AI Native Daily Paper Digest – 20260415

1. ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
🔑 Keywords: GUI agents, Reinforcement Learning, ClawGUI, Environment Instability, Application Modernization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research introduces ClawGUI, an open-source framework designed to overcome key challenges in GUI agent development, including providing a unified reinforcement learning infrastructure, standardized evaluation protocols, and cross-platform deployment capabilities.
🛠️ Research Methods:
– ClawGUI-RL offers the first open-source GUI agent RL framework with support for both parallel virtual environments and real devices through a Process Reward Model.
– ClawGUI-Eval establishes a standardized evaluation pipeline covering multiple benchmarks and models, achieving high reproduction accuracy.
– ClawGUI-Agent enables the deployment of trained agents across various operating systems with hybrid CLI-GUI control.
💬 Research Conclusions:
– ClawGUI successfully addresses existing gaps in GUI agent development infrastructure, achieving improved performance and reliability compared to baseline models.
– The framework allows trained agents to achieve significant success rates on tasks such as MobileWorld GUI-Only.
👉 Paper link: https://huggingface.co/papers/2604.11784
2. Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
🔑 Keywords: On-policy distillation, large language models, compatible thinking patterns, high-probability tokens, token-level reward
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to systematically investigate the dynamics and mechanisms of On-policy distillation (OPD) in large language models.
🛠️ Research Methods:
– The study identifies two key conditions for successful OPD and validates these through weak-to-strong reverse distillation experiments.
– It includes probing into the token-level mechanism to understand the alignment on tokens at student-visited states.
💬 Research Conclusions:
– Successful OPD requires compatible thinking patterns between teacher and student models and the presence of novel capabilities from teachers.
– The study highlights practical strategies to recover failing OPD and raises concerns about the scalability of OPD to long-horizon distillation scenarios.
👉 Paper link: https://huggingface.co/papers/2604.13016

3. SPPO: Sequence-Level PPO for Long-Horizon Reasoning Tasks
🔑 Keywords: Sequence-Level PPO, Proximal Policy Optimization, Large Language Models, Chain-of-Thought, Sequence-Level Contextual Bandit
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce Sequence-Level PPO (SPPO) to address instability in long-chain reasoning tasks by reformulating the reasoning process as a Sequence-Level Contextual Bandit problem.
🛠️ Research Methods:
– The approach involves a scalable algorithm with decoupled scalar value functions to improve sample efficiency and stability by avoiding multi-sampling.
💬 Research Conclusions:
– SPPO significantly outperforms standard PPO on mathematical benchmarks and matches the performance of more computation-heavy methods while being resource-efficient.
👉 Paper link: https://huggingface.co/papers/2604.08865

4. BERT-as-a-Judge: A Robust Alternative to Lexical Methods for Efficient Reference-Based LLM Evaluation
🔑 Keywords: Large Language Model Evaluation, BERT-as-a-Judge, Generative Outputs, Semantic Correctness, Lexical Evaluation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary aim is to enhance large language model (LLM) evaluation by introducing BERT-as-a-Judge, which focuses on semantic correctness rather than rigid lexical methods, offering a more robust and scalable assessment of generative outputs.
🛠️ Research Methods:
– Conducted a large-scale empirical study involving 36 models and 15 downstream tasks to investigate the limitations of current lexical evaluation methods.
– Developed an encoder-driven approach using BERT-as-a-Judge for assessing answer correctness in reference-based generative settings with lightweight training requirements.
💬 Research Conclusions:
– BERT-as-a-Judge consistently outperforms lexical baseline methods and matches larger LLM judges’ performance, offering a balance between accuracy and computational cost.
– Released project artifacts to facilitate downstream adoption and provide practical guidance for practitioners in the field.
👉 Paper link: https://huggingface.co/papers/2604.09497

5. Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
🔑 Keywords: Nemotron 3 Super, NVFP4, LatentMoE, MTP layers, inference throughput
💡 Category: Generative Models
🌟 Research Objective:
– The key aim of the study is to enhance model efficiency and accuracy through the development of the Nemotron 3 Super, employing a novel architecture and training regime.
🛠️ Research Methods:
– The model incorporates NVFP4 for pre-training, uses the LatentMoE architecture for optimizing performance metrics, and includes MTP layers to accelerate inference.
💬 Research Conclusions:
– Nemotron 3 Super demonstrates significant improvements in inference throughput, showing up to 2.2x and 7.5x speed gains compared to existing models like GPT-OSS-120B and Qwen3.5-122B, and supports extensive context lengths while maintaining competitive accuracy.
👉 Paper link: https://huggingface.co/papers/2604.12374

