AI Native Daily Paper Digest – 20260429

1. Recursive Multi-Agent Systems
🔑 Keywords: RecursiveMAS, multi-agent systems, latent-space recursive computation, RecursiveLink module, gradient-based credit assignment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Explore if agent collaboration can be scaled through recursion using the RecursiveMAS framework, extending recursive scaling principles from single models to multi-agent systems.
🛠️ Research Methods:
– Developed a recursive multi-agent framework with a RecursiveLink module connecting agents and employing an inner-outer loop learning algorithm for system co-optimization through shared gradient-based credit assignment.
💬 Research Conclusions:
– RecursiveMAS demonstrates superior efficiency and accuracy over traditional multi-agent systems, achieving an average accuracy improvement of 8.3%, 1.2 to 2.4 times faster inference speed, and a significant reduction in token usage by 34.6%-75.6% across multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2604.25917

2. DV-World: Benchmarking Data Visualization Agents in Real-World Scenarios
🔑 Keywords: Data Visualization, Cross-Platform Evolution, Intent Alignment, Native Environment
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce DV-World, a comprehensive benchmark designed to evaluate data visualization agents across professional lifecycles in the real world.
🛠️ Research Methods:
– Developed a benchmark in three domains: DV-Sheet, DV-Evolution, and DV-Interact, incorporating Table-value Alignment and MLLM-as-a-Judge for evaluation.
💬 Research Conclusions:
– State-of-the-art models perform below 50% in handling real-world data visualization tasks, highlighting significant challenges.
👉 Paper link: https://huggingface.co/papers/2604.25914

3. Meta-CoT: Enhancing Granularity and Generalization in Image Editing
🔑 Keywords: Meta-CoT, Image Editing, Chain-of-Thought, Decomposability, Generalizability
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance image editing capabilities by decomposing editing operations into a task-target-understanding framework, improving granularity and generalization.
🛠️ Research Methods:
– Proposes Meta-CoT, which breaks down single-image editing tasks into triplets and fundamental meta-tasks, incorporating a CoT-Editing Consistency Reward to align editing with Chain-of-Thought reasoning.
💬 Research Conclusions:
– Meta-CoT achieves a 15.8% performance improvement across 21 editing tasks and demonstrates strong generalization to unseen tasks, with source code and benchmarks provided for public access.
👉 Paper link: https://huggingface.co/papers/2604.24625

4. Mutual Forcing: Dual-Mode Self-Evolution for Fast Autoregressive Audio-Video Character Generation
🔑 Keywords: Mutual Forcing, autoregressive audio-video generation, joint audio-video modeling, self-distillation, training-inference consistency
💡 Category: Generative Models
🌟 Research Objective:
– To efficiently generate audio-video content with long-horizon synchronization using a unified model that combines few-step and multi-step training modes.
🛠️ Research Methods:
– Developed a framework called Mutual Forcing that integrates uni-modal generators into a combined model using a two-stage training strategy to optimize joint audio-video modeling and facilitate fast autoregressive generation.
💬 Research Conclusions:
– Mutual Forcing eliminates the necessity for an additional teacher model, reduces overhead, and enhances model training with real paired data. It delivers competitive or superior results compared to existing methods with significantly fewer steps, demonstrating improved efficiency and quality.
👉 Paper link: https://huggingface.co/papers/2604.25819

5. Co-Director: Agentic Generative Video Storytelling
🔑 Keywords: AI-generated summary, hierarchical multi-agent framework, semantic coherence, global optimization problem, multimodal self-refinement
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance video storytelling by addressing it as a global optimization problem using a hierarchical multi-agent framework to maintain semantic coherence.
🛠️ Research Methods:
– The framework utilizes a multi-armed bandit approach to guide creative direction and employs multimodal self-refinement loops to prevent identity drift and ensure sequence-level consistency.
💬 Research Conclusions:
– Co-Director outperforms existing methods, offering a robust solution capable of generalizing across broader cinematic narratives and successfully evaluated using the GenAD-Bench dataset.
👉 Paper link: https://huggingface.co/papers/2604.24842

