AI Native Daily Paper Digest – 20260526

1. DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
🔑 Keywords: DVAO, Reinforcement Learning, multi-reward settings, empirical reward variance, training stability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research introduces Dynamic Variance-adaptive Advantage Optimization (DVAO) to address training instability in multi-reward reinforcement learning by adaptively weighting objectives based on empirical reward variance.
🛠️ Research Methods:
– DVAO dynamically adjusts combination weights for each objective within a rollout group and employs a self-adaptive cross-objective regularization mechanism to maintain bounded advantage magnitudes for stable training.
💬 Research Conclusions:
– Extensive experiments demonstrate that DVAO significantly outperforms baseline methods, achieving superior multi-objective Pareto frontier and robust training stability, especially in mathematical reasoning and tool-use benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.25604

2. Macaron-A2UI: A Model for Generative UI in Personal Agents
🔑 Keywords: Generative UI, Personal Agents, A2UI-Bench, LoRA-based Supervised Fine-tuning, Reward-driven Reinforcement Learning
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The main goal is to advance beyond text-only interaction by enabling personal agents to generate both natural language and lightweight, executable UI actions for enhanced dialogue capabilities.
🛠️ Research Methods:
– The study introduces Macaron-A2UI, trained with large-scale Generative UI data from diverse dialogue sources, using parameter-efficient LoRA-based supervised fine-tuning followed by reward-driven reinforcement learning.
💬 Research Conclusions:
– The Macaron-A2UI model achieves a 75.6 overall score on the A2UI-Bench, surpassing full-schema baseline models, indicating superior performance in dynamic UI synthesis without schema hints. The release includes models, benchmark, and evaluation protocols to support future research.
👉 Paper link: https://huggingface.co/papers/2605.24830

3. TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
🔑 Keywords: AI-generated, feed-forward, triangle primitives, camera poses, mesh generation
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces TriSplat, a feed-forward 3D reconstruction network designed to generate simulation-ready meshes directly from single images, eliminating the need for expensive post-processing steps.
🛠️ Research Methods:
– TriSplat uses oriented triangle primitives to predict local 3D point maps, triangle attributes, and camera poses. This method refines geometry normals using image-conditioned normal heads and stabilizes early training through a mono-normal bootstrap schedule.
💬 Research Conclusions:
– TriSplat achieves more geometry-faithful reconstructions than existing Gaussian feed-forward baselines while maintaining competitive novel-view rendering quality. Its output can be directly utilized in physics engines and rendering pipelines, offering a practical solution for feed-forward 3D scene reconstruction.
👉 Paper link: https://huggingface.co/papers/2605.26115
4. ParaVT: Taming the Tool Prior Paradox for Parallel Tool Use in Agentic Video Reinforcement Learning
🔑 Keywords: ParaVT, Parallel Video Tool calling, multi-agent reinforcement learning, Tool Prior Paradox, PARA-GRPO
💡 Category: Reinforcement Learning
🌟 Research Objective:
– ParaVT aims to enhance long-video understanding by leveraging multi-agent reinforcement learning to enable parallel video tool calling, overcoming the limitations of sequential tool dispatch methods.
🛠️ Research Methods:
– Introduces PARA-GRPO, which incorporates targeted format rewards and frame-budget randomization to stabilize RL model outputs and mitigate issues from pretrained tool priors.
💬 Research Conclusions:
– ParaVT shows significant improvement over existing frameworks, with an average increase of +7.9% in long-video understanding benchmarks and enhanced training-time format compliance through the use of PARA-GRPO.
👉 Paper link: https://huggingface.co/papers/2605.20342

5. ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention
🔑 Keywords: ThriftAttention, long-context workloads, block-scaled quantisation, FP16 precision, FP4 inference
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aimed to address the quality degradation in long-context settings of attention computation using ThriftAttention, which selectively applies higher precision to critical query-key interactions.
🛠️ Research Methods:
– The research employed a two-stage process where a heuristic selects critical query-key block pairs for FP16 precision, while the remaining computations are done in FP4. Both results are merged using online softmax.
💬 Research Conclusions:
– ThriftAttention manages to recover 89.1% of the performance gap between FP4 and FP16 by computing only 5% of query-key blocks in FP16, with benefits increasing alongside sequence length, mitigating FP4 quality degradation in long-context scenarios.
👉 Paper link: https://huggingface.co/papers/2605.23081

