AI Native Daily Paper Digest – 20260609

1. SWE-Explore: Benchmarking How Coding Agents Explore Repositories
🔑 Keywords: SWE-Explore, coding agents, repository exploration, line budget, agentic exploration
💡 Category: AI Systems and Tools
🌟 Research Objective:
– SWE-Explore introduces a benchmark to assess the repository exploration capabilities of coding agents, focusing on ranked lists of code within line budgets to surpass traditional retrieval methods.
🛠️ Research Methods:
– The study evaluates 848 issues across 10 programming languages and 203 repositories, emphasizing metrics like coverage, ranking, and context-efficiency, derived from agent trajectories.
💬 Research Conclusions:
– Agentic explorers demonstrate superior performance compared to classical retrieval methods, notably in line-level coverage and efficient ranking, which differentiate state-of-the-art explorers.
👉 Paper link: https://huggingface.co/papers/2606.07297

2. Latent Spatial Memory for Video World Models
🔑 Keywords: Video world models, Latent spatial memory, Diffusion latent space, End-to-end video generation
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce latent spatial memory for video world models to eliminate pixel-space reconstruction overhead.
🛠️ Research Methods:
– Implement a framework called Mirage that constructs 3D memory directly in diffusion latent space through depth-guided back-projection and novel view synthesis.
💬 Research Conclusions:
– The proposed method achieves up to 10.57 times faster video generation and reduces memory footprint by 55 times compared to traditional methods, achieving state-of-the-art performance on benchmarks like WorldScore and RealEstate10K.
👉 Paper link: https://huggingface.co/papers/2606.09828
3. Agents’ Last Exam
🔑 Keywords: AI agents, real-world tasks, industry clusters, task taxonomy, living benchmark
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces Agents’ Last Exam (ALE), a benchmark tailored to evaluate AI agents on long-term, economically valuable real-world tasks that cover 13 industry clusters and over 1,000 tasks.
🛠️ Research Methods:
– ALE was developed in collaboration with over 250 industry experts, structured around a task taxonomy with 55 subfields, and designed to continuously grow with new workflows and industries.
💬 Research Conclusions:
– Current evaluation results show a significant gap between AI benchmark performance and real-world deployment, with an average full pass rate of only 2.6%. ALE is intended to bridge this gap by offering a more practical measure of AI impact on GDP-relevant tasks.
👉 Paper link: https://huggingface.co/papers/2606.05405

4. FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
🔑 Keywords: Lookahead Sparse Attention, Neural Memory Indexer, KV Cache, FlashMemory, Dual-Encoder Architecture
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the GPU memory bottleneck caused by conventional LLMs during decoding by introducing Lookahead Sparse Attention (LSA) empowered by a Neural Memory Indexer.
🛠️ Research Methods:
– The LSA technique involves proactive management of the KV cache by predicting future context demands.
– Utilizes a decoupled training strategy with a standard dual-encoder architecture, trained independently using standard retrieval training frameworks.
💬 Research Conclusions:
– The proposed LSA approach significantly reduces GPU memory usage for long-context tasks, compressing the average physical KV cache footprint to 13.5% compared to the full-context baseline.
– Maintains or slightly improves downstream accuracy, achieving a +0.6% margin on average and reducing KV cache overhead by over 90% at extreme scales without impacting reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2606.09079

5. Human Psychometric Questionnaires Mischaracterize LLM Behavior
🔑 Keywords: LLM behavior, real-world interactions, generation-based profiling, psychometric questionnaires, generation probabilities
💡 Category: Natural Language Processing
🌟 Research Objective:
– To determine the reliability of human psychometric questionnaires in predicting LLM behavior during everyday user interactions.
🛠️ Research Methods:
– Comparison of LLM value and personality profiles derived from Likert self-reports and generation probabilities over value-laden responses to user queries.
💬 Research Conclusions:
– Psychometric questionnaires are insufficient for predicting LLM behavior as they fail to replicate realistic user query responses, while generation-based profiling provides a more accurate understanding.
👉 Paper link: https://huggingface.co/papers/2509.10078

6. End-to-End Context Compression at Scale
🔑 Keywords: Latent Context Language Models, Compression Ratios, Encoder-decoder Compression, Architecture Search, Pre-training
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance encoder-decoder compression techniques through architectural search and extensive pre-training to develop Latent Context Language Models (LCLMs) that efficiently manage long contexts with improved performance and memory usage compared to traditional KV cache methods.
🛠️ Research Methods:
– The authors conducted an architecture search and pre-trained various encoder-decoder model variants from scratch to determine optimal design and training strategies. They introduced LCLMs with pre-trained encoder-decoder models at different compression ratios of 1:4, 1:8, and 1:16 on over 350B tokens.
💬 Research Conclusions:
– The LCLMs effectively enhance the Pareto frontier of general-task performance, compression speed, and memory usage. They serve as efficient backbones for long-horizon agents, facilitating skim through compressed contexts and adaptive expansion of relevant segments when needed.
👉 Paper link: https://huggingface.co/papers/2606.09659

7. A Geometric Account of Activation Steering through Angle-Norm Decomposition
🔑 Keywords: hidden-state norm, angular structure, spherical steering, activation steering, language models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to challenge the notion that hidden-state norms carry concept-relevant information in language models and to understand how concepts are represented through angular structures and norms.
🛠️ Research Methods:
– Conducted a controlled empirical study to explore the roles of angular and radial components by comparing different steering methods in language models.
💬 Research Conclusions:
– Findings indicate concepts are mainly represented through angular structures, yet the hidden-state norm is crucial for stability and effectiveness in steering methods. The study suggests that activation steering should be parameterized by angular and radial components for better interpretability and performance.
👉 Paper link: https://huggingface.co/papers/2606.06735