6. Toward Scalable Terminal Task Synthesis via Skill Graphs
🔑 Keywords: SkillSynth, terminal task synthesis, scenario-mediated, skill graph, execution trajectories
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective of the study is to introduce SkillSynth, an automated framework aimed at enhancing the diversity and quality of execution trajectories for training terminal agents.
🛠️ Research Methods:
– SkillSynth constructs a scenario-mediated skill graph to generate a wide array of terminal task instances, using multi-agent harnesses to instantiate these into executable tasks. The framework samples workflow paths from the graph, controlling the diversity of trajectories explicitly.
💬 Research Conclusions:
– Experiments using Terminal-Bench show that SkillSynth effectively enhances the diversity of execution trajectories. Task instances generated by SkillSynth have been used to train the Hy3 Preview, improving its capabilities in terminal-based environments.
👉 Paper link: https://huggingface.co/papers/2604.25727

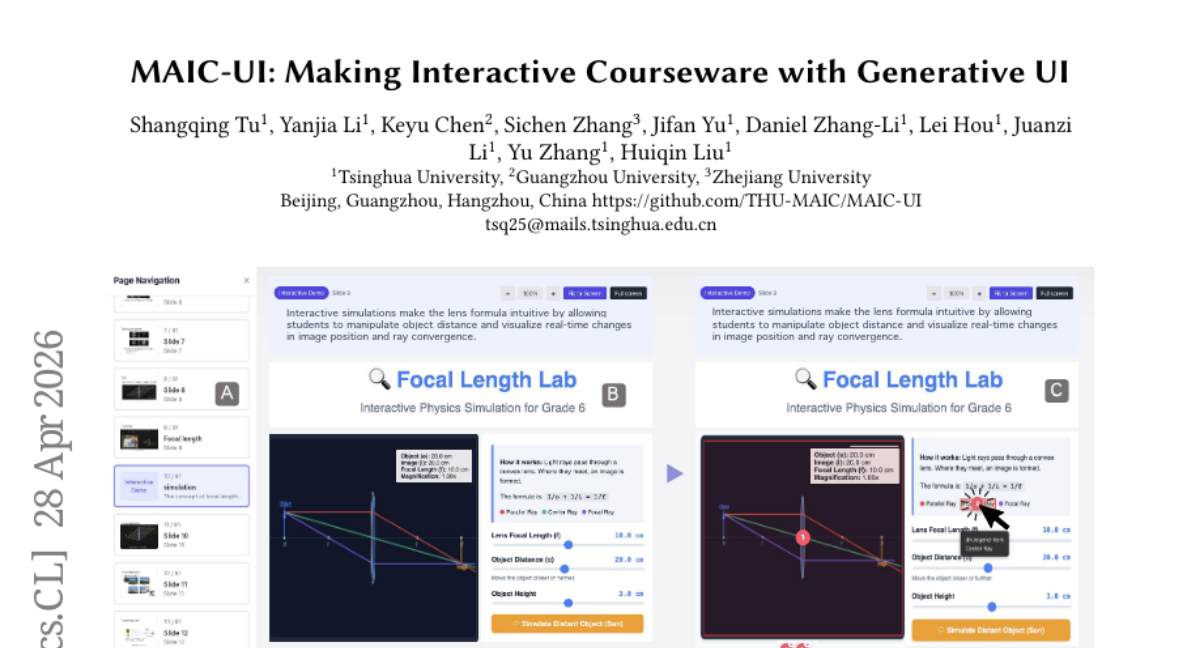
7. MAIC-UI: Making Interactive Courseware with Generative UI
🔑 Keywords: Zero-code, Interactive STEM courseware, Incremental generation, Pedagogical rigor, Multi-modal understanding
💡 Category: AI in Education
🌟 Research Objective:
– The objective of the study is to introduce MAIC-UI, a zero-code system designed to empower educators to create and edit interactive STEM courseware rapidly and efficiently, thus overcoming traditional barriers such as the need for HTML/CSS/JavaScript expertise.
🛠️ Research Methods:
– The study employs a zero-code authoring system that utilizes structured knowledge analysis with multi-modal understanding, a generate-verify-optimize pipeline, and Click-to-Locate editing with Unified Diff-based incremental generation for rapid iteration cycles.
💬 Research Conclusions:
– MAIC-UI decreases editing iterations and enhances learnability and controllability compared to direct Text-to-HTML generation. Classroom deployments demonstrated significant improvements in learning outcomes, fostering learning agency and reducing outcome disparities in students.
👉 Paper link: https://huggingface.co/papers/2604.25806
8. IAM: Identity-Aware Human Motion and Shape Joint Generation
🔑 Keywords: identity-aware motion generation, body morphology, motion dynamics, multimodal signals, joint motion-shape generation
💡 Category: Generative Models
🌟 Research Objective:
– Propose an identity-aware motion generation framework that models the relationship between body morphology and motion dynamics using multimodal signals.
🛠️ Research Methods:
– Utilize multimodal signals such as natural language descriptions and visual cues for representing identity.
– Introduce a joint motion-shape generation paradigm to synthesize motion sequences alongside body shape parameters.
💬 Research Conclusions:
– The framework improves motion realism and motion-identity consistency while maintaining high motion quality as demonstrated on motion capture datasets and large-scale in-the-wild videos.
👉 Paper link: https://huggingface.co/papers/2604.25164
9. GoClick: Lightweight Element Grounding Model for Autonomous GUI Interaction
🔑 Keywords: GoClick, GUI element grounding, vision-language model, encoder-decoder architecture, Progressive Data Refinement
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce GoClick, a lightweight model for GUI element grounding on mobile devices, focusing on high accuracy and low computational needs.
🛠️ Research Methods:
– Implement an encoder-decoder architecture to develop a model with only 230M parameters.
– Utilize Progressive Data Refinement techniques for data optimization, including task type filtering and data ratio adjustment.
💬 Research Conclusions:
– GoClick achieves high visual grounding accuracy, comparable to larger models, while maintaining efficiency.
– Enhances GUI agent performance in a device-cloud collaboration framework by improving element localization and success rates.
👉 Paper link: https://huggingface.co/papers/2604.23941