6. Your Embedding Model is SMARTer Than You Think
🔑 Keywords: SMART, Multimodal Retrieval, Single-Vector Models, Contrastive Training, Late-Interaction
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the performance of multimodal retrieval by leveraging latent multi-vector capabilities from single-vector models, using the SMART framework.
🛠️ Research Methods:
– Employed contrastive training on pooled embeddings to influence retrieval geometry, followed by applying direct late-interaction during inference over frozen hidden states.
💬 Research Conclusions:
– The SMART framework offers a plug-and-play enhancement that reduces computational costs and enhances performance across various modalities, outperforming state-of-the-art models in multimodal tasks.
– Lightweight post-training with SMART further improves retrieval efficiency and effectiveness, particularly excelling in Visual Document retrieval.
👉 Paper link: https://huggingface.co/papers/2605.24938
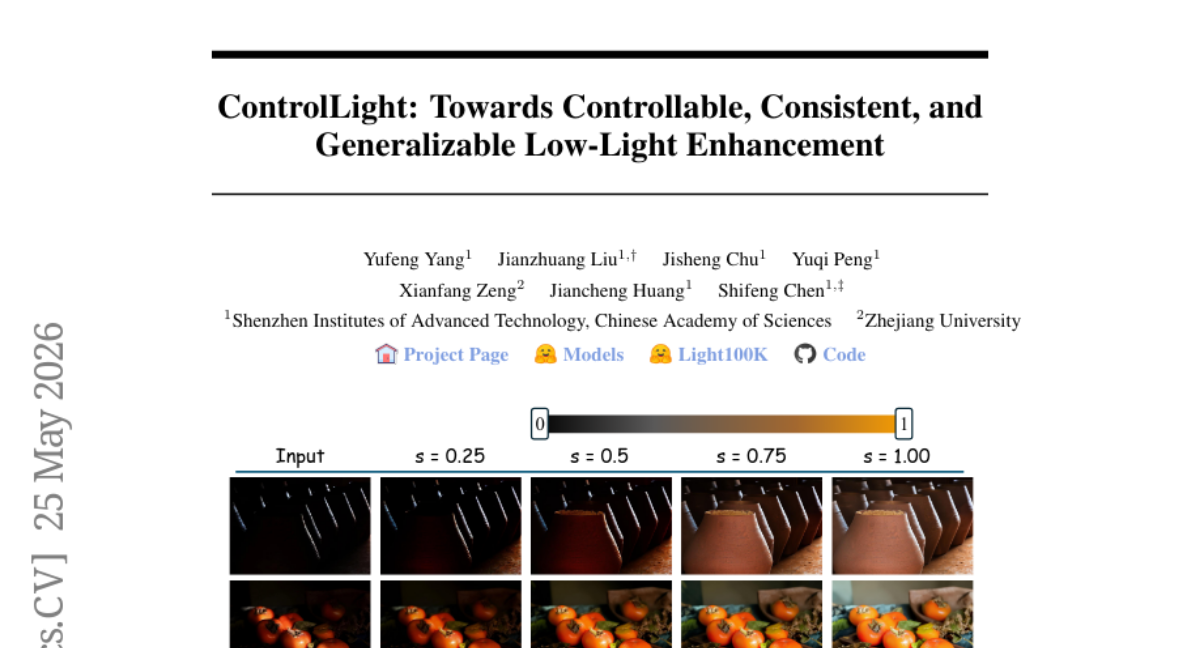
7. ControlLight: Towards Controllable, Consistent, and Generalizable Low-Light Enhancement
🔑 Keywords: ControlLight, low-light enhancement, large-scale dataset, weighted flow matching loss, generalization
💡 Category: Computer Vision
🌟 Research Objective:
– Propose ControlLight, a controllable framework for enhancing low-light images, ensuring consistent and generalizable performance.
🛠️ Research Methods:
– Utilize a large-scale dataset with continuous illumination-strength supervision and introduce a misalignment-aware weighted flow matching loss to preserve image structure.
💬 Research Conclusions:
– ControlLight demonstrates state-of-the-art performance with strong controllability and generalization to real-world scenarios, providing satisfactory enhancement results while maintaining visual realism.
👉 Paper link: https://huggingface.co/papers/2605.25569
8. Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User’s Digital World
🔑 Keywords: Claw-Anything, Large Language Model Agents, personal assistants, proactive assistance, automated data-generation pipeline
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to evaluate large language model agents in comprehensive user activity contexts to assess their capabilities as always-on personal assistants.
🛠️ Research Methods:
– Introduced the Claw-Anything benchmark which encompasses long-horizon activity histories, interdependent backend services, and multi-device GUI and CLI interactions.
– Simulated user activity through multi-round event injection to create complex, realistic world states and noise.
💬 Research Conclusions:
– Current agent systems like GPT-5.5 achieve only 34.5% pass@1, highlighting the gap between existing capabilities and the requirements for always-on personal assistance.
– A data-generation pipeline was developed that generates 2,000 training environments, improving the base model by 23.7%.
👉 Paper link: https://huggingface.co/papers/2605.26086

9. Anticipate and Learn: Unleashing Idle-Time Compute in Proactive Agents
🔑 Keywords: Proactive Agent Architecture, Idle-time Computation, Dialogue History, Task Completion, User Effort
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces ProAct, a proactive agent architecture that utilizes idle-time computation to anticipate and fulfill likely upcoming user needs, aiming to improve task completion efficiency and accuracy.
🛠️ Research Methods:
– ProAct employs a methodology of analyzing evolving dialogue history in conjunction with persistent memory to predict future user needs, enhancing the agent’s ability to prepare before a user query.
– The study includes the development of ProActEval, a comprehensive benchmark with 200 scenarios across 40 domains for evaluating proactive capabilities.
💬 Research Conclusions:
– ProAct significantly outperforms reactive baselines by reducing task completion turns by 14.8%, user effort by 11.7%, and hallucination rates by 28.1%.
– MemBench evaluations highlight ProAct’s state-of-the-art reflective accuracy, confirming its sustained and robust performance.
👉 Paper link: https://huggingface.co/papers/2605.25971

10. SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
🔑 Keywords: Large Language Model Agents, SkillEvolBench, Experience Reuse, Procedural Skills, Raw Trajectory Reuse
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to evaluate the transition from experience reuse to the formation of reusable procedural skills in large language model agents, utilizing the SkillEvolBench benchmark.
🛠️ Research Methods:
– The study employs SkillEvolBench, a diagnostic benchmark with 180 tasks across six environments to assess skill formation. Agents update a skill library with compacted trajectories and receive verifier feedback, then face deployment tasks that test their skills under different conditions.
💬 Research Conclusions:
– Current agents often adapt locally and struggle to form robust reusable skills, and raw trajectory reuse often outperforms distilled skills. Writing more skills alone does not ensure success, as this may introduce episode-specific drift and clutter, highlighting the inadequacy of current abstraction procedures.
👉 Paper link: https://huggingface.co/papers/2605.24117