6. Many-Tier Instruction Hierarchy in LLM Agents
🔑 Keywords: Large language model agents, Many-Tier Instruction Hierarchy, instruction conflict resolution
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose Many-Tier Instruction Hierarchy (ManyIH), a new paradigm for resolving instruction conflicts in large language model agents with multiple privilege levels.
🛠️ Research Methods:
– Introduction of ManyIH-Bench, the first benchmark requiring models to handle up to 12 levels of conflicting instructions, encapsulating 853 agentic tasks.
💬 Research Conclusions:
– Current leading models perform poorly (around 40% accuracy) when dealing with scaled instruction conflict, highlighting the need for improved methods targeting fine-grained and scalable instruction conflict resolution in agentic settings.
👉 Paper link: https://huggingface.co/papers/2604.09443

7. Self-Adversarial One Step Generation via Condition Shifting
🔑 Keywords: text-to-image synthesis, adversarial training, flow models, GAN aligned, LoRA
💡 Category: Generative Models
🌟 Research Objective:
– To enable efficient one-step text-to-image synthesis while overcoming adversarial training with endogenous gradient estimation from flow models.
🛠️ Research Methods:
– Utilization of regression-based distillation and consistency objectives.
– Development of APEX, leveraging condition shifting to generate GAN aligned gradients without the need for a discriminator.
💬 Research Conclusions:
– APEX demonstrates superior quality and speed compared to existing models, outperforming larger models like FLUX-Schnell 12B.
– Achieves a GenEval score of 0.89 with a significant inference speedup, proving the efficacy of the proposed approach.
👉 Paper link: https://huggingface.co/papers/2604.12322

8. Rethinking the Diffusion Model from a Langevin Perspective
🔑 Keywords: Diffusion models, Langevin perspective, VAEs, flow matching, score matching
💡 Category: Generative Models
🌟 Research Objective:
– To offer a unified Langevin perspective on diffusion models, clarifying their theoretical foundations and connections.
🛠️ Research Methods:
– The paper systematically organizes diffusion models using a simpler, clearer, and more intuitive Langevin perspective, addressing various complex questions related to diffusion models.
💬 Research Conclusions:
– The Langevin perspective provides straightforward answers to key questions, demonstrating how different mathematical formulations can be unified under a common framework, and offering valuable pedagogical insights for learners and researchers.
👉 Paper link: https://huggingface.co/papers/2604.10465

9. You Only Judge Once: Multi-response Reward Modeling in a Single Forward Pass
🔑 Keywords: Multimodal reward model, cross-entropy, N-way preference learning, speedup, reinforcement learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduction of a discriminative multimodal reward model optimizing open-ended generation tasks.
🛠️ Research Methods:
– Utilization of a multi-response design to achieve efficient N-way reward evaluation through concatenated input and cross-entropy scoring.
– Development of two new benchmarks, MR^2Bench-Image and MR^2Bench-Video, for evaluating the model’s performance.
💬 Research Conclusions:
– The proposed model displayed superior performance across multiple multimodal benchmarks compared to existing larger models.
– Incorporating the model within reinforcement learning frameworks such as GRPO led to substantial improvements in training stability and open-ended generation quality.
👉 Paper link: https://huggingface.co/papers/2604.10966

10. Accelerating Speculative Decoding with Block Diffusion Draft Trees
🔑 Keywords: Speculative Decoding, Autoregressive Language Models, Block Diffusion Drafter, Draft Tree, Best-First Heap Algorithm
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance speculative decoding by developing the DDTree method to improve the efficiency and performance of autoregressive language models.
🛠️ Research Methods:
– Construct draft trees from block diffusion drafter distributions using a best-first heap algorithm to optimize continuations.
– Verify the draft tree in a single target model forward pass with an ancestor-only attention mask.
💬 Research Conclusions:
– DDTree improves the draft verification process and places itself among leading speculative decoding methods by building upon the successes of the DFlash model.
👉 Paper link: https://huggingface.co/papers/2604.12989
11. Lightning OPD: Efficient Post-Training for Large Reasoning Models with Offline On-Policy Distillation
🔑 Keywords: On-policy distillation, teacher consistency, large language models, supervised fine-tuning, performance efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the feasibility of performing on-policy distillation offline and develop a framework to enhance efficiency by enforcing teacher consistency without live teacher inference servers.
🛠️ Research Methods:
– Propose Lightning OPD framework to precompute teacher log-probabilities over SFT rollouts, ensuring the same teacher model is used for both supervised fine-tuning and OPD.
💬 Research Conclusions:
– Lightning OPD achieves state-of-the-art performance with a 4.0x speedup over standard OPD, effectively reducing infrastructure requirements while maintaining performance parity.
👉 Paper link: https://huggingface.co/papers/2604.13010

