AI Native Daily Paper Digest – 20260522

1. TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
🔑 Keywords: TransitLM, Large Language Models, Transit Route Planning, GPS Coordinates, Data-Driven
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main objective is to enable end-to-end transit route planning using large language models trained on structured transit data, bypassing traditional map-based approaches.
🛠️ Research Methods:
– Development and utilization of the TransitLM dataset, comprising over 13 million transit route planning records from four Chinese cities, with continual pre-training and benchmark data for evaluation tasks.
💬 Research Conclusions:
– Experiments indicate that models trained on TransitLM can generate structurally valid routes with high accuracy, implicitly grounding arbitrary GPS coordinates to stations without explicit mapping, thus demonstrating the feasibility of map-free route generation from origin-destination information.
👉 Paper link: https://huggingface.co/papers/2605.22355

2. DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Discriminative Token Credit Assignment, Token-Gradient Vectors, AI-Generated Summary
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To improve reinforcement learning from verifiable rewards by introducing a discriminative token credit assignment method.
🛠️ Research Methods:
– Developed a perspective of RLVR updates as a linear discriminator over token-gradient vectors to determine token probability adjustments during learning.
– Proposed DelTA method to enhance token-gradient direction distinction by adjusting token coefficients for more effective side-wise centroids.
💬 Research Conclusions:
– DelTA significantly outperforms the previous baselines on mathematical benchmarks and demonstrates strong generalization abilities in various domains, including code generation and out-of-domain evaluations.
👉 Paper link: https://huggingface.co/papers/2605.21467

3. Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
🔑 Keywords: RTPurbo, Long-context inference, Full-attention LLMs, Intrinsic sparsity, Sparse attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to leverage intrinsic sparsity in full-attention LLMs to enhance the efficiency of long-context inference with minimal training overhead, achieving significant speedups while maintaining near-lossless accuracy.
🛠️ Research Methods:
– The approach is based on three key observations: a small subset of attention heads requires full long-context processing, long-range retrieval is managed by a low-dimensional subspace allowing efficient token retrieval, and dynamic top-p selection is more optimal than fixed top-k sparsification. RTPurbo retains the full KV cache for retrieval heads and uses a lightweight token indexer for sparse attention.
💬 Research Conclusions:
– RTPurbo demonstrates that strong sparse inference can be achieved without expensive native sparse pretraining. It shows substantial efficiency gains, including up to a 9.36x speedup in prefill and a 2.01x speedup in decode, while preserving near-lossless accuracy in long-context benchmarks and reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2605.16928

4. PhysX-Omni: Unified Simulation-Ready Physical 3D Generation for Rigid, Deformable, and Articulated Objects
🔑 Keywords: 3D generation, geometry representation, simulation-ready, PhysX-Omni, Vision-Language Models
💡 Category: Generative Models
🌟 Research Objective:
– PhysX-Omni is introduced as a unified framework to generate simulation-ready physical 3D assets across diverse asset categories, addressing limitations in existing methods.
🛠️ Research Methods:
– Development of a novel geometry representation tailored for Vision-Language Models, which enhances generation performance without compression.
– Construction of PhysXVerse, a comprehensive 3D dataset, and PhysX-Bench, an evaluation benchmark covering multiple attributes.
💬 Research Conclusions:
– PhysX-Omni demonstrates strong performance in both generation and understanding capabilities, with significant potential for applications in simulation-ready scene generation and robotic policy learning.
– The framework aids in advancing embodied AI and physics-based simulation applications.
👉 Paper link: https://huggingface.co/papers/2605.21572
5. Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Spreadsheet Automation, Domain-Specific Benchmarks, Spreadsheet Gym, LLM-Based Interactions
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the performance of AI spreadsheet agents in realistic Excel environments through the development of the Spreadsheet-RL framework, allowing for improved handling of both general and domain-specific tasks.
🛠️ Research Methods:
– Implementation of a reinforcement learning fine-tuning framework with an automated pipeline for scalable data collection from online forums and the introduction of a Domain-Spreadsheet benchmark dataset.
– Developing a Spreadsheet Gym environment to expose Excel functionalities for multi-turn RL training within a Python sandbox.
💬 Research Conclusions:
– Spreadsheet-RL significantly boosts AI agent effectiveness, nearly doubling the Pass@1 rates on spreadsheet task benchmarks, highlighting a strong potential for generalization and real-world applications in spreadsheet automation.
👉 Paper link: https://huggingface.co/papers/2605.22642

6. Forecasting Scientific Progress with Artificial Intelligence
🔑 Keywords: AI Systems, Scientific Forecasting, CUSP Benchmark, Uncertainty Estimation, Domain-dependent Limitations
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate AI’s capability to predict scientific progress using a new framework, CUSP, in the context of domain-based systematic overconfidence and inconsistent performance.
🛠️ Research Methods:
– Introduction of a temporally grounded evaluation framework, including CUSP, which analyzes feasibility assessment, mechanistic reasoning, generative solution design, and temporal prediction across multi-disciplinary scientific events.
💬 Research Conclusions:
– Current AI models exhibit systemic limitations across domains, failing to reliably predict scientific advances and exhibiting overconfidence with strong response biases, highlighting the unreliability of AI systems as predictive tools for scientific progress.
👉 Paper link: https://huggingface.co/papers/2605.22681

7. Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
🔑 Keywords: Sensor2Sensor, Autonomous Driving Systems, diffusion models, 4D Gaussian Splatting, multi-modal sensor suite
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to create a high-fidelity, multi-modal sensor suite from in-the-wild dashcam videos to aid in the training and validation of Autonomous Driving Systems.
🛠️ Research Methods:
– The proposed Sensor2Sensor uses 4D Gaussian Splatting for rendering and a diffusion architecture for generative conversion, addressing the lack of paired training data by converting real AV logs into dashcam-style videos.
💬 Research Conclusions:
– Sensor2Sensor successfully transforms challenging internet and dashcam footage into realistic multi-modal data formats, expanding the available data sources for autonomous vehicle development.
👉 Paper link: https://huggingface.co/papers/2605.22809

8. SpaceDG: Benchmarking Spatial Intelligence under Visual Degradation
🔑 Keywords: SpaceDG, spatial reasoning, visual degradation, MLLMs, robust spatial intelligence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces the SpaceDG dataset and benchmark to evaluate and enhance the robustness of multimodal language models (MLLMs) in spatial reasoning under conditions of visual degradation.
🛠️ Research Methods:
– Construction of the SpaceDG dataset using a degradation synthesis engine for realistic simulation of nine types of visual degradation in approximately 1 million QA pairs from indoor scenes.
– Development of the SpaceDG-Bench with human-verified questions to evaluate the impact of visual degradations on spatial reasoning across multiple reasoning categories.
💬 Research Conclusions:
– Findings reveal that existing MLLMs show significant performance gaps under visual degradations, exposing critical robustness issues.
– Fine-tuning on the SpaceDG dataset improves model robustness to visual degradations, sometimes even surpassing human performance without performance drops on unaltered images.
👉 Paper link: https://huggingface.co/papers/2605.22536
9. Q-ARVD: Quantizing Autoregressive Video Diffusion Models
🔑 Keywords: Autoregressive Video Diffusion Models, Quantization, Frame-wise Sensitivity, Weight Outlier, Adaptive Dual-Scale Quantization
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to address the high inference costs in Autoregressive Video Diffusion Models (ARVDs) by developing Q-ARVD, a novel quantization framework that deals with frame-wise sensitivity imbalance and weight outlier patterns.
🛠️ Research Methods:
– The study investigates empirical challenges in quantizing ARVDs by analyzing existing quantization schemes’ behavior and designing Q-ARVD, which includes a final-quality aware frame-weighting mechanism and an outlier-aware adaptive dual-scale quantization.
💬 Research Conclusions:
– Q-ARVD demonstrates superior performance in accurately quantizing ARVDs by addressing frame-wise sensitivity and outlier patterns, ensuring improved efficiency for practical deployment in video generation applications.
👉 Paper link: https://huggingface.co/papers/2605.21072
10. Unsupervised Process Reward Models
🔑 Keywords: Unsupervised Reward Models, Language Model, Reinforcement Learning, Policy Optimization, Next-token Probabilities
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop an unsupervised reward model (uPRM) that eliminates the need for human annotations in training, improving scalability in complex reasoning tasks.
🛠️ Research Methods:
– Utilization of next-token probabilities from language models to define a scoring function that identifies erroneous reasoning steps without manual supervision.
💬 Research Conclusions:
– uPRM enhances accuracy in identifying erroneous steps by up to 15% compared to LLM-as-a-Judge.
– uPRM is as effective as supervised PRMs and outperforms majority voting by up to 6.9% in test-time scaling scenarios.
– In reinforcement learning, uPRM provides more robust policy optimization than supervised models using ground-truth labels.
👉 Paper link: https://huggingface.co/papers/2605.10158

11. KVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving
🔑 Keywords: KVServe, Disaggregated LLM Serving, KV Compression, Bayesian Profiling Engine, Service-Aware Online Controller
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces KVServe, a service-aware and adaptive framework for optimizing key-value communication compression in disaggregated large language model serving.
🛠️ Research Methods:
– KVServe utilizes a modular strategy that unifies KV compression and introduces a Bayesian Profiling Engine, reducing extensive offline search overhead.
– It implements a Service-Aware Online Controller that combines an analytical latency model with a bandit approach for efficient profile selection under constraints.
💬 Research Conclusions:
– KVServe significantly improves job completion time (JCT) and time-to-first-token (TTFT) in disaggregated LLM serving, achieving up to 9.13 times JCT speedup and 32.8 times TTFT reduction.
👉 Paper link: https://huggingface.co/papers/2605.13734

12. Swift Sampling: Selecting Temporal Surprises via Taylor Series
🔑 Keywords: Swift Sampling, training-free, visual latent space, frame selection, temporal surprises
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Swift Sampling, a training-free algorithm designed to identify high-information moments in videos by detecting deviations from predicted visual feature trajectories in a visual latent space.
🛠️ Research Methods:
– Utilized predictive coding inspired by the human brain to model video as a differentiable trajectory in visual latent space, calculating the velocity and acceleration of features.
– Applied Taylor expansion to project paths of subsequent frames to identify and select temporally surprising frames.
💬 Research Conclusions:
– Swift Sampling is computationally efficient, costing only 0.02x additional computation over baseline and outperforms uniform sampling and other baselines in accuracy on long videos with limited frame budgets, improving up to +12.5 points.
👉 Paper link: https://huggingface.co/papers/2605.22678

13. One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
🔑 Keywords: Multi-Agent Framework, Narrative Pacing, Spatial Consistency, Production-Level Quality Control, 3D-Grounded First-Frame Generation
💡 Category: Generative Models
🌟 Research Objective:
– To introduce a hierarchical multi-agent framework that efficiently generates short dramas from a single sentence by ensuring narrative pacing, spatial consistency, and quality control.
🛠️ Research Methods:
– Implementing a multi-agent debate-based story generation module for narrative coherence.
– A 3D-grounded first-frame generation mechanism to maintain spatial reference.
– Multi-stage reviewer loops for error detection and targeted revision across production stages.
💬 Research Conclusions:
– The proposed framework, “One Sentence, One Drama,” successfully improves narrative quality, cross-clip consistency, and the overall viewing experience, outperforming existing production pipelines.
👉 Paper link: https://huggingface.co/papers/2605.22144

