AI Native Daily Paper Digest – 20260417
1. HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
🔑 Keywords: HY-World 2.0, multi-modal world model, 3D world representations, 3D Gaussian Splatting, interactive exploration
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce HY-World 2.0, which generates high-fidelity 3D Gaussian Splatting scenes from diverse input modalities such as text prompts and images.
🛠️ Research Methods:
– Implementing a four-stage approach including Panorama Generation, Trajectory Planning, World Expansion, and World Composition.
– Introducing innovations to improve panorama fidelity, scene understanding, and model architecture for enhanced 3D prediction.
💬 Research Conclusions:
– HY-World 2.0 achieves state-of-the-art performance on several benchmarks and offers results comparable to closed-source models.
– The release of model weights, code, and technical details supports reproducibility and further research in 3D world modeling.
👉 Paper link: https://huggingface.co/papers/2604.14268
2. ASGuard: Activation-Scaling Guard to Mitigate Targeted Jailbreaking Attack
🔑 Keywords: Activation-Scaling Guard, Large Language Models, Jailbreaking, Attention Heads, Fine-Tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To mitigate brittle refusal behaviors in Large Language Models (LLMs) by addressing vulnerabilities to tense-based jailbreaking attacks.
🛠️ Research Methods:
– Employed circuit analysis to identify attention heads linked to jailbreaking.
– Trained channel-wise scaling vectors to recalibrate tense-vulnerable heads.
– Implemented preventative fine-tuning for enhanced refusal mechanisms.
💬 Research Conclusions:
– ASGuard reduces the success rate of targeted jailbreaking attacks while maintaining model utility.
– The approach demonstrates how understanding model internals can lead to more interpretable and reliable AI safety solutions.
👉 Paper link: https://huggingface.co/papers/2509.25843

3. DR^{3}-Eval: Towards Realistic and Reproducible Deep Research Evaluation
🔑 Keywords: Deep Research Agents, Multimodal Understanding, Report Generation, Multi-Dimensional Evaluation Framework, Hallucination Control
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To propose DR$^{3}$-Eval, a benchmark for evaluating deep research agents on multimodal, multi-file report generation, simulating real-world web environments.
🛠️ Research Methods:
– Constructed from authentic user-provided materials and paired with a static research sandbox corpus.
– Introduce a multi-dimensional evaluation framework measuring various aspects like Information Recall and Factual Accuracy.
💬 Research Conclusions:
– DR$^{3}$-Eval is a challenging benchmark that reveals critical failure modes in retrieval robustness and hallucination control.
– Validation of the framework shows alignment with human judgments.
– Experiments demonstrate the benchmark’s applicability and difficulty in evaluating state-of-the-art language models.
👉 Paper link: https://huggingface.co/papers/2604.14683

4. GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
🔑 Keywords: Global Scene Representation, 3D Gaussian Splatting, Representation Compactness, Novel-view Synthesis, Coarse-to-fine Training
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces GlobalSplat, a framework for achieving compact and consistent 3D Gaussian splatting with improved computational efficiency and reduced overhead.
🛠️ Research Methods:
– GlobalSplat employs a strategy of “align first, decode later” to create a global latent scene representation. It uses a coarse-to-fine training approach to efficiently manage decoded capacity and prevent representation bloat.
💬 Research Conclusions:
– GlobalSplat generates compact, globally consistent reconstructions without relying on pretrained pixel-prediction backbones, showing competitive novel-view synthesis performance on datasets like RealEstate10K and ACID with significantly fewer resources compared to dense pipelines.
👉 Paper link: https://huggingface.co/papers/2604.15284

5. Switch-KD: Visual-Switch Knowledge Distillation for Vision-Language Models
🔑 Keywords: Vision-Language Models, Knowledge Distillation, multimodal alignment, multimodal knowledge transfer, Visual-Switch Distillation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose a novel visual-switch framework, Switch-KD, that enhances multimodal knowledge transfer in Vision-Language Models (VLMs) by efficiently applying knowledge distillation despite deployment challenges.
🛠️ Research Methods:
– Introduction of Switch-KD, comprising Visual-Switch Distillation to integrate visual outputs into language pathways and Dynamic Bi-directional Logits Difference (DBiLD) loss for adaptive, bidirectional supervision that aligns informative probability regions.
💬 Research Conclusions:
– Switch-KD enables a 0.5B TinyLLaVA to effectively distill rich multimodal knowledge from a larger 3B teacher, resulting in an average improvement of 3.6 points across 10 multimodal benchmarks without architectural changes.
👉 Paper link: https://huggingface.co/papers/2604.14629

6. Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems
🔑 Keywords: Claude Code, AI-generated summary, human values, architectural design, design principles
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to analyze the Claude Code’s architecture, focusing on identifying motivating human values and tracing them through design principles to specific implementation choices.
🛠️ Research Methods:
– The research method includes analyzing the publicly available TypeScript source code of Claude Code and comparing it with OpenClaw to understand different architectural responses based on deployment contexts.
💬 Research Conclusions:
– The study concludes by identifying motivating human values and corresponding architectural designs in Claude Code and OpenClaw. It emphasizes different architectural solutions like the while-loop core system, permission system, context management, and extensibility mechanisms. The paper also highlights open design directions for future agent systems based on recent empirical research.
👉 Paper link: https://huggingface.co/papers/2604.14228

7. Boosting Visual Instruction Tuning with Self-Supervised Guidance
🔑 Keywords: Visual instruction tuning, Vision-centric reasoning, Multimodal language models, Self-supervised tasks, Instruction tuning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The aim is to enhance vision-centric reasoning in multimodal language models using visual instruction tuning with naturally phrased self-supervised tasks.
🛠️ Research Methods:
– The researchers propose augmenting visual instruction tuning by reformulating classical self-supervised pretext tasks into image-instruction-response triplets without requiring human annotations or additional training stages.
💬 Research Conclusions:
– The study demonstrates that incorporating a small fraction (3-10%) of visually grounded instructions significantly improves performance on vision-centric evaluations across multiple models and benchmarks.
👉 Paper link: https://huggingface.co/papers/2604.12966

8. LongAct: Harnessing Intrinsic Activation Patterns for Long-Context Reinforcement Learning
🔑 Keywords: LongAct, Long-context reasoning, Sparse updates, Reinforcement Learning, Large Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to enhance the reasoning capabilities of Large Language Models (LLMs) by implementing a new strategy for long-context reasoning using saliency-guided sparse updates.
🛠️ Research Methods:
– By observing high-magnitude activations in query and key vectors, the study leverages insights from model quantization. The approach focuses on shifting from uniform updates to saliency-guided sparse updates to optimize model performance.
💬 Research Conclusions:
– LongAct achieves approximately 8% improvement on LongBench v2 and enhances generalization across diverse Reinforcement Learning algorithms, suggesting the effectiveness of focusing on high-magnitude activations for long-context reasoning.
👉 Paper link: https://huggingface.co/papers/2604.14922

9. RadAgent: A tool-using AI agent for stepwise interpretation of chest computed tomography
🔑 Keywords: RadAgent, Vision-language models, Clinical accuracy, Robustness, Reasoning trace
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to introduce RadAgent, a tool-using AI agent, to enhance the generation of chest CT reports through an interpretable, step-by-step reasoning approach.
🛠️ Research Methods:
– RadAgent is compared to the existing 3D vision-language model CT-Chat, focusing on clinical accuracy, robustness under adversarial conditions, and the new capability of faithfulness in reporting.
💬 Research Conclusions:
– RadAgent improves chest CT report generation by offering a fully inspectable intermediate decision trace, resulting in a 6.0-point improvement in macro-F1 and 5.4-point improvement in micro-F1 for clinical accuracy, a 24.7-point improvement in robustness, and a 37.0% achievement in faithfulness.
👉 Paper link: https://huggingface.co/papers/2604.15231

10. MM-WebAgent: A Hierarchical Multimodal Web Agent for Webpage Generation
🔑 Keywords: MM-WebAgent, AIGC, multimodal webpage generation, hierarchical agentic framework, iterative self-reflection
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to propose MM-WebAgent, a hierarchical agentic framework designed to coordinate AIGC-based element generation for creating visually coherent webpages with consistent style and improved global coherence.
🛠️ Research Methods:
– The framework employs hierarchical planning and iterative self-reflection to jointly optimize global layout, local multimodal content, and their integration.
– Additionally, the research introduces a benchmark for multimodal webpage generation and develops a multi-level evaluation protocol for systematic assessment.
💬 Research Conclusions:
– Experiments demonstrate that MM-WebAgent significantly outperforms existing code-generation and agent-based baselines, mainly in terms of multimodal element generation and integration.
👉 Paper link: https://huggingface.co/papers/2604.15309

