AI Native Daily Paper Digest – 20260508

1. Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
🔑 Keywords: Skill1, skill selection, skill library, task-outcome objective, reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Develop Skill1, a unified framework that trains a single policy for skill selection, utilization, and distillation, achieving superior performance in complex tasks.
🛠️ Research Methods:
– Skill1 framework co-evolves skills by generating queries, re-ranking skill library candidates, solving tasks, and distilling new skills based on a shared task-outcome objective.
💬 Research Conclusions:
– Skill1 outperforms existing skill-based and reinforcement learning models in environments like ALFWorld and WebShop, with evidence showing the effective co-evolution of capabilities.
👉 Paper link: https://huggingface.co/papers/2605.06130

2. Continuous Latent Diffusion Language Model
🔑 Keywords: Hierarchical Latent Diffusion Language Model, Non-autoregressive Inductive Bias, Global Semantic Prior, Text Generation, Scaling Behavior
💡 Category: Generative Models
🌟 Research Objective:
– To propose Cola DLM, a hierarchical latent diffusion language model, as a principled alternative for efficient text generation, moving beyond traditional autoregressive paradigms.
🛠️ Research Methods:
– Utilized a hierarchical information decomposition approach with text-to-latent mapping, global semantic prior modeling, and conditional decoding.
– Conducted experiments with comparisons to autoregressive and LLaDA baselines across 8 benchmarks and 4 research questions.
💬 Research Conclusions:
– Cola DLM successfully demonstrates flexible non-autoregressive inductive bias, supports semantic compression, and extends across continuous modalities.
– The results suggest hierarchical continuous latent prior modeling may offer superior generation quality and scaling behavior than token-level approaches, pointing towards unified modeling for discrete and continuous modalities.
👉 Paper link: https://huggingface.co/papers/2605.06548

3. RaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation
🔑 Keywords: Heterogeneous Ensemble, Large Language Models, GPT-4o-mini, AI-Generated Summary, Domain-Adapted Model
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aimed to achieve top performance in the SemEval-2026 MTRAGEval task using a diverse ensemble of language models with dual prompting strategies.
🛠️ Research Methods:
– A heterogeneous ensemble of seven large language models was employed, featuring different prompting variants. A GPT-4o-mini judge selected the best candidate per instance.
💬 Research Conclusions:
– The model diversity was crucial for performance, consistently outperforming any single model. Introduction of Meno-Lite-0.1 highlighted a strong cost-performance trade-off, and the study provided insights into MTRAGEval annotation limitations and potential improvements.
👉 Paper link: https://huggingface.co/papers/2605.04523

4. When to Trust Imagination: Adaptive Action Execution for World Action Models
🔑 Keywords: World Action Models, Future-Reality Verification, Adaptive WAM Execution, Future Forward Dynamics Causal Attention, Mixture-of-Horizon Training
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enhance the execution of World Action Models (WAMs) by introducing adaptive mechanisms that ensure the predicted future remains consistent with real-world observations.
🛠️ Research Methods:
– Implementation of Future Forward Dynamics Causal Attention (FFDC) to verify consistency between predicted and real observations, enabling adaptive action execution.
– Introduction of Mixture-of-Horizon Training to improve the coverage of long-horizon trajectories in robotic manipulation.
💬 Research Conclusions:
– The proposed method improves the robustness-efficiency trade-off, reducing WAM forward passes and execution time while increasing the success rate in both benchmark and real-world experiments.
👉 Paper link: https://huggingface.co/papers/2605.06222

5. SkillOS: Learning Skill Curation for Self-Evolving Agents
🔑 Keywords: SkillOS, self-evolving agents, skill curation, composite rewards, SkillRepo
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to develop SkillOS, a reinforcement learning framework for enabling self-evolving LLM agents to learn complex long-term skill curation policies that improve performance across diverse tasks and executor architectures.
🛠️ Research Methods:
– SkillOS pairs a frozen agent executor with a trainable skill curator, utilizing composite rewards and grouped task streams to learn from skill-relevant task dependencies, updating an external SkillRepo based on experience.
💬 Research Conclusions:
– SkillOS consistently surpasses both memory-free and memory-based baselines in effectiveness and efficiency, with learnings from the skill curator generalizing well across different executor backbones and task domains, producing more targeted skill use and evolving higher-level meta-skills.
👉 Paper link: https://huggingface.co/papers/2605.06614

6. Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes
🔑 Keywords: empirical loop, lineage feedback, specialist agents, program-level recipe edits, AI-generated summary
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Investigate an empirical loop that autonomously refines code through external evaluation feedback without human intervention.
🛠️ Research Methods:
– Utilize specialist agents to create trials that include code edits and evaluations, iterating over an auditable trajectory of proposals and experiments.
💬 Research Conclusions:
– Demonstrated significant improvements in various tasks such as Parameter Golf validation, NanoChat-D12 CORE, and CIFAR-10 Airbench96 wallclock time without human proposal or intervention.
👉 Paper link: https://huggingface.co/papers/2605.05724

7. Audio-Visual Intelligence in Large Foundation Models
🔑 Keywords: Audio-Visual Intelligence, large foundation models, multimodal data, cross-modal fusion, Audio-Visual Intelligence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to provide a comprehensive review of Audio-Visual Intelligence (AVI) through the lens of large foundation models, establishing a unified taxonomy for understanding, generation, and interaction tasks within this multidisciplinary field.
🛠️ Research Methods:
– The survey synthesizes methodological foundations such as modality tokenization, cross-modal fusion, autoregressive and diffusion-based generation, and large-scale pretraining, among others, to structure and integrate diverse tasks and practices in AVI.
💬 Research Conclusions:
– A coherent framework is established offering structured comparisons across task families, identifying open challenges in synchronization, spatial reasoning, controllability, and safety. The survey underscores the importance of unified audio-vision architectures for future research in large-scale AVI.
👉 Paper link: https://huggingface.co/papers/2605.04045

8. Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key
🔑 Keywords: ScaleLogic, Reinforcement Learning, Logical Reasoning, Scaling Exponent, Curriculum-Based Training
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to systematically study the scaling of reinforcement learning training compute with task difficulty using a new framework, ScaleLogic.
🛠️ Research Methods:
– Introduced ScaleLogic, a synthetic logical reasoning framework, allowing independent control over reasoning depth and logical expressiveness. Analysis conducted on the scaling of reinforcement learning with these factors.
💬 Research Conclusions:
– Reinforcement Learning compute scales by a power law with reasoning depth, with scaling exponent increasing with logical expressiveness. More expressive training leads to larger performance gains and compute efficiency in downstream tasks.
👉 Paper link: https://huggingface.co/papers/2605.06638

9. ReflectDrive-2: Reinforcement-Learning-Aligned Self-Editing for Discrete Diffusion Driving
🔑 Keywords: ReflectDrive-2, autonomous driving, discrete diffusion planner, reinforcement learning, trajectory revision
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study introduces ReflectDrive-2, aiming to improve autonomous driving by enabling efficient trajectory revision through a masked discrete diffusion planner and parallel decoding.
🛠️ Research Methods:
– Utilizes a two-stage training approach, combining structure-aware perturbations to refine trajectories and reinforcement learning to enhance trajectory revision and decision-making.
– Implements a decision–draft–reflect pipeline co-designed with a reflective decoding stack to optimize performance.
💬 Research Conclusions:
– ReflectDrive-2 demonstrates significant improvement in PDMS performance, reaching 91.0 with camera-only input and 94.8 in an oracle setup using NAVSIM, with a low average latency of 31.8 ms on NVIDIA Thor.
👉 Paper link: https://huggingface.co/papers/2605.04647

