AI Native Daily Paper Digest – 20260413
1. WildDet3D: Scaling Promptable 3D Detection in the Wild
🔑 Keywords: 3D object detection, open-world detection, geometry-aware architecture, large-scale dataset, monocular 3D object detection
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a unified framework for 3D object detection that supports multiple prompt types and integrates geometric cues to enable open-world detection.
🛠️ Research Methods:
– Introduce WildDet3D, a geometry-aware architecture accepting text, point, and box prompts and utilizing auxiliary depth signals.
– Create WildDet3D-Data, the largest open 3D detection dataset using human-verified 3D boxes from 2D annotations, covering 13.5K categories.
💬 Research Conclusions:
– WildDet3D achieves state-of-the-art performance across various benchmarks and settings, significantly improving with integrated depth cues during inference.
👉 Paper link: https://huggingface.co/papers/2604.08626
2. RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details
🔑 Keywords: RefineAnything, region-specific image refinement, multimodal diffusion-based refinement model, Focus-and-Refine, Boundary Consistency Loss
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce region-specific image refinement, focusing on enhancing local details while preserving non-edited pixels in images.
🛠️ Research Methods:
– Implement a multimodal diffusion-based model named RefineAnything, utilizing a focus-and-refine strategy and a boundary-aware loss function to improve refinement precision and background preservation.
💬 Research Conclusions:
– RefineAnything delivers strong improvements in local detail accuracy and background consistency, demonstrated by achieving substantial performance gains over competitive baselines in the RefineEval benchmark.
👉 Paper link: https://huggingface.co/papers/2604.06870

3. EXAONE 4.5 Technical Report
🔑 Keywords: EXAONE 4.5, vision language model, native multimodal pretraining, document understanding, context length
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce EXAONE 4.5, an enhanced open-weight vision language model that improves document understanding and general language capabilities through advanced data curation and context extension.
🛠️ Research Methods:
– Integration of a visual encoder into the EXAONE 4.0 framework to enable native multimodal pretraining over visual and textual modalities. Training on large-scale, document-centric corpora for targeted performance gains.
💬 Research Conclusions:
– EXAONE 4.5 demonstrates competitive performance in general benchmarks and surpasses state-of-the-art models in document understanding and Korean contextual reasoning, with extendable capabilities for industrial deployment and diverse application scenarios.
👉 Paper link: https://huggingface.co/papers/2604.08644

4. Backdoor Attacks on Decentralised Post-Training
🔑 Keywords: backdoor attack, pipeline parallelism, decentralized post-training, model misalignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to explore the vulnerability of pipeline parallelism in decentralized post-training of large language models and how an intermediate-stage backdoor attack can cause significant model misalignment.
🛠️ Research Methods:
– The study focuses on an adversary controlling an intermediate stage of the training pipeline to perform a backdoor attack, testing the attack’s effect on model alignment under different conditions.
💬 Research Conclusions:
– The attack significantly reduces alignment even with minimal adversary control, from 80% to 6% with a trigger word, and remains effective in 60% of cases even after applying safety alignment training.
👉 Paper link: https://huggingface.co/papers/2604.02372

5. ECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion
🔑 Keywords: ECHO, Chest X-ray Report Generation, AI-Generated Summary, Direct Conditional Distillation, Response-Asymmetric Diffusion
💡 Category: AI in Healthcare
🌟 Research Objective:
– Develop a diffusion-based vision-language model, ECHO, to efficiently generate chest X-ray reports with high clinical accuracy and reduced inference latency.
🛠️ Research Methods:
– Introduce Direct Conditional Distillation (DCD) framework to address mean-field bias, enabling one-step-per-block inference.
– Implement Response-Asymmetric Diffusion (RAD) to optimize training efficiency without losing effectiveness.
💬 Research Conclusions:
– ECHO surpasses state-of-the-art autoregressive models, improving RaTE and SemScore significantly with an 8x speed increase in inference, while maintaining clinical accuracy.
👉 Paper link: https://huggingface.co/papers/2604.09450