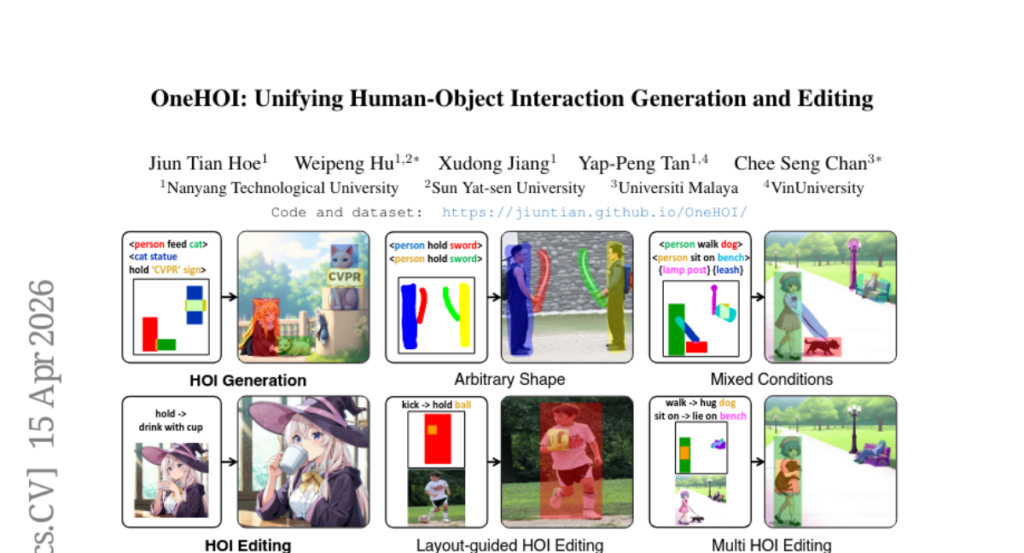
11. OneHOI: Unifying Human-Object Interaction Generation and Editing
🔑 Keywords: Human-Object Interaction, Unified Diffusion Transformer, Relational Diffusion Transformer, Structured HOI Attention, AI-Generated Summary
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to introduce OneHOI, a unified diffusion transformer framework for Human-Object Interaction (HOI) generation and editing.
🛠️ Research Methods:
– Utilizes relational modeling and structured attention mechanisms, incorporating role- and instance-aware HOI tokens, layout-based spatial Action Grounding, and Structured HOI Attention.
💬 Research Conclusions:
– OneHOI achieves state-of-the-art results in both HOI generation and editing by consolidating multiple functionalities into a single cohesive process, supporting various conditions like layout-guided and mixed-condition control.
👉 Paper link: https://huggingface.co/papers/2604.14062
12. KV Packet: Recomputation-Free Context-Independent KV Caching for LLMs
🔑 Keywords: KV Packet, Large Language Models, caching, soft-token adapters, recomputation-free
💡 Category: Natural Language Processing
🌟 Research Objective:
– The aim is to eliminate the recomputation overhead in large language models by treating cached documents as immutable packets with trainable soft-token adapters.
🛠️ Research Methods:
– The method involves using a recomputation-free cache reuse framework with soft-token adapters trained via self-supervised distillation to address context discontinuities.
💬 Research Conclusions:
– KV Packet achieves near-zero FLOPs and lower Time-to-First-Token latency while maintaining F1 scores comparable to full recomputation baselines.
👉 Paper link: https://huggingface.co/papers/2604.13226

13. Towards Autonomous Mechanistic Reasoning in Virtual Cells
🔑 Keywords: Large language models, multi-agent framework, mechanistic reasoning, biologically grounded knowledge retrieval, VC-TRACES dataset
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to enhance large language models for biological research through a new multi-agent framework capable of generating and validating mechanistic explanations.
🛠️ Research Methods:
– Introduction of a structured explanation formalism for virtual cells that utilizes mechanistic action graphs.
– Development of VCR-Agent, a multi-agent framework integrating biologically grounded knowledge retrieval with verifier-based filtering to autonomously generate and validate mechanistic reasoning.
💬 Research Conclusions:
– The research demonstrates that training with verified explanations from the VC-TRACES dataset improves factual precision and provides better supervision for downstream gene expression prediction, highlighting the importance of reliable mechanistic reasoning for virtual cells.
👉 Paper link: https://huggingface.co/papers/2604.11661

