AI Native Daily Paper Digest – 20260605

1. Code2LoRA: Hypernetwork-Generated Adapters for Code Language Models under Software Evolution
🔑 Keywords: Code2LoRA, LoRA adapters, hypernetwork framework, GRU hidden state, repository-specific
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce Code2LoRA, a hypernetwork framework designed for generating repository-specific LoRA adapters to enhance code language models.
🛠️ Research Methods:
– Created RepoPeftBench, a benchmark with static and evolution tracks, to evaluate performance on Python repositories against parameter-efficient fine-tuning baselines.
💬 Research Conclusions:
– Code2LoRA-Static and Code2LoRA-Evo achieved significant exact match rates in cross-repo and in-repo scenarios, demonstrating their effectiveness over existing LoRA fine-tuning methods.
👉 Paper link: https://huggingface.co/papers/2606.06492
2. TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
🔑 Keywords: TIDE, iterative discovery, thought templates
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to introduce TIDE, a framework for discovering hidden problems in context using templates and iterative methods.
🛠️ Research Methods:
– TIDE employs two mechanisms: iterative discovery for extending problem coverage and thought templates to anchor predictions within recognizable problem classes.
💬 Research Conclusions:
– TIDE demonstrates significant improvements in task coverage, problem identification, and resolution in personal workspaces and software repositories, surpassing traditional single-shot and parallel multi-agent approaches.
👉 Paper link: https://huggingface.co/papers/2606.04743

3. VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
🔑 Keywords: VideoKR, Knowledge-Intensive, Human-in-the-loop, Video Reasoning, Expert-Domain
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce VideoKR, a pioneering large-scale training dataset focused on enhancing knowledge- and reasoning-intensive video understanding.
🛠️ Research Methods:
– Developed a human-in-the-loop, skill-oriented example generation pipeline to cultivate progressively deeper video reasoning capabilities.
💬 Research Conclusions:
– Models post-trained on VideoKR showcase superior performance on knowledge-intensive video reasoning tasks while maintaining competitiveness in general video reasoning, emphasizing data design’s pivotal role.
👉 Paper link: https://huggingface.co/papers/2606.05259

4. RobotValues: Evaluating Household Robots When Human Values Conflict
🔑 Keywords: RobotValues, value-conflict scenarios, household robots, default value preferences, VLMs
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Evaluate household robot planners in value-conflict scenarios using the RobotValues benchmark to test their ability to prioritize human values over task completion.
🛠️ Research Methods:
– Utilization of LLM-assisted scenario generation, stakeholder-grounded value extraction, image generation, and automatic quality control to construct a benchmark with 10,000 scenarios.
💬 Research Conclusions:
– Vision-language models (VLMs) used in robotics display default value preferences and often fail to prioritize specific conflicting values when instructed, making incorrect decisions 80% of the time.
👉 Paper link: https://huggingface.co/papers/2606.03312

5. LoomVideo: Unifying Multimodal Inputs into Video Generation and Editing
🔑 Keywords: LoomVideo, video generation, video editing, Multimodal Large Language Model, Scale-and-Add conditioning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce LoomVideo, a 5B-parameter efficient architecture for unified video generation and editing.
🛠️ Research Methods:
– Utilizes a Multimodal Large Language Model and Deepstack injection for feature alignment.
– Implements Scale-and-Add conditioning to significantly reduce computational cost.
💬 Research Conclusions:
– LoomVideo achieves state-of-the-art performance with superior efficiency and speed, particularly excelling in e-commerce and fashion generation scenarios.
– The model provides a 5.41x acceleration in inference speed over similarly capable models.
👉 Paper link: https://huggingface.co/papers/2606.06042