14. Segment Anything with Motion, Geometry, and Semantic Adaptation for Complex Nonlinear Visual Object Tracking
🔑 Keywords: Visual Object Tracking, SAM 2, Motion Predictor, Semantic Cues, Geometric Constraints
💡 Category: Computer Vision
🌟 Research Objective:
– This research aims to enhance the robustness and generalization of visual object tracking (VOT) in complex scenarios by adapting SAM 2 with motion prediction, semantic detection, and geometric constraints.
🛠️ Research Methods:
– The study introduces a new tracking framework, SAMOSA, which incorporates a lightweight nonlinear motion predictor to model target dynamics, utilizes semantic cues for target shift detection and recovery from tracking failures, and applies geometric cues for structural constraints and improved tracking stability.
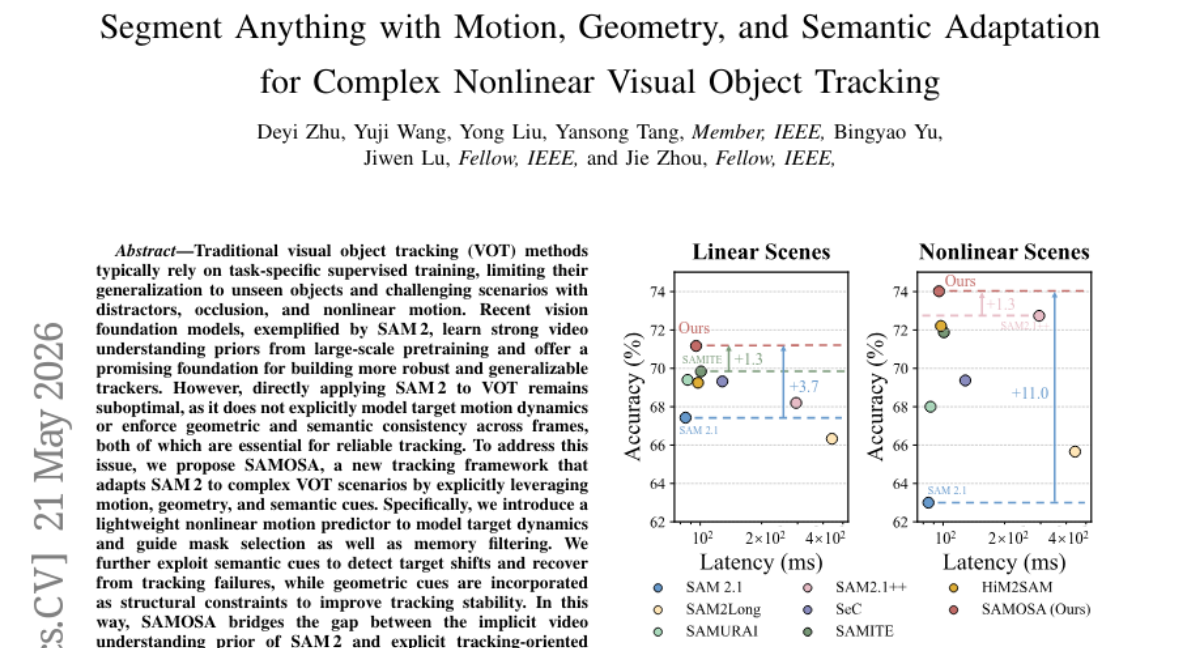
💬 Research Conclusions:
– SAMOSA demonstrates notable performance improvements over state-of-the-art SAM 2 based approaches and showcases superior generalization compared to supervised VOT methods, especially in scenarios characterized by complex nonlinear motion.
👉 Paper link: https://huggingface.co/papers/2605.22538
15. Diversed Model Discovery via Structured Table Discovery
🔑 Keywords: Model Search, Semantic Similarity, Structured Tables, Table Discovery Operators, Evidence Coverage
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance diversity and coverage in model recommendation systems by integrating semantic with structured table-based retrieval.
🛠️ Research Methods:
– Developed StructuredSemanticSearch, combining semantic task alignment with structure-aware table discovery operators like unionability and joinability.
– Implemented a nugget-based, auditable protocol for evaluating the effectiveness of the model search system.
💬 Research Conclusions:
– The structured, table-driven approach showed improved coverage of evidence and diversity over semantic baselines in model-recommendation queries.
👉 Paper link: https://huggingface.co/papers/2605.22766

16. TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
🔑 Keywords: TerminalWorld, Reverse-Engineering, Benchmarking, Real-World Categories, Terminal Recordings
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The research introduces TerminalWorld, a scalable data engine that automatically reverse-engineers high-fidelity evaluation tasks from terminal recordings.
🛠️ Research Methods:
– By processing 80,870 terminal recordings, TerminalWorld produces a benchmark of 1,530 tasks validated across 18 real-world categories and covering 1,280 unique commands.
💬 Research Conclusions:
– The benchmarking reveals that current systems struggle with real-world terminal workflows, achieving a maximum pass rate of 62.5%, and TerminalWorld offers distinct real-world capabilities with low correlation to existing benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.22535

