AI Native Daily Paper Digest – 20260514

1. MinT: Managed Infrastructure for Training and Serving Millions of LLMs
🔑 Keywords: MinT, Low-Rank Adaptation, LoRA, distributed policy management, large model architectures
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces MinT, a managed infrastructure system designed for efficient Low-Rank Adaptation (LoRA) training and serving, focusing on scaling across large model architectures and improving policy management.
🛠️ Research Methods:
– MinT utilizes a service interface to manage base models while exporting lightweight adapter revisions through processes like rollout, update, export, and evaluation. It scales in three ways: Scale Up for expansive model architectures, Scale Down for reduced storage, and Scale Out for effective policy addressability.
💬 Research Conclusions:
– MinT successfully manages million-scale LoRA policy catalogs by optimizing training and serving processes for selected adapter revisions over large 1T-class base models, improving both efficiency and scalability.
👉 Paper link: https://huggingface.co/papers/2605.13779

2. AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
🔑 Keywords: AnyFlow, video diffusion, flow-map transition, consistency distillation, ODE sampling
💡 Category: Generative Models
🌟 Research Objective:
– To introduce AnyFlow, a novel any-step video diffusion distillation framework that optimizes sampling trajectories using flow-map transition learning and backward simulation techniques.
🛠️ Research Methods:
– Shifting the distillation target to optimize the full ODE sampling trajectory and proposing Flow Map Backward Simulation for efficient on-policy distillation.
💬 Research Conclusions:
– AnyFlow matches or surpasses consistency-based methods in few-step video generation performance, demonstrating its effectiveness in scaling with sampling step budgets.
👉 Paper link: https://huggingface.co/papers/2605.13724
3. EVA-Bench: A New End-to-end Framework for Evaluating Voice Agents
🔑 Keywords: EVA-Bench, Voice agents, Composite metrics, Task completion, Noise robustness
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Develop a comprehensive evaluation framework, EVA-Bench, for voice agents to simulate realistic conversations and measure performance effectively across voice-specific failure modes.
🛠️ Research Methods:
– Utilized a bot-to-bot audio conversation system for dynamic multi-turn dialogues and automatic simulation validation, incorporating two composite metrics EVA-A (Accuracy) and EVA-X (Experience) for performance measurement across different agent architectures.
💬 Research Conclusions:
– Found no system exceeds 0.5 on both EVA-A and EVA-X pass@1 metrics simultaneously. Noted substantial divergence between peak and reliable performance and observed significant robustness gaps due to accent and noise perturbations, with variation across architectures and metrics.
👉 Paper link: https://huggingface.co/papers/2605.13841

4. Qwen-Image-VAE-2.0 Technical Report
🔑 Keywords: Variational Autoencoders, reconstruction fidelity, Global Skip Connections, semantic alignment, diffusability
💡 Category: Generative Models
🌟 Research Objective:
– To improve the reconstruction fidelity and diffusability of high-compression Variational Autoencoders with enhanced architectures and training strategies.
🛠️ Research Methods:
– Utilized improved architecture with Global Skip Connections and expanded latent channels.
– Scaled training to billions of images and used a synthetic rendering engine.
– Implemented asymmetric, attention-free encoder-decoder and enhanced semantic alignment strategies.
💬 Research Conclusions:
– Qwen-Image-VAE-2.0 achieves state-of-the-art performance, excelling in both general and text-rich scenarios with high compression ratio.
– Demonstrated superior diffusability, significantly enhancing convergence speed compared to existing models.
👉 Paper link: https://huggingface.co/papers/2605.13565

5. TrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking
🔑 Keywords: Dense 3D tracking, Monocular video, Video diffusion transformers, Dual-latent representation, Temporal RoPE alignment
💡 Category: Computer Vision
🌟 Research Objective:
– To enable efficient dense 3D tracking from monocular video by adapting video diffusion transformers with dual-latent representation and temporal RoPE alignment.
🛠️ Research Methods:
– Utilization of dual-latent representation for per-frame geometry and reference-anchored tracking.
– Temporal RoPE alignment to specify target time for tracking, while using LoRA fine-tuning to convert generative models into reference-anchored tracking formulations.
💬 Research Conclusions:
– TrackCraft3R achieves state-of-the-art performance in dense 3D tracking benchmarks, excelling in speed and memory usage, and shows robustness to large motions and long videos.
👉 Paper link: https://huggingface.co/papers/2605.12587

6. FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
🔑 Keywords: FrameSkip, Vision-Language-Action, action variation, temporal supervision imbalance, visual-action coherence
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to enhance VLA policy training by introducing FrameSkip, a method that prioritizes high-importance frames based on specific metrics, to address the temporal supervision imbalance in dense robot demonstration trajectories.
🛠️ Research Methods:
– The study employs FrameSkip, a data-layer frame selection framework, which scores trajectory frames using criteria such as action variation and visual-action coherence, and remaps training samples towards frames of higher importance while maintaining a target retention ratio.
💬 Research Conclusions:
– FrameSkip improves the success-retention trade-off in VLA policy training, achieving a higher macro-average success rate of 76.15% compared to 66.50% with full-frame training across benchmark environments, while preserving only 20% of unique frames.
👉 Paper link: https://huggingface.co/papers/2605.13757

7. Asymmetric Flow Models
🔑 Keywords: Asymmetric Flow Modeling, Flow-based generation, Low-rank structure, Pixel diffusion models, Text-to-image generation
💡 Category: Generative Models
🌟 Research Objective:
– The objective was to develop a method, Asymmetric Flow Modeling (AsymFlow), that achieves efficient high-dimensional flow-based generation by restricting noise prediction to low-rank subspaces while maintaining full data prediction capabilities.
🛠️ Research Methods:
– AsymFlow utilizes a rank-asymmetric velocity parameterization to control noise prediction, enabling full-dimensional velocity recovery without altering the network architecture or the training/sampling procedures.
💬 Research Conclusions:
– AsymFlow achieved state-of-the-art performance in pixel-space text-to-image generation, demonstrated by a leading 1.57 FID on ImageNet 256×256, and showcased significant visual realism improvements when finetuned from pretrained latent models.
👉 Paper link: https://huggingface.co/papers/2605.12964

