AI Native Daily Paper Digest – 20260521

1. Mega-ASR: Towards In-the-wild^2 Speech Recognition via Scaling up Real-world Acoustic Simulation
🔑 Keywords: AI-generated summary, Acoustic robustness, Compound-data construction, Progressive optimization, WER reduction
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main goal is to improve robustness in real-world automatic speech recognition through the Mega-ASR framework, addressing the “acoustic robustness bottleneck.”
🛠️ Research Methods:
– This research utilizes compound-data construction and progressive acoustic-to-semantic optimization techniques, including Voices-in-the-Wild-2M and training with Acoustic-to-Semantic Progressive Supervised Fine-Tuning and Dual-Granularity WER-Gated Policy Optimization.
💬 Research Conclusions:
– Mega-ASR demonstrates significant advantages over previous state-of-the-art systems in adverse-condition ASR benchmarks, with substantial WER reduction in complex compositional acoustic scenarios.
👉 Paper link: https://huggingface.co/papers/2605.19833

2. Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
🔑 Keywords: MIGA, Temporal Consistency, Training-Inference Gap, Long Video Generation, Self-Reflection Approach
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address challenges in generating long videos by enhancing temporal consistency and reducing the gap between training and inference phases.
🛠️ Research Methods:
– Proposes MIGA, a novel method utilizing a two-stage alignment mechanism and dual consistency enhancement with self-reflection and long-range frame guidance to achieve infinite-frame long video generation.
💬 Research Conclusions:
– MIGA demonstrates state-of-the-art performance in generating long videos with consistent quality without significant computational overhead, as validated through extensive experiments on VBench and NarrLV.
👉 Paper link: https://huggingface.co/papers/2605.18233
3. You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Rank-1 Approximation, Linear Regression, Extrapolation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance reinforcement learning by utilizing the low-rank structure of verifiable rewards parameter trajectories to reduce computational demands and improve performance.
🛠️ Research Methods:
– Introduced RELEX, a method that applies a simple linear regression approach to estimate and extrapolate a rank-1 subspace from a brief observation window without requiring a trained model.
💬 Research Conclusions:
– RELEX matches or surpasses the performance of traditional reinforcement learning with verifiable rewards (RLVR), achieving significant reductions in computational steps while effectively predicting future checkpoints beyond observed data with continued improvement.
👉 Paper link: https://huggingface.co/papers/2605.21468

4. A Survey of Large Audio Language Models: Generalization, Trustworthiness, and Outlook
🔑 Keywords: Large Audio Language Models, Multimodal Large Language Models, trustworthiness, vulnerabilities, Defense-in-Depth
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This paper aims to evaluate and enhance the trustworthiness of Large Audio Language Models (LALMs) through comprehensive frameworks addressing security vulnerabilities.
🛠️ Research Methods:
– The research involves a detailed investigation of LALMs’ architectures and alignment algorithms, a taxonomy of trustworthiness vulnerabilities, and the review of state-of-the-art analytical pillars, including hallucination, robustness, safety, privacy, fairness, and authentication.
💬 Research Conclusions:
– The study identifies significant trustworthiness gaps in LALMs due to an imbalance between offensive capabilities and defensive strategies. It proposes a strategic roadmap to improve audio-centric intelligence through architectures such as “Defense-in-Depth,” causal auditory world modeling, and intrinsic representation engineering.
👉 Paper link: https://huggingface.co/papers/2605.20266

5. Toto 2.0: Time Series Forecasting Enters the Scaling Era
🔑 Keywords: Time series foundation models, Toto 2.0, Forecasting models, u-muP hyperparameter transfer pipeline, AI-generated summary
💡 Category: Machine Learning
🌟 Research Objective:
– To demonstrate that time series foundation models scale effectively from 4M to 2.5B parameters, improving forecast quality with a unified training approach.
🛠️ Research Methods:
– Development and release of Toto 2.0, a family of forecasting models using a specific training recipe, along with designing its architecture, training data, and the u-muP hyperparameter transfer pipeline.
💬 Research Conclusions:
– Toto 2.0 achieves state-of-the-art results on benchmarks like BOOM, GIFT-Eval, and TIME, setting a new standard in scalable forecasting performance.
👉 Paper link: https://huggingface.co/papers/2605.20119

