AI Native Daily Paper Digest – 20260604
1. Audio Interaction Model
🔑 Keywords: Audio Interaction Model, Large Audio Language Models, SoundFlow, Streaming Audio Models, Real-time ASR
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Develop a unified streaming audio model that combines offline task execution with real-time audio instruction following in an end-to-end framework.
🛠️ Research Methods:
– The development of SoundFlow, facilitating an always-on perceive-decide-respond loop through streaming-native data construction and comprehension-aware training.
– Creation of StreamAudio-2M, a comprehensive streaming corpus, and Proactive-Sound-Bench to evaluate proactive audio intervention.
💬 Research Conclusions:
– Audio-Interaction preserves competitive performance on mainstream audio tasks while enabling new real-time capabilities such as ASR, streaming audio instruction, and proactive help.
👉 Paper link: https://huggingface.co/papers/2606.05121

2. Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
🔑 Keywords: Deep-research agents, span-level error localization, error spans, claim-centric auditing, trajectory evidence
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Develop a framework to audit deep-research agents by identifying error spans in their reasoning paths, enhancing reliability assessment beyond final answer evaluation.
🛠️ Research Methods:
– Collect 2,790 trajectories from agent frameworks, backbone models, and benchmarks, convert logs into semantic spans; annotate error spans through LLM-assisted expert review.
– Build TELBench, a benchmark for identifying error spans and propose DRIFT, a claim-centric auditing framework to track agent claims and their support in trajectory evidence.
💬 Research Conclusions:
– DRIFT improves span-level error localization and first-error accuracy by up to 30 percentage points, providing a process-level view of reliability in deep-research agents.
👉 Paper link: https://huggingface.co/papers/2606.02060

3. OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs
🔑 Keywords: streaming spatial intelligence, multimodal language models, OVO-S-Bench, allocentric mapping, chain-of-thought reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce a comprehensive benchmark, OVO-S-Bench, for evaluating streaming spatial intelligence in multimodal language models, particularly in applications such as robotics, augmented reality, and autonomous driving.
🛠️ Research Methods:
– Creation of a fully human-annotated benchmark consisting of 1,680 questions over 348 videos, with annotations made by 12 trained annotators who also participated in blind cross-reviews. The benchmark features questions at four levels of abstraction and uses precise timing for queries and evidence intervals.
💬 Research Conclusions:
– Existing MLLMs, especially those emphasizing streaming and spatial tuning, underperform in comparison to their backbones, with major challenges in allocentric mapping. Furthermore, ungrounded chain-of-thought reasoning exacerbates spatial errors. The study identifies significant bottlenecks and sets a challenging test environment for advancing streaming spatial MLLMs.
👉 Paper link: https://huggingface.co/papers/2606.03890

4. M^3Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
🔑 Keywords: Multi-modal models, Memory, Video understanding, Cognitive psychology, Disentangled representations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to improve the memory capabilities of multi-modal models, particularly in maintaining disentangled representations and addressing human-like interference patterns to enhance video understanding systems.
🛠️ Research Methods:
– Introduction of M^3Eval, a comprehensive evaluation framework grounded in cognitive psychology, with carefully constructed tasks to assess different memory dimensions in multi-modal models.
💬 Research Conclusions:
– Multi-modal models show consistent weaknesses in maintaining disentangled representations and demonstrate interference patterns different from human memory. These models also have more reliable memory in the spatial domain rather than the temporal domain, with limited symbolic memory abilities. The findings emphasize the need for better memory mechanisms in multi-modal models.
👉 Paper link: https://huggingface.co/papers/2606.05008