12. Do Thought Streams Matter? Evaluating Reasoning in Gemini Vision-Language Models for Video Scene Understanding
🔑 Keywords: internal reasoning traces, video scene understanding, vision-language models, Flash Lite, compression-step hallucination
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To examine the effect of internal reasoning traces on video scene understanding in vision-language models and identify where quality improvements plateau.
🛠️ Research Methods:
– Utilized four configurations of Google’s Gemini 2.5 Flash and Flash Lite on scenes from 100 hours of video, with evaluation metrics like Contentfulness, Thought-Final Coverage, and Dominant Entity Analysis. GPT-5 was used as an independent evaluator.
💬 Research Conclusions:
– Additional reasoning leads to quality gains that plateau quickly, with significant improvement in the initial few hundred tokens. Flash Lite achieves the best quality-to-token usage balance, and reasoning constraints lead to compression-step hallucination in the model outputs.
👉 Paper link: https://huggingface.co/papers/2604.11177

13. LASA: Language-Agnostic Semantic Alignment at the Semantic Bottleneck for LLM Safety
🔑 Keywords: Language-Agnostic, Semantic Alignment, LLM Safety, Semantic Bottleneck, Safety Alignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve the safety performance of Large Language Models (LLMs) across different languages by aligning safety mechanisms with language-agnostic semantic representations.
🛠️ Research Methods:
– The study identifies a semantic bottleneck in LLMs, suggesting that their safety vulnerability is due to a bias towards high-resource languages. The proposed Language-Agnostic Semantic Alignment (LASA) targets this bottleneck to enhance cross-language safety.
💬 Research Conclusions:
– Experiments demonstrate that LASA significantly reduces the average attack success rate from 24.7% to 2.8% on selected LLM models, supporting the view that safety should be embedded in semantic space rather than surface text.
👉 Paper link: https://huggingface.co/papers/2604.12710

14. Learning Versatile Humanoid Manipulation with Touch Dreaming
🔑 Keywords: Multimodal Transformer, Humanoid Robots, Reinforcement Learning, Touch Dreaming, Proprioception
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a Humanoid Transformer with Touch Dreaming (HTD) that enhances dexterity in humanoid robots by integrating tactile sensing with visual and proprioceptive data for contact-rich tasks.
🛠️ Research Methods:
– Development of an RL-based whole-body controller for stable execution.
– Creation of a VR-based data collection system for real-world demonstrations.
– Implementation of a multimodal encoder-decoder Transformer trained with behavioral cloning and touch dreaming.
💬 Research Conclusions:
– HTD demonstrated a significant 90.9% improvement in success rate over the baseline for various tasks.
– Tactile prediction in latent space proved more effective than raw tactile prediction, leading to a 30% boost in success rates.
– The study illustrates the capabilities of integrated data for high-dexterity humanoid manipulation in real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2604.13015

15. Domain-Specific Latent Representations Improve the Fidelity of Diffusion-Based Medical Image Super-Resolution
🔑 Keywords: Domain-specific autoencoders, Medical image super-resolution, Latent diffusion models, MedVAE, AI-generated summary
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research aims to replace generic variational autoencoders with domain-specific autoencoders to improve the quality of medical image super-resolution.
🛠️ Research Methods:
– Conducted controlled experiments with latent diffusion models, holding pipeline components constant while replacing Stable Diffusion VAE with domain-specific MedVAE.
💬 Research Conclusions:
– Replacing generic VAEs with MedVAE results in a significant PSNR improvement in medical image super-resolution. This approach improves reconstruction fidelity and predicts downstream super-resolution performance, demonstrating that domain-specific VAE selection is crucial.
👉 Paper link: https://huggingface.co/papers/2604.12152