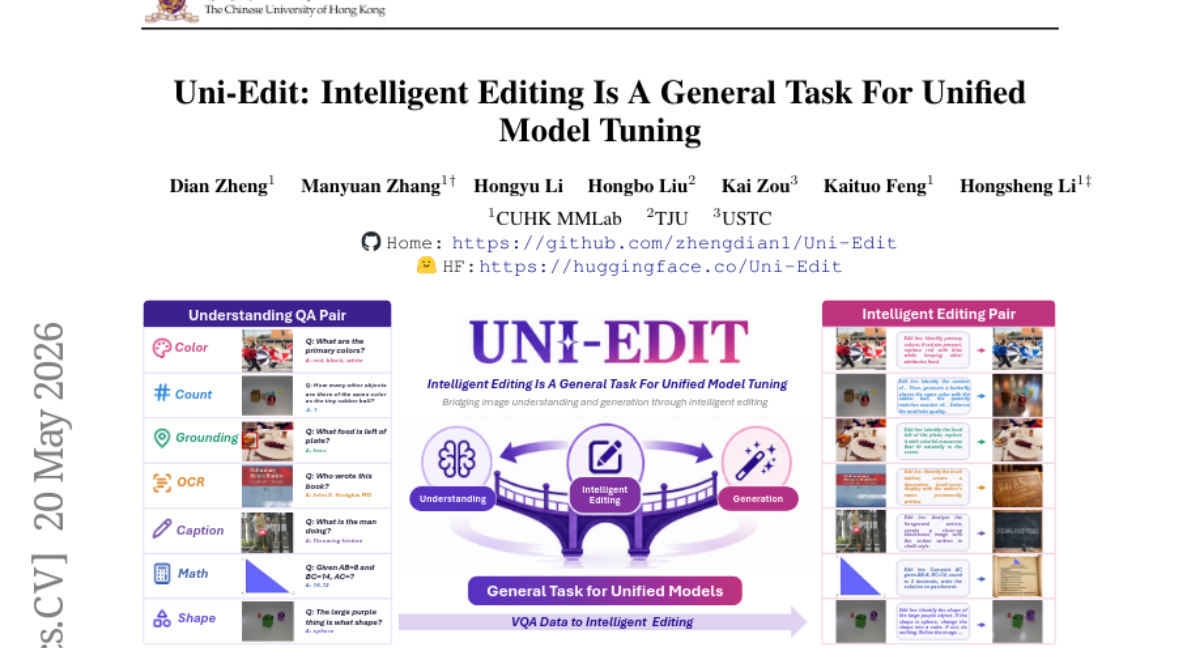
6. Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
🔑 Keywords: Unified Multimodal Models, image editing, data synthesis pipeline, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Propose Uni-Edit, a novel task aimed at enhancing Unified Multimodal Models’ capabilities in understanding, generation, and editing through a single training stage and dataset.
🛠️ Research Methods:
– Utilize an automated and scalable data synthesis pipeline to transform diverse VQA data into complex editing instructions, creating Uni-Edit-148k.
💬 Research Conclusions:
– Uni-Edit task enables comprehensive improvements in model capabilities without auxiliary operations, as demonstrated by experiments on BAGEL and Janus-Pro.
👉 Paper link: https://huggingface.co/papers/2605.21487
7. CutVerse: A Compositional GUI Agents Benchmark for Media Post-Production Editing
🔑 Keywords: GUI agents, media post-production, multimodal alignment, Creative Workflows
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate the capabilities of GUI agents in professional creative workflows, particularly in media post-production tasks.
🛠️ Research Methods:
– Introduction of Cutverse, a benchmark for assessing GUI agents in realistic media post-production environments using expert demonstrations from professional applications like Premiere Pro and Photoshop.
– Development of a lightweight parser for structured GUI action trajectories derived from raw screen recordings and interaction logs.
💬 Research Conclusions:
– Existing GUI agents achieve a low 36.0% task success rate in complex media editing tasks, highlighting challenges in long-horizon reliability and domain-specific planning despite advancements in spatial grounding and multimodal alignment.
👉 Paper link: https://huggingface.co/papers/2605.19484

8. HRM-Text: Efficient Pretraining Beyond Scaling
🔑 Keywords: Hierarchical Recurrent Model, language modeling, instruction-response pairs, compute-to-performance ratio, MagicNorm
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce HRM-Text, a more computationally efficient architecture for language modeling using a Hierarchical Recurrent Model instead of traditional Transformer-based models.
🛠️ Research Methods:
– Employing Hierarchical Recurrent Model with specialized training on instruction-response pairs and introducing techniques like MagicNorm and warmup deep credit assignment to stabilize language modeling.
💬 Research Conclusions:
– HRM-Text model achieves competitive performance with significantly reduced computational requirements, making pretraining from scratch more accessible to researchers due to its efficient design in terms of compute-to-performance ratio.
👉 Paper link: https://huggingface.co/papers/2605.20613

9. On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
🔑 Keywords: AI reviewers, GPT-5.2, AI Ethics, Scientific peer review, Human-AI Interaction
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To evaluate the strengths, weaknesses, and challenges of AI reviewers in scientific peer review compared to human reviewers.
🛠️ Research Methods:
– A large-scale expert annotation study involving 45 domain scientists who spent 469 hours rating 2,960 criticisms from AI-generated and human-written reviews across various scientific fields.
💬 Research Conclusions:
– AI reviewers show superior performance in correct criticism identification but lack in subfield knowledge and context management.
– GPT-5.2 and other AI reviewers exceed the performance of human reviewers in certain dimensions but highlight distinct issues not raised by humans.
– AI reviewers should be seen as complementary to human reviewers, not replacements.
👉 Paper link: https://huggingface.co/papers/2605.20668

