AI Native Daily Paper Digest – 20260507
1. Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
🔑 Keywords: Video Diffusion Model, Reliability, Perplexity, Distillation, Visual Quality
💡 Category: Generative Models
🌟 Research Objective:
– Stream-R1 aims to enhance video diffusion model distillation by adaptively weighting supervision based on reliability and perplexity, improving visual quality, motion quality, and text alignment without extra computational cost.
🛠️ Research Methods:
– Introduces a Reliability-Perplexity Aware Reward Distillation framework, Stream-R1, which adaptively reweights the objective across rollout and spatiotemporal-element levels through a reward-guided mechanism.
💬 Research Conclusions:
– Stream-R1 consistently improves visual, motion quality, and text alignment in video generation compared to traditional distillation approaches, achieving this without architectural changes or additional inference costs.
👉 Paper link: https://huggingface.co/papers/2605.03849

2. RLDX-1 Technical Report
🔑 Keywords: RLDX-1, Multi-Stream Action Transformer, dexterous manipulation, modality integration, real-time deployment
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research introduces RLDX-1, a robotic policy designed for dexterous manipulation, to improve performance over existing Vision-Language-Action models in complex real-world tasks.
🛠️ Research Methods:
– Utilization of a Multi-Stream Action Transformer architecture to integrate heterogeneous modalities through modality-specific streams with cross-modal joint self-attention.
– Implementation of system-level design choices, including synthetic training data for rare scenarios and optimization for real-time deployment.
💬 Research Conclusions:
– RLDX-1 outperforms recent Vision-Language-Action models in both simulation benchmarks and real-world tasks, particularly achieving high success rates in humanoid tasks, indicating its advancements in controlling high-DoF humanoid robots under diverse demands.
👉 Paper link: https://huggingface.co/papers/2605.03269
3. HERMES++: Toward a Unified Driving World Model for 3D Scene Understanding and Generation
🔑 Keywords: HERMES++, 3D scene understanding, future geometry prediction, BEV representation, Large Language Models
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop HERMES++, a unified model integrating 3D scene understanding and future geometry prediction for autonomous driving.
🛠️ Research Methods:
– Utilizes BEV representation to integrate multi-view spatial information.
– Introduces LLM-enhanced queries and temporal linking to connect semantic and geometric understanding.
– Employs joint geometric optimization to align model predictions with geometry-aware priors.
💬 Research Conclusions:
– HERMES++ shows superior performance over specialized methods in future point cloud prediction and 3D scene understanding.
– The model and associated code will be open-sourced for further research and application.
👉 Paper link: https://huggingface.co/papers/2604.28196

4. Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
🔑 Keywords: BRIGHT-Pro, RTriever-Synth, Reasoning-intensive retrieval, Agentic search systems, LoRA fine-tuning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce BRIGHT-Pro to expand expert-annotated reasoning-intensive retrieval benchmarks and RTriever-Synth as an aspect-decomposed synthetic corpus to enhance retriever performance.
🛠️ Research Methods:
– Implement agentic search evaluation and LoRA fine-tuning on RTriever-4B from Qwen3-Embedding-4B using BRIGHT-Pro and RTriever-Synth.
💬 Research Conclusions:
– Aspect-aware and agentic evaluation methods reveal behaviors in retrievers not captured by standard metrics, and RTriever-4B shows substantial improvements over its base model.
👉 Paper link: https://huggingface.co/papers/2605.04018