10. SwiftI2V: Efficient High-Resolution Image-to-Video Generation via Conditional Segment-wise Generation
🔑 Keywords: SwiftI2V, High-resolution I2V, Conditional Segment-wise Generation, bidirectional contextual interaction, token budget
💡 Category: Generative Models
🌟 Research Objective:
– The main objective of this research is to develop an efficient high-resolution image-to-video (I2V) generation framework that addresses existing challenges and achieves scalable, input-faithful video synthesis with reduced computational requirements.
🛠️ Research Methods:
– SwiftI2V employs a two-stage design with Conditional Segment-wise Generation to synthesize videos segment-by-segment, using a bounded per-step token budget to improve efficiency.
– The approach utilizes bidirectional contextual interaction to enhance cross-segment coherence and input fidelity.
💬 Research Conclusions:
– SwiftI2V significantly reduces the computational load, achieving a 202x reduction in total GPU-time, and enables practical 2K I2V generation on both datacenter and consumer GPUs, maintaining performance comparable to end-to-end baselines.
👉 Paper link: https://huggingface.co/papers/2605.06356
11. RemoteZero: Geospatial Reasoning with Zero Human Annotations
🔑 Keywords: RemoteZero, Geospatial Reasoning, MLLM, Self-Evolution, Semantic Verification
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce RemoteZero to enable geospatial reasoning without box supervision, utilizing semantic verification capabilities of MLLMs to improve localization from unlabeled remote sensing data.
🛠️ Research Methods:
– Leverage the discriminative ability of MLLMs for semantic verification instead of traditional geometric supervision to facilitate GRPO training without box annotations.
💬 Research Conclusions:
– RemoteZero achieves competitive performance against strong supervised methods, showcasing the potential of self-verifying training for geospatial reasoning and localization.
👉 Paper link: https://huggingface.co/papers/2605.04451

12. The Scaling Properties of Implicit Deductive Reasoning in Transformers
🔑 Keywords: Deep Transformers, bidirectional masking, implicit deductive reasoning, Horn clauses, algorithmic alignment
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To investigate the scaling properties of implicit deductive reasoning in depth-bounded Transformers using bidirectional masking.
🛠️ Research Methods:
– Systematic decorrelation of provability from spurious features and enforcing algorithmic alignment in deep models.
💬 Research Conclusions:
– Implicit reasoning in sufficiently deep models with bidirectional prefix masking can closely match explicit chain-of-thought performance across various graph structures and problem sizes. However, explicit chain-of-thought methods remain necessary for depth extrapolation.
👉 Paper link: https://huggingface.co/papers/2605.04330

13. Prescriptive Scaling Laws for Data Constrained Training
🔑 Keywords: Data-Constrained Regimes, Overfitting Penalty, Compute-Optimal Allocation, Weight Decay, Scaling Law
💡 Category: Machine Learning
🌟 Research Objective:
– The research objective is to modify the Chinchilla scaling law to account for data repetition effects and provide compute-optimal training strategies in data-constrained scenarios.
🛠️ Research Methods:
– The methods involve modeling excess loss under data repetition with an additive overfitting penalty, allowing for adjustments in compute allocation.
💬 Research Conclusions:
– The study finds that further data repetition is counterproductive after a certain point, and resources are better allocated to model capacity. The research also concludes that strong weight decay significantly reduces the overfitting coefficient, aligning with recent findings in data-constrained regimes.
👉 Paper link: https://huggingface.co/papers/2605.01640

14. PianoCoRe: Combined and Refined Piano MIDI Dataset
🔑 Keywords: PianoCoRe, music information retrieval, MIDI, note-level alignment, expressive performance modeling
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study introduces PianoCoRe, a large-scale piano MIDI dataset, to enhance applications in music information retrieval by providing diverse performances and note-level alignments.
🛠️ Research Methods:
– The authors curated and refined major open-source piano corpora, resulting in a dataset with 250,046 performances and tiered subsets to support various applications. They also developed a MIDI quality classifier and the RAScoP alignment refinement pipeline.
💬 Research Conclusions:
– PianoCoRe reduces temporal noise and eliminates tempo outliers, showing improved robustness in expressive performance modeling compared to models trained on smaller datasets. This positions PianoCoRe as a comprehensive resource for future piano performance research.
👉 Paper link: https://huggingface.co/papers/2605.06627
15. Are We Making Progress in Multimodal Domain Generalization? A Comprehensive Benchmark Study
🔑 Keywords: Multimodal Domain Generalization, AI-generated summary, action recognition, sentiment analysis, neural networks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduction of MMDG-Bench, a unified benchmark for evaluating Multimodal Domain Generalization (MMDG) across diverse tasks and modalities.
🛠️ Research Methods:
– Standardized evaluation using six datasets across three tasks: action recognition, mechanical fault diagnosis, and sentiment analysis. It involves six modality combinations and nine representative methods, with systematic assessment criteria including corruption robustness and missing-modality generalization.
💬 Research Conclusions:
– Specialized MMDG methods show only marginal improvements over the ERM baseline.
– No single method consistently outperforms across all settings, with a significant performance gap remaining.
– Trimodal fusion does not consistently surpass bimodal configurations.
– All methods suffer notably under corruption and missing-modality scenarios, affecting model trustworthiness.
👉 Paper link: https://huggingface.co/papers/2605.06643