17. Training Large Language Models to Predict Clinical Events
🔑 Keywords: Longitudinal clinical notes, Foresight Learning, LoRA adaptation, clinical prediction
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to enhance clinical prediction by leveraging longitudinal clinical notes and adapting the Foresight Learning method for more accurate and reliable predictions.
🛠️ Research Methods:
– The research converts MIMIC-III notes into prediction examples, consisting of patient context, natural-language questions, and resolved labels. A LoRA adapter is then trained to improve prediction accuracy and reduce uncertainty.
💬 Research Conclusions:
– The approach achieves improvements by reducing calibration error and Brier score compared to base models, showing enhanced performance in clinical prediction tasks without the need for structured feature engineering.
👉 Paper link: https://huggingface.co/papers/2605.12817

18. More Context, Larger Models, or Moral Knowledge? A Systematic Study of Schwartz Value Detection in Political Texts
🔑 Keywords: Moral Knowledge, Value Detection, Zero-shot LLMs, Supervised Models, Early Fusion
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the effects of context and moral knowledge on sentence-level value detection in political texts.
🛠️ Research Methods:
– Compared different input levels including sentence, window, and full-document.
– Employed supervised DeBERTa-v3 encoders and zero-shot LLMs, utilizing a moral knowledge base in both no-RAG and retrieval-augmented settings.
💬 Research Conclusions:
– Full-document context enhances the performance of supervised DeBERTa encoders but does not benefit zero-shot LLMs uniformly.
– Retrieved moral knowledge consistently improves performance across models and contexts, especially with early fusion.
– Larger models or longer inputs do not guarantee better performance.
👉 Paper link: https://huggingface.co/papers/2605.22641

19. Rule2DRC: Benchmarking LLM Agents for DRC Script Synthesis with Execution-Guided Test Generation
🔑 Keywords: Rule2DRC, DRC script synthesis, AI Native, execution feedback, SplitTester
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary goal is to introduce Rule2DRC, a comprehensive benchmark designed to improve rule-to-script synthesis for DRC by assessing functional correctness through execution outcomes.
🛠️ Research Methods:
– The study employs Rule2DRC with 1,000 rule-to-script tasks and an extensive set of 13,921 evaluation layouts.
– It also uses SplitTester, which utilizes execution feedback for program selection to enhance Best-of-N selection performance.
💬 Research Conclusions:
– Rule2DRC provides a robust evaluation framework focused on functional correctness without needing evaluation layouts as input, offering significant improvements in script synthesis and selection.
👉 Paper link: https://huggingface.co/papers/2605.15669

20. Platonic Representations in the Human Brain: Unsupervised Recovery of Universal Geometry
🔑 Keywords: self-supervised encoder, fMRI data, cross-subject retrieval, neural geometry, AI-generated summary
💡 Category: Foundations of AI
🌟 Research Objective:
– Investigate whether a shared neural geometry can be recovered across human brains, similar to the representational convergence observed in artificial neural networks.
🛠️ Research Methods:
– Utilized fMRI data from the Natural Scenes Dataset to propose a self-supervised encoder that learns subject-specific embeddings from brain data using repeated stimulus presentations.
– Applied unsupervised orthogonal rotations to translate independently learned embedding spaces across subjects without paired data.
💬 Research Conclusions:
– Demonstrated that subject-specific fMRI representations in the human visual cortex are approximately isometric across individuals, indicating shared neural geometry which can be translated through geometric transformations.
👉 Paper link: https://huggingface.co/papers/2605.20496

21. “I didn’t Make the Micro Decisions”: Measuring, Inducing, and Exposing Goal-Level AI Contributions in Collaboration
🔑 Keywords: CoTrace, large language models, human-AI collaboration, goal-level attribution, indirect contributions
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The primary aim is to introduce and evaluate CoTrace, a framework designed to analyze the role of large language models in shaping goals during human-AI collaboration.
🛠️ Research Methods:
– CoTrace framework decomposes explicit goals into verifiable requirements and traces contributions across dialogue turns, using controlled simulations and real-world collaboration logs.
💬 Research Conclusions:
– The study finds that large language models make 11-26% direct contributions to goal shaping but have a considerable impact by introducing concrete requirements and indirect contributions. Interaction design significantly influences goal-shaping behavior, and exposure to goal-level analyses in user studies revealed that users often miscalibrate the contributions of AI-assisted work.
👉 Paper link: https://huggingface.co/papers/2605.21363

22. Lean Refactor: Multi-Objective Controllable Proof Optimization via Agentic Strategy Search
🔑 Keywords: Lean Refactor, retrieval-augmented agentic framework, multi-objective optimization, version compatibility, token-level compression
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces Lean Refactor, a framework aimed at improving Lean proof refactoring by efficiently managing multi-objective optimization, version compatibility, and scalability challenges.
🛠️ Research Methods:
– Utilizes a retrieval-augmented agentic framework with a curated database of multi-objective refactoring strategies to assist a frozen agentic LLM, annotated with metadata for Lean/Mathlib versions and compilation-cost reduction.
💬 Research Conclusions:
– Lean Refactor achieves significant improvements, including over 70% token-level compression and up to 60% reduction in compilation time, demonstrating stronger zero-shot version transfer capabilities for Lean proofs compared to previous methods.
👉 Paper link: https://huggingface.co/papers/2605.20244