11. MemForest: An Efficient Agent Memory System with Hierarchical Temporal Indexing
🔑 Keywords: MemForest, long-context LLM agents, memory framework, temporal data management, parallel chunk extraction
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the scalability and reduce latency in long-context LLM agents by proposing MemForest, a novel memory framework.
🛠️ Research Methods:
– Introduced parallel chunk extraction and hierarchical temporal indexing in MemForest to reformulate agent memory management.
💬 Research Conclusions:
– MemForest enhances performance by achieving 79.8% accuracy in LongMemEval-S and providing a 6x improvement in memory construction throughput compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2605.23986

12. Faithfulness Metrics Don’t Measure Faithfulness: A Meta-Evaluation with Ground Truth
🔑 Keywords: Chains of thought, faithfulness metrics, ground-truth labels, automated labeling pipeline, prediction biases
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate faithfulness metrics related to Chains of thought in large language models and address their reliability and efficiency issues.
🛠️ Research Methods:
– Development of a benchmark (BonaFide) with 3,066 labeled Chains of thought across 13 tasks and 10 models.
– Construction of tasks with outputs that reveal necessary intermediate computations and an automated labeling pipeline to generate ground-truth faithfulness labels.
💬 Research Conclusions:
– Most faithfulness metrics perform randomly and exhibit significant limitations, including strong prediction biases and inefficiency, especially for longer Chains of thought.
– There is a necessity for more reliable and efficient faithfulness evaluation metrics as existing ones yield only moderate success with prohibitive computational costs.
👉 Paper link: https://huggingface.co/papers/2605.25052

13. MetaphorVU: Towards Metaphorical Video Understanding
🔑 Keywords: metaphorical video understanding, cross-domain mapping, MetaphorVU-Bench, metaphor knowledge graph, MetaphorBoost
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address the challenges in metaphoric video understanding by developing a new benchmark named MetaphorVU-Bench and an enhancement framework.
🛠️ Research Methods:
– Construction of MetaphorVU-Bench for comprehensive analysis.
– Implementation of a metaphor knowledge graph and introduction of MetaphorBoost for inference-time enhancement.
💬 Research Conclusions:
– Existing multimodal large language models (MLLMs) exhibit poor performance in metaphorical video understanding.
– The proposed methods and benchmark provide a foundation for improving MLLMs’ cross-domain mapping and high-order cognitive capabilities.
👉 Paper link: https://huggingface.co/papers/2605.25461

14. Helix4D: Complex 4D Mesh Generation
🔑 Keywords: Helix4D, dynamic mesh generation, Trellis2, frame-local attention, 4D temporal encoding
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a dynamic mesh generation framework using Helix4D that addresses complex topology changes and rare cases like transparent objects in video-to-4D methods by enhancing Trellis2.
🛠️ Research Methods:
– Utilized sliding-window cross-frame attention and 4D temporal encoding to adapt Trellis2’s frame-local attention for 4D video-conditioned generation.
💬 Research Conclusions:
– Helix4D successfully improves high-quality dynamic mesh generation on complex dynamics, as demonstrated through extensive experiments on ActionBench and challenging datasets.
👉 Paper link: https://huggingface.co/papers/2605.26109
15. CoSPlay: Cooperative Self-Play at Test-Time with Self-Generated Code and Unit Test
🔑 Keywords: Cooperative Self-Play, GT-free, Code Generation, Unit Tests, Reinforcement Learning
💡 Category: Generative Models
🌟 Research Objective:
– The main goal is to enhance code generation and unit test quality without relying on Ground-Truth Unit Tests (GT UTs), using a framework called CoSPlay.
🛠️ Research Methods:
– CoSPlay employs a GT-free, training-free framework leveraging cooperative self-play. It iteratively refines codes and unit tests through bidirectional pass-count signals, facilitating the co-evolution of solutions and tests.
💬 Research Conclusions:
– CoSPlay significantly improves code generation efficiency, boosting average BoN from 22.1% to 33.2% and unit test accuracy from 14.6% to 78.3%. It demonstrates superiority over GT-free TTS baselines and provides a scalable inference strategy for competitive code generation without needing GT data.
👉 Paper link: https://huggingface.co/papers/2605.23491

16. Coloring the Noise: Adversarial Sobolev Alignment for Faithful Image Super Resolution
🔑 Keywords: Spectral Misalignment, Riemannian Geometry, Adversarial Training, Image Super-Resolution, Generative Priors
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenge of spectral misalignment in Image Super-Resolution (SR) to enhance structural fidelity and minimize artifacts by introducing the ASASR framework.
🛠️ Research Methods:
– The proposed ASASR framework leverages Riemannian geometry, using a Sobolev-induced model, to align generative priors with the natural image manifold through a colored noise transition kernel and parametric adversarial training using the Riesz Representation Theorem.
💬 Research Conclusions:
– ASASR outperforms leading generative baselines by ensuring spectral consistency and structural fidelity, offering an effective solution to mitigate artifacts in Image Super-Resolution tasks.
👉 Paper link: https://huggingface.co/papers/2605.23264

