AI Native Daily Paper Digest – 20260401

1. FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
🔑 Keywords: FIPO, Reinforcement Learning, Discounted Future-KL Divergence, Dense Advantage Formulation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Present FIPO, an algorithm enhancing reinforcement learning by improving credit assignment and reasoning in language models.
🛠️ Research Methods:
– Incorporate discounted future-KL divergence into policy updates to improve token weighting based on their influence.
💬 Research Conclusions:
– FIPO extends reasoning chains and improves problem-solving, outperforming standard baselines in mathematical tasks.
👉 Paper link: https://huggingface.co/papers/2603.19835

2. LongCat-Next: Lexicalizing Modalities as Discrete Tokens
🔑 Keywords: Discrete Native Autoregressive, Multimodal Systems, Visual Transformer, Tokenization, LongCat-Next
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Discrete Native Autoregressive (DiNA), a framework for unified multimodal processing in a shared discrete space.
🛠️ Research Methods:
– Development of the Discrete Native Any-resolution Visual Transformer (dNaViT) for tokenization and de-tokenization of visual signals at arbitrary resolutions.
💬 Research Conclusions:
– LongCat-Next excels across multimodal benchmarks by integrating text, vision, and audio under a unified autoregressive objective, aiming to bridge the gap between understanding and generation.
👉 Paper link: https://huggingface.co/papers/2603.27538

3. GEMS: Agent-Native Multimodal Generation with Memory and Skills
🔑 Keywords: AI Native, Agent-Native, Multimodal, Agent Memory, Optimization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance multimodal generation capabilities through the development of the GEMS framework, focusing on overcoming limitations of foundational models on both general-purpose and downstream tasks.
🛠️ Research Methods:
– Utilizing a structured multi-agent framework called Agent Loop for iterative generation quality improvement, employing Agent Memory for persistent trajectory-level storage, and incorporating Agent Skill for domain-specific expertise extension.
💬 Research Conclusions:
– GEMS demonstrated significant performance improvements across mainstream and downstream tasks, notably enabling the lightweight 6B model Z-Image-Turbo to outperform state-of-the-art models like Nano Banana 2 on benchmark tests like GenEval2.
👉 Paper link: https://huggingface.co/papers/2603.28088

4. VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
🔑 Keywords: VGGRPO, Latent Geometry Model, 4D reconstruction, latent space, camera motion smoothness
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to enhance video diffusion models with latent geometry guidance to achieve improved geometric consistency and camera stability without the need for costly VAE decoding.
🛠️ Research Methods:
– VGGRPO framework introduces a Latent Geometry Model for stitching video diffusion latents with geometry foundation models, enabling direct decoding from the latent space. The approach employs latent-space Group Relative Policy Optimization with rewards for camera motion smoothness and geometry reprojection consistency.
💬 Research Conclusions:
– VGGRPO successfully improves camera stability and geometric consistency in both static and dynamic benchmarks, while eliminating the expensive process of VAE decoding, offering a more efficient method for world-consistent video generation.
👉 Paper link: https://huggingface.co/papers/2603.26599
5. CutClaw: Agentic Hours-Long Video Editing via Music Synchronization
🔑 Keywords: CutClaw, Multi-agent framework, Multimodal Language Models, Narrative consistency, Audio alignment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop an autonomous multi-agent framework called CutClaw to optimize and automate the creation of short, rhythmically consistent videos from raw footage using Multimodal Language Models.
🛠️ Research Methods:
– Utilize a hierarchical multimodal decomposition to capture visual and audio details.
– Employ a Playwriter Agent to manage storytelling and narrative consistency.
– Collaborate with Editor and Reviewer Agents to refine final video cuts based on aesthetic and semantic criteria.
💬 Research Conclusions:
– CutClaw significantly outperforms state-of-the-art methods in generating high-quality, rhythm-aligned short videos, demonstrating its effective use of technology in streamlining video editing processes.
👉 Paper link: https://huggingface.co/papers/2603.29664
6. MonitorBench: A Comprehensive Benchmark for Chain-of-Thought Monitorability in Large Language Models
🔑 Keywords: Large language models, Chains of thought, Monitorability, Decision-critical factors, Structural reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces MonitorBench, a comprehensive benchmark designed to evaluate the monitorability of chains of thought within large language models (LLMs).
🛠️ Research Methods:
– MonitorBench includes 1,514 test instances across 19 tasks and 7 categories, offering stress-test settings to assess the degradation of CoT monitorability under various conditions.
💬 Research Conclusions:
– Findings reveal that the monitorability of LLMs’ chains of thought improves with the need for structural reasoning, but generally decreases, particularly in closed-source models and under stress-test conditions.
– Both open- and closed-source LLMs can exhibit intentional reduction in monitorability, with decreases up to 30% in tasks lacking structural reasoning.
👉 Paper link: https://huggingface.co/papers/2603.28590

