AI Native Daily Paper Digest – 20260424

1. LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
🔑 Keywords: Time Series Reasoning, TSRM, Chain-of-Thought, Vision-Language Models, Multi-stage Curriculum Fine-tuning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to improve the understanding of temporal data by Large Language Models (LLMs) through the introduction of a hierarchical time series reasoning dataset and model.
🛠️ Research Methods:
– The researchers formulated a four-level taxonomy to enhance cognitive complexity in Time Series Reasoning and introduced HiTSR, a dataset with 83k samples.
– Proposed the TSRM LLaTiSA employing visualized patterns and precision-calibrated numerical tables, fine-tuned via a multi-stage curriculum approach.
💬 Research Conclusions:
– LLaTiSA demonstrates superior performance and strong out-of-distribution generalization across various TSR tasks and real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2604.17295
2. UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
🔑 Keywords: UniT, Human-to-Humanoid Transfer, Cross-Reconstruction Mechanism, Embodiment-Agnostic, Shared Latent Space
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To create a unified visual-language representation that enables efficient and scalable human-to-humanoid action transfer by overcoming kinematic mismatches.
🛠️ Research Methods:
– The introduction of UniT framework utilizing a tri-branch cross-reconstruction mechanism to anchor kinematics to physical outcomes and a fusion branch for a shared latent space of embodiment-agnostic intents.
💬 Research Conclusions:
– UniT offers significant improvements in data efficiency and generalization in policy learning, demonstrating zero-shot task transfer in simulations and real-world. It also enables direct cross-embodiment action transfer, enhancing humanoid video generation through aligned dynamics.
👉 Paper link: https://huggingface.co/papers/2604.19734

3. Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
🔑 Keywords: Large Language Models, Skill Bank, Skill Pipeline, Long Horizon Decision Making
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a co-evolution framework called COSPLAY that enhances Large Language Models’ ability to discover, retain, and reuse structured skills across episodes in long-horizon interactive environments.
🛠️ Research Methods:
– Implementation of a learnable skill bank and a skill pipeline to guide LLM decision agents, enabling improved skill retrieval and action generation.
💬 Research Conclusions:
– COSPLAY framework, using an 8B base model, achieves over 25.1% average reward improvement against four frontier LLM baselines on single-player game benchmarks and remains competitive on multi-player social reasoning games.
👉 Paper link: https://huggingface.co/papers/2604.20987

4. VLAA-GUI: Knowing When to Stop, Recover, and Search, A Modular Framework for GUI Automation
🔑 Keywords: GUI agentic framework, Completeness Verifier, Loop Breaker, Search Agent, Coding Agent
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to tackle early stopping and repetitive loop issues in autonomous GUI agents using a modular framework called VLAA-GUI, which integrates components for verification, loop breaking, and search capabilities.
🛠️ Research Methods:
– The study employs three integrated components: Completeness Verifier for enforcing success criteria, Loop Breaker for managing interaction modes and strategy shifts, and Search Agent for querying LLMs for unfamiliar workflows. These components are further supported by Coding and Grounding Agents when needed.
💬 Research Conclusions:
– Evaluation across five backbones on Linux and Windows tasks showed top performance, with some models surpassing human performance. Ablation studies reveal consistent improvement across frameworks, particularly benefiting weaker backbones with sufficient step budgets. The Loop Breaker significantly reduces step wastage for loop-prone models.
👉 Paper link: https://huggingface.co/papers/2604.21375

5. Hybrid Policy Distillation for LLMs
🔑 Keywords: Knowledge Distillation, Large Language Models, Hybrid Policy Distillation, Mode Coverage, Computational Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the stability and efficiency of knowledge distillation across various model sizes and tasks using a novel approach called Hybrid Policy Distillation.
🛠️ Research Methods:
– Combines forward and reverse KL divergence to balance mode coverage and mode-seeking.
– Utilizes off-policy data with lightweight, approximate on-policy sampling.
💬 Research Conclusions:
– Demonstrates improved optimization stability and computational efficiency.
– Shows enhanced performance in long-generation math reasoning, short-generation dialogue, and code tasks across diverse model families and scales.
👉 Paper link: https://huggingface.co/papers/2604.20244

