AI Native Daily Paper Digest – 20260518
1. CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
🔑 Keywords: CiteVQA, Attribution Hallucination, Document Vision-Language Models, Doc-VQA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce CiteVQA to evaluate document vision-language models, ensuring both answer accuracy and correct citation of evidence.
🛠️ Research Methods:
– Develop a benchmark comprising 1,897 questions across diverse documents, using automated pipelines and expert review for validation.
– Evaluate models using Strict Attributed Accuracy to assess the reliability of answers with correct source citation.
💬 Research Conclusions:
– Current models exhibit notable attribution hallucinations, providing accurate answers but citing incorrect sources.
– The best-performing model achieves a Strict Attributed Accuracy of only 76.0, highlighting a significant gap in model reliability.
👉 Paper link: https://huggingface.co/papers/2605.12882

2. MMSkills: Towards Multimodal Skills for General Visual Agents
🔑 Keywords: Multimodal procedural knowledge, Visual agents, Reusable skills, Decision making, MMSkills
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance visual agents’ decision-making capabilities by developing MMSkills, which leverage external reusable skills through a structured multimodal procedural knowledge framework.
🛠️ Research Methods:
– The introduction of a framework that represents, generates, and utilizes multimodal procedures, utilizing a trajectory-to-skill generator to convert public non-evaluation trajectories into usable multimodal skills.
– Implementation of a branch-loaded multimodal skill agent for inspecting and aligning state cards and keyframes with the live environment.
💬 Research Conclusions:
– MMSkills improve both frontier and smaller visual agents in GUI and game-based benchmarks, demonstrating the effectiveness of integrating external multimodal procedural knowledge with model-internal priors.
👉 Paper link: https://huggingface.co/papers/2605.13527

3. Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
🔑 Keywords: On-policy distillation, parameter-level mechanisms, update trajectory, plug-and-play acceleration, EffOPD
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the parameter-level mechanisms that make On-policy distillation (OPD) efficient and to introduce a method for accelerating OPD training in large language models.
🛠️ Research Methods:
– The research argues that OPD’s efficiency comes from establishing a stable update trajectory early in training.
– EffOPD, a plug-and-play acceleration method, is proposed which selects an extrapolation step size without additional modules or complex tuning.
💬 Research Conclusions:
– EffOPD achieves a 3x speedup in training while maintaining comparable performance, offering insights into efficient post-training for large models.
👉 Paper link: https://huggingface.co/papers/2605.11739

4. Distilling Long-CoT Reasoning through Collaborative Step-wise Multi-Teacher Decoding
🔑 Keywords: CoRD, collaborative multi-teacher decoding, reasoning trajectories, predictive perplexity scoring, beam search
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce CoRD, a framework to enhance reasoning through collaborative multi-teacher decoding and step-wise reasoning synthesis.
🛠️ Research Methods:
– Utilized predictive perplexity-based scoring and beam search for constructing reasoning trajectories.
💬 Research Conclusions:
– CoRD improves reasoning data quality and student performance, demonstrating well generalization across various settings with efficient supervision.
👉 Paper link: https://huggingface.co/papers/2605.02290

5. Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
🔑 Keywords: Flash-GRPO, training efficiency, video diffusion models, iso-temporal grouping, temporal gradient rectification
💡 Category: Generative Models
🌟 Research Objective:
– The aim is to enhance the training efficiency of video diffusion models by resolving temporal variance and gradient inconsistency.
🛠️ Research Methods:
– Implemented Flash-GRPO, a single-step training framework utilizing iso-temporal grouping to maintain temporal consistency and temporal gradient rectification to manage gradient magnitudes.
💬 Research Conclusions:
– Flash-GRPO significantly accelerates training and achieves state-of-the-art alignment quality without compromising stability, effectively supporting models ranging from 1.3B to 14B parameters.
👉 Paper link: https://huggingface.co/papers/2605.15980

6. ReactiveGWM: Steering NPC in Reactive Game World Models
🔑 Keywords: ReactiveGWM, NPC behaviors, cross-attention modules, game-agnostic representation
💡 Category: Generative Models
🌟 Research Objective:
– To introduce ReactiveGWM, which enables dynamic interactions between players and NPCs in game worlds by decoupling player controls from NPC behaviors using diffusion models with cross-attention modules.
🛠️ Research Methods:
– Utilized cross-attention modules and a diffusion backbone to achieve a game-agnostic representation of interactive logic, facilitating zero-shot strategy transfer to various game world models.
💬 Research Conclusions:
– ReactiveGWM demonstrates the ability to maintain detailed player control and robust NPC strategy adherence, allowing for scalable and strategy-rich interactions without domain-specific retraining, as evidenced in evaluations on Street Fighter games.
👉 Paper link: https://huggingface.co/papers/2605.15256
7. Solvita: Enhancing Large Language Models for Competitive Programming via Agentic Evolution
🔑 Keywords: Solvita, Continuous Learning, Reinforcement Learning, Program Synthesis, Multi-agent Frameworks
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Solvita, an agentic evolution framework, that accomplishes state-of-the-art performance in continuous learning for code generation through reinforcement learning applied to knowledge networks.
🛠️ Research Methods:
– Implement a closed-loop system with four specialized agents, each paired with a graph-structured knowledge network, to address the stateless nature of current frameworks and enable dynamic learning via reinforcement learning updates.
💬 Research Conclusions:
– Solvita significantly outperforms existing multi-agent code-generation systems and improves accuracy substantially compared to single-pass baselines in diverse competitive programming environments.
👉 Paper link: https://huggingface.co/papers/2605.15301