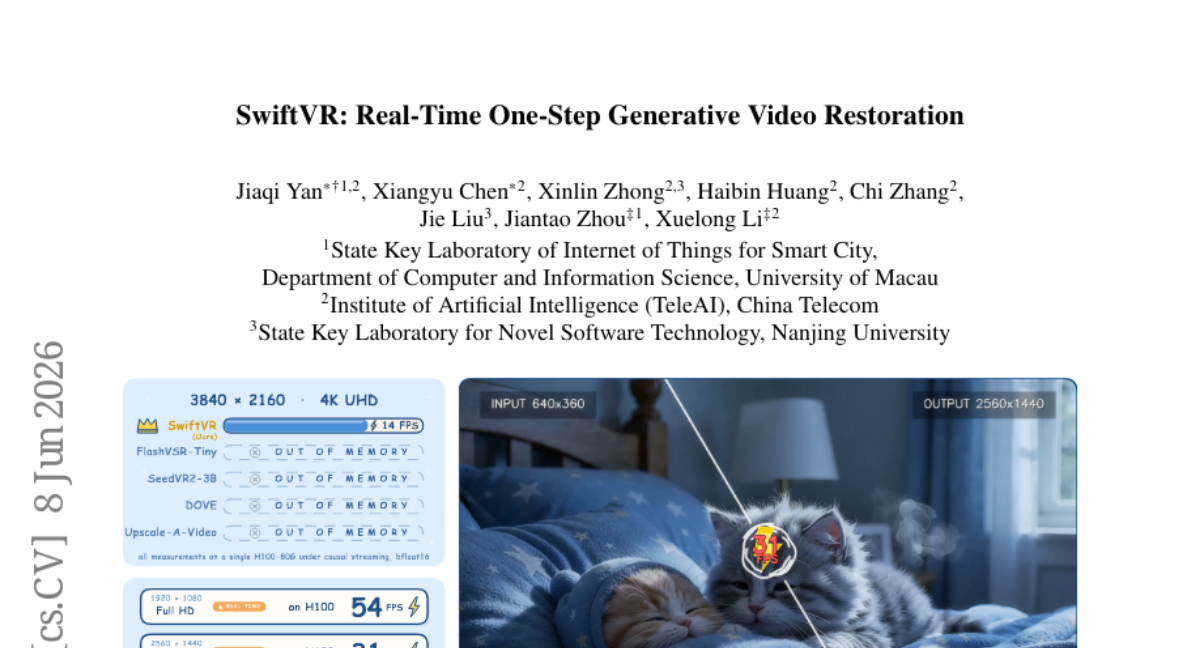
8. SwiftVR: Real-Time One-Step Generative Video Restoration
🔑 Keywords: real-time video restoration, consumer GPUs, efficient attention mechanisms, lightweight autoencoding, causal chunk-wise protocol
💡 Category: Generative Models
🌟 Research Objective:
– To enable real-time video restoration on consumer GPUs achieving high frame rates at 4K resolution through efficient attention mechanisms and lightweight autoencoding.
🛠️ Research Methods:
– Utilization of mask-free shifted-window self-attention for efficient spatial window processing and lightweight restoration-aware autoencoding for fast, quality-preserving chunk-wise decoding.
💬 Research Conclusions:
– SwiftVR sustains significant frame rates on high-resolution settings and is the first generative VR model enabling real-time 1080p streaming on consumer-grade GPUs, ensuring strong no-reference perceptual quality with low inference cost.
👉 Paper link: https://huggingface.co/papers/2606.09516
9. Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders
🔑 Keywords: Hallucinations, Whisper ASR, Sparse AutoEncoder, Activation-space steering, SAE latent-space steering
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to detect and reduce hallucinations in Whisper ASR using internal representations from audio encoder activations and Sparse AutoEncoder latents.
🛠️ Research Methods:
– The research involves extracting audio encoder activations and evaluating two representation spaces: raw Whisper activations and Sparse AutoEncoder latents. Two strategies are proposed for steering: activation-space steering and SAE latent-space steering.
💬 Research Conclusions:
– The results show a remarkable reduction in hallucination rates, from 72.63% to 14.11% for Whisper small and from 86.88% to 27.33% for Whisper large-v3, with minimal transcription degradation, demonstrating the effectiveness of the proposed strategies.
👉 Paper link: https://huggingface.co/papers/2606.07473

10. DEI: Diversity in Evolutionary Inference for Quality-Diversity Search
🔑 Keywords: Heterogeneous Large Language Models, Evolutionary Inference, Quality-Diversity, Mutation Operators, Cross-Model Adversarial Pressure
💡 Category: Generative Models
🌟 Research Objective:
– To showcase how using heterogeneous large language models as mutation operators in a distributed Quality-Diversity search framework can enhance evolutionary inference.
🛠️ Research Methods:
– Implemented DEI, a distributed Quality-Diversity framework that utilizes heterogeneous LLMs for mutation operations, extending the Digital Red Queen framework for cross-model competition and robustness.
💬 Research Conclusions:
– DEI’s use of model diversity significantly improves performance over homogeneous setups, demonstrated by higher QD-Scores and coverage in the Core War domain. This highlights the importance of model diversity as opposed to mere parallelism in distributed LLM-based QD search.
👉 Paper link: https://huggingface.co/papers/2605.27130

11. SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
🔑 Keywords: SlimSearcher, Pareto-efficient trajectory filtering, Adaptive Reward Shaping, Reinforcement Learning, computational efficiency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper introduces SlimSearcher, a framework designed to improve the efficiency of deep research agents by balancing the trade-off between computational costs and accuracy.
🛠️ Research Methods:
– The framework employs Pareto-efficient trajectory filtering during Supervised Fine-Tuning and Adaptive Reward Shaping during Reinforcement Learning to enhance efficiency and accuracy.
💬 Research Conclusions:
– Experiments on benchmarks such as GAIA, BrowseComp, and XBenchDeepSearch show that SlimSearcher can reduce tool-call rounds by 17%-58% while maintaining or enhancing accuracy.
👉 Paper link: https://huggingface.co/papers/2606.07074

12. Liberating LLM Capabilities in Full-Duplex Speech Models
🔑 Keywords: tri-channel speech interface, full-duplex interaction, Listen-Write-Speak, text-first paradigm, autoregressive LLM
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The paper proposes a text-first tri-channel speech interface that emphasizes the importance of visible text output alongside spoken responses for real-time and structured conversational tasks.
🛠️ Research Methods:
– Introduces the Listen-Write-Speak (LWS) paradigm using an autoregressive LLM to handle audio, text, and speech concurrently with a shared causal attention context, leveraging a Token Schema without architectural changes.
💬 Research Conclusions:
– The study demonstrates that visible writing can effectively serve as a first-class output channel for speech interaction, maintaining high responsiveness and performance across multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.07547

13. Light-WAM: Efficient World Action Models with State-Fusion Action Decoding
🔑 Keywords: Light-WAM, World Action Models, robot manipulation, video backbone, StateFusionActionExpert
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The main goal is to develop a lightweight World Action Model called Light-WAM for efficient robot manipulation that incorporates future-video supervision to enhance temporal structure representation.
🛠️ Research Methods:
– Use a compact video backbone and downsampled latent space to reduce video co-training costs.
– Implement the StateFusionActionExpert to directly predict action chunks with learned-query pooling from multiple backbone layers.
💬 Research Conclusions:
– Light-WAM demonstrates strong performance on LIBERO and achieves functional multi-task performance on RoboTwin 2.0 with only 0.44B trainable parameters.
– Achieves low inference latency of 72.03ms with 4.1GiB peak GPU memory usage and improved training throughput.
👉 Paper link: https://huggingface.co/papers/2606.08242