8. HAGE: Harnessing Agentic Memory via RL-Driven Weighted Graph Evolution
🔑 Keywords: weighted multi-relational memory, query-conditioned traversal, relational memory graph, reinforcement learning, adaptive memory retrieval
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to improve long-horizon reasoning accuracy in AI systems through the introduction of HAGE, a weighted multi-relational memory framework.
🛠️ Research Methods:
– HAGE reorganizes memory as sequential, query-conditioned traversal over a unified relational memory graph, with edge embeddings modulated by a routing network.
– Utilizes a reinforcement learning-based training framework to optimize routing behavior and edge representations with respect to downstream tasks.
💬 Research Conclusions:
– The HAGE framework demonstrates improved reasoning accuracy and an advantageous accuracy-efficiency trade-off compared to existing agentic memory systems.
👉 Paper link: https://huggingface.co/papers/2605.09942

9. Orthrus: Memory-Efficient Parallel Token Generation via Dual-View Diffusion
🔑 Keywords: Dual-architecture framework, Autoregressive Large Language Models, Parallel token generation, Diffusion models, Consensus mechanism
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces Orthrus, which aims to unify exact generation fidelity of autoregressive LLMs with the high-speed parallel generation capabilities of diffusion models.
🛠️ Research Methods:
– Utilizes a dual-architecture framework augmenting a frozen LLM with a trainable module to facilitate both autoregressive and parallel diffusion views, maintaining a shared KV cache for ensuring precise inference.
💬 Research Conclusions:
– Orthrus achieves a balance between high-speed parallel generation and exact inference fidelity, providing up to a 7.8x speedup with minimal additional memory and parameter overhead.
👉 Paper link: https://huggingface.co/papers/2605.12825

10. RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
🔑 Keywords: RoboEvolve, vision-language models, video generation models, co-evolutionary loop, continual learning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to enhance robotic manipulation scalability through a framework that integrates Vision-Language Models (VLMs) and Video Generation Models (VGMs) to improve data efficiency and foster continuous learning.
🛠️ Research Methods:
– The approach involves a co-evolutionary loop combining VLMs and VGMs, employing a cognitive-inspired dual-phase mechanism with daytime exploration for behavioral discovery and nighttime consolidation to optimize policies.
💬 Research Conclusions:
– RoboEvolve significantly enhances performance metrics, achieves high data efficiency with a 50x reduction in labeled data needs, and demonstrates robust continual learning capabilities without catastrophic forgetting.
👉 Paper link: https://huggingface.co/papers/2605.13775

11. Offline Preference Optimization for Rectified Flow with Noise-Tracked Pairs
🔑 Keywords: Rectified Flow, PNAPO, Preference Optimization, Noise-Image Interpolation
💡 Category: Generative Models
🌟 Research Objective:
– Address the limitation of existing preference datasets in text-to-image models by introducing Prior Noise-Aware Preference Optimization (PNAPO) for rectified flow models.
🛠️ Research Methods:
– Augment preference data with noise samples and employ noise-image interpolation for effective trajectory estimation.
– Introduce a dynamic regularization strategy based on reward gap and training progress.
💬 Research Conclusions:
– PNAPO improves preference metrics and reduces training compute when applied to state-of-the-art rectified flow text-to-image models.
👉 Paper link: https://huggingface.co/papers/2605.09433

12. LEAD: Length-Efficient Adaptive and Dynamic Reasoning for Large Language Models
🔑 Keywords: LEAD, Chain-of-Thought, Reinforcement Learning, Efficiency Rewards, Accuracy-Efficiency Score
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance mathematical reasoning accuracy and efficiency by dynamically adapting reasoning efficiency with the LEAD method.
🛠️ Research Methods:
– LEAD employs online calibration of correctness-efficiency trade-offs and adaptive problem-specific length targets to replace static heuristics, using Potential-Scaled Instability for optimization.
💬 Research Conclusions:
– LEAD achieves superior accuracy and Accuracy-Efficiency Score on five mathematical reasoning benchmarks, offering shorter outputs versus the base model while excelling among RL-trained reasoning methods.
👉 Paper link: https://huggingface.co/papers/2605.09806

13. MAP: A Map-then-Act Paradigm for Long-Horizon Interactive Agent Reasoning
🔑 Keywords: Map-then-Act Paradigm, Delayed Environmental Perception, Epistemic Bottleneck, Knowledge-Augmented Execution, Global Exploration
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Address the limitations of interactive LLM agents in environmental perception during execution by introducing the Map-then-Act Paradigm (MAP).
🛠️ Research Methods:
– Proposed a framework consisting of three stages: Global Exploration, Task-Specific Mapping, and Knowledge-Augmented Execution, aimed at improving agents’ environmental understanding before execution.
💬 Research Conclusions:
– Demonstrated that the MAP paradigm provides consistent gains in benchmarks, enabling better performance in various environments and highlighting the importance of environment understanding over mere imitation.
👉 Paper link: https://huggingface.co/papers/2605.13037

14. FeatCal: Feature Calibration for Post-Merging Models
🔑 Keywords: Feature drift, Model merging, Calibration method, Sample efficiency, Closed-form solution
💡 Category: Machine Learning
🌟 Research Objective:
– The objective of the study is to address performance gaps in model merging through the analysis of feature drift and to propose a calibration method called FeatCal to enhance efficiency and benchmark results.
🛠️ Research Methods:
– The research utilizes a theoretical framework to decompose feature drift into upstream propagation and local mismatch. FeatCal employs a layer-wise calibration of merged model weights using a small calibration set, executed through an efficient closed-form solution without gradient descent.
💬 Research Conclusions:
– FeatCal significantly outperforms existing calibration baselines on benchmarks such as CLIP and GLUE, demonstrating better sample efficiency and reduced calibration costs, while maintaining the benefits of model merging.
👉 Paper link: https://huggingface.co/papers/2605.13030

15. Retrieval from Within: An Intrinsic Capability of Attention-Based Models
🔑 Keywords: Intrinsic Retrieval, Attention-based models, retrieval-augmented generation, evidence recall, answer quality
💡 Category: Natural Language Processing
🌟 Research Objective:
– To determine if an attention-based encoder-decoder can retrieve directly from its internal representations, unifying retrieval and generation processes.
🛠️ Research Methods:
– Introduced the INTRA framework, where decoder attention queries score pre-encoded evidence chunks reused as context for generation.
💬 Research Conclusions:
– INTRA unifies retrieval and generation, eliminating the retriever-generator mismatch typical in RAG pipelines.
– Demonstrates superior performance over traditional retrieval pipelines in evidence recall and end-to-end answer quality on question-answering benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.05806