8. CM-EVS: Sparse Panoramic RGB-D-Pose Data for Complete Scene Coverage
🔑 Keywords: 3D visual learning, panoramic RGB-D-pose data, ERP viewpoint curator, geometry-consistent
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to convert 3D assets into sparse panoramic RGB-D-pose data that ensures complete scene coverage with minimal redundancy and auditable provenance.
🛠️ Research Methods:
– The authors propose COVER, a training-free ERP viewpoint curator that projects observed geometry into candidate probes, scores coverage, and penalizes depth conflicts.
💬 Research Conclusions:
– Using COVER, the authors developed CM-EVS, a panoramic RGB-D-pose dataset that demonstrates improved trade-off between coverage and conflict, providing a sparse, compact, and auditable resource for geometry-consistent panoramic 3D learning.
👉 Paper link: https://huggingface.co/papers/2605.15597

9. Unlocking Dense Metric Depth Estimation in VLMs
🔑 Keywords: Vision-Language Models, dense geometry, depth head, vision-text supervision, 3D spatial reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– DepthVLM aims to enhance Vision-Language Models’ capabilities in 3D spatial reasoning by adding dense geometry prediction while maintaining multimodal capabilities.
🛠️ Research Methods:
– The study introduces a lightweight depth head added to the LLM backbone and uses a unified vision-text supervision paradigm with a two-stage training schedule to generate full-resolution depth maps.
💬 Research Conclusions:
– DepthVLM outperforms existing VLMs in inference efficiency, surpasses leading vision models, and improves complex 3D spatial reasoning, indicating progress towards a unified foundation model.
👉 Paper link: https://huggingface.co/papers/2605.15876
10. Steered LLM Activations are Non-Surjective
🔑 Keywords: Activation steering, white-box control, interpretability, safety research, surjectivity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore whether activation steering in language models can be replicated by standard textual prompts and establish a distinction between white-box and black-box control methods.
🛠️ Research Methods:
– The study involves casting the capability of steered behavior realization as a surjectivity problem, with both theoretical proofs and empirical illustrations across three widely used LLMs.
💬 Research Conclusions:
– It was concluded that activation steering pushes the model’s residual streams off the state manifold achievable by discrete textual prompts, highlighting a formal separation between white-box steerability and black-box prompting.
👉 Paper link: https://huggingface.co/papers/2604.09839

11. Efficient Image Synthesis with Sphere Latent Encoder
🔑 Keywords: Few-step image generation, Latent denoising model, Pixel space, Image encoder, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to improve efficiency and performance in few-step image generation by separating pixel-space operations from latent denoising training.
🛠️ Research Methods:
– A decoupled framework is implemented, featuring a fixed pretrained image encoder and a separate latent denoising model trained in a spherical latent space. This approach eliminates repeated pixel-space operations during training and inference.
💬 Research Conclusions:
– The proposed method outperforms existing models like Sphere Encoder on datasets such as Animal-Faces, Oxford-Flowers, and ImageNet-1K in both image generation quality and inference speed, while maintaining competitiveness with few-step and multi-step baselines.
👉 Paper link: https://huggingface.co/papers/2605.15592
12. FFAvatar: Few-Shot, Feed-Forward, and Generalizable Avatar Reconstruction
🔑 Keywords: FFAvatar, 3D head avatar reconstruction, FLAME parameters, Multi-View Query-Former, real-time deployment
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce FFAvatar, a feed-forward framework for high-quality 3D head avatar reconstruction from few unposed images.
🛠️ Research Methods:
– Utilization of Multi-View Query-Former to fuse information from several images.
– End-to-end FLAME parameter prediction directly from pixels.
– Implementation of a three-stage training curriculum including scalable pretraining, multi-view fine-tuning, and optional personalization.
💬 Research Conclusions:
– FFAvatar outperforms existing models, achieving a substantial performance gain on the NeRSemble benchmark.
– It enables rapid avatar reconstruction and supports real-time animation on a single NVIDIA A100 GPU.
👉 Paper link: https://huggingface.co/papers/2605.15320