5. Benchmarks are Not Enough: RAMP for Runtime Assessing of Agentic Models in Production Systems
🔑 Keywords: RAMP, software engineering agents, runtime assessment, compiler-construction workloads, failure propagation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective of this research is to develop the RAMP framework to provide a more realistic assessment of long-horizon software engineering agents, capturing the complexity of real-world production environments.
🛠️ Research Methods:
– The research utilizes RAMP, built on the YatCC platform, to introduce compiler-construction workloads with serial dependencies and toolchain interactions, assessing performance through a unified runtime assessment architecture.
💬 Research Conclusions:
– The findings reveal significant capability degradation in software engineering agents across serial workflows, highlighting systematic failure propagation and substantial resource inefficiencies, underlining the need for continuous, production-grounded evaluation methods.
👉 Paper link: https://huggingface.co/papers/2605.27492
6. Streaming Communication in Multi-Agent Reasoning
🔑 Keywords: StreamMA, multi-agent reasoning, latency, pipelining, step-level scaling law
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce StreamMA to enable efficient multi-agent reasoning by streaming intermediate results to improve latency and effectiveness.
🛠️ Research Methods:
– Utilization of a “generate-then-transfer” paradigm with formal analysis of stream, serial, and single protocols across multiple reasoning benchmarks and LLMs.
💬 Research Conclusions:
– StreamMA reduces latency and enhances effectiveness by leveraging reliable early steps and pipelining; shows significant performance improvement over baselines.
– A new “step-level scaling law” is discovered, enhancing both effectiveness and efficiency by increasing per-agent steps.
👉 Paper link: https://huggingface.co/papers/2606.05158

7. MMG2Skill: Can Agents Distill In-the-Wild Guides into Self-Evolving Skills?
🔑 Keywords: guide-to-skill learning, closed-loop framework, vision-language model, trajectory-level feedback, MMG2Skill
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to convert web-based procedural guides into executable skills to enhance agent performance in various tasks such as GUI control, gameplay, and card play.
🛠️ Research Methods:
– The MMG2Skill framework formalizes guide-to-skill learning by compiling guides into structured skills and refining them through closed-loop learning, leveraging a fixed vision-language model (VLM) agent, and trajectory-level root-cause feedback.
💬 Research Conclusions:
– The framework consistently outperforms baseline agents with substantial macro-average performance gains across different models and settings. Structured skill construction and trajectory-driven revisions are crucial for these improvements, and early stopping mechanisms can efficiently reduce performance regression in successful tasks.
👉 Paper link: https://huggingface.co/papers/2606.01993

8. MemTrain: Self-Supervised Context Memory Training
🔑 Keywords: Memory capabilities, Self-supervised training, Long-horizon language models, MemTrain, GRPO
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance the context-memory capability of long-horizon language model agents for improved downstream reasoning performance.
🛠️ Research Methods:
– Introduced MemTrain, a self-supervised training framework utilizing two proxy tasks over unlabeled Wikipedia corpora, coupled with optimization through GRPO.
💬 Research Conclusions:
– MemTrain framework significantly improves memory-intensive reasoning performance, achieving up to 17.67-point gains in benchmarks compared to direct task-specific post-training.
👉 Paper link: https://huggingface.co/papers/2606.03197

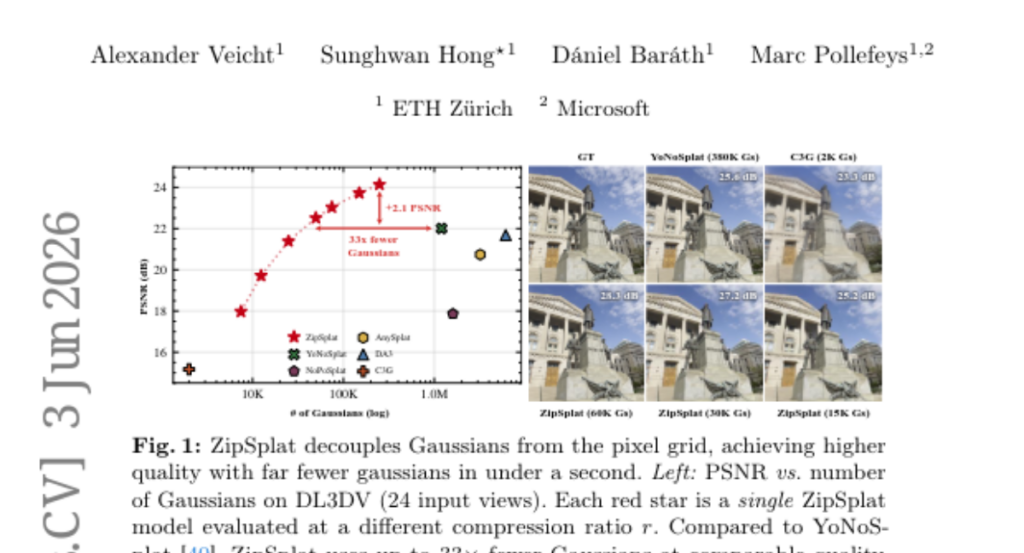
9. ZipSplat: Fewer Gaussians, Better Splats
🔑 Keywords: Token-based feed-forward, 3D Gaussian Splatting, Pose-free imaging, Multi-view backbone, K-means clustering
💡 Category: Computer Vision
🌟 Research Objective:
– To propose a new method, ZipSplat, that decouples 3D Gaussian placement from the pixel grid, enabling efficient scene reconstruction with fewer Gaussians and superior performance on pose-free imaging tasks.
🛠️ Research Methods:
– Utilizes a token-based feed-forward model with a multi-view backbone to extract dense visual tokens, compresses them using k-means clustering, refines tokens with cross- and self-attention, and decodes them into Gaussians with a lightweight MLP.
💬 Research Conclusions:
– ZipSplat sets a new state of the art in DL3DV and RealEstate10K benchmarks with significantly fewer Gaussians than previous methods, improving performance metrics by surpassing the best pose-free baseline by 2.1dB and 1.2dB PSNR respectively.
– It generalizes zero-shot to datasets like Mip-NeRF360 and ScanNet++, outperforming all comparable baselines.
👉 Paper link: https://huggingface.co/papers/2606.05102
10. AAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
🔑 Keywords: AAD-1, Asymmetric Adversarial Distillation, autoregressive, motion collapse, training instability
💡 Category: Generative Models
🌟 Research Objective:
– The main goal is to enhance one-step autoregressive image-to-video generation by resolving issues related to motion collapse and training instability while leveraging Asymmetric Adversarial Distillation.
🛠️ Research Methods:
– The research employs a novel framework, AAD-1, that introduces an asymmetric design between the generator and discriminator, along with a phased training strategy to maintain stability and prevent motion collapse.
💬 Research Conclusions:
– Extensive experiments on VBench confirm that AAD-1 delivers state-of-the-art results in one-step autoregressive video generation, achieving improved performance over current methods.
👉 Paper link: https://huggingface.co/papers/2606.03972

11. AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
🔑 Keywords: AutoLab, long-horizon iterative optimization, benchmark, persistent iteration, time awareness
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to evaluate the long-horizon iterative optimization capabilities of frontier models across diverse domains, focusing on the importance of persistence and time awareness over initial performance.
🛠️ Research Methods:
– The introduction of AutoLab as a new benchmark for ultra long-horizon closed-loop optimization with 36 tasks spanning four domains. This benchmark challenges models to improve from a suboptimal baseline under a strict time budget.
💬 Research Conclusions:
– AutoLab demonstrates that the key to success lies in an agent’s ability to persistently iterate, benchmark, and utilize empirical feedback. Time awareness and persistent iteration are crucial, as shown by the performance of claude-opus-4.6, while many other models underperform.
👉 Paper link: https://huggingface.co/papers/2606.05080

12. AUDITFLOW: Executable Symbolic Environments for Structured Financial Reporting Verification
🔑 Keywords: Language-model agents, AuditFlow, US-GAAP taxonomy, Evidence Verification
💡 Category: AI in Finance
🌟 Research Objective:
– The primary objective is to develop a framework, AuditFlow, for structured financial audit verification that separates adaptive search from deterministic verification.
🛠️ Research Methods:
– A graph-grounded multi-agent framework is proposed, utilizing a static US-GAAP taxonomy graph and a dynamic XBRL filing graph, enabling typed tool access for fact retrieval, taxonomy traversal, numerical checking, and rule evaluation.
💬 Research Conclusions:
– AuditFlow achieved 82.09% joint audit accuracy in tests with GPT-5.5, significantly outperforming existing baselines. The study demonstrated the necessity of a symbolic environment for reliable audit verification, as its removal drastically reduced accuracy.
👉 Paper link: https://huggingface.co/papers/2606.03031

13. GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
🔑 Keywords: GRAIL, 3D asset composition, sim-to-real transfer, humanoid robot, video foundation models
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective of this research is to enable effective sim-to-real transfer for robot control using diverse humanoid manipulation and locomotion data generated through 3D asset composition and video foundation models.
🛠️ Research Methods:
– The research utilizes a digital generation pipeline, GRAIL, which composes 3D assets, simulator-ready scenes, and integrates video foundation models to synthesize interactions. This setup allows for model-based object tracking and interaction-aware optimization without relying on physical setups.
💬 Research Conclusions:
– The study concludes that using GRAIL-generated data alone, task-general trackers can be trained and implemented successfully, achieving 84% real-world success on diverse object pick-up and 90% success on stair-climbing with the Unitree G1 humanoid robot.
👉 Paper link: https://huggingface.co/papers/2606.05160

