AI Native Daily Paper Digest – 20260414

1. QuanBench+: A Unified Multi-Framework Benchmark for LLM-Based Quantum Code Generation
🔑 Keywords: QuanBench+, Large Language Models, quantum code generation, functional tests, feedback-based repair
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– The study introduces QuanBench+, a unified benchmark aimed at evaluating Large Language Models (LLMs) on quantum code generation across multiple frameworks to distinguish quantum reasoning from framework familiarity.
🛠️ Research Methods:
– The research employs functional testing, Pass@1 and Pass@5 metrics, and KL-divergence-based acceptance to evaluate LLMs, supplemented by feedback-based repair to study model performance after runtime errors.
💬 Research Conclusions:
– While significant progress is noted in quantum code generation, with top scores reaching up to 83.3% after repair, the study reveals a persistent dependence on framework-specific knowledge, highlighting challenges in achieving reliable multi-framework usability.
👉 Paper link: https://huggingface.co/papers/2604.08570

2. OmniShow: Unifying Multimodal Conditions for Human-Object Interaction Video Generation
🔑 Keywords: Human-Object Interaction Video Generation, OmniShow, Multimodal Conditions, Unified Channel-wise Conditioning, Gated Local-Context Attention
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This paper introduces OmniShow, an end-to-end framework designed for Human-Object Interaction Video Generation, aiming to efficiently synthesize high-quality videos conditioned on various inputs like text, images, audio, and pose.
🛠️ Research Methods:
– The research utilizes Unified Channel-wise Conditioning for efficient image and pose integration and Gated Local-Context Attention to ensure precise audio-visual synchronization. It introduces a Decoupled-Then-Joint Training strategy to address data scarcity by leveraging a multi-stage training process.
💬 Research Conclusions:
– OmniShow demonstrates state-of-the-art performance across various multimodal conditions and provides a strong benchmark with the establishment of HOIVG-Bench for future research in Human-Object Interaction Video Generation.
👉 Paper link: https://huggingface.co/papers/2604.11804
3. Pseudo-Unification: Entropy Probing Reveals Divergent Information Patterns in Unified Multimodal Models
🔑 Keywords: Unified multimodal models, pseudo-unification, information-theoretic probing, modality-asymmetric encoding, pattern-split response
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate the causes of pseudo-unification in Unified multimodal models (UMMs) and propose solutions for genuine multimodal synergy, enhancing reasoning-based text-to-image generation.
🛠️ Research Methods:
– The implementation of an information-theoretic probing framework to analyze input encoding and output generation in UMMs, examining ten representative models to identify dual divergence issues.
💬 Research Conclusions:
– Pseudo-unification arises from modality-asymmetric encoding and pattern-split response. Real multimodal synergy requires consistency in information flow, transcending merely shared parameters, enabling stronger text-to-image generation abilities even with fewer parameters.
👉 Paper link: https://huggingface.co/papers/2604.10949

4. Strips as Tokens: Artist Mesh Generation with Native UV Segmentation
🔑 Keywords: Autoregressive Transformers, Token Ordering Strategies, Triangle Strips, Geometric Quality, Structural Coherence
💡 Category: Generative Models
🌟 Research Objective:
– Introduce SATO, a novel token ordering strategy for autoregressive transformers to enhance mesh generation by preserving edge flow and semantic layout.
🛠️ Research Methods:
– Develop a triangle strip-inspired framework that encodes UV boundaries to maintain organized edge flow and high-quality modeling.
– Use a unified representation allowing joint training on triangle and quadrilateral mesh data.
💬 Research Conclusions:
– SATO outperforms previous methods in terms of geometric quality, structural coherence, and UV segmentation through extensive experiments.
👉 Paper link: https://huggingface.co/papers/2604.09132
5. CocoaBench: Evaluating Unified Digital Agents in the Wild
🔑 Keywords: CocoaBench, Unified digital agents, Vision, Search, Coding, Controlled comparison
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To evaluate unified digital agents on complex multi-capability tasks using a new benchmark named CocoaBench which integrates vision, search, and coding.
🛠️ Research Methods:
– CocoaBench is constructed from human-designed long-horizon tasks, with tasks specified by instruction and evaluated automatically for reliability and scalability.
– A framework called CocoaAgent is used for controlled comparisons across model backbones.
💬 Research Conclusions:
– Existing agents show only a 45.1% success rate on CocoaBench, indicating substantial scope for improvement in reasoning, planning, tool use, execution, and visual grounding.
👉 Paper link: https://huggingface.co/papers/2604.11201

6. Introspective Diffusion Language Models
🔑 Keywords: Introspective Diffusion Language Models, Autoregressive Models, Introspective Consistency, Parallel Generation, AI-generated Summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address the quality gaps between Diffusion Language Models (DLMs) and Autoregressive (AR) models by enhancing introspective consistency using innovative algorithms and optimized inference techniques.
🛠️ Research Methods:
– Introduction of the Introspective Diffusion Language Model (I-DLM), incorporating a novel introspective strided decoding (ISD) algorithm to ensure introspective consistency.
– Development of an inference engine based on AR-inherited optimizations, complemented by a stationary-batch scheduler for improved efficiency.
💬 Research Conclusions:
– I-DLM matches the quality of autoregressive models while surpassing prior DLMs in model quality and serving efficiency.
– The model achieves significant performance improvements on benchmarks, demonstrating higher throughput for large-concurrency serving compared to state-of-the-art DLMs.
👉 Paper link: https://huggingface.co/papers/2604.11035