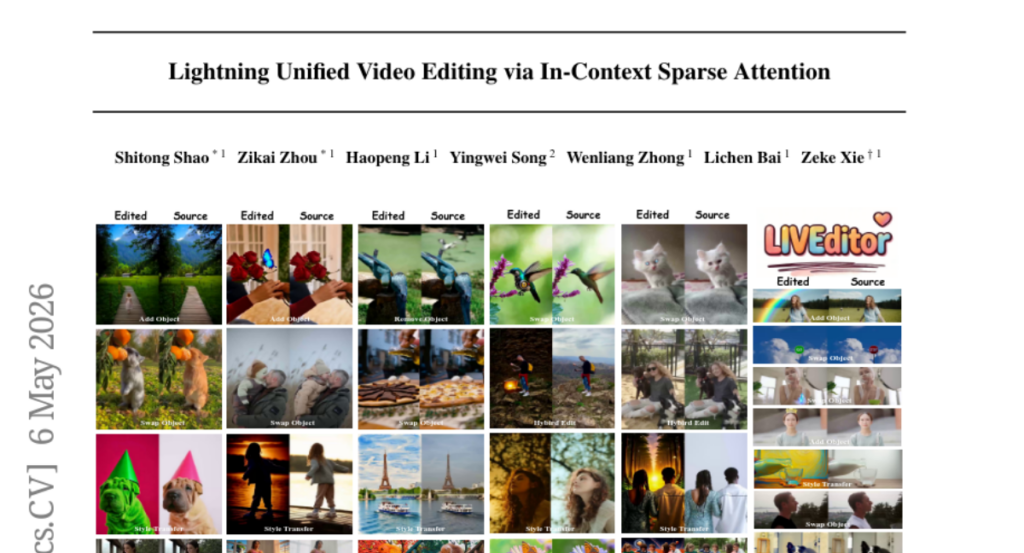
5. Lightning Unified Video Editing via In-Context Sparse Attention
🔑 Keywords: In-Context Learning, Video Editing, Sparse Attention, Query Sharpness, LIVEditor
💡 Category: Computer Vision
🌟 Research Objective:
– The study introduces In-context Sparse Attention (ISA), a framework designed to reduce computational costs and maintain visual quality in video editing using In-Context Learning paradigms.
🛠️ Research Methods:
– The ISA approach includes a pre-selection strategy that prunes redundant context and a dynamic query grouping mechanism. This mechanism routes high-error queries to full attention and low-error queries to a computationally efficient 0-th order Taylor sparse attention.
💬 Research Conclusions:
– LIVEditor, a model built using ISA and a specialized video-editing data pipeline, achieves a 60% reduction in attention-module latency while surpassing current state-of-the-art methods without compromising visual fidelity.
👉 Paper link: https://huggingface.co/papers/2605.04569
6. MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction
🔑 Keywords: MiniCPM-o 4.5, Omni-Flow, Real-time Streaming Interaction, Human-like Multimodal Interaction, Edge Devices
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– MiniCPM-o 4.5 aims to achieve real-time full-duplex multimodal interaction for more human-like AI engagement.
🛠️ Research Methods:
– Utilization of Omni-Flow, a unified streaming framework, aligning inputs and outputs temporally to enable simultaneous perception and response.
– Implementation involves an architecture design optimized for efficiency and low RAM cost on edge devices.
💬 Research Conclusions:
– MiniCPM-o 4.5 demonstrates superior performance in omni-modal understanding and speech generation, outperforming existing models like Qwen3-Omni-30B-A3B.
– The model exhibits proactive behavior in a multimodal environment and maintains computation efficiency with higher performance capabilities at its parameter scale.
👉 Paper link: https://huggingface.co/papers/2604.27393

7. ResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
🔑 Keywords: ResRL, Large Language Models (LLMs), negative sample projection, diversity, reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective of this research is to improve the reasoning capabilities of Large Language Models (LLMs) while maintaining diversity by decoupling semantic distributions between positive and negative responses using a method called ResRL.
🛠️ Research Methods:
– The method involves applying Residual Reinforcement Learning (ResRL) which uses negative sample projection to decouple similar semantic distributions among responses. This is achieved by linking Lazy Likelihood Displacement to mitigate head-gradient interference and using SVD-based low-rank positive subspace projection to enhance projection residuals.
💬 Research Conclusions:
– ResRL improves reasoning capabilities while preserving response diversity, outperforming existing methods on various benchmarks, including notable improvements in mathematical reasoning surpassing NSR’s performance on Avg@16 and Pass@128 scores.
👉 Paper link: https://huggingface.co/papers/2605.00380

8. APEX: Large-scale Multi-task Aesthetic-Informed Popularity Prediction for AI-Generated Music
🔑 Keywords: AI-generated music, Aesthetic Quality, Multi-task learning, Frozen Audio Embeddings, Music Popularity Prediction
💡 Category: Generative Models
🌟 Research Objective:
– Develop APEX, a large-scale multi-task learning framework for predicting both popularity and aesthetic quality of AI-generated music.
🛠️ Research Methods:
– Utilized frozen audio embeddings from MERT, a self-supervised music understanding model.
– Trained on a dataset comprising over 211k songs from Suno and Udio.
💬 Research Conclusions:
– APEX demonstrates strong generalization across different generative architectures.
– Incorporating aesthetic features improves preference prediction in out-of-distribution evaluations involving human preference battles.
👉 Paper link: https://huggingface.co/papers/2605.03395