16. AgentLens: Revealing The Lucky Pass Problem in SWE-Agent Evaluation
🔑 Keywords: Software Engineering Agents, AgentLens, Lucky Pass, Process-level Assessment, Quality Scores
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate software engineering (SWE) agents using a process-level framework to differentiate between effective and ineffective approaches by identifying patterns like Lucky Passes and providing quality scoring.
🛠️ Research Methods:
– Evaluation of 2,614 OpenHands trajectories from eight model backends on 60 SWE-bench Verified tasks, constructing task-level process references and using AgentLens framework for quality scoring and pattern analysis.
💬 Research Conclusions:
– The process-level framework, AgentLens, distinguishes passing trajectories into Lucky, Solid, and Ideal tiers. Lucky Passes are further broken down into recurring mechanisms, with quality scores showing variance in model effectiveness, influencing ranking positions significantly.
👉 Paper link: https://huggingface.co/papers/2605.12925

17. The Extrapolation Cliff in On-Policy Distillation of Near-Deterministic Structured Outputs
🔑 Keywords: AI-generated summary, On-policy distillation, Reward extrapolation, Lambda, Format-preserving
💡 Category: Machine Learning
🌟 Research Objective:
– The study delves into the effects of increasing the reward-extrapolation coefficient in On-policy Distillation and its impact on structured-output tasks.
🛠️ Research Methods:
– Utilized a single-position Bernoulli reduction to derive a clip-safety threshold and extended rules to calibrated K-ary listwise JSON tasks with empirical validation through various tests.
💬 Research Conclusions:
– Identified a critical threshold (lambda*) where operating above it causes a shift from format-preserving to format-collapsing in structured-output tasks, achieving performance parity with significant parameter reduction.
👉 Paper link: https://huggingface.co/papers/2605.08737

18. Position: LLM Inference Should Be Evaluated as Energy-to-Token Production
🔑 Keywords: Energy-to-token, Token Production Function, Joules/token, Operational efficiency, PUE
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research aims to evaluate LLM inference as energy-to-token production, emphasizing factors beyond traditional metrics like accuracy and latency.
🛠️ Research Methods:
– A Token Production Function is formalized to analyze token production under constraints such as compute-per-token and energy-per-token.
– System optimizations like KV-cache compression and quantization are considered energy-to-token levers.
💬 Research Conclusions:
– The study suggests that inference papers should report energy-related metrics (e.g., Joules/token) alongside accuracy and latency.
– System optimizations should focus on reducing resource consumption under fixed quality and service targets.
👉 Paper link: https://huggingface.co/papers/2605.11733

19. An Empirical Study of Automating Agent Evaluation
🔑 Keywords: Automated agent evaluation, EvalAgent, AI assistants, evaluation skills, meta-evaluation framework
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To investigate the efficacy of AI assistants, specifically EvalAgent, in automating the end-to-end agent evaluation process with improved reliability and accuracy.
🛠️ Research Methods:
– Introduction of EvalAgent, an AI tool that employs specialized evaluation skills and a trace-based pipeline to produce evaluation artifacts.
– Development of a meta-evaluation framework and the AgentEvalBench benchmark to systematically assess the performance of generated evaluations.
– Proposal of the Eval@1 metric to evaluate the effectiveness of evaluation code execution.
💬 Research Conclusions:
– EvalAgent significantly enhances evaluation accuracy, as evidenced by an increase in the Eval@1 metric from 17.5% to 65%.
– EvalAgent demonstrates a 79.5% preference rate over baseline methods according to human expert evaluation.
– The integration of evaluation skills is crucial, with their removal causing Eval@1 performance to drop to 30%.
👉 Paper link: https://huggingface.co/papers/2605.11378

20. F-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
🔑 Keywords: AI-generated summary, Large Language Models, autoregressive model, factorized group-relative policy optimization, end-to-end optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Propose a unified framework to address the credit assignment challenges in end-to-end retrieval optimization by combining candidate generation and ranking in a single autoregressive model.
🛠️ Research Methods:
– Factorized group-relative policy optimization (F-GRPO) is used, which factorizes the policy into candidate generation and ranking while utilizing a single LLM backbone.
💬 Research Conclusions:
– The framework improves top-ranked performance over existing GRPO and decoupled baselines and outperforms supervised alternatives; it remains competitive with strong zero-shot rerankers without requiring architectural changes at inference time.
👉 Paper link: https://huggingface.co/papers/2605.12995

21. IndicMedDialog: A Parallel Multi-Turn Medical Dialogue Dataset for Accessible Healthcare in Indic Languages
🔑 Keywords: Multilingual Dialogue Systems, Indic Languages, Personalized Symptom Elicitation, Parameter-efficient Adaptation, Clinical Plasibility
💡 Category: AI in Healthcare
🌟 Research Objective:
– Introduce IndicMedDialog, a parallel multi-turn medical dialogue dataset covering English and nine Indic languages, for realistic and multilingual medical consultations.
🛠️ Research Methods:
– Extend MDDial with LLM-generated consultations, translated with TranslateGemma, verified and refined for accuracy.
– Fine-tune IndicMedLM via parameter-efficient adaptation, incorporating patient pre-context for personalized interactions.
💬 Research Conclusions:
– Evaluated against zero-shot multilingual baselines and performed systematic error analysis, validating clinical plausibility through medical expert evaluation.
👉 Paper link: https://huggingface.co/papers/2605.13292

22. FAAST: Forward-Only Associative Learning via Closed-Form Fast Weights for Test-Time Supervised Adaptation
🔑 Keywords: FAAST, task adaptation, forward-only computation, fast weights, pretrained models
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce FAAST, a forward-only associative adaptation method aimed at efficient task adaptation by using fast weights.
🛠️ Research Methods:
– Implement a method that compiles labeled examples into fast weights through a single-pass forward-only computation, eliminating dependence on memory or context.
💬 Research Conclusions:
– FAAST achieves significant improvements in speed and memory efficiency, reducing adaptation time by over 90% and saving memory usage by up to 95% compared to traditional methods like backpropagation and memory/context-based adaptation. This makes FAAST a highly efficient solution for resource-constrained models across image classification and language modeling benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.04651

