AI Native Daily Paper Digest – 20260408

1. Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
🔑 Keywords: Video Understanding, Robustness, Faithfulness, Video-MME-v2, Multimodal Reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective of the research is to introduce Video-MME-v2, a comprehensive benchmark to rigorously evaluate the robustness and faithfulness of video understanding models.
🛠️ Research Methods:
– The study employs a progressive tri-level hierarchy to increment the complexity of video comprehension, alongside a group-based non-linear evaluation strategy.
– Data quality is ensured through a controlled human annotation pipeline involving multiple rounds of quality assurance.
💬 Research Conclusions:
– Results show a significant performance gap between current models, like Gemini-3-Pro, and human experts, along with hierarchical bottlenecks in visual information aggregation and temporal modeling.
– It is revealed that thinking-based reasoning depends heavily on textual cues, influencing performance based on the presence or absence of subtitles.
👉 Paper link: https://huggingface.co/papers/2604.05015

2. Learning to Retrieve from Agent Trajectories
🔑 Keywords: agentic search, agent trajectories, retrieval models, relevance intensity, weighted optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the mismatch in retrieval models for agentic search by training them directly from agent interaction data using agent trajectories as a new paradigm for supervision.
🛠️ Research Methods:
– Introducing a framework called LRAT, which mines high-quality retrieval supervision from multi-step agent interactions, incorporating relevance intensity through weighted optimization.
💬 Research Conclusions:
– The LRAT framework consistently improves evidence recall, end-to-end task success, and execution efficiency across various agent architectures and scales, highlighting agent trajectories as a practical and scalable supervision source for retrieval models.
👉 Paper link: https://huggingface.co/papers/2604.04949

3. GBQA: A Game Benchmark for Evaluating LLMs as Quality Assurance Engineers
🔑 Keywords: Large Language Models, Bug Discovery, Game Development, Multi-agent Systems, Autonomous Software Engineering
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate the effectiveness of large language models (LLMs) in autonomously detecting software bugs within complex runtime environments using a newly introduced Game Benchmark for Quality Assurance (GBQA).
🛠️ Research Methods:
– Implementation of a benchmark comprising 30 games with 124 human-verified bugs, using a multi-agent system to generate and manage bugs; includes a baseline interactive agent with a ReAct loop and memory mechanism for comprehensive bug exploration.
💬 Research Conclusions:
– Autonomous bug discovery in dynamic environments remains challenging for current LLMs, with the best-performing model identifying only 48.39% of the verified bugs. GBQA serves as an effective testbed for future advancements in autonomous software engineering.
👉 Paper link: https://huggingface.co/papers/2604.02648

4. Beyond Accuracy: Unveiling Inefficiency Patterns in Tool-Integrated Reasoning
🔑 Keywords: PTE, Tool-Integrated Reasoning, KV-Cache, inference latency, Prefill Token Equivalents
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to introduce a new hardware-aware metric called Prefill Token Equivalents (PTE) to better measure efficiency in Tool-Integrated Reasoning scenarios by accounting for KV-Cache inefficiencies and long tool responses.
🛠️ Research Methods:
– This study evaluates PTE across five TIR benchmarks and validates its correlation with actual inference latency in a high-concurrency industrial setting.
💬 Research Conclusions:
– PTE aligns better with wall-clock latency than traditional token counts and maintains consistent efficiency rankings across various hardware profiles, highlighting inefficiency patterns in TIR and showing that higher PTE costs correlate with lower reasoning correctness. Simply using more tools does not enhance answer quality.
👉 Paper link: https://huggingface.co/papers/2604.05404

5. Watch Before You Answer: Learning from Visually Grounded Post-Training
🔑 Keywords: Vision-language models, VidGround, Video understanding, RL-based post-training algorithms, Visual grounding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address text-based biases in benchmarks and datasets to enhance vision-language model video understanding.
🛠️ Research Methods:
– Introduce VidGround, a technique using visually grounded questions for post-training.
– Utilize RL-based post-training algorithms in tandem with VidGround.
💬 Research Conclusions:
– VidGround improves performance by up to 6.2 points using 69.1% of original data.
– Data quality is crucial, with VidGround’s simple algorithm outperforming more complex techniques.
👉 Paper link: https://huggingface.co/papers/2604.05117

6. MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
🔑 Keywords: MegaTrain, Large Language Models, Host Memory, Full Precision, CPU-GPU Bandwidth Bottleneck
💡 Category: AI Systems and Tools
🌟 Research Objective:
– MegaTrain aims to enable efficient training of large language models with over 100 billion parameters on a single GPU, utilizing host memory storage and optimized data streaming techniques.
🛠️ Research Methods:
– MegaTrain stores parameters and optimizer states in host memory and uses GPUs as transient compute engines.
– Implements a pipelined double-buffered execution engine to handle CPU-GPU bandwidth issues by overlapping parameter prefetching, computation, and gradient offloading.
– Utilizes stateless layer templates to dynamically bind weights, which eliminates persistent graph metadata and enhances scheduling flexibility.
💬 Research Conclusions:
– On a single H200 GPU with 1.5TB host memory, MegaTrain can train models up to 120 billion parameters.
– The system achieves 1.84 times the training throughput of DeepSpeed ZeRO-3 when training 14 billion parameter models.
– It also allows for 7 billion parameter model training with 512k token context on a single GH200.
👉 Paper link: https://huggingface.co/papers/2604.05091

7. ClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
🔑 Keywords: ClawsBench, LLM agents, mock services, task success rate, unsafe action rate
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate and improve LLM agents in realistic productivity settings using ClawsBench, a benchmark involving high-fidelity mock services and structured tasks.
🛠️ Research Methods:
– The study involved using five mock services to simulate environments and decomposing agent scaffolding into domain skills and meta prompts to analyze their effects on task success and safety.
💬 Research Conclusions:
– Agents showed task success rates between 39% and 64% but also exhibited unsafe action rates from 7% to 33%. Eight unsafe behavior patterns were identified, highlighting areas for improvement.
👉 Paper link: https://huggingface.co/papers/2604.05172

8. General Multimodal Protein Design Enables DNA-Encoding of Chemistry
🔑 Keywords: DISCO, Multimodal Model, Deep Generative Model, Heme Enzymes, Directed Evolution
💡 Category: Generative Models
🌟 Research Objective:
– Introduce DISCO, a novel multimodal model that co-designs protein sequences and 3D structures to create new heme enzymes with unprecedented catalytic abilities.
🛠️ Research Methods:
– Use of inference-time scaling to optimize objectives across protein sequence and structure modalities, conditioned on reactive intermediates.
💬 Research Conclusions:
– DISCO successfully designs enzymes that conduct novel carbene-transfer reactions with higher activities compared to engineered enzymes, indicating potential for genetically encodable transformations.
👉 Paper link: https://huggingface.co/papers/2604.05181

9. Action Images: End-to-End Policy Learning via Multiview Video Generation
🔑 Keywords: World Action Models, Multiview Video Generation, Pixel-Grounded, Zero-Shot Policy, Interpretable Action Images
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to enhance robot policy learning by developing a unified world action model that integrates policy learning with multiview video generation using pixel-grounded action images.
🛠️ Research Methods:
– The study translates 7-DoF robot actions into interpretable action images, allowing the video backbone to function as a zero-shot policy without separate action modules or policy heads.
💬 Research Conclusions:
– The proposed approach achieves superior zero-shot success rates and enhances the quality of video-action joint generation in both simulated bench settings (RLBench) and real-world evaluations, indicating that interpretable action images offer a promising path for policy learning.
👉 Paper link: https://huggingface.co/papers/2604.06168