16. EDU-CIRCUIT-HW: Evaluating Multimodal Large Language Models on Real-World University-Level STEM Student Handwritten Solutions
🔑 Keywords: MLLMs, handwritten solutions, auto-grading, upstream recognition, AI-enabled grading system
💡 Category: AI in Education
🌟 Research Objective:
– The study aims to evaluate the capabilities of Multimodal Large Language Models (MLLMs) in interpreting complex STEM handwritten student solutions to improve educational grading systems.
🛠️ Research Methods:
– Released EDU-CIRCUIT-HW dataset with 1,300+ authentic handwritten student solutions.
– Conducted evaluations using expert-verified transcriptions and grading reports, assessing both upstream recognition fidelity and downstream auto-grading performance of various MLLMs.
💬 Research Conclusions:
– MLLMs exhibit significant limitations in understanding complex handwritten logic, affecting their reliability for auto-grading.
– A proposed hybrid approach, combining error detection with minimal human oversight, can enhance AI-enabled grading robustness.
👉 Paper link: https://huggingface.co/papers/2602.00095

17. Generative Quantum-inspired Kolmogorov-Arnold Eigensolver
🔑 Keywords: Quantum Chemistry, Kolmogorov-Arnold eigensolver, Quantum-inspired, HPC, Strongly Correlated Systems
💡 Category: Quantum Machine Learning
🌟 Research Objective:
– The study aims to reduce classical computational overhead in quantum chemistry workflows while maintaining accuracy and improving convergence for strongly correlated systems using a generative quantum-inspired Kolmogorov-Arnold eigensolver (GQKAE).
🛠️ Research Methods:
– GQKAE is a parameter-efficient extension of the generative quantum eigensolver, replacing parameter-heavy networks with hybrid quantum-inspired Kolmogorov-Arnold modules. It utilizes single-qubit DatA Re-Uploading ActivatioN modules for expressive mappings.
💬 Research Conclusions:
– GQKAE achieves chemical accuracy comparable to GPT-based architectures while reducing trainable parameters and memory by approximately 66%. It also enhances convergence and final energy errors for strongly correlated systems like N2 and LiH, offering a scalable approach for HPC-quantum co-design on near-term quantum platforms.
👉 Paper link: https://huggingface.co/papers/2605.04604

18. Sparkle: Realizing Lively Instruction-Guided Video Background Replacement via Decoupled Guidance
🔑 Keywords: Background Replacement, Video Editing, Foreground-Background Interactions, Data Synthesis, Evaluation Benchmark
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a new dataset and benchmark for background replacement in video editing, addressing the limitations in existing datasets with a scalable pipeline.
🛠️ Research Methods:
– Designed a pipeline that decouples foreground and background guidance with strict quality filtering to generate high-quality datasets.
💬 Research Conclusions:
– Sparkle dataset and the model trained on it show substantially better performance than existing baselines on both OpenVE-Bench and Sparkle-Bench, filling a significant gap in background replacement tasks.
👉 Paper link: https://huggingface.co/papers/2605.06535

19. TIDE: Every Layer Knows the Token Beneath the Context
🔑 Keywords: TIDE, EmbeddingMemory, Rare Token Problem, Contextual Collapse Problem
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address limitations in large language model (LLM) design by introducing TIDE to mitigate the Rare Token and Contextual Collapse Problems.
🛠️ Research Methods:
– TIDE augments the transformer with an EmbeddingMemory system which involves independent MemoryBlocks that map token indices to context-free semantic vectors, injected at each layer through a depth-conditioned softmax router.
💬 Research Conclusions:
– TIDE effectively addresses issues related to single-token identity injection, enhancing performance in language modeling and various downstream tasks.
👉 Paper link: https://huggingface.co/papers/2605.06216

20.