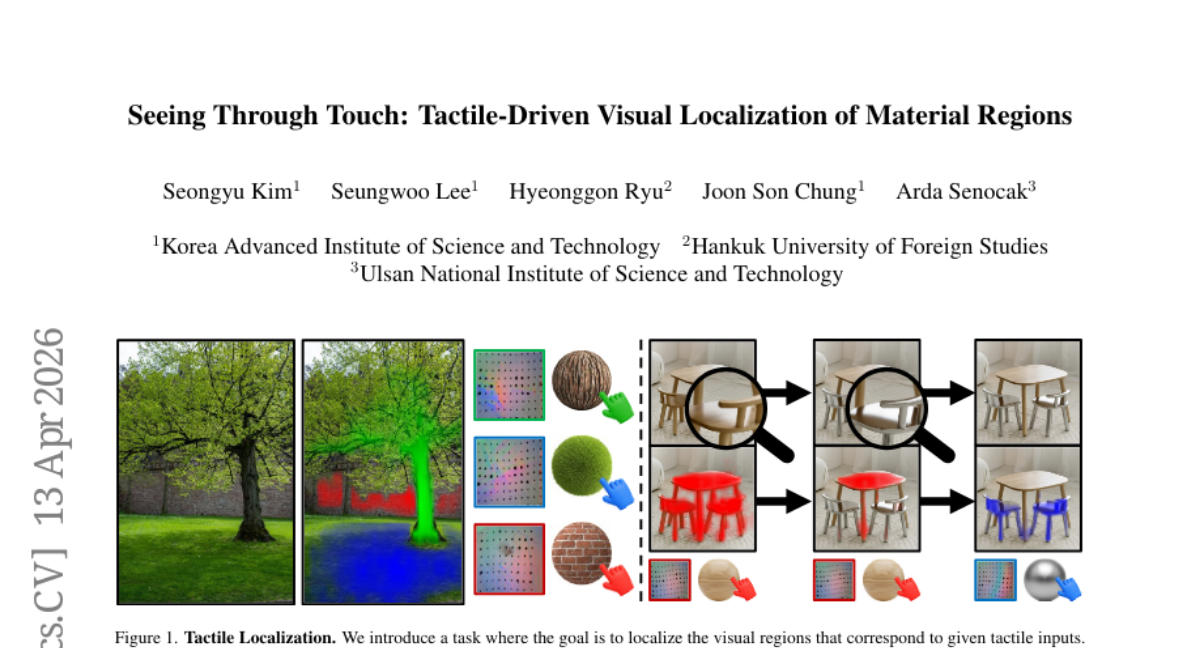
16. Seeing Through Touch: Tactile-Driven Visual Localization of Material Regions
🔑 Keywords: Tactile Localization, Dense Cross-Modal Feature Interactions, Material Segmentation, Visuo-Tactile Methods, Tactile Saliency Maps
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance tactile localization by identifying image regions sharing the same material properties as a tactile input, addressing limitations of existing visuo-tactile methods through improved datasets and material diversification strategies.
🛠️ Research Methods:
– A new model employing dense cross-modal feature interactions to create tactile saliency maps for touch-conditioned material segmentation is proposed. The research further introduces augmented datasets including in-the-wild multi-material scene images and a material-diversity pairing strategy to improve localization accuracy.
💬 Research Conclusions:
– Experimental results demonstrate that the proposed method significantly outperforms prior visuo-tactile methods in achieving precise tactile localization.
👉 Paper link: https://huggingface.co/papers/2604.11579
17. PokeRL: Reinforcement Learning for Pokemon Red
🔑 Keywords: PokeRL, Reinforcement Learning, PPO, Environment Wrapper, Hierarchical Reward
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a modular reinforcement learning system named PokeRL for training agents on early-game tasks in Pokemon Red.
🛠️ Research Methods:
– Utilization of a loop-aware environment wrapper in the PyBoy emulator with map masking.
– Implementation of a multi-layer anti-loop and anti-spam mechanism.
– Design of a dense hierarchical reward system.
💬 Research Conclusions:
– Practical systems like PokeRL are essential for modeling failure modes such as loops and spam, serving as an intermediate step between toy benchmarks and full-fledged Pokemon League champion agents.
👉 Paper link: https://huggingface.co/papers/2604.10812

18. Spatial Competence Benchmark
🔑 Keywords: Spatial Competence, Internal Representation, Discrete Structure, Deterministic Checkers, Simulator-Based Evaluators
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to evaluate the spatial competence of large AI models using a new benchmark called the Spatial Competence Benchmark (SCBench), focusing on tasks requiring executable outputs that are verified by deterministic checkers or simulator-based evaluators.
🛠️ Research Methods:
– The researchers introduced SCBench, which assesses models through a hierarchical capability structure, examining performance under varying token budget constraints and analyzing the accuracy at different hierarchical levels.
💬 Research Conclusions:
– The study found that the accuracy of the three frontier models decreases monotonically up the capability ladder on SCBench. Additionally, it was observed that accuracy increases are concentrated at low token budgets and quickly saturate, with failures mostly due to locally plausible geometries that violate global constraints.
👉 Paper link: https://huggingface.co/papers/2604.09594

19. CONSCIENTIA: Can LLM Agents Learn to Strategize? Emergent Deception and Trust in a Multi-Agent NYC Simulation
🔑 Keywords: large language models, strategic behavior, multi-agent simulation, policy learning, adversarial persuasion
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To understand how strategic behavior emerges in multi-agent environments, particularly in LLM-driven agents within a simulated urban setting.
🛠️ Research Methods:
– Constructing a large-scale multi-agent simulation in a simplified model of New York City to observe strategic interactions under opposing incentives.
– Utilizing Kahneman-Tversky Optimization to iteratively optimize agent policies across multiple interaction rounds.
💬 Research Conclusions:
– LLM agents demonstrate limited strategic behaviors like selective trust and deception but remain vulnerable to adversarial persuasion.
– Improvements in the task success rate of Blue agents from 46.0% to 57.3% were observed, although susceptibility to adversarial influence remains significant.
👉 Paper link: https://huggingface.co/papers/2604.09746

20.