14. WebRISE: Requirement-Induced State Evaluation for MLLM-Generated Web Artifacts
🔑 Keywords: WebRISE, MLLM-generated, Interaction Contract Graphs, user-intent transitions, implicit constraints
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research introduces WebRISE to evaluate web artifacts generated by MLLMs through interaction contracts capturing user intent transitions and requirement checks.
🛠️ Research Methods:
– WebRISE compiles task requirements into Interaction Contract Graphs that span multiple input modalities and include observable states, transitions, and DOM/visual assertions.
💬 Research Conclusions:
– WebRISE outperforms traditional methods in error detection, revealing significant model performance gaps. Even the strongest MLLMs show limited transition validity and requirement coverage, with video providing the strongest interaction signal.
👉 Paper link: https://huggingface.co/papers/2606.03220

15. KletterMix: Climbing Toward High-Quality German Pretraining Data
🔑 Keywords: KletterMix, German corpus, language model pretraining, translation quality, downstream evaluations
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce KletterMix, a high-quality German corpus for language model pretraining and assess its impact on German-language tasks.
🛠️ Research Methods:
– Development of KletterMix via translation of an English corpus while maintaining structure, metadata, and diversity.
– Evaluation through controlled pretraining and comparison to existing German corpora.
💬 Research Conclusions:
– KletterMix, by preserving much of the semantic and stylistic richness through careful translation, demonstrates measurable improvements in German-language downstream tasks, enhancing the German pretraining data ecosystem.
👉 Paper link: https://huggingface.co/papers/2606.03773

16. Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
🔑 Keywords: FiRe-OPD, On-Policy distillation, optimization stability, token selection, supervision signals
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance On-Policy Distillation (OPD) in large language models by introducing FiRe-OPD, a method that filters low-quality trajectories and applies soft reweighting to improve optimization stability and the selection of informative tokens.
🛠️ Research Methods:
– The proposed FiRe-OPD method involves filtering trajectories to eliminate low-quality samples and employing a soft-weighting mechanism to highlight informative tokens, contrasting with hard token selection, and is evaluated in various OPD settings including single and multi-teacher contexts.
💬 Research Conclusions:
– FiRe-OPD demonstrates superior performance in OPD optimization compared to recent token-level methods, achieving significant improvements in benchmarks such as AIME 2024 and Miner, and the method’s effectiveness is validated across different teaching scenarios.
👉 Paper link: https://huggingface.co/papers/2606.02684

17. MapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level Map Generation
🔑 Keywords: MapAgent, autonomous driving, vectorized mapping, constraint-aware reasoning, production automation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to develop an industrial-grade agentic architecture called MapAgent for automating the generation of specification-compliant lane maps, enhancing lane-level navigation for autonomous driving.
🛠️ Research Methods:
– MapAgent integrates a vectorization backbone with constraint-aware reasoning and deterministic map editing to produce lane maps. It employs a Judge-Planner-Worker loop for specification inspection and error correction.
💬 Research Conclusions:
– The integration of MapAgent into Baidu Maps has demonstrated its effectiveness, enabling lane-level map generation for over 360 cities with a production automation rate exceeding 95%.
👉 Paper link: https://huggingface.co/papers/2606.04513

18. Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
🔑 Keywords: Wide-baseline matching, multimodal large language models, ReasonMatch-Bench, Dynamic Correspondence Reinforcement Learning, data-generation pipeline
💡 Category: Computer Vision
🌟 Research Objective:
– To improve spatial reasoning in multimodal large language models through a systematic evaluation and training framework.
🛠️ Research Methods:
– Introduced ReasonMatch-Bench for testing wide-baseline matching capabilities.
– Developed a scalable data-generation pipeline to automatically extract training data from video-3D corpora.
– Proposed Dynamic Correspondence Reinforcement Learning to enhance training.
💬 Research Conclusions:
– Existing MLLMs struggle with fine-grained wide-baseline correspondence tasks.
– The proposed framework and methods significantly improve model performance on ReasonMatch-Bench and related benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.03577