23. Live Music Diffusion Models: Efficient Fine-Tuning and Post-Training of Interactive Diffusion Music Generators
🔑 Keywords: Audio diffusion models, Live Music Diffusion Models, consumer hardware, ARC-Forcing paradigm, generative instrument
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to adapt audio diffusion models for interactive music generation, making them efficient for real-time performance on consumer hardware.
🛠️ Research Methods:
– The research employs novel training paradigms and block-wise KV Caching to improve computational efficiency.
– Introduction of ARC-Forcing paradigm to stabilize post-training alignment without reinforcement learning.
💬 Research Conclusions:
– Live Music Diffusion Models outperform traditional models in inference complexity.
– LMDMs effectively support creative applications like text-conditioned generation and live music jamming.
– These models transform real-time musician improvisation, functioning as a generative instrument on consumer laptops.
👉 Paper link: https://huggingface.co/papers/2605.22717
24. Minimalist Visual Inertial Odometry
🔑 Keywords: Visual-Inertial Odometry, differential-drive robots, photodiodes, optical Gabor masks, Temporal Convolutional Network
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a minimalist visual-inertial odometry approach for accurate planar motion estimation using a minimal number of sensors.
🛠️ Research Methods:
– Utilized four photodiodes with optical Gabor masks and a Temporal Convolutional Network (TCN) within a physically-grounded simulator to optimize mask parameters and decode speed measurements.
💬 Research Conclusions:
– The minimalist sensing setup effectively estimates planar odometry by decoding speed from limited measurements without requiring extensive processing resources, demonstrating efficiency and accuracy across various terrains without real-world fine-tuning.
👉 Paper link: https://huggingface.co/papers/2605.19990
25.

26. SAM 3D Animal: Promptable Animal 3D Reconstruction from Images in the Wild
🔑 Keywords: promptable framework, multi-animal 3D reconstruction, SMAL+, keypoints, masks
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to develop a new promptable framework, SAM 3D Animal, for reconstructing multiple animals in 3D from a single image, directly addressing challenges in varied species scenes with occlusion.
🛠️ Research Methods:
– Utilizes the SMAL+ parametric animal model to enable joint reconstruction of multiple animal instances, integrating keypoints and mask prompts for improved scene disambiguation.
– Introduces Herd3D, a diverse multi-animal 3D dataset with over 5K images to enhance model training across species, interactions, and occlusion patterns.
💬 Research Conclusions:
– The framework achieves state-of-the-art results in animal 3D reconstruction, demonstrating a scalable and effective solution compared to existing methods in both model-based and model-free scenarios.
👉 Paper link: https://huggingface.co/papers/2605.07604

27. FashionLens: Toward Versatile Fashion Image Retrieval via Task-Adaptive Learning
🔑 Keywords: unified framework, fashion image retrieval, Multimodal Large Language Models, Proposal-Guided Spherical Query Calibrator, Gradient-Guided Adaptive Sampling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop a unified framework capable of handling diverse realistic fashion retrieval scenarios for versatile fashion image retrieval.
🛠️ Research Methods:
– Introduce U-FIRE, a comprehensive benchmark consolidating fragmented fashion datasets, and propose FashionLens based on Multimodal Large Language Models.
– Design a Proposal-Guided Spherical Query Calibrator to dynamically align query representations using adaptive spherical linear interpolation.
– Develop a Gradient-Guided Adaptive Sampling strategy for re-weighting tasks considering learning difficulty and data scale.
💬 Research Conclusions:
– FashionLens achieves state-of-the-art performance across various retrieval scenarios and generalizes robustly to unseen tasks. The framework, data, and code are publicly available online.
👉 Paper link: https://huggingface.co/papers/2605.22552

28. OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understanding
🔑 Keywords: OmniPro, omni-modal large language models, proactive streaming video understanding, dual-mode evaluation, multimodal analysis
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce OmniPro, the first benchmark for evaluating omni-modal large language models’ proactive streaming video understanding.
🛠️ Research Methods:
– Dual-mode evaluation protocol including Probe mode and Online mode for comprehensive assessment.
💬 Research Conclusions:
– Audio provides gains, but its utilization varies across models.
– Long-horizon robustness is limited as performance degrades over time.
– Non-speech audio perception is identified as the weakest dimension.
👉 Paper link: https://huggingface.co/papers/2605.18577

29. Disentangling Sampling from Training Budget in Class-Imbalanced CT Body Composition Segmentation
🔑 Keywords: episodic sampling, few-shot learning, medical image segmentation, class imbalance, implicit regularization
💡 Category: AI in Healthcare
🌟 Research Objective:
– To enhance class-balanced batch construction in medical image segmentation by utilizing episodic sampling from few-shot learning, particularly under low-data conditions.
🛠️ Research Methods:
– The study decouples episodic sampling from its original context and evaluates its effectiveness in body composition segmentation using CT images. It compares episodic, random, and weighted sampling methods on muscle and adipose tissues from 210 scans in the SAROS dataset.
💬 Research Conclusions:
– Episodic sampling significantly outperforms random and weighted sampling under low-data training, showing a residual advantage consistent with implicit regularization effects of class-balanced batches. It presents a low-cost and model-agnostic strategy for addressing class imbalance issues in medical image segmentation.
👉 Paper link: https://huggingface.co/papers/2605.20405

30. Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws
🔑 Keywords: Optimizer, Representation Scaling, Transformer Models, Muon, AdamW
💡 Category: Natural Language Processing
🌟 Research Objective:
– Examine how different optimizers, such as Muon and AdamW, influence spectral scaling behaviors in Transformer models, focusing on representation capacity utilization.
🛠️ Research Methods:
– Analysis of eigenspectra in feed-forward network representations and comparison of spectral scaling laws under different optimizers, keeping architecture constant.
💬 Research Conclusions:
– The optimizer significantly affects representation scaling, with Muon showing superior linear scaling compared to AdamW, especially in challenging learning scenarios. The study highlights the need for co-designing optimizers and architectures to optimize representation scaling.
👉 Paper link: https://huggingface.co/papers/2605.21803