21. SpotSound: Enhancing Large Audio-Language Models with Fine-Grained Temporal Grounding
🔑 Keywords: SpotSound, Audio Language Model, Temporal Grounding, Hallucinated Timestamps, SpotSound-Bench
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve temporal grounding in long-form audio by introducing SpotSound, an audio language model that reduces false timestamps and addresses issues caused by sparse events in noisy environments.
🛠️ Research Methods:
– Developed a novel training objective for SpotSound to suppress hallucinated timestamps for absent events.
– Introduced SpotSound-Bench, a rigorous benchmark for evaluating temporal grounding where target events are less than ~10% of each audio clip.
💬 Research Conclusions:
– SpotSound achieves state-of-the-art results in temporal grounding benchmarks while maintaining strong performance in general downstream audio-language tasks.
– The code, models, and benchmark are publicly available for further research and application.
👉 Paper link: https://huggingface.co/papers/2604.13023

22. When Reasoning Models Hurt Behavioral Simulation: A Solver-Sampler Mismatch in Multi-Agent LLM Negotiation
🔑 Keywords: Reasoning-enhanced models, bounded rational behavior, simulation fidelity, bounded reflection, multi-agent negotiation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper investigates the appropriateness of reasoning-enhanced large language models for simulating boundedly rational behavior, specifically in social, economic, and policy simulations.
🛠️ Research Methods:
– The authors study three multi-agent negotiation environments: a fragmented-authority trading-limits scenario, a unified-opposition trading-limits scenario, and a grid-curtailment case in emergency electricity management.
– They assess different reflection conditions (no reflection, bounded reflection, native reasoning) across primary model families and extend these methodologies to OpenAI’s GPT-4.1 and GPT-5.2.
💬 Research Conclusions:
– The study reveals that bounded reflection provides more diverse and compromise-oriented outcomes compared to no reflection or native reasoning.
– It highlights the distinction between model capability and simulation fidelity, advocating for behavioral simulations to qualify models more as samplers rather than solely solvers.
👉 Paper link: https://huggingface.co/papers/2604.11840

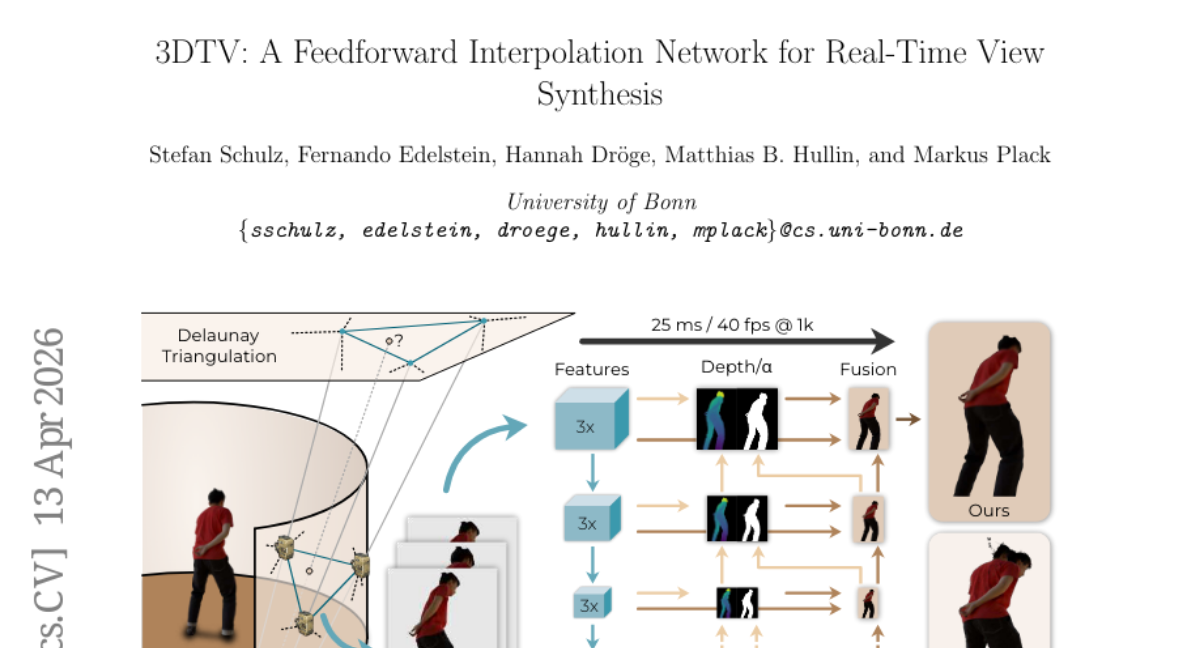
23. 3DTV: A Feedforward Interpolation Network for Real-Time View Synthesis
🔑 Keywords: 3DTV, sparse-view interpolation, feedforward network, occlusion-aware blending, real-time rendering
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to develop 3DTV, a feedforward network for real-time sparse-view interpolation that merges lightweight geometry with learning to achieve efficient multi-view rendering without scene-specific optimization.
🛠️ Research Methods:
– Utilize a Delaunay-based triplet selection for angular coverage.
– Introduce a pose-aware depth module to estimate a coarse-to-fine depth pyramid for feature reprojection and occlusion-aware blending.
💬 Research Conclusions:
– 3DTV consistently outperforms recent real-time novel-view baselines in quality and efficiency.
– It offers robust rendering across diverse scenes without explicit proxies, making it suitable for low-latency multi-view streaming and interactive rendering applications like AR/VR and telepresence.
👉 Paper link: https://huggingface.co/papers/2604.11211
24. Beyond Perception Errors: Semantic Fixation in Large Vision-Language Models
🔑 Keywords: Vision-language models, semantic fixation, controlled benchmark, prompt interventions, joint-rule training
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper investigates semantic fixation in Vision-language models, where default interpretations are preferred over alternative valid rule mappings.
🛠️ Research Methods:
– A controlled benchmark called VLM-Fix was introduced to evaluate standard and inverse rule formulations in abstract strategy games. Prompt interventions and post-training evaluations were used to measure and adjust semantic fixation behaviors.
💬 Research Conclusions:
– Findings reveal a consistent preference for standard rules in models, with prompt interventions partially mitigating the fixation. Joint-rule training improves transfer capabilities, and late-layer activation steering can edit semantic-fixation errors.
👉 Paper link: https://huggingface.co/papers/2604.12119