13. WorldAct: Activating Monolithic 3D Worlds into Interactive-Ready Object-Centric Scenes
🔑 Keywords: WorldAct framework, 3D environments, multimodal agents, geometric reconstruction
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces WorldAct, a framework designed to transform static 3D generated environments into editable and interactive scenes, enhancing their utility in immersive content creation and embodied simulation.
🛠️ Research Methods:
– Utilizes a multimodal agent to perform scene decomposition, identify actionable objects, reconstruct geometrically aligned object-level meshes, and apply 3D inpainting to restore backgrounds.
💬 Research Conclusions:
– WorldAct enhances interaction scenarios by enabling object-level editing, collision-aware manipulation, and embodied task execution while maintaining global scene coherence. This suggests a practical step towards developing editable and interactive 3D world models.
👉 Paper link: https://huggingface.co/papers/2605.15843
14. Look Before You Leap: Autonomous Exploration for LLM Agents
🔑 Keywords: autonomous exploration, Exploration Checkpoint Coverage, reinforcement learning, Explore-then-Act paradigm, interaction budget
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to enhance agent adaptability by introducing a focus on autonomous exploration capabilities, addressing premature exploitation issues in large language model-based agents.
🛠️ Research Methods:
– A novel metric called Exploration Checkpoint Coverage is introduced to measure exploration breadth, and a new training strategy that integrates task-execution and exploration rollouts with optimized verifiable rewards is developed.
💬 Research Conclusions:
– The study concludes that systematic exploration training is essential for developing agents that are generalizable and effective in real-world environments, proposing the Explore-then-Act paradigm to improve overall agent performance.
👉 Paper link: https://huggingface.co/papers/2605.16143

15. ChangeFlow — Latent Rectified Flow for Change Detection in Remote Sensing
🔑 Keywords: Change Detection, Change Mask, Generative Formulation, Latent Space, Rectified Flow
💡 Category: Generative Models
🌟 Research Objective:
– The study proposes ChangeFlow, a generative framework for remote sensing change detection, aiming to improve accuracy and robustness through synthesis of change masks in latent space.
🛠️ Research Methods:
– Utilizes a structured yet lightweight conditioning signal and a stochastic design to support sampling-based prediction ensembling, allowing aggregation of multiple predicted change masks.
💬 Research Conclusions:
– ChangeFlow enhances the robustness of change detection models, achieving an average F1 score of 80.4%, outperforming previous methods by 1.3 points on average, while maintaining competitive inference speed.
👉 Paper link: https://huggingface.co/papers/2605.15375

16. Learning POMDP World Models from Observations with Language-Model Priors
🔑 Keywords: Pinductor, POMDP, LLM, Sample Efficiency, World-Model Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate if language-model priors can reduce costly interactions in learning POMDP models from limited observation-action data.
🛠️ Research Methods:
– Introduce Pinductor, which uses an LLM to propose and iteratively refine POMDP models based on belief-based likelihood scores from minimal observation-action trajectories.
💬 Research Conclusions:
– Pinductor matches the performance of methods with privileged hidden state access and significantly exceeds the sample efficiency of traditional tabular approaches, establishing language-model priors as a practical tool for efficient world-model learning in partially observable environments.
👉 Paper link: https://huggingface.co/papers/2605.13740

17. Raster2Seq: Polygon Sequence Generation for Floorplan Reconstruction
🔑 Keywords: sequence-to-sequence modeling, autoregressive decoder, floorplan reconstruction, learnable anchors, attention mechanism
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to reconstruct structured vector graphics from rasterized floorplan images using a sequence-to-sequence paradigm to accurately preserve the geometry and semantics of complex floorplans.
🛠️ Research Methods:
– The proposed method employs an autoregressive decoder, which predicts polygon corners based on image features and prior corners, utilizing learnable anchors representing spatial coordinates to guide attention mechanisms.
💬 Research Conclusions:
– The proposed Raster2Seq method achieves state-of-the-art performance on benchmarks like Structure3D and Raster2Graph, and generalizes well to challenging datasets such as WAFFLE with complex geometric variations.
👉 Paper link: https://huggingface.co/papers/2602.09016
18. Physics-R1: An Audited Olympiad Corpus and Recipe for Visual Physics Reasoning
🔑 Keywords: Multimodal-Physics Evaluation, Vision-Language Reasoning, Train-Eval Contamination, Translation Drift, MCQ Saturation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to identify and document previously undetected issues in multimodal-physics evaluations that distort vision-language reasoning measurements.
🛠️ Research Methods:
– The research utilizes a comprehensive, multi-stage auditing process, including Jaccard, mxbai-embed-large cosine, and Haiku-4.5 LLM-judge audits, to reveal near-duplicates and paraphrase candidates, as well as evaluate translations and response formats.
💬 Research Conclusions:
– Significant distortions exist in current evaluation practices due to train-eval contamination, translation drift, and MCQ saturation. New artifacts released address these gaps and demonstrate improved outcomes in multimodal-physics reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2605.14040