31. DecQ: Detail-Condensing Queries for Enhanced Reconstruction and Generation in Representation Autoencoders
🔑 Keywords: Representation Autoencoders, frozen vision foundation models, detail-condensing queries, reconstruction quality, generative performance
💡 Category: Generative Models
🌟 Research Objective:
– Introduce DecQ to enhance Representation Autoencoders by addressing the trade-off between reconstruction quality and generative performance without disrupting pretrained semantic spaces.
🛠️ Research Methods:
– Implement lightweight detail-condensing queries within the decoder to extract fine-grained information from intermediate features, and evaluate performance in terms of PSNR and convergence speed.
💬 Research Conclusions:
– DecQ improves reconstruction quality of Representation Autoencoders, increasing PSNR from 19.13 dB to 22.76 dB with minimal added computational cost, and achieves 3.3 times faster convergence in generative modeling, with FID scores of 1.41 without guidance and 1.05 with guidance.
👉 Paper link: https://huggingface.co/papers/2605.22777

32. AnyMo: Geometry-Aware Setup-Agnostic Modeling of Human Motion in the Wild
🔑 Keywords: Geometry-aware framework, Physics-grounded IMU simulation, Graph encoder, Zero-shot activity recognition, Cross-modal retrieval
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce AnyMo, a geometry-aware framework for setup-agnostic human motion modeling, enabling improved cross-dataset activity recognition and cross-modal retrieval.
🛠️ Research Methods:
– Utilize physics-grounded IMU simulation over dense body-surface placements to create synthetic signals.
– Pre-train a graph encoder from paired synthetic placement views and masked partial observations.
– Tokenize multi-position IMU into full-body motion tokens, aligning them with an LLM for motion-language understanding.
💬 Research Conclusions:
– AnyMo enhances wearable motion understanding, achieving significant improvements in zero-shot activity recognition, cross-modal retrieval, and wearable IMU motion captioning, demonstrating its potential as a generalist model for motion understanding in diverse real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2605.22715

33. From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
🔑 Keywords: SCRL, Reinforcement Learning, Curriculum Learning, Credit Assignment, Mathematical Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Address inefficiencies in reinforcement learning for verifiable rewards through the introduction of Subproblem Curriculum Reinforcement Learning (SCRL).
🛠️ Research Methods:
– Uses subproblem-level normalization to assign rewards and enable finer-grained credit assignment without external rubrics.
– Implements a curriculum learning framework to improve mathematical reasoning across challenging benchmarks.
💬 Research Conclusions:
– SCRL shows significant improvement over existing curriculum-learning baselines, enhancing the average accuracy significantly on multiple reasoning benchmarks.
– Demonstrates better exploration and performance on difficult reasoning tasks, lifting hard problems out of gradient dead zones.
👉 Paper link: https://huggingface.co/papers/2605.22074

34. AutoRubric-T2I: Robust Rule-Based Reward Model for Text-to-Image Alignment
🔑 Keywords: AutoRubric-T2I, Vision-Language Model, Text-to-Image, Rubric Learning, Reward Models
💡 Category: Generative Models
🌟 Research Objective:
– The primary objective is to develop AutoRubric-T2I, a framework that automatically generates and selects explicit rubrics to guide Vision-Language Model judges for text-to-image generation, thereby providing high-quality reward signals with minimal human annotation.
🛠️ Research Methods:
– The method involves synthesizing reasoning traces from preference pairs into candidate rubrics, scoring these using a Vision-Language Model, and employing an ell_1-Regularized Logistic Regression Refiner to select the most discriminative rubrics.
💬 Research Conclusions:
– AutoRubric-T2I significantly reduces the need for large-scale reward-model training, producing high-quality reward signals with minimal data. It outperforms existing models on image reward benchmarks like MMRB2 and enhances generation quality in downstream T2I tasks.
👉 Paper link: https://huggingface.co/papers/2605.17602

35. SceneAligner: 3D-Grounded Floorplan Localization in the Wild
🔑 Keywords: Floorplan Localization, 3D Scene Reconstruction, Cross-Modal Correspondences, 2D Foundation Model, Structural Consistency
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a deep learning approach for floorplan localization that can operate effectively in real-world environments using limited data, by leveraging 3D scene reconstruction and cross-modal correspondence learning.
🛠️ Research Methods:
– Utilize an unconstrained image collection to reconstruct a gravity-aligned 3D scene, which is projected onto a 2D density map serving as a floorplan proxy.
– Align the density map with the input floorplan via a 2D similarity transform.
– Adapt a 2D foundation model to learn cross-modal correspondences with a fine-tuning scheme to ensure semantically aligned matches and structural consistency.
💬 Research Conclusions:
– The proposed method significantly improves floorplan localization over existing methods, even in sparse settings, demonstrating its effectiveness with minimal inputs.
– The methods and data utilized in this study will be made publicly available.
👉 Paper link: https://huggingface.co/papers/2605.22581

36. Bernini: Latent Semantic Planning for Video Diffusion
🔑 Keywords: Multimodal Large Language Models, Diffusion Models, Video Generation, Semantic Planning, ViT Embedding Space
💡 Category: Generative Models
🌟 Research Objective:
– To unify multimodal large language models and diffusion models for state-of-the-art video generation and editing by separating semantic planning from pixel rendering.
🛠️ Research Methods:
– Utilization of an MLLM-based planner for semantic representation in ViT embedding space, combined with a DiT-based renderer for pixel synthesis. Introduction of Segment-Aware 3D Rotary Positional Embedding and incorporation of chain-of-thought reasoning.
💬 Research Conclusions:
– The proposed Bernini framework achieves state-of-the-art performance in video generation and editing. It effectively generalizes to challenging editing tasks while maintaining efficient training and leveraging pretrained model strengths.
👉 Paper link: https://huggingface.co/papers/2605.22344