10. The Last Harness You’ll Ever Build
🔑 Keywords: AI agents, automated harness engineering, evolutionary loops, meta-learning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to automate the deployment of AI agents by using a two-level framework that optimizes task-specific harnesses through evolutionary loops and meta-learning protocols.
🛠️ Research Methods:
– The framework consists of two levels: the first level optimizes a worker agent’s harness for a single task using the Harness Evolution Loop, while the second level, the Meta-Evolution Loop, optimizes the evolution protocol to enable quick harness adaptation across diverse tasks.
💬 Research Conclusions:
– The proposed framework shifts the need for manual harness engineering to an automated process, potentially eliminating the need for human intervention in adapting agents to new task domains.
👉 Paper link: https://huggingface.co/papers/2604.21003

11. Preferences of a Voice-First Nation: Large-Scale Pairwise Evaluation and Preference Analysis for TTS in Indian Languages
🔑 Keywords: multilingual TTS, linguistic diversity, perceptual dimensions, SHAP analysis, Bradley-Terry modeling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to develop a controlled multidimensional pairwise evaluation framework for multilingual Text to Speech (TTS) systems, with a focus on linguistic control and perceptual annotation across 10 Indic languages.
🛠️ Research Methods:
– The study involves evaluating 7 state-of-the-art TTS systems using over 5,000 native and code-mixed sentences, collecting more than 120,000 pairwise comparisons from 1,900 native raters. The evaluations are made across 6 perceptual dimensions including intelligibility, expressiveness, voice quality, liveliness, noise, and hallucinations, utilizing Bradley-Terry modeling and SHAP analysis.
💬 Research Conclusions:
– The research constructs a multilingual leaderboard and interprets human preferences while analyzing the reliability of the leaderboard. It highlights the model strengths and trade-offs across different perceptual dimensions.
👉 Paper link: https://huggingface.co/papers/2604.21481

12.