21. BioTool: A Comprehensive Tool-Calling Dataset for Enhancing Biomedical Capabilities of Large Language Models
🔑 Keywords: Biomedical tool-calling, Large Language Model, AI Native, Fine-tuning, BioTool
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop BioTool, a comprehensive biomedical tool-calling dataset aimed at improving the performance of large language models (LLMs) in specialized biomedical domains.
🛠️ Research Methods:
– Fine-tuning a 4-billion-parameter LLM on the BioTool dataset, which includes 34 tools and 7,040 human-verified API call pairs covering areas like genomics and proteomics.
💬 Research Conclusions:
– BioTool fine-tuning significantly boosts LLM performance in biomedical tool-calling, surpassing commercial alternatives like GPT-5.1, and enhances downstream answer quality as per human expert evaluations.
👉 Paper link: https://huggingface.co/papers/2605.05758

22. Recovering Hidden Reward in Diffusion-Based Policies
🔑 Keywords: EnergyFlow, inverse reinforcement learning, reward extraction, policy generalization, structural constraints
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces EnergyFlow, a framework designed to unify generative action modeling with inverse reinforcement learning to enhance reward extraction and policy generalization.
🛠️ Research Methods:
– The authors parameterize a scalar energy function with its gradient acting as a denoising field, facilitating reward extraction without adversarial training.
– The framework capitalizes on maximum-entropy optimality and denoising score matching to recover expert’s soft Q-function gradients.
💬 Research Conclusions:
– EnergyFlow achieves state-of-the-art performance in imitation tasks and provides a robust reward signal for reinforcement learning, outperforming traditional IRL methods.
– Structural constraints aid in reducing hypothesis complexity and improving out-of-distribution generalization, serving as inductive biases for policy generalization.
👉 Paper link: https://huggingface.co/papers/2605.00623

23. When No Benchmark Exists: Validating Comparative LLM Safety Scoring Without Ground-Truth Labels
🔑 Keywords: Safety Scoring, Scenario-Based Audit, Instrumental-Validity Chain, AUROC, Local-First Scoring
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to establish a method for benchmarkless comparative safety scoring to evaluate language model safety in the absence of pre-existing labeled benchmarks.
🛠️ Research Methods:
– Utilizes scenario-based audits and an instrumental-validity chain to assess responsiveness, variance dominance, and stability. Demonstrated with a local-first scoring instrument, SimpleAudit, validated on a Norwegian safety pack.
💬 Research Conclusions:
– The research demonstrates that in the Norwegian public-sector case, safety assessments vary based on scenario category and risk measure. It stresses that scores and related metrics must be reported collectively for meaningful deployment evidence.
👉 Paper link: https://huggingface.co/papers/2605.06652

24. GeoStack: A Framework for Quasi-Abelian Knowledge Composition in VLMs
🔑 Keywords: GeoStack, Vision-Language Models, domain experts, adapter manifold, catastrophic forgetting
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address the challenge of knowledge composition in Vision-Language Models without causing catastrophic forgetting by using GeoStack.
🛠️ Research Methods:
– Introduce a modular framework, GeoStack, which enforces geometric and structural constraints on adapter manifolds.
– Demonstrate a weight-folding property that ensures O(1) inference complexity regardless of the number of domain experts integrated.
💬 Research Conclusions:
– GeoStack effectively provides long-term knowledge composition, significantly mitigating catastrophic forgetting while enabling efficient multi-domain adaptation and class-incremental learning.
👉 Paper link: https://huggingface.co/papers/2605.06477