23. From Pixels to Concepts: Do Segmentation Models Understand What They Segment?
🔑 Keywords: CAFE, concept-faithful segmentation, promptable models, counterfactual manipulation, semantic grounding
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to evaluate concept-faithful segmentation in promptable segmentation models using a new benchmark called CAFE (Counterfactual Attribute Factuality Evaluation).
🛠️ Research Methods:
– The CAFE benchmark assesses models through attribute-level counterfactual manipulation by modifying attributes such as surface appearance, context, or material composition while preserving the target region and ground-truth mask.
💬 Research Conclusions:
– Experiments using CAFE reveal a gap between localization quality and concept discrimination, indicating that accurate mask prediction does not always ensure faithful semantic grounding in models.
👉 Paper link: https://huggingface.co/papers/2605.09591

24. ShapeCodeBench: A Renewable Benchmark for Perception-to-Program Reconstruction of Synthetic Shape Scenes
🔑 Keywords: ShapeCodeBench, perception-to-program reconstruction, raster image, executable drawing program, synthetic benchmark
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a benchmark named ShapeCodeBench for evaluating models in generating executable drawing programs from raster images.
🛠️ Research Methods:
– Utilize a synthetic benchmark that generates raster images for models to emit executable drawing programs, evaluated using metrics like exact match and pixel accuracy.
💬 Research Conclusions:
– The benchmarking results show competitive performance in specific scenarios, yet the exact match rates are low, indicating potential for further improvements and developments.
👉 Paper link: https://huggingface.co/papers/2605.11680

25. Active Tabular Augmentation via Policy-Guided Diffusion Inpainting
🔑 Keywords: Tabular Augmentation Policy, diffusion inpainting, learner-conditioned policy, data-scarce domains
💡 Category: Generative Models
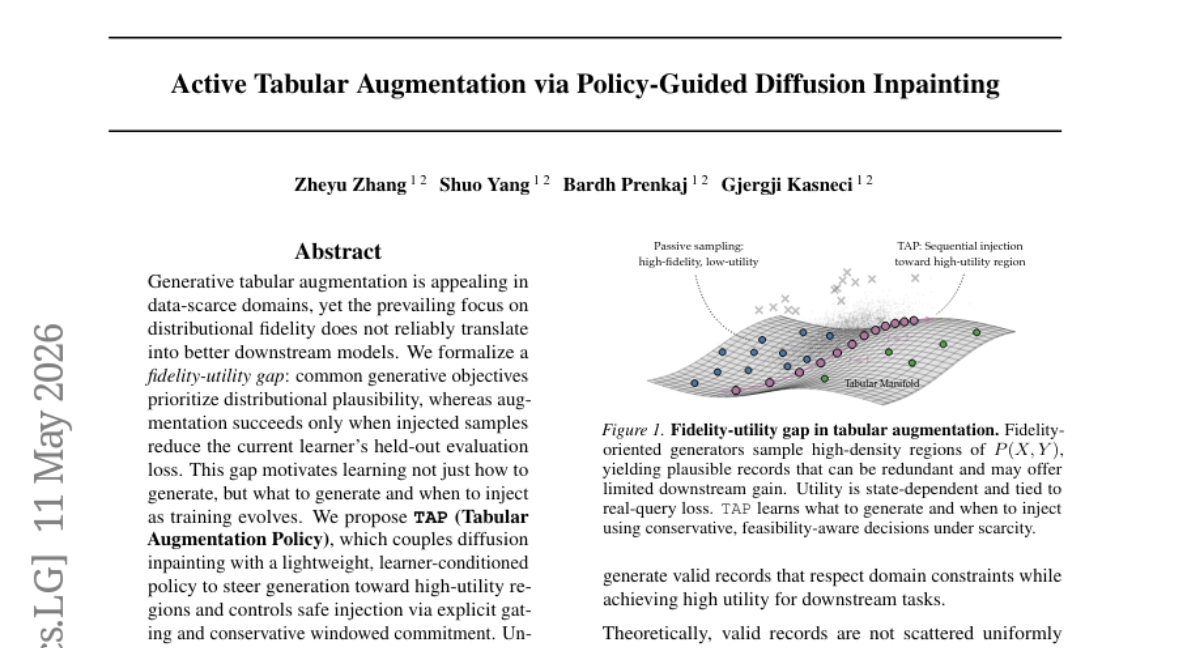
🌟 Research Objective:
– The study aims to address the fidelity-utility gap in generative tabular augmentation, particularly in data-scarce domains, by focusing on not just generating data but optimizing when and what to generate to improve downstream model performance.
🛠️ Research Methods:
– The proposed method, TAP (Tabular Augmentation Policy), combines diffusion inpainting with a lightweight, learner-conditioned policy to direct data generation towards high-utility regions, ensuring safe data augmentation through explicit gating and conservative windowed commitment.
💬 Research Conclusions:
– TAP consistently outperformed strong generative baselines in data-scarce environments, achieving up to a 15.6 percentage point increase in classification accuracy and reducing regression RMSE by up to 32% across seven real-world datasets.
👉 Paper link: https://huggingface.co/papers/2605.10315
26. Learning to Explore: Scaling Agentic Reasoning via Exploration-Aware Policy Optimization
🔑 Keywords: variational inference, exploration-aware, reinforcement learning, text-based benchmarks, GUI-based benchmarks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to develop an exploration-aware reinforcement learning framework that enables Large Language Model (LLM) agents to selectively explore actions only when the uncertainty is high.
🛠️ Research Methods:
– The proposed method integrates a fine-grained reward function through variational inference, which evaluates exploratory actions by estimating their potential to enhance future decision-making. Additionally, it employs an exploration-aware grouping mechanism for optimizing these actions separately from task-completion actions.
💬 Research Conclusions:
– The framework demonstrated consistent performance improvements across diverse and challenging text-based and GUI-based agent benchmarks, allowing for selective exploration and efficient transition to task execution.
👉 Paper link: https://huggingface.co/papers/2605.08978

27. Federation of Experts: Communication Efficient Distributed Inference for Large Language Models
🔑 Keywords: Mixture of Experts, Federation of Experts, KV heads, Inference Throughput, Latency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance computational efficiency in Large Language Models by restructuring mixture of experts blocks into clusters, thus improving communication bottlenecks.
🛠️ Research Methods:
– The novel Federation of Experts (FoE) architecture is introduced, restructuring transformer layer MoE blocks into multiple clusters each responsible for KV heads, and reducing communication overhead in both single-node and multi-node settings.
💬 Research Conclusions:
– The implementation of FoE demonstrates a significant improvement in inference throughput and latency, reducing forward-pass latency by up to 5.2x, while maintaining generation quality similar to the original Mixture of Experts model.
👉 Paper link: https://huggingface.co/papers/2605.06206

28.