17. Injecting Image Guidance into Text-Conditioned Diffusion Models at Inference
🔑 Keywords: Visual Concept Fusion, Stable Diffusion, CLIP image features, text embedding space, InfoNCE
💡 Category: Generative Models
🌟 Research Objective:
– To introduce Visual Concept Fusion (VCF) as a new method enabling dual text and image conditioning in diffusion models without retraining.
🛠️ Research Methods:
– Utilizes a lightweight aligner to map image tokens to the text embedding manifold with InfoNCE and cross-attention reconstruction losses.
– Incorporates a fusion strategy to preserve both textual and visual semantics.
– Offers an optional Prompt-Noise Optimization module for test-time refinement.
💬 Research Conclusions:
– VCF effectively transfers visual attributes such as style, composition, and color palette from reference images while maintaining prompt adherence.
– Demonstrated to outperform baselines in reference fidelity with a balance between text alignment and visual correspondence.
👉 Paper link: https://huggingface.co/papers/2605.25191

18. ECHO: Terminal Agents Learn World Models for Free
🔑 Keywords: Environment Cross-entropy Hybrid Objective, Policy-gradient Loss, Dense Supervision, Terminal Feedback, Self-improvement
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The main goal is to enhance agent performance and self-improvement capabilities by combining policy-gradient loss with auxiliary environment observation prediction for dense supervision.
🛠️ Research Methods:
– The introduction of ECHO (Environment Cross-entropy Hybrid Objective), which combines standard policy-gradient loss with an auxiliary loss to predict environment observation tokens, utilizing feedback from terminal interactions for dense supervision.
💬 Research Conclusions:
– ECHO notably improves performance on TerminalBench-2.0, doubling the pass@1 rate of GRPO. It enhances policy prediction of terminal dynamics without the need for additional rollouts or expert demonstrations and enables self-improvement on unseen tasks using environment interactions.
👉 Paper link: https://huggingface.co/papers/2605.24517

19. Directional Alignment Mitigates Reward Hacking in Reinforcement Learning for Language Models
🔑 Keywords: Reward hacking, reinforcement learning updates, language models, optimization drift, trusted-direction projection
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This research aims to investigate reward hacking in language models, specifically focusing on how this phenomenon arises through the geometry of reinforcement learning updates.
🛠️ Research Methods:
– The study analyzes optimization drift using dominant singular directions of parameter updates and introduces trusted-direction projection to constrain gradient movement within a clean reference subspace.
💬 Research Conclusions:
– The proposed trusted-direction projection approach effectively delays shortcut exploitation and helps preserve task performance in reward-hacking scenarios, particularly in mathematical reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2605.25189

20. How Far Will They Go? Red-Teaming Online Influence with Large Language Models
🔑 Keywords: red-teaming, political influence campaigns, LLM Overton Windows, jailbreaks, political expressivity
💡 Category: Natural Language Processing
🌟 Research Objective:
– To assess the potential misuse of open-source large language models in political influence campaigns and establish a systematic framework for their evaluation.
🛠️ Research Methods:
– Introduced an empirical red-teaming framework to measure LLM Overton Windows, and evaluated over 30 LLMs spanning 10 model families and five countries to quantify the effects of natural-language jailbreaks.
💬 Research Conclusions:
– Open-source LLMs often show left-leaning biases in political expressivity, with notable regional differences. The size of Overton Windows contracts inversely with model size, with jailbreak effectiveness varying significantly across model families.
👉 Paper link: https://huggingface.co/papers/2605.22880

21. HorizonStream: Long-Horizon Attention for Streaming 3D Reconstruction
🔑 Keywords: HorizonStream, geometric propagation, streaming 3D reconstruction, Geometric Linear Attention, evidence influence kernel
💡 Category: Computer Vision
🌟 Research Objective:
– To address long-term 3D reconstruction challenges by modeling geometric propagation using an evidence influence kernel, enabling stable and scalable streaming reconstruction.
🛠️ Research Methods:
– Formalizes geometric propagation through an evidence influence kernel and proposes HorizonStream, a long-horizon Transformer with factors like Geometric Linear Attention and Geometric Local Attention to manage temporal and spatial evidence.
💬 Research Conclusions:
– HorizonStream achieves state-of-the-art streaming 3D reconstruction performance, effectively generalizing to long sequences with constant memory and linear time complexity.
👉 Paper link: https://huggingface.co/papers/2605.23889

22. Pixel-Level Pavement Distress Assessment Using Instance Segmentation
🔑 Keywords: Mask R-CNN, instance segmentation, Detectron2, ResNet-101 FPN, crack-area fraction
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a vision-based pavement distress analysis system to improve crack detection accuracy through precise geometric localization.
🛠️ Research Methods:
– Utilized Mask R-CNN instance segmentation with five Detectron2-based backbone variants, and fine-tuned using the UWGB-StreetCrack dataset for crack and pothole identification.
💬 Research Conclusions:
– The Mask R-CNN model with a ResNet-101 FPN backbone outperformed with high precision (84.23%), recall (90.04%), and an F1 score of 87.04%, proving instance segmentation as a viable method for pavement distress analysis. Comparatively, YOLO with CSPDarknet53 showed substantially lower precision and recall.
👉 Paper link: https://huggingface.co/papers/2605.26095