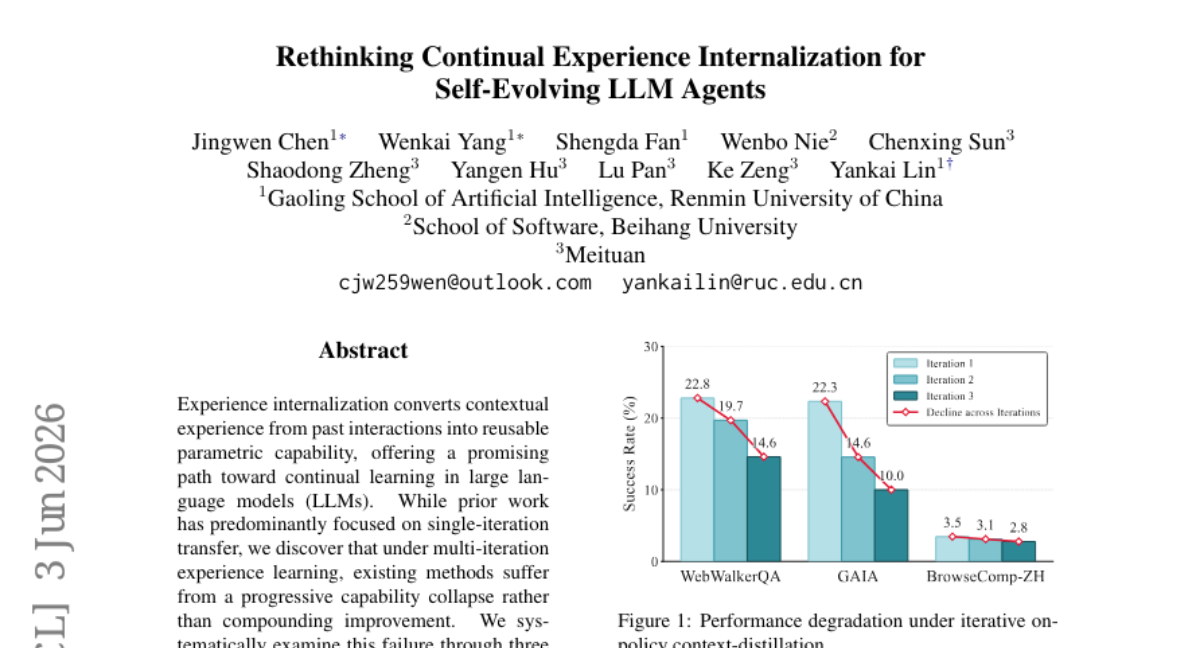
6. Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
🔑 Keywords: Experience internalization, Continual learning, Large language models, Capability collapse, Internalization regime
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the mechanisms of experience internalization to enable continual learning in large language models.
🛠️ Research Methods:
– Systematic examination of three dimensions: experience granularity, experience injection pattern, and internalization regime.
💬 Research Conclusions:
– Principle-level experience is more durable than instance-level experience for transferability.
– Step-wise injection is superior to global injection for aligning experiences with decision states.
– Off-policy context-distillation provides a more stable training signal than on-policy context-distillation for improving stability in experience internalization.
👉 Paper link: https://huggingface.co/papers/2606.04703
7. The Road Ahead in Autonomous Driving: The KITScenes Multimodal Dataset
🔑 Keywords: KITScenes Multimodal dataset, high-fidelity sensors, HD maps, embodied AI, geographic diversity
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to provide a comprehensive European driving dataset with high-fidelity sensors, including rich 3D maps and diverse urban environments, to advance embodied AI research.
🛠️ Research Methods:
– Utilizes a fully synchronized sensor suite comprising high-resolution cameras, long-range lidar, 4D imaging radar, and GNSS/INS for precise localization. The dataset features complete HD maps validated through autonomous driving trials.
💬 Research Conclusions:
– The KITScenes Multimodal dataset enriches existing datasets by offering unprecedented map completeness and geographic diversity, setting benchmarks in HD map construction, long-range depth estimation, novel view synthesis, and end-to-end driving.
👉 Paper link: https://huggingface.co/papers/2606.02956
8. LLMs Can Leak Training Data But Do They Want To? A Propensity-Aware Evaluation of Memorization in LLMs
🔑 Keywords: PropMe, memorization evaluation, SimpleTrace, propensity-aware framework, prefix-based capability attacks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate language model memorization by differentiating between forced reproduction capabilities and natural propensity using the PropMe framework.
🛠️ Research Methods:
– Introduces PropMe, a propensity-aware framework, and SimpleTrace, a lightweight tracing tool. Utilizes propensity-transformed metrics across open models and datasets, focusing on prefix-based capability attacks versus non-adversarial evaluations.
💬 Research Conclusions:
– The study concludes that large language models can reveal training data when directly elicited, but do so less frequently under non-adversarial circumstances. It also highlights the importance of assessing both worst-case extractability and ordinary leakage propensity for a comprehensive view of memorization capabilities.
👉 Paper link: https://huggingface.co/papers/2606.06286

9. MAOAM: Unified Object and Material Selection with Vision-Language Models
🔑 Keywords: unified vision-language model, object selection, material selection, interactive image editing, MAOAM
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce MAOAM, a unified selection framework to enhance object and material selection via text and click interactions, supporting diverse editing workflows with improved robustness.
🛠️ Research Methods:
– Utilizes a vision-language model (VLM) with a segmentation head to create pixel-accurate masks from user-defined prompts, aiming at both object and material selection.
💬 Research Conclusions:
– Demonstrated accurate and coherent selection capabilities in diverse scenarios, improving image editing workflows by integrating text and click-based interactions effectively.
👉 Paper link: https://huggingface.co/papers/2606.04880

10. Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
🔑 Keywords: Memory-augmented language models, Belief Entropy, Metacognitive Memory Policy Optimization, long-horizon tasks, epistemic uncertainty
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to improve performance in memory-augmented language models tackling long-horizon tasks by focusing on memory quality instead of solely outcome success.
🛠️ Research Methods:
– The study introduces Belief Entropy as a self-supervised proxy to assess uncertainty about latent task states.
– Metacognitive Memory Policy Optimization (MMPO) is proposed to provide memory-specific supervision and penalize summaries increasing epistemic uncertainty, departing from traditional outcome-based signals.
💬 Research Conclusions:
– Experiments demonstrate that MMPO consistently outperforms existing methods in diverse long-horizon tasks, maintaining high performance even in large contexts.
👉 Paper link: https://huggingface.co/papers/2605.30159

11. World-Language-Action Model for Unified World Modeling, Language Reasoning, and Action Synthesis
🔑 Keywords: World-language-action models, Autoregressive Transformer, Long-horizon task execution, Cross-embodiment learning, State-of-the-art
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to develop world-language-action (WLA) models, integrating textual instructions, images, and robot state predictions to efficiently execute long-horizon tasks and enhance cross-embodiment learning.
🛠️ Research Methods:
– An autoregressive (AR) Transformer backbone is used to predict future states by combining semantic-level textual intentions with fine-grained physical dynamics, enabled by a World Expert for supervising physical dynamics and meta-queries for world prediction impacting action generation.
💬 Research Conclusions:
– The WLA-0 prototype, with 2B active parameters, demonstrates state-of-the-art capabilities in multi-task and long-horizon learning in simulated and real-world environments, achieving notable success rates on RoboTwin2.0 Clean and RMBench tasks, and shows potential for learning novel tasks from cross-embodiment robot videos without action annotations.
👉 Paper link: https://huggingface.co/papers/2606.05979
12. AffordanceVLA: A Vision-Language-Action Model Empowering Action Generation through Affordance-Aware Understanding
🔑 Keywords: AffordanceVLA, Vision-Language-Action, perception-action mapping, affordance forecasting, robotic manipulation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– AffordanceVLA aims to establish a precise perception-action mapping by integrating structured affordance forecasting with Vision-Language models to enhance robotic manipulation.
🛠️ Research Methods:
– The framework utilizes a Mixture-of-Transformer architecture with specialized experts, combined with a three-stage training strategy and automated data augmentation to tackle data scarcity issues in robotic datasets.
💬 Research Conclusions:
– AffordanceVLA demonstrates strong performance in diverse manipulation scenarios through its spatially grounded and semantically conditioned affordance cues, bridging the gap between vision, language, and action.
👉 Paper link: https://huggingface.co/papers/2606.06155

13. MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
🔑 Keywords: MLEvolve, LLM-based, multi-agent framework, machine learning algorithm discovery, self-evolving
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce MLEvolve, an LLM-based self-evolving multi-agent framework designed for machine learning algorithm discovery to overcome existing limitations in long-horizon tasks.
🛠️ Research Methods:
– Utilizes Progressive MCGS to enhance search mechanisms with graph-based reference edges and an entropy-inspired progressive schedule.
– Implements Retrospective Memory for dynamic knowledge retrieval and reuse to facilitate agent evolution.
💬 Research Conclusions:
– MLEvolve exhibits state-of-the-art performance on MLE-Bench across various metrics and outperforms methods like AlphaEvolve in mathematical algorithm optimization tasks, showcasing strong cross-domain generalization.
👉 Paper link: https://huggingface.co/papers/2606.06473

14. SePO: Self-Evolving Prompt Agent for System Prompt Optimization
🔑 Keywords: Self-Evolving Prompt Optimization, evolutionary search, task agents, prompt optimization, fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance AI agent performance by jointly optimizing both task and prompt agent system prompts using a novel method called Self-Evolving Prompt Optimization (SePO).
🛠️ Research Methods:
– The study employs an evolutionary search strategy with a self-referential design, using a single prompt agent to improve both task agents’ system prompts and its own system prompt.
💬 Research Conclusions:
– Self-Evolving Prompt Optimization significantly outperforms existing methods across five different benchmarks, demonstrating an average accuracy improvement of 4.49 points over the Manual-CoT technique. The optimization skill gained from pre-training efficiently generalizes across various tasks beyond the pre-training mixture.
👉 Paper link: https://huggingface.co/papers/2606.04465

15. SEAOTTER: Sensor Embedded Autoencoding with One-Time Transcode for Efficient Reconstruction
🔑 Keywords: Cloud Robotics, Learned Latent, JPEG Compatibility, Asymmetric Autoencoders, SEAOTTER
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study presents a compression framework for cloud robotics that merges learned latent representations with standard JPEG compatibility to enhance encoding and decoding speed while maintaining high perceptual quality.
🛠️ Research Methods:
– Introduction of the SEAOTTER framework, which pairs a Sensor Embedded Autoencoder with a One-Time Transcode for Efficient Reconstruction, utilizing a learnable JPEG color and quantization transform to improve accuracy in various perception tasks.
💬 Research Conclusions:
– The proposed framework achieves significant improvements over AVIF, with 7 times faster encoding, 3.5 times faster decoding, and +8% ImageNet top-1 accuracy, all while preserving compatibility with existing JPEG infrastructure.
👉 Paper link: https://huggingface.co/papers/2606.03940

16. Regret Minimization with Adaptive Opponents in Repeated Games
🔑 Keywords: Repeated Policy Regret, adaptive opponents, game-theoretic, non-convex optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study focuses on minimizing regret in repeated games with adaptive opponents by introducing a new metric: Repeated Policy Regret.
🛠️ Research Methods:
– Identification of necessary conditions to achieve sublinear RP-Regret.
– Proposal of three algorithms designed for minimizing non-convex RP-Regret.
💬 Research Conclusions:
– Minimizing RP-Regret leads to finding better equilibria and more cooperative solutions in repeated games like Stag-Hunt.
👉 Paper link: https://huggingface.co/papers/2606.06486

17. Latent Reasoning with Normalizing Flows
🔑 Keywords: Latent reasoning, normalizing flows, chain-of-thought, probabilistic sampling, KV-cache decoding
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance large language models’ reasoning capabilities by integrating latent reasoning through normalizing flows without losing the benefits of autoregressive generation.
🛠️ Research Methods:
– The framework, called NF-CoT, uses normalizing flows to conduct intermediate computations in continuous states, maintaining compatibility with left-to-right generation and probabilistic sampling.
💬 Research Conclusions:
– NF-CoT has been shown to improve code-generation pass rates and reduce reasoning costs compared to explicit chain-of-thought methods and previous latent reasoning frameworks.
👉 Paper link: https://huggingface.co/papers/2606.06447

18. MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
🔑 Keywords: Mechanical engineering drawing, Multimodal Large Language Models, MechVQA, High-density visual question answering, Domain knowledge
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance understanding of mechanical engineering drawings using a specialized dataset and domain-specific model.
🛠️ Research Methods:
– Introduction of MechVQA dataset containing 3.3k images and 21k question-answer pairs.
– Development of MechVL model through a multi-stage training paradigm.
💬 Research Conclusions:
– MechVL model outperforms existing baselines by 7.57 percentage points, providing a reusable foundation for deploying MLLMs in mechanical design and inspection.
👉 Paper link: https://huggingface.co/papers/2605.30794

19. LLM Anonymization Against Agentic Re-Identification
🔑 Keywords: LLM-powered, anonymization, re-identification, contextual utility, adaptive privacy scope
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Develop AURA, a framework to balance privacy protection and utility retention in text anonymization using LLM-powered methods.
🛠️ Research Methods:
– Utilization of adaptive privacy scopes and mask-reconstruct methods evaluated against re-identification attacks from web-search agents and utility based on real-user interviews.
💬 Research Conclusions:
– AURA enhances the privacy-utility frontier by improving resistance to agentic re-identification while preserving contextual utility through adaptive privacy and mask-reconstruct techniques.
👉 Paper link: https://huggingface.co/papers/2605.30848