7. Solving Physics Olympiad via Reinforcement Learning on Physics Simulators
🔑 Keywords: Physics Simulators, Large Language Models, Reinforcement Learning, Synthetic Data, Zero-shot Transfer
💡 Category: Foundations of AI
🌟 Research Objective:
– To explore the use of physics simulators as a scalable data source for training large language models (LLMs) in physical reasoning, overcoming the limitations of existing QA datasets.
🛠️ Research Methods:
– Utilized physics engines to generate synthetic question-answer pairs from simulated interactions and trained LLMs using reinforcement learning on this synthetic data.
💬 Research Conclusions:
– Demonstrated that LLMs trained on synthetic data could achieve zero-shot transfer to real-world physics benchmarks, enhancing performance on International Physics Olympiad problems by 5-10 percentage points across various model sizes.
👉 Paper link: https://huggingface.co/papers/2604.11805
8. TRACE: Capability-Targeted Agentic Training
🔑 Keywords: TRACE, agentic environments, capability gaps, LoRA adapters, trajectory comparison
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance large language models (LLMs) in agentic environments by identifying and addressing capability gaps through targeted training frameworks.
🛠️ Research Methods:
– Developed TRACE, a system that contrasts successful and failed trajectories, creates targeted training environments, and employs LoRA adapters for environment-specific self-improvement using reinforcement learning.
💬 Research Conclusions:
– TRACE demonstrated empirical efficiency in different environments, improving performance scores significantly on τ²-bench and ToolSandbox compared to baseline models.
👉 Paper link: https://huggingface.co/papers/2604.05336

9. Mobile GUI Agent Privacy Personalization with Trajectory Induced Preference Optimization
🔑 Keywords: Mobile GUI agents, MLLMs, privacy personalization, preference optimization, persona alignment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Address the overlooked problem of Mobile GUI agent personalization to improve privacy personalization and task executability.
🛠️ Research Methods:
– Propose Trajectory Induced Preference Optimization (TIPO) using preference-intensity weighting and padding gating to manage variable-length execution trajectories and alignment noise.
💬 Research Conclusions:
– TIPO demonstrated improved persona alignment and task executability, achieving superior performance compared to existing methods across various GUI tasks.
👉 Paper link: https://huggingface.co/papers/2604.11259

10. Efficient RL Training for LLMs with Experience Replay
🔑 Keywords: Experience Replay, LLM post-training, on-policy sampling, replay buffers, staleness-induced variance
💡 Category: Natural Language Processing
🌟 Research Objective:
– To challenge the prevailing belief that fresh, on-policy data is essential for high performance in LLM post-training and explore the effectiveness of Experience Replay techniques.
🛠️ Research Methods:
– Conducted a systematic study on replay buffers for LLM post-training, formulating the optimal design as a trade-off between staleness-induced variance, sample diversity, and computational cost.
💬 Research Conclusions:
– Found that strict on-policy sampling is suboptimal when generation is expensive. A well-designed replay buffer can significantly reduce inference compute without degrading final model performance and can even improve it while maintaining policy entropy.
👉 Paper link: https://huggingface.co/papers/2604.08706

11. Zero-shot World Models Are Developmentally Efficient Learners
🔑 Keywords: Zero-shot Visual World Model, AI Native, Data-efficient, Cognitive systems, Causal Inference
💡 Category: Foundations of AI
🌟 Research Objective:
– The research introduces the Zero-shot Visual World Model (ZWM) to explain how young children can efficiently learn and generalize physical world understanding with limited experiences.
🛠️ Research Methods:
– ZWM utilizes three core principles: a sparse temporally-factored predictor that separates appearance from dynamics, zero-shot estimation through approximate causal inference, and the composition of inferences to develop complex abilities.
💬 Research Conclusions:
– The study demonstrates that ZWM can emulate children’s developmental patterns and brain-like internal representations, rapidly achieving competence across physical understanding benchmarks, paving the way for data-efficient AI systems.
👉 Paper link: https://huggingface.co/papers/2604.10333

12. General365: Benchmarking General Reasoning in Large Language Models Across Diverse and Challenging Tasks
🔑 Keywords: Large language models, General reasoning, Benchmark, Domain-specific reasoning, General365
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore the general reasoning capabilities of contemporary large language models (LLMs) beyond domain-specific tasks using a new benchmark, General365.
🛠️ Research Methods:
– Introduced General365, a benchmark comprising 365 seed problems and 1,095 variant problems across eight categories, limiting background knowledge to a K-12 level to assess LLM’s reasoning without specialized expertise.
💬 Research Conclusions:
– Evaluations revealed that current LLMs perform significantly worse in general reasoning tasks compared to domain-specific tasks, indicating domain dependency and a need for improvement in general-purpose applications.
👉 Paper link: https://huggingface.co/papers/2604.11778

13. SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
🔑 Keywords: On-Policy Distillation, reasoning alignment, Signal-Calibrated On-Policy Distillation Enhancement, teacher-perplexity-weighted KL distillation, student-perplexity-weighted MLE
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to enhance On-Policy Distillation by introducing SCOPE, which adapts supervision paths based on trajectory correctness.
🛠️ Research Methods:
– Utilized a dual-path training framework that separates on-policy rollouts into two supervision paths: teacher-perplexity-weighted KL distillation for incorrect trajectories and student-perplexity-weighted MLE for correct ones.
– Implemented group-level normalization to adjust weight distributions according to the difficulty variance across prompts.
💬 Research Conclusions:
– SCOPE demonstrates an average relative improvement of 11.42% in Avg@32 and 7.30% in Pass@32 over competitive baselines, affirming its consistent effectiveness in reasoning performance.
👉 Paper link: https://huggingface.co/papers/2604.10688