13. Offline Evaluation Measures of Fairness in Recommender Systems
🔑 Keywords: recommender system fairness, fairness evaluation measures, AI Ethics and Fairness, robustness, guidelines
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The research aims to address the limitations in the evaluation of fairness in recommender systems by analyzing theoretical flaws and developing novel approaches to improve the robustness and applicability of fairness evaluation measures.
🛠️ Research Methods:
– Conduct theoretical and empirical analysis of existing fairness evaluation measures to expose their limitations.
– Investigate a wide range of offline evaluation measures across different fairness notions, focusing on both users and items, and varying evaluation granularities.
💬 Research Conclusions:
– Propose new evaluation approaches and measures that overcome existing limitations, thereby enhancing interpretability and applicability.
– Provide guidelines for selecting appropriate fairness evaluation measures, facilitating more precise application in practical scenarios and thus advancing the state-of-the-art in the offline evaluation of fairness in recommender systems.
👉 Paper link: https://huggingface.co/papers/2604.25032

14. Seeing Isn’t Believing: Uncovering Blind Spots in Evaluator Vision-Language Models
🔑 Keywords: Vision-Language Models, Evaluator VLMs, image-to-text, text-to-image, perturbations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study systematically evaluates the reliability issues of current Evaluator VLMs in detecting various types of output errors.
🛠️ Research Methods:
– Introduces targeted perturbations across key error dimensions and evaluates 4 prominent VLMs using over 4000 perturbed instances and multiple evaluation techniques.
💬 Research Conclusions:
– Current VLM evaluators have substantial blind spots, particularly with fine-grained compositional and spatial errors, revealing their unreliable nature for benchmarking and urging caution in their development use. Code and data have been made publicly available.
👉 Paper link: https://huggingface.co/papers/2604.21523

15. AutoGUI-v2: A Comprehensive Multi-Modal GUI Functionality Understanding Benchmark
🔑 Keywords: AutoGUI-v2, autonomous agents, Vision-Language Models, functionality understanding, interaction logic
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to evaluate autonomous agents’ capability in understanding and predicting interactions within Graphical User Interfaces (GUIs) using the AutoGUI-v2 benchmark.
🛠️ Research Methods:
– Utilizes a novel VLM-human collaborative pipeline for parsing multi-platform screenshots to create hierarchical functional regions and diverse evaluation tasks.
💬 Research Conclusions:
– The evaluation found that open-source Vision-Language Models fine-tuned on agent data excel in functional grounding, whereas commercial models perform better in functionality captioning. However, all models exhibit challenges with complex interaction logic, indicating that deep functional understanding remains crucial for advancing GUI agents.
👉 Paper link: https://huggingface.co/papers/2604.24441

16. A Systematic Post-Train Framework for Video Generation
🔑 Keywords: Supervised Fine-Tuning, Reinforcement Learning from Human Feedback, Group Relative Policy Optimization, temporal coherence, visual quality
💡 Category: Generative Models
🌟 Research Objective:
– To bridge the gap between pretraining performance of video diffusion models and real-world deployment requirements by enhancing controllability, temporal coherence, and visual quality.
🛠️ Research Methods:
– Four-stage post-training framework involving Supervised Fine-Tuning, Reinforcement Learning from Human Feedback with Group Relative Policy Optimization, Prompt Enhancement, and Inference Optimization.
💬 Research Conclusions:
– The proposed pipeline significantly mitigates common artifacts and enhances controllability, visual aesthetics, while maintaining efficient sampling costs, offering a practical blueprint for real-world deployment.
👉 Paper link: https://huggingface.co/papers/2604.25427