14. C2: Scalable Rubric-Augmented Reward Modeling from Binary Preferences
🔑 Keywords: Cooperative Communication, Reward Model, Rubric Generation, Binary Preferences
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to improve reward model reliability through Cooperative yet Critical reward modeling (C2), which facilitates critical collaboration between a reward model and a rubric generator trained solely from binary preferences.
🛠️ Research Methods:
– The researchers employed a framework where the reward model collaborates with a rubric generator, creating contrastive rubric pairs to test influence on reward model decisions and ensuring only helpful rubrics are followed during inference.
💬 Research Conclusions:
– C2 significantly enhances reward model judgments, improving performance metrics like RM-Bench scores and length-controlled win rates on tests such as AlpacaEval 2.0, all without needing costly rubric annotations.
👉 Paper link: https://huggingface.co/papers/2604.13618

15. Model Capability Dominates: Inference-Time Optimization Lessons from AIMO 3
🔑 Keywords: Majority voting, mathematical reasoning, correlated errors, reasoning strategies, model capability
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore the impact of majority voting, diverse reasoning strategies, and model capability on mathematical reasoning.
🛠️ Research Methods:
– Tested the Diverse Prompt Mixer approach on the AIMO 3 competition involving 3 models and 23+ experiments over 50 IMO-level problems using one H100 80 GB, and a 5-hour limit.
💬 Research Conclusions:
– Diverse reasoning strategies are more impactful than prompt engineering.
– Correlated errors limit the effectiveness of majority voting in improving mathematical reasoning.
– Model capability is more dominant over prompt-level interventions in closing the gap, with the current majority-vote score affected by selection loss, not prompt loss.
👉 Paper link: https://huggingface.co/papers/2603.27844

16.

17. Three-Phase Transformer
🔑 Keywords: Three-Phase Transformer, decoder-only Transformers, self-stabilizing equilibrium, parameter-sharing knob, absolute-position side-channel
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce the Three-Phase Transformer (3PT) to enhance decoder-only Transformers with channel partitioning and phase-respecting operations for improved training stability and convergence.
🛠️ Research Methods:
– Implement a structural prior using cyclic channels, RMSNorm, Givens rotation, and a Gabriel’s horn profile to achieve an orthogonal composition with RoPE, and explore N variable as a parameter-sharing tool.
💬 Research Conclusions:
– 3PT achieves superior performance with a significant perplexity reduction and faster convergence compared to baseline models, demonstrating its potential as an efficient mechanism for neural network stability and performance optimization.
👉 Paper link: https://huggingface.co/papers/2604.14430

18. An Optimal Transport-driven Approach for Cultivating Latent Space in Online Incremental Learning
🔑 Keywords: Online Incremental Learning, Distributional Shifts, Mixture Model, Optimal Transport Theory, Catastrophic Forgetting
💡 Category: Machine Learning
🌟 Research Objective:
– The study introduces an Online Mixture Model learning framework based on Optimal Transport theory to tackle incremental learning challenges caused by distributional shifts, enhancing centroid updates and class similarity estimation.
🛠️ Research Methods:
– Utilizes an Online Mixture Model framework where centroids evolve incrementally with new data. A Dynamic Preservation strategy is designed to regulate the latent space and maintain class separability over time.
💬 Research Conclusions:
– The proposed method provides precise characterization of complex data streams, improves class similarity estimation for unseen samples, and mitigates catastrophic forgetting, demonstrating superior effectiveness in experimental evaluations.
👉 Paper link: https://huggingface.co/papers/2211.16780

19. Reinforcement Learning via Value Gradient Flow
🔑 Keywords: Value Gradient Flow, behavior-regularized reinforcement learning, optimal transport problem, adaptive test-time scaling, value gradients
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces a scalable method for behavior-regularized reinforcement learning called Value Gradient Flow (VGF), aiming to address the challenge of value over-optimization in offline and LLM RL benchmarks.
🛠️ Research Methods:
– VGF is formulated as an optimal transport problem solved via discrete gradient flow, where value gradients guide particles from a reference distribution to the optimal policy distribution.
💬 Research Conclusions:
– VGF demonstrates state-of-the-art performance, outperforming previous methods on benchmarks such as D4RL, OGBench, and achieving effective results on LLM RL tasks. The approach supports adaptive test-time scaling by managing the transport budget.
👉 Paper link: https://huggingface.co/papers/2604.14265