29. WriteSAE: Sparse Autoencoders for Recurrent State
🔑 Keywords: WriteSAE, Sparse Autoencoder, Hybrid Recurrent Language Models, Matrix Cache Write, Token-level Interventions
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces WriteSAE, a new sparse autoencoder enabling decomposition and editing of matrix cache writes in state-space and hybrid recurrent language models to enhance token-level interventions.
🛠️ Research Methods:
– WriteSAE uniquely decomposes decoder atoms into native write shapes and trains under matched Frobenius norm, allowing effective token intervention by substituting atoms and predicting logit shifts.
💬 Research Conclusions:
– WriteSAE significantly outperforms existing models like Gated DeltaNet and Mamba-2 in token interventions, with successful applications demonstrated in matrix-recurrent write sites, elevating performance metrics dramatically.
👉 Paper link: https://huggingface.co/papers/2605.12770

30. FlowCompile: An Optimizing Compiler for Structured LLM Workflows
🔑 Keywords: FlowCompile, structured LLM workflows, compile-time exploration, accuracy-latency trade-offs, workflow optimization
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To optimize complex multi-agent tasks in AI by exploring workflow configurations at compile-time to balance accuracy and latency without retraining.
🛠️ Research Methods:
– Introduce FlowCompile, a workflow compiler that decomposes workflows into sub-agents, profiles them under diverse configurations, and estimates workflow-level accuracy and latency using a structure-aware proxy.
💬 Research Conclusions:
– FlowCompile consistently outperforms existing heuristically optimized and routing-based configurations, delivering up to a 6.4x speedup and creating a reusable optimization artifact.
👉 Paper link: https://huggingface.co/papers/2605.13647

31. SafeHarbor: Hierarchical Memory-Augmented Guardrail for LLM Agent Safety
🔑 Keywords: AI-generated summary, Large Language Model (LLM) agents, decision boundaries, context-aware defense rules, self-evolution mechanism
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To design SafeHarbor, a novel framework for LLM agents that establishes precise decision boundaries by using context-aware defense rules to enhance safety without compromising utility.
🛠️ Research Methods:
– Implementing a hierarchical memory system and an information entropy-based self-evolution mechanism to support dynamic rule injection for improved safety and performance.
💬 Research Conclusions:
– SafeHarbor achieves state-of-the-art performance by maintaining a high refusal rate for harmful requests while also ensuring significant benign task utility, as demonstrated in experiments with GPT-4o.
👉 Paper link: https://huggingface.co/papers/2605.05704

32. Source or It Didn’t Happen: A Multi-Agent Framework for Citation Hallucination Detection
🔑 Keywords: AI-generated summary, citation hallucination detection, multi-agent detector
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective of this research is to develop a system that can accurately detect fabricated citations in scientific writing by classifying them into a 12-code taxonomy.
🛠️ Research Methods:
– The research employs a cascading multi-agent system, CiteTracer, which extracts structured citations, retrieves evidence, applies deterministic field matching, and routes ambiguous cases to specialized judges.
💬 Research Conclusions:
– CiteTracer demonstrates high accuracy, achieving 97.1% on a synthetic benchmark and effectively detecting 97.1% of fabrications in real-world citations without abstaining.
👉 Paper link: https://huggingface.co/papers/2605.08583

33. M2Retinexformer: Multi-Modal Retinexformer for Low-Light Image Enhancement
🔑 Keywords: Multi-Modal, Retinexformer, Depth Cues, Cross-Attention, Adaptive Gating
💡 Category: Multi-Modal Learning
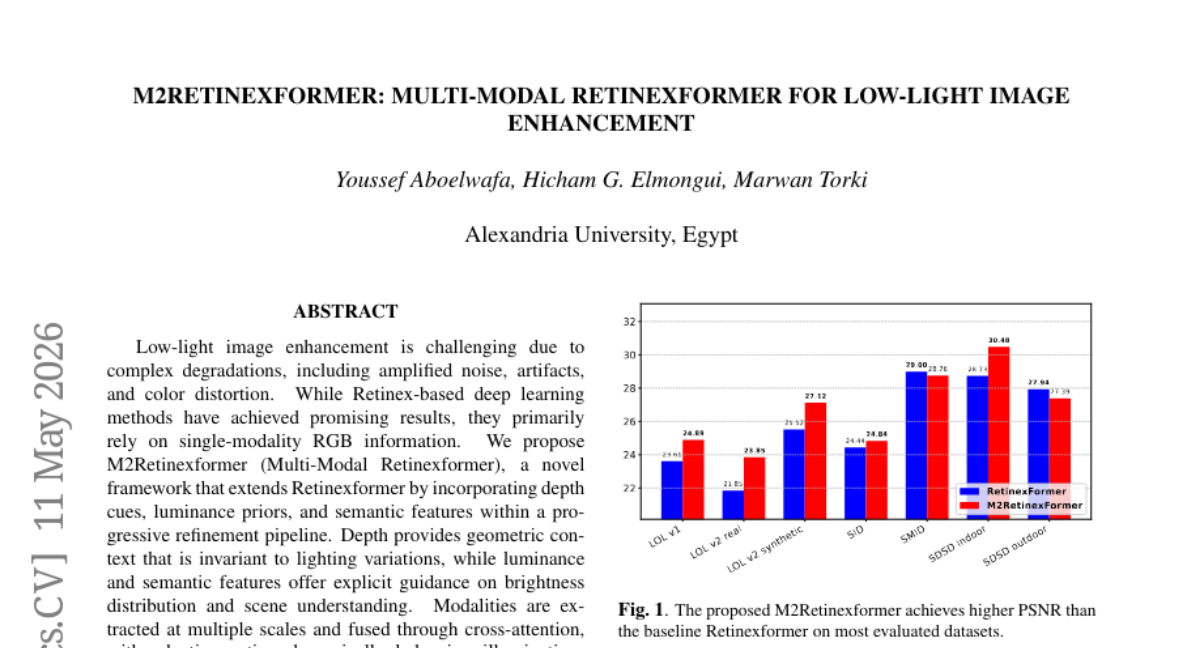
🌟 Research Objective:
– To enhance low-light image quality by integrating depth cues, luminance priors, and semantic features through a novel multi-modal framework.
🛠️ Research Methods:
– Utilization of cross-attention fusion and adaptive gating mechanisms within a framework called M2Retinexformer for processing multi-scale modalities.
💬 Research Conclusions:
– The proposed framework demonstrates improved performance over existing Retinexformer and state-of-the-art methods on LOL, SID, SMID, and SDSD benchmark datasets.
👉 Paper link: https://huggingface.co/papers/2605.12556
34. From Generalist to Specialist Representation
🔑 Keywords: Nonparametric Identifiability, Generalist Model, Specialist Representation, Task-Relevant Latent Representation, Sparsity Regularization
💡 Category: Foundations of AI
🌟 Research Objective:
– Establish nonparametric identifiability for task-relevant representations from generalist models without relying on parametric assumptions or interventions.
🛠️ Research Methods:
– Proven identifiability of structures between time steps and tasks in a nonparametric and unsupervised setting.
– Demonstrated disentanglement of task-relevant representations using a simple sparsity regularization.
💬 Research Conclusions:
– Provides a hierarchical foundation for task structure identifiability across time steps and disentanglement of task-relevant representations within each step, marking a step toward transitioning from generalist to specialist models.
👉 Paper link: https://huggingface.co/papers/2605.12733