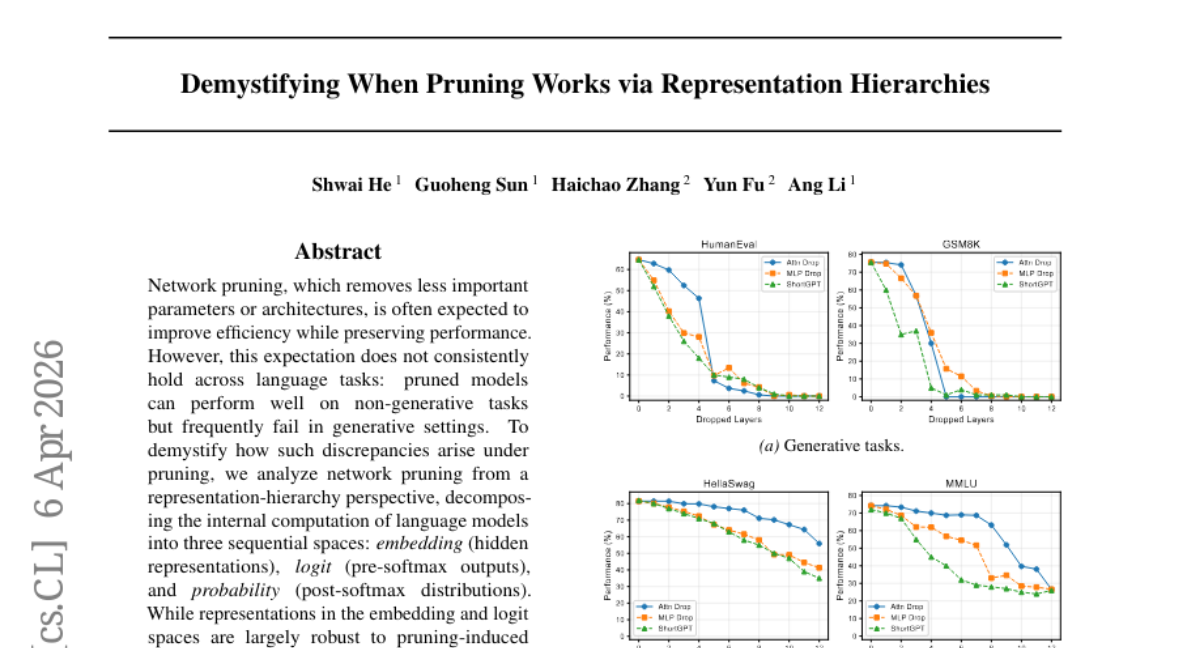
10. Demystifying When Pruning Works via Representation Hierarchies
🔑 Keywords: Network pruning, Representation-hierarchy, Generative settings, Non-generative tasks, Pruning-induced perturbations
💡 Category: Natural Language Processing
🌟 Research Objective:
– To dissect the impact of network pruning on different tasks by analyzing its effects on sequential representation spaces in language models.
🛠️ Research Methods:
– The study decomposes language model computations into embedding, logit, and probability spaces, examining the robustness of each space against pruning-induced perturbations.
💬 Research Conclusions:
– The study finds that while embedding and logit spaces maintain robustness, the transformation from logits to probabilities is sensitive to perturbations, leading to reduced performance in generative tasks. Nonetheless, pruning proves effective in non-generative tasks like retrieval and multiple-choice selection due to stability in the categorical-token probability subspace.
👉 Paper link: https://huggingface.co/papers/2603.24652
11. Experience Transfer for Multimodal LLM Agents in Minecraft Game
🔑 Keywords: Echo, transfer-oriented memory framework, Multimodal LLM agents, In-Context Analogy Learning, experience transfer
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance the efficiency of Multimodal LLM agents in complex game environments by utilizing Echo, a framework that leverages prior interactions to solve new tasks effectively.
🛠️ Research Methods:
– Echo decomposes reusable knowledge into five dimensions and applies In-Context Analogy Learning to adapt experiences to new tasks, tested through experiments in Minecraft.
💬 Research Conclusions:
– Echo demonstrates a significant speed-up in object-unlocking tasks, showcasing its potential to increase the efficiency and adaptability of agents through experience transfer.
👉 Paper link: https://huggingface.co/papers/2604.05533

12. QiMeng-PRepair: Precise Code Repair via Edit-Aware Reward Optimization
🔑 Keywords: PRepair, Large Language Models, over-editing, Self-Breaking, Self-Repairing
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To reduce over-editing in program repair by using PRepair framework which combines controlled bug injection and edit-aware policy optimization.
🛠️ Research Methods:
– Introduces PRepair framework with two components: Self-Breaking for generating diverse buggy programs and Self-Repairing using Edit-Aware Group Relative Policy Optimization (EA-GRPO) to train models for minimal yet correct edits.
💬 Research Conclusions:
– PRepair improves repair precision by up to 31.4% and significantly increases decoding throughput, showing potential for precise and practical code repair.
👉 Paper link: https://huggingface.co/papers/2604.05963