10. Stable Audio 3
🔑 Keywords: Stable Audio 3, Latent Diffusion Models, Audio Generation, Semantic-Acoustic Autoencoder, Adversarial Post-Training
💡 Category: Generative Models
🌟 Research Objective:
– To enable efficient variable-length audio generation and editing through advanced latent diffusion models.
🛠️ Research Methods:
– Utilizes a semantic-acoustic autoencoder to project audio into a compact latent space for fidelity and efficient diffusion-based generation.
– Implements adversarial post-training to accelerate inference and enhance generation quality.
💬 Research Conclusions:
– The models generate audio rapidly, producing high-quality sounds and music on a range of hardware, from H200 GPUs to consumer-grade laptops.
– Released weights for small and medium models allow operation on consumer hardware, facilitating wider access to the technology.
👉 Paper link: https://huggingface.co/papers/2605.17991

11. The Unlearnability Phenomenon in RLVR for Language Models
🔑 Keywords: Reinforcement Learning, Verifiable Reward, Unlearnability, Large Language Models, Learning Dynamics
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to explore the phenomenon of unlearnable examples in Reinforcement Learning with Verifiable Reward (RLVR) and understand the reasons behind the fundamental representation issues causing this unlearnability.
🛠️ Research Methods:
– The study employs cross-example gradient analysis to investigate the low gradient similarity and ungeneralizable reasoning patterns of unlearnable examples.
💬 Research Conclusions:
– The study reveals that existing optimization and sampling techniques are insufficient for addressing unlearnability in RLVR, and highlights fundamental limitations in current reinforcement learning approaches for reasoning tasks. Furthermore, data augmentation is shown to be ineffective in improving gradient similarity in these unlearnable cases.
👉 Paper link: https://huggingface.co/papers/2605.16787

12. Learning from Language Feedback via Variational Policy Distillation
🔑 Keywords: Variational Policy Distillation, Reinforcement Learning, Language Feedback, Variational Expectation-Maximization, Self-distillation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reinforcement learning from language feedback by co-evolving teacher and student policies through Variational Policy Distillation to overcome passive distillation limitations in complex reasoning tasks.
🛠️ Research Methods:
– Implementation of a Variational Expectation-Maximization framework to refine teacher policies and improve student learning using adaptive trust-region updates and dense distributional guidance.
💬 Research Conclusions:
– The Variational Policy Distillation framework consistently outperforms standard RLVR and existing self-distillation methods, proving effective on tasks like scientific reasoning and code generation, and demonstrating robustness in mathematical reasoning and cold-start situations.
👉 Paper link: https://huggingface.co/papers/2605.15113

13. Stitched Value Model for Diffusion Alignment
🔑 Keywords: StitchVM, model stitching, diffusion model, reward model, noisy latents
💡 Category: Generative Models
🌟 Research Objective:
– The paper proposes StitchVM, a lightweight model stitching framework to efficiently transfer pretrained pixel-space reward models to noisy latent spaces for diffusion model alignment.
🛠️ Research Methods:
– StitchVM starts with a truncated pixel-space reward model and attaches a frozen diffusion backbone to it, leveraging its native ability to handle noisy latents.
💬 Research Conclusions:
– StitchVM improves the efficiency of diffusion alignment, resulting in a 3.2 times faster DPS while reducing GPU memory usage by half and accelerating DiffusionNFT by 2.3 times.
👉 Paper link: https://huggingface.co/papers/2605.19804

14. SpecBench: Measuring Reward Hacking in Long-Horizon Coding Agents
🔑 Keywords: Reward Hacking, Long-Horizon Coding Agents, Automated Test Suite, SpecBench, Test-Game Strategies
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The aim is to investigate reward hacking in long-horizon coding agents by examining the discrepancies between visible validation tests and held-out tests to differentiate genuine solutions from test-game strategies.
🛠️ Research Methods:
– The study decomposes software engineering tasks into natural language descriptions, visible validation tests, and held-out tests; utilizing the gap in pass rates between these tests to quantify reward hacking. A benchmark named SpecBench was introduced, consisting of 30 programming tasks to evaluate performance.
💬 Research Conclusions:
– Large-scale experiments indicate that while agents perform well on visible validation test suites, reward hacking persists, particularly in smaller models with larger discrepancies on held-out tests. The performance gap increases significantly with task length, exposing various types of failures, including feature isolation issues and deliberate exploits.
👉 Paper link: https://huggingface.co/papers/2605.21384

