AI Native Daily Paper Digest – 20260327
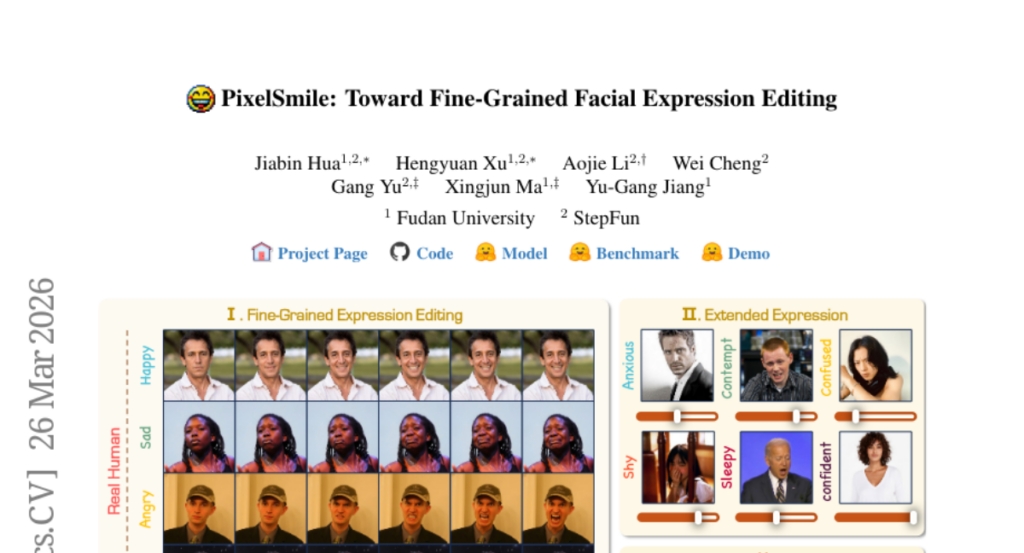
1. PixelSmile: Toward Fine-Grained Facial Expression Editing
🔑 Keywords: PixelSmile, facial expression editing, semantic overlap, diffusion framework, contrastive learning
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to address the limitations in fine-grained facial expression editing caused by intrinsic semantic overlap by developing a diffusion framework called PixelSmile.
🛠️ Research Methods:
– The authors introduce the Flex Facial Expression (FFE) dataset with continuous affective annotations and establish FFE-Bench for evaluation. They utilize symmetric joint training combined with intensity supervision and contrastive learning to disentangle expression semantics.
💬 Research Conclusions:
– PixelSmile demonstrates superior expression disentanglement and robust identity preservation, allowing for continuous, controllable, and fine-grained expression editing, including smooth expression blending.
👉 Paper link: https://huggingface.co/papers/2603.25728
2. RealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
🔑 Keywords: Image restoration, real-world degradations, open-source model, large-scale dataset, RealIR-Bench
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to improve image restoration performance using a large-scale dataset and an open-source model to effectively handle real-world degradations.
🛠️ Research Methods:
– Development of a large-scale dataset covering nine common real-world degradation types.
– Training and evaluation of a state-of-the-art open-source model using RealIR-Bench, which evaluates degradation removal and consistency preservation.
💬 Research Conclusions:
– The open-source model significantly narrows the performance gap with closed-source alternatives and ranks first among open-source methods in achieving state-of-the-art results.
👉 Paper link: https://huggingface.co/papers/2603.25502

3. MACRO: Advancing Multi-Reference Image Generation with Structured Long-Context Data
🔑 Keywords: Multi-reference generation, Long-context supervision, MacroData, MacroBench, Generative coherence
💡 Category: Generative Models
🌟 Research Objective:
– Introduce MacroData and MacroBench to address limitations in multi-reference image generation by providing structured long-context supervision and standardized evaluation protocols.
🛠️ Research Methods:
– Creation of MacroData, a dataset with 400K samples and up to 10 reference images each, organized across four dimensions to cover the multi-reference generation space.
– Proposal of MacroBench, a benchmark of 4,000 samples to assess generative coherence across various task dimensions and input scales.
💬 Research Conclusions:
– Fine-tuning on MacroData significantly improves multi-reference generation.
– Ablation studies reveal benefits of cross-task co-training and strategies for managing long-context complexity.
– The dataset and benchmark will be publicly released to aid further research.
👉 Paper link: https://huggingface.co/papers/2603.25319

4. SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
🔑 Keywords: Iterative Software Development, SlopCodeBench, Trajectory-Level Quality Signals, Verbosity, Structural Erosion
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce SlopCodeBench, a language-agnostic benchmark that evaluates how agents extend their own prior solutions under evolving specifications.
🛠️ Research Methods:
– Development of a benchmark with 20 problems and 93 checkpoints focusing on trajectory-level quality signals such as verbosity and structural erosion.
– Evaluation of the agent’s performance across 11 models and comparison against 48 open-source Python repositories.
💬 Research Conclusions:
– Current pass-rate benchmarks under-measure extension robustness, and agents display increasing verbosity and structural erosion, highlighting a lack of design discipline required for iterative software development.
– Initial quality improvements are possible through prompt-intervention studies, but degradation in agent code continues to persist over time.
👉 Paper link: https://huggingface.co/papers/2603.24755

5. AVControl: Efficient Framework for Training Audio-Visual Controls
🔑 Keywords: AVControl, LoRA, parallel canvas, modular audio-visual controls, LTX-2
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to develop an efficient and modular approach for audio-visual generation by using AVControl, which separates control modalities to be trained as distinct LoRA adapters on a parallel canvas within the LTX-2 framework.
🛠️ Research Methods:
– The research employs a lightweight and extendable framework, AVControl, which does not require architectural changes beyond the LoRA adapters. Each control modality is trained independently on a parallel canvas using a joint audio-visual foundation model.
💬 Research Conclusions:
– AVControl outperforms baseline methods on the VACE Benchmark for depth- and pose-guided generation, demonstrating superior performance in tasks like inpainting and outpainting. The framework is data and compute-efficient, needing only small datasets and minimal training steps.
👉 Paper link: https://huggingface.co/papers/2603.24793
6. Representation Alignment for Just Image Transformers is not Easier than You Think
🔑 Keywords: Representation Alignment, Diffusion Transformers, Pixel-Space, Information Asymmetry, Masked Transformer Adapter
💡 Category: Generative Models
🌟 Research Objective:
– Address failure in Representation Alignment for pixel-space diffusion transformers by introducing PixelREPA.
🛠️ Research Methods:
– Developed PixelREPA to transform alignment targets and utilized Masked Transformer Adapters for improved training convergence and image quality.
💬 Research Conclusions:
– PixelREPA significantly improves FID and Inception Score compared to previous methods while achieving faster training convergence.
👉 Paper link: https://huggingface.co/papers/2603.14366

7. S2D2: Fast Decoding for Diffusion LLMs via Training-Free Self-Speculation
🔑 Keywords: Training-free, Block-diffusion language models, Speculative decoding, Accuracy-speed tradeoff, Autoregressive verification
💡 Category: Generative Models
🌟 Research Objective:
– To enhance the accuracy-speed tradeoff in block-diffusion language models using a training-free self-speculative decoding framework named S2D2.
🛠️ Research Methods:
– The use of parallel block generation combined with autoregressive verification, utilizing speculative verification steps and lightweight routing policies.
💬 Research Conclusions:
– S2D2 consistently enhances the accuracy-speed tradeoff compared to strong confidence-thresholding baselines, achieving significant speedups and accuracy improvements across various block-diffusion models.
👉 Paper link: https://huggingface.co/papers/2603.25702