13. Squeez: Task-Conditioned Tool-Output Pruning for Coding Agents
🔑 Keywords: task-conditioned tool-output pruning, AI-generated summary, SWE-bench repository, fine-tune, LoRA
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to develop a task-conditioned tool-output pruning model that increases efficiency by reducing input token consumption while maintaining high recall and F1 scores.
🛠️ Research Methods:
– The researchers introduced a benchmark consisting of 11,477 examples, including interactions from the SWE-bench repository and synthetic multi-ecosystem tool outputs. They fine-tuned the Qwen 3.5 2B model using LoRA and compared it against larger zero-shot models and heuristic pruning baselines.
💬 Research Conclusions:
– The task-conditioned tool-output pruning model significantly reduced input token consumption by 92%, achieving 0.86 recall and 0.80 F1, outperforming larger models and baselines by a wide margin.
👉 Paper link: https://huggingface.co/papers/2604.04979
14. CUE-R: Beyond the Final Answer in Retrieval-Augmented Generation
🔑 Keywords: Retrieval-Augmented Generation, Intervention-Based Framework, Operational Utility, Evidence Role Taxonomy
💡 Category: Natural Language Processing
🌟 Research Objective:
– To measure the operational utility of individual retrieved items in Retrieval-Augmented Generation (RAG) systems by analyzing changes in correctness, grounding faithfulness, and confidence error through an intervention-based approach.
🛠️ Research Methods:
– Introduction of CUE-R, a lightweight intervention-based framework utilizing operators like REMOVE, REPLACE, and DUPLICATE to perturb evidence and measure utility across three axes, alongside a trace-divergence signal.
💬 Research Conclusions:
– The experiments demonstrate that REMOVE and REPLACE operators significantly harm correctness and grounding, indicating the importance of evidence effects, while DUPLICATE is often redundant yet not neutral. The study emphasizes that intervention-based utility analysis offers valuable insights beyond traditional answer-only evaluation.
👉 Paper link: https://huggingface.co/papers/2604.05467

15. Can Natural Image Autoencoders Compactly Tokenize fMRI Volumes for Long-Range Dynamics Modeling?
🔑 Keywords: fMRI, autoencoder, Transformer encoder, spatiotemporal modeling, continuous tokens
💡 Category: AI in Healthcare
🌟 Research Objective:
– The primary aim is to address the limitations in modeling long-range spatiotemporal dynamics in functional Magnetic Resonance Imaging (fMRI) due to high dimensionality.
🛠️ Research Methods:
– Developed TABLeT, a novel approach using a 2D autoencoder to tokenize fMRI volumes into compact continuous tokens.
– Utilized a simple Transformer encoder to efficiently model long-sequence spatiotemporal dynamics with limited VRAM.
💬 Research Conclusions:
– TABLeT outperforms existing models on benchmarks like UK-Biobank, HCP, and ADHD-200 datasets.
– Demonstrates improved computational and memory efficiency over voxel-based methods.
– Self-supervised masked token modeling enhances downstream task performance, offering a scalable and interpretable approach for brain activity modeling.
👉 Paper link: https://huggingface.co/papers/2604.03619

16.

17. Expert-Choice Routing Enables Adaptive Computation in Diffusion Language Models
🔑 Keywords: Diffusion Language Models, Expert-choice Routing, Load Balancing, Denoising Step
💡 Category: Generative Models
🌟 Research Objective:
– To improve the efficiency and effectiveness of Diffusion Language Models (DLMs) using Expert-choice (EC) routing for better load balancing and adaptive computation allocation.
🛠️ Research Methods:
– Implementing expert-choice routing in DLM mixture-of-experts models to provide deterministic load balancing.
– Introducing timestep-dependent expert capacity to optimize expert allocation according to the denoising step.
💬 Research Conclusions:
– EC routing offers higher throughput and faster convergence than the traditional token-choice routing in DLMs.
– Allocating extra capacity to low-mask-ratio steps significantly enhances performance and learning efficiency.
– Pretrained token-choice DLMs can be adapted to EC routing for improved convergence and accuracy across various tasks.
👉 Paper link: https://huggingface.co/papers/2604.01622