9. MedSkillAudit: A Domain-Specific Audit Framework for Medical Research Agent Skills
🔑 Keywords: Medical Research Agent Skills, Audit Framework, Expert Review, AI in Healthcare, MedSkillAudit
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop and evaluate a domain-specific audit framework for assessing the reliability and readiness of medical research agent skills in healthcare applications.
🛠️ Research Methods:
– Developed MedSkillAudit, a layered framework assessing skill release readiness.
– Evaluated 75 skills across five medical research categories.
– Compared system-expert agreement using ICC and Cohen’s kappa with human inter-rater baseline.
💬 Research Conclusions:
– MedSkillAudit demonstrated higher reliability than human inter-rater assessments with an ICC of 0.449.
– Highlighted the practical benefits of domain-specific pre-deployment audits for medical research agent skills.
👉 Paper link: https://huggingface.co/papers/2604.20441

10. When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning
🔑 Keywords: Autoregressive Models, SxS Interleaved Reasoning, AI-generated Summary, Private Reasoning, Reinforcement Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to implement Side-by-Side (SxS) Interleaved Reasoning in autoregressive models to improve the accuracy and efficiency by controlling disclosure timing.
🛠️ Research Methods:
– The approach involves constructing entailment-aligned interleaved trajectories using answer prefixes matched with supporting reasoning prefixes, and training with SFT (Supervised Fine-Tuning) and RL (Reinforcement Learning).
💬 Research Conclusions:
– The SxS Interleaved Reasoning method improves the accuracy-content-latency Pareto trade-offs in various benchmarks, enhancing performance under the new format across different architectures and domains.
👉 Paper link: https://huggingface.co/papers/2605.03314

11. KinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
🔑 Keywords: KinDER, physical reasoning, kinematic constraints, dynamic constraints, reinforcement learning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce KinDER as a benchmark for Kinematic and Dynamic Embodied Reasoning, focusing on physical reasoning challenges in robot learning and planning.
🛠️ Research Methods:
– Utilized procedurally generated environments and baselines across multiple learning paradigms, including motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches.
💬 Research Conclusions:
– Empirical evaluation reveals that current methods struggle with many environments, highlighting substantial gaps in existing physical reasoning approaches. Additionally, real-to-sim-to-real experiments assess simulation and real-world interaction correspondence, with KinDER being open-sourced for systematic comparison in robotics.
👉 Paper link: https://huggingface.co/papers/2604.25788

12. Turning Drift into Constraint: Robust Reasoning Alignment in Non-Stationary Environments
🔑 Keywords: Autonomous Preference Optimization, reasoning alignment, multi-modal large language models, constraint-aware optimization, concept drift
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address reasoning alignment challenges in multi-modal large language models under conditions of concept drift, improving robustness and performance.
🛠️ Research Methods:
– Proposed a novel framework named Autonomous Preference Optimization (APO), treating inter-model divergences as dynamic negative constraints with a two-stage protocol involving supervised bootstrapping and constraint-aware optimization.
💬 Research Conclusions:
– Demonstrated superior robustness and accuracy in chest X-ray interpretation with the APO framework, outperforming proprietary source models. Released the CXR-MAX benchmark to support further research.
👉 Paper link: https://huggingface.co/papers/2510.04142

13.

14. TT4D: A Pipeline and Dataset for Table Tennis 4D Reconstruction From Monocular Videos
🔑 Keywords: 3D ball trajectories, learned lifting network, monocular broadcast videos, AI-generated summary, table tennis dataset
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a high-fidelity table tennis dataset (TT4D) reconstructed from monocular broadcast videos to enable virtual replay, player analysis, and robot learning.
🛠️ Research Methods:
– Utilize a novel reconstruction pipeline using a learned lifting network to transform unsegmented 2D ball tracks into 3D trajectories, aiding in time segmentation and spin estimation.
💬 Research Conclusions:
– The pipeline reliably reconstructs 3D ball trajectories and spin, even under high occlusion, and uniquely supports estimating racket pose & velocity and generative modeling of rallies from general-view videos.
👉 Paper link: https://huggingface.co/papers/2605.01234