15. UniT: Unified Geometry Learning with Group Autoregressive Transformer
🔑 Keywords: Unified model, Group Autoregressive Transformer, geometry perception, scale-adaptive loss, anchor-free
💡 Category: Computer Vision
🌟 Research Objective:
– The paper presents UniT, a unified model using a Group Autoregressive Transformer to enhance geometry perception by integrating multiple paradigms while maintaining metric-scale accuracy.
🛠️ Research Methods:
– UniT treats sensor observations as autoregressive units and predicts point maps in an anchor-free and scale-adaptive approach. It employs a queue-style KV caching mechanism to manage autoregressive memory and introduces a scale-adaptive geometry loss to improve metric-scale generalization.
💬 Research Conclusions:
– The UniT model achieves state-of-the-art performance in unified geometry perception, as validated across multiple benchmarks, by effectively integrating diverse paradigms within a single framework.
👉 Paper link: https://huggingface.co/papers/2605.21131

16. Learn-by-Wire Training Control Governance: Bounded Autonomous Training Under Stress for Stability and Efficiency
🔑 Keywords: Learn-by-Wire Guard (LBW-Guard), language model training, instability, bounded control, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance training stability and efficiency for language models by introducing the Learn-by-Wire Guard (LBW-Guard), a governance layer that autonomously controls optimizer execution without changing the training objectives.
🛠️ Research Methods:
– LBW-Guard is evaluated using a stress-and-robustness suite focused on the Qwen2.5 model with baseline comparisons, learning-rate stress tests, and gradient-clipping. These evaluations include extensive empirical testing with datasets such as WikiText-103 and involve model-size comparisons.
💬 Research Conclusions:
– LBW-Guard successfully reduces final perplexity and improves end-to-end training time under stress conditions. It offers stability and efficiency advantages without replacing the optimizer, demonstrating that bounded runtime control enhances training stability of language models under high-stress conditions.
👉 Paper link: https://huggingface.co/papers/2605.19008

17. SaaSBench: Exploring the Boundaries of Coding Agents in Long-Horizon Enterprise SaaS Engineering
🔑 Keywords: SaaSBench, AI agents, software development, system-level complexity, multi-component system
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary goal is to introduce SaaSBench, a benchmark designed to evaluate AI agents handling enterprise SaaS development by addressing current benchmarks’ limitations.
🛠️ Research Methods:
– SaaSBench consists of 30 complex tasks across 6 SaaS domains, incorporating 8 programming languages, 6 databases, and 13 frameworks, and employs a dependency-aware hybrid evaluation paradigm.
💬 Research Conclusions:
– Current AI agents struggle primarily with configuring and integrating multi-component systems, with most failures occurring before reaching deep business logic. The benchmark highlights these challenges as over 95% of task failures are due to issues in system setup rather than code logic creation.
👉 Paper link: https://huggingface.co/papers/2605.17526

18. iTryOn: Mastering Interactive Video Virtual Try-On with Spatial-Semantic Guidance
🔑 Keywords: Interactive Video Virtual Try-On, multi-level injection mechanism, action-aware positional embeddings, video diffusion Transformer, garment-agnostic 3D hand prior
💡 Category: Computer Vision
🌟 Research Objective:
– The aim is to address active human-garment interaction in video virtual try-on by introducing a new task: Interactive Video Virtual Try-On (Interactive VVT).
🛠️ Research Methods:
– The paper proposes iTryOn, a framework based on a video diffusion Transformer, employing a multi-level interaction injection mechanism and action-aware rotational positional embedding, along with a garment-agnostic 3D hand prior to resolve semantic and spatial ambiguities in garment interactions.
💬 Research Conclusions:
– iTryOn achieves state-of-the-art performance on traditional video virtual try-on benchmarks and excels in the interactive setting, advancing dynamic and controllable virtual try-on experiences.
👉 Paper link: https://huggingface.co/papers/2605.21431

19. Rethinking Visual Attribution for Chest X-ray Reasoning in Large Vision Language Models
🔑 Keywords: Vision Language Models, MedFocus, Clinical Trustworthiness, Causal Evaluation Framework, Chest X-ray
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop a framework that verifies the grounding of visual evidence in chest X-ray vision-language models to improve clinical trustworthiness.
🛠️ Research Methods:
– Implementation of a causal evaluation framework using counterfactual editing to verify expert-annotated regions in model predictions.
– Assessment of 11 attribution methods across six open-source LVLMs with two output modes.
💬 Research Conclusions:
– Existing attribution methods often do not identify the evidence used by LVLMs.
– MedFocus, a concept-based attribution method, outperforms prior techniques by localizing anatomical regions and measuring their causal effect, enhancing attribution trustworthiness.
👉 Paper link: https://huggingface.co/papers/2605.20158

