tasks.
👉 Paper link: https://huggingface.co/papers/2603.19232

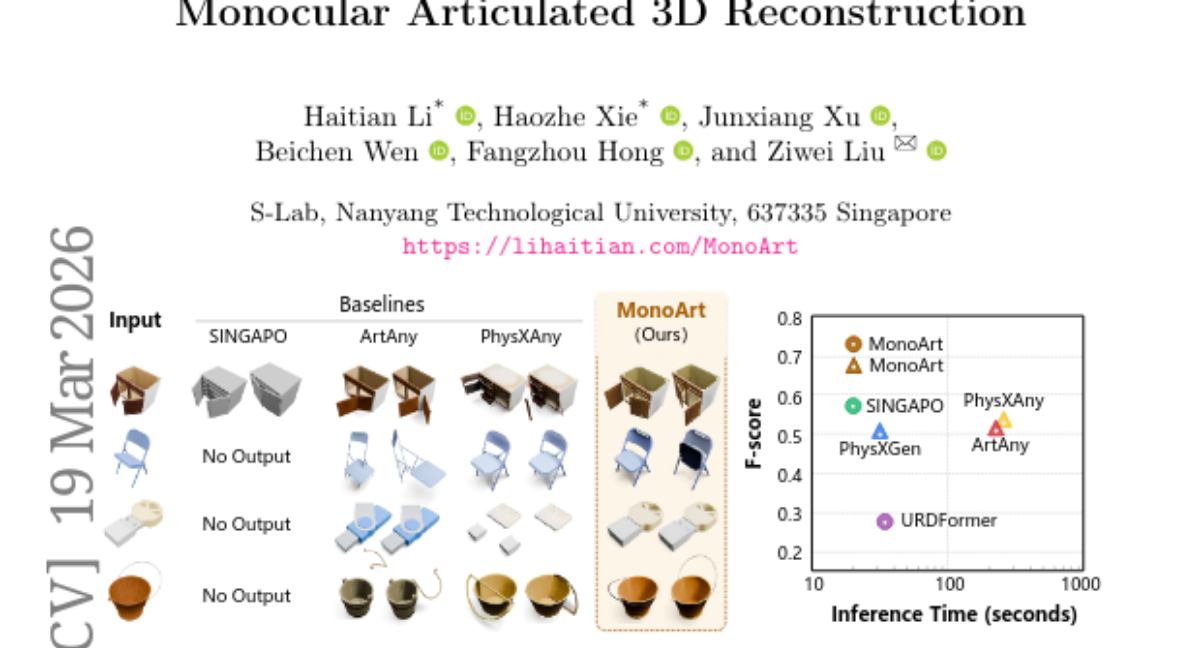
31. MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction
🔑 Keywords: MonoArt, progressive structural reasoning, articulated 3D objects, canonical geometry, robotic manipulation
💡 Category: Computer Vision
🌟 Research Objective:
– MonoArt aims to reconstruct articulated 3D objects from single images using a unified framework that emphasizes progressive structural reasoning.
🛠️ Research Methods:
– The framework transforms visual observations into canonical geometry and structured part representations, enabling stable inference without external templates.
💬 Research Conclusions:
– MonoArt demonstrates state-of-the-art performance in reconstruction accuracy and inference speed, and it extends to applications like robotic manipulation and articulated scene reconstruction.
👉 Paper link: https://huggingface.co/papers/2603.19231
32. 3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
🔑 Keywords: 3D-aware video customization, temporal motion, spatial geometry, AI-generated summary, visual conditioning module
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce a novel 3D-aware video customization framework that addresses limitations in 3D geometry reconstruction by decoupling spatial geometry from temporal motion.
🛠️ Research Methods:
– Utilizes a 1-frame optimization approach combined with a visual conditioning module for enhanced texture generation and view-consistent video creation.
💬 Research Conclusions:
– The proposed method effectively integrates a robust 3D prior without extensive video training, enabling dynamic video generation and maintaining true 3D identity through multi-view joint optimization.
👉 Paper link: https://huggingface.co/papers/2603.18524
33. SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
🔑 Keywords: Semantic Anchoring, Motion Alignment, Video Editing, Pre-training, Zero-shot
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a factorized approach for video editing that separates semantic anchoring from motion modeling to enable instruction-guided edits while preserving motion.
🛠️ Research Methods:
– Introduced SAMA framework that differentiates between semantic anchoring and motion alignment.
– First stage involves semantic anchoring through predicting semantic tokens and video latents at sparse anchor frames.
– Second stage involves motion alignment via pre-training on motion-centric video restoration tasks.
– Utilized a two-stage optimization pipeline: factorized pre-training followed by supervised fine-tuning.
💬 Research Conclusions:
– The factorized pre-training alone provides strong zero-shot video editing capabilities.
– SAMA achieves state-of-the-art performance among open-source models and is competitive with leading commercial systems.
👉 Paper link: https://huggingface.co/papers/2603.19228