19. Self-Distilled Policy Gradient
🔑 Keywords: Self-distillation, Policy-gradient, Reinforcement Learning, KL regularization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to improve the stability and performance of reinforcement learning by combining self-distillation with verifier advantages and KL regularization.
🛠️ Research Methods:
– It introduces the SDPG framework, which integrates on-policy self-distillation with a verifier-advantage approach and reference-policy KL regularization.
💬 Research Conclusions:
– Empirical results demonstrate that SDPG enhances stability and performance compared to existing baselines like RLVR and self-distillation.
👉 Paper link: https://huggingface.co/papers/2606.04036

20. Echo-Infinity: Learning Evolving Memory for Real-Time Infinite Video Generation
🔑 Keywords: Echo Infinity, evolving memory, autoregressive methods, Unified Relative RoPE, video diffusion transformers
💡 Category: Generative Models
🌟 Research Objective:
– To develop Echo Infinity, an autoregressive framework for real-time infinite video generation utilizing a learnable evolving memory and Unified Relative RoPE.
🛠️ Research Methods:
– Implementation of a dynamic and learnable memory system that abstracts and compresses any-length history at constant cost.
– Introduction of the Unified Relative RoPE Recipe to overcome finite RoPE constraints and improve training efficiency with video diffusion transformers.
💬 Research Conclusions:
– Echo Infinity achieves state-of-the-art performance in both short and long video generation, showcasing the potential for practical real-time infinite video generation.
👉 Paper link: https://huggingface.co/papers/2606.04527

21. ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
🔑 Keywords: ThoughtFold, Large Reasoning Models, redundant explorations, Chain-of-Thoughts, fine-grained preference learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Address over-thinking in Large Reasoning Models by eliminating redundant explorations in chain-of-thought reasoning processes using fine-grained preference learning.
🛠️ Research Methods:
– Utilize fine-grained preference learning and an introspective strategy to identify and penalize redundant explorations, using masked preference optimization to streamline reasoning paths.
💬 Research Conclusions:
– ThoughtFold significantly enhances efficiency by reducing token usage in reasoning models by approximately 56% while maintaining state-of-the-art accuracy.
👉 Paper link: https://huggingface.co/papers/2606.03503

22. Qwen-Image-Flash: Beyond Objective Design
🔑 Keywords: Few-step distillation, Visual generative models, Training recipe, Teacher guidance, Task mixture
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to optimize few-step distillation for visual generative models by exploring improved training recipes beyond conventional distillation objectives.
🛠️ Research Methods:
– The research investigates three critical factors: data composition, teacher guidance, and task mixture, using Qwen-Image-2.0 as a case study in text-to-image generation and instruction-guided image editing.
💬 Research Conclusions:
– The findings indicate that a holistic approach in the training pipeline, which includes well-structured data, effective teacher guidance, and a balanced task mixture, is crucial for enhancing the effectiveness of few-step distillation in visual generative models.
👉 Paper link: https://huggingface.co/papers/2606.03746

23. Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
🔑 Keywords: reward hacking, rubric-based reinforcement learning, LLM-as-a-Judge, CHERRL, controller hacking environment
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce CHERRL, a controlled environment for studying and analyzing reward hacking in rubric-based reinforcement learning using LLM judges.
🛠️ Research Methods:
– Utilize CHERRL to inject known biases into LLM-as-a-Judge, allowing stable reproduction and explicit observation of reward hacking, and precise identification of its onset.
💬 Research Conclusions:
– CHERRL provides a clean experimental testbed for exploring mechanisms and mitigations of reward hacking, facilitating automatic detection from training logs, and examining judge biases from discoverability and exploitability perspectives.
👉 Paper link: https://huggingface.co/papers/2606.04923

24. Cosmos 3: Omnimodal World Models for Physical AI
🔑 Keywords: Cosmos 3, omnimodal world models, mixture-of-transformers architecture, Physical AI, embodied agents
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Cosmos 3, an omnimodal world model designed to jointly process and generate different data types through a unified mixture-of-transformers architecture.
🛠️ Research Methods:
– Develop a unified framework that integrates various modalities, including language, image, video, audio, and action sequences, achieving state-of-the-art performance across multiple tasks.
💬 Research Conclusions:
– Cosmos 3 establishes a new benchmark for understanding and generation tasks and is recognized as the best open-source Text-to-Image, Image-to-Video, and policy models. The project’s resources are made available to the community to accelerate research in Physical AI.
👉 Paper link: https://huggingface.co/papers/2606.02800