18. REAM: Merging Improves Pruning of Experts in LLMs
🔑 Keywords: Mixture-of-Experts, large language models, memory optimization, AI Native, Router-weighted Expert Activation Merging
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main goal is to reduce memory requirements in Mixture-of-Experts large language models by introducing a novel method, Router-weighted Expert Activation Merging (REAM), which preserves model performance while enhancing efficiency.
🛠️ Research Methods:
– REAM works by grouping and merging expert weights instead of pruning them. The method is benchmarked against existing techniques such as REAP across multiple-choice and generative tasks in large language models.
💬 Research Conclusions:
– The study reveals that REAM can often outperform traditional memory reduction methods and approaches the performance of uncompressed models by effectively managing the mix of calibration data to examine the trade-off between different task performances.
👉 Paper link: https://huggingface.co/papers/2604.04356

19. Scientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning
🔑 Keywords: Graphics Program Synthesis, TikZ, Multimodal Large Language Models, Dual Self-Consistency Reinforcement Learning, Round-Trip Verification
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to improve graphics program synthesis by addressing data quality and evaluation gaps in generating executable TikZ code from images.
🛠️ Research Methods:
– Introduces a closed-loop framework with a large-scale dataset (SciTikZ-230K) and benchmark (SciTikZ-Bench) along with a novel reinforcement learning method, Dual Self-Consistency Reinforcement Learning, to optimize code generation.
💬 Research Conclusions:
– The proposed system, SciTikZer-8B, achieves state-of-the-art performance in graphics program synthesis, outperforming existing models such as Gemini-2.5-Pro and Qwen3-VL-235B-A22B-Instruct.
👉 Paper link: https://huggingface.co/papers/2604.06079

20. Context-Value-Action Architecture for Value-Driven Large Language Model Agents
🔑 Keywords: Large Language Models, behavioral rigidity, Context-Value-Action architecture, Value Verifier, prompt-driven reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the issue of behavioral rigidity in Large Language Models by developing a Context-Value-Action architecture that decouples action generation from cognitive reasoning using a Value Verifier.
🛠️ Research Methods:
– Implemented a Context-Value-Action architecture based on the Stimulus-Organism-Response model and Schwartz’s Theory of Basic Human Values.
– Trained a novel Value Verifier on authentic human data to model dynamic value activation.
💬 Research Conclusions:
– The proposed CVA architecture significantly outperforms existing models, effectively mitigating value polarization and improving both behavioral fidelity and interpretability in language models.
👉 Paper link: https://huggingface.co/papers/2604.05939

21. FactReview: Evidence-Grounded Reviews with Literature Positioning and Execution-Based Claim Verification
🔑 Keywords: FactReview, evidence-grounded reviewing, claim extraction, execution-based claim verification, AI in peer review
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop FactReview, a system aimed at improving the reliability of peer review assessments in machine learning by utilizing evidence-grounded methods.
🛠️ Research Methods:
– FactReview employs claim extraction, literature positioning, and execution-based claim verification to analyze and verify manuscript claims, enhancing the peer review process.
💬 Research Conclusions:
– FactReview assigns labels to claims, indicating their level of support, and demonstrated its efficacy in a case study by reproducing results and critically assessing broader performance claims, highlighting AI’s role as a supporting tool rather than a decision-maker in peer review.
👉 Paper link: https://huggingface.co/papers/2604.04074