23. Broadening Access to Transportation Safety Data with Generative AI: A Schema-Grounded Framework for Spatial Natural Language Queries
🔑 Keywords: Transportation safety analysis, Natural language interface, Large language model, Deterministic execution, Schema-grounded
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to bridge the gap in transportation safety analysis by providing a natural language interface using large language models to make data access and analysis more accessible to local agencies and stakeholders.
🛠️ Research Methods:
– Utilizes a large language model to interpret user queries and translates them into structured semantic frames, validated by a rule-based layer, and compiled into a directed acyclic graph of spatial operations executed against a PostGIS database. The design emphasizes separating language interpretation from deterministic execution.
💬 Research Conclusions:
– The framework effectively broadens access to transportation safety data while ensuring results are reproducible and reliable. The validation layer successfully corrected errors, demonstrating the practical application and value of combining natural language accessibility with deterministic execution in public-sector planning.
👉 Paper link: https://huggingface.co/papers/2605.21712

24. Decoding the Critique Mechanism in Large Reasoning Models
🔑 Keywords: Large Reasoning Models, self-verification, critique ability, critique vector, chain-of-thought
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To investigate the hidden critique abilities of Large Reasoning Models (LRMs) that aid in error recovery through internal mechanisms.
🛠️ Research Methods:
– Systematic investigation by introducing arithmetic mistakes in intermediate reasoning steps to analyze error recovery, using feature space analysis to identify critique vectors.
💬 Research Conclusions:
– LRMs can reach correct solutions despite intermediate errors due to an internal critique mechanism. Steering latent representations with identified critique vectors enhances error detection and model performance without additional training.
👉 Paper link: https://huggingface.co/papers/2603.16331

25. Seeing the Needle in the Haystack: Towards Weakly-Supervised Log Instance Anomaly Localization via Counterfactual Perturbation
🔑 Keywords: Log anomaly detection, Weakly supervised framework, Prototype-guided structural modeling, Counterfactual perturbation consistency regularization
💡 Category: Machine Learning
🌟 Research Objective:
– To develop a weakly supervised framework, LogMILP, for log anomaly detection and instance-level localization using prototype-guided structural modeling.
🛠️ Research Methods:
– Utilizes Multi-Instance Learning with prototype guidance and counterfactual perturbation consistency to improve anomaly localization.
💬 Research Conclusions:
– LogMILP achieves competitive detection and more reliable instance-level localization performance under coarse-grained supervision on public datasets.
👉 Paper link: https://huggingface.co/papers/2605.10988

26.

27. MotiMotion: Motion-Controlled Video Generation with Visual Reasoning
🔑 Keywords: AI Native, motion-controlled video generation, vision-language reasoning, confidence-aware control, image-to-video benchmark
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to improve the plausibility of motion-controlled video generation by introducing a reasoning-then-generation framework called MotiMotion.
🛠️ Research Methods:
– Utilizes a training-free vision-language reasoner to refine trajectories and envision secondary motions.
– Incorporates a confidence-aware control scheme to modulate guidance strength.
💬 Research Conclusions:
– MotiMotion generates videos with more plausible object behaviors and interactions, favored in both VLM-based evaluations and human studies over existing methods.
👉 Paper link: https://huggingface.co/papers/2605.22818

28. ClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
🔑 Keywords: ClaimDiff-RL, reward granularity, long-form image captioning, hallucination, factuality
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces ClaimDiff-RL to address reward granularity issues in long-form image captioning by using reference-conditioned atomic claim differences as reward units. This enables detailed measurement and tuning of hallucination and omission errors.
🛠️ Research Methods:
– The researchers implemented a framework with a multimodal judge that evaluates visually grounded differences, verifies against the image, and assigns error types and severity levels for better reward composition in reinforcement learning.
💬 Research Conclusions:
– ClaimDiff-RL improves the balance between hallucination and missing facts, preserves general capabilities, and surpasses existing models in specific areas such as object counting and scene recognition, highlighting its effectiveness as a reward mechanism in captioning tasks.
👉 Paper link: https://huggingface.co/papers/2605.20278

29. Decoupling Communication from Policy: Robust MARL under Bandwidth Constraints
🔑 Keywords: Multi-Agent Reinforcement Learning, Communication Architecture, Bandwidth Constraints, Latent Representation, SLIM
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To propose a novel communication architecture for Multi-Agent Reinforcement Learning that decouples policy representation from communication pathways in order to improve performance under bandwidth constraints.
🛠️ Research Methods:
– Introduction of a normalized per-agent bandwidth budget called β to unify sparsity, rounds, and message dimension.
– Development of a minimal architecture named SLIM to separate communication pathways from policy’s latent representation.
💬 Research Conclusions:
– The proposed approach achieved state-of-the-art performance on several benchmarks of partially observable MARL, demonstrating scalability and robustness with only minor performance degradation under limited communication.
👉 Paper link: https://huggingface.co/papers/2605.21085

30. RankJudge: A Multi-Turn LLM-as-a-Judge Synthetic Benchmark Generator
🔑 Keywords: RankJudge, LLM-as-a-judge, multi-turn conversations, benchmark generator
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to develop a benchmark generator, RankJudge, to evaluate large language model judges on complex multi-turn conversations.
🛠️ Research Methods:
– The research employs the creation of conversation pairs with injected flaws and uses statistical models like the Bradley-Terry model for ranking and assessing the difficulty of these conversations across various domains such as machine learning, biomedicine, and finance.
💬 Research Conclusions:
– The study concludes that the rankings of LLM judges are robust under different conditions and criteria, indicating the effectiveness of RankJudge in reducing label noise and stabilizing judge evaluations.
👉 Paper link: https://huggingface.co/papers/2605.21748