37. Efficient Agentic Reasoning Through Self-Regulated Simulative Planning
🔑 Keywords: agentic reasoning, simulative reasoning, self-regulation, reactive execution, reinforcement learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance efficient agentic reasoning by decomposing decision-making into simulative reasoning, self-regulation, and reactive execution, enabling controlled planning for better performance while reducing token usage.
🛠️ Research Methods:
– Developed SR²AM, an agentic LLM with simulative reasoning and self-regulation as distinct stages, employing a world model. Explored two versions: one recording decisions from a multi-module system and another reconstructing plans from pretrained reasoning LLMs, trained via supervised and reinforcement learning.
💬 Research Conclusions:
– Across varied tasks including math and web information seeking, SR²AM demonstrates competitive performance with significantly fewer tokens compared to larger models. Reinforcement learning increases planning horizon and demonstrates self-regulation’s broader applicability beyond planning.
👉 Paper link: https://huggingface.co/papers/2605.22138

38. ClinSeekAgent: Automating Multimodal Evidence Seeking for Agentic Clinical Reasoning
🔑 Keywords: ClinSeekAgent, Large Language Models, Multimodal Evidence, Clinical Decision Support, AI in Healthcare
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study introduces ClinSeekAgent, an automated agentic framework designed to dynamically acquire and synthesize multimodal clinical evidence from raw data to enhance decision-making in clinical tasks.
🛠️ Research Methods:
– ClinSeekAgent actively gathers evidence by querying medical knowledge bases, navigating raw EHRs, and using medical imaging tools. It refines hypotheses and integrates evidence into clinical decisions. It also functions as both an inference-time agent and a training-time pipeline.
💬 Research Conclusions:
– ClinSeekAgent demonstrates improved performance in both text-only and multimodal clinical tasks, with significant F1 score improvements over existing models. Its effectiveness is further validated through the development of ClinSeek-Bench and the distillation of agent trajectories into compact models.
👉 Paper link: https://huggingface.co/papers/2605.20176

39. Forecasting Downstream Performance of LLMs With Proxy Metrics
🔑 Keywords: Proxy metrics, token-level statistics, expert-written solutions, model performance forecasting, cross-entropy loss
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary goal is to develop more reliable model performance forecasting methods using proxy metrics derived from token-level statistics in expert-written solutions, surpassing traditional loss-based methods during various development stages.
🛠️ Research Methods:
– The study involves constructing proxy metrics by aggregating token-level statistics such as entropy, top-k accuracy, and expert token rank from candidate models’ next token distributions.
💬 Research Conclusions:
– Proxy metrics outperform traditional methods in multiple settings: cross-family model selection, pretraining data selection with significantly reduced computational requirements, and training-time forecasting with notably lower error rates, suggesting expert trajectories provide a valuable signal for assessing model capabilities across development stages.
👉 Paper link: https://huggingface.co/papers/2605.18607
40. GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
🔑 Keywords: self-evolving framework, Tool-Orchestrated Visual Experience Distillation, reference selection, prompt construction, state-of-the-art performance
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to develop a general image-generation agent, capable of self-evolving through trajectories, to handle varied and demanding generation challenges effectively.
🛠️ Research Methods:
– The proposed GenEvolve framework models each generation attempt as a tool-orchestrated trajectory. It uses Visual Experience Distillation to provide dense token-level supervision, enhancing search and reference abilities.
💬 Research Conclusions:
– Experiments demonstrate substantial gains over strong baselines, achieving state-of-the-art performance among current frameworks, underscoring the effectiveness of GenEvolve in image generation tasks.
👉 Paper link: https://huggingface.co/papers/2605.21605

41. Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention
🔑 Keywords: Gated DeltaNet-2, linear attention, channel-wise gates, long-context language modeling, retrieval tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to improve upon existing linear attention models by introducing Gated DeltaNet-2, which separates erase and write operations through distinct channel-wise gates to enhance performance in long-context language modeling and retrieval tasks.
🛠️ Research Methods:
– Gated DeltaNet-2 builds on Delta-rule models and Kimi Delta Attention by utilizing a channel-wise erase gate and a channel-wise write gate, alongside fast-weight updates and a chunkwise WY algorithm, allowing efficient parallel training.
💬 Research Conclusions:
– Among various attention model variants, Gated DeltaNet-2 demonstrates superior overall performance, particularly excelling in long-context tasks and multi-key retrieval settings.
👉 Paper link: https://huggingface.co/papers/2605.22791

42. Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles
🔑 Keywords: Reinforcement Learning, Multimodal Tasks, Orchestration Framework, Sequential Decision-Making, Computational Efficiency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to develop Maestro, a Reinforcement Learning-driven orchestration framework, that effectively composes expert models and skills for multimodal tasks to enhance performance and reduce computational overhead.
🛠️ Research Methods:
– Maestro is built as a sequential decision-making process using a hierarchical model-skill registry. It employs a lightweight policy to dynamically assemble ensembles of frozen expert models and a two-tier skill library.
💬 Research Conclusions:
– Maestro achieves an average accuracy of 70.1% on various benchmarks, outperforming GPT-5 and Gemini-2.5-Pro, and demonstrates generalization to unseen models and skills without needing retraining, all while maintaining high computational efficiency.
👉 Paper link: https://huggingface.co/papers/2605.22177

43. FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
🔑 Keywords: video generation, sliding windows, Tweedie matching, temporal consistency, stochastic early-phase sampling
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenges of generating long sequences using video diffusion models by proposing a novel, architecture-agnostic inference-time method.
🛠️ Research Methods:
– Utilizes overlapping sliding windows with Tweedie matching to ensure temporal consistency and manifold constraint.
– Employs stochastic early-phase sampling to synchronize trajectories and maintain visual fidelity.
💬 Research Conclusions:
– The method enhances temporal consistency and visual quality, producing videos significantly longer than traditional models without additional training.
– Extends capabilities to audio-video joint generation and text-to-3DGS without fine-tuning.
👉 Paper link: https://huggingface.co/papers/2605.20910

44. SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers
🔑 Keywords: SEGA, high-resolution text-to-image generation, Diffusion transformers, Rotary Position Embeddings, spatial-frequency structure
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to improve high-resolution text-to-image generation by adaptively scaling attention in accordance with the spatial-frequency structure during denoising steps.
🛠️ Research Methods:
– SEGA, a training-free method, dynamically scales attention across RoPE components based on the latent’s spatial-frequency structure at each denoising step.
💬 Research Conclusions:
– SEGA improves structural coherence and fine-detail fidelity, outperforming state-of-the-art training-free baselines in high-resolution synthesis across multiple target resolutions.
👉 Paper link: https://huggingface.co/papers/2605.22668

45. WorldKV: Efficient World Memory with World Retrieval and Compression
🔑 Keywords: WorldKV, AI-generated summary, Autoregressive video diffusion models, KV-cache attention, Sliding window inference
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to maintain consistency in AI-generated persistent world generation in video diffusion models while optimizing throughput.
🛠️ Research Methods:
– The proposed method, WorldKV, combines World Retrieval and World Compression to manage memory and throughput efficiently. World Retrieval selectively brings back relevant cached scenes, and World Compression reduces storage by pruning redundant tokens, allowing more history under a fixed budget.
💬 Research Conclusions:
– WorldKV achieves consistency and competitive performance in persistent world generation without fine-tuning, matching full KV-cache memory fidelity at double the throughput.
👉 Paper link: https://huggingface.co/papers/2605.22718

46. LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
🔑 Keywords: LatentOmni, cross-modal reasoning, audio-visual reasoning, latent space, temporal consistency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to introduce LatentOmni, a framework that enhances cross-modal reasoning by integrating textual reasoning with audio-visual latent states to improve performance in reasoning tasks.
🛠️ Research Methods:
– LatentOmni employs feature-level supervision and Omni-Sync Position Embedding (OSPE) to align latent reasoning states and ensure temporal consistency in audio-visual reasoning tasks.
💬 Research Conclusions:
– Through comprehensive evaluation, LatentOmni outperforms existing open-source models and explicit text-based Chain-of-Thought (CoT) approaches, indicating latent-space joint reasoning as a promising path for improving omnimodal understanding.
👉 Paper link: https://huggingface.co/papers/2605.22012

47. ACC: Compiling Agent Trajectories for Long-Context Training
🔑 Keywords: Agent Context Compilation, long-context reasoning, tool responses, environment observations, supervised fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces Agent Context Compilation (ACC) to enhance long-context reasoning in Language Models by transforming agent trajectories into structured QA pairs for direct supervision, bypassing the need for extra annotations.
🛠️ Research Methods:
– ACC converts problem-solving agent trajectories across fields like search and software engineering into long-context QA pairs, facilitating training without tool dependence, which is validated on long-range dependency modeling tasks like MRCR and GraphWalks.
💬 Research Conclusions:
– ACC enables effective long-context reasoning and achieves notable results in tasks like MRCR and GraphWalks, comparable to larger models, while maintaining general model capabilities. It also restructures attention and specialization within the trained models.
👉 Paper link: https://huggingface.co/papers/2605.21850

48. π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
🔑 Keywords: Proactive Assistance, Personal Assistant Agents, Large Language Models, Hidden User Intents, Multi-turn Interactions
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Address the gap in current benchmarks by introducing π-Bench, a benchmark designed to evaluate proactive assistance in personal assistant systems, focusing on identifying hidden user intents during sustained multi-turn interactions.
🛠️ Research Methods:
– Introduced π-Bench, comprising 100 multi-turn tasks across 5 domain-specific user personas, to test agents’ ability to anticipate and address user needs with hidden intents, inter-task dependencies, and cross-session continuity.
💬 Research Conclusions:
– Proactive assistance remains challenging.
– There is a clear distinction between proactivity and task completion.
– Prior interaction data are valuable for resolving proactive intents in later tasks.
👉 Paper link: https://huggingface.co/papers/2605.14678

49. Perception or Prejudice: Can MLLMs Go Beyond First Impressions of Personality?
🔑 Keywords: Multimodal Large Language Models, Grounded Personality Reasoning, Big Five score prediction, behavioral understanding, Prejudice Gap
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces a new task and dataset to evaluate personality reasoning in multimodal language models, highlighting the gap between accurate predictions and grounded reasoning processes.
🛠️ Research Methods:
– Developed a formalized task called Grounded Personality Reasoning (GPR).
– Released a new dataset named MM-OCEAN comprising 1,104 videos and 5,320 MCQs, incorporating human verification and timestamped behavioral observations.
– Designed a three-tier evaluation benchmark, including metrics like Prejudice Rate, Confabulation Rate, and others, performance-tested on 27 MLLMs.
💬 Research Conclusions:
– The analysis reveals significant gaps as 51% of correct ratings were not backed by retrieved cues, and Holistic-Grounding Rates varied between 0-33.5%. This uncovers a disconnect between accurate score prediction and reasoning for the appropriate reason, suggesting a roadmap for improving grounded social cognition in MLLMs.
👉 Paper link: https://huggingface.co/papers/2605.22109