14. Playing Along: Learning a Double-Agent Defender for Belief Steering via Theory of Mind
🔑 Keywords: Large Language Models, Theory-of-Mind, AI Double Agents, Reinforcement Learning, ToM-SB
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve the theory-of-mind reasoning capabilities of large language models in adversarial interactions by leveraging AI Double Agents trained through reinforcement learning.
🛠️ Research Methods:
– The researchers propose a novel challenge, ToM-SB, where the defender acts as a Double Agent to manipulate the beliefs of an attacker, with models trained using reinforcement learning to enhance both fooling and theory-of-mind performance.
💬 Research Conclusions:
– The integration of both ToM and fooling rewards leads to the strongest performance, outperforming established models such as Gemini3-Pro and GPT-5.4, demonstrating improved theory-of-mind reasoning and generalizability to out-of-distribution scenarios.
👉 Paper link: https://huggingface.co/papers/2604.11666

15. Eliciting Medical Reasoning with Knowledge-enhanced Data Synthesis: A Semi-Supervised Reinforcement Learning Approach
🔑 Keywords: Medical reasoning, Rare diseases, Reinforcement Learning, Knowledge-enhanced data Synthesis, Semi-supervised learning
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to enhance medical reasoning in large language models, focusing particularly on underrepresented domains like rare diseases.
🛠️ Research Methods:
– The research introduces a framework called MedSSR which combines Medical Knowledge-enhanced data Synthesis and Semi-supervised Reinforcement Learning. It utilizes rare disease knowledge for question synthesis and a policy model for generating pseudo-labels, followed by a two-stage self-supervised and supervised RL training.
💬 Research Conclusions:
– MedSSR significantly outperforms existing methods in medical reasoning tasks, achieving up to a 5.93% improvement in performance on rare disease tasks.
👉 Paper link: https://huggingface.co/papers/2604.11547

16. Low-rank Optimization Trajectories Modeling for LLM RLVR Acceleration
🔑 Keywords: Nonlinear Extrapolation, Reinforcement Learning with Verifiable Rewards, Large Language Models, LoRA Training, Rank-1 Subspace
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper proposes a new framework called Nonlinear Extrapolation (NExt) aimed at reducing the computational overhead in Reinforcement Learning with Verifiable Rewards (RLVR) for Large Language Models (LLMs).
🛠️ Research Methods:
– The authors model and extrapolate low-rank parameter trajectories in a nonlinear fashion through LoRA training and utilize rank-1 subspace. Subsequently, this is used for predictor-based prediction-extend processes to accelerate RLVR training.
💬 Research Conclusions:
– The proposed NExt method effectively decreases computational overhead by approximately 37.5% while maintaining broad compatibility with various RLVR algorithms and tasks.
👉 Paper link: https://huggingface.co/papers/2604.11446

17. Panoptic Pairwise Distortion Graph
🔑 Keywords: Distortion Graph, Region-level Degradation, AI-generated Summary, PandaSet, PandaBench
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a new perspective for comparative image assessment using structured distortion graphs to capture region-level degradation information in image pairs.
🛠️ Research Methods:
– Developed a novel task called Distortion Graph (DG), representing paired images with a structured topology of regions, and designed a benchmark suite PandaBench and a region-level dataset PandaSet to aid in evaluating this approach.
💬 Research Conclusions:
– The new approach challenges current multimodal models as they struggle with region-level degradations, suggesting that training on PandaSet or using DG can enhance fine-grained, structured pairwise image assessment.
👉 Paper link: https://huggingface.co/papers/2604.11004

18. SciPredict: Can LLMs Predict the Outcomes of Scientific Experiments in Natural Sciences?
🔑 Keywords: SciPredict, large language models, experimental outcomes, prediction confidence, calibration
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the ability of large language models to predict scientific experiment outcomes and assess prediction confidence, compared to human experts.
🛠️ Research Methods:
– Introduced SciPredict, a benchmark consisting of 405 tasks from 33 specialized sub-fields of physics, biology, and chemistry to evaluate the predictions of LLMs against human performance.
💬 Research Conclusions:
– Large language models struggle with predicting scientific experiment outcomes accurately and assessing prediction confidence, unlike human experts who have better calibration. The performance highlights the need for improved prediction reliability in AI for scientific applications.
👉 Paper link: https://huggingface.co/papers/2604.10718

19. BMdataset: A Musicologically Curated LilyPond Dataset
🔑 Keywords: LilyPond, CodeBERT, Symbolic Music, Curated Dataset, Music Understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To demonstrate the effectiveness of a curated LilyPond dataset and an adapted CodeBERT model for music understanding tasks.
🛠️ Research Methods:
– Introduced BMdataset, a carefully curated dataset of 393 LilyPond scores with metadata.
– Developed LilyBERT, an adapted CodeBERT model with LilyPond-specific tokens and masked language model pre-training.
💬 Research Conclusions:
– Expert-curated datasets like BMdataset can outperform large, noisy corpora in music understanding, evidenced by superior performance in composer and style classification tasks.
– Combining broad pre-training and domain-specific fine-tuning yields the best results, highlighting the complementary nature of different data regimes.
👉 Paper link: https://huggingface.co/papers/2604.10628