25. Hierarchical SVG Tokenization: Learning Compact Visual Programs for Scalable Vector Graphics Modeling
🔑 Keywords: Hierarchical SVG Tokenization, Autoregressive Vector Graphics Generation, Spatial Consistency, AI-generated Summary, Sequence Efficiency
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces HiVG, a framework aiming to enhance autoregressive vector graphics generation by addressing issues in geometric structure representation and spatial consistency.
🛠️ Research Methods:
– HiVG introduces a hierarchical SVG tokenization framework using atomic and segment tokens, along with a Hierarchical Mean–Noise initialization strategy and curriculum training to improve token embedding and learning of SVG programs.
💬 Research Conclusions:
– Extensive experiments on both text-to-SVG and image-to-SVG tasks show that HiVG improves generation fidelity, spatial consistency, and sequence efficiency compared to conventional tokenization methods.
👉 Paper link: https://huggingface.co/papers/2604.05072

26. VideoFlexTok: Flexible-Length Coarse-to-Fine Video Tokenization
🔑 Keywords: VideoFlexTok, video representation, variable-length sequence, generative flow decoder, video generation
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces VideoFlexTok, a novel method for efficient video representation using variable-length token sequences that capture both abstract and fine-grained details.
🛠️ Research Methods:
– The research evaluates VideoFlexTok on class- and text-to-video generative tasks, utilizing a generative flow decoder for video reconstruction to reduce computational cost while maintaining video quality.
💬 Research Conclusions:
– VideoFlexTok achieves similar generation quality with significantly reduced model size and token count compared to traditional 3D grid tokenizers, allowing for longer video generation with fewer resources.
👉 Paper link: https://huggingface.co/papers/2604.12887
27. Parcae: Scaling Laws For Stable Looped Language Models
🔑 Keywords: Parcae, looped architectures, spectral norm, scaling laws, Transformer
💡 Category: Machine Learning
🌟 Research Objective:
– The objective is to address instability in looped architectures by proposing a new stable architecture named Parcae, which constrains spectral norms to enhance model scaling and quality.
🛠️ Research Methods:
– The research redefines looping as a nonlinear time-variant dynamical system. By linear approximation and spectral norm constraints through a negative diagonal parameterization, the instability issues are tackled in looped architectures.
💬 Research Conclusions:
– Parcae offers improved stability and scaling, achieving lower validation perplexity and enhanced quality in comparison to traditional models. It shows effectiveness when scaled, improving quality by significant margins against standard Transformer baselines.
👉 Paper link: https://huggingface.co/papers/2604.12946