20. SuperLocalMemory V3.3: The Living Brain — Biologically-Inspired Forgetting, Cognitive Quantization, and Multi-Channel Retrieval for Zero-LLM Agent Memory
Systems
🔑 Keywords: Local-first agent memory, Cognitive memory processes, Zero-LLM, SuperLocalMemory V3.3, Fisher-Rao Quantization-Aware Distance
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a local-first agent memory system, SuperLocalMemory V3.3, implementing comprehensive cognitive memory processes with advanced retrieval and forgetting mechanisms.
🛠️ Research Methods:
– Introduced Fisher-Rao Quantization-Aware Distance (FRQAD), Ebbinghaus Adaptive Forgetting, 7-channel cognitive retrieval, memory parameterization, and a zero-friction auto-cognitive pipeline.
💬 Research Conclusions:
– Achieved superior memory performance in zero-LLM settings and set new benchmarks in cognitive retrieval, forgetting mechanisms, and memory lifecycle automation, with open-source availability and CPU operation.
👉 Paper link: https://huggingface.co/papers/2604.04514
21. Cross-Tokenizer LLM Distillation through a Byte-Level Interface
🔑 Keywords: Byte-Level Distillation, Cross-tokenizer knowledge transfer, Byte level
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the unsolved problem of Cross-tokenizer distillation by proposing a simple baseline method called Byte-Level Distillation (BLD).
🛠️ Research Methods:
– Byte-Level Distillation operates at the byte level, converting the teacher’s output distribution to byte-level probabilities and attaching a byte-level decoder head to the student model.
💬 Research Conclusions:
– Despite its simplicity, Byte-Level Distillation performs competitively, occasionally surpassing complex existing methods across various model sizes and distillation tasks, highlighting byte level as a promising common ground for cross-tokenizer knowledge transfer.
👉 Paper link: https://huggingface.co/papers/2604.07466

22. LeapAlign: Post-Training Flow Matching Models at Any Generation Step by Building Two-Step Trajectories
🔑 Keywords: LeapAlign, flow matching models, gradient propagation, reward gradients, image-text alignment
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to improve fine-tuning of flow matching models by reducing computational costs while maintaining alignment with human preferences.
🛠️ Research Methods:
– Introduced LeapAlign, which reduces computational costs by shortening trajectory steps and enabling direct gradient propagation.
– Implemented two consecutive leaps to effectively update early generation steps, enhancing gradient stability.
💬 Research Conclusions:
– LeapAlign outperforms state-of-the-art methods in image quality and image-text alignment when fine-tuning the Flux model.
– Adaptively assigns higher training weights to more consistent trajectories, leading to stable and efficient model updates.
👉 Paper link: https://huggingface.co/papers/2604.15311

23. Don’t Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG
🔑 Keywords: Corpus2Skill, Retrieval-Augmented Generation, hierarchical skill directory, LLM agent, dense retrieval
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance retrieval-augmented generation by organizing document corpora into hierarchical skill directories.
🛠️ Research Methods:
– Iteratively clusters documents and generates summaries, forming a tree of navigable skill files to aid LLM agents in navigating and reasoning during query processing.
💬 Research Conclusions:
– Corpus2Skill allows agents to navigate and combine scattered evidence more effectively, outperforming several baseline models in the WixQA benchmark.
👉 Paper link: https://huggingface.co/papers/2604.14572

24. Beyond Prompts: Unconditional 3D Inversion for Out-of-Distribution Shapes
🔑 Keywords: text-to-3D generative models, prompt modifications, geometric representation, linguistic sensitivity, semantic manipulation
💡 Category: Generative Models
🌟 Research Objective:
– To address the limitations of state-of-the-art text-to-3D generative models by overcoming latent sink traps through decoupling geometric representation from linguistic sensitivity.
🛠️ Research Methods:
– Analysis of sampling trajectories of generative models and leveraging the model’s unconditional generative prior to support complex geometries.
💬 Research Conclusions:
– The proposed framework enhances robustness in text-based 3D shape editing by bypassing latent sinks, enabling high-fidelity semantic manipulation of out-of-distribution 3D shapes.
👉 Paper link: https://huggingface.co/papers/2604.14914

25. Representations Before Pixels: Semantics-Guided Hierarchical Video Prediction
🔑 Keywords: Re2Pix, hierarchical video prediction, semantic representation, latent diffusion model, train-test mismatch
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to improve future video generation by first predicting semantic representations and using them to guide photorealistic visual synthesis.
🛠️ Research Methods:
– The study employs a two-stage approach using Re2Pix that includes semantic representation prediction and representation-guided visual synthesis, leveraging nested dropout and mixed supervision strategies to address train-test mismatches.
💬 Research Conclusions:
– The proposed semantics-first design significantly enhances temporal semantic consistency, perceptual quality, and training efficiency on driving benchmarks compared to existing strong diffusion baselines.
👉 Paper link: https://huggingface.co/papers/2604.11707