6. AgentSwing: Adaptive Parallel Context Management Routing for Long-Horizon Web Agents
🔑 Keywords: AgentSwing, Context Management, Long-Horizon Information-Seeking, Probabilistic Framework, Parallel Context Management
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces AgentSwing, a state-aware adaptive framework designed to enhance long-horizon information-seeking by effectively managing context through dynamic strategies.
🛠️ Research Methods:
– The research employs a probabilistic framework that defines success in long-horizon scenarios through dimensions of search efficiency and terminal precision, utilizing parallel context management and lookahead routing.
💬 Research Conclusions:
– AgentSwing demonstrates superior performance compared to static context management methods, achieving significant improvements in long-horizon scenarios with fewer interaction turns while enhancing the ultimate performance capabilities of web agents. Additionally, the probabilistic framework offers valuable insights for future strategy designs in context management.
👉 Paper link: https://huggingface.co/papers/2603.27490

7. ScheMatiQ: From Research Question to Structured Data through Interactive Schema Discovery
🔑 Keywords: AI-generated summary, annotation schema, LLM, domain experts, open source
💡 Category: Natural Language Processing
🌟 Research Objective:
– ScheMatiQ aims to generate annotation schemas and structured databases from document collections using large language model (LLM) calls to facilitate domain-specific analysis in fields like law and computational biology.
🛠️ Research Methods:
– It leverages a backbone LLM to process questions and document corpora, producing schemas and grounded databases, and offers an interactive web interface for real-time extraction steering and revisions.
💬 Research Conclusions:
– ScheMatiQ proves effective in supporting real-world analysis in collaboration with domain experts and is available as an open-source tool with a public web interface for experimentation by experts across various disciplines.
👉 Paper link: https://huggingface.co/papers/2604.09237

8. Envisioning the Future, One Step at a Time
🔑 Keywords: Autoregressive diffusion model, sparse point trajectories, open-set future scene dynamics, motion prediction, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to predict open-set future scene dynamics by modeling sparse point trajectories, enabling scalable multi-modal motion prediction with physical plausibility.
🛠️ Research Methods:
– Utilizes an autoregressive diffusion model to advance trajectories through short, predictable transitions while modeling uncertainty, allowing for fast rollout of diverse futures from a single image.
💬 Research Conclusions:
– The method achieves predictive accuracy comparable to dense simulators but with orders-of-magnitude faster sampling speeds, making future prediction both scalable and practical.
👉 Paper link: https://huggingface.co/papers/2604.09527
9. Process Reward Agents for Steering Knowledge-Intensive Reasoning
🔑 Keywords: Process Reward Agents, Knowledge-Intensive, Frozen Policy, Search-Based Decoding, Medical Reasoning Benchmarks
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Process Reward Agents (PRA) to improve search-based decoding in knowledge-intensive reasoning by providing domain-grounded, step-wise rewards for frozen policies.
🛠️ Research Methods:
– Utilization of PRA to rank and prune candidate trajectories during each step of generation, validated through experiments on multiple medical reasoning benchmarks.
💬 Research Conclusions:
– PRA outperforms strong baselines, significantly improving accuracy on the MedQA benchmark and demonstrating the ability to generalize across model sizes without retraining the frozen policy.
👉 Paper link: https://huggingface.co/papers/2604.09482

10. CT-1: Vision-Language-Camera Models Transfer Spatial Reasoning Knowledge to Camera-Controllable Video Generation
🔑 Keywords: Vision-Language-Camera, Diffusion Transformer model, camera control accuracy, Wavelet-based Regularization Loss
💡 Category: Generative Models
🌟 Research Objective:
– To develop CT-1, a model for generating videos with precise and flexible camera movements by learning camera trajectories.
🛠️ Research Methods:
– Utilization of Diffusion Transformers and Wavelet-based Regularization Loss to learn complex camera trajectory distributions.
– Construction of CT-200K, a large-scale dataset with over 47 million frames to train the model.
💬 Research Conclusions:
– CT-1 effectively bridges the gap between spatial reasoning and video synthesis, achieving a 25.7% improvement in camera control accuracy compared to previous methods.
👉 Paper link: https://huggingface.co/papers/2604.09201