14. SDR: Set-Distance Rewards for Radiology Report Generation
🔑 Keywords: set-based rewards, embedding distances, chest X-ray report generation, vision–language models, reinforcement learning
💡 Category: AI in Healthcare
🌟 Research Objective:
– To improve chest X-ray report generation by employing set-based rewards using embedding distances that facilitate effective post-training and test-time selection without the need for causal reasoning structures.
🛠️ Research Methods:
– Used a set-based approach where reports are split into sentences and transformed into unordered embedding sets.
– Proposed set-to-set distances between generated and reference embeddings as continuous, permutation-invariant rewards.
– Conducted experiments across two datasets and three vision-language models, comparing post-training set-to-set distance based rewards against supervised fine-tuning.
💬 Research Conclusions:
– Set-to-set distance based rewards consistently outperform supervised fine-tuning on all headline metrics with notable improvements in BERTScore, RadGraph F1, and CheXbert F1 scores.
– The approach facilitates test-time best-of-N selection, providing a significant performance improvement over random selection.
– Set-distance rewards enable more efficient test-time scaling, reducing generated tokens while maintaining quality, thus establishing them as a unified signal for both post-training and test-time scaling in chest X-ray report generation.
👉 Paper link: https://huggingface.co/papers/2606.00440

15. Trajectory-Refined Distillation
🔑 Keywords: On-policy distillation, Prefix failure, Trajectory-refined distillation, Large language models, Teacher guidance
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address prefix failure in on-policy distillation (OPD) for large language models by proposing trajectory-level corrections.
🛠️ Research Methods:
– The paper introduces Trajectory-Refined Distillation (TRD), a method that corrects student’s rollouts at the trajectory level under teacher guidance to mitigate prefix failure.
💬 Research Conclusions:
– TRD successfully improves exploration by exposing students to alternative valid derivations, enhances single-attempt accuracy, and broadens reasoning coverage, outperforming prior baselines across various benchmarks and scales.
👉 Paper link: https://huggingface.co/papers/2606.08432

16. DuMate-DeepResearch: An Auditable Multi-Agent System with Recursive Search and Rubric-Grounded Reasoning
🔑 Keywords: Deep Research, Multi-agent Framework, Long-form Synthesis, Planning, Tool Ecosystem
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The aim is to create a multi-agent framework called DuMate-DeepResearch to address the challenges of deep research tasks, improving planning, evidence acquisition, and report synthesis.
🛠️ Research Methods:
– The framework decouples task understanding, planning, and scheduling from evidence acquisition and report rendering, making decisions traceable using a dynamic optimization approach.
– Introduces dynamic graph-based planning, recursive two-level execution, and rubric-based test-time optimization mechanisms.
💬 Research Conclusions:
– DuMate-DeepResearch achieved state-of-the-art results on two benchmarks, marking top scores in both overall performance and specific metrics such as information recall and analysis.
👉 Paper link: https://huggingface.co/papers/2606.07299

17. Evaluation Cards: An Interpretive Layer for AI Evaluation Reporting
🔑 Keywords: EvalCards, AI evaluation, interpretive signals, benchmark metadata, score comparability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop EvalCards, a framework that standardizes and unifies AI evaluation reporting across various platforms to overcome inconsistencies and facilitate reliable comparisons.
🛠️ Research Methods:
– A structured review of 52 papers and 10 stakeholder interviews to derive a reporting schema.
– Implementation of four key interpretive signals: reproducibility, documentation completeness, provenance and risk, and score comparability.
💬 Research Conclusions:
– A new operational reporting layer was created, deploying a monitoring tool that applied to thousands of models, benchmarks, and results, exposing systematic gaps in current AI evaluation reporting practices.
👉 Paper link: https://huggingface.co/papers/2606.09809

18. WorldCraft: From Camera Navigation to Object Manipulation in Interactive Video World Models
🔑 Keywords: WorldCraft, video-based world models, object-level trajectory actions, camera navigation, trajectory-centric control
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce WorldCraft, a framework that extends video-based world models to include object-level trajectory control while maintaining camera navigation functionalities.
🛠️ Research Methods:
– Utilizes a trajectory-centric control pipeline with components like Normalized World Trajectory, Spatial-Pathway LoRA, and Trajectory-Anchored State Persistence to achieve simultaneous object manipulation and camera navigation.
💬 Research Conclusions:
– WorldCraft successfully enables precise object control, preserves camera navigation fidelity, and maintains object state across extended scenarios, even during off-camera excursions.
👉 Paper link: https://huggingface.co/papers/2605.25077

19. AsyncWebRL: Efficient Multi-Step RL for Visual Web Agents
🔑 Keywords: AsyncWebRL, asynchronous reinforcement learning, trajectory normalization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This research aims to enhance vision-language web agent training by employing asynchronous reinforcement learning and modifying trajectory normalization to achieve faster throughput and better performance on challenging tasks.
🛠️ Research Methods:
– The study introduces AsyncWebRL, which combines an asynchronous design with specific adaptations like an everlasting rollout pool and lightweight screenshot handling, resulting in a significant speedup in training throughput.
– Implementing a modification in trajectory normalization by replacing 1/|τ_i| with a constant 1/k, improving trajectory shortening while maintaining success rates.
💬 Research Conclusions:
– The AsyncWebRL approach sets a new open-source state-of-the-art performance on the WebGym out-of-distribution test split, with notable performance improvements on more difficult tasks, achieving up to +48% relative gain on the hardest slice.
👉 Paper link: https://huggingface.co/papers/2606.05597
20. Hardening Agent Benchmarks with Adversarial Hacker-Fixer Loops
🔑 Keywords: LLM agents, exploit-resistant verifiers, reward hacking, hacker-fixer loop, Terminal Wrench
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to identify vulnerabilities in agent benchmark verification systems and develop an automated iterative process using LLM agents to create robust verifiers that resist exploitation while maintaining legitimate task performance.
🛠️ Research Methods:
– An audit was conducted on 1,968 tasks across five terminal-agent benchmarks to assess hackability by frontier models.
– The introduction of the hacker-fixer loop, which uses three LLM agents iteratively: a hacker, a fixer, and a solver to build exploit-resistant verifiers without per-task manual patching.
💬 Research Conclusions:
– The hacker-fixer loop significantly reduced attack success rates; for example, it brought the attack success rate from 62% to 0% on KernelBench.
– Weaker agents in the loop were effective against more powerful attackers, underscoring the loop’s robustness in identifying and mitigating exploits.
– Terminal Wrench was released as a snapshot of the current attack surface and a basis for future research, including patched verifiers and discovered exploits.
👉 Paper link: https://huggingface.co/papers/2606.08960

21. Where Rectified Flows Leak: Characterising Membership Signals Along the Interpolation Path
🔑 Keywords: Rectified Flows, Membership Inference Attack, training data traces, interpolation path, bell-shaped curve
💡 Category: Generative Models
🌟 Research Objective:
– To understand what generative models retain from training data and its implications for privacy and copyright.
🛠️ Research Methods:
– Analysis of the interpolation path in Rectified Flows to identify differences in the reconstruction of training and test data, and derivation of a maximum point under Gaussian assumptions.
💬 Research Conclusions:
– The study suggests that Rectified Flows encode subtle traces of training data exploitable for membership inference attacks, with a universal bell-shaped structure identified in the data reconstruction curve.
👉 Paper link: https://huggingface.co/papers/2606.07271