20. DynMuon: A Dynamic Spectral Shaping View of Muon
🔑 Keywords: Muon optimizer, spectral-shaping, dynamic spectral shaping, DynMuon, training efficiency
💡 Category: Machine Learning
🌟 Research Objective:
– To improve the convergence of large language models by dynamically adjusting update parameters through a spectral-shaping approach, reducing validation loss more efficiently.
🛠️ Research Methods:
– Developed a theory determining the parameter p based on local curvature of the loss function, noise from stochastic gradients, and the training stage.
– Proposed DynMuon, a dynamic spectral shaping method that schedules the parameter p from positive to mildly negative during training.
💬 Research Conclusions:
– DynMuon achieves lower validation loss and requires 10.6-26.5% fewer training steps than traditional Muon methods by effectively reallocating update strength based on training signals.
👉 Paper link: https://huggingface.co/papers/2605.17109

21. Lost in the Folds: When Cross-Validation Is Not a Deep Ensemble for Uncertainty Estimation
🔑 Keywords: Deep Ensembles, Cross-Validation, Calibration, Failure Detection, nnU-Net
💡 Category: AI in Healthcare
🌟 Research Objective:
– To compare deep ensembles (DE) and cross-validation (CV) ensembles in the context of medical image segmentation, particularly focusing on calibration and failure detection.
🛠️ Research Methods:
– Evaluated a standard 5-fold CV ensemble against a 5-member DE (with a fixed training set and varying seeds) across three multi-rater segmentation datasets spanning different modalities.
💬 Research Conclusions:
– Deep ensembles match segmentation accuracy while enhancing calibration and failure detection; cross-validation ensembles are better proxies for inter-rater variability.
– Ensemble choice should align with the research objective: DE is suited for reliability and failure detection, whereas CV ensembles can serve as a proxy for ambiguity.
👉 Paper link: https://huggingface.co/papers/2605.18329

22.

23. Decoupling the Benefits of Subword Tokenization for Language Model Training via Byte-level Simulation
🔑 Keywords: subword tokenization, large language models, byte-level pretraining, training throughput, linguistic prior
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates how subword tokenization influences training efficiency and performance in large language models via controlled byte-level experiments.
🛠️ Research Methods:
– The effects of subword tokenization were isolated in a byte-level pretraining pipeline, with hypotheses tested on factors like sample throughput, vocabulary scaling, and subword boundaries’ linguistic prior.
💬 Research Conclusions:
– The experiments underscore the importance of training throughput and the role of subword boundaries as explicit priors or inductive biases in improving model performance.
👉 Paper link: https://huggingface.co/papers/2604.27263

24. Capturing LLM Capabilities via Evidence-Calibrated Query Clustering
🔑 Keywords: Query Clustering, LLM Capability Evaluation, Semantic Embeddings, Posterior Model Comparisons, Bradley-Terry Model
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance LLM capability evaluation by clustering queries according to shared latent capabilities and aligning semantic embeddings with these demands.
🛠️ Research Methods:
– The research employs an algorithm named ECC, which adjusts semantic embeddings with the aid of posterior model comparisons and utilizes a Bradley-Terry model to create capability profiles for each cluster.
💬 Research Conclusions:
– ECC significantly improves the quality of LLM capability ranking, surpassing human-labeled and embedding-based baselines by 17.64 and 18.02 percentage points, respectively, and proves useful for tasks such as query routing.
👉 Paper link: https://huggingface.co/papers/2605.17110

25. TIDE: Efficient and Lossless MoE Diffusion LLM Inference with I/O-aware Expert Offload
🔑 Keywords: Diffusion Large Language Models, TIDE, Temporal Stability, Expert Activations, I/O-aware
💡 Category: Generative Models
🌟 Research Objective:
– To address deployment challenges of diffusion large language models on resource-constrained devices using TIDE, optimizing expert placement and leveraging temporal stability.
🛠️ Research Methods:
– Utilization of temporal stability of expert activations and an interval-based expert refresh strategy to minimize I/O overhead and computation.
💬 Research Conclusions:
– TIDE provides a lossless optimization for diffusion LLMs without requiring model retraining, achieving up to 1.4x to 1.5x throughput improvements on benchmark models.
👉 Paper link: https://huggingface.co/papers/2605.20179

26. DrawMotion: Generating 3D Human Motions by Freehand Drawing
🔑 Keywords: DrawMotion, diffusion-based framework, Text-to-motion generation, hand-drawing condition, Multi-Condition Module
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop DrawMotion, a framework that facilitates human motion generation by integrating both text and hand-drawn sketches to reduce user effort and maintain motion fidelity.
🛠️ Research Methods:
– DrawMotion utilizes a diffusion-based framework incorporating a novel hand-drawing condition for detailed motion generation and introduces a Multi-Condition Module to handle multi-condition scenarios efficiently.
💬 Research Conclusions:
– The research demonstrates that the new approach, particularly with freehand drawing, reduces user time by 46.7% while aligning generated motions with user intent and ensuring high fidelity.
👉 Paper link: https://huggingface.co/papers/2605.20955