20. Video2LoRA: Parametric Video Internalization for Vision-Language Models
🔑 Keywords: Video2LoRA, Low-Rank Adaptation, video processing, vision-language models, inference cost
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The main objective is to enhance video processing efficiency in vision-language models by predicting Low-Rank Adaptation weights, thereby reducing computational costs while retaining video-faithful outputs.
🛠️ Research Methods:
– The introduction of Video2LoRA method involves a perceiver hypernetwork that reads intermediate representations from a frozen Vision-Language Model (VLM) to generate Low-Rank Adaptation adapters in a single forward pass.
💬 Research Conclusions:
– Video2LoRA achieves equivalent performance to direct video-in-context inference, reducing answer-time visual-token load and query TTFT significantly while being stable for extensive frame and pixel ranges.
👉 Paper link: https://huggingface.co/papers/2606.04351

21. Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
🔑 Keywords: Discrete-WAM, Autonomous Driving, Causal Reasoning, Discrete Tokens, Discrete Diffusion Framework
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce Discrete-WAM, a unified discrete latent vision-action world policy for autonomous driving, enabling compositional causal reasoning and counterfactual reasoning.
🛠️ Research Methods:
– Utilize aligned discrete tokens and a shared discrete diffusion framework for compositional generalization across diverse driving scenarios.
💬 Research Conclusions:
– Discrete-WAM achieves competitive performance on large-scale autonomous-driving benchmarks, supporting controllable generation and offering a principled path to more reliable decision-making.
👉 Paper link: https://huggingface.co/papers/2606.05645

22. Trust Region Q Adjoint Matching
🔑 Keywords: Off-policy reinforcement learning, Trust Region Q-Adjoint Matching, pretrained flow policies, projected dual descent, model collapse
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to address the instability in off-policy reinforcement learning by introducing Trust Region Q-Adjoint Matching (TRQAM) to ensure stable fine-tuning of pretrained flow policies.
🛠️ Research Methods:
– TRQAM uses projected dual descent to adaptively control the path-space KL divergence, and optimizes the trust-region parameter (λ) in stochastic optimal control dynamics to stabilize the learning process.
💬 Research Conclusions:
– Experiments on 50 OGBench tasks demonstrate that TRQAM consistently outperforms existing approaches in offline RL and offline-to-online RL, achieving a 68% success rate compared to a strong baseline of 46%.
👉 Paper link: https://huggingface.co/papers/2605.27079

23. Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
🔑 Keywords: Atomic Decomposition, Recombination, Verifiable Code Tasks, Reinforcement Learning, Large Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To propose the Atomic Decomposition and Recombination (ADR) framework for generating novel and challenging verifiable code tasks to enhance the scalability of Reinforcement Learning with Verifiable Rewards (RLVR) in Large Language Models.
🛠️ Research Methods:
– The ADR framework decomposes tasks into atomic elements and performs controlled recombination to produce new tasks, surpassing the limitations of previous heuristic approaches for data synthesis.
💬 Research Conclusions:
– ADR demonstrates excellent originality, difficulty, diversity, and test quality over existing methods and improves coding performance across RLVR in various domains such as algorithmic programming, tool usage, and data science.
👉 Paper link: https://huggingface.co/papers/2605.31058

24. Quality-Guided Semi-Supervised Learning for Medical Image Segmentation
🔑 Keywords: Semi-supervised learning, pseudolabels, segmentation quality, quality predictor, medical image segmentation
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop a quality-guided semi-supervised learning framework that enhances medical image segmentation by improving pseudolabel reliability and segmentation performance.
🛠️ Research Methods:
– Introduction of a dedicated quality predictor trained on variable-quality masks from synthetic corruptions and partially trained segmentation models.
– Integration of the quality predictor into SSL through quality-aware regularization loss and quality-based pseudolabel sample reweighting.
💬 Research Conclusions:
– Proposed method consistently improves over existing semi-supervised learning methods in medical image segmentation, validated through extensive experiments across five datasets and multiple architectures.
👉 Paper link: https://huggingface.co/papers/2606.01753

25. ForeSci: Evaluating LLM Agents for Forward-Looking AI Research Judgment
🔑 Keywords: LLM agents, forward-looking research, ForeSci, decision-making systems, AI domains
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduction of ForeSci, a benchmark aimed at evaluating the ability of LLM agents to make forward-looking research decisions based on historical evidence in AI domains.
🛠️ Research Methods:
– Creation of tasks derived from pre-cutoff taxonomy branches and use of specific answer-generation backbones preceding task cutoffs to enhance accuracy and traceability.
– Evaluation of native LLMs, Hybrid RAG, and research-agent adaptations across various backbones to test evidence organization and decision-making capabilities.
💬 Research Conclusions:
– Evidence organization improves traceability and factual support.
– The effectiveness of evidence organization depends significantly on the decision family, with a noted challenge of evidence-decision decoupling affecting research judgements.
👉 Paper link: https://huggingface.co/papers/2606.00644

26.