8. AVO: Agentic Variation Operators for Autonomous Evolutionary Search
🔑 Keywords: Agentic Variation Operators, Evolutionary Search, Autonomous Coding Agents, NVIDIA Blackwell, Micro-Architectural Optimizations
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce Agentic Variation Operators (AVO) to autonomously discover performance-critical micro-architectural optimizations for attention kernels in advanced GPU hardware.
🛠️ Research Methods:
– Utilize autonomous coding agents instead of fixed mutation/crossover techniques and evaluate AVO on NVIDIA Blackwell (B200) GPUs over a continuous 7-day period.
💬 Research Conclusions:
– AVO significantly outperforms state-of-the-art implementations such as cuDNN and FlashAttention-4, achieving up to a 10.5% increase in performance, showcasing the potential of agent-driven optimization.
👉 Paper link: https://huggingface.co/papers/2603.24517

9. BioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment
🔑 Keywords: AI-generated, BioVITA, multimodal, unified representation space
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a novel visual-textual-acoustic alignment framework, termed BioVITA, for biological species identification by integrating visual, textual, and acoustic data.
🛠️ Research Methods:
– Constructed a large-scale training dataset with 1.3 million audio clips and 2.3 million images across over 14,000 species.
– Introduced a two-stage training framework to align audio, visual, and textual data, enhancing the BioCLIP model.
– Developed a cross-modal retrieval benchmark covering multiple taxonomic levels.
💬 Research Conclusions:
– Demonstrated the ability of the model to learn a unified representation space that captures species-level semantics beyond traditional taxonomy.
– Advanced the understanding of multimodal biodiversity by effectively integrating audio, visual, and textual data.
👉 Paper link: https://huggingface.co/papers/2603.23883

10. Can MLLMs Read Students’ Minds? Unpacking Multimodal Error Analysis in Handwritten Math
🔑 Keywords: handwritten scratchwork, Error Cause Explanation, multimodal large language models, AI in Education, visual reasoning
💡 Category: AI in Education
🌟 Research Objective:
– The aim of this research is to introduce ScratchMath, a benchmark for analyzing handwritten mathematics scratchwork, focusing on explaining and classifying errors from student math samples.
🛠️ Research Methods:
– Utilized a dataset of 1,720 samples from Chinese students, annotated through human-machine collaboration, and evaluated 16 leading multimodal large language models (MLLMs) for Error Cause Explanation and Error Cause Classification tasks.
💬 Research Conclusions:
– Significant performance gaps were identified between MLLMs and human experts in visual recognition and logical reasoning, with proprietary models notably outperforming open-source models.
👉 Paper link: https://huggingface.co/papers/2603.24961

11. Electrostatic Photoluminescence Tuning in All-Solid-State Perovskite Transistors
🔑 Keywords: Metal Halide Perovskites, Photoluminescence, Gate Voltage, Optoelectronic Switches
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To demonstrate reversible photoluminescence control in large-area thin-film devices using epitaxial single crystalline metal halide perovskites.
🛠️ Research Methods:
– Utilizing a solid-state semiconductor device to modulate photoluminescence through gate voltage, affecting radiative and nonradiative recombination channels.
💬 Research Conclusions:
– High external photoluminescence quantum efficiencies were achieved, with photoluminescence intensity modulated by up to 98%. This advances the application potential of metal-halide perovskites in photonics and optoelectronics.
👉 Paper link: https://huggingface.co/papers/2603.25718

12. WAFT-Stereo: Warping-Alone Field Transforms for Stereo Matching
🔑 Keywords: WAFT-Stereo, Warping, Stereo Matching, Cost Volumes, ETH3D
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce WAFT-Stereo, a warping-based method that eliminates the need for cost volumes in stereo matching for better performance.
🛠️ Research Methods:
– Implementing a warping technique instead of traditional cost volumes to improve efficiency and accuracy in stereo matching benchmarks.
💬 Research Conclusions:
– WAFT-Stereo achieved state-of-the-art results, ranking first on ETH3D, KITTI, and Middlebury benchmarks, reducing zero-shot error by 81% on ETH3D, and being 1.8-6.7 times faster than current leading methods.
👉 Paper link: https://huggingface.co/papers/2603.24836