31. Representation over Routing: Overcoming Surrogate Hacking in Multi-Timescale PPO
🔑 Keywords: Multi-timescale reinforcement learning, Actor-Critic, Target Decoupling, temporal attention routing, Paradox of Temporal Uncertainty
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to address algorithmic pathologies in multi-timescale reinforcement learning by developing a Target Decoupling architecture to better handle delayed-reward environments.
🛠️ Research Methods:
– The researchers introduce a Target Decoupling architecture that separates temporal predictions in the critic from policy updates in the actor, providing empirical evaluations using the LunarLander-v2 environment.
💬 Research Conclusions:
– The proposed architecture significantly improves performance in reinforcement learning tasks by avoiding policy collapse and escaping local optima, without resorting to hyperparameter tuning, and it achieves consistent results across multiple seeds.
👉 Paper link: https://huggingface.co/papers/2604.13517

32. Towards Evaluation Engineering: An Empirical Study of ML Evaluation Harnesses in the Wild
🔑 Keywords: Evaluation Harnesses, Machine Learning Infrastructure, Operational Challenges
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to empirically study evaluation harnesses, identifying operational challenges and engineering concerns within machine learning infrastructures.
🛠️ Research Methods:
– An empirical analysis was conducted on 57 evaluation harnesses, with issues classified by workflow stage and root cause, resulting in a five-stage harness model.
💬 Research Conclusions:
– The study found that the majority of operational challenges occur in the Specification stage, with key issues being unimplemented features, documentation gaps, and missing input validation. These insights highlight the need to treat evaluation engineering as a distinct software engineering concern.
👉 Paper link: https://huggingface.co/papers/2605.24213

33. SimuWoB: Simulating Real-World Mobile Apps for Fast and Faithful GUI Agent Benchmarking
🔑 Keywords: Mobile GUI agents, large language models, synthetic benchmark, high-fidelity virtual environments, long-horizon interactions
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce SimuWoB, a fully synthetic benchmark with 120 challenging tasks for mobile GUI agents, addressing gaps in current evaluation methods.
🛠️ Research Methods:
– Development of a robust virtual environment generation framework that creates high-fidelity tasks and provides automatic reward generation.
💬 Research Conclusions:
– Current mobile GUI agents have an average success rate of 27.92%, dropping to 17.82% on long-horizon tasks, indicating weaknesses in complex scenarios. The synthetic environment generalizes well to real-world scenarios, offering insights for future development.
👉 Paper link: https://huggingface.co/papers/2605.25160

34. SemBridge: Language Transfer in Sparse Encoders via Multilingual Semantic Bridges
🔑 Keywords: SemBridge, cross-lingual adaptation, multilingual bridge models, semantic alignment, zero-shot retrieval
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance cross-lingual adaptation in sparse encoders by utilizing SemBridge to improve retrieval performance across multiple languages.
🛠️ Research Methods:
– The method involves using multilingual dense embeddings as a bridge to establish semantic alignments between source and target vocabularies, followed by selective initialization of target-language tokens with semantically related source-language tokens.
💬 Research Conclusions:
– SemBridge demonstrates superior zero-shot retrieval performance and improved retrieval performance after fine-tuning compared to existing baselines, suggesting its effectiveness in deploying high-performance sparse retrieval systems in diverse linguistic environments.
👉 Paper link: https://huggingface.co/papers/2605.26002

35. Reinforcing Few-step Generators via Reward-Tilted Distribution Matching
🔑 Keywords: Reward-Tilted Distribution Matching Distillation, distribution matching distillation, reward-guided reinforcement learning, KL divergence, few-step image generation
💡 Category: Generative Models
🌟 Research Objective:
– The paper proposes a two-stage framework called Reward-Tilted Distribution Matching Distillation (RTDMD) to improve the alignment of few-step image generation models with human preferences.
🛠️ Research Methods:
– The method combines distribution matching distillation with reward-guided reinforcement learning. The framework includes Ambient-Consistent Distribution Matching Distillation (AC-DMD), utilizing a consistency regularizer and a hybrid policy gradient strategy to optimize reward maximization and reduce variance.
💬 Research Conclusions:
– The RTDMD framework achieves state-of-the-art results in preference, aesthetic, and compositional metrics on datasets such as SD3, SD3.5, and FLUX.2, outperforming previous methods with only 4 inference steps.
👉 Paper link: https://huggingface.co/papers/2605.26108

36. SEAL: Synergistic Co-Evolution of Agents and Learning Environments
🔑 Keywords: SEAL, closed-loop co-evolution, interactive tool-use agents, Agent-Environment Misalignment, low-resource agent learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to address the Agent-Environment Misalignment by proposing SEAL, a closed-loop co-evolution framework enhancing interactive tool-use capabilities in large language models through simultaneous adaptation of agent policies and training environments.
🛠️ Research Methods:
– SEAL collects on-policy trajectories under executable verification, diagnoses failed rollouts into turn-level failure labels, and uses these diagnoses for both environment-side adaptation and model-side policy optimization.
💬 Research Conclusions:
– SEAL improves agent learning efficiency significantly, achieving average-point gains of +8.25 to +26.25 with only 400 training samples and demonstrating strong out-of-distribution transfer capabilities, underscoring the benefits of joint learner and environment adaptation.
👉 Paper link: https://huggingface.co/papers/2605.24426