27. SABER: Benchmarking Operational Safety of LLM Coding Agents in Stateful Project Workspaces
🔑 Keywords: Large Language Models, Coding Agents, Environment-Aware Operational Safety, Safety Profiles, Harmful Safety-Violation Rate
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce SABER, a benchmark for evaluating the safety of large language models as coding agents in realistic project environments.
🛠️ Research Methods:
– SABER places models in realistic agent-style projects to assess safety based on the action sequence’s final environment state rather than binary prompt refusals.
💬 Research Conclusions:
– Even the best large language models have over a 54% harmful safety-violation rate, revealing current alignment deficiencies and distinct safety profiles across models.
👉 Paper link: https://huggingface.co/papers/2606.01317

28. BRepCLIP: Contrastive Multimodal Pretraining on BRep Primitives for CAD Understanding
🔑 Keywords: BRepCLIP, Multimodal Representation Learning, Contrastive Pretraining, CAD Models, Boundary Representations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce BRepCLIP, a framework for aligning boundary representation (BRep) geometry of CAD models with language and image embeddings using contrastive pretraining.
🛠️ Research Methods:
– Model CAD objects as sequences of face and edge tokens with discrete vocabularies for surface and curve geometry, augmented with spatial and semantic descriptors. Use a transformer encoder to aggregate these into a global BRep embedding aligned with CLIP’s text and image encoders.
💬 Research Conclusions:
– BRepCLIP achieves superior retrieval and classification performance over point-based methods, showing significant improvements in retrieval and classification scores across various datasets and proving effective as a CAD-aware similarity metric.
👉 Paper link: https://huggingface.co/papers/2606.05515

29. Is This Edit Correct? A Multi-Dimensional Benchmark for Reasoning-Aware Image Editing
🔑 Keywords: RE-Edit, image editing systems, reasoning dimensions, logical consistency, Diffusion-based image editing
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce RE-Edit, a benchmark for reasoning-aware image editing that evaluates systems across five reasoning dimensions: physical, environmental, cultural, causal, and referential.
🛠️ Research Methods:
– Development of a benchmark comprising 1,000 curated samples, each designed to test the logical consistency of image editing systems beyond visual plausibility.
– Evaluation of ten open-source and two commercial image editing models using dimension-aligned criteria for fine-grained analysis.
💬 Research Conclusions:
– Finding that even advanced image editing systems struggle with multi-dimensional reasoning despite high-quality visuals.
– Introduction of a lightweight reasoning-guided post-edit baseline, demonstrating the potential of explicit reasoning to improve model performance in a model-agnostic manner.
👉 Paper link: https://huggingface.co/papers/2606.05172

30. Multimodal Music Recommendation System using LLMs
🔑 Keywords: multimodal framework, session-based music recommendation, LLM-based sequential reasoning, audio and lyric embeddings, cross-modal integration
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance music recommendation accuracy by integrating audio, lyric, and semantic signals using a multimodal framework that employs LLM-based sequential reasoning.
🛠️ Research Methods:
– The study adopts a multimodal framework to enrich the LastFM-1K dataset with audio and lyric embeddings, LLM-generated semantic metadata, and listening completion ratios.
– The research leverages E4SRec, extending it with various item ID encoder backbones and LLM backbones, including SASRec, BERT4Rec, GRU4Rec, LLaMa-2-13B, Qwen2.5-7B-Instruct, and LLaMa-3-70B.
💬 Research Conclusions:
– The integration of content-based features significantly improves recommendation accuracy, demonstrating up to 95% improvement in Recall and 79% in NDCG.
– The study highlights challenges in cross-modal integration, noting that naive multimodal fusion does not always yield additive improvements.
– A large-scale multimodal benchmark for music recommendation is released.
👉 Paper link: https://huggingface.co/papers/2606.00125

31. The Shape of Addition: Geometric Structures of Arithmetic in Large Language Models
🔑 Keywords: Large Language Models, Arithmetic Fragility, Geometric Structures, Noisy Quantization Model, Geometric Slippages
💡 Category: Natural Language Processing
🌟 Research Objective:
– Analyze the geometric structures causing arithmetic fragility in Large Language Models (LLMs) and propose a new model to address these issues.
🛠️ Research Methods:
– Introduce and utilize the Noisy Quantization Model to explain arithmetic errors in LLMs and employ geometric frameworks to detect and correct quantization failures during inference.
💬 Research Conclusions:
– Identified and explained the Iso-Raw-Sum Trajectory (IRST) as a key structure in arithmetic fragility, validating the insights through geometric consistency checks that successfully detect and correct arithmetic errors.
👉 Paper link: https://huggingface.co/papers/2606.03645

32. Absorbing Complexity: An Interaction-Native Knowledge Harness for Financial LLM Agents
🔑 Keywords: Financial AI agents, InKH, knowledge management, temporal memory, AI Native
💡 Category: AI in Finance
🌟 Research Objective:
– The study introduces the Interaction-native Knowledge Harness (InKH) architecture to embed complexity within financial AI agents, reducing the need for users to manage this complexity.
🛠️ Research Methods:
– Utilized a controlled synthetic benchmark with 24 random seeds, 4 rounds, and 80 episodes per round, comparing InKH against 6 baselines in 46,080 evaluations.
💬 Research Conclusions:
– InKH significantly reduces latency, token cost, and stale-knowledge usage, while improving task quality and traceability, demonstrating that system-absorbed complexity enhances financial AI agent efficacy.
👉 Paper link: https://huggingface.co/papers/2606.01886

33. Benchmark Everything Everywhere All at Once
🔑 Keywords: Automated benchmark creation, LLMs, scalability, domain-specific reasoning, Benchmark Agent
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Develop an automated system, Benchmark Agent, for creating diverse evaluation datasets to facilitate continuous model assessment.
🛠️ Research Methods:
– The framework encompasses user query analysis, subtask design, data annotation, and quality control. Evaluations include human assessments and consistency checks.
💬 Research Conclusions:
– Benchmark Agent produces high-quality benchmarks with minimal human intervention and highlights weaknesses in current models, particularly in domain-specific reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2606.06462

34. AURA: Intent-Directed Probing for Implicit-Need Surfacing in Situated LLM Agents
🔑 Keywords: Intent Inference, Implicit Needs, Gap Scoring, Tool Usage, Probe Consumption
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Enhance query answering by estimating implicit needs and optimizing tool usage through an intent inference step.
🛠️ Research Methods:
– Incorporate an inference step that produces an IntentFrame to estimate implicit needs.
– Utilize gap scoring to control per-query probe budget and tool selection.
– Benchmark with a 100-query four-scene implicit-intent dataset.
💬 Research Conclusions:
– AURA achieves improved implicit-need coverage compared to standard approaches, with significant gains across multiple scenes.
– The approach reduces probe consumption and maintains privacy compliance on factual lookups.
– The improvement is attributed to gap calibration rather than answer memorization.
👉 Paper link: https://huggingface.co/papers/2606.05557