35. Frequency Bias and OOD Generalization in Neural Operators under a Variable-Coefficient Wave Equation
🔑 Keywords: Neural Operators, PDE Solving, Fourier Neural Operator, Deep Operator Network, Distribution Shifts
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to investigate the generalization behaviors of neural operators for partial differential equations (PDEs) under distribution shifts, specifically focusing on smoothness and frequency variations.
🛠️ Research Methods:
– The analysis was conducted using two neural operator architectures, the Fourier Neural Operator (FNO) and the Deep Operator Network (DeepONet), in a one-dimensional wave propagation context. The study evaluated their performance under structured out-of-distribution (OOD) settings that vary input frequency and coefficient smoothness.
💬 Research Conclusions:
– Both FNO and DeepONet maintain stable performance under smoothness shifts, with FNO achieving lower error. However, under frequency shifts, FNO shows a sharp increase in error for high-frequency inputs, while DeepONet presents milder degradation. The findings suggest a fundamental gap between in-distribution performance and generalization under distribution shifts, highlighting the importance of addressing architectural representation bias in developing reliable neural operators for physics-based PDE simulations.
👉 Paper link: https://huggingface.co/papers/2605.12997

36. PersonalAI 2.0: Enhancing knowledge graph traversal/retrieval with planning mechanism for Personalized LLM Agents
🔑 Keywords: PersonalAI 2.0, Knowledge Graphs, GraphRAG, Information-Retention Score
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to enhance large language model-based systems by integrating external knowledge graphs to improve factual correctness and precision in answer generation.
🛠️ Research Methods:
– Utilization of dynamic, multistage query processing pipelines and adaptive information search mechanisms.
– Implementation of graph traversal algorithms like BeamSearch and WaterCircles to outperform standard retrieval methods.
💬 Research Conclusions:
– PersonalAI 2.0 demonstrates an average 4% gain in reducing hallucination rates and boosting precision when evaluated by LLM-as-a-Judge across multiple benchmarks.
– An 18% boost is achieved with enabled search plan enhancements over six datasets, highlighting its potential as a foundational model for personalized AI applications.
– The ablation study reveals a state-of-the-art result on the MINE-1 benchmark, achieving an 89% information-retention score.
👉 Paper link: https://huggingface.co/papers/2605.13481

37. MC-RFM: Geometry-Aware Few-Shot Adaptation via Mixed-Curvature Riemannian Flow Matching
🔑 Keywords: Riemannian flow-matching, few-shot adaptation, hyperbolic factor, Euclidean factor, Transformer backbones
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a novel framework (MC-RFM) for few-shot adaptation in mixed-curvature manifolds to outperform existing methods across benchmarks.
🛠️ Research Methods:
– Develop a product manifold approach combining hyperbolic and Euclidean spaces to model feature displacement.
– Implement adaptation through task-conditioned continuous transport with a flow-matching objective.
💬 Research Conclusions:
– MC-RFM outperforms current methods in visual recognition benchmarks, particularly on Transformer backbones and fine-grained datasets, by effectively modeling feature representation geometry.
👉 Paper link: https://huggingface.co/papers/2605.08557

38. MemReread: Enhancing Agentic Long-Context Reasoning via Memory-Guided Rereading
🔑 Keywords: MemReread, long-context reasoning, agent memory, question decomposition, reinforcement learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address long-context reasoning challenges while maintaining linear time complexity, avoiding intermediate retrieval through question decomposition and rereading.
🛠️ Research Methods:
– Developed MemReread based on streaming reading to trigger question decomposition and rereading, utilizing a reinforcement learning framework for dynamic control over computational overhead.
💬 Research Conclusions:
– MemReread outperforms baseline frameworks on long-context reasoning tasks while preserving logical flow, maintaining linear time complexity.
👉 Paper link: https://huggingface.co/papers/2605.10268

39. Visual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
🔑 Keywords: Multimodal large language models, Visual Aesthetic Benchmark, comparative selection, fine-tuning, expert judgment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Examine the alignment of multimodal models with human expert aesthetic judgment, focusing on the effectiveness of scalar score predictions versus direct ranking comparisons in visual tasks.
🛠️ Research Methods:
– Introduced the Visual Aesthetic Benchmark (VAB) featuring 400 tasks across various visual disciplines to evaluate models on comparative selection using expert consensus labels.
💬 Research Conclusions:
– The study highlights a significant performance gap between multimodal models and human experts in aesthetic judgment, with only 26.5% task accuracy compared to 68.9% by humans. Fine-tuning on expert data significantly improves model performance, indicating the transferability of the VAB comparative signal.
👉 Paper link: https://huggingface.co/papers/2605.12684