7. Think Anywhere in Code Generation
🔑 Keywords: Think-Anywhere, Large Language Models, Code Generation, Cold-start Training, Outcome-based RL Rewards
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to develop a novel reasoning mechanism, Think-Anywhere, that allows large language models to invoke thinking on-demand during code generation to improve performance across multiple benchmarks.
🛠️ Research Methods:
– Implemented through cold-start training to teach imitation of reasoning patterns, followed by utilizing outcome-based reinforcement learning rewards to enable autonomous exploration for reasoning invocation.
💬 Research Conclusions:
– Think-Anywhere achieves state-of-the-art performance in code generation benchmarks and adapts reasoning to high-entropy positions, providing enhanced interpretability and generalization across diverse language models.
👉 Paper link: https://huggingface.co/papers/2603.29957

8. BizGenEval: A Systematic Benchmark for Commercial Visual Content Generation
🔑 Keywords: BizGenEval, image generation models, commercial visual content, capability dimensions, evaluation tasks
💡 Category: Generative Models
🌟 Research Objective:
– Introduce BizGenEval, a new benchmark for systematically evaluating image generation models on commercial visual content creation tasks.
🛠️ Research Methods:
– Assess 26 popular image generation systems across five document types, focusing on four key capability dimensions, using 400 prompts and 8000 checklist questions.
💬 Research Conclusions:
– Current generative models show substantial capability gaps compared to the requirements of professional visual content creation, highlighting the need for a standardized benchmark like BizGenEval.
👉 Paper link: https://huggingface.co/papers/2603.25732

9. Falcon Perception
🔑 Keywords: Perception-centric systems, Falcon Perception, Transformer, Early-fusion, AI Systems
💡 Category: Computer Vision
🌟 Research Objective:
– Examine the necessity of architectural separation in perception-centric systems and explore a unified architecture approach with Falcon Perception, introducing a dense Transformer for improved task modeling.
🛠️ Research Methods:
– Implement a unified dense Transformer architecture that integrates image patches and text tokens in a shared parameter space, using a combination of bidirectional and causal attention patterns for task prediction.
💬 Research Conclusions:
– Falcon Perception demonstrates significant enhancement in mask quality and performance on benchmarks such as SA-Co and PBench, proving the viability of early-fusion architecture for efficient and accurate perception and task modeling.
👉 Paper link: https://huggingface.co/papers/2603.27365

10. The Model Says Walk: How Surface Heuristics Override Implicit Constraints in LLM Reasoning
🔑 Keywords: Large language models, Heuristic Override Benchmark, Causal-behavioral analysis, Sigmoid heuristics, Constraint inference
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate systematic reasoning failures in large language models when surface cues conflict with feasibility constraints, using a comprehensive framework to diagnose, measure, bridge, and treat these heuristic biases.
🛠️ Research Methods:
– Applied causal-behavioral analysis to the “car wash problem” across six models, revealing certain heuristic patterns.
– Conducted experiments using the Heuristic Override Benchmark to assess model performance across various heuristic and constraint families.
– Utilized parametric probes to verify the generalization of sigmoid heuristic patterns.
💬 Research Conclusions:
– Large language models demonstrate consistent heuristic biases that lead to reasoning failures, particularly in constraint inference rather than missing knowledge.
– A minimal hint can significantly improve model performance, indicating the nature of reasoning failures.
– Heuristic override is identified as a systematic reasoning vulnerability, and the research provides a benchmark for measuring and addressing these issues.
👉 Paper link: https://huggingface.co/papers/2603.29025