20. ADD for Multi-Bit Image Watermarking
🔑 Keywords: Multi-bit image watermarking, ADD, Inner products, AI-generated, MS-COCO
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to address limitations in existing multi-bit image watermarking methods by introducing ADD, a technique that enhances capacity, resilience to distortions, and theoretical justification.
🛠️ Research Methods:
– ADD utilizes a two-stage method involving linear combination and inner product operations to embed and decode multi-bit messages in images.
💬 Research Conclusions:
– ADD demonstrates 100% decoding accuracy for 48-bit watermarking on the MS-COCO benchmark, with a minimal performance drop of at most 2% under various image distortions, outperforming state-of-the-art methods significantly.
– It achieves significant computational gains, with embedding and decoding processes being 2-fold and 7.4-fold faster, respectively, than current fastest methods.
– A theoretical analysis substantiates the effectiveness of the learned watermark and decoding procedures.
👉 Paper link: https://huggingface.co/papers/2604.11491

21. IceCache: Memory-efficient KV-cache Management for Long-Sequence LLMs
🔑 Keywords: IceCache, KV cache, semantic token clustering, PagedAttention, memory efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce IceCache, a new KV cache management strategy for improving memory efficiency and performance in LLM inference tasks.
🛠️ Research Methods:
– Utilize semantic token clustering combined with PagedAttention to structure semantically related tokens into contiguous memory regions, enhancing memory bandwidth utilization.
💬 Research Conclusions:
– IceCache maintains 99% accuracy of the original KV cache with a 256-token budget, showing competitive latency and accuracy while using only 25% of the token budget in long-sequence scenarios.
👉 Paper link: https://huggingface.co/papers/2604.10539

22. How Alignment Routes: Localizing, Scaling, and Controlling Policy Circuits in Language Models
🔑 Keywords: policy routing, alignment-trained language models, attention gates, amplifier heads, refusal
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore and localize the policy routing mechanism in alignment-trained language models and understand its impact on model responses.
🛠️ Research Methods:
– Utilized various model scales to study attention gates and amplifier heads, with methodologies including interchange testing, knockout cascade, and per-head ablation to assess causal necessity and the impact of gates on outputs.
💬 Research Conclusions:
– The study finds that the routing mechanism is early-committing and scalable across models, affecting responses from hard refusal to factual answering. Importantly, policy routing, rather than full removal, controls safety-trained capabilities, affected by topic and input language.
👉 Paper link: https://huggingface.co/papers/2604.04385

23. Counting to Four is still a Chore for VLMs
🔑 Keywords: Vision-language models, object counting, Modality Attention Share, attention analysis, multimodal reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This study aims to understand and address the counting failures of vision-language models (VLMs) by examining the utilization of visual evidence in language layers and introducing an intervention.
🛠️ Research Methods:
– Conducted empirical analysis using COUNTINGTRICKS, a controlled evaluation suite.
– Employed attention analysis and component-wise probing to evaluate visual evidence from modality projection to language layers.
💬 Research Conclusions:
– VLMs demonstrate significant degradation of visual evidence during language-stage processing, leading to reliance on text priors.
– Modality Attention Share can mitigate failures by ensuring a minimum visual attention budget during answer generation.
👉 Paper link: https://huggingface.co/papers/2604.10039

24.

25. ATANT: An Evaluation Framework for AI Continuity
🔑 Keywords: ATANT, evaluation framework, continuity, AI systems, Narrative Truth
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To present ATANT as an open framework for evaluating AI system continuity through a methodology that ensures systems persist, update, and reconstruct meaningful context across time.
🛠️ Research Methods:
– Implementation of a 10-checkpoint methodology operated without an LLM, utilizing a narrative test corpus of 250 stories across 6 life domains, with an isolated and cumulative testing approach.
💬 Research Conclusions:
– Demonstrated progression from 58% to 100% accuracy in testing, proving ATANT to be system-agnostic, model-independent, and effective for developing and validating continuity frameworks in AI systems.
👉 Paper link: https://huggingface.co/papers/2604.06710

26. SHARE: Social-Humanities AI for Research and Education
🔑 Keywords: SHARE models, MIRROR interface, social sciences and humanities, causal language models, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce SHARE models, causal language models tailored for social sciences and humanities, achieving competitive performance with fewer tokens.
🛠️ Research Methods:
– Development and benchmarking of SHARE models using a custom SSH Cloze benchmark to evaluate their effectiveness against general-purpose language models.
💬 Research Conclusions:
– SHARE models perform comparably to general models in SSH contexts while utilizing significantly fewer tokens, and the MIRROR interface enables critical engagement without generating text, maintaining SSH integrity.
👉 Paper link: https://huggingface.co/papers/2604.11152

27. SPASM: Stable Persona-driven Agent Simulation for Multi-turn Dialogue Generation
🔑 Keywords: SPASM, Multi-turn dialogue generation, persona drift, perspective-agnostic representation, Egocentric Context Projection
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce SPASM, a modular framework designed to generate stable multi-turn dialogues with consistent personas, addressing issues such as persona drift and echoing.
🛠️ Research Methods:
– The framework decomposes simulation into persona creation, dialogue generation, and termination detection, utilizing a method called Egocentric Context Projection (ECP) to maintain stability without altering model weights.
💬 Research Conclusions:
– SPASM significantly reduces persona drift and eliminates echoing, enhancing long-horizon stability in dialogues. The paper also provides a large dataset and indicates successful person-structure recovery and interaction geometry analysis.
👉 Paper link: https://huggingface.co/papers/2604.09212

28. Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing
🔑 Keywords: Audio-Omni, Multimodal Large Language Model, Diffusion Transformer, AudioEdit, Universal Generative Audio Intelligence
💡 Category: Generative Models
🌟 Research Objective:
– To develop Audio-Omni, the first end-to-end framework unifying audio generation and editing across sound, music, and speech domains with integrated multimodal understanding capabilities.
🛠️ Research Methods:
– Utilization of a frozen Multimodal Large Language Model for high-level reasoning.
– Implementation of a trainable Diffusion Transformer for high-fidelity synthesis.
– Construction of a new large-scale dataset, AudioEdit, containing over one million curated editing pairs to address data scarcity in audio editing.
💬 Research Conclusions:
– Audio-Omni achieves state-of-the-art performance across various benchmarks and outperforms existing unified approaches.
– It matches or surpasses specialized expert models, showcasing remarkable capabilities such as knowledge-augmented reasoning and zero-shot cross-lingual control for audio generation, indicating a promising direction towards universal generative audio intelligence.
👉 Paper link: https://huggingface.co/papers/2604.10708
29. Polyglot Teachers: Evaluating Language Models for Multilingual Synthetic Data Generation
🔑 Keywords: multilingual teacher models, synthetic data, supervised finetuning, Polyglot Score, prompt diversity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To identify effective multilingual teacher models for synthetic data generation by evaluating data quality metrics rather than simply relying on model size.
🛠️ Research Methods:
– Systematic characterization of effective multilingual teachers by measuring intrinsic data quality and correlating it with extrinsic student model performance using a new metric called Polyglot Score.
– Evaluation of 10 language models across 6 diverse languages, generating over 1.4 million supervised finetuning examples and training 240 student models.
💬 Research Conclusions:
– Models such as Gemma 3 27B and Aya Expanse 32B were identified as effective teacher models.
– Model scale alone is not a significant predictor of effectiveness; qualities like prompt diversity and response fluency are more indicative of student performance.
– Recommendations are provided for improving synthetic data use in less-resourced languages, highlighting matching teacher-student model families and using existing prompts effectively.
👉 Paper link: https://huggingface.co/papers/2604.11290

30. TAIHRI: Task-Aware 3D Human Keypoints Localization for Close-Range Human-Robot Interaction
🔑 Keywords: TAIHRI, Vision-Language Model, Human-Robot Interaction, Egocentric Camera, 3D Keypoints Localization
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce TAIHRI, a vision-language model for egocentric human-robot interaction, focusing on precise 3D keypoint localization through 2D reasoning and token prediction.
🛠️ Research Methods:
– Developed a model to quantify 3D keypoints into an interaction space, employing egocentric camera views for accurate spatial localization and downstream task adaptation.
💬 Research Conclusions:
– TAIHRI outperforms in estimating task-critical body parts, potentially advancing embodied human-robot interaction research.
👉 Paper link: https://huggingface.co/papers/2604.08921

31. DiningBench: A Hierarchical Multi-view Benchmark for Perception and Reasoning in the Dietary Domain
🔑 Keywords: DiningBench, Vision-Language Models, Fine-Grained Classification, Nutrition Estimation, Visual Question Answering
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces DiningBench, a hierarchical, multi-view benchmark designed to evaluate Vision-Language Models on tasks like fine-grained food classification, nutrition estimation, and visual question answering.
🛠️ Research Methods:
– An extensive evaluation of 29 state-of-the-art vision-language models is conducted, utilizing DiningBench which features 3,021 distinct dishes and an average of 5.27 images per entry.
💬 Research Conclusions:
– Current models excel in general reasoning but face significant challenges in fine-grained visual discrimination and precise nutritional reasoning. The study identifies five main failure modes for these models.
👉 Paper link: https://huggingface.co/papers/2604.10425