35. EvoDS: Self-Evolving Autonomous Data Science Agent with Skill Learning and Context Management
🔑 Keywords: EvoDS, Autonomous Skill Acquisition, Adaptive Context Compression, Reinforcement Learning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to enhance automated data science capabilities by introducing a self-evolving autonomous data science agent, EvoDS, which utilizes skill acquisition and adaptive context management.
🛠️ Research Methods:
– Implemented two strategies: Autonomous Skill Acquisition (ASA) and Adaptive Context Compression (ACC), within a two-stage multi-agent training scheme, leveraging reinforcement learning principles to improve context management and skill synthesis.
💬 Research Conclusions:
– EvoDS demonstrates a significant performance improvement, outperforming state-of-the-art data science agents by an average of 28.9% across various benchmarks and eliminating out-of-token failures.
👉 Paper link: https://huggingface.co/papers/2606.03841

36. Revising Context, Shifting Simulated Stance: Auditing LLM-Based Stance Simulation in Online Discussions
🔑 Keywords: LLM-based stance simulation, context sensitivity, counterfactual context revision, multimodal approaches
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate how Large Language Models (LLMs) simulate social media user stances, focusing on context sensitivity in counterfactual scenarios.
🛠️ Research Methods:
– Applied controlled revision strategies to both text-only and multimodal conversational contexts to simulate stance changes.
– Evaluated the effectiveness of these strategies using metrics such as average directional stance shift and stance transition rate.
💬 Research Conclusions:
– Both text-only and multimodal approaches exhibit robust stance transitions, highlighting the importance and complexity of context sensitivity in LLM-based stance simulations.
– The study provides a framework for understanding these simulations, bringing attention to both the potential and risks of using LLMs for simulating opinion dynamics online.
👉 Paper link: https://huggingface.co/papers/2606.06443

37. AdaCodec: A Predictive Visual Code for Video MLLMs
🔑 Keywords: AdaCodec, Video MLLMs, Visual Tokens, Inter-frame Changes, Predictive Visual Code
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces AdaCodec, a system designed to reduce redundancy in video encoding by selectively transmitting full visual tokens only when scene prediction fails.
🛠️ Research Methods:
– AdaCodec operates by first sending a full reference frame when the scene cannot be predicted well from prior context, otherwise it encodes compact inter-frame changes.
💬 Research Conclusions:
– AdaCodec significantly outperforms a baseline model by improving efficiency in visual token usage and reducing time-to-first-token from 9.26s to 1.62s across multiple benchmarks, even at reduced visual-token budgets.
👉 Paper link: https://huggingface.co/papers/2606.02569

38. Flash-WAM: Modality-Aware Distillation for World Action Models
🔑 Keywords: Flash-WAM, Modality-aware, World-action models, Real-time inference, Consistency function
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study introduces Flash-WAM, a modality-aware step-distillation framework to enhance World-action models (WAMs) for real-time inference by addressing inconsistencies across noise regimes in video and action streams.
🛠️ Research Methods:
– The paper employs a step-distillation process inspired by consistency distillation, utilizing different parametrization techniques (linear-gradient-scaling and variance-preserving) to optimize video and action streams’ noise conditions.
💬 Research Conclusions:
– Flash-WAM significantly reduces latency and maintains high task success rates in simulation benchmarks, enabling real-time inference on platforms like RoboTwin 2.0 and improving performance on real-world tasks compared to naive consistency distillation.
👉 Paper link: https://huggingface.co/papers/2606.05254

39. Towards Truly Multilingual ASR: Generalizing Code-Switching ASR to Unseen Language Pairs
🔑 Keywords: Automatic Speech Recognition, code-switching ASR, synthetic CS speech generation, model merging, domain generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the generalization capabilities of code-switching ASR models across unseen language pairs using model merging and domain generalization methods.
🛠️ Research Methods:
– The study employed model merging and domain generalization techniques to test the transferability of bilingual code-switching capabilities to new language pairs.
💬 Research Conclusions:
– Merged bilingual CS-ASR models showed modest generalization to unseen language pairs, indicating limited transferability of bilingual CS capabilities.
👉 Paper link: https://huggingface.co/papers/2606.05846

40. Learning Geometric Representations from Videos for Spatial Intelligent Multimodal Large Language Models
🔑 Keywords: GeoVR, 3D awareness, geometric knowledge distillation, semantic latent space, spatial intelligence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– GeoVR aims to enhance multimodal large language models (MLLMs) by introducing 3D awareness through a novel framework that restructures their semantic latent space using geometric knowledge from 3D foundation models.
🛠️ Research Methods:
– The framework utilizes a multi-objective learning strategy employing four geometric targets, including camera pose estimation, dense depth map regression, metric scale factor prediction, and multi-scale 3D feature distillation, to develop strong 3D understanding.
💬 Research Conclusions:
– GeoVR, through extensive experiments on spatial reasoning benchmarks, demonstrates state-of-the-art performance and establishes a new paradigm in endowing foundation models with spatial intelligence.
👉 Paper link: https://huggingface.co/papers/2606.05833