11. AutoWeather4D: Autonomous Driving Video Weather Conversion via G-Buffer Dual-Pass Editing
🔑 Keywords: AutoWeather4D, 3D-aware editing, G-buffer Dual-pass Editing, photorealism, autonomous driving
💡 Category: Computer Vision
🌟 Research Objective:
– To develop AutoWeather4D, a 3D-aware weather editing framework that decouples geometry and illumination for efficient weather modification in autonomous driving applications.
🛠️ Research Methods:
– Employed a G-buffer Dual-pass Editing mechanism consisting of a Geometry Pass for surface-anchored physical interactions and a Light Pass for dynamic 3D local relighting through analytical light transport.
💬 Research Conclusions:
– AutoWeather4D provides comparable photorealism and structural consistency to existing generative models while enabling fine-grained parametric physical control, making it a practical data engine for autonomous driving.
👉 Paper link: https://huggingface.co/papers/2603.26546

12. How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
🔑 Keywords: Large Language Models, Auditory Knowledge, Audio-Grounded Evaluation, Knowledge Representation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate the extent to which Large Language Models encode auditory knowledge through text-only pre-training and its impact on downstream performance.
🛠️ Research Methods:
– Comparison of LLMs under three settings: direct probing on the AKB-2000 benchmark, cascade evaluation using text from an audio captioner, and audio-grounded evaluation by fine-tuning LLMs with an audio encoder.
💬 Research Conclusions:
– Auditory knowledge encoded by LLMs varies significantly across models, and there is a strong correlation between text-only results and audio performance, providing empirical insights into LLMs’ role in audio research.
👉 Paper link: https://huggingface.co/papers/2603.19195

13. Distilling Human-Aligned Privacy Sensitivity Assessment from Large Language Models
🔑 Keywords: Large language models, Privacy evaluation, Encoder models, Human agreement, De-identification systems
💡 Category: Natural Language Processing
🌟 Research Objective:
– To provide an efficient privacy evaluation method for textual data using distilled encoder models from large language models, while maintaining strong human agreement and reducing computational costs.
🛠️ Research Methods:
– Distillation of the privacy assessment capabilities of Mistral Large 3 into lightweight encoder models with as few as 150M parameters.
– Training of efficient classifiers using a large-scale dataset of privacy-annotated texts across 10 diverse domains.
💬 Research Conclusions:
– The distilled encoder models preserved strong agreement with human annotations.
– These models showed practical utility for evaluating de-identification systems by significantly reducing computational requirements.
👉 Paper link: https://huggingface.co/papers/2603.29497

14. WorldFlow3D: Flowing Through 3D Distributions for Unbounded World Generation
🔑 Keywords: 3D World Generation, Flow Matching, Scene Attributes, Cross-Domain Generalizability, Scene Generation Fidelity
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the research is to develop WorldFlow3D, a novel method for generating unbounded 3D worlds, enhancing rapid convergence and high-quality generation with controllable geometric and texture properties.
🛠️ Research Methods:
– The method involves modeling 3D data distributions as a flow matching problem, using a latent-free flow approach that facilitates causal and accurate 3D structure generation.
💬 Research Conclusions:
– The study confirms the effectiveness of WorldFlow3D in generating high-quality scenes in various domains, demonstrating superior scene generation fidelity compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2603.29089