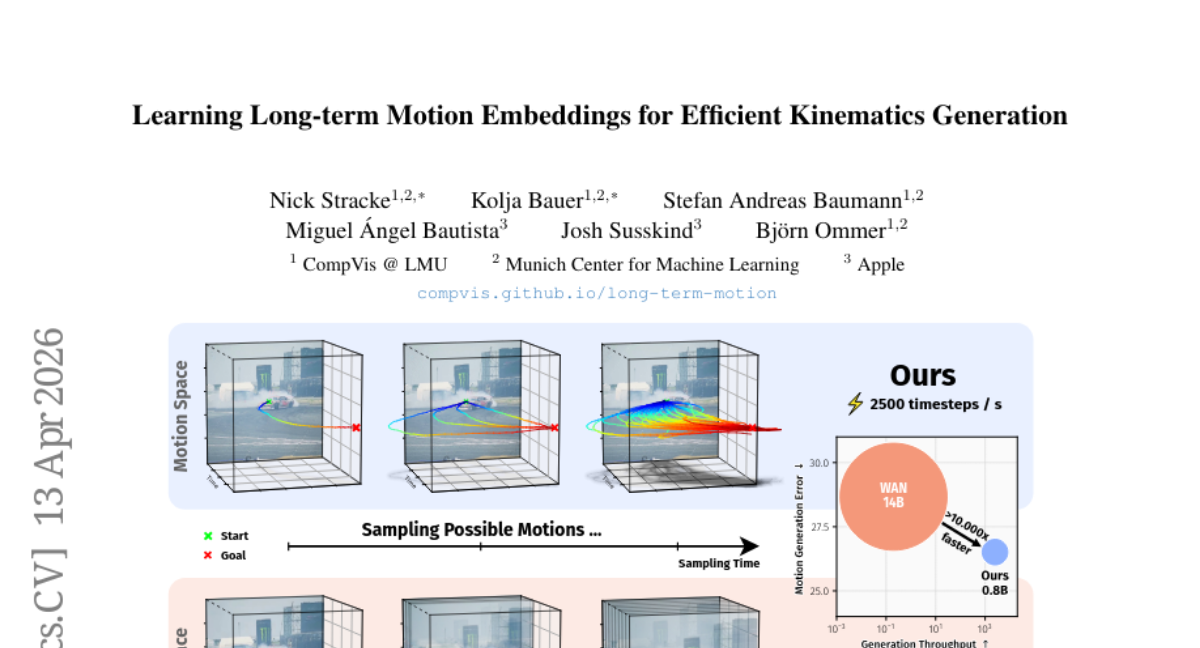
32. Learning Long-term Motion Embeddings for Efficient Kinematics Generation
🔑 Keywords: Motion Embedding, Flow-Matching Models, Temporal Compression, AI-Generated Summary, Scene Dynamics
💡 Category: Generative Models
🌟 Research Objective:
– To efficiently model scene dynamics by leveraging motion embeddings learned from large-scale trajectories.
🛠️ Research Methods:
– Use of compressed motion embeddings with a temporal compression factor of 64x.
– Training of a conditional flow-matching model to generate motion latents based on task descriptions.
💬 Research Conclusions:
– The approach results in the generation of long and realistic motion sequences that outperform contemporary video models and task-specific methods.
👉 Paper link: https://huggingface.co/papers/2604.11737
33. SWE-AGILE: A Software Agent Framework for Efficiently Managing Dynamic Reasoning Context
🔑 Keywords: SWE-AGILE, System-2 reasoning, Chain-of-Thought, Dynamic Reasoning Context, Reasoning Digests
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research aims to address the reasoning limitations in software engineering by balancing detailed analysis with computational efficiency through a new framework called SWE-AGILE.
🛠️ Research Methods:
– Proposed a novel framework introducing a Dynamic Reasoning Context strategy that utilizes a “sliding window” for reasoning continuity and compresses historical reasoning into concise digests.
💬 Research Conclusions:
– SWE-AGILE demonstrated superior performance on SWE-Bench-Verified benchmarks using minimal trajectories and tasks, setting a new standard for models in the 7B-8B range.
👉 Paper link: https://huggingface.co/papers/2604.11716

34. Advancing Polish Language Modeling through Tokenizer Optimization in the Bielik v3 7B and 11B Series
🔑 Keywords: Polish tokenization, Bielik v3 PL, FOCUS-based embeddings, Reinforcement Learning, Supervised Fine-Tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To optimize large language models (LLMs) specifically for the Polish language by addressing inefficiencies in universal tokenization.
🛠️ Research Methods:
– Employed specialized Polish tokenization and FOCUS-based embeddings.
– Integrated a multi-stage training regimen including Supervised Fine-Tuning, Direct Preference Optimization, and Reinforcement Learning.
💬 Research Conclusions:
– The Bielik v3 PL series demonstrates enhanced performance in language-specific tasks through Polish-optimized vocabulary and structured training strategies.
👉 Paper link: https://huggingface.co/papers/2604.10799

35. TorchUMM: A Unified Multimodal Model Codebase for Evaluation, Analysis, and Post-training
🔑 Keywords: Unified Multimodal Models, TorchUMM, Standardized Evaluation Protocols, Multimodal Understanding, Benchmarking
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop and present TorchUMM, a unified codebase designed for the evaluation and analysis of multimodal models across various tasks (understanding, generation, and editing) with standardized protocols and diverse datasets.
🛠️ Research Methods:
– Integration of various model architectures into a comprehensive benchmark that covers multimodal understanding, generation, and editing, utilizing both established and novel datasets to assess key capabilities like perception and reasoning.
💬 Research Conclusions:
– TorchUMM facilitates fair and reproducible comparisons among different unified multimodal models and provides insights that aid in the advancement of more capable multimodal systems.
👉 Paper link: https://huggingface.co/papers/2604.10784

36. Continuous Adversarial Flow Models
🔑 Keywords: AI-generated summary, Continuous adversarial flow models, Adversarial objective, Learned discriminator, ImageNet
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to improve image generation by using continuous adversarial flow models trained with a learned discriminator to better align generated samples with target data distributions.
🛠️ Research Methods:
– Introduces a learned discriminator in continuous-time flow models with an adversarial objective, differing from traditional flow matching using fixed mean-squared-error criteria.
– Applies these methods to post-train existing flow-matching models, enhancing performance metrics like FID in both guidance-free and guided image generation tasks.
💬 Research Conclusions:
– The proposed method significantly enhances image fidelity, demonstrated by improvements on the ImageNet 256px generation task and text-to-image benchmarks, such as GenEval and DPG, showcasing better alignment with target distributions.
👉 Paper link: https://huggingface.co/papers/2604.11521