22. Chiaroscuro Attention: Spending Compute in the Dark
🔑 Keywords: CHIAR-Former, spectral entropy, self-attention, DCT, attention FLOPs
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance transformer efficiency on large text datasets by dynamically routing tokens using spectral entropy to select optimal operators.
🛠️ Research Methods:
– A 4-layer hybrid transformer, CHIAR-Former, is proposed, which routes tokens among DCT spectral mixing, RBF kernel mixing, and full self-attention, with evaluations conducted on datasets like WikiText-103 and IMDB sentiment classification.
💬 Research Conclusions:
– The CHIAR-Former demonstrated a 45% improvement in performance over traditional full-attention models on WikiText-103 with reduced computational resources, indicating the advantages of spectral routing in large-scale text processing.
👉 Paper link: https://huggingface.co/papers/2606.08327

23. OASIS: From Simulation Data Collection to Real-World Humanoid Loco-Manipulation
🔑 Keywords: simulation-data-driven framework, humanoid loco-manipulation, 3D generative model, hierarchical visuomotor policy, domain randomization
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to enhance humanoid robot loco-manipulation by utilizing a simulation-data-driven framework named OASIS, leveraging simulation to overcome limitations in traditional robot manipulation task demonstrations.
🛠️ Research Methods:
– The authors employ a 3D generative model to create realistic assets and collect trajectories through teleoperation in simulation, which are further augmented with domain randomization. They design a hierarchical visuomotor policy based on this augmented simulation data.
💬 Research Conclusions:
– The proposed framework, OASIS, demonstrates that policies trained on simulated data achieve better zero-shot performance compared to those trained on real-robot teleoperation data, ensuring higher success rates on various tasks by capturing broader environmental variations.
👉 Paper link: https://huggingface.co/papers/2606.08548
24. Precision Is Not Faithfulness: Coverage-Aware Evaluation of Grounded Generation with a Complete Oracle
🔑 Keywords: Reference-free faithfulness, precision, recall, grounded generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the limitation of reference-free faithfulness metrics that only measure precision, proposing a new metric that combines precision and recall to offer a more comprehensive evaluation of generated content’s faithfulness.
🛠️ Research Methods:
– The researchers utilize Formula 1 telemetry as a deterministic domain to measure both precision and recall by having access to complete ground truth. They conduct experiments on a multilingual benchmark and a second complete-oracle domain, NOAA weather forecasts, to validate their metric.
💬 Research Conclusions:
– The study finds that high-precision models often have poor fact coverage, thus ranking lower when evaluated with both precision and recall. A new verifier-guided generation method is proposed, improving precision and recall without needing references, demonstrating the effectiveness of their proposed metric.
👉 Paper link: https://huggingface.co/papers/2606.09376

25. Lean4Agent: Formal Modeling and Verification for Agent Workflow and Trajectory
🔑 Keywords: Large Language Models, Lean4, Formal Verification, Multi-step Workflows, Agent Behavior
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary aim is to enhance the reliability and performance of multi-step workflows in Large Language Models (LLMs) using a formal verification framework with Lean4, a dependent-type formal language.
🛠️ Research Methods:
– Development of Lean4 Agent, which utilizes Lean4 to model and verify agent behavior, with the FormalAgentLib library to ensure semantic consistency and debug workflow execution, and LeanEvolve to enhance workflows utilizing results from FormalAgentLib.
💬 Research Conclusions:
– Achieved an 11.94% improvement on verification-passing workflows over failing ones and enhanced SWE performance by 7.47% using LeanEvolve. Stablished a foundational framework for formal modeling and verification of agent behavior with dependent-type formal languages.
👉 Paper link: https://huggingface.co/papers/2606.06523

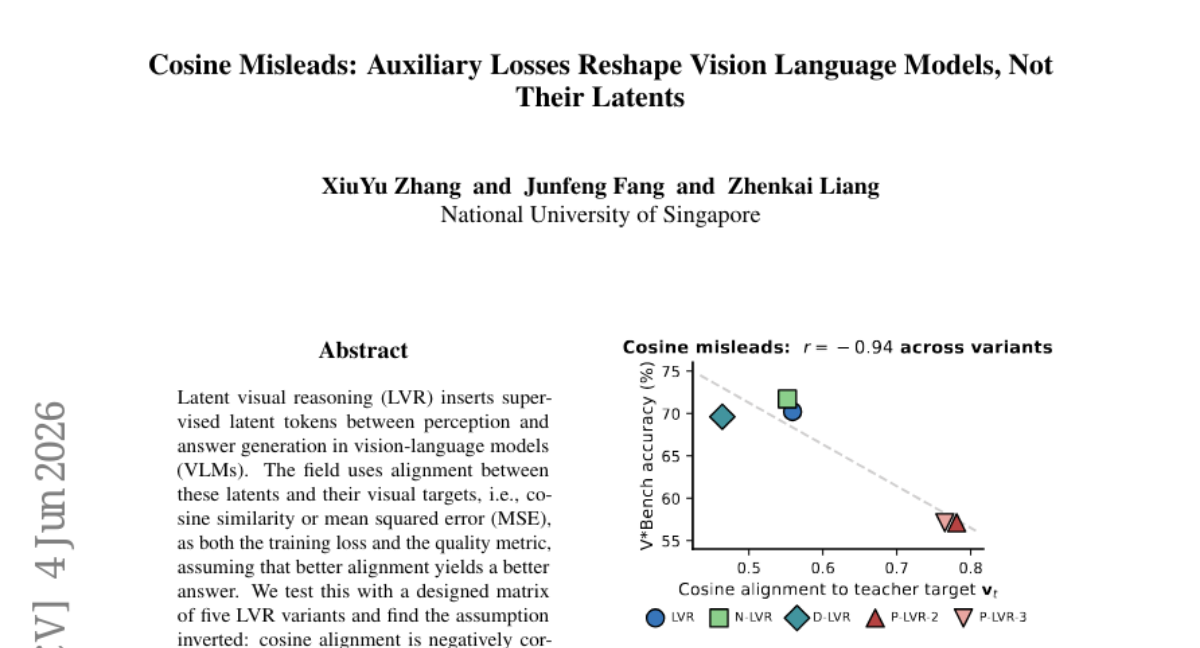
26. Cosine Misleads: Auxiliary Losses Reshape Vision Language Models, Not Their Latents
🔑 Keywords: Latent Visual Reasoning, Supervised Latent Tokens, Cosine Similarity, Information Bottleneck, Vision-Language Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Challenge conventional views on the relationship between latent mechanisms and accuracy in vision-language models (VLMs), specifically focusing on the correlation between cosine alignment of supervised latents and model accuracy.
🛠️ Research Methods:
– Experimentation with a designed matrix of five different Latent Visual Reasoning (LVR) variants to evaluate the correlation between cosine alignment and accuracy.
– Introduction of PRISM diagnostics: a linear probe to determine answer decodability and a corruption test to assess the dependency on latent states.
💬 Research Conclusions:
– The study reveals an inverse correlation between the cosine alignment of supervised latents and model accuracy (r=-0.94).
– Answers in VLMs are decoded from downstream latents rather than directly within them, indicating limited dependency on these latent states.
– An Information Bottleneck approach demonstrates that auxiliary objectives reshape models through shared parameters, rather than exclusively through the targeted latent variables.
👉 Paper link: https://huggingface.co/papers/2606.05753
27. Reasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
🔑 Keywords: Large language models, machine translation, low-resource languages, linguistic reasoning traces, in-context learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the potential of large language models to improve machine translation for extremely low-resource languages by using structured linguistic reasoning traces.
🛠️ Research Methods:
– Proposing a pipeline for generating linguistic reasoning traces from resources like Universal Dependencies treebanks, dictionaries, and grammar-rule banks.
– Evaluating linguistic reasoning traces in the contexts of in-context learning, supervised fine-tuning, and reinforcement fine-tuning, specifically for Xibe and Chintang languages.
💬 Research Conclusions:
– Linguistic reasoning traces significantly enhance translation performance during inference as reliable sentence-specific traces improve performance across models and languages.
– Using traces as training data results in less consistent improvements, indicating that effective inference-time guidance can better leverage grammatical information for low-resource machine translation, while generating reliable analyses remains challenging.
👉 Paper link: https://huggingface.co/papers/2606.03782