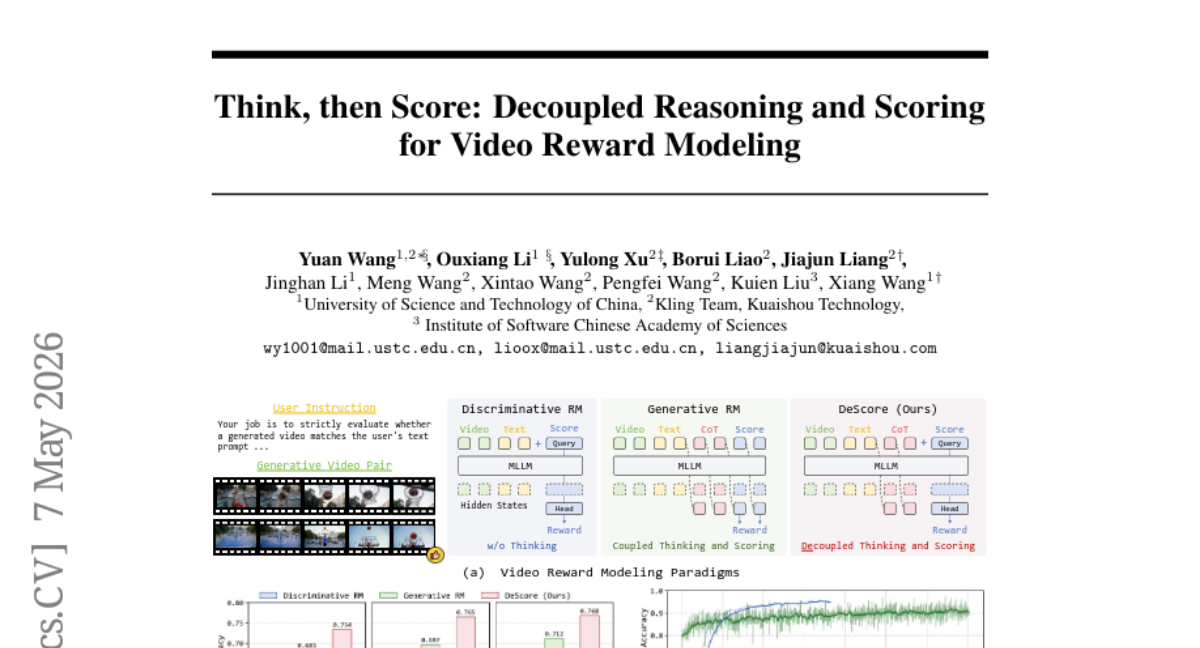
25. Think, then Score: Decoupled Reasoning and Scoring for Video Reward Modeling
🔑 Keywords: video reward models, Chain-of-Thought reasoning, decoupled think-then-score, reinforcement learning, multimodal large language models
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance the training efficiency and generalization of video reward models by decoupling the thinking and scoring processes.
🛠️ Research Methods:
– The researchers introduced DeScore, a two-stage framework that includes a discriminative cold start with a random mask mechanism and dual-objective reinforcement learning.
💬 Research Conclusions:
– DeScore improves interpretability and generalization by using a “think-then-score” paradigm, enhancing the model’s reasoning quality and ensuring alignments with human preferences.
👉 Paper link: https://huggingface.co/papers/2605.05922
26. Balanced Aggregation: Understanding and Fixing Aggregation Bias in GRPO
🔑 Keywords: Balanced Aggregation, Reinforcement Learning, Token-Level Policy Gradient, Training Stability, Final Performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reinforcement learning with verifiable rewards by addressing optimization biases in token-level policy gradient aggregation.
🛠️ Research Methods:
– Implementation of Balanced Aggregation, computing token-level means within positive and negative subsets and combining them with sequence-count-based weights.
💬 Research Conclusions:
– Balanced Aggregation improves training stability and performance over standard token and sequence aggregation, highlighting the critical role of aggregation in GRPO-style reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2605.04077

27. KernelBench-X: A Comprehensive Benchmark for Evaluating LLM-Generated GPU Kernels
🔑 Keywords: KernelBench-X, Triton kernel generation, correctness, iterative refinement, hardware efficiency
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To investigate where LLM-generated Triton kernel generation capability breaks down and why, utilizing the KernelBench-X benchmark.
🛠️ Research Methods:
– Systematic comparison of five representative methods across 176 tasks in 15 categories focusing on category-aware evaluation of correctness and hardware efficiency.
💬 Research Conclusions:
– Task structure affects kernel correctness more than method design.
– Iterative refinement improves correctness but at the cost of performance.
– Correctness does not guarantee efficiency; significant variance in kernel performance.
👉 Paper link: https://huggingface.co/papers/2605.04956