6. EditCrafter: Tuning-free High-Resolution Image Editing via Pretrained Diffusion Model
🔑 Keywords: EditCrafter, high-resolution image editing, pretrained text-to-image diffusion models, tiled inversion, noise-damped manifold-constrained guidance
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the research is to introduce EditCrafter, a method for editing high-resolution images without the need for tuning, by utilizing pretrained text-to-image diffusion models.
🛠️ Research Methods:
– The approach involves the use of tiled inversion to maintain the original identity of high-resolution images and a proposed noise-damped manifold-constrained classifier-free guidance (NDCFG++) to achieve effective image editing.
💬 Research Conclusions:
– EditCrafter has been shown to produce impressive editing results across various resolutions without the need for fine-tuning or optimization.
👉 Paper link: https://huggingface.co/papers/2604.10268
7. Vista4D: Video Reshooting with 4D Point Clouds
🔑 Keywords: Vista4D, 4D point cloud, video reshooting, camera control, 4D consistency
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Vista4D, a video reshooting framework leveraging 4D point cloud representation to synthesize scenes from different viewpoints while ensuring 4D consistency and camera control.
🛠️ Research Methods:
– Utilize a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to maintain content appearance and provide rich camera signals.
– Train with reconstructed multiview dynamic data for robust performance against point cloud artifacts during real-world inference.
💬 Research Conclusions:
– Demonstrated improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines across various videos and camera paths.
– Method generalizes to applications like dynamic scene expansion and 4D scene recomposition.
👉 Paper link: https://huggingface.co/papers/2604.21915
8. Encoder-Free Human Motion Understanding via Structured Motion Descriptions
🔑 Keywords: Structured Motion Description, text-based large language models, motion question answering, motion captioning, LoRA adaptation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Structured Motion Description (SMD) to enhance large language models (LLMs) in human motion reasoning by converting joint position sequences into structured natural language.
🛠️ Research Methods:
– Employ a rule-based, deterministic approach inspired by biomechanical analysis, transforming motion data into descriptive text without requiring learned encoders or alignment modules.
💬 Research Conclusions:
– SMD surpasses state-of-the-art results in motion question answering and captioning tasks and offers practical benefits like interoperability across different LLMs and human-readable representation for interpretable attention analysis.
👉 Paper link: https://huggingface.co/papers/2604.21668

9. Trust but Verify: Introducing DAVinCI — A Framework for Dual Attribution and Verification in Claim Inference for Language Models
🔑 Keywords: Large Language Models, Dual Attribution, Verification framework, factual reliability, entailment-based reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the factual reliability and interpretability of Large Language Model outputs through a dual attribution and verification framework called DAVinCI.
🛠️ Research Methods:
– DAVinCI operates in two stages: it attributes claims to internal components and external sources, and it verifies these claims using entailment-based reasoning and confidence calibration.
💬 Research Conclusions:
– DAVinCI significantly improves classification accuracy, attribution precision, recall, and F1-score by 5-20% compared to standard verification-only baselines. It provides a scalable solution for building auditable and trustworthy AI systems.
👉 Paper link: https://huggingface.co/papers/2604.21193

10. PersonalAI: A Systematic Comparison of Knowledge Graph Storage and Retrieval Approaches for Personalized LLM agents
🔑 Keywords: knowledge graph, external memory framework, Retrieval-Augmented Generation, large language models, temporal dependencies
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance language model personalization by effectively incorporating user interaction history through a knowledge graph-based external memory framework.
🛠️ Research Methods:
– Implementation of a flexible external memory framework using a knowledge graph constructed automatically by large language models.
– Introduction of a hybrid graph design supporting dynamic semantic and temporal representations with varied retrieval mechanisms like A*, WaterCircles traversal, and beam search.
💬 Research Conclusions:
– Demonstrated that different memory and retrieval configurations yield optimal performance across various tasks such as TriviaQA and DiaASQ benchmarks.
– Extended DiaASQ with temporal annotations and internally contradictory statements to validate the system’s robustness in managing temporal dependencies and context-aware reasoning.
👉 Paper link: https://huggingface.co/papers/2506.17001

11. Temporally Extended Mixture-of-Experts Models
🔑 Keywords: Mixture-of-Experts, Reinforcement Learning, Options Framework, Deliberation Costs
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To reduce expert switching rates in Mixture-of-Experts models while maintaining model accuracy using a temporal extension via the reinforcement learning options framework.
🛠️ Research Methods:
– Utilization of the options framework in reinforcement learning, integrating a controller in the model to determine when and which expert sets to switch, applying the method to models like gpt-oss-20b.
💬 Research Conclusions:
– The approach significantly reduces expert switch rates from over 50% to below 5% while retaining up to 90% of base-model accuracy, illustrating the feasibility of converting pre-trained models to temporally extended MoEs with minimal training.
👉 Paper link: https://huggingface.co/papers/2604.20156

12.