28. Set-Based Transformer for Atmospheric Compensation in Standoff LWIR Hyperspectral Imaging
🔑 Keywords: Lightweight deep learning, LWIR hyperspectral imaging, atmospheric compensation, transmittance estimation, sparse autoencoder
💡 Category: Machine Learning
🌟 Research Objective:
– Develop a lightweight deep learning framework for atmospheric compensation in passive long-wave infrared hyperspectral imaging.
🛠️ Research Methods:
– Utilize a set-based deep learning framework to jointly estimate transmittance, atmospheric path radiance, and downwelling spectrum from multi-range radiance measurements. Analyze learned representation using a sparse autoencoder.
💬 Research Conclusions:
– The framework demonstrates low spectral distortion in atmospheric compensation tasks, with geographically coherent latent features emerging without location supervision. Publicly available dataset and code.
👉 Paper link: https://huggingface.co/papers/2606.08324

29. Pruning and Distilling Mixture-of-Experts into Dense Language Models
🔑 Keywords: Mixture-of-Experts, Knowledge Distillation, Memory-Constrained Deployment, Dense Architectures, Scoring Method
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a systematic framework for converting Mixture-of-Experts (MoE) models into fully dense architectures, addressing memory constraints during deployment.
🛠️ Research Methods:
– Experts within MoE are scored, selected, and grouped through a variety of methods, then concatenated into a dense feedforward network. Knowledge distillation is applied from the original MoE to refine the dense architecture.
💬 Research Conclusions:
– The novel diversity-aware scoring method outperforms previous methods in various testing configurations, demonstrating a significant improvement in downstream accuracy (+6.3 pp) and training speed (1.6x faster) compared to traditional pruning techniques.
👉 Paper link: https://huggingface.co/papers/2605.28207

30.

31. EMMA: Extracting Multiple physical parameters from Multimodal Data
🔑 Keywords: EMMA, physics-informed, multimodal, Liquid Time-Constant, dynamical parameters
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce and utilize EMMA, a novel physics-informed multimodal framework, for recovering dynamical parameters directly from raw video, audio, and image data.
🛠️ Research Methods:
– Utilization of a Liquid Time-Constant network and physics-constrained loss for learning latent dynamics and enforcing consistency with differential equations.
– A unified feature pipeline enables the alignment of data across various modalities without the need for additional segmentations or sensors.
💬 Research Conclusions:
– EMMA achieves robust multi-parameter recovery and outperforms existing single-modality baselines. It is established as a scalable solution for extracting physics-consistent models from multimodal data.
👉 Paper link: https://huggingface.co/papers/2605.24047
32. Honest Lying: Understanding Memory Confabulation in Reflexive Agents
🔑 Keywords: Reflexion-style agents, self-generated reflections, memory confabulation, Reflection Repetition Rate, trajectory-level failure signals
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to identify and address the issue of persistent errors in Reflexion-style agents due to incorrect self-generated reflections, specifically measured by a new metric called the Reflection Repetition Rate (RRR).
🛠️ Research Methods:
– The research utilizes the Reflection Repetition Rate (RRR) metric to detect repeated reliance on incorrect reflections across environments such as ALFWorld and HumanEval and employs programmatic extraction of trajectory-level failure signals to mitigate these errors.
💬 Research Conclusions:
– The study finds that memory confabulation leads to persistent errors and incorrect task interpretations. Mitigation strategies significantly increase correct object mention and reduce RRR, demonstrating that improvements in reflective memory processes can reduce errors and support more accurate task execution.
👉 Paper link: https://huggingface.co/papers/2605.29463

33. CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
🔑 Keywords: CIPER, Cross-view geo-localization, 3-DoF pose estimation, transformer encoder, multi-task objective
💡 Category: Computer Vision
🌟 Research Objective:
– The study presents CIPER, aiming to solve cross-view geo-localization by improving simultaneous city-scale retrieval and precise 3-DoF pose estimation.
🛠️ Research Methods:
– Utilizes a shared transformer encoder with task-specific tokens and a two-way transformer pose decoder for disentangling retrieval features and improving localization accuracy.
💬 Research Conclusions:
– CIPER demonstrates competitive performance on VIGOR, KITTI, and Ford Multi-AV datasets, particularly in scenarios with limited field-of-view and variable orientations.
👉 Paper link: https://huggingface.co/papers/2606.05011

34. PIPE-Cypher: Automatic Enterprise Benchmark Generation for Text-to-Cypher Systems
🔑 Keywords: Local Benchmark-Generation Pipeline, Property Graphs, Text2Cypher, Execution Validation, Diversity Controls
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop PIPE-Cypher, a local benchmark-generation pipeline that transforms live property graphs and seed queries into balanced NL-to-Cypher datasets for enterprise knowledge graphs.
🛠️ Research Methods:
– Utilizes processes such as schema profiling, reverse-query grounding, constrained generation, execution validation, and the employment of a calibrated local LLM judge, utilizing local Qwen3.5-9B generation and judging.
💬 Research Conclusions:
– PIPE-Cypher consistently creates repeatable and adaptable Text2Cypher benchmarks. It highlights that zero-shot transfer is limited whereas schema-specific example banks enhance compatible model performances.
👉 Paper link: https://huggingface.co/papers/2606.08481