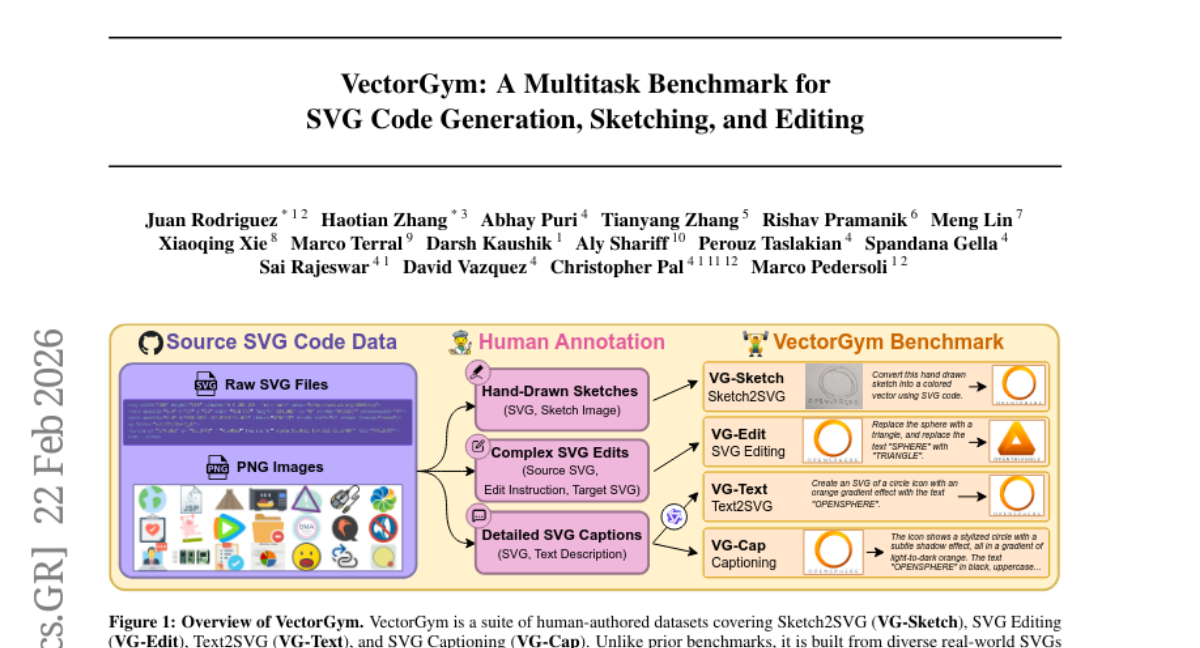
15. VectorGym: A Multitask Benchmark for SVG Code Generation, Sketching, and Editing
🔑 Keywords: Scalable Vector Graphics, Text-to-SVG Generation, Sketch-to-SVG Conversion, Multi-task Reinforcement Learning, Visual Code Generation
💡 Category: Generative Models
🌟 Research Objective:
– The research introduces VectorGym, a comprehensive benchmark suite for Scalable Vector Graphics (SVG) focusing on tasks like text-to-SVG generation, sketch-to-SVG conversion, complex SVG editing, and visual understanding.
🛠️ Research Methods:
– The benchmark uses a multi-task reinforcement learning approach with rendering-based rewards, incorporating human-annotated datasets and curriculum learning techniques.
💬 Research Conclusions:
– VectorGym demonstrates state-of-the-art performance using the Qwen3-VL 8B model, surpassing larger models, and includes a VLM-as-a-Judge metric for validating SVG generation with human correlation studies.
👉 Paper link: https://huggingface.co/papers/2603.29852
16. PoseDreamer: Scalable and Photorealistic Human Data Generation Pipeline with Diffusion Models
🔑 Keywords: PoseDreamer, diffusion models, synthetic datasets, 3D human mesh, image-quality
💡 Category: Generative Models
🌟 Research Objective:
– The main objective is to generate large-scale synthetic 3D human mesh datasets using diffusion models that improve upon traditional methods in terms of image quality and performance.
🛠️ Research Methods:
– The approach involves a novel pipeline combining diffusion models, controllable image generation, Direct Preference Optimization, curriculum-based hard sample mining, and multi-stage quality filtering.
💬 Research Conclusions:
– The resulting dataset includes over 500,000 high-quality synthetic samples with a 76% improvement in image quality metrics compared to rendering-based datasets. Models trained with PoseDreamer data match or surpass performance of those trained on real-world and traditional synthetic datasets.
👉 Paper link: https://huggingface.co/papers/2603.28763