28. The Granularity Axis: A Micro-to-Macro Latent Direction for Social Roles in Language Models
🔑 Keywords: Large language models (LLMs), social roles, Granularity Axis, hidden states, activation steering
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate whether large language models encode the granularity of social roles, ranging from individual to organizational levels, in their internal representations.
🛠️ Research Methods:
– Define a contrast-based Granularity Axis to analyze role representation space and perform projections of role-level hidden states.
– Conduct experiments with Qwen3-8B and Llama-3.1-8B-Instruct, constructing 75 social roles across five granularity levels and collecting 91,200 role-conditioned responses.
💬 Research Conclusions:
– The study finds that social role granularity is a structured and causally manipulable latent direction in the behavior of language models.
– Activation steering along the Granularity Axis effectively shifts response granularity, with differences in controllability between models suggesting variability in default operating regimes.
👉 Paper link: https://huggingface.co/papers/2605.06196

29. AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
🔑 Keywords: AI co-mathematician, mathematical workflows, theorem proving, stateful workspace, problem-solving benchmarks
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To create an interactive platform, AI co-mathematician, that assists mathematicians in open-ended research utilizing AI agents.
🛠️ Research Methods:
– Provides a holistic support system for workflows including ideation, literature search, theorem proving, and theory building through a stateful, asynchronous workspace.
💬 Research Conclusions:
– The AI co-mathematician successfully aids researchers in solving open problems, discovering new research directions, and identifying overlooked literature. It achieves state-of-the-art results, including a 48% score on FrontierMath Tier 4 benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.06651

30. TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
🔑 Keywords: TabEmbed, Tabular Embedding Benchmark, Semantic Matching, Contrastive Learning, Universal Tabular Representation Learning
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce TabEmbed, a generalist embedding model for unifying tabular classification and retrieval within a shared embedding space.
🛠️ Research Methods:
– Employ large-scale contrastive learning with positive-aware hard negative mining to address tabular tasks reformulated as semantic matching problems.
💬 Research Conclusions:
– TabEmbed significantly outperforms existing text embedding models on TabBench, setting a new standard for universal tabular representation learning.
👉 Paper link: https://huggingface.co/papers/2605.04962

31. UniPool: A Globally Shared Expert Pool for Mixture-of-Experts
🔑 Keywords: Mixture-of-Experts, Shared Expert Pool, Stable Routing, Parameter Growth, Depth Scaling
💡 Category: Machine Learning
🌟 Research Objective:
– The goal of this research is to introduce UniPool, a novel shared expert pool architecture for Mixture-of-Experts (MoE) models, aimed at reducing parameter growth with depth while maintaining or improving model performance.
🛠️ Research Methods:
– UniPool employs a global shared pool of expert capacity, accessed via independent per-layer routers. The design incorporates stable and balanced training mechanisms, including a pool-level auxiliary loss and the NormRouter for scale-stable routing.
💬 Research Conclusions:
– UniPool consistently improves validation loss and perplexity over conventional MoE baselines across various model scales, demonstrating that expert parameters can grow sublinearly under a shared-pool architecture, enhancing efficiency and effectiveness without linear parameter expansion.
👉 Paper link: https://huggingface.co/papers/2605.06665

32. A^2TGPO: Agentic Turn-Group Policy Optimization with Adaptive Turn-level Clipping
🔑 Keywords: Reinforcement Learning, Agentic LLMs, Information Gain, Policy Optimization, Adaptive Turn-level Clipping
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve policy optimization for agentic large language models (LLMs) experiencing sparse rewards and credit assignment issues through a novel approach, A²TGPO.
🛠️ Research Methods:
– Utilizes Information Gain as an intrinsic process signal while introducing turn-group normalization, variance-rescaled discounted accumulation, and adaptive turn-level clipping to optimize policy updates.
💬 Research Conclusions:
– The proposed A²TGPO method effectively redesigns the process of information gain normalization, accumulation, and clipping to better evaluate and optimize policy in reinforcement learning for agentic LLMs.
👉 Paper link: https://huggingface.co/papers/2605.06200

33. StraTA: Incentivizing Agentic Reinforcement Learning with Strategic Trajectory Abstraction
🔑 Keywords: Strategic Trajectory Abstraction, trajectory-level strategy, reinforcement learning, sample efficiency, final performance
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce a framework named Strategic Trajectory Abstraction (StraTA) to enhance long-horizon decision making in large language models.
🛠️ Research Methods:
– Implementation of StraTA that uses a combination of trajectory-level strategy and hierarchical GRPO-style rollout design, with enhancements like diverse strategy rollout and critical self-judgment.
💬 Research Conclusions:
– StraTA significantly improves sample efficiency and performance, achieving high success rates of 93.1% on ALFWorld and 84.2% on WebShop, and a 63.5% overall score in SciWorld, surpassing existing strong baselines.
👉 Paper link: https://huggingface.co/papers/2605.06642