35. Send a SCOUT First: Pre-hoc Reasoning for Adaptive Detector Allocation in Prompt-Injection Defense
🔑 Keywords: SCOUT framework, prompt-injection detection, detector allocation, safety-utility threshold, SCOUT-450
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The SCOUT framework aims to dynamically allocate prompt-injection detection by predicting the reliability and latency of detectors to improve safety and efficiency over single-detector approaches.
🛠️ Research Methods:
– The framework reframes defense as detector allocation, deciding which detectors to run per request and whether to escalate to an LLM judge, using predictions based on past detector behavior.
💬 Research Conclusions:
– SCOUT reduces the attack-success rate by 46% and total wall-clock time by 40%, with only a 5.1-point drop in benign utility, when compared to an always-on GPT-4o judge. It also shows improved performance on external benchmarks, enhancing the safety-utility frontier.
👉 Paper link: https://huggingface.co/papers/2605.30837

36. Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
🔑 Keywords: Self-Evaluation Elicitation, Reinforcement Learning, Calibration, Masked Distillation, Transferable Quality Evaluation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to improve model calibration for quality assessment through a novel method called Self-Evaluation Elicitation (SEE).
🛠️ Research Methods:
– The SEE method employs calibration-coupled reinforcement learning and masked distillation in a short cycle to enhance prediction accuracy whilst maintaining answer quality.
💬 Research Conclusions:
– The SEE method successfully surfaces a model’s latent ability to predict judge scores beyond specific preferences, demonstrating a transferable quality evaluation on various benchmarks.
👉 Paper link: https://huggingface.co/papers/2606.05122

37. SigmaScale: LLM Compression with SVD-based Low-Rank Decomposition and Learned Scaling Matrices
🔑 Keywords: Large Language Model, compression, scaling matrices, activation-aware compression, effective-rank entropy
💡 Category: Natural Language Processing
🌟 Research Objective:
– To present SigmaScale, a method for learning auxiliary scaling matrices to improve the compression of Large Language Models using truncated Singular Value Decomposition.
🛠️ Research Methods:
– SigmaScale optimizes vectors for diagonal row and column scaling transformations based on activation-aware compression loss, lowering the effective intrinsic rank of weight matrices.
💬 Research Conclusions:
– SigmaScale demonstrates competitive performance with state-of-the-art SVD-based compression methods across benchmarks, offering a flexible route for low-rank LLM compression, which is beneficial in reducing LLM-inference computing costs.
👉 Paper link: https://huggingface.co/papers/2606.07098

38. Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning
🔑 Keywords: Skill-3D, 3D spatial reasoning, scene-aware skills, tool utilization, self-evolving
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces the Skill-3D framework which aims to improve agent performance in 3D spatial reasoning tasks by developing scene-aware skills through a self-evolving system.
🛠️ Research Methods:
– Skill-3D utilizes a self-evolving memory and skill library to develop and refine scene-aware skills. This system tracks tool-use trajectories across different scenes, distilling successful ones into reusable skills and using failed attempts as learning lessons.
💬 Research Conclusions:
– Experiments demonstrate significant improvements in tool utilization in 3D reasoning tasks, such as a 67% enhancement for Gemini-3-Flash on MMSI-Bench and a 43% improvement for Qwen3-VL-8B on VSI-Bench, highlighting the effectiveness of skill-guided tool use strategies.
👉 Paper link: https://huggingface.co/papers/2606.07436

39. EmpiriGraph-Psy: A Dataset and LLM Pipeline for Extracting Empirical Relation Graphs from Psychology Abstracts
🔑 Keywords: Empirical Graph Extraction, Variable-Centered, Psychology, Staged Pipeline, Typed Graphs
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to map psychology abstracts to typed graphs using normalized variables and empirical relations, specifically targeting variable-oriented empirical fields like psychology to bridge existing gaps in scientific relation extraction benchmarks.
🛠️ Research Methods:
– A staged pipeline approach is employed for graph extraction, which involves separate steps for variable extraction, normalization, hierarchy construction, evidence selection, relation extraction, and edge validation. This method is compared against direct extraction methods.
💬 Research Conclusions:
– The staged pipeline approach significantly improves performance, achieving a macro-F1 of 0.74, though challenges in moderating relations and concept hierarchies remain, particularly in extracting higher-order empirical claims from abstracts.
👉 Paper link: https://huggingface.co/papers/2606.08362

40. PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
🔑 Keywords: Privileged Bayesian Self-Distillation, Credit Assignment, Reinforcement Learning, Bayesian Evidence Scoring, Autoregressive Decomposition
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Privileged Bayesian Self-Distillation to enable fine-grained credit assignment in long-horizon tasks by converting sparse rewards into calibrated turn-level signals.
🛠️ Research Methods:
– Utilization of Bayes’ rule to transform the posterior-to-prior probability ratio into a tractable likelihood ratio between a student model and a privileged teacher model.
– Implementation of autoregressive decomposition to derive turn-level signals from Bayesian evidence scoring.
💬 Research Conclusions:
– PBSD enhances performance across various settings and facilitates effective policy learning and improved generalization by transforming sparse outcome supervision into Bayes-calibrated credit signals.
👉 Paper link: https://huggingface.co/papers/2606.09348

41. Experience Makes Skillful: Enabling Generalizable Medical Agent Reasoning via Self-Evolving Skill Memory
🔑 Keywords: SkeMex, Medical Agents, Skill Memory, Clinical Decision Making, Contextual Utility
💡 Category: AI in Healthcare
🌟 Research Objective:
– To develop SkeMex, a self-evolving framework that enhances medical agent systems through structured skill memory to improve long-term clinical reasoning.
🛠️ Research Methods:
– Utilization of a post-deployment self-evolution framework distilling informative interaction trajectories into structured skills, organized in a multi-branch repository and governed by context-dependent utility.
💬 Research Conclusions:
– SkeMex outperforms existing memory-based agents in clinical tasks, generalizes across model backbones, and supports the adaptation of transferable skill memory.
👉 Paper link: https://huggingface.co/papers/2606.09365

42. Trust Functions: Near-Lossless Weak-to-Strong Generalization by Learning When to Trust the Weak Teacher
🔑 Keywords: Trust Functions, Weak-to-Strong Generalization, Reliable Labels, Data Selection
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance weak-to-strong generalization by leveraging trust functions to identify reliable weak labels for training across various domains.
🛠️ Research Methods:
– Introduce trust functions that assign trust scores to weak labels, using these scores to filter weak supervision and enable iterative training chains.
💬 Research Conclusions:
– Trust functions enable students to match or exceed performance with ground-truth supervision, facilitating an effective weak-to-strong generalization process.
👉 Paper link: https://huggingface.co/papers/2606.01000