17. V-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think
🔑 Keywords: Variational GRPO, ELBO-based surrogates, generative models, human preferences, text-to-image synthesis
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal is to improve text-to-image synthesis by aligning generative models more efficiently with human preferences using the Variational GRPO method.
🛠️ Research Methods:
– This method combines ELBO-based surrogates with Group Relative Policy Optimization (GRPO), enhancing stability and efficiency in the alignment process.
💬 Research Conclusions:
– Variational GRPO achieves state-of-the-art performance in text-to-image synthesis with significant speed improvements over previous methods like MixGRPO and DiffusionNFT.
👉 Paper link: https://huggingface.co/papers/2604.23380

18. TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents
🔑 Keywords: On-policy distillation, Trajectory-Level KL Instability, Temporal Curriculum, multi-turn agent settings
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate the instability and limitations of vanilla On-policy distillation (OPD) in multi-turn agent settings, particularly focusing on Trajectory-Level KL Instability.
🛠️ Research Methods:
– Introduce TCOD (Temporal Curriculum On-Policy Distillation), employing a curriculum approach to progressively expand trajectory depth and enhance training stability.
💬 Research Conclusions:
– TCOD effectively mitigates KL escalation, increases KL stability, and significantly improves agent performance in multi-turn tasks compared to vanilla OPD, with improvements up to 18 points. It can also surpass the teacher’s performance and generalize to tasks where the teacher fails.
👉 Paper link: https://huggingface.co/papers/2604.24005

19. BARRED: Synthetic Training of Custom Policy Guardrails via Asymmetric Debate
🔑 Keywords: BARRED, custom guardrails, synthetic training data, multi-agent debate, dimension decomposition
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a framework called BARRED for generating synthetic training data that enhances the performance of custom guardrail policies over existing language models.
🛠️ Research Methods:
– Utilizes dimension decomposition and multi-agent debate to generate diverse and high-fidelity synthetic data without extensive human annotation.
💬 Research Conclusions:
– The BARRED framework allows small language models to outperform state-of-the-art proprietary models by relying on synthetic data, highlighting the importance of dimension decomposition and debate-based verification for effective model fine-tuning.
👉 Paper link: https://huggingface.co/papers/2604.25203

20. Step-Audio-R1.5 Technical Report
🔑 Keywords: Audio Language Models, Reinforcement Learning, Human Feedback, Chain-of-Thought, Immersive Dialogue
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate the limitations of current reinforcement learning paradigms in audio language models, specifically addressing the “verifiable reward trap” and its impact on conversational quality.
🛠️ Research Methods:
– Employ Reinforcement Learning from Human Feedback (RLHF) to refine audio reasoning capabilities, introducing Step-Audio-R1.5 to enhance interactive experiences.
💬 Research Conclusions:
– Step-Audio-R1.5 effectively maintains analytical reasoning while transforming interaction quality, bridging the gap between mechanical verification and sensory empathy for immersive long-turn dialogues.
👉 Paper link: https://huggingface.co/papers/2604.25719