17. OptiMer: Optimal Distribution Vector Merging Is Better than Data Mixing for Continual Pre-Training
🔑 Keywords: OptiMer, Continual pre-training, Bayesian optimization, Data mixture ratio, Post-hoc optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop OptiMer, a system that decouples data mixture ratio selection from training using post-hoc Bayesian optimization to enhance continual pre-training of LLMs across languages and domains.
🛠️ Research Methods:
– Trained individual continual pre-training (CPT) models per dataset, extracted distribution vectors that capture parameter shifts, and conducted post-hoc Bayesian optimization to find optimal composition weights.
💬 Research Conclusions:
– OptiMer outperforms traditional data mixture and model averaging baselines with significantly reduced search costs; optimized weights improve data mixture continual pre-training, and the vector pool can be re-optimized for varying objectives without retraining.
👉 Paper link: https://huggingface.co/papers/2603.28858
18. MMFace-DiT: A Dual-Stream Diffusion Transformer for High-Fidelity Multimodal Face Generation
🔑 Keywords: Multimodal face generation, text-to-image diffusion models, spatial priors, dual-stream transformer, visual fidelity
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces a unified dual-stream diffusion transformer to enhance multimodal face synthesis by integrating spatial and semantic information.
🛠️ Research Methods:
– Utilizes a dual-stream transformer block with Rotary Position-Embedded (RoPE) Attention to process spatial and semantic tokens in parallel, ensuring a balance between modalities.
– A novel Modality Embedder adapts to different spatial conditions dynamically.
💬 Research Conclusions:
– MMFace-DiT achieves a 40% improvement in visual fidelity and prompt alignment compared to other models, setting a new standard for controllable and cohesive multimodal generative modeling.
👉 Paper link: https://huggingface.co/papers/2603.29029

19. Learn2Fold: Structured Origami Generation with World Model Planning
🔑 Keywords: AI-generated summary, Learn2Fold, neuro-symbolic framework, language model, graph-structured world model
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To generate physically valid origami folding sequences from text using the Learn2Fold neuro-symbolic framework.
🛠️ Research Methods:
– Combines semantic proposals from a large language model with verification by a graph-structured world model, integrated in a lookahead planning loop.
💬 Research Conclusions:
– Learn2Fold effectively creates robust folding sequences for complex patterns by decoupling semantic proposal and physical verification.
👉 Paper link: https://huggingface.co/papers/2603.29585

20. FlowPIE: Test-Time Scientific Idea Evolution with Flow-Guided Literature Exploration
🔑 Keywords: FlowPIE, Scientific Idea Generation, AI-driven Research, Monte Carlo Tree Search, Cross-domain Knowledge
💡 Category: Generative Models
🌟 Research Objective:
– The objective of this research is to develop a novel framework, FlowPIE, that enhances scientific idea generation by integrating retrieval and generation processes to overcome limitations of existing static paradigms.
🛠️ Research Methods:
– FlowPIE employs a flow-guided Monte Carlo Tree Search alongside genetic algorithm principles, utilizing LLM-based generative reward models to iteratively evolve and enrich idea diversity and quality.
💬 Research Conclusions:
– The results indicate that FlowPIE outperforms existing large language models and agent-based systems by generating ideas with superior novelty, feasibility, and diversity, and effectively mitigates constraints such as information cocoons.
👉 Paper link: https://huggingface.co/papers/2603.29557

21. Extend3D: Town-Scale 3D Generation
🔑 Keywords: Extend3D, object-centric 3D generative model, under-noising, 3D-aware optimization
💡 Category: Generative Models
🌟 Research Objective:
– Extend an object-centric 3D generative model with adaptive latent space to generate complete 3D scenes from a single image.
🛠️ Research Methods:
– Utilizing overlapping patches in the extended latent space with a monocular depth estimator to initialize scenes, and iterative refinement to address noise through under-noising.
– Introducing 3D-aware optimization objectives to enhance geometric structure and texture fidelity.
💬 Research Conclusions:
– The proposed Extend3D pipeline achieves superior results in 3D scene generation compared to prior methods, supported by human preference and quantitative experiments.
👉 Paper link: https://huggingface.co/papers/2603.29387