19. GQLA: Group-Query Latent Attention for Hardware-Adaptive Large Language Model Decoding
🔑 Keywords: Group-Query Latent Attention, Multi-head Latent Attention, Efficient Inference, AI Native, Tensor Parallelism
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research introduces Group-Query Latent Attention (GQLA), which enables efficient inference on multiple hardware without the need for retraining by exposing multiple decoding paths from a single set of trained weights.
🛠️ Research Methods:
– The study employs a minimal modification of Multi-head Latent Attention (MLA) to create GQLA with two algebraically equivalent decoding paths suitable for high-performance and commodity GPUs.
💬 Research Conclusions:
– GQLA’s approach allows for adaptability to different target hardware without retraining or custom kernels, offering significant efficiency improvements by supporting zero-redundancy tensor parallelism and improved per-token KV cache compression.
👉 Paper link: https://huggingface.co/papers/2605.15250

20. Known By Their Actions: Fingerprinting LLM Browser Agents via UI Traces
🔑 Keywords: LLM-based agents, model vulnerabilities, interaction timings, passive JavaScript tracker, randomised timing delays
💡 Category: Natural Language Processing
🌟 Research Objective:
– To determine if websites can passively identify the large language model (LLM) powering web browsing agents using behavioral patterns and timing data.
🛠️ Research Methods:
– The study involves 14 frontier LLMs across four web environments, utilizing a passive JavaScript tracker to capture agent actions and interaction timings. Classifiers were trained on these actions to generalize across model sizes and families.
💬 Research Conclusions:
– Passive identification of underlying models in web browsing agents is highly accurate (up to 96% F1). Classifier performance significantly degrades with randomised timing delays, but can largely recover when retrained, indicating a potential security risk regarding targeted attacks on model vulnerabilities.
👉 Paper link: https://huggingface.co/papers/2605.14786

21. MLAIRE: Multilingual Language-Aware Information Retrieval Evaluation Protocal
🔑 Keywords: Multilingual Information Retrieval, Semantic Retrieval, Query-Language Preference, Language-Aware Metrics, Retrieval-Augmented Generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces MLAIRE, an evaluation protocol designed to enhance multilingual information retrieval by separating semantic retrieval accuracy from query-language preference.
🛠️ Research Methods:
– MLAIRE controls pools with parallel passages in different languages, measuring both semantic retrieval accuracy and query-language preference using new language-aware metrics like Language Preference Rate (LPR) and Lang-nDCG.
💬 Research Conclusions:
– Standard retrieval metrics often obscure important differences: while some retrievers excel in semantic retrieval, they might return results in a non-query language; others may favor query-language preference but retrieve less relevant content.
👉 Paper link: https://huggingface.co/papers/2605.07249

22.

23. Stress-Testing the Reasoning Competence of LLMs With Proofs Under Minimal Formalism
🔑 Keywords: ProofGrid, machine-checkable proofs, reasoning depth, epistemic instability, proof synthesis
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce ProofGrid, a benchmark suite for evaluating Large Language Model (LLM) reasoning using machine-checkable proofs to assess reasoning depth and stability.
🛠️ Research Methods:
– Utilization of tasks in proof writing, proof checking, proof masking, and proof gap-filling with minimal formal notation, particularly using Natural Deduction Language (NDL).
– Development of an instrumented proof-checking pipeline that enhances measurement resolution by locating substantive reasoning failures.
💬 Research Conclusions:
– Results indicate frontier models show proficiency in foundational tasks but struggle with complex tasks requiring global combinatorial reasoning or low-level proof synthesis.
– Identification of epistemic instability, where models produce flawed proofs yet correctly reject isolated local inferences, formalized with an Epistemic Stability Index.
– Complementary analyses using 2PL IRT analyses, Wright maps, and a normalized task-discrimination measure based on Fisher information.
👉 Paper link: https://huggingface.co/papers/2605.12524

24. No One Knows the State of the Art in Geospatial Foundation Models
🔑 Keywords: Geospatial foundation models, Evaluation, Standardization, Model weights, Pretraining controls
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to address the lack of standardized evaluation and reporting in Geospatial Foundation Models (GFMs), which affects performance comparison and reproducibility.
🛠️ Research Methods:
– An audit of 152 papers revealing discrepancies in evaluations and protocols across different studies.
💬 Research Conclusions:
– The authors propose six concrete steps, including named-license weight release and shared core evaluations, to improve standardization and foster innovation in GFMs.
👉 Paper link: https://huggingface.co/papers/2605.12678