37. Towards Customized Multimodal Role-Play
🔑 Keywords: AI-generated summary, Customized Multimodal Role-Play, cross-modal consistency, few-shot customization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main objective is to introduce a new task called Customized Multimodal Role-Play (CMRP) and a corresponding dataset, which enables consistent character customization across text and image modalities through few-shot learning.
🛠️ Research Methods:
– Utilized a unified model framework called UniCharacter, which involves a two-stage training process: Unified Supervised Finetuning (Unified-SFT) and Character-Specific Group Relative Policy Optimization (Character-GRPO). The method leverages a small set of images and interaction examples to achieve cross-modal consistency and character coherence.
💬 Research Conclusions:
– The experiments on the RoleScape-20 dataset indicate that the proposed method significantly outperforms previous approaches, validating the effectiveness of the cross-modal consistency design and few-shot customization strategies. The research lays the groundwork for next-generation characterful and immersive interactive agents.
👉 Paper link: https://huggingface.co/papers/2605.08129

38. CRONOS: Benchmarking Counterfactual Physical Consistency in Video Models
🔑 Keywords: CRONOS, video prediction, counterfactual physical consistency, intervention-based benchmark
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce CRONOS as a benchmark for assessing counterfactual physical consistency in video prediction models by using controlled interventions.
🛠️ Research Methods:
– Use of a photorealistic Unreal Engine environment to generate videos with controlled changes in scene context, viewpoint, object appearance, and object category while maintaining consistent physical event types.
💬 Research Conclusions:
– Recent video generators show significant failures in maintaining counterfactual physical consistency, particularly when changes in viewpoint occur. CRONOS serves as a reproducible testbed for examining these inconsistencies and provides a concrete target for model improvement.
👉 Paper link: https://huggingface.co/papers/2605.23699

39. Language Models Need Sleep
🔑 Keywords: Transformer-based large language models, sleep-like consolidation mechanism, fast weights, recurrent passes, attention mechanism
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve long-context processing in transformer models using a sleep-like consolidation mechanism without compromising inference speed.
🛠️ Research Methods:
– Implementation of a sleep-like mechanism converting recent context into fast weights, utilizing offline recurrent passes, and updating the state-space model blocks.
– Evaluation on synthetic tasks such as cellular automata and multi-hop graph retrieval, and a realistic math reasoning task.
💬 Research Conclusions:
– The proposed mechanism enhances performance, particularly with increased sleep duration, notably on tasks requiring deeper reasoning where traditional transformers and SSM-attention hybrids do not perform well.
👉 Paper link: https://huggingface.co/papers/2605.26099

40. InstructSAM: Segment Any Instance with Any Instructions
🔑 Keywords: InstructSAM, multi-instance segmentation, vision-language models, learnable instance queries, hybrid-attention mechanism
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce InstructSAM, a unified framework for performing multi-instance segmentation using instruction-driven queries.
🛠️ Research Methods:
– Formulation of instance segmentation as a set-structured query prediction problem, utilizing a hybrid-attention mechanism and learnable instance queries within a vision-language model (VLM) to facilitate interaction and accurate segmentation.
💬 Research Conclusions:
– InstructSAM outperforms previous methods and enhances SAM3 by enabling efficient single-pass multi-instance prediction and strong results on complex benchmarks.
👉 Paper link: https://huggingface.co/papers/2605.26102

41. Geometry-Aware Image Flow Matching
🔑 Keywords: Geometry-aware modelling, Spherical manifolds, Optimal transport, Natural images, Hypersphere
💡 Category: Generative Models
🌟 Research Objective:
– Investigate the potential of leveraging geometric structures on hyperspheres for natural image synthesis, moving beyond traditional Euclidean approaches.
🛠️ Research Methods:
– Introduced Spherical Optimal Transport Flow Matching and Spherical Flow Matching, utilizing angular distances and manifold constraints to improve image synthesis performance.
💬 Research Conclusions:
– Demonstrated that geometry-aware methods outperform traditional Euclidean approaches, offering a novel perspective by bridging the gap between Riemannian manifold-based modeling and natural image generation.
👉 Paper link: https://huggingface.co/papers/2605.25294

42. Channel-wise Vector Quantization
🔑 Keywords: Channel-wise Vector Quantization, Image Tokenization, Next-channel Prediction, Codebook Utilization, Text-to-image Generation
💡 Category: Generative Models
🌟 Research Objective:
– To introduce Channel-wise Vector Quantization (CVQ) to replace traditional patch-wise tokens with channel-wise tokens in image tokenization.
🛠️ Research Methods:
– Developed a novel image tokenization paradigm, CVQ, and built a Channel-wise Autoregressive (CAR) model to predict image channels sequentially.
💬 Research Conclusions:
– CVQ achieves 100% codebook utilization with a large codebook size and improves reconstruction quality.
– The CAR model demonstrates strong effectiveness for text-to-image generation, achieving a DPG score of 86.7 and a GenEval score of 0.79.
👉 Paper link: https://huggingface.co/papers/2605.26089

43. On-Policy Adversarial Flow Distillation for Autoregressive Video Generation
🔑 Keywords: Adversarial Flow Distillation, Heterogeneous Video Generation, On-Policy Feedback, Forward-Process Flow-Matching
💡 Category: Generative Models
🌟 Research Objective:
– The research introduces Adversarial Flow Distillation (AFD) to distill heterogeneous video generation models efficiently without needing teacher scores or detailed trajectory information.
🛠️ Research Methods:
– AFD employs an on-policy framework for video distillation by querying the teacher and rolling out the student on identical prompts. It uses a Bradley-Terry discriminator to calculate teacher-student discrepancies, then applies forward-process flow-matching updates to the student’s noised states.
💬 Research Conclusions:
– The AFD approach improves the generation of motion- and physics-sensitive video content while maintaining overall quality. It proves effective across various autoregressive student models and confirms the benefit of adaptive on-policy feedback and forward-process credit assignment.
👉 Paper link: https://huggingface.co/papers/2605.26105