28. GlotOCR Bench: OCR Models Still Struggle Beyond a Handful of Unicode Scripts
🔑 Keywords: Vision-language models, GlotOCR Bench, OCR systems, Unicode scripts, pretraining coverage
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to evaluate OCR generalization across over 100 Unicode scripts using the newly introduced GlotOCR Bench.
🛠️ Research Methods:
– The benchmark involved rendering images from real multilingual texts using Google Fonts, HarfBuzz shaping, and FreeType rasterization, covering LTR and RTL scripts. The rendered images were manually reviewed for accuracy.
💬 Research Conclusions:
– Vision-language models show limited generalization, performing well on fewer than ten scripts and failing for scripts beyond thirty. The performance of OCR systems is closely linked to script-level pretraining coverage, with unfamiliar scripts leading to random noise or incorrect character generation.
👉 Paper link: https://huggingface.co/papers/2604.12978

29. Masked by Consensus: Disentangling Privileged Knowledge in LLM Correctness
🔑 Keywords: Large Language Models, Self-awareness, Factual Knowledge, Correctness Classifiers, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate if Large Language Models possess privileged knowledge about answer correctness through self-representations.
🛠️ Research Methods:
– Trained correctness classifiers using question representations from both a model’s hidden states and external models, especially focusing on disagreement subsets.
💬 Research Conclusions:
– Self-representations show domain-specific advantages in factual knowledge tasks but not in math reasoning; the advantage emerges from early-to-mid model layers.
👉 Paper link: https://huggingface.co/papers/2604.12373

30. Generative Refinement Networks for Visual Synthesis
🔑 Keywords: Generative Refinement Networks, Hierarchical Binary Quantization, image generation, entropy-guided sampling
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Generative Refinement Networks (GRN) to improve computational efficiency and visual quality in image generation.
🛠️ Research Methods:
– Utilize Hierarchical Binary Quantization (HBQ) for near-lossless discrete tokenization and integrate entropy-guided sampling for complexity-aware, adaptive-step generation.
💬 Research Conclusions:
– GRN sets new records in image reconstruction and class-conditional image generation on the ImageNet benchmark and exhibits superior performance in text-to-image and text-to-video generation.
👉 Paper link: https://huggingface.co/papers/2604.13030

31. LARY: A Latent Action Representation Yielding Benchmark for Generalizable Vision-to-Action Alignment
🔑 Keywords: Latent Action Representation, Visual Foundation Models, Action Supervision, Physical Control, Semantic-Level Abstraction
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce the LARY Benchmark to evaluate the effectiveness of Latent Action Representation in converting visual signals into ontology-independent forms for robust control in vision-to-action tasks.
🛠️ Research Methods:
– Compilation of a large-scale dataset including over one million videos, 151 action categories, 620K image pairs, and 595K motion trajectories to test visual and action space alignment.
💬 Research Conclusions:
– General visual foundation models surpass specialized embodied models without needing action supervision and show better alignment between visual and physical action spaces compared to pixel-based methods.
– Semantic-level abstraction provides a more efficient and effective pathway from vision to action than pixel-level reconstruction.
👉 Paper link: https://huggingface.co/papers/2604.11689

32. The Blind Spot of Agent Safety: How Benign User Instructions Expose Critical Vulnerabilities in Computer-Use Agents
🔑 Keywords: AI Safety, OS-BLIND, Multi-Agent Systems, Attack Success Rate, Safety Alignment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate the safety vulnerabilities of Computer-use Agents (CUAs) under conditions where benign instructions cause harmful outcomes through contextual or execution-based risks.
🛠️ Research Methods:
– Introduction of OS-BLIND, a benchmark consisting of 300 human-crafted tasks across 12 categories and 8 applications, designed to test CUAs under unintended attack conditions. Evaluation included frontier models and agentic frameworks focusing on environment-embedded threats and agent-initiated harms.
💬 Research Conclusions:
– CUAs exhibit a high attack success rate (ASR), exceeding 90%, even with safety-aligned models under benign instructions. Multi-agent systems increase vulnerability, with ASR rising significantly when safety-aligned models are deployed. Existing safety defenses provide limited protection, highlighting the need for improved safety measures.
👉 Paper link: https://huggingface.co/papers/2604.10577