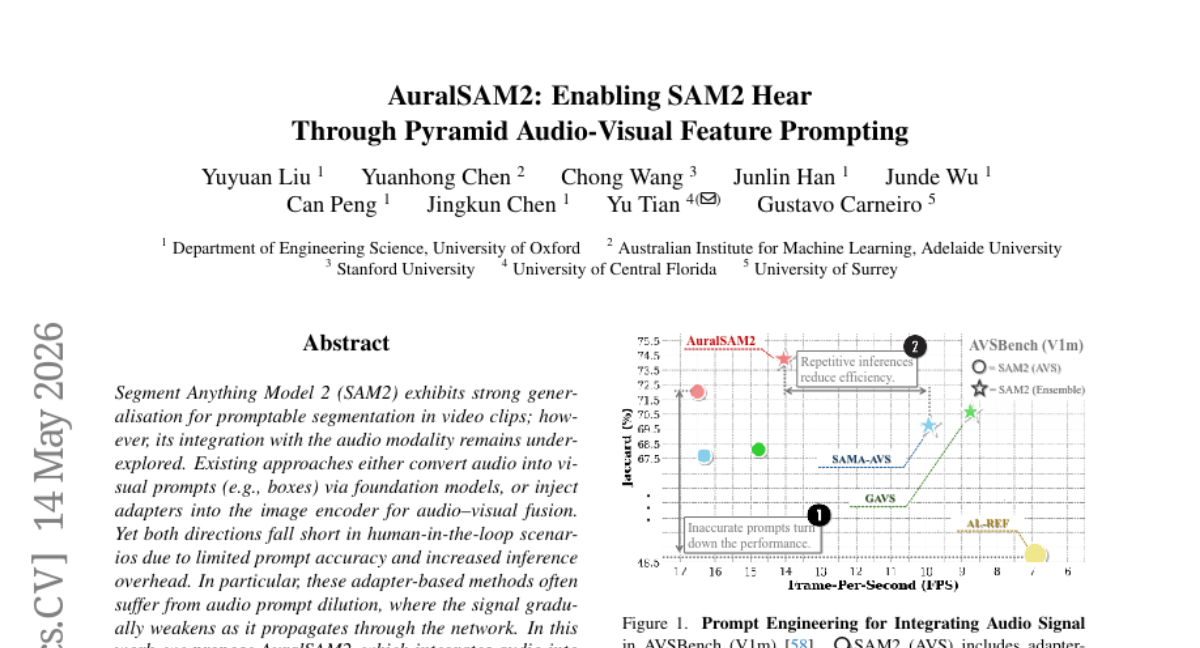
25. AuralSAM2: Enabling SAM2 Hear Through Pyramid Audio-Visual Feature Prompting
🔑 Keywords: AuralFuser, cross-modal influence, promptable segmentation, audio-guided contrastive loss
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To integrate audio into the Segment Anything Model 2 (SAM2) using the AuralFuser module to enhance cross-modal influence while preserving segmentation efficiency.
🛠️ Research Methods:
– Developed AuralFuser to fuse audio and visual features, generating sparse and dense prompts guided by audio within SAM2’s feature pyramid.
– Introduced an audio-guided contrastive loss for better alignment of auditory and visual modalities.
💬 Research Conclusions:
– Achieved notable accuracy improvements on public benchmarks with minimal impact on the interactive efficiency of promptable segmentation.
👉 Paper link: https://huggingface.co/papers/2506.01015
26. Follow the Mean: Reference-Guided Flow Matching
🔑 Keywords: Flow Matching, Controllable Generation, Reference-Mean Guidance, Semi-Parametric Guidance, AI-Generated Summary
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to demonstrate that flow matching enables controllable generation through example-based adaptation, providing an alternative to the traditional methods of fine-tuning and auxiliary networks.
🛠️ Research Methods:
– The study employs two methods for controllable generation: Reference-Mean Guidance, which is training-free and applies a closed-form endpoint-mean correction to a pre-trained model, and Semi-Parametric Guidance, which uses a learned residual refiner to match model quality while allowing changes at inference time.
💬 Research Conclusions:
– The findings suggest a paradigm shift towards generative models that adapt through data rather than parameter updates, offering a new control interface that relies on modifying the reference set rather than model weights.
👉 Paper link: https://huggingface.co/papers/2605.10302

27. Forgetting That Sticks: Quantization-Permanent Unlearning via Circuit Attribution
🔑 Keywords: Quantization, Machine Unlearning, MANSU, Causal Circuit Attribution, Sparsity-Permanence Tradeoff
💡 Category: Machine Learning
🌟 Research Objective:
– The paper investigates how quantization affects machine unlearning and introduces the concept of a sparsity-permanence tradeoff.
🛠️ Research Methods:
– The research employs MANSU, combining causal circuit attribution, circuit-restricted null-space projection, and other techniques to address the limitations presented by quantization.
💬 Research Conclusions:
– MANSU effectively resolves issues with preserving forgetting and retention post-quantization, distinguishing structural erasure from behavioral suppression, and is validated across various models.
👉 Paper link: https://huggingface.co/papers/2605.15138