11. On Semiotic-Grounded Interpretive Evaluation of Generative Art
🔑 Keywords: Generative Art, Peircean Semiotics, Human-GenArt Interaction, Hierarchical Semiosis Graph, SemJudge
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop a framework to evaluate Generative Art through Peircean semiotics, focusing on symbolic and indexical meanings to improve alignment with human artistic interpretation.
🛠️ Research Methods:
– A Peircean computational semiotic theory is formalized, modeling Human-GenArt Interaction as cascaded semiosis. The proposed evaluator, SemJudge, utilizes a Hierarchical Semiosis Graph to assess HGI comprehensively.
💬 Research Conclusions:
– SemJudge provides deeper and more insightful interpretations of AI-generated art compared to existing evaluators by effectively assessing symbolic and indexical meanings and aligning more closely with human judgments.
👉 Paper link: https://huggingface.co/papers/2604.08641

12. AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation
🔑 Keywords: AVGen-Bench, Text-to-Audio-Video, Multi-granular Evaluation, Multimodal Large Language Models, Semantic Controllability
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address the need for an integrated benchmark for Text-to-Audio-Video generation, highlighting the gap between aesthetic quality and semantic accuracy.
🛠️ Research Methods:
– Introduce AVGen-Bench with high-quality prompts across 11 real-world categories for T2AV generation.
– Employ a multi-granular evaluation framework using lightweight specialist models and Multimodal Large Language Models (MLLMs) to assess perceptual quality and semantic controllability.
💬 Research Conclusions:
– Identified a significant disparity between strong audio-visual aesthetics and weak semantic reliability, including issues in text rendering, speech coherence, physical reasoning, and musical pitch control.
– Made code and benchmark resources accessible at the provided URL for further exploration and assessment.
👉 Paper link: https://huggingface.co/papers/2604.08540

13. Semantic Richness or Geometric Reasoning? The Fragility of VLM’s Visual Invariance
🔑 Keywords: Vision-Language Models, geometric transformations, spatial invariance, semantic understanding, multimodal systems
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study investigates the vulnerabilities of state-of-the-art Vision-Language Models under geometric transformations, focusing on their lack of robust spatial invariance and equivariance.
🛠️ Research Methods:
– Systematic evaluation across various visual domains, including symbolic sketches, natural photographs, and abstract art, to assess the performance of VLMs in different scenarios.
💬 Research Conclusions:
– The findings reveal a systematic gap between semantic understanding and spatial reasoning in current VLMs, suggesting the necessity for enhanced geometric grounding in future multimodal systems.
👉 Paper link: https://huggingface.co/papers/2604.01848

14. Cactus: Accelerating Auto-Regressive Decoding with Constrained Acceptance Speculative Sampling
🔑 Keywords: Speculative sampling, constrained optimization, large language models, Cactus, acceptance rates
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enhance speculative sampling methods as constrained optimization problems to control distribution divergence while maintaining high acceptance rates and output quality.
🛠️ Research Methods:
– The research introduces Cactus, a constrained acceptance speculative sampling approach ensuring controlled divergence from the verifier distribution and increasing acceptance rates.
💬 Research Conclusions:
– The empirical results show the effectiveness of the Cactus method across various benchmarks, confirming its capability to maintain output quality with improved acceptance rates.
👉 Paper link: https://huggingface.co/papers/2604.04987

15. Robust Reasoning Benchmark
🔑 Keywords: Large Language Models, reasoning processes, perturbation pipeline, dense attention mechanisms, contextual resets
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To evaluate the robustness of reasoning in Large Language Models when faced with perturbations, using a newly proposed perturbation pipeline.
🛠️ Research Methods:
– Utilized a set of 14 perturbation techniques on the AIME 2024 dataset to test 8 state-of-the-art models, with a focus on distinguishing mechanical parsing errors from reasoning failures.
💬 Research Conclusions:
– Open-weight models display significant accuracy degradation due to structural fragility in reasoning, with intermediate steps polluting dense attention mechanisms. Future architectures need to incorporate explicit contextual resets to enhance reliability.
👉 Paper link: https://huggingface.co/papers/2604.08571

16.