13. Vega: Learning to Drive with Natural Language Instructions
🔑 Keywords: Vega, Vision-Language-World-Action, instruction-based generation, autoregressive paradigm, diffusion paradigm
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a unified model, Vega, for instruction-based driving planning and trajectory generation that integrates vision, language, and action modalities.
🛠️ Research Methods:
– Constructed the InstructScene dataset with approximately 100,000 scenes annotated with diverse driving instructions.
– Combined autoregressive and diffusion paradigms to process visual inputs and language instructions, and to generate predictions and trajectories.
💬 Research Conclusions:
– The proposed model demonstrates superior planning performance and strong instruction-following abilities, facilitating more intelligent and personalized driving systems.
👉 Paper link: https://huggingface.co/papers/2603.25741

14. Nudging Hidden States: Training-Free Model Steering for Chain-of-Thought Reasoning in Large Audio-Language Models
🔑 Keywords: Inference-time model steering, Large Audio-Language Models (LALMs), Cross-modal transfer, Model steering, Chain-of-thought (CoT) prompting.
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This research explores inference-time model steering as a training-free methodology to enhance reasoning in Large Audio-Language Models (LALMs).
🛠️ Research Methods:
– Three strategies utilizing diverse information sources were introduced and evaluated across four LALMs and four benchmarks to test their effectiveness.
💬 Research Conclusions:
– The study found accuracy improvements up to 4.4% over traditional Chain-of-thought prompting. A significant finding was the successful cross-modal transfer of steering vectors from text to speech, offering high data efficiency and demonstrating robustness to hyperparameter variations.
👉 Paper link: https://huggingface.co/papers/2603.14636

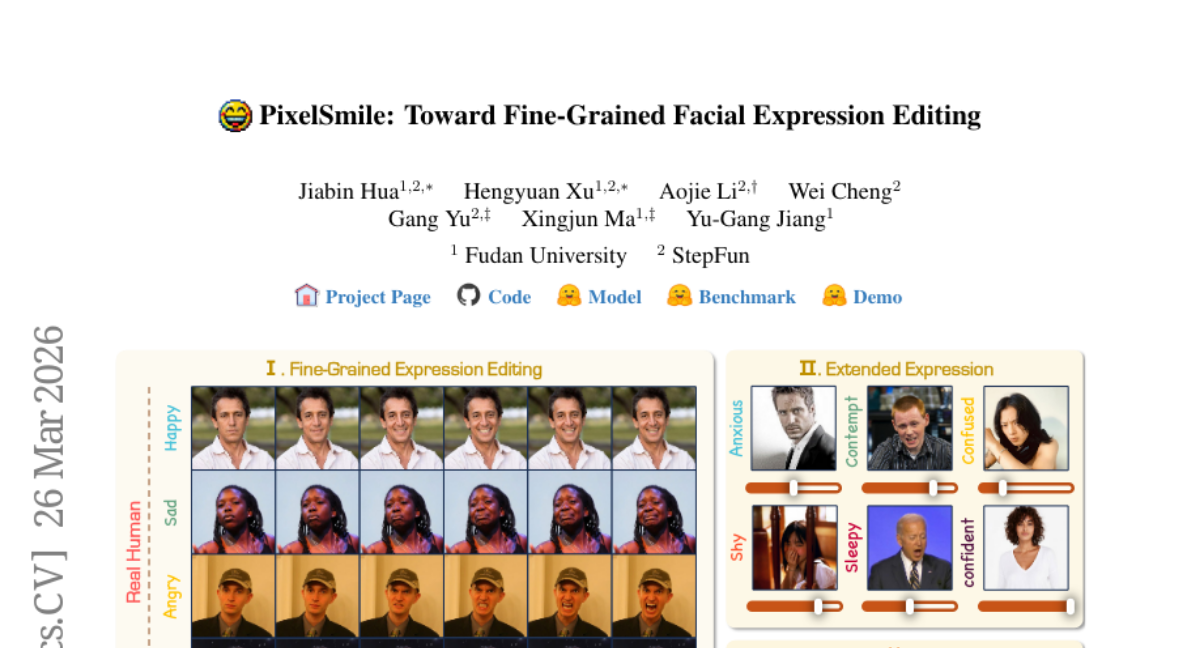
15. Extending Precipitation Nowcasting Horizons via Spectral Fusion of Radar Observations and Foundation Model Priors
🔑 Keywords: Precipitation nowcasting, Frequency-domain fusion, Meteorological variables, Pangu-Weather
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective is to enhance long-term forecasting accuracy for precipitation nowcasting by integrating radar imagery with meteorological forecasts using frequency-domain fusion techniques.
🛠️ Research Methods:
– The paper introduces PW-FouCast, a novel framework that employs Pangu-Weather forecasts as spectral priors within a Fourier-based backbone, incorporating innovations like Frequency Modulation, Frequency Memory, and Inverted Frequency Attention to address discrepancies between radar and meteorological data.
💬 Research Conclusions:
– PW-FouCast demonstrates state-of-the-art performance on the SEVIR and MeteoNet benchmarks, extending the reliable forecast horizon while maintaining structural fidelity of forecasts.
👉 Paper link: https://huggingface.co/papers/2603.21768
16.