28. OmniHumanoid: Streaming Cross-Embodiment Video Generation with Paired-Free Adaptation
🔑 Keywords: Cross-embodiment video generation, Humanoid embodiments, Motion transfer, Embodiment-specific adaptation, Motion fidelity
💡 Category: Generative Models
🌟 Research Objective:
– The objective of the research is to enable scalable adaptation of humanoid embodiments by factorizing motion transfer and embodiment-specific adaptation.
🛠️ Research Methods:
– Develop a framework called OmniHumanoid that learns a shared motion transfer model from motion-aligned paired videos across multiple embodiments and adapts to new ones using unpaired videos through lightweight embodiment-specific adapters.
– Introduce a branch-isolated attention design to separate motion conditioning from embodiment-specific modulation.
💬 Research Conclusions:
– OmniHumanoid achieves strong motion fidelity and embodiment consistency, enabling scalable adaptation to unseen humanoid embodiments without retraining the shared motion model.
👉 Paper link: https://huggingface.co/papers/2605.12038

29. HodgeCover: Higher-Order Topological Coverage Drives Compression of Sparse Mixture-of-Experts
🔑 Keywords: Sparse Mixture-of-Experts, harmonic kernel, HodgeCover, learning-free compression, simplicial topology
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper introduces a novel compression approach for Sparse Mixture-of-Experts layers using harmonic kernel analysis to optimize expert merging patterns, enabling efficient inference without retraining.
🛠️ Research Methods:
– The method employs harmonic kernel analyses from simplicial topology and Hodge-decomposition of edge-barrier signals, combined with a hybrid variant of HodgeCover and weight pruning.
💬 Research Conclusions:
– The approach successfully achieves state-of-the-art performance in aggressive expert reduction on Sparse MoE backbones, indicating that the harmonic kernel is pivotal in improving compressor effectiveness in key scenarios.
👉 Paper link: https://huggingface.co/papers/2605.13997

30. Learning from Failures: Correction-Oriented Policy Optimization with Verifiable Rewards
🔑 Keywords: Correction-Oriented Policy Optimization, Reinforcement Learning with Verifiable Rewards, reasoning capabilities, error correction, failed trajectories
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces Correction-Oriented Policy Optimization (CIPO) to enhance reinforcement learning by converting failed trajectories into correction supervision, thereby improving reasoning and error correction in large language models.
🛠️ Research Methods:
– By integrating correction samples derived from the model’s own failed attempts with the standard Reinforcement Learning with Verifiable Rewards (RLVR) objective, CIPO refines learning effectiveness and error correction capabilities.
💬 Research Conclusions:
– Extensive experiments on 11 benchmarks in mathematical reasoning and code generation demonstrate that CIPO significantly surpasses existing baselines in both reasoning and correction performance, enhancing intrinsic reasoning capacity rather than merely adjusting existing correct answer probabilities.
👉 Paper link: https://huggingface.co/papers/2605.14539

31. Agentic Discovery of Neural Architectures: AIRA-Compose and AIRA-Design
🔑 Keywords: AI agents, foundation models, Transformer-based, autonomous design, AIRA-Compose, AIRA-Design
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to explore the autonomous design of foundation models that go beyond standard Transformers through a dual-framework approach, focusing on architectural search and mechanistic implementation.
🛠️ Research Methods:
– Utilizes a dual-framework: AIRA-Compose for high-level architecture search and AIRA-Design for low-level mechanistic implementation, involved 11 agents for architecture search and 20 agents for designing attention mechanisms.
💬 Research Conclusions:
– The AI-designed architectures improved performance and efficiency, with AIRAformer-D and AIRAhybrid-D enhancing accuracy on downstream tasks and models such as AIRAformer-C scaling significantly faster. These frameworks demonstrate the potential for AI agents to discover architectures and optimizations that match or surpass human-designed baselines, paving the way toward recursive self-improvement.
👉 Paper link: https://huggingface.co/papers/2605.15871