17. MixFlow: Mixed Source Distributions Improve Rectified Flows
🔑 Keywords: Diffusion models, Rectified flows, Generative path curvatures, κ-FC, Sampling efficiency
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the limitation of high generative path curvatures in diffusion models and rectified flows by introducing the κ-FC formulation and MixFlow training strategy to enhance sampling efficiency and image quality.
🛠️ Research Methods:
– Introduced κ-FC, conditioning the source distribution on an arbitrary signal κ for better alignment with data distribution.
– Presented MixFlow, a training strategy that improves sample efficiency by reducing generative path curvatures through a flow model trained on linear mixtures of distributions.
💬 Research Conclusions:
– The implemented strategies improved generation quality by 12% in FID compared to standard rectified flow and 7% over previous baselines, demonstrating considerable acceleration in training convergence.
👉 Paper link: https://huggingface.co/papers/2604.09181

18. Large Language Models Align with the Human Brain during Creative Thinking
🔑 Keywords: Creative thinking, Large language models, brain-LLM alignment, Representational Similarity Analysis, post-training objectives
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the alignment between brain activity and large language model (LLM) representations during creative thinking tasks, particularly focusing on how model size and post-training objectives influence this alignment.
🛠️ Research Methods:
– Utilizes fMRI data from 170 participants performing the Alternate Uses Task and applies Representational Similarity Analysis to assess alignment with creativity-related brain networks.
💬 Research Conclusions:
– Brain-LLM alignment is influenced by model size and idea originality, with larger models showing stronger alignment. Post-training objectives can selectively shape this alignment, with a creativity-optimized model enhancing alignment with high-creativity neural responses and certain training leading to different alignment patterns, indicating that training objectives can significantly alter LLM representations in creative contexts.
👉 Paper link: https://huggingface.co/papers/2604.03480

19. Beyond the Assistant Turn: User Turn Generation as a Probe of Interaction Awareness in Language Models
🔑 Keywords: Large Language Models, Interaction Awareness, User-turn Generation, Task Accuracy, Temperature Sampling
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce user-turn generation as a probe for measuring interaction awareness in large language models, separate from task accuracy.
🛠️ Research Methods:
– Conducted experiments across 11 large language models and 5 datasets to assess the relationship between interaction awareness and task accuracy, employing techniques like deterministic generation, temperature sampling, and controlled perturbations.
💬 Research Conclusions:
– Found that interaction awareness is distinct from task accuracy and typically goes unmeasured in standard benchmarks; demonstrated that it remains latent unless probed with user-turn generation and higher temperature sampling, potentially improved with collaboration-oriented post-training.
👉 Paper link: https://huggingface.co/papers/2604.02315

20. Initialisation Determines the Basin: Efficient Codebook Optimisation for Extreme LLM Quantization
🔑 Keywords: Additive quantization, LLM compression, OA-EM, Hessian-weighted Mahalanobis distance, representational ratio
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to address the challenges in additive quantization for LLM compression, specifically the issues arising at 2-bit precision due to codebook initialization.
🛠️ Research Methods:
– The researchers propose OA-EM, an output-aware EM initialization method utilizing Hessian-weighted Mahalanobis distance to improve initial conditions for optimization.
💬 Research Conclusions:
– The study finds that OA-EM consistently outperforms traditional methods in producing better solutions after PV-tuning across various compression rates, architectures, and search budgets, particularly by overcoming the poor optimization regions caused by traditional initializations.
👉 Paper link: https://huggingface.co/papers/2604.08118