41. Towards One-to-Many Temporal Grounding
🔑 Keywords: One-to-Many Temporal Grounding, Temporal Grounding, Count Accuracy, Effective Temporal F1, Chain-of-Thought reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to address the challenge of One-to-Many Temporal Grounding by introducing a comprehensive benchmark, novel reward functions, and improved policy optimization.
🛠️ Research Methods:
– Establishes the first comprehensive benchmark for One-to-Many Temporal Grounding (OMTG) with new evaluation metrics like Count Accuracy and Effective Temporal F1.
– Develops a high-quality OMTG dataset with 56k samples and novel temporal and caption reward functions utilizing Chain-of-Thought reasoning for policy optimization.
💬 Research Conclusions:
– The proposed model achieves a new state-of-the-art Effective Temporal F1 of 43.65% on the OMTG benchmark, outperforming previous models by significant margins.
👉 Paper link: https://huggingface.co/papers/2606.06294

42. Imagine Before You Predict: Interleaved Latent Visual Reasoning for Video Event Prediction
🔑 Keywords: Future-L1, Video event prediction, Latent visual reasoning, Autoregressive decoding, State-of-the-art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Future-L1 is designed to improve video event prediction by maintaining visual semantics in latent space during autoregressive decoding, aiming for enhanced prediction accuracy.
🛠️ Research Methods:
– The Future-L1 framework alternates between language tokens and continuous latent visual spans.
– Constructs Future-L1-50K dataset and employs LA-DAPO, a latent-aware RL objective with outcome-contrastive and temporal-diversity rewards, to optimize latent trajectories.
💬 Research Conclusions:
– Future-L1 achieves state-of-the-art results, significantly improving benchmark scores on FutureBench and TwiFF-Bench, demonstrating the benefits of preserving visual semantics in latent space rather than converting all reasoning into text.
👉 Paper link: https://huggingface.co/papers/2606.05769

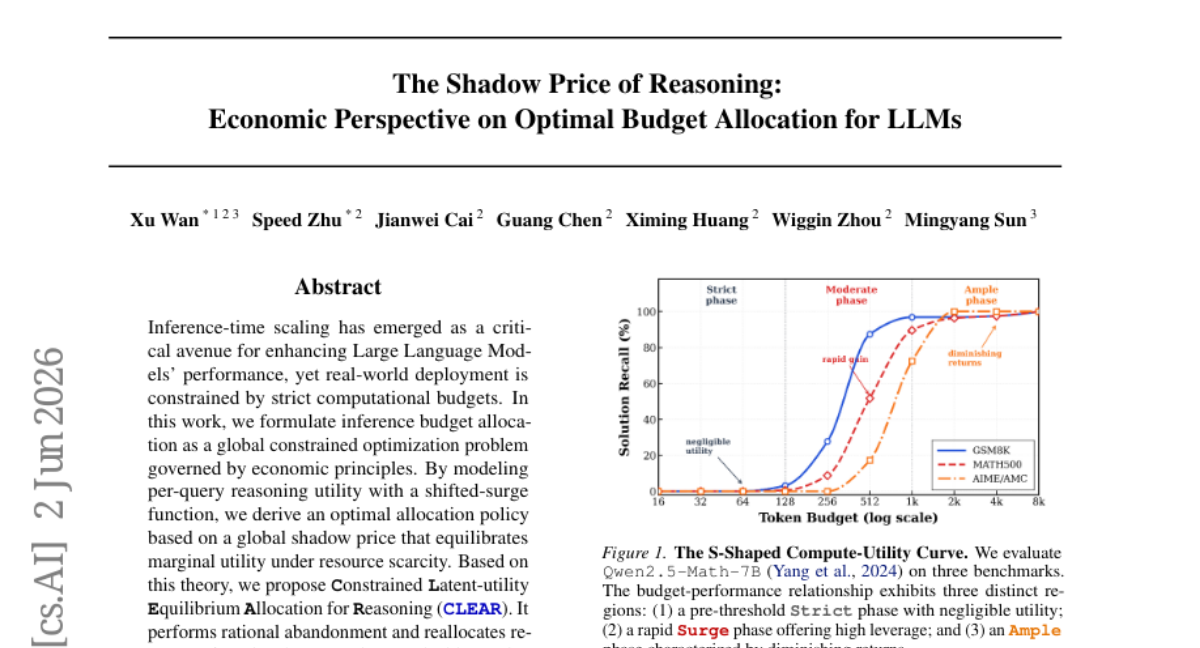
43. The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
🔑 Keywords: Inference-time scaling, Large Language Models, constrained optimization, economic principles, global shadow price
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance performance in resource-constrained environments by improving inference-time scaling for Large Language Models through a novel economic principle-based optimization strategy.
🛠️ Research Methods:
– The paper formulates inference budget allocation as a global constrained optimization problem, employing economic principles and modeling per-query reasoning utility with a shifted-surge function to derive an optimal allocation policy.
💬 Research Conclusions:
– The proposed Constrained Latent-utility Equilibrium Allocation for Reasoning (CLEAR) strategy reallocates resources to solvable queries, significantly improving the Pareto frontier of token cost versus mean accuracy. In resource-scarce regimes, CLEAR enhances global accuracy up to 3 times compared to uniform allocation.
👉 Paper link: https://huggingface.co/papers/2606.03092
44. OPRD: On-Policy Representation Distillation
🔑 Keywords: On-Policy Representation Distillation, hidden-state space, sampling variance, training efficiency
💡 Category: Machine Learning
🌟 Research Objective:
– Improve the traditional on-policy distillation by aligning student and teacher representations in the hidden-state space to reduce variance and improve training efficiency.
🛠️ Research Methods:
– Introduce On-Policy Representation Distillation (OPRD) that aligns student and teacher representations in hidden-state space, bypassing the LM head and providing richer per-layer structural information.
💬 Research Conclusions:
– OPRD closes the student-teacher gap effectively, trains 1.44x faster, and uses 54% less memory than existing top-k OPD methods.
👉 Paper link: https://huggingface.co/papers/2606.06021