44. CUA-Gym: Scaling Verifiable Training Environments and Tasks for Computer-Use Agents
🔑 Keywords: RLVR, computer-use agents, verifiable rewards, CUA-Gym, synthetic environments
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To address data scarcity in computer-use agents by developing a scalable generation pipeline and synthetic environments for enhanced performance in RLVR.
🛠️ Research Methods:
– Introduce CUA-Gym, a pipeline co-generating task instructions, environment states, and reward functions, employing Generator and Discriminator agents with orchestration.
– Develop CUA-Gym-Hub, a suite of high-fidelity mock web applications to expand RLVR data scale.
💬 Research Conclusions:
– CUA-Gym dataset improved performance on benchmarks like OSWorld-Verified, with models trained on it showing superior scalability and transferability to other environments such as WebArena.
– The synthesis pipeline and related resources will be open-sourced to the community.
👉 Paper link: https://huggingface.co/papers/2605.25624

45. Pantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion
🔑 Keywords: Digital Twins, 360° Video Generation, Spatial-Temporal Consistency, 3D-Aware, Geometric Caching
💡 Category: Generative Models
🌟 Research Objective:
– To develop a high-fidelity 360° video generation framework, Pantheon360, for digital twins featuring spatial-temporal consistency.
🛠️ Research Methods:
– Combines 3D-aware diffusion with explicit geometric caching to handle the challenges of narrow field of view in perspective video generators.
💬 Research Conclusions:
– Pantheon360 achieves superior visual quality and geometric coherence, enabling reliable 360° scene generation for simulation and digital-twin applications.
👉 Paper link: https://huggingface.co/papers/2605.25449

46. AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery
🔑 Keywords: AutoResearch, AI-powered scientific workflow automation, Vibe Research, AI scientist systems, provenance
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper explores the evolution of AI systems from task-specific assistants to automators of entire research workflows, emphasizing the need for improved autonomy, reproducibility, and accountability.
🛠️ Research Methods:
– It examines the current fragmented state of AI systems across various scientific domains and analyzes the redistribution of control and accountability in scientific workflows through AutoResearch.
💬 Research Conclusions:
– The study concludes that while AI systems show promise in structured and verifiable settings, their applicability remains limited in complex and ethically sensitive domains. Five evaluation dimensions are proposed to guide future development and assessment.
👉 Paper link: https://huggingface.co/papers/2605.23204

47. QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
🔑 Keywords: QUEST, deep research agents, reinforcement learning, data synthesis pipeline, knowledge synthesis
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Develop an open-family of deep research agents, known as QUEST, capable of performing diverse long-horizon search tasks with proficiency in fact seeking, citation grounding, and report synthesis.
🛠️ Research Methods:
– Utilized a combination of mid-training, supervised fine-tuning, and reinforcement learning within a data synthesis pipeline based on unified rubric trees to generate training data with verifiable rewards.
💬 Research Conclusions:
– QUEST models demonstrate strong performance across eight deep research benchmarks, often surpassing closed-source agents, thereby showcasing superior capabilities among open-weight agents.
👉 Paper link: https://huggingface.co/papers/2605.24218

48. Toward Native Multimodal Modeling: A Roadmap
🔑 Keywords: Native Multimodal Modeling, Architecture Nativity, Input-Output Duality, Unified Transformer Paradigm, Scenario-Oriented Generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To present a formalized roadmap for transitioning to native multimodal modeling, emphasizing the intrinsic integration of modalities for superior performance.
🛠️ Research Methods:
– Formal definition of architectural nativity distinguishing different fusion paradigms.
– Organization of native models based on input-output duality into three categories.
💬 Research Conclusions:
– The study provides a comprehensive investigation and defines an end-to-end pipeline for native multimodal modeling, including architectural coordination, data curation, and model evaluation within a unified transformer framework.
👉 Paper link: https://huggingface.co/papers/2605.25343

49. Foundation Protocol: A Coordination Layer for Agentic Society
🔑 Keywords: Autonomous agents, social infrastructure, coordination, AI economy, Foundation Protocol
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce the Foundation Protocol (FP) as a graph-first coordination layer for integrating autonomous agents and other entities into a human-AI society.
🛠️ Research Methods:
– Develop FP to unify heterogeneous entities and support multi-party organization, event-based collaboration, and economic functions like metering and settlement.
💬 Research Conclusions:
– FP provides a framework for composability and accountability, facilitating the creation of a shared infrastructure for an open, pluralistic, and governable human-AI society.
👉 Paper link: https://huggingface.co/papers/2605.23218
50. WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
🔑 Keywords: Interactive world models, WBench, multi-turn benchmark, video quality, multimodal models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to establish WBench as a comprehensive multi-turn benchmark to systematically evaluate interactive world models across five dimensions: video quality, setting adherence, interaction adherence, consistency, and physics compliance.
🛠️ Research Methods:
– WBench uses 289 test cases with 1,058 interaction turns covering diverse scenarios, and employs 22 automatic sub-metrics validated against human judgments, leveraging specialist vision and large multimodal models.
💬 Research Conclusions:
– The study reveals that no single state-of-the-art model excels across all evaluation dimensions, providing detailed insights into individual model strengths and weaknesses. The resources are made available for further research at the provided GitHub repository.
👉 Paper link: https://huggingface.co/papers/2605.25874