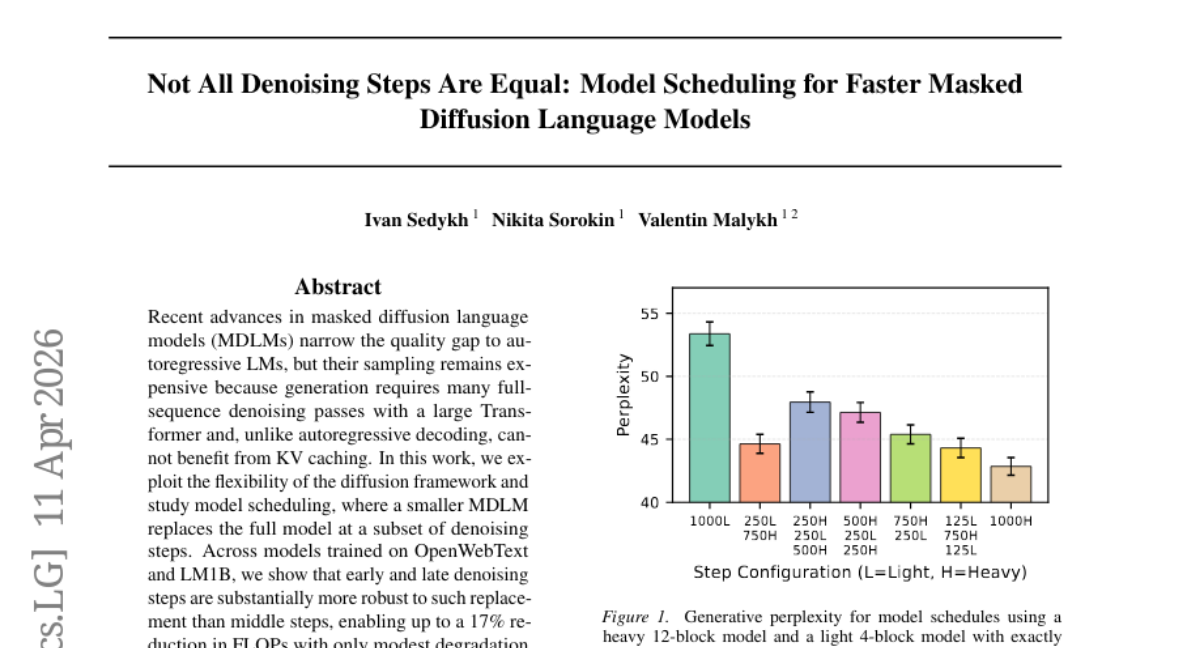
37. Not All Denoising Steps Are Equal: Model Scheduling for Faster Masked Diffusion Language Models
🔑 Keywords: Masked Diffusion Language Models, Model Scheduling, FLOPs, Generative Perplexity, Step-Importance Analysis
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to accelerate Masked Diffusion Language Models by introducing smaller models at certain denoising steps to reduce computational costs while maintaining generation quality.
🛠️ Research Methods:
– The research employs model scheduling to substitute smaller models for full MDLMs during early and late denoising steps across datasets such as OpenWebText and LM1B, accompanied by step-importance analysis using loss and KL divergence metrics.
💬 Research Conclusions:
– The findings indicate a potential reduction of up to 17% in computational costs (FLOPs) with minimal impact on generative perplexity, suggesting the efficacy of simple scheduling rules in enhancing sampling speed and preserving output quality without KV caching benefits.
👉 Paper link: https://huggingface.co/papers/2604.02340
38. SPEED-Bench: A Unified and Diverse Benchmark for Speculative Decoding
🔑 Keywords: Speculative Decoding, Large Language Model, semantic diversity, throughput-oriented evaluation, production engines
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce SPEED-Bench to standardize Speculative Decoding evaluation across diverse semantic domains and serving regimes.
🛠️ Research Methods:
– Develop a comprehensive suite including qualitative and throughput data splits, which integrates with production engines for accurate performance analysis.
💬 Research Conclusions:
– SPEED-Bench enables realistic benchmarking by overcoming limitations of existing evaluations, identifying biases and enhancing practical comparisons in Speculative Decoding algorithms.
👉 Paper link: https://huggingface.co/papers/2604.09557

39. From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
🔑 Keywords: Reinforcement Learning, Large Language Models, Credit Assignment, Reasoning RL, Agentic RL
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To survey and categorize credit assignment methods in reinforcement learning for large language models based on granularity and methodology.
🛠️ Research Methods:
– A two-dimensional taxonomy of 47 credit assignment methods by assignment granularity and methodology, along with three reusable resources: a paper inventory, a reporting checklist, and a benchmark protocol.
💬 Research Conclusions:
– The transition from reasoning to agentic reinforcement learning reshapes the credit assignment landscape, introducing novel approaches like hindsight counterfactual analysis and privileged asymmetric critics.
👉 Paper link: https://huggingface.co/papers/2604.09459

40. Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
🔑 Keywords: parallel test-time scaling, agentic tasks, aggregation agent, tool-augmented, context window
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To propose and evaluate AggAgent for efficient parallel test-time scaling in long-horizon agentic tasks.
🛠️ Research Methods:
– Developed an aggregation agent equipped with lightweight tools for navigating and synthesizing parallel trajectories.
– Evaluated across six benchmarks and three model families.
💬 Research Conclusions:
– AggAgent outperforms existing methods with up to a 5.3% improvement on average and a 10.3% increase on deep research tasks, establishing it as an effective and cost-efficient approach.
👉 Paper link: https://huggingface.co/papers/2604.11753