33. Habitat-GS: A High-Fidelity Navigation Simulator with Dynamic Gaussian Splatting
🔑 Keywords: Embodied AI, 3D Gaussian Splatting, Gaussian Avatars, Photorealistic Rendering, Human-Aware Navigation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aimed to enhance agent generalization and human-aware navigation in Embodied AI through the integration of 3D Gaussian Splatting and Gaussian Avatars into Habitat-Sim.
🛠️ Research Methods:
– The researchers implemented a 3DGS renderer for real-time photorealistic rendering and introduced a Gaussian avatar module for dynamic human modeling, facilitating agents to learn in realistic settings.
💬 Research Conclusions:
– Experiments demonstrated that 3DGS scenes improve cross-domain generalization in point-goal navigation tasks. Modeling with Gaussian avatars led to effective human-aware navigation. The system’s scalability was validated across varying scene complexities.
👉 Paper link: https://huggingface.co/papers/2604.12626
34. Towards Long-horizon Agentic Multimodal Search
🔑 Keywords: LMM-Searcher, multimodal deep search, file-based visual representation, cross-modal multi-hop reasoning, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce LMM-Searcher, a framework to address heterogeneous information and high token costs in long-horizon multimodal deep search.
🛠️ Research Methods:
– Utilization of a file-based visual representation mechanism and lightweight textual identifiers to manage visual assets.
– Development of a progressive visual loading strategy using a tailored fetch-image tool for active perception.
💬 Research Conclusions:
– The LMM-Searcher framework effectively handles long-horizon multimodal searches, achieving state-of-the-art performance on benchmarks and demonstrating strong generalizability.
👉 Paper link: https://huggingface.co/papers/2604.12890

35. Lyra 2.0: Explorable Generative 3D Worlds
🔑 Keywords: 3D scene creation, video generation, spatial forgetting, temporal drifting, generative reconstruction
💡 Category: Generative Models
🌟 Research Objective:
– To enable large-scale 3D scene creation through persistent video generation that addresses spatial forgetting and temporal drifting in long-horizon video models.
🛠️ Research Methods:
– Employs a generative reconstruction approach combining video models with 3D outputs and trains with self-augmented histories to correct temporal drift.
– Maintains per-frame 3D geometry for information routing and establishes dense correspondences for addressing spatial forgetting.
💬 Research Conclusions:
– Lyra 2.0 can generate persistent, explorable 3D worlds at scale and supports substantially longer and 3D-consistent video trajectories, improving the reliability of high-quality 3D scene recovery.
👉 Paper link: https://huggingface.co/papers/2604.13036

36. Toward Autonomous Long-Horizon Engineering for ML Research
🔑 Keywords: AiScientist, Autonomous AI research, Long-horizon ML research engineering, Durable state continuity, Hierarchical orchestration
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to enhance long-horizon machine learning research engineering by introducing AiScientist, which focuses on structured coordination and durable state management to improve performance on benchmark tasks.
🛠️ Research Methods:
– AiScientist integrates hierarchical orchestration with a File-as-Bus workspace, allowing a top-level Orchestrator to maintain control while specialized agents leverage durable artifacts like analyses and code to drive progress over extended periods.
💬 Research Conclusions:
– AiScientist outperforms existing benchmarks, improving scores on PaperBench and MLE-Bench Lite, demonstrating that effective long-horizon ML research engineering requires coordinated efforts over durable project states.
👉 Paper link: https://huggingface.co/papers/2604.13018

37. Turing Test on Screen: A Benchmark for Mobile GUI Agent Humanization
🔑 Keywords: humanization capabilities, autonomous GUI agents, Turing Test on Screen, behavioral divergence, imitability
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To propose humanization capabilities for autonomous GUI agents to avoid detection by digital platforms and to establish a benchmark to balance imitability with task performance.
🛠️ Research Methods:
– Introduced the “Turing Test on Screen” modeled as a MinMax optimization problem between detector and agent.
– Collected a high-fidelity dataset of mobile touch dynamics and analyzed vanilla LMM-based agents for detectability.
– Established the Agent Humanization Benchmark (AHB) and detection metrics to quantify the trade-off between imitability and utility.
💬 Research Conclusions:
– Demonstrated methods ranging from heuristic noise to data-driven behavioral matching to enable agents to achieve high imitability theoretically and empirically without compromising performance.
– Shifted focus towards agent behavior within human-centric ecosystems for seamless coexistence in adversarial digital environments.
👉 Paper link: https://huggingface.co/papers/2604.09574

38. KnowRL: Boosting LLM Reasoning via Reinforcement Learning with Minimal-Sufficient Knowledge Guidance
🔑 Keywords: Knowledge-Guided Reinforcement Learning, Atomic Knowledge Points, Constrained Subset Search, Pruning Interaction Paradox
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance reasoning in language models through a knowledge-guided reinforcement learning framework, focusing on compact and efficient guidance subsets.
🛠️ Research Methods:
– Employ Constrained Subset Search to create interaction-aware guidance subsets, identifying and optimizing for pruning interaction paradoxes in training.
💬 Research Conclusions:
– KnowRL-Nemotron-1.5B significantly outperforms existing RL and hint-based models, achieving state-of-the-art performance on reasoning benchmarks at the 1.5B parameter scale.
👉 Paper link: https://huggingface.co/papers/2604.12627