21. Cross-Modal Emotion Transfer for Emotion Editing in Talking Face Video
🔑 Keywords: Cross-Modal Emotion Transfer, Emotion Semantic Vectors, Talking Face Generation, Pretrained Audio Encoder, Disentangled Facial Expression Encoder
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve expressive talking face videos by developing a Cross-Modal Emotion Transfer (C-MET) approach, which models emotion semantic vectors between speech and visual feature spaces.
🛠️ Research Methods:
– The research utilizes a large-scale pretrained audio encoder and a disentangled facial expression encoder to learn emotion semantic vectors, representing differences between emotional embeddings across modalities.
💬 Research Conclusions:
– The C-MET approach significantly improves emotion accuracy by 14% compared to existing methods, effectively generating expressive talking face videos, including unseen extended emotions.
👉 Paper link: https://huggingface.co/papers/2604.07786
22. EquiformerV3: Scaling Efficient, Expressive, and General SE(3)-Equivariant Graph Attention Transformers
🔑 Keywords: SE(3)-equivariant graph neural networks, 3D atomic modeling, EquiformerV3, potential energy surfaces
💡 Category: Foundations of AI
🌟 Research Objective:
– The objective is to enhance SE(3)-equivariant graph neural networks in terms of efficiency, expressivity, and generality for improved 3D atomic modeling.
🛠️ Research Methods:
– Introduction of optimized implementation, modifications to EquiformerV2 such as equivariant merged layer normalization, improved feedforward network hyper-parameters, and novel activations like SwiGLU-S^2.
💬 Research Conclusions:
– EquiformerV3 achieves a 1.75x speedup in software implementation and state-of-the-art results in modeling potential energy surfaces, particularly beneficial for energy-conserving simulations and tasks requiring higher-order derivatives.
👉 Paper link: https://huggingface.co/papers/2604.09130

23. p1: Better Prompt Optimization with Fewer Prompts
🔑 Keywords: prompt optimization, system prompt, reward variance, user prompts, reasoning benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates what makes a task suitable for prompt optimization by analyzing the balance between response stochasticity and system prompt quality variance.
🛠️ Research Methods:
– Developed a user prompt filtering method, named p1, that selects a subset of user prompts with high variance to distinguish good system prompts from bad ones.
💬 Research Conclusions:
– The p1 method significantly enhances prompt optimization over training on the full dataset, outperforming strong baselines, and demonstrates that even a small number of prompts can generalize well to other reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2604.08801

24. Large Language Models Generate Harmful Content Using a Distinct, Unified Mechanism
🔑 Keywords: Large language models, alignment training, emergent misalignment, weight pruning, harmful content generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research investigates the internal organization of harmfulness in large language models (LLMs) and how it contributes to emergent misalignment during fine-tuning.
🛠️ Research Methods:
– The study employs targeted weight pruning as a causal intervention to explore and understand the internal structure related to harmful content generation in LLMs.
💬 Research Conclusions:
– The study finds that harmful content generation relies on a compact set of weights different from those used for benign capabilities.
– Alignment training reshapes the internal structure of harmful representations, leading to a greater compression of harm generation weights compared to unaligned models.
– This compression explains emergent misalignment, where fine-tuning in narrow domains can trigger broad misalignment if it engages the compressed weights.
– Pruning harm generation weights reduces emergent misalignment substantially, highlighting the dissociation between harmfulness generation and recognition/explanation capabilities in LLMs.
👉 Paper link: https://huggingface.co/papers/2604.09544

25. VisionFoundry: Teaching VLMs Visual Perception with Synthetic Images
🔑 Keywords: VisionFoundry, Vision-language models, Large language models, Synthetic data generation, Visual perception
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main objective is to improve visual perception tasks in vision-language models using synthetic visual question answering data generated by VisionFoundry.
🛠️ Research Methods:
– The researchers used a pipeline called VisionFoundry that generates synthetic visual data using large language models to create tasks, questions, and text-to-image prompts, which are then verified for consistency with a vision-language model.
💬 Research Conclusions:
– The study concludes that synthetic supervision, facilitated by tools like VisionFoundry, can significantly enhance visual perception in vision-language models, achieving improvements in visual perception benchmarks up to 10%.
👉 Paper link: https://huggingface.co/papers/2604.09531

26. Structured Causal Video Reasoning via Multi-Objective Alignment
🔑 Keywords: Video-LLMs, Structured Event Facts, causal relationships, CausalFact-60K, Multi-Objective Reinforcement Learning
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a method to enhance video understanding using structured representations of events and their causal relationships.
🛠️ Research Methods:
– Introduced CausalFact-60K and a four-stage training pipeline with steps like facts alignment and Multi-Objective Reinforcement Learning (MORL).
💬 Research Conclusions:
– Proposed Factum-4B improves video understanding by achieving reliable reasoning and stronger performance in tasks requiring fine-grained temporal inference.
👉 Paper link: https://huggingface.co/papers/2604.04415