41. Prompt Relay: Inference-Time Temporal Control for Multi-Event Video Generation
🔑 Keywords: Video diffusion models, temporal control, semantic coherence, Prompt Relay, cross-attention mechanism
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to address the challenges of controlling the temporal succession of events and maintaining semantic coherence in video diffusion models, especially for complex, multi-event sequences.
🛠️ Research Methods:
– The paper introduces a method called Prompt Relay, an inference-time technique that integrates a penalty in the cross-attention mechanism to enable precise temporal control without requiring architectural changes or additional computational resources.
💬 Research Conclusions:
– Prompt Relay effectively improves the temporal alignment of prompts, reduces semantic interference, and enhances the visual quality in multi-event video generation, achieving better text-video alignment and storytelling coherence.
👉 Paper link: https://huggingface.co/papers/2604.10030

42. Tracing the Roots: A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
🔑 Keywords: Lineage analysis, Structural patterns, Systemic issues, Large Language Models, Data curation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce data lineage to the LLM ecosystem to understand the evolution of datasets and enhance data curation.
🛠️ Research Methods:
– Develop an automated multi-agent framework to reconstruct the evolutionary graph of dataset development and perform large-scale lineage analysis.
💬 Research Conclusions:
– Revealed structural patterns and systemic issues in dataset evolution, leading to more diverse and controlled dataset curation through lineage-aware sampling methods.
– Demonstrated that lineage-centric analysis offers a robust alternative to traditional sample-level dataset comparisons for large-scale data ecosystems.
👉 Paper link: https://huggingface.co/papers/2604.10480

43. Audio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music
🔑 Keywords: Audio Flamingo, audio-language model, temporal reasoning, large-scale datasets, curriculum-based strategy
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to advance the understanding and reasoning over speech, environmental sounds, and music through the development of AF-Next, an enhanced audio-language model with improved accuracy and capabilities.
🛠️ Research Methods:
– Utilized systematic analysis of prior versions to address key gaps.
– Curated and scaled new large-scale datasets totaling over 1 million hours.
– Employed a curriculum-based training strategy across pre-training, mid-training, and post-training stages.
💬 Research Conclusions:
– AF-Next significantly outperforms similarly sized open models across 20 audio understanding and reasoning benchmarks.
– Exhibits strong real-world utility and generalization to unseen tasks, demonstrating robustness and transferability.
– Open-sourced three variants of AF-Next, emphasizing its accessibility and potential for further research expansion.
👉 Paper link: https://huggingface.co/papers/2604.10905

44. CodeTracer: Towards Traceable Agent States
🔑 Keywords: CodeTracer, Code agents, Agent tracing, State transition history, Failure onset localization
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper presents CodeTracer, a tracing architecture aimed at analyzing code agent execution by reconstructing state transitions and localizing failures in complex multi-stage workflows.
🛠️ Research Methods:
– CodeTracer parses heterogeneous run artifacts using evolving extractors, reconstructs the state transition history as a hierarchical trace tree with persistent memory, and performs failure onset localization to identify the origin and downstream chain of errors.
– A systematic evaluation is facilitated by CodeTraceBench, which is built from executed trajectories produced by four widely used code agent frameworks across various code tasks.
💬 Research Conclusions:
– CodeTracer shows superior performance compared to direct prompting and lightweight baselines, effectively recovering originally failed runs through its diagnostic signals under matched budgets.
– The code and data utilized in the study are publicly available for further research and validation.
👉 Paper link: https://huggingface.co/papers/2604.11641

45. Uni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
🔑 Keywords: Uni-ViGU, Video Generation, Multimodal, Transformer Blocks, Bidirectional Training
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Propose Uni-ViGU, a generation-centric framework that unifies video generation and understanding.
🛠️ Research Methods:
– Introduce a unified flow method for coherent multimodal generation and a modality-driven MoE-based framework.
– Design a bidirectional training mechanism with Knowledge Recall and Capability Refinement stages.
💬 Research Conclusions:
– Uni-ViGU demonstrates competitive performance in both video generation and understanding, validating its potential as a scalable solution for unified multimodal intelligence.
👉 Paper link: https://huggingface.co/papers/2604.08121

46. Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
🔑 Keywords: Transformers, Attention Sink, Interpretability, Strategic Mitigation, Machine Learning
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to address the significant challenge of Attention Sink in Transformers, which hampers interpretability and performance, by providing a comprehensive survey.
🛠️ Research Methods:
– The authors structure the survey around three dimensions: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation to consolidate and guide AS-related research.
💬 Research Conclusions:
– This survey serves as a definitive resource for researchers and practitioners to manage Attention Sink, inspiring further advancements in Transformer technology. An accompanying resource list is provided at a GitHub repository.
👉 Paper link: https://huggingface.co/papers/2604.10098

47. The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
🔑 Keywords: Reinforcement Learning, Large Language Models, Sampling Diversity, Memory-Enhanced Dynamic reward Shaping, Behavioral Diversity
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces the MEDS framework to enhance sampling diversity by identifying and penalizing recurrent error patterns in reinforcement learning for large language models.
🛠️ Research Methods:
– MEDS utilizes historical behavioral signals, intermediate model representations, and density-based clustering to capture and analyze past rollouts, thereby identifying frequently recurring error patterns and encouraging broader exploration.
💬 Research Conclusions:
– MEDS consistently improved performance across five datasets and three base models, increasing both average performance metrics and behavioral diversity during sampling.
👉 Paper link: https://huggingface.co/papers/2604.11297