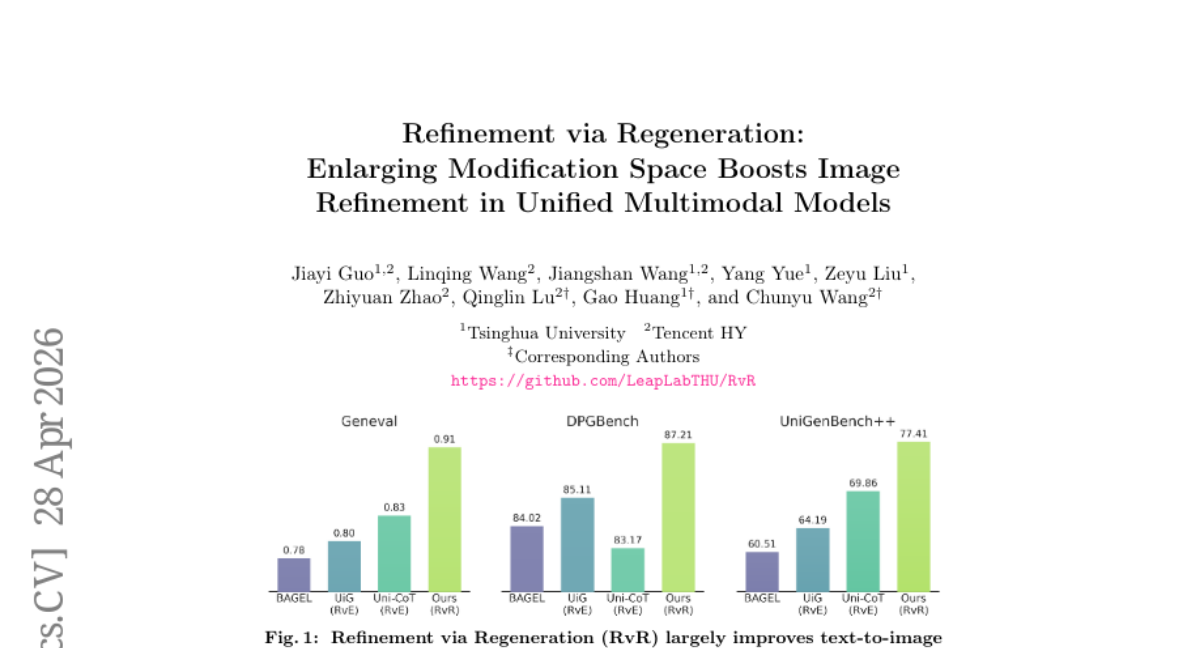
21. Refinement via Regeneration: Enlarging Modification Space Boosts Image Refinement in Unified Multimodal Models
🔑 Keywords: Refinement via Regeneration, Unified multimodal models, text-to-image, semantic alignment, conditional image regeneration
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve multi-modal model refinement by transitioning from editing-based approaches to conditional image regeneration, leading to better semantic alignment in text-to-image tasks.
🛠️ Research Methods:
– A novel framework called Refinement via Regeneration is proposed that refines images by regenerating them based on conditional inputs, avoiding traditional editing methods.
💬 Research Conclusions:
– Demonstrated significant improvement in evaluation metrics such as Geneval, DPGBench, and UniGenBench++, proving the efficacy of the RvR approach.
👉 Paper link: https://huggingface.co/papers/2604.25636
22. AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
🔑 Keywords: AI agents, AutoResearchBench, Deep Research, Wide Research, autonomous scientific research
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To present AutoResearchBench, a benchmark designed to evaluate AI agents’ capability in autonomous scientific literature discovery.
🛠️ Research Methods:
– Utilizes two task types: Deep Research, involving multi-step probing, and Wide Research, which requires comprehensive paper collection.
💬 Research Conclusions:
– AutoResearchBench sets a high difficulty benchmark, showing that powerful LLMs achieve low accuracy rates (9.39% in Deep Research and 9.31% in Wide Research) compared to previous benchmarks.
– Dataset, evaluation pipeline, and code are publicly released to encourage further research.
👉 Paper link: https://huggingface.co/papers/2604.25256

23. Programming with Data: Test-Driven Data Engineering for Self-Improving LLMs from Raw Corpora
🔑 Keywords: Programming with Data, structured knowledge representation, language models, domain-specific capabilities, data repair
💡 Category: Foundations of AI
🌟 Research Objective:
– To create a principled framework for systematically transferring human expertise into large language models using structured knowledge representation and systematic feedback.
🛠️ Research Methods:
– Training data is treated as source code, enabling unit testing and debugging to address model failures identified as concept-level gaps and reasoning-chain breaks.
💬 Research Conclusions:
– Demonstrates that the training data and model behavior relationship is traceable and repairable. This approach provides consistent improvements across different model scales and architectures without degrading general capabilities.
👉 Paper link: https://huggingface.co/papers/2604.24819