32. MobileEgo Anywhere: Open Infrastructure for long horizon egocentric data on commodity hardware
🔑 Keywords: Vision Language Action, egocentric datasets, mobile hardware, smartphone sensors
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop MobileEgo Anywhere, a framework for collecting extensive egocentric robot data using smartphone sensors for the large-scale training of Vision Language Action models.
🛠️ Research Methods:
– Utilization of modern smartphone sensor suites for long-term camera pose tracking, releasing a novel dataset of 200 hours of egocentric data, and providing an open-source mobile application and processing pipeline.
💬 Research Conclusions:
– The framework lowers hardware barriers, democratizes data collection, and enables large-scale acquisition of diverse egocentric data, fostering the accelerated development of generalizable robotic policies.
👉 Paper link: https://huggingface.co/papers/2605.05945
33. Sparse Autoencoders enable Robust and Interpretable Fine-tuning of CLIP models
🔑 Keywords: SAE-FT, vision-language models, fine-tuning, Sparse Autoencoder, distribution shifts
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a novel method called SAE-FT for robust fine-tuning of vision-language models while improving robustness against distribution shifts.
🛠️ Research Methods:
– Utilized sparse autoencoder constraints on visual representations to regularize changes, preventing the addition/removal of semantically significant features during fine-tuning.
💬 Research Conclusions:
– SAE-FT is computationally efficient and matches or exceeds state-of-the-art performance in ImageNet and distribution shift benchmarks, while maintaining interpretability and preventing catastrophic forgetting.
👉 Paper link: https://huggingface.co/papers/2605.15961

34. DiagnosticIQ: A Benchmark for LLM-Based Industrial Maintenance Action Recommendation from Symbolic Rules
🔑 Keywords: Large Language Models, AI-Generated Summary, Symbolic Rules, Failure Modes, Embedding-based Distractor Sampling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to evaluate whether large language models (LLMs) can effectively translate industrial monitoring rules into maintenance actions, focusing on their potential as decision support systems in complex environments.
🛠️ Research Methods:
– Development of a benchmark consisting of 6,690 expert-validated multiple-choice questions based on 118 rule-action pairs across 16 asset types.
– Implementation of a symbolic-to-MCQA pipeline normalizing rules to Disjunctive Normal Form, alongside embedding-based distractor sampling.
– Evaluation of 29 LLMs and 4 embedding baselines, probing different failure modes such as brittleness and pattern-matching through five variants.
💬 Research Conclusions:
– The top-performing LLMs are competitively close, although the best shows a significant advantage according to the Bradley-Terry Elo ranking.
– Models exhibit vulnerabilities, losing accuracy when presented with expanded distractors and revealing pattern-matching tendencies under condition inversion.
– The study identifies calibration, rather than capability, as a bottleneck in deploying these models for fault detection in industrial applications.
👉 Paper link: https://huggingface.co/papers/2605.08614

35. MetaAgent-X : Breaking the Ceiling of Automatic Multi-Agent Systems via End-to-End Reinforcement Learning
🔑 Keywords: MetaAgent-X, Automatic Multi-Agent Systems, End-to-End Training, Reinforcement Learning, Stagewise Co-evolution
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce MetaAgent-X, an end-to-end reinforcement learning framework that optimizes automatic multi-agent systems design and execution.
🛠️ Research Methods:
– Utilization of Executor Designer Hierarchical Rollout and Stagewise Co-evolution to improve training stability and reveal the dynamics of co-evolution between designer and executor.
💬 Research Conclusions:
– MetaAgent-X outperforms existing automatic MAS baselines with up to 21.7% gains, demonstrating that a stagewise co-evolution process is effective for building self-designing and self-executing agentic models.
👉 Paper link: https://huggingface.co/papers/2605.14212

36. PAGER: Bridging the Semantic-Execution Gap in Point-Precise Geometric GUI Control
🔑 Keywords: AI Native, GUI agents, vision-language models, topology-aware agent, precision-sensitive tasks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve precision-sensitive tasks for GUI agents through a topology-aware framework that enhances task success with structured planning and pixel-level execution.
🛠️ Research Methods:
– Introduction of PAGE Bench with 4,906 problems and pixel-level GUI actions.
– Development of PAGER, a topology-aware agent utilizing dependency-structured planning and precision-aligned reinforcement learning.
💬 Research Conclusions:
– PAGER significantly increases task success and step success rate compared to baseline models, establishing a new standard for point-precise GUI control.
👉 Paper link: https://huggingface.co/papers/2605.15963

37. From Plans to Pixels: Learning to Plan and Orchestrate for Open-Ended Image Editing
🔑 Keywords: experiential framework, long-horizon image editing, reward-driven execution, coherence, reliability
💡 Category: Computer Vision
🌟 Research Objective:
– To propose a new experiential framework for enhancing coherence and reliability in long-horizon image editing tasks through a combination of planning and reward-driven execution.
🛠️ Research Methods:
– The framework employs a planner for generating structured atomic decompositions, and an orchestrator to select tools and regions for executing tasks, facilitated by a vision language judge to provide outcome-based rewards.
💬 Research Conclusions:
– By integrating planning with reward-driven execution, the proposed approach demonstrates more coherent and reliable edits compared to existing single-step or rule-based multistep methods.
👉 Paper link: https://huggingface.co/papers/2605.15181