40. Vividh-ASR: A Complexity-Tiered Benchmark and Optimization Dynamics for Robust Indic Speech Recognition
🔑 Keywords: studio-bias, multilingual ASR, Vividh-ASR, R-MFT, Whisper
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to identify and address the studio-bias in multilingual ASR models used for low-resource languages, improving spontaneous speech performance without sacrificing efficiency.
🛠️ Research Methods:
– The introduction of Vividh-ASR, a complexity-stratified benchmark, and the implementation of controlled studies on learning-rate timing and curriculum ordering. The reverse multi-stage fine-tuning (R-MFT) approach was applied to compare performance.
💬 Research Conclusions:
– Early large parameter updates and a hard-to-easy curriculum significantly enhance performance on spontaneous speech, achieving efficiency in parameters.
– The R-MFT method allows a 244M Whisper model to match or exceed the performance of larger models, ensuring the preservation of acoustic geometry in the encoder while concentrating adaptation in the decoder.
👉 Paper link: https://huggingface.co/papers/2605.13087

41. BEACON: A Multimodal Dataset for Learning Behavioral Fingerprints from Gameplay Data
🔑 Keywords: Continuous authentication, Behavioral biometrics, Multimodal dataset, Esports, Behavioral profiling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce BEACON, a large-scale, multimodal dataset to advance research in continuous authentication and behavioral biometrics in competitive gaming environments.
🛠️ Research Methods:
– Captures fine-grained behavioral signals in competitive Valorant gameplay across diverse skill tiers using extensive data from multiple modalities, including mouse dynamics, keystrokes, and network captures.
💬 Research Conclusions:
– Provides a comprehensive benchmark for studying continuous authentication, user drift, and behavioral profiling in high-cognitive load esports settings; enables the development and testing of next-generation behavioral fingerprinting and security models.
👉 Paper link: https://huggingface.co/papers/2605.10867

42. Context Training with Active Information Seeking
🔑 Keywords: Context Optimization, Active Information Seeking, Large Language Models, Search-Based Training, Downstream Tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance context optimization methods with active information seeking tools like Wikipedia search and browser tools to improve performance in diverse domains.
🛠️ Research Methods:
– Integration of search and browser tools with context optimizers in large language models, utilizing a search-based training procedure to maintain and prune multiple candidate contexts.
💬 Research Conclusions:
– Active information seeking enhances performance and delivers consistent gains across low-resource translation, health scenarios, and reasoning tasks. The method is also data-efficient and robust across various hyperparameters.
👉 Paper link: https://huggingface.co/papers/2605.13050

43. Results and Retrospective Analysis of the CODS 2025 AssetOpsBench Challenge
🔑 Keywords: Privacy-Aware, Codabench, Multi-Agent Orchestration, Hidden Evaluation, Leaderboard
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To analyze the CODS 2025 challenge, focusing on the metrics of leaderboard evaluation, impact of hidden evaluations, and rewarded design patterns.
🛠️ Research Methods:
– Utilized data from rank sheets, submission logs, team registrations, best-submission exports, organizer reports, system papers, and source trees for verified planning tracks.
💬 Research Conclusions:
– The public planning leaderboard reaches saturation at 72.73%, with no improvement from richer prompts.
– Hidden evaluations show moderate correlation between public and private scores in planning, but negative correlation in execution.
– The official composite score is minimally affected by numerical changes, with possible impact on team rankings.
– Operationally account-based, yet substantively team-based results are evident, with a significant reduction in effective team count from registrations.
– Successful execution methods prioritize improving guardrails like response selection and context control over novel agent architectures.
👉 Paper link: https://huggingface.co/papers/2605.08518

44. Revisiting DAgger in the Era of LLM-Agents
🔑 Keywords: DAgger, Long-Horizon, Supervised Fine-Tuning, Reinforcement Learning, Covariate Shift
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to improve long-horizon language model (LM) agents by combining the strengths of supervised fine-tuning and reinforcement learning through a DAgger-style training approach.
🛠️ Research Methods:
– The research employs a hybrid DAgger algorithm that interpolates between student and teacher policies for trajectory collection, directly interacting with environments to mitigate covariate shift and enhance feedback quality.
💬 Research Conclusions:
– The DAgger-style training significantly enhances the performance of LM agents, as demonstrated with software-engineering agents, surpassing existing 4B and 8B post-training baselines, and closing the gap with larger models on evaluation benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.12913

45. RealICU: Do LLM Agents Understand Long-Context ICU Data? A Benchmark Beyond Behavior Imitation
🔑 Keywords: RealICU, ICU, Large Language Models, Clinical Recommendation, Patient Trajectory
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to evaluate large language models (LLMs) for decision support in intensive care units (ICUs) using a hindsight-annotated benchmark, RealICU, to reveal limitations in clinical recommendation accuracy and early interpretation bias.
🛠️ Research Methods:
– The researchers introduce RealICU, formulating tasks such as assessing patient status and recommending actions, using hindsight annotations. Two datasets, RealICU-Gold and RealICU-Scale, were created to gauge the performance of existing LLMs in a realistic ICU environment.
💬 Research Conclusions:
– RealICU reveals two failure modes in existing LLMs: a recall-safety tradeoff and an anchoring bias to early interpretations. The study also introduces ICU-Evo to improve long-horizon reasoning, yet safety failures persist, emphasizing the need for enhanced AI decision-support systems in high-stakes care.
👉 Paper link: https://huggingface.co/papers/2605.13542

46. PresentAgent-2: Towards Generalist Multimodal Presentation Agents
🔑 Keywords: PresentAgent-2, presentation video generation, multimodal media, agentic framework, interaction
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop PresentAgent-2, an agentic framework for generating presentation videos from user queries, leveraging multimodal resources and interactive delivery.
🛠️ Research Methods:
– Utilized deep research on presentation-friendly sources to collect multimodal resources (text, images, GIFs, videos).
– Constructed and evaluated three presentation modes: Single Presentation, Discussion, and Interaction, with criteria focused on content quality and media use.
💬 Research Conclusions:
– PresentAgent-2 advances presentation generation from static slides to a dynamic, query-driven, and research-grounded process, integrating multimodal media and interactive engagement.
👉 Paper link: https://huggingface.co/papers/2605.11363
47. Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
🔑 Keywords: Multi-hop question answering, Retrieval-Augmented Generation, Program synthesis, Reasoning process, Deterministic feedback
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Reformulate multi-hop question answering as program synthesis and execution for enhanced structured reasoning and performance.
🛠️ Research Methods:
– Introduce \pyrag framework, representing reasoning processes as executable Python programs rather than free-form reasoning, and facilitate compiler-grounded self-repair and execution-driven adaptive retrieval.
💬 Research Conclusions:
– The \pyrag framework demonstrates significant performance improvements over existing methods on diverse QA benchmarks and makes publicly available models and resources.
👉 Paper link: https://huggingface.co/papers/2605.12975