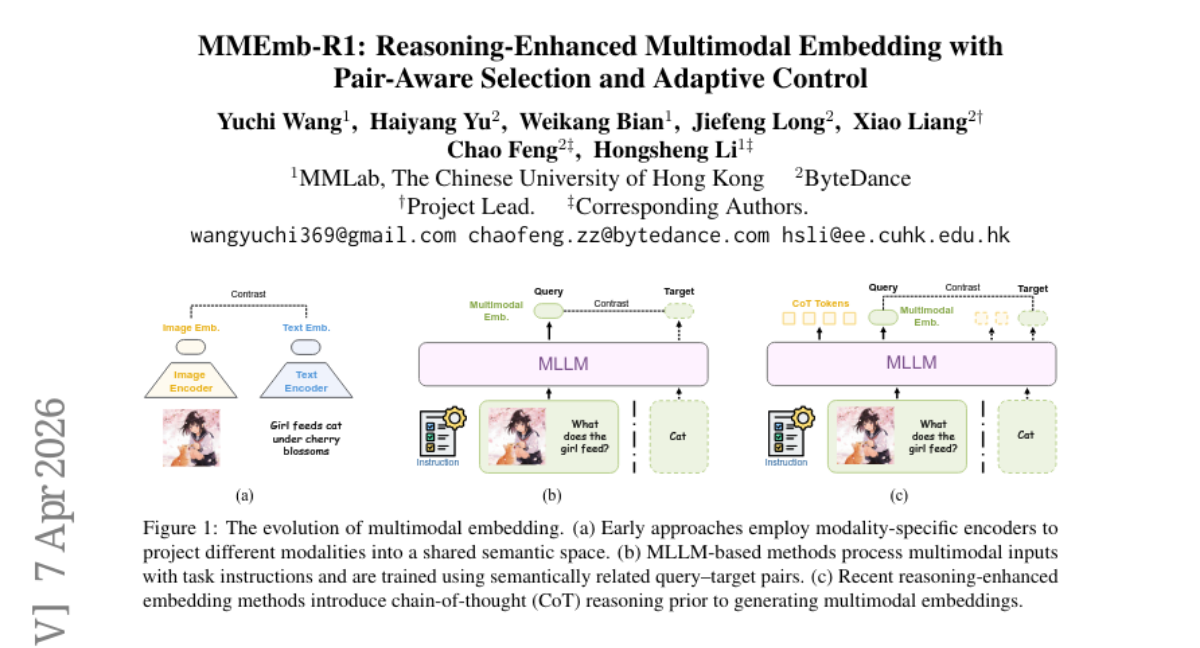
22. MMEmb-R1: Reasoning-Enhanced Multimodal Embedding with Pair-Aware Selection and Adaptive Control
🔑 Keywords: multimodal embedding, adaptive reasoning, latent variable, reinforcement learning, MMEB-V2 benchmark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop an adaptive multimodal embedding framework, MMEmb-R1, that selectively applies reasoning to improve efficiency and performance in benchmark tasks.
🛠️ Research Methods:
– Utilizes latent variables and pair-aware reasoning selection with counterfactual intervention to identify beneficial reasoning paths.
– Employs reinforcement learning to selectively invoke reasoning, minimizing unnecessary computation and latency.
💬 Research Conclusions:
– Achieved a state-of-the-art score of 71.2 on the MMEB-V2 benchmark with significantly reduced reasoning overhead and inference latency.
👉 Paper link: https://huggingface.co/papers/2604.06156
23. MedGemma 1.5 Technical Report
🔑 Keywords: MedGemma 1.5 4B, medical imaging, document understanding, clinical reasoning, AI in Healthcare
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to enhance medical AI capabilities by integrating expanded multimodal support and improving performance in medical imaging, document understanding, and clinical reasoning.
🛠️ Research Methods:
– Integration of high-dimensional medical imaging, such as CT/MRI volumes and histopathology images, through new training data and innovations like long-context 3D volume slicing.
– Utilization of anatomical localization and advancements in multi-timepoint chest X-ray analysis to support the improvement in medical document understanding.
💬 Research Conclusions:
– MedGemma 1.5 4B shows significant performance improvements compared to its predecessor; for instance, it improves 3D MRI and CT condition classification accuracy and boosts macro F1 gains in pathology imaging.
– Additionally, it exhibits enhanced clinical knowledge and reasoning capabilities, with marked improvements in MedQA and EHRQA accuracies.
👉 Paper link: https://huggingface.co/papers/2604.05081

24. In-Place Test-Time Training
🔑 Keywords: In-Place Test-Time Training, Large Language Models, Fast Weights, Next-Token-Prediction, Autoregressive Language Modeling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces In-Place Test-Time Training, which allows Large Language Models to adapt parameters during inference without the need for costly retraining.
🛠️ Research Methods:
– The approach modifies the final projection matrix in MLP blocks, employing a tailored objective aligned with Next-Token-Prediction for autoregressive language modeling.
💬 Research Conclusions:
– This framework enhances models by enabling them to achieve superior performance on tasks with extensive contexts and consistently outperforms existing Test-Time Training approaches.
👉 Paper link: https://huggingface.co/papers/2604.06169