38. Hölder Policy Optimisation
🔑 Keywords: Group Relative Policy Optimisation, Hölder mean, token-level probability aggregation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance large language models by optimizing policy update mechanisms through a novel framework called HölderPO.
🛠️ Research Methods:
– Introduced HölderPO framework leveraging the Hölder mean to unify token-level probability aggregation, with dynamic annealing to adjust parameter p for optimal trade-off management.
💬 Research Conclusions:
– HölderPO provides superior stability and convergence, achieving a state-of-the-art average accuracy of 54.9% on mathematical benchmarks and a 93.8% success rate on ALFWorld, outperforming standard GRPO with a 7.2% relative gain.
👉 Paper link: https://huggingface.co/papers/2605.12058

39. Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR
🔑 Keywords: Reinforcement Learning, Strategy Nudging, Verifiable Rewards, Exploration, Large Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve reasoning capabilities in large language models by enhancing reinforcement learning with verifiable rewards through the NudgeRL framework, which uses structured exploration and strategy nudging.
🛠️ Research Methods:
– Introduce Strategy Nudging to condition each rollout on strategy-level contexts for diverse reasoning trajectories.
– Propose a unified objective that decomposes reward signals and incorporates a distillation objective for transferring behaviors to the base policy.
💬 Research Conclusions:
– NudgeRL outperforms standard GRPO with larger rollout budgets and exceeds performance of oracle-guided RL baselines across multiple math benchmarks, demonstrating an efficient alternative to brute-force scaling and privileged information methods.
👉 Paper link: https://huggingface.co/papers/2605.15726

40. InsightTok: Improving Text and Face Fidelity in Discrete Tokenization for Autoregressive Image Generation
🔑 Keywords: InsightTok, discrete visual tokenization, perceptual losses, autoregressive image generation
💡 Category: Generative Models
🌟 Research Objective:
– The paper targets the improvement of text and face reconstruction in visual generation by addressing the limitations of standard discrete-tokenizer objectives.
🛠️ Research Methods:
– A novel framework called InsightTok is introduced, utilizing localized, content-aware perceptual losses, along with a compact 16k codebook and a 16x downsampling rate to enhance text and face fidelity.
💬 Research Conclusions:
– InsightTok significantly surpasses previous tokenizers in reconstructing text and face details without sacrificing general image reconstruction quality, demonstrating the benefits of specialized supervision in tokenizer training.
👉 Paper link: https://huggingface.co/papers/2605.14333

41. DexJoCo: A Benchmark and Toolkit for Task-Oriented Dexterous Manipulation on MuJoCo
🔑 Keywords: DexJoCo, dexterous manipulation, benchmark, toolkit, dexterous hands
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To establish a benchmark and toolkit, DexJoCo, for evaluating dexterous manipulation tasks, emphasizing tool-use, bimanual coordination, and long-horizon execution.
🛠️ Research Methods:
– Development of a benchmark and toolkit with 11 functional tasks.
– Implementation of a low-cost data collection system generating 1.1K task trajectories.
– Application of domain randomization for robustness assessment, alongside diverse benchmarks including visual and dynamics randomization, multi-task training, and action-head adaptation.
💬 Research Conclusions:
– Identification of key challenges and common limitations in current dexterous manipulation policies, providing insights for future research directions in dexterous hand robot learning.
👉 Paper link: https://huggingface.co/papers/2605.16257
42. FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
🔑 Keywords: FashionChameleon, motion coherence, AI-generated summary, real-time generation, Teacher Model
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to achieve real-time interactive multi-garment video customization while preserving motion coherence, specifically important for applications in e-commerce and content creation.
🛠️ Research Methods:
– The FashionChameleon framework employs three key techniques:
1. A Teacher Model with In-Context Learning using single-garment video data to ensure coherence during garment switching.
2. Streaming Distillation and In-Context Learning for consistency and efficiency.
3. A Training-Free KV Cache Rescheduling method to allow seamless garment switching while maintaining motion coherence.
💬 Research Conclusions:
– FashionChameleon enables interactive customization and consistent long-video extrapolation, achieving real-time generation rates significantly faster than existing methods.
👉 Paper link: https://huggingface.co/papers/2605.15824

43. PhysBrain 1.0 Technical Report
🔑 Keywords: PhysBrain 1.0, physical commonsense supervision, Vision-language-action models, embodied control tasks, language-sensitive adaptation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Leverage human egocentric video to generate physical commonsense supervision for improving vision-language-action models in embodied control tasks.
🛠️ Research Methods:
– Employ a data engine to convert large-scale human egocentric video into structured supervision by extracting scene elements, spatial dynamics, action execution, and depth-aware relations, and turn these into question-answer style supervision for training.
💬 Research Conclusions:
– PhysBrain 1.0 achieves state-of-the-art results across several benchmarks, showing strong performance, especially in out-of-domain scenarios, suggesting that scaling physical commonsense from human interaction video enhances multimodal understanding and robot action execution.
👉 Paper link: https://huggingface.co/papers/2605.15298