45. Unsupervised Skill Discovery for Agentic Data Analysis
🔑 Keywords: DataCOPE, data-analytic agent, skill discovery, Adaptive Checklist Verifier, Answer Agreement Verifier
💡 Category: Machine Learning
🌟 Research Objective:
– The main objective of the research is to develop DataCOPE, an unsupervised framework that discovers reusable data-analysis skills to improve the performance in report-style and reasoning-style tasks.
🛠️ Research Methods:
– DataCOPE utilizes verifier-guided exploration, deriving verifier signals from exploration trajectories to evaluate quality and agreement. It involves a Data-Analytic Agent for trajectory generation, an Unsupervised Verifier for signal extraction, and a Skill Manager for contrastive skill distillation. The framework is instantiated with an Adaptive Checklist Verifier for report-style analysis and an Answer Agreement Verifier for reasoning-style analysis.
💬 Research Conclusions:
– DataCOPE consistently enhances performance over baseline models, achieving an average improvement in mean score by 9.71% for report-style tasks and 32.30% for reasoning-style tasks across various model settings.
👉 Paper link: https://huggingface.co/papers/2606.06416

46. Dream.exe: Can Video Generation Models Dream Executable Robot Manipulation?
🔑 Keywords: Video generation models, robotic manipulation, physics simulator, trajectory fidelity, execution success
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To evaluate video generation models on their ability to reflect physical reality through robotic manipulation tasks, and assess if visual quality predicts executable motion accuracy.
🛠️ Research Methods:
– Introduce Dream.exe, an evaluation framework with a video-to-execution pipeline to assess the execution ability of videos generated for robotic tasks in a physics simulator.
💬 Research Conclusions:
– Several models achieved measurable execution success, indicating that generative priors learned from large datasets may contain meaningful physical knowledge, although visual quality does not reliably predict executability.
👉 Paper link: https://huggingface.co/papers/2606.04811

47. Complexity-Balanced Diffusion Splitting
🔑 Keywords: Complexity-Balanced Splitting, generative capacity, temporal capacity allocation, diffusion timeline, synthesis quality
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to improve synthesis quality in generative models without increasing inference costs by introducing Complexity-Balanced Splitting (CBS), which allocates generative capacity across specialized sub-networks based on local complexity measures.
🛠️ Research Methods:
– CBS divides the diffusion timeline into segments with equal approximation burden using two monitor functions: a spatial measure based on Dirichlet energy and a geometric measure based on sampling trajectories’ acceleration. A lightweight auxiliary model estimates local complexity profiles to optimize temporal partitioning.
💬 Research Conclusions:
– CBS consistently enhances synthesis quality across various architectures and datasets, achieving a ~35% improvement in FID on SiT-XL with CFG compared to naive temporal partitioning, without additional inference cost.
👉 Paper link: https://huggingface.co/papers/2606.06477

48. Personal AI Agent for Camera Roll VQA
🔑 Keywords: Conversational AI, Visual Question Answering, Hierarchical Memory, Personal Camera Roll
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To develop a Conversational AI agent for answering visual questions using a personal camera roll with hierarchical memory and specialized tools.
🛠️ Research Methods:
– Creation and manual annotation of a dataset named camroll containing 50 users, 31,476 images, and 2,500 QA pairs to support real-world usage.
💬 Research Conclusions:
– The camroll-agent demonstrates superior performance in long-context understanding compared to existing baselines, indicating the need for different approaches in AI agents for personalized visual memory versus textual memory.
👉 Paper link: https://huggingface.co/papers/2606.05275

49. Reinforcement Learning Elicits Contextual Learning of Unseen Language Translation
🔑 Keywords: Reinforcement learning, Large language models, Zero-shot transfer, Meta-skill, Linguistic context
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance the ability of large language models to translate unseen languages by utilizing in-context linguistic knowledge instead of memorizing specific languages.
🛠️ Research Methods:
– The study employs a reinforcement learning approach using a surface-level translation metric, chrF, as the reward to train models on unseen language translation.
💬 Research Conclusions:
– The reinforcement learning-trained models successfully leverage linguistic context, outperforming in-context learning and supervised fine-tuning, and potentially apply RL to tasks beyond traditional reasoning such as language learning from context.
👉 Paper link: https://huggingface.co/papers/2606.06428

50. AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
🔑 Keywords: AdaPlanBench, adaptive planning, Large Language Model, dual constraints, interactive benchmark
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces AdaPlanBench, a benchmark for evaluating Large Language Models (LLMs) on their capacity to adaptively plan and re-plan under progressively revealed world and user constraints.
🛠️ Research Methods:
– Utilizes a set of 307 household tasks and a scalable constraint construction pipeline to augment each task with dual constraints.
– LLM agents interact through a multi-turn protocol where constraints are revealed only when violated, requiring iterative plan revisions.
💬 Research Conclusions:
– Experiments with ten leading LLMs indicate that adaptive planning under dual constraints is challenging, with a maximum accuracy of 67.75%.
– Performance is particularly degraded by user constraints and is affected by weaker physical grounding and reduced effectiveness.
👉 Paper link: https://huggingface.co/papers/2606.05622

51. ArcANE: Do Role-Playing Language Agents Stay in Character at the Right Time?
🔑 Keywords: Role-playing language agents, ArcANE, Character Arc, Narrative Evaluation, psychological trajectory
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to develop and evaluate benchmarks for Role-playing language agents that focus on dynamic character development and psychological trajectory alignment rather than static factual recall.
🛠️ Research Methods:
– Introduced ArcANE, a benchmark evaluating character development across 17 novels and 80 principal characters, using an approach that segments narratives into phases along a psychological axis to test model responses.
💬 Research Conclusions:
– ArcANE-conditioned models demonstrate superior performance compared to other context strategies, especially in scenarios unexplored in source texts, with fine-tuned models (ArcANE-8B/32B) further enhancing performance outside source text contexts.
👉 Paper link: https://huggingface.co/papers/2606.05553