43. Phase Marginalization for Patch-Grid Instability in Vision Transformers
🔑 Keywords: Phase Marginalization, Vision Transformers, patch-grid phase, dense prediction, Uniform Phase Marginalization
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to address phase-dependent instability in Vision Transformers by proposing the novel method of Phase Marginalization for evaluating structured patch-grid phases and aggregating outputs in the original image coordinate system.
🛠️ Research Methods:
– A post-hoc marginalization approach called Phase Marginalization is formalized to handle patch-grid phases for dense predictions without additional training. This method includes evaluating structured patch-grid phases and inverse-aligning dense outputs.
💬 Research Conclusions:
– This research demonstrates that Uniform Phase Marginalization with K = 4 surpasses the traditional K = 1 baseline in segmentation, depth, and local matching experiments. It provides better performance with a modest compute-matched advantage over generic test-time augmentation in Cityscapes experiments. The study also highlights that using K = 8 or K = 16 offers minimal accuracy gain at higher costs.
👉 Paper link: https://huggingface.co/papers/2606.08132

44. Optical Reasoning: Rethinking Images as an Expressive Reasoning Medium Beyond Text
🔑 Keywords: Optical reasoning, Chain-of-Thought, Large Language Models, Multimodal Large Language Models, Token efficiency
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This study proposes the concept of optical reasoning, exploring the use of images as a standalone reasoning medium for language and multimodal tasks to achieve higher token efficiency compared to traditional text-based approaches.
🛠️ Research Methods:
– The study introduces two variants of optical reasoning: typographic-based, which optimizes visual layouts, and graphical-based, which composes text and graphical elements into visual rationales.
💬 Research Conclusions:
– Optical reasoning can match or surpass traditional text reasoning, reducing reasoning tokens by 28.57% on language tasks and 16% on multimodal tasks, thus enhancing token efficiency by 1.96 times. This indicates that images can effectively encode rationales while providing a unified visual platform for reasoning.
👉 Paper link: https://huggingface.co/papers/2606.09585

45. Robotic Policy Adaptation via Weight-Space Meta-Learning
🔑 Keywords: WIZARD, Vision-Language-Action models, LoRA parameters, meta-learning, task adaptation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective is to develop WIZARD, a framework providing task-specific adaptation for Vision-Language-Action models without requiring fine-tuning, utilizing language instructions and demonstration videos.
🛠️ Research Methods:
– WIZARD operates by predicting task-specific LoRA parameters in a single forward pass, using language instructions and demonstration videos during the meta-training phase to generate expert LoRA updates without target-task action labels.
💬 Research Conclusions:
– Experiments on LIBERO demonstrate that WIZARD significantly improves performance, enhancing results by up to ~2x on unseen datasets and up to ~14x on unseen tasks, especially on a Franka Emika Panda, where WIZARD surpasses a real-domain adapted baseline.
👉 Paper link: https://huggingface.co/papers/2606.07217

46. Text-to-Image Models Need Less from Text Encoders Than You Think
🔑 Keywords: Text-to-image models, text embeddings, diffusion transformer-based models, visual quality, text fidelity
💡 Category: Generative Models
🌟 Research Objective:
– To explore which aspects of text representation are essential for image generation in text-to-image models.
🛠️ Research Methods:
– Developed a new text embedding that captures only individual word meanings and order, lacking complete contextual information, to evaluate its impact on image generation.
💬 Research Conclusions:
– Text-to-image models primarily depend on simple text representation aspects like word merging and order, rather than exploiting richer contextual information. The study finds that such simplified text embeddings can still guide image generation successfully, maintaining high visual quality and text fidelity.
👉 Paper link: https://huggingface.co/papers/2606.03715

47. Answer Presence Drives RAG Rewriting Gains
🔑 Keywords: QA performance, gold answer, intervention audit, LLM rewriter, sentinel changes
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the causal factors behind the performance boost in multi-hop QA systems, specifically determining whether the presence of the gold answer in rewritten contexts is the main driver.
🛠️ Research Methods:
– The researchers conducted controlled interventions where they manipulated rewritten contexts by either removing or injecting the gold answer and assessed the impact on QA performance across multiple reader configurations and datasets.
💬 Research Conclusions:
– The presence of the gold answer in rewritten contexts significantly enhances QA performance, with its removal causing notable F1 decrease, and injection causing improvement. Conventional probing methods demonstrated fragility to sentinel changes.
👉 Paper link: https://huggingface.co/papers/2606.05633

48. Reasoning Arena: Trace Tournaments When Verifiable Rewards Fall Short
🔑 Keywords: Reinforcement Learning, Verifiable Rewards, Reasoning Arena, Trace Tournaments, Bradley-Terry Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reinforcement learning for large language models by introducing a more informative reward system through the Reasoning Arena framework.
🛠️ Research Methods:
– Implementing trace tournaments to differentiate reasoning quality among non-diverse reward groups.
– Utilizing a judge system and dynamically updated trace pools for efficient relative ranking.
– Applying Bradley-Terry models on incomplete comparison graphs to facilitate scalable RL integration.
💬 Research Conclusions:
– Reasoning Arena outperforms the baseline RLVR by 7.6% in reasoning tasks, accelerates training speed by 27% to 41%, and reduces computation by nearly 50%.
👉 Paper link: https://huggingface.co/papers/2606.09380

49. Why Muon Outperforms Adam: A Curvature Perspective
🔑 Keywords: Muon, Adam, large language model training, curvature penalty, Normalized Directional Sharpness (NDS)
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to uncover the reasons behind Muon’s superior performance over Adam in large language model training, focusing on curvature perspectives.
🛠️ Research Methods:
– Application of second-order Taylor approximation to the training landscape.
– Analysis of curvature penalties through decomposition into components like squared update norm and NDS.
– Investigation of training data imbalance using Zipf-Probabilistic Context-Free Grammar (PCFG).
💬 Research Conclusions:
– Muon exhibits a larger one-step loss decrease and incurs a smaller second-order curvature penalty than Adam, attributed to lower NDS.
– Data imbalance and heterogeneous curvature conditions amplify Muon’s advantages.
👉 Paper link: https://huggingface.co/papers/2606.04662

50. OmniCap-IF: Benchmarking and Improving Instruction Following Abilities for Omni-Video Captioning
🔑 Keywords: OmniCap-IF, omni-modal captioning, instruction-following, format-content tradeoff, Temporal Grounding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces OmniCap-IF, the first comprehensive benchmark to evaluate instruction-following capabilities in omni-modal captioning, addressing the gap in assessing multi-modal reasoning under complex user instructions.
🛠️ Research Methods:
– A systematic framework is employed to evaluate captions on format correctness and content correctness across 50 distinct constraint types in pure visual, pure audio, and audio-visual modalities, including Temporal Grounding for spatio-temporal precision.
💬 Research Conclusions:
– The study reveals significant performance disparities among models and identifies a critical “format-content tradeoff,” explaining that increased formatting complexity degrades omni-modal reasoning. OmniCaptioner-IF, a new model, demonstrates notable improvements through a curated 54K instruction-tuning dataset.
👉 Paper link: https://huggingface.co/papers/2606.08572

51. Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
🔑 Keywords: Reward Models, Reinforced Fine-Tuning, Reinforcement Learning, Structured Agentic Task, Evidence Aggregation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce a unified reward modeling framework called Skill-RM that treats reward computation as a structured agentic task.
🛠️ Research Methods:
– Utilizes a consistent interface for orchestrating heterogeneous resources, dynamically selecting and aggregating evidence based on specific input requirements.
💬 Research Conclusions:
– Skill-RM outperforms traditional judge baselines in reward benchmarks and downstream applications by providing a unified solution for reward modeling with superior performance.
👉 Paper link: https://huggingface.co/papers/2606.03980

52. Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
🔑 Keywords: Bayesian-Agent, SOPs, hypotheses, task performance, model success
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to introduce Bayesian-Agent, a framework using Bayesian inference for enhancing agent behavior and task performance by treating reusable skills and SOPs as hypotheses for success.
🛠️ Research Methods:
– Utilizes Bayesian inference to guide agent behavior and optimize task performance through posterior-guided harness optimization. The framework records trajectory evidence and maintains a categorical posterior over each skill.
💬 Research Conclusions:
– Bayesian-Agent framework improves the performance of different benchmarks significantly, suggesting that agent skill evolution is more effective when viewed as posterior-guided harness optimization rather than uncalibrated prompt accumulation.
👉 Paper link: https://huggingface.co/papers/2606.08348

53. AHA-WAM:Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
🔑 Keywords: AHA-WAM, dual Diffusion Transformers, asynchronous world-action model, horizon-adaptive offset training, Observation-Guided Video-Context Routing
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop an Asynchronous Horizon-Adaptive World-Action Model (AHA-WAM) for efficient long-horizon planning and real-time action execution in robotic manipulation tasks.
🛠️ Research Methods:
– Utilization of dual Diffusion Transformers architecture to decouple temporal resolutions for world prediction and action execution.
– Implementation of horizon-adaptive offset training and Observation-Guided Video-Context Routing for asynchronous execution.
💬 Research Conclusions:
– AHA-WAM achieved state-of-the-art performance, with 92.80% success on RoboTwin and 78.3% success in real-world tasks without robot-data pretraining.
– The model demonstrated a 24.17 Hz closed-loop control with a 4.59x speedup over Fast-WAM.
👉 Paper link: https://huggingface.co/papers/2606.09811

54. OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
🔑 Keywords: Vision-language model, OmniGameArena, reflection-based improvement, Unreal Engine 5, Improvement Dynamics Curve
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To establish a unified benchmark, OmniGameArena, for evaluating Vision-language model (VLM) agents across diverse game settings to track their performance evolution and skill generalization.
🛠️ Research Methods:
– Introduced twelve games built with Unreal Engine 5 encompassing Solo, PvP, and Coop modes.
– Developed a unified action interface and Improvement Dynamics Curve (IDC) which uses a tool-using reflector LLM to refine bounded skill prompts over multiple rounds.
💬 Research Conclusions:
– Demonstrated the effectiveness of IDC by reporting performance metrics on a cold-start leaderboard and additional observables, showcasing how agent scores evolve and how skills generalize across tasks.
👉 Paper link: https://huggingface.co/papers/2606.09826

55. Echo-Memory: A Controlled Study of Memory in Action World Models
🔑 Keywords: Echo-Memory, memory mechanisms, action-conditioned world models, replay quality, state-space recurrence
💡 Category: Generative Models
🌟 Research Objective:
– To investigate the impact of memory structure and capacity on the performance of action-conditioned world models.
🛠️ Research Methods:
– Conducted a controlled study using Echo-Memory, varying only the memory storage and retrieval mechanisms while keeping other factors like the video diffusion backbone constant.
💬 Research Conclusions:
– Raw context provides a robust capacity baseline, significantly enhancing open-domain return performance.
– Compact memory designs, while efficient, can lead to the loss of essential evidence for accurate memory recall.
– State-space recurrence stands out as the most effective mechanism for open-domain returns, demonstrating the critical role of implicit memory structure.
👉 Paper link: https://huggingface.co/papers/2606.09803

56. SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
🔑 Keywords: SpatialWorld, multimodal agents, spatial reasoning, partial observability, text-based actions
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introducing SpatialWorld as a unified benchmark to evaluate interactive spatial understanding in multimodal agents through diverse real-world tasks.
🛠️ Research Methods:
– Integration of eight heterogeneous simulation backends under a unified protocol, enabling tasks with vision-only partial observability and decision-making via a text-based action interface.
💬 Research Conclusions:
– Highlighting challenges in robust spatial task solving, with the most advanced model achieving a low task success rate, revealing inefficiencies and performance variations across domain-specific tasks.
👉 Paper link: https://huggingface.co/papers/2606.09669

57. CoVEBench: Can Video Editing Models Handle Complex Instructions?
🔑 Keywords: CoVEBench, compositional video editing, multi-point editing instructions, video fidelity, video quality
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces CoVEBench, a benchmark designed to assess the capabilities of current models in compositional video editing, specifically focusing on handling complex and multi-step editing tasks while preserving spatiotemporal content.
🛠️ Research Methods:
– CoVEBench consists of 416 curated source videos, 626 multi-point editing instructions, and 9,990 fine-grained checklist items to evaluate models on instruction compliance and video fidelity using automated metrics for assessing video quality.
💬 Research Conclusions:
– The study finds that compositional video editing remains challenging; models often fail to implement all edits correctly, breach preservation constraints, or generate artifacts when executing multiple operations at the same time.
👉 Paper link: https://huggingface.co/papers/2606.08415
58. LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
🔑 Keywords: LatentSkill, LoRA adapters, weight space, semantic geometry, parameter-space arithmetic
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective of the research is to develop LatentSkill, a framework designed to efficiently convert textual skills into LoRA adapters for agent systems, reducing context overhead while maintaining modularity and composability.
🛠️ Research Methods:
– The researchers utilized LatentSkill to transform textual skills into plug-and-play LoRA adapters using a pretrained hypernetwork, allowing these skills to be stored in weight space instead of context space.
💬 Research Conclusions:
– LatentSkill was shown to outperform in-context skill baselines in specific benchmarks, achieving significant improvements in task success and efficiency in ALFWorld and Search-QA. It demonstrated that weight-space skills are efficient, modular, and offer less exposure compared to context-space skills.
👉 Paper link: https://huggingface.co/papers/2606.06087

59. On the Geometry of On-Policy Distillation
🔑 Keywords: On-policy distillation, Parameter space, Subspace locking, Reinforcement learning, Supervised fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research investigates the unique geometric patterns in parameter space dynamics of On-policy distillation (OPD) and compares them with supervised fine-tuning and reinforcement learning with verifiable rewards.
🛠️ Research Methods:
– The study uses parameter-space diagnostics to compare the trajectory of OPD updates in parameter space with other methods, highlighting subspace locking and relaxed off-principal updates.
💬 Research Conclusions:
– OPD forms a distinct update geometry, characterized by fewer weight updates and subspace locking, which is functionally sufficient for OPD but not for supervised fine-tuning. The study highlights how OPD’s dynamics are unique and not merely intermediate between other methods.
👉 Paper link: https://huggingface.co/papers/2606.07082