13. 3D-VCD: Hallucination Mitigation in 3D-LLM Embodied Agents through Visual Contrastive Decoding
🔑 Keywords: 3D-VCD, Hallucination Mitigation, Visual Contrastive Decoding, Geometric Perturbations, 3D Scene Graph
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The main objective is to introduce 3D-VCD, the first inference-time visual contrastive decoding framework focused on mitigating hallucinations in 3D embodied agents.
🛠️ Research Methods:
– 3D-VCD constructs distorted 3D scene graphs through semantic and geometric perturbations applied to object-centric representations, contrasting predictions between original and perturbed contexts.
💬 Research Conclusions:
– The study demonstrates that 3D-VCD effectively improves grounded reasoning without retraining, suggesting it as a practical solution for enhancing the reliability of embodied intelligence by using inference-time contrastive decoding with structured 3D representations.
👉 Paper link: https://huggingface.co/papers/2604.08645

14. Test-Time Adaptation for EEG Foundation Models: A Systematic Study under Real-World Distribution Shifts
🔑 Keywords: EEG foundation models, AI-generated summary, Test-time adaptation, Optimization-free methods, Gradient-based approaches
💡 Category: AI in Healthcare
🌟 Research Objective:
– To introduce NeuroAdapt-Bench for systematically evaluating test-time adaptation methods on EEG foundation models under realistic distribution shifts.
🛠️ Research Methods:
– The study evaluates representative TTA approaches from other domains across multiple pretrained foundation models, diverse downstream tasks, and heterogeneous datasets that include in-distribution, out-of-distribution, and extreme modality shifts like Ear-EEG.
💬 Research Conclusions:
– Standard TTA methods show inconsistent and often degrading performance, with gradient-based approaches particularly affected, whereas optimization-free methods offer greater stability and more reliable improvements.
– The findings highlight the limitations of existing TTA techniques in EEG and emphasize the need for domain-specific adaptation strategies.
👉 Paper link: https://huggingface.co/papers/2604.16926

15. Explainable Disentangled Representation Learning for Generalizable Authorship Attribution in the Era of Generative AI
🔑 Keywords: Variational Autoencoder, Authorship Attribution, AI-generated Text Detection, Discriminative Disentanglement, Explainable AI
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve authorship attribution and AI-generated text detection by disentangling style from content using a novel framework called Explainable Authorship Variational Autoencoder (EAVAE).
🛠️ Research Methods:
– Utilized supervised contrastive learning for pretraining style encoders.
– Implemented a variational autoencoder architecture with separate encoders for style and content representations.
– Employed a novel discriminator for effective disentanglement and generation of natural language explanations.
💬 Research Conclusions:
– Presented method achieves state-of-the-art performance in authorship attribution across various datasets.
– Demonstrated superior performance in AI-generated text detection, especially in few-shot learning scenarios.
👉 Paper link: https://huggingface.co/papers/2604.21300

16. Coevolving Representations in Joint Image-Feature Diffusion
🔑 Keywords: CoReDi, semantic representation, VAE latents, generative modeling, lightweight linear projection
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance generative modeling by adapting the semantic representation space during training through Coevolving Representation Diffusion (CoReDi).
🛠️ Research Methods:
– CoReDi utilizes a lightweight linear projection that evolves alongside the diffusion model and employs techniques such as stop-gradient targets, normalization, and targeted regularization to stabilize the process.
💬 Research Conclusions:
– CoReDi improves convergence speed and sample quality in generative models using both VAE latent and pixel-space diffusion, demonstrating better performance than models with fixed representation spaces.
👉 Paper link: https://huggingface.co/papers/2604.17492

17. WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
🔑 Keywords: reinforcement learning, website generation, multi-page websites, multimodal rewards, Large Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to develop a novel framework, WebGen-R1, for project-level website generation using reinforcement learning that integrates structured scaffolding and multimodal rewards.
🛠️ Research Methods:
– Utilizes an end-to-end RL framework with a scaffold-driven generation paradigm and introduces cascaded multimodal rewards to enhance architectural integrity and aesthetics in multi-page website creation.
💬 Research Conclusions:
– WebGen-R1 significantly outperforms existing open-source models in generating deployable, visually aesthetic websites and rivals state-of-the-art models in functional success and rendering validity.
👉 Paper link: https://huggingface.co/papers/2604.20398

18. UniGenDet: A Unified Generative-Discriminative Framework for Co-Evolutionary Image Generation and Generated Image Detection
🔑 Keywords: AI-generated summary, generative networks, discriminative frameworks, generative-discriminative framework, multimodal self-attention mechanism
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal of the research is to develop a unified generative-discriminative framework, called UniGenDet, that enables co-evolutionary image generation and detection using symbiotic attention mechanisms and unified fine-tuning algorithms.
🛠️ Research Methods:
– The study proposes a symbiotic multimodal self-attention mechanism and a unified fine-tuning algorithm to bridge the task gap between image generation and detection.
– It introduces a detector-informed generative alignment mechanism to enhance seamless information exchange.
💬 Research Conclusions:
– The proposed UniGenDet framework allows for improved interpretability in authenticity identification and guides the creation of higher-fidelity images.
– Extensive experiments demonstrate that the method achieves state-of-the-art performance across multiple datasets.
👉 Paper link: https://huggingface.co/papers/2604.21904

19. Context Unrolling in Omni Models
🔑 Keywords: Omni, multimodal model, Context Unrolling, multimodal knowledge manifold, downstream reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Omni, a unified model designed to improve reasoning capabilities across various data modalities.
🛠️ Research Methods:
– Omni is trained natively on diverse modalities such as text, images, videos, 3D geometry, and hidden representations. This enables the model to perform Context Unrolling, allowing it to reason explicitly across multiple modal representations before predictions.
💬 Research Conclusions:
– Omni enhances the aggregation of complementary information from heterogeneous modalities, leading to a more accurate approximation of the shared multimodal knowledge manifold. The model delivers strong performance on generation and understanding benchmarks and showcases advanced reasoning capabilities across modalities.
👉 Paper link: https://huggingface.co/papers/2604.21921

20. TingIS: Real-time Risk Event Discovery from Noisy Customer Incidents at Enterprise Scale
🔑 Keywords: incident discovery, event linking engine, Large Language Models, cascaded routing, noise reduction
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary aim is to develop TingIS, an enterprise-grade system that efficiently identifies critical incidents from high-volume, noisy customer reports in cloud-native services.
🛠️ Research Methods:
– The system employs a multi-stage event linking engine using Large Language Models to merge events effectively. It also uses a cascaded routing mechanism for precise business attribution and a multi-dimensional noise reduction pipeline.
💬 Research Conclusions:
– TingIS, when deployed in a real-world environment, achieves a P90 alert latency of 3.5 minutes and a 95% discovery rate for high-priority incidents, significantly surpassing baseline methods in routing accuracy, clustering quality, and Signal-to-Noise Ratio.
👉 Paper link: https://huggingface.co/papers/2604.21889