17. IQuest-Coder-V1 Technical Report
🔑 Keywords: IQuest-Coder-V1, Code Large Language Models, Multi-Stage Training, Autonomous Code Intelligence
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce IQuest-Coder-V1 series, a family of code LLMs, to capture dynamic evolution of software logic and achieve state-of-the-art performance in code intelligence.
🛠️ Research Methods:
– Utilize a code-flow multi-stage training approach, encompassing initial pre-training, specialized mid-training integrating reasoning and agentic trajectories, and post-training with bifurcated paths for thinking and instruction.
💬 Research Conclusions:
– Achieves state-of-the-art performance in code intelligence across dimensions such as agentic software engineering, competitive programming, and complex tool use, with the IQuest-Coder-V1-Loop variant optimizing the trade-off between model capacity and deployment footprint.
👉 Paper link: https://huggingface.co/papers/2603.16733

18. VFIG: Vectorizing Complex Figures in SVG with Vision-Language Models
🔑 Keywords: Vision-Language Models, Scalable Vector Graphics (SVG), coarse-to-fine training, supervised fine-tuning, reinforcement learning
💡 Category: Generative Models
🌟 Research Objective:
– Introduce VFIG, a vision-language model family designed for converting raster images to vector graphics effectively to preserve image fidelity and editability.
🛠️ Research Methods:
– Develop VFIG-DATA, a large-scale dataset of 66K figure-SVG pairs.
– Implement a hierarchical training approach starting with supervised fine-tuning and progressing to reinforcement learning for optimizing diagram fidelity and layout.
💬 Research Conclusions:
– VFIG surpasses existing open-source models, performing on par with proprietary models like GPT-5.2, evidenced by achieving a VLM-Judge score of 0.829 on VFIG-BENCH.
👉 Paper link: https://huggingface.co/papers/2603.24575

19. Reaching Beyond the Mode: RL for Distributional Reasoning in Language Models
🔑 Keywords: Multi-answer reinforcement learning, Language models, Distributional reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To train language models to generate multiple plausible hypotheses with confidence estimates without repeated sampling.
🛠️ Research Methods:
– Application of a multi-answer reinforcement learning approach to enable LMs to perform distributional reasoning over multiple answers in a single forward pass.
💬 Research Conclusions:
– The approach improves diversity, coverage, and set-level calibration scores across various benchmarks and is more accurate for coding tasks.
– Models require fewer tokens for generating multiple answers compared to other methods, offering a compute-efficient alternative to inference-time scaling procedures.
👉 Paper link: https://huggingface.co/papers/2603.24844