27. Multi-User Large Language Model Agents
🔑 Keywords: Large Language Models, Multi-User Interaction, Privacy Preservation, Coordination Efficiency, Multi-Principal Decision Problem
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically study and address the challenges of multi-user interactions with large language model agents by defining it as a multi-principal decision problem.
🛠️ Research Methods:
– Formalizing multi-user interaction and introducing a unified protocol to handle multi-principal decision-making.
– Designing and implementing stress-testing scenarios to evaluate current LLM capabilities in instruction following, privacy preservation, and coordination.
💬 Research Conclusions:
– Identified systematic gaps in current LLMs, such as instability in prioritizing conflicting objectives, increasing privacy violations over interactions, and efficiency bottlenecks in coordination.
👉 Paper link: https://huggingface.co/papers/2604.08567

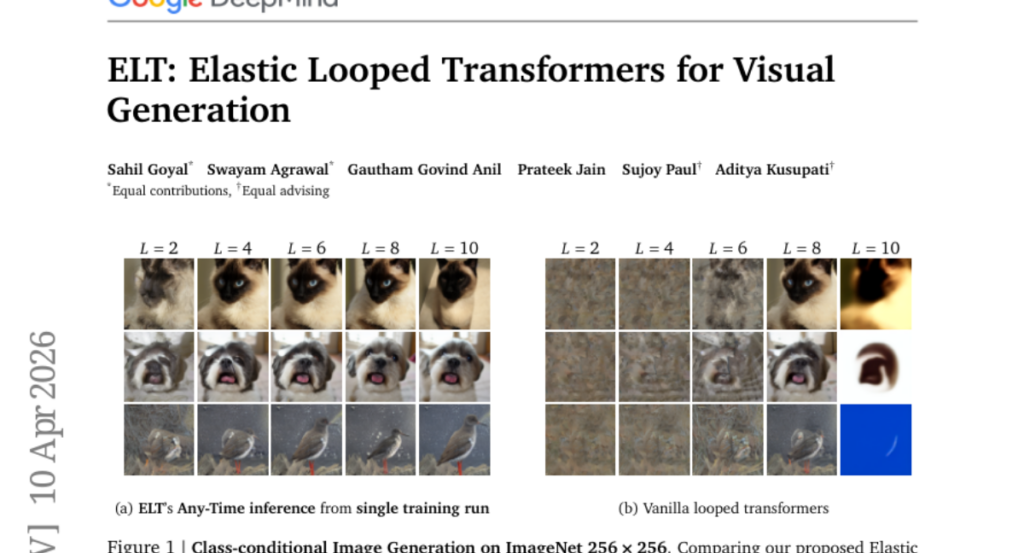
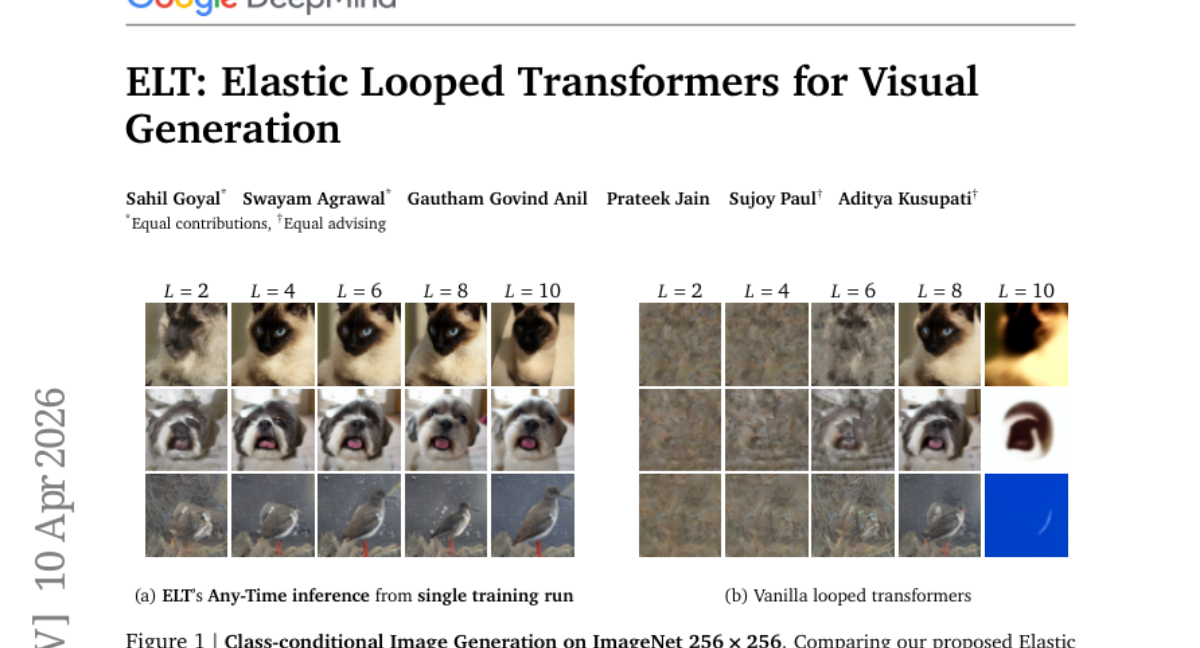
28. ELT: Elastic Looped Transformers for Visual Generation
🔑 Keywords: Elastic Looped Transformers, parameter-efficient, recurrent transformer architecture, Intra-Loop Self Distillation, Any-Time inference
💡 Category: Generative Models
🌟 Research Objective:
– The primary objective is to develop a visual generative model that is highly parameter-efficient while maintaining high-quality outputs.
🛠️ Research Methods:
– Utilization of a recurrent transformer architecture with weight-sharing and Intra-Loop Self Distillation to achieve efficiency and consistency.
💬 Research Conclusions:
– Elastic Looped Transformers achieve significant parameter reduction and competitive performance in visual generation tasks, exemplified by superior FID and FVD scores in class-conditional settings.
👉 Paper link: https://huggingface.co/papers/2604.09168
29. Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
🔑 Keywords: Memory-Augmented, Interactive Video Generation, Diffusion Models, Real-Time Generation, World Models