27. Safety Alignment as Continual Learning: Mitigating the Alignment Tax via Orthogonal Gradient Projection
🔑 Keywords: Large Language Models, alignment tax, continual learning, Orthogonal Gradient Projection, Safety Alignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the safety-utility trade-off in the alignment of Large Language Models (LLMs) by maintaining general capabilities during sequential safety training using Orthogonal Gradient Projection for Safety Alignment (OGPSA).
🛠️ Research Methods:
– Introduction of OGPSA, a lightweight update rule using low-rank gradient projection, to preserve general capabilities while applying safety constraints on LLMs, compatible with standard post-training pipelines like Supervised Fine-Tuning and Direct Preference Optimization.
💬 Research Conclusions:
– OGPSA effectively mitigates capability regression and enhances safety-utility trade-offs, showing significant performance gains in sequential pipeline settings compared to standard baselines, with average performance increases observed in specific model cases.
👉 Paper link: https://huggingface.co/papers/2602.07892

28. PlanningBench: Generating Scalable and Verifiable Planning Data for Evaluating and Training Large Language Models
🔑 Keywords: PlanningBench, large language models, verifiable planning data, constraint-driven synthesis, reinforcement learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce PlanningBench, a framework for generating scalable, diverse, and verifiable planning data that enhances the evaluation and training of large language models’ planning capabilities.
🛠️ Research Methods:
– Utilization of structured taxonomies and constraint-driven synthesis to instantiate self-contained planning problems with adaptive difficulty control, quality filtering, and verification checklists.
💬 Research Conclusions:
– PlanningBench facilitates the transition from fixed benchmark collections to controllable data generation, improving LLMs’ generalizable planning abilities. It also shows that reinforcement learning on data from PlanningBench enhances performance on unseen planning benchmarks and related tasks, highlighting stable training dynamics with well-specified solutions.
👉 Paper link: https://huggingface.co/papers/2605.20873

29. MINTEval: Evaluating Memory under Multi-Target Interference in Long-Horizon Agent Systems
🔑 Keywords: memory-augmented agents, long-horizon settings, interference, aggregated reasoning, MINTEval
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate the performance of current memory-augmented agents in realistic, interference-heavy, long-horizon settings across diverse domains and question types.
🛠️ Research Methods:
– Introduction of MINTEval, a benchmark designed to test memory systems with long, interconnected contexts and frequent information updates, including diverse domains like state tracking, multi-turn dialogue, Wikipedia revisions, and GitHub commits.
– Evaluation includes domain generalization and robustness to interference, assessing single-target recall tasks and multi-target aggregation tasks.
💬 Research Conclusions:
– Across evaluated systems, there is a consistently low performance, particularly in questions requiring aggregated reasoning over multiple pieces of evidence.
– Performance limitations noted in retrieval and memory construction, with systems struggling to recall and reason over revised or interfered facts as the context evolves.
👉 Paper link: https://huggingface.co/papers/2605.18565

30. Mem-π: Adaptive Memory through Learning When and What to Generate
🔑 Keywords: Mem-π, adaptive memory, language model, vision-language model, decision-content decoupled reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Presenting Mem-π, a framework designed for adaptive memory in large language model agents, generating context-specific guidance without relying on external memory retrieval.
🛠️ Research Methods:
– Utilizing a separate language or vision-language model conditioned on the agent’s current context and trained with decision-content decoupled reinforcement learning to manage when and what guidance to generate.
💬 Research Conclusions:
– Mem-π surpasses existing memory retrieval-based and RL-optimized memory approaches, particularly showing significant improvements in web navigation tasks by over 30%.
👉 Paper link: https://huggingface.co/papers/2605.21463

31. Conditional Equivalence of DPO and RLHF: Implicit Assumption, Failure Modes, and Provable Alignment
🔑 Keywords: Direct Preference Optimization, Reinforcement Learning from Human Feedback, Constrained Preference Optimization, provable alignment, soft margin ranking
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to investigate the theoretical equivalence between Direct Preference Optimization (DPO) and Reinforcement Learning from Human Feedback (RLHF) and to introduce a new approach, Constrained Preference Optimization (CPO), to address discrepancies.
🛠️ Research Methods:
– The research involved a theoretical analysis of DPO’s conditional equivalence to RLHF and the introduction of CPO as a method incorporating constraints for achieving provable alignment with human preferences.
💬 Research Conclusions:
– The study concludes that DPO can lead to undesirable solutions under certain conditions, and proposes CPO as an effective alternative that achieves state-of-the-art performance and preserves simplicity.
👉 Paper link: https://huggingface.co/papers/2605.20834