15. CreativityBench: Evaluating Agent Creative Reasoning via Affordance-Based Tool Repurposing
🔑 Keywords: large language models, creative problem-solving, affordance reasoning, affordance-based creativity, CreativityBench
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate the creative problem-solving abilities of large language models, particularly in novel tool usage through affordance reasoning.
🛠️ Research Methods:
– Introduced CreativityBench, a benchmark for evaluating affordance-based creativity.
– Developed a large-scale affordance knowledge base with 4,000 entities and 150,000+ annotations.
– Constructed 14,000 grounded tasks requiring physically plausible solutions under constraints.
💬 Research Conclusions:
– Current models can select plausible objects but struggle with identifying specific parts and underlying physical mechanisms.
– Scaling models does not significantly enhance creative affordance discovery, indicating limits in current AI capabilities for novel tool use.
– CreativityBench offers a valuable platform for examining this aspect of intelligence, with implications for future AI planning and reasoning modules.
👉 Paper link: https://huggingface.co/papers/2605.02910

16. The First Token Knows: Single-Decode Confidence for Hallucination Detection
🔑 Keywords: first-token confidence, phi_first, semantic self-consistency, hallucinations, AUROC
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the effectiveness of first-token confidence (phi_first) in detecting hallucinations compared to semantic self-consistency and other methods.
🛠️ Research Methods:
– Comparison of phi_first calculated from the normalized entropy of top-K logits during greedy decode with semantic self-consistency across three instruction-tuned models and two benchmarks.
💬 Research Conclusions:
– Phi_first matches or exceeds semantic self-consistency in performance for closed-book short-answer factual question answering, showing it as a computationally efficient alternative.
– Phi_first presents a strong correlation with semantic agreement, suggesting that initial token distribution captures sufficient uncertainty information.
– Recommends phi_first as a baseline before utilizing sampling-based uncertainty estimation methods.
👉 Paper link: https://huggingface.co/papers/2605.05166

17. Diffusion Model as a Generalist Segmentation Learner
🔑 Keywords: Diffusion models, Semantic segmentation, Open-vocabulary segmentation, Latent space, CLIP-aligned text pathway
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to demonstrate that pretrained diffusion models can be adapted for semantic and open-vocabulary segmentation tasks across diverse domains.
🛠️ Research Methods:
– Utilizes a technique called DiGSeg (Diffusion Models as a Generalist Segmentation Learner), encoding input images and masks into latent space and using a diffusion U-Net. Integrates a parallel CLIP-aligned text pathway for language feature alignment.
💬 Research Conclusions:
– The research shows that modern diffusion backbones can serve as generalist segmentation learners, achieving state-of-the-art performance without the need for domain-specific architectural customization, thereby narrowing the gap between visual generation and understanding.
👉 Paper link: https://huggingface.co/papers/2604.24575

18. SWE-WebDevBench: Evaluating Coding Agent Application Platforms as Virtual Software Agencies
🔑 Keywords: SWE-WebDev Bench, AI-powered application development, Vibe Coding, Architectural Decisions
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces SWE-WebDev Bench to evaluate AI-powered application development platforms on multiple dimensions such as requirement understanding, architectural decision-making, and production readiness.
🛠️ Research Methods:
– Evaluation was conducted using a 68-metric framework spanning 25 primary and 43 diagnostic metrics across seven groups. The study assessed six platforms across three domains with a focus on interaction mode, agency angle, and complexity tier.
💬 Research Conclusions:
– Four main shortcomings in current AI app builders were highlighted: specification bottleneck, frontend-backend decoupling, steep production-readiness cliff, and security and infrastructure failures. SWE-WebDev Bench was released for community use to address these gaps.
👉 Paper link: https://huggingface.co/papers/2605.04637

19. Parameter-Efficient Multi-View Proficiency Estimation: From Discriminative Classification to Generative Feedback
🔑 Keywords: Multi-view Proficiency Estimation, SkillFormer, PATS, ProfVLM, Interpretable Feedback Generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to estimate how well a person performs an action rather than identifying the action itself, which is vital for coaching, rehabilitation, and talent identification.
🛠️ Research Methods:
– Introduced three methods for multi-view proficiency estimation: SkillFormer, PATS, and ProfVLM, leveraging parameter-efficient architectures, improved temporal sampling, and reformulated proficiency estimation.
💬 Research Conclusions:
– The methods demonstrate state-of-the-art accuracy on Ego-Exo4D with significant reductions in parameters and training epochs. They highlight a shift toward efficient, multi-view systems that prioritize selective fusion, proficiency-aware sampling, and provide actionable generative feedback.
👉 Paper link: https://huggingface.co/papers/2605.03848

20. Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
🔑 Keywords: JoyAI-Image, Multimodal Large Language Model, Multimodal Diffusion Transformer, Spatial Intelligence, Controllable Visual Synthesis
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– JoyAI-Image aims to achieve unified visual understanding, text-to-image generation, and instruction-guided image editing with enhanced spatial intelligence.
🛠️ Research Methods:
– The model integrates a spatially enhanced Multimodal Large Language Model (MLLM) with a Multimodal Diffusion Transformer (MMDiT), employing a scalable training strategy that includes unified instruction tuning, long-text rendering supervision, and spatially grounded data.
💬 Research Conclusions:
– JoyAI-Image shows state-of-the-art or highly competitive performance across various tasks, enhancing geometry-aware reasoning and controllable visual synthesis, and offers a promising path for applications in vision-language-action systems and world models.
👉 Paper link: https://huggingface.co/papers/2605.04128

21. D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
🔑 Keywords: D-OPSD, Supervised Fine-tuning, Few-step Inference, On-policy Learning, Multimodal Features
💡 Category: Generative Models
🌟 Research Objective:
– To develop a novel training approach, D-OPSD, that facilitates efficient supervised fine-tuning of diffusion models while preserving few-step inference capabilities.
🛠️ Research Methods:
– Implementing on-policy self-distillation by having the model act as both teacher and student with distinct contexts, utilizing text and multimodal features during training.
💬 Research Conclusions:
– D-OPSD enables diffusion models to learn new concepts and styles without compromising their original few-step inference capacity.
👉 Paper link: https://huggingface.co/papers/2605.05204

22. PhysForge: Generating Physics-Grounded 3D Assets for Interactive Virtual World
🔑 Keywords: PhysForge, Hierarchical Physical Blueprint, physics-grounded diffusion model, KineVoxel Injection
💡 Category: Generative Models
🌟 Research Objective:
– To overcome the limitations of static geometry by creating interactively functional 3D assets through physics-grounded synthesis.
🛠️ Research Methods:
– Developed a decoupled two-stage framework including a Visual-Language Model (VLM) for planning and a physics-grounded diffusion model for synthesis, supported by a large-scale dataset, PhysDB.
💬 Research Conclusions:
– PhysForge successfully produces functionally plausible, simulation-ready 3D assets, enhancing the potential for interactive virtual worlds and embodied AI.
👉 Paper link: https://huggingface.co/papers/2605.05163
23. OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
🔑 Keywords: OpenSearch-VL, multimodal search agents, reinforcement learning, Wiki path sampling, tool environment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop an open-source framework for training advanced multimodal search agents using reinforcement learning, emphasizing the creation of high-quality data and new training algorithms.
🛠️ Research Methods:
– Introduced a pipeline for data curation using techniques like Wikipedia path sampling and source-anchor visual grounding.
– Designed a diverse tool environment that integrates text and image search, as well as various image processing techniques.
– Developed a multi-turn fatal-aware GRPO training algorithm to manage tool failures effectively.
💬 Research Conclusions:
– OpenSearch-VL successfully enhances performance with over 10-point average improvements across multiple benchmarks, achieving results comparable to proprietary models. The release of data, code, and models supports open research in this domain.
👉 Paper link: https://huggingface.co/papers/2605.05185

24. Stream-T1: Test-Time Scaling for Streaming Video Generation
🔑 Keywords: Streaming Video Generation, Temporal Guidance, Diffusion Models, TTS, Temporal Dependency
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve test-time video generation efficiency by addressing the structural bottlenecks of diffusion model-based methods through the introduction of Stream-T1, a streaming video generation framework.
🛠️ Research Methods:
– The Stream-T1 framework includes three components: Stream-Scaled Noise Propagation for temporal dependency, Stream-Scaled Reward Pruning for optimal balance between aesthetics and coherence, and Stream-Scaled Memory Sinking for effective guidance of subsequent video streams.
💬 Research Conclusions:
– Evaluations on video benchmarks indicate that Stream-T1 significantly enhances temporal consistency, motion smoothness, and frame-level visual quality compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2605.04461