💡 Category: Generative Models
🌟 Research Objective:
– To enhance interactive video generation by achieving real-time 720p synthesis with long-term temporal consistency using memory-augmented diffusion models.
🛠️ Research Methods:
– Introduced improvements in data, model, and inference, including an upgraded data engine for high-quality data and a training framework ensuring long-horizon consistency.
– Developed a multi-segment autoregressive distillation strategy combined with model quantization and VAE decoder pruning for efficient real-time inference.
💬 Research Conclusions:
– Matrix-Game 3.0 demonstrates up to 40 FPS real-time generation at 720p resolution, maintaining stable memory consistency over long sequences. Scaling up to a larger model further enhances generation quality, offering a practical pathway for industrial-scale deployable world models.
👉 Paper link: https://huggingface.co/papers/2604.08995
30. FORGE:Fine-grained Multimodal Evaluation for Manufacturing Scenarios
🔑 Keywords: Multimodal Large Language Models, domain-specific knowledge, fine-grained domain semantics, supervised fine-tuning, manufacturing tasks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce FORGE, a high-quality multimodal dataset, aimed at bridging the gap in evaluating MLLMs on real-world manufacturing tasks.
🛠️ Research Methods:
– A multimodal dataset is created combining real-world 2D images and 3D point clouds with detailed domain semantics to test 18 cutting-edge MLLMs across three specific tasks: workpiece verification, structural surface inspection, and assembly verification.
💬 Research Conclusions:
– The study uncovers that the key limitation is the lack of domain-specific knowledge rather than issues with visual grounding, suggesting a future research focus area. Structured annotations on the dataset offer significant improvement through supervised fine-tuning, showing a possible path toward domain-adapted MLLMs with a reported accuracy enhancement of up to 90.8%.
👉 Paper link: https://huggingface.co/papers/2604.07413