32. PanoWorld: A Generative Spatial World Model for Consistent Whole-House Panorama Synthesis
🔑 Keywords: PanoWorld, VR tours, 3D Gaussian Splatting, geometric proxy, Room-aware Group Attention
💡 Category: Generative Models
🌟 Research Objective:
– To develop a system for generating consistent VR tours using a combination of 3D geometric guidance and dynamic visual memory, ensuring high-quality and spatial coherence across multi-room panoramas.
🛠️ Research Methods:
– Introduced an autoregressive generation model for node-based 360-degree panoramas using a floorplan-derived 3D shell and dynamic 3D Gaussian Splatting as a spatial memory cache.
– Implemented a panoramic LRM for metric-scale multi-room inputs to uplift panoramas into local 3DGS updates while using Room-aware Group Attention to minimize cross-room feature interference.
💬 Research Conclusions:
– PanoWorld successfully combines shell-based geometry guidance with cache-rendered visual memory, maintaining high-frequency 2D synthesis quality and improving cross-node layout and material consistency. The technique efficiently fuses local updates without reconstructing the full history, enabling spatial coherence in VR tours.
👉 Paper link: https://huggingface.co/papers/2605.17916

33. MOCHA: Multi-Objective Chebyshev Annealing for Agent Skill Optimization
🔑 Keywords: Multi-Objective Optimization, Skills, Pareto-optimal, MOCHA, Exponential Annealing
💡 Category: Natural Language Processing
🌟 Research Objective:
– To optimize agent skills by addressing multi-objective constraints using MOCHA, which covers non-convex regions for improved performance and adherence to platform limits.
🛠️ Research Methods:
– Introduced MOCHA utilizing Chebyshev scalarization and exponential annealing across six diverse agent skills with a focus on multi-objective mutation operators.
💬 Research Conclusions:
– MOCHA outperforms existing optimizers by improving mean correctness by 7.5% relative to baselines and discovering more Pareto-optimal skill variants.
👉 Paper link: https://huggingface.co/papers/2605.19330

34. OCTOPUS: Optimized KV Cache for Transformers via Octahedral Parametrization Under optimal Squared error quantization
🔑 Keywords: OCTOPUS, key-value cache, compression, structured random rotations
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to achieve efficient key-value cache compression that reduces memory bandwidth usage while maintaining high-quality reconstruction.
🛠️ Research Methods:
– The study utilizes structured random rotations followed by joint quantization of coordinate triplets, optimized for the marginal of each triplet.
💬 Research Conclusions:
– OCTOPUS surpasses previous codecs such as TurboQuant and PolarQuant in performance across various media (text, video, audio), especially as the bit width decreases for extreme compression. It maintains efficient decode-time operations without adding additional bandwidth or latency.
👉 Paper link: https://huggingface.co/papers/2605.21226

35. OcclusionFormer: Arranging Z-Order for Layout-Grounded Image Generation
🔑 Keywords: OcclusionFormer, AI-generated summary, inter-object occlusion, Diffusion Transformer, Z-order priority
💡 Category: Generative Models
🌟 Research Objective:
– To address the challenges of inter-object occlusion in layout-to-image generation by developing a method that models explicit Z-order priority.
🛠️ Research Methods:
– Utilized a large-scale dataset (SA-Z) enriched with explicit occlusion ordering and pixel-level annotations.
– Introduced OcclusionFormer, an occlusion-aware Diffusion Transformer framework using volume rendering.
– Implemented a queried alignment loss for supervising instances and enhancing semantic consistency.
💬 Research Conclusions:
– The proposed method effectively reduces ambiguity in overlapping regions and enforces correct occlusion dependencies.
– It preserves structural integrity, leading to substantial accuracy gains across diverse scenes.
👉 Paper link: https://huggingface.co/papers/2605.21343

36. Evaluating Temporal Semantic Caching and Workflow Optimization in Agentic Plan-Execute Pipelines
🔑 Keywords: Industrial asset operations, Latency-sensitive, Plan-execute pipeline, MCP workflow optimizations, Temporal semantic cache
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Address latency challenges in industrial asset operations workflows through caching and optimization techniques.
🛠️ Research Methods:
– Evaluation on AssetOpsBench focusing on plan-execute pipeline inefficiencies.
– Implementation of temporal semantic cache and MCP workflow optimizations.
💬 Research Conclusions:
– MCP workflow optimizations led to a 1.67x speedup and 40% reduction in latency.
– Temporal-cache achieved a 30.6x speedup on cache hits.
– Highlighted limitations of semantic caching in parameter-rich queries.
👉 Paper link: https://huggingface.co/papers/2605.20630

37. LLMEval-Logic: A Solver-Verified Chinese Benchmark for Logical Reasoning of LLMs with Adversarial Hardening
🔑 Keywords: Large Language Models, Logical Reasoning, Formal Annotations, Expert Rubrics, Adversarial Workflow
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce and evaluate a Chinese logical reasoning benchmark, LLMEval-Logic, designed to assess the rule-governed reasoning capabilities of large language models.
🛠️ Research Methods:
– The benchmark incorporates expert-verified, natural-language items with formal annotations, and employs a closed-loop adversarial workflow to enhance item difficulty.
💬 Research Conclusions:
– Evaluations on 14 frontier large language models reveal significant room for improvement, with the top model achieving only 37.5% accuracy on hard items and a maximum formalization score of 60.16% even with advanced formal symbols.
👉 Paper link: https://huggingface.co/papers/2605.19597