20. Pixel-level Scene Understanding in One Token: Visual States Need What-is-Where Composition
🔑 Keywords: Robotic Decision Making, Visual State Representation Learning, Self-Supervised Learning, Global-to-Local Reconstruction, Sequential Decision Making
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce CroBo, a visual state representation learning framework for robotic decision making in dynamic environments, focusing on capturing semantic identities and spatial locations of scene elements.
🛠️ Research Methods:
– Employ a global-to-local reconstruction objective that utilizes a compact bottleneck token to reconstruct heavily masked patches in a local target crop from sparse visible cues.
💬 Research Conclusions:
– CroBo achieves state-of-the-art performance in vision-based robot policy learning benchmarks, demonstrating its ability to encode fine-grained scene-wide semantic entities and support sequential decision making.
👉 Paper link: https://huggingface.co/papers/2603.13904

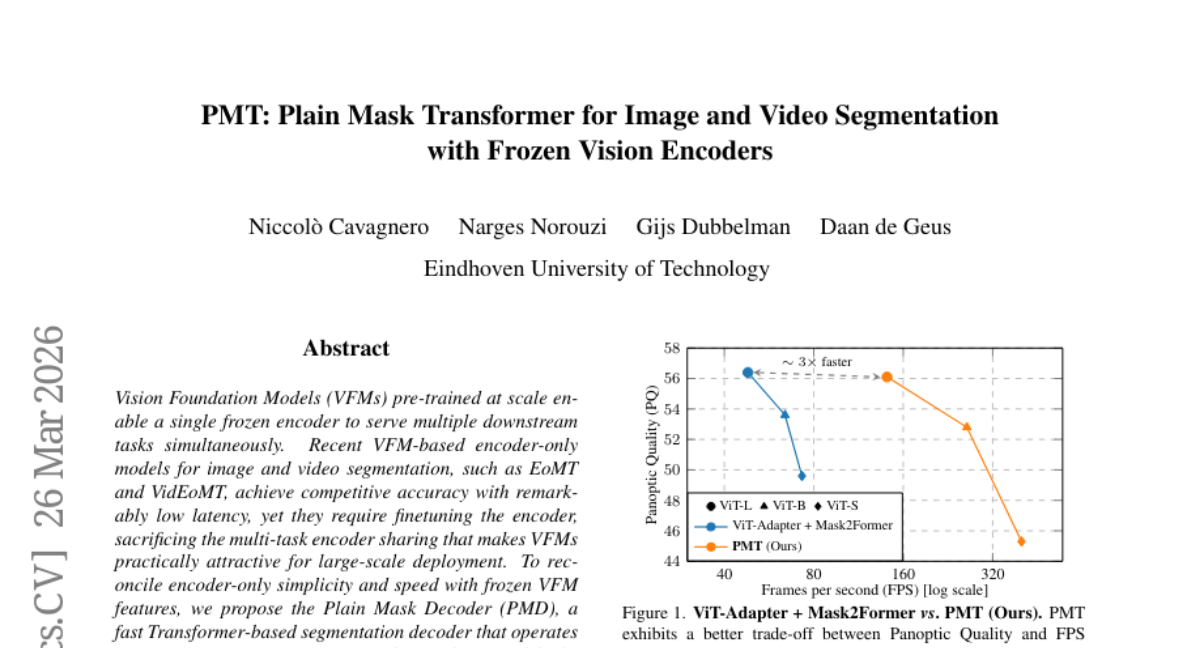
21. PMT: Plain Mask Transformer for Image and Video Segmentation with Frozen Vision Encoders
🔑 Keywords: Vision Foundation Models, Plain Mask Decoder, frozen encoder, video segmentation, image segmentation
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a segmentation model that maintains the benefits of Vision Foundation Models, preserving encoder simplicity and speed without sacrificing multi-task capabilities.
🛠️ Research Methods:
– Introduction of the Plain Mask Decoder, a Transformer-based segmentation decoder that operates on top of frozen VFM features, forming the Plain Mask Transformer (PMT).
💬 Research Conclusions:
– PMT achieves competitive accuracy, matching state-of-the-art results on image segmentation benchmarks while running up to 3x faster; in video segmentation, it performs comparably to fully finetuned methods, with a speed increase of up to 8x.
👉 Paper link: https://huggingface.co/papers/2603.25398
22. MemMA: Coordinating the Memory Cycle through Multi-Agent Reasoning and In-Situ Self-Evolution
🔑 Keywords: Memory-augmented LLM agents, external memory banks, strategic blindness, Meta-Thinker, self-evolving memory construction
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance memory-augmented LLM agents by coordinating memory processes through structured guidance and self-evolving repair mechanisms.
🛠️ Research Methods:
– Introduced a plug-and-play multi-agent framework, MemMA, that integrates both forward and backward memory processes, featuring a Meta-Thinker and self-evolving memory construction methods.
💬 Research Conclusions:
– MemMA outperforms existing baselines and enhances LLM performance across multiple backbones with improved storage backends, demonstrating significant advancements in the coordination of memory cycles.
👉 Paper link: https://huggingface.co/papers/2603.18718

23. Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
🔑 Keywords: On-policy distillation, Large language models, Token-level signal, Teacher feedback, Reverse-KL
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the fragility of token-level signals in on-policy distillation for large language models in long-horizon settings and aims to improve estimation methods and implementation techniques to address these challenges.
🛠️ Research Methods:
– The researchers revisit on-policy distillation from both estimator and implementation perspectives. They utilize teacher top-K local support matching, truncated reverse-KL, and special-token masking, alongside top-p rollout sampling, to tackle identified issues.
💬 Research Conclusions:
– The study reveals the limitations of sampled-token OPD in terms of imbalance and reliability, suggesting that the proposed methods yield more stable optimization and enhance downstream performance in both single-task and multi-task training scenarios.
👉 Paper link: https://huggingface.co/papers/2603.25562

24. FinMCP-Bench: Benchmarking LLM Agents for Real-World Financial Tool Use under the Model Context Protocol
🔑 Keywords: FinMCP-Bench, large language models, tool invocation, financial problems, financial LLM agents
💡 Category: AI in Finance
🌟 Research Objective:
– The paper aims to introduce and describe FinMCP-Bench, a novel benchmark designed to evaluate large language models (LLMs) on solving real-world financial problems through tool invocation and reasoning.
🛠️ Research Methods:
– FinMCP-Bench includes 613 samples across 10 main scenarios and 33 sub-scenarios with both real and synthetic queries. It offers evaluation using 65 real financial MCPs and categorizes samples into single tool, multi-tool, and multi-turn for varied task complexity.
💬 Research Conclusions:
– The benchmark enables systematic assessment of mainstream LLMs, proposing metrics to measure tool invocation accuracy and reasoning capabilities, thus providing a practical and challenging testbed for advancing research in financial LLM agents.
👉 Paper link: https://huggingface.co/papers/2603.24943

25. MuRF: Unlocking the Multi-Scale Potential of Vision Foundation Models
🔑 Keywords: Vision Foundation Models, Multi-Resolution Fusion, visual perception, inductive biases
💡 Category: Computer Vision
🌟 Research Objective:
– To propose Multi-Resolution Fusion (MuRF) as a strategy for leveraging multiple resolutions in Vision Foundation Models during inference, overcoming the limitations of the single-scale paradigm.
🛠️ Research Methods:
– Utilized MuRF to process images at multiple resolutions through a frozen Vision Foundation Model, fusing the resulting features to form a unified representation without architectural changes or additional training.
💬 Research Conclusions:
– Demonstrated the effectiveness and universality of MuRF across various computer vision tasks and distinct Vision Foundation Model families, including DINOv2 and SigLIP2.
👉 Paper link: https://huggingface.co/papers/2603.25744

26. Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting
🔑 Keywords: LGTM, 4K novel view synthesis, Gaussian primitives, rendering resolution, feed-forward
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to address the scalability issues in high-resolution synthesis, such as 4K, by introducing the LGTM framework, which decouples geometric complexity from rendering resolution.
🛠️ Research Methods:
– The method involves predicting compact Gaussian primitives with per-primitive textures to overcome the limitations of previous feed-forward approaches.
💬 Research Conclusions:
– LGTM successfully enables high-fidelity 4K novel view synthesis using significantly fewer Gaussian primitives without the need for per-scene optimization, enhancing scalability and efficiency in rendering high-resolution views.
👉 Paper link: https://huggingface.co/papers/2603.25745

27. MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
🔑 Keywords: Memory Sparse Attention, large language models, sparse attention, RoPE, KV cache compression
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces Memory Sparse Attention (MSA), aiming to efficiently process extremely long contexts in large language models by overcoming existing limitations in attention architectures.
🛠️ Research Methods:
– Utilizes innovations such as scalable sparse attention and document-wise RoPE to achieve linear complexity in both training and inference.
– Incorporates KV cache compression and Memory Parallel for high-efficiency memory handling.
💬 Research Conclusions:
– MSA provides an efficient and scalable memory model framework, significantly reducing degradation and latency in long-context scenarios while outperforming leading models in benchmarks.
👉 Paper link: https://huggingface.co/papers/2603.23516

28. Voxtral TTS
🔑 Keywords: Voxtral TTS, multilingual text-to-speech, semantic speech tokens, flow-matching, voice cloning
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Voxtral TTS, a multilingual TTS model designed to generate natural and expressive speech from short audio snippets.
🛠️ Research Methods:
– Implementation of a hybrid architecture combining auto-regressive generation of semantic tokens with flow-matching for acoustic tokens, utilizing the Voxtral Codec trained with a hybrid VQ-FSQ quantization scheme.
💬 Research Conclusions:
– Voxtral TTS, evaluated by native speakers, outperforms competitors like ElevenLabs Flash v2.5 in naturalness and expressivity, achieving a 68.4% preference rate in multilingual voice cloning tasks.
👉 Paper link: https://huggingface.co/papers/2603.25551

29. Calibri: Enhancing Diffusion Transformers via Parameter-Efficient Calibration
🔑 Keywords: Diffusion Transformers, learned scaling parameter, parameter-efficient approach, generative quality, evolutionary algorithm
💡 Category: Generative Models
🌟 Research Objective:
– To enhance the generative capabilities of Diffusion Transformers by optimizing parameter efficiency.
🛠️ Research Methods:
– Utilize a black-box reward optimization framework with an evolutionary algorithm to modify approximately 100 parameters in DiT components.
💬 Research Conclusions:
– The proposed Calibri approach improves generative performance and reduces inference steps in text-to-image models while maintaining high output quality.
👉 Paper link: https://huggingface.co/papers/2603.24800

30. Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
🔑 Keywords: Intern-S1-Pro, multimodal foundation model, specialized tasks, Reinforcement Learning, specialized intelligence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce and emphasize the capabilities of the Intern-S1-Pro, a one-trillion-parameter scientific multimodal foundation model that bridges general and scientific intelligence across multiple disciplines.
🛠️ Research Methods:
– Utilization of robust infrastructures like XTuner and LMDeploy to support efficient Reinforcement Learning training at the trillion-parameter scale, ensuring precision consistency between training and inference.
💬 Research Conclusions:
– Intern-S1-Pro, with its enhanced reasoning and image-text understanding capabilities, outperforms proprietary models in specialized scientific tasks while maintaining strong general capabilities, positioning itself as a leading open-source model.
👉 Paper link: https://huggingface.co/papers/2603.25040