22. daVinci-LLM:Towards the Science of Pretraining
🔑 Keywords: Pretraining, Adaptive Curriculum, Data Processing, Data Darwinism, Systematic Exploration
💡 Category: Foundations of AI
🌟 Research Objective:
– Explore pretraining methodology through open scientific approaches to enhance model capability development.
🛠️ Research Methods:
– Utilization of daVinci-LLM integrating industrial-scale resources with full research freedom.
– Application of a Data Darwinism framework with a L0-L9 taxonomy for systematic data processing.
💬 Research Conclusions:
– Data processing depth significantly enhances model capabilities, making it a critical dimension alongside volume scaling.
– Different domains have distinct saturation dynamics necessitating adaptive strategies.
– Compositional balance is crucial to prevent performance collapse and enable targeted capability enhancement.
– The complete exploration process contributes to the cumulative scientific knowledge in pretraining.
👉 Paper link: https://huggingface.co/papers/2603.27164

23. Unify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis
🔑 Keywords: Unify-Agent, multimodal understanding, image synthesis, agent-based modeling, FactIP
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance image synthesis through Unify-Agent, integrating agent-based modeling with multimodal understanding.
🛠️ Research Methods:
– The study utilizes an agentic pipeline for image generation, which includes processes like prompt understanding, multimodal evidence searching, grounded recaptioning, and synthesis, supported by a multimodal data pipeline and a collection of 143K high-quality agent trajectories.
💬 Research Conclusions:
– Unify-Agent significantly improves image generation capabilities in various benchmarks and tasks, approaching the efficacy of top closed-source models by effectively leveraging reasoning, searching, and generation processes grounded in external knowledge.
👉 Paper link: https://huggingface.co/papers/2603.29620

24. Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
🔑 Keywords: medical imaging, foundation models, metadata-driven fusion, datasets
💡 Category: AI in Healthcare
🌟 Research Objective:
– The paper aims to address the fragmentation and limited scale of medical imaging datasets by proposing a metadata-driven fusion paradigm to integrate scattered resources.
🛠️ Research Methods:
– Conducted the largest survey of medical image datasets, analyzing over 1,000 open-access datasets, and proposed a metadata-driven fusion paradigm to transform fragmented data into larger, more coherent resources.
💬 Research Conclusions:
– The study provides a comprehensive repository via an interactive discovery portal to facilitate dataset integration, supporting the development of robust medical foundation models and faster data discovery.
👉 Paper link: https://huggingface.co/papers/2603.27460

25. Lingshu-Cell: A generative cellular world model for transcriptome modeling toward virtual cells
🔑 Keywords: Lingshu-Cell, masked discrete diffusion model, single-cell transcriptomics, perturbation response, transcriptome-wide expression
💡 Category: Generative Models
🌟 Research Objective:
– To introduce Lingshu-Cell, a masked discrete diffusion model that learns transcriptomic state distributions and supports conditional simulation under perturbation.
🛠️ Research Methods:
– Utilization of a discrete token space compatible with single-cell transcriptomic data to capture complex expression dependencies across thousands of genes without prior gene filtering.
💬 Research Conclusions:
– Lingshu-Cell effectively reproduces transcriptomic distributions, marker-gene patterns, and cell-subtype proportions across diverse tissues and species, and excels in predicting transcriptome expression changes due to genetic perturbations and cytokine responses.
👉 Paper link: https://huggingface.co/papers/2603.25240

26. CARLA-Air: Fly Drones Inside a CARLA World — A Unified Infrastructure for Air-Ground Embodied Intelligence
🔑 Keywords: CARLA-Air, Unreal Engine, embodied intelligence, multi-modal sensing, co-simulation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introducing CARLA-Air, a platform that combines high-fidelity driving and multirotor flight simulation using the Unreal Engine framework for joint air-ground agent modeling.
🛠️ Research Methods:
– Developed an open-source infrastructure that integrates both CARLA and AirSim functionalities, maintaining native Python APIs and ROS 2 interfaces, enabling zero-modification code reuse.
💬 Research Conclusions:
– CARLA-Air supports rich simulations with photorealistic environments and synchronized multi-modal sensing, addressing the segmented nature of existing simulators and facilitating various embodied intelligence workloads.
👉 Paper link: https://huggingface.co/papers/2603.28032