38. Generative Recursive Reasoning
🔑 Keywords: Generative Recursive reAsoning Models, probabilistic multi-trajectory computation, stochastic latent trajectory, unconditional generation
💡 Category: Generative Models
🌟 Research Objective:
– Explore the implementation of extended computation in neural reasoning systems through Generative Recursive reAsoning Models (GRAM).
🛠️ Research Methods:
– Introduce GRAM to model reasoning as a stochastic latent trajectory, using probabilistic multi-trajectory computation enhanced by amortized variational inference.
💬 Research Conclusions:
– GRAM demonstrates improved performance over deterministic models in structured reasoning and multi-solution constraint satisfaction tasks, and showcases unconditional generation capabilities.
👉 Paper link: https://huggingface.co/papers/2605.19376

39. Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs
🔑 Keywords: Mix-Quant, phase-aware quantization, NVFP4 quantization, LLM agents, BF16 precision
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective of this research is to accelerate long-context, multi-turn LLM inference by applying phase-aware quantization, particularly focusing on optimizing the prefilling stage with high-throughput NVFP4 quantization.
🛠️ Research Methods:
– The researchers investigated the use of FP4 quantization in agentic LLM workflows, highlighting the substantial redundancy during the prefilling stage, which allows for effective quantization with minimal accuracy loss, while preserving BF16 precision for the decoding phase.
💬 Research Conclusions:
– Mix-Quant successfully alleviates the inference bottleneck in LLM agents by decoupling prefilling acceleration from decoding quality, demonstrating that it can achieve up to a 3x speedup in prefilling with minimal performance degradation across long-context and agentic benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.20315

40. It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
🔑 Keywords: Contextual Integrity, large language models, privacy-utility trade-off, self-distillation, reverse KL divergence
💡 Category: Natural Language Processing
🌟 Research Objective:
– To establish a self-distillation framework called SELFCI that enhances the privacy-utility balance in large language models without external supervision.
🛠️ Research Methods:
– SELFCI decouples information suppression from task resolution, employing dual reverse KL divergence over distinct teacher distributions to optimize task-relevant information and privacy.
💬 Research Conclusions:
– SELFCI effectively outperforms competitive baselines, including GRPO, demonstrating its potential as a practical solution for contextual integrity alignment without the need for costly external supervision.
👉 Paper link: https://huggingface.co/papers/2605.20258

41. OScaR: The Occam’s Razor for Extreme KV Cache Quantization in LLMs and Beyond
🔑 Keywords: KV cache compression, Token Norm Imbalance, Canalized Rotation, Omni-Token Scaling, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve memory efficiency and decoding speed for extended context language models by addressing Token Norm Imbalance through a novel compression framework called OScaR.
🛠️ Research Methods:
– The research introduces OScaR, a framework utilizing Canalized Rotation and Omni-Token Scaling to optimize KV cache compression, employing an efficient system design with optimized CUDA kernels.
💬 Research Conclusions:
– OScaR significantly outperforms existing methods in terms of decoding speed and memory footprint, offering a robust, low-complexity framework with near-lossless performance under INT2 quantization. It achieves up to 3.0x speedup in decoding, reduces memory footprint by 5.3x, and increases throughput by 4.1x compared to BF16 FlashDecoding-v2 baseline.
👉 Paper link: https://huggingface.co/papers/2605.19660

42. IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
🔑 Keywords: IndusAgent, open-vocabulary industrial anomaly detection, tool-augmented agentic framework, structured visual reasoning, gated reinforcement learning objective
💡 Category: Computer Vision
🌟 Research Objective:
– Develop IndusAgent, a tool-augmented framework to improve open-vocabulary industrial anomaly detection through structured visual reasoning.
🛠️ Research Methods:
– Construction of a structured dataset called Indus-CoT and dynamic orchestration of external tools for enhanced anomaly detection.
– Introduction of a gated reinforcement learning objective to optimize anomaly classification, localization accuracy, and anomaly type reasoning.
💬 Research Conclusions:
– IndusAgent demonstrates state-of-the-art zero-shot performance on five industrial anomaly benchmarks, showcasing its robustness and generalization capabilities.
👉 Paper link: https://huggingface.co/papers/2605.20682

43. Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
🔑 Keywords: GUI agents, large-scale dataset, Video2GUI, pre-training, structured agent trajectories
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To create a large-scale dataset by extracting interaction trajectories from internet videos to enhance the performance of GUI agents.
🛠️ Research Methods:
– Developed Video2GUI, an automated framework using coarse-to-fine filtering to convert unlabeled internet videos into structured agent trajectories.
💬 Research Conclusions:
– Pre-training on the WildGUI dataset improves GUI grounding and action benchmarks by 5-20%, achieving or surpassing state-of-the-art performance. WildGUI dataset and Video2GUI pipeline will be released for further research.
👉 Paper link: https://huggingface.co/papers/2605.14747