25. DARE: Diffusion Large Language Models Alignment and Reinforcement Executor
🔑 Keywords: Diffusion large language models, iterative denoising, parallel generation, reinforcement learning, post-training
💡 Category: Generative Models
🌟 Research Objective:
– The paper focuses on establishing a unified framework for post-training and evaluating diffusion large language models (dLLMs) to address the fragmentation in the open-source ecosystem.
🛠️ Research Methods:
– It introduces DARE, which is built on shared execution stacks and integrates supervised fine-tuning, parameter-efficient fine-tuning, preference optimization, and dLLM-specific reinforcement learning.
💬 Research Conclusions:
– DARE provides broad algorithmic coverage, supports reproducible benchmark evaluations, and accelerates the development and deployment of post-training methods for dLLMs, making it a reusable substrate for current and emerging research.
👉 Paper link: https://huggingface.co/papers/2604.04215

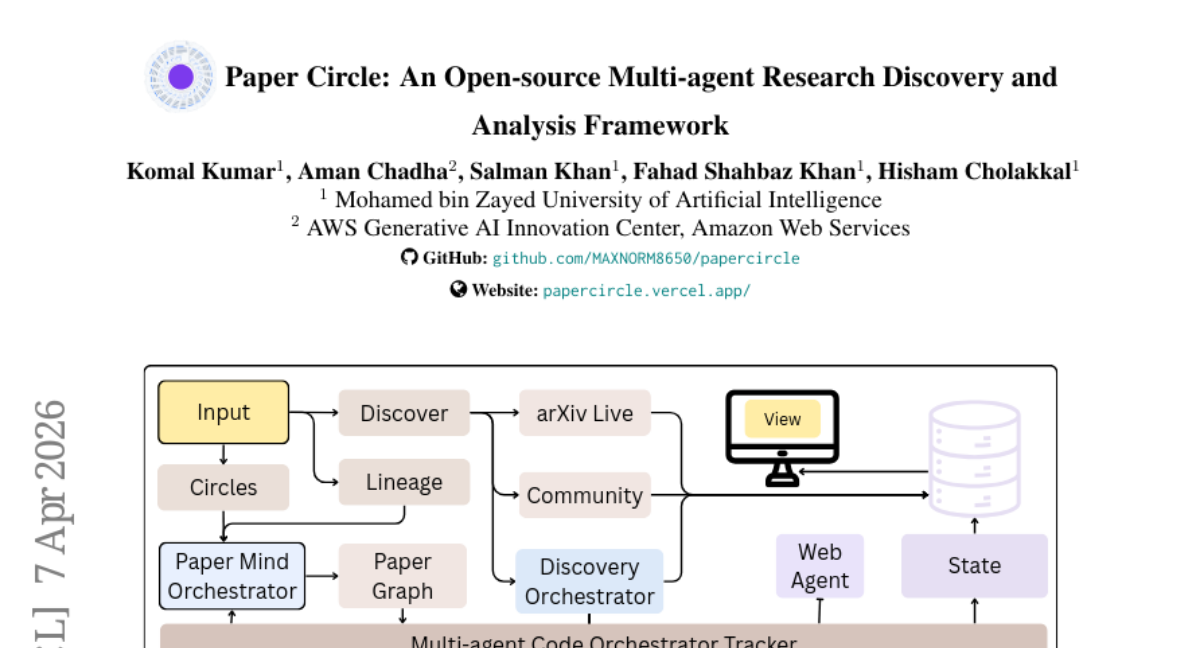
26. Paper Circle: An Open-source Multi-agent Research Discovery and Analysis Framework
🔑 Keywords: Multi-agent system, Knowledge graph, Research discovery, Agent roles, Paper Circle
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to reduce the effort required for researchers to find, assess, organize, and understand academic literature through the development of the Paper Circle system.
🛠️ Research Methods:
– Utilizes a multi-agent orchestration framework with two pipelines: a Discovery Pipeline for integrating retrieval processes and an Analysis Pipeline for transforming papers into structured knowledge graphs.
💬 Research Conclusions:
– The Paper Circle system demonstrates consistent improvements in paper retrieval and review generation, validated by benchmarks on hit rate, MRR, and Recall at K, with stronger results from advanced agent models.
👉 Paper link: https://huggingface.co/papers/2604.06170
27. How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
🔑 Keywords: Skill utilization, LLM-based agents, skill refinement, Terminal-Bench 2.0, pass rate
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the utility of skills in LLM-based agents under more realistic and progressively challenging conditions, highlighting the discrepancy between idealized conditions and real-world settings.
🛠️ Research Methods:
– Conducted a comprehensive study using a large collection of 34k real-world skills.
– Analyzed the effectiveness of query-specific and query-agnostic skill refinement strategies to improve skill utilization.
💬 Research Conclusions:
– Found that performance gains from skills diminish significantly under realistic settings, approaching no-skill baselines in challenging scenarios.
– Showed that query-specific skill refinement effectively recovers lost performance, demonstrated by improved pass rates on Terminal-Bench 2.0.
– Results indicate both the potential and current limitations of skill usage in LLM-based agents.
👉 Paper link: https://huggingface.co/papers/2604.04323

28. Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision
🔑 Keywords: AI-generated summary, triplet supervision, Dual Module architecture, video diffusion transformers, identity preservation
💡 Category: Computer Vision
🌟 Research Objective:
– To develop Vanast, a unified framework for generating garment-transferred human animation videos by combining image-based virtual try-on and pose-driven animation.
🛠️ Research Methods:
– Utilize large-scale triplet supervision to counteract issues like identity drift and garment distortion. Introduce Dual Module architecture for video diffusion transformers to stabilize training and enhance generative quality.
💬 Research Conclusions:
– Vanast effectively produces high-fidelity, identity-consistent animations across diverse garment types while maintaining garment accuracy and pose adherence.
👉 Paper link: https://huggingface.co/papers/2604.04934
29. ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
🔑 Keywords: ThinkTwice, Group Relative Policy Optimization, reasoning problems, self-refinement, policy optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce ThinkTwice, a two-phase framework that optimizes large language models for reasoning and self-refinement using Group Relative Policy Optimization.
🛠️ Research Methods:
– Utilizes Group Relative Policy Optimization in a two-phase training approach applying a binary correctness reward over mathematical reasoning benchmarks including models Qwen3-4B and Olmo3-7B.
💬 Research Conclusions:
– Demonstrates substantial improvement in reasoning and refinement performance over existing online policy optimization baselines, showing significant percentage point gains in benchmarks such as AIME.
– Highlights a rectify-then-fortify curriculum which initially focuses on correcting errors and later shifts to preserving correct solutions, leading to enhanced training dynamics.
👉 Paper link: https://huggingface.co/papers/2604.01591

30. ACES: Who Tests the Tests? Leave-One-Out AUC Consistency for Code Generation
🔑 Keywords: LLM-generated code, test correctness, circular dependency, leave-one-out evaluation, AUC ConsistEncy Scoring
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop ACES, a method to rank tests based on their ability to distinguish correct from incorrect code generated by large language models (LLMs).
🛠️ Research Methods:
– Implements leave-one-out evaluation and AUC consistency scoring to break the circular dependency in code candidate selection without determining test correctness directly.
💬 Research Conclusions:
– ACES, with its variants ACES-C and ACES-O, effectively ranks tests using a binary pass matrix, achieving state-of-the-art results on multiple code generation benchmarks without substantial overhead.
👉 Paper link: https://huggingface.co/papers/2604.03922

31. Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
🔑 Keywords: trajectory-aware grading, safety assessments, multimodal perception, autonomous agents, multi-step workflows
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective of Claw-Eval is to address limitations in existing agent benchmarks by implementing a comprehensive evaluation across multiple modalities, focusing on trajectory-aware grading and safety assessments.
🛠️ Research Methods:
– Claw-Eval consists of 300 human-verified tasks in 9 categories, recording agent actions through execution traces, audit logs, and environment snapshots. It uses trajectory-aware grading with 2,159 rubric items and a scoring protocol evaluating Completion, Safety, and Robustness.
💬 Research Conclusions:
– Experiments reveal that trajectory-opaque evaluations miss a significant portion of safety violations and robustness failures. Error injection impacts consistency more than capability, and there is considerable variance in multimodal performance, with agents performing worse on video data compared to documents or images.
👉 Paper link: https://huggingface.co/papers/2604.06132