48. Learning Agentic Policy from Action Guidance
🔑 Keywords: Agentic reinforcement learning, Large Language Models, exploration capability, action data, supervised fine-tuning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce a method to enhance exploration capabilities in Large Language Models using agentic reinforcement learning with action data from human interactions.
🛠️ Research Methods:
– Utilize action data as plan-style reference guidance to improve the agentic policy’s ability to reach reward states.
– Implement mixed-policy training to combine guided and unguided rollouts, minimizing off-policy risk through a minimal intervention principle.
💬 Research Conclusions:
– The proposed ActGuide-RL method significantly improves performance on search-agent benchmarks, reducing reliance on extensive supervised fine-tuning data by using scalable action guidance.
👉 Paper link: https://huggingface.co/papers/2605.12004

49. The DAWN of World-Action Interactive Models
🔑 Keywords: World-Action Interactive Models, Autonomous Driving, DAWN, Latent Generative Baseline, Long-Horizon Planning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to enhance autonomous driving by integrating scene evolution and action planning through World-Action Interactive Models (WAIMs).
🛠️ Research Methods:
– The research introduces the DAWN model, which leverages a semantic latent space to couple a World Predictor with a World-Conditioned Action Denoiser for recursive refinement during inference.
💬 Research Conclusions:
– DAWN demonstrates strong planning performance and safety on multiple autonomous driving benchmarks, supporting interactive world-action generation as a promising approach for effective long-horizon trajectory generation.
👉 Paper link: https://huggingface.co/papers/2605.11550

50. Many-Shot CoT-ICL: Making In-Context Learning Truly Learn
🔑 Keywords: In-context learning, large language models, chain-of-thought, test-time learning, Curvilinear Demonstration Selection
💡 Category: Natural Language Processing
🌟 Research Objective:
– To study the scaling behaviors of many-shot in-context learning (ICL) for reasoning tasks and contrast it with non-reasoning tasks.
🛠️ Research Methods:
– Examination of many-shot chain-of-thought ICL across various language models to analyze the effects of CoT demonstrations, retrieval methods, and demonstration ordering.
💬 Research Conclusions:
– Standard many-shot rules do not apply universally across reasoning tasks.
– Increasing CoT demonstrations benefits reasoning-oriented models but can destabilize non-reasoning models.
– Similarity-based retrieval is ineffective for reasoning tasks due to poor procedural compatibility prediction.
– Performance variability arises with more CoT demonstrations.
– Introduced Curvilinear Demonstration Selection method, achieving improved performance.
👉 Paper link: https://huggingface.co/papers/2605.13511

51. Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
🔑 Keywords: Image Editing Models, Evaluation Protocols, Reward Models, Structured Reasoning, Scoring Rubrics
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces Edit-Compass and EditReward-Compass, a unified evaluation suite designed to address challenges in assessing image editing and reward models.
🛠️ Research Methods:
– Edit-Compass involves 2,388 annotated instances across six task categories with multi-dimensional evaluation using structured reasoning and scoring rubrics.
– EditReward-Compass uses 2,251 preference pairs to simulate realistic reward modeling scenarios.
💬 Research Conclusions:
– Existing benchmarks are inadequate for evaluating cutting-edge image editing and reward models; the new suite aims to provide a more reliable assessment framework.
👉 Paper link: https://huggingface.co/papers/2605.13062

52. Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
🔑 Keywords: AI agents, negotiation games, LLM-based, target-adaptive text-tabular, decision-oriented feature
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate whether AI agents can predict the decisions of unfamiliar counterparts in negotiation games by using target-adaptive text-tabular prediction.
🛠️ Research Methods:
– AI agents utilize a tabular foundation model combining structured game state and LLM-based text representations, enhanced by a frozen LLM as an Observer for decision-oriented features.
💬 Research Conclusions:
– The study demonstrates that the formulated target-adaptive text-tabular approach effectively predicts counterpart decisions, outperforming direct prompting methods and showing improved prediction accuracy.
👉 Paper link: https://huggingface.co/papers/2605.12411

53. Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
🔑 Keywords: Long-context modeling, Vision-language models, Long-document VQA, Retrieval-heavy mixtures, MMProLong
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Enhance vision-language models’ capability to manage long-context data effectively and improve performance in long-document understanding.
🛠️ Research Methods:
– Conducted a systematic study on long-context continued pre-training for a 7B model, exploring the design and balancing of long-context data mixtures.
💬 Research Conclusions:
– Long-document VQA is more effective than OCR transcription, with balanced sequence-length distribution outperforming target-length-focused approaches.
– Retrieval-heavy data mixtures improve task diversity and long-context capabilities, preserving short-context abilities.
– MMProLong, developed with a limited 5B-token budget, enhances performance on long-document VQA by 7.1% and generalizes well to multiple long-context tasks without additional training.
👉 Paper link: https://huggingface.co/papers/2605.13831

54. MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
🔑 Keywords: Multimodal Tabular Learning, Tabular Foundation Models, pretrained embeddings, MulTaBench
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to improve performance in Multimodal Tabular Learning by demonstrating that task-specific embedding tuning is beneficial, especially when modalities provide complementary predictive signals.
🛠️ Research Methods:
– Introduction of MulTaBench, a benchmark of 40 datasets divided between image-tabular and text-tabular tasks, focusing on predictive tasks where task-specific tuning is required.
💬 Research Conclusions:
– Target-aware representation tuning enhances performance across text and image modalities, and various tabular learners, proving beneficial for developing new Multimodal Tabular Foundation Models.
👉 Paper link: https://huggingface.co/papers/2605.10616