26. TRACER: Trace-Based Adaptive Cost-Efficient Routing for LLM Classification
🔑 Keywords: TRACER, ML surrogates, production traces, interpretability artifacts, parity gate
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce TRACER, an open-source system using production traces to train ML surrogates for LLM classification, enhancing cost-efficiency and interpretability in deployment.
🛠️ Research Methods:
– TRACER trains lightweight surrogates on labeled input-output pairs from LLM production logs, activating only when agreement with the original model surpasses a threshold.
💬 Research Conclusions:
– TRACER achieves high surrogate coverage on benchmarks, with flexibility in handling classifications and deferrals, and is open-source for broader utilization.
👉 Paper link: https://huggingface.co/papers/2604.14531

27. UniDoc-RL: Coarse-to-Fine Visual RAG with Hierarchical Actions and Dense Rewards
🔑 Keywords: Reinforcement Learning, Large Vision-Language Models, Active Visual Perception, Fine-Grained Visual Semantics
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce UniDoc-RL, a unified reinforcement learning framework for optimizing retrieval, reranking, visual perception, and reasoning in Large Vision-Language Models (LVLMs) through hierarchical decision-making.
🛠️ Research Methods:
– Utilizes a sequential decision-making model with a hierarchical action space, applying a dense multi-reward scheme for task-aware supervision, and based on Group Relative Policy Optimization (GRPO) without relying on a separate value network.
💬 Research Conclusions:
– UniDoc-RL consistently outperforms state-of-the-art baselines in experiments across three benchmarks, achieving up to 17.7% improvement over previous RL-based methods.
👉 Paper link: https://huggingface.co/papers/2604.14967

28. HiVLA: A Visual-Grounded-Centric Hierarchical Embodied Manipulation System
🔑 Keywords: Vision-Language-Action, Diffusion Transformer, semantic planning, motor control, cascaded cross-attention
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper presents HiVLA, a hierarchical vision-language-action framework designed to decouple semantic planning from motor control in robotic manipulation to enhance reasoning capabilities.
🛠️ Research Methods:
– HiVLA employs a Diffusion Transformer action expert with cascaded cross-attention for robust task execution and integrates task decomposition and visual grounding at a high level.
💬 Research Conclusions:
– HiVLA significantly outperforms current end-to-end models, demonstrating exceptional performance in long-horizon skill composition and fine-grained manipulation of small objects in cluttered environments.
👉 Paper link: https://huggingface.co/papers/2604.14125

29. How to Fine-Tune a Reasoning Model? A Teacher-Student Cooperation Framework to Synthesize Student-Consistent SFT Data
🔑 Keywords: Teacher-Student Cooperation, Data Synthesis, Synthetic Data, Supervised Fine-Tuning, Reasoning Models
💡 Category: Generative Models
🌟 Research Objective:
– Address the stylistic divergence in synthetic data to improve model fine-tuning performance.
🛠️ Research Methods:
– Proposed the TESSY framework, which interleaves teacher and student models to generate sequences with both style consistency and advanced reasoning capabilities.
💬 Research Conclusions:
– TESSY achieves significant performance improvements in reasoning tasks, outperforming traditional synthetic data fine-tuning approaches.
👉 Paper link: https://huggingface.co/papers/2604.14164

30. RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework
🔑 Keywords: Autonomous Driving, Generator-Discriminator Framework, Reinforcement Learning, Trajectory Generation, Spatial Warping
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Develop a unified generator-discriminator framework for improved stability and performance in autonomous driving motion planning.
🛠️ Research Methods:
– Introduced RAD-2 using a diffusion-based generator and an RL-optimized discriminator to enhance trajectory planning.
– Implemented Temporally Consistent Group Relative Policy Optimization for improved reinforcement learning.
– Proposed On-policy Generator Optimization and introduced BEV-Warp for efficient training.
💬 Research Conclusions:
– RAD-2 significantly reduces the collision rate by 56% compared to existing diffusion-based planners.
– Demonstrated improvements in perceived safety and driving smoothness in complex urban environments.
👉 Paper link: https://huggingface.co/papers/2604.15308