21. Seeing Fast and Slow: Learning the Flow of Time in Videos
🔑 Keywords: Video Speed Manipulation, Self-Supervised Learning, Temporal Reasoning, Slow-Motion Video, High-Speed Cameras
💡 Category: Computer Vision
🌟 Research Objective:
– To explore and manipulate the flow of time in videos as a learnable visual concept.
🛠️ Research Methods:
– Developed self-supervised temporal reasoning models to detect speed changes and estimate video playback speed using multimodal cues and temporal structure.
– Curated the largest slow-motion video dataset from in-the-wild sources for further model development.
💬 Research Conclusions:
– Demonstrated temporal control capabilities, including speed-conditioned video generation and temporal super-resolution, transforming low-FPS videos into high-FPS sequences.
– Highlighted the potential for temporally controllable video generation, temporal forensics detection, and enriched world-models understanding event unfolding over time.
👉 Paper link: https://huggingface.co/papers/2604.21931
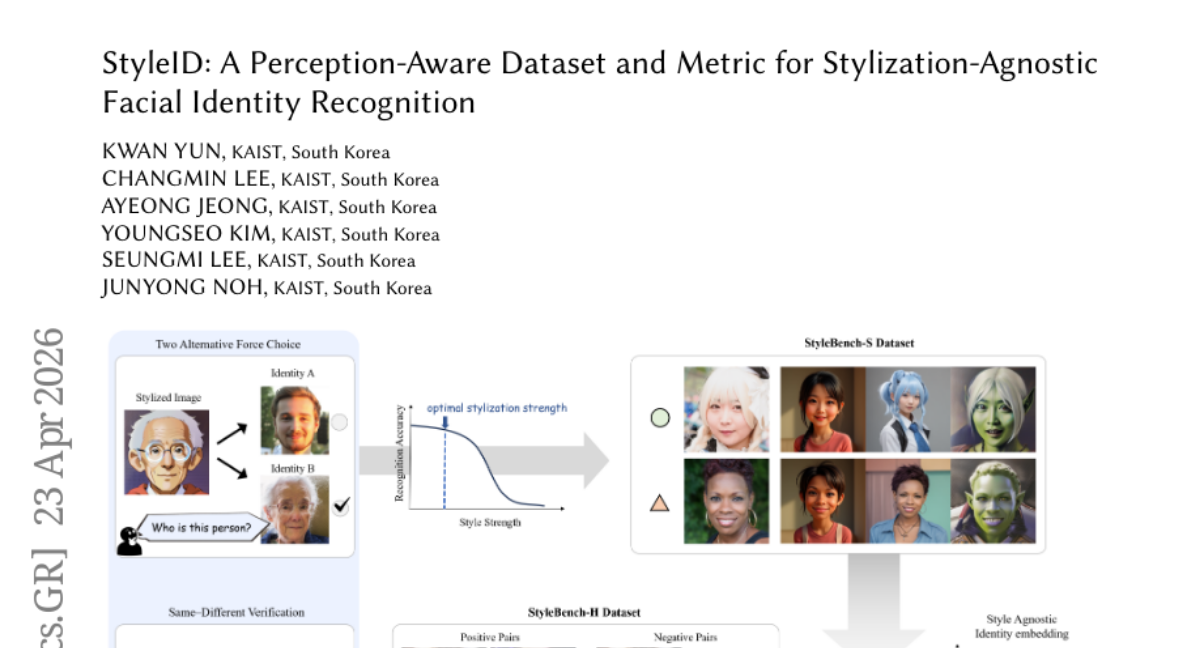
22. StyleID: A Perception-Aware Dataset and Metric for Stylization-Agnostic Facial Identity Recognition
🔑 Keywords: facial identity preservation, stylization, human perception-aware dataset, semantic encoders
💡 Category: Computer Vision
🌟 Research Objective:
– The primary aim of the study is to evaluate and preserve facial identity under various creative stylizations, such as cartoons and paintings, with an emphasis on aligning algorithms with human perception.
🛠️ Research Methods:
– The research employed StyleID, a comprehensive evaluation framework comprising two datasets, StyleBench-H and StyleBench-S, derived from both human verification judgments and psychometric experiments to ensure the preservation of facial identity across different styles and strengths.
💬 Research Conclusions:
– Findings indicate that the use of calibrated semantic encoders in the StyleID framework enhances the correlation with human judgments and robustness in recognizing facial identities in artist-drawn portraits, demonstrating the need for a style-agnostic framework in facial identity preservation.
👉 Paper link: https://huggingface.co/papers/2604.21689
23. WorldMark: A Unified Benchmark Suite for Interactive Video World Models
🔑 Keywords: Interactive Video Generation, WorldMark Benchmark, Unified Controls, Evaluation Metrics, World Models
💡 Category: Generative Models
🌟 Research Objective:
– Introduce WorldMark, a standardized benchmark for evaluating interactive video generation models under identical scenarios and controls.
🛠️ Research Methods:
– Develop a unified action-mapping layer for consistent model comparisons.
– Create a hierarchical test suite with varied evaluation cases.
– Offer a modular evaluation toolkit for diverse visual quality metrics.
💬 Research Conclusions:
– WorldMark enables fair cross-model comparisons by standardizing test conditions.
– Launches World Model Arena for real-time model competition and evaluation.
👉 Paper link: https://huggingface.co/papers/2604.21686