34. Nonsense Helps: Prompt Space Perturbation Broadens Reasoning Exploration
🔑 Keywords: Reinforcement Learning, verifiable rewards, Large Language Models, zero-advantage problem, Lorem Perturbation for Exploration
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to address the zero-advantage problem in reinforcement learning when training Large Language Models by introducing a novel approach called Lorem Perturbation for Exploration (LoPE).
🛠️ Research Methods:
– The research proposes using prompt-space perturbations by prepending sequences from the Lorem Ipsum vocabulary to prompts to enhance exploration in model training across various model sizes (1.7B, 4B, and 7B).
💬 Research Conclusions:
– LoPE significantly improves exploration success rates compared to conventional resampling methods, establishing itself as an effective baseline for enhancing exploration in LLM reinforcement learning applications.
👉 Paper link: https://huggingface.co/papers/2605.05566

35. Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
🔑 Keywords: Continuous-Time Distribution Matching, diffusion model distillation, velocity field extrapolation, visual fidelity.
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces Continuous-Time Distribution Matching (CDM) to transition diffusion model distillation from discrete to continuous optimization.
🛠️ Research Methods:
– Two continuous-time designs, including a dynamic continuous schedule and continuous-time alignment objective, are utilized to enforce distribution matching at arbitrary points on sampling trajectories.
💬 Research Conclusions:
– CDM enhances visual fidelity for few-step image generation without complex auxiliary objectives, as evidenced by experiments on architectures like SD3-Medium and Longcat-Image.
👉 Paper link: https://huggingface.co/papers/2605.06376

36. MARBLE: Multi-Aspect Reward Balance for Diffusion RL
🔑 Keywords: MARBLE, multi-reward reinforcement learning, diffusion models, quadratic programming, policy gradients
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To address limitations in multi-reward reinforcement learning fine-tuning of diffusion models by leveraging a gradient-space optimization framework without manual reward weighting.
🛠️ Research Methods:
– Implementation of MARBLE, which maintains independent advantage estimators and harmonizes policy gradients through solving a quadratic programming problem. Introduces an amortized formulation to reduce computational costs while stabilizing updates with EMA smoothing.
💬 Research Conclusions:
– MARBLE improves alignment across all reward dimensions on a test model with five rewards, turning the worst-aligned reward’s gradient cosine consistently positive in the majority of mini-batches, while maintaining nearly baseline training speed.
👉 Paper link: https://huggingface.co/papers/2605.06507

37. MiA-Signature: Approximating Global Activation for Long-Context Understanding
🔑 Keywords: Mindscape Activation Signature, compressed representation, global activation pattern, long-context understanding, computational efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a compressed representation method, termed as Mindscape Activation Signature (MiA-Signature), for approximating global activation states in large language models while retaining computational efficiency.
🛠️ Research Methods:
– Implementing MiA-Signature through submodular-based selection of high-level concepts, and refining it using lightweight iterative updates with the aid of working memory.
💬 Research Conclusions:
– Integration of MiA-Signatures into RAG and agentic systems shows consistent performance gains in long-context understanding tasks.
👉 Paper link: https://huggingface.co/papers/2605.06416

38. Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
🔑 Keywords: Direct corpus interaction, Agentic search, Modern retrieval systems, BRIGHT and BEIR datasets, Multi-hop QA
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve agentic search effectiveness by enabling agents to directly query raw text, surpassing limitations of traditional retrieval methods.
🛠️ Research Methods:
– The study employs direct corpus interaction (DCI) using general-purpose terminal tools without reliance on embedding models or retrieval APIs.
💬 Research Conclusions:
– Direct corpus interaction significantly outperforms existing retrieval methods across various IR benchmarks and agentic search tasks, offering a broader interface-design space for enhanced retrieval and reasoning ability.
👉 Paper link: https://huggingface.co/papers/2605.05242
