China AI Native Industry Insights – 20260612 – Xiaomi MiMo | Alibaba | Tencent | more
Explore Xiaomi MiMo Code, MNN’s Arm SME2 boost, Tencent’s HPC-Ops upgrade. Discover more in Today’s China AI Native Industry Insights.
1. Xiaomi releases and open-sources MiMo Code V0.1.0, an AI programming assistant with persistent memory system
Xiaomi has released and open-sourced MiMo Code V0.1.0, a terminal-based AI programming assistant built on the OpenCode project under MIT license. The tool features a persistent memory system that addresses long conversation context loss through project memory, session checkpoints, and task progress tracking mechanisms. It includes the MiMo-V2.5 multimodal model with performance comparable to Claude Sonnet 4.6, supports integration with mainstream models like DeepSeek, Kimi, and GLM, and introduces a Compose mode for end-to-end software development workflows. The system achieved 62% on SWE-Bench Pro and 73% on Terminal Bench 2 benchmarks, outperforming Claude Code using the same underlying model.
Read more: https://mp.weixin.qq.com/s/WkMPz-eBK2Hz0ZTQEwtx6w
Video Credit: The original article
2. MNN inference engine adds Arm SME2 support achieving 80% speedup for Qwen3-VL on-device deployment
Alibaba’s MNN inference engine has integrated support for Arm’s second-generation Scalable Matrix Extension (SME2) instruction set, enabling significant performance improvements for on-device AI model deployment. Testing with the Qwen3-VL-4B-Instruct multimodal model on SME2-enabled flagship devices like vivo X300 showed an 81% speedup in the prefill stage and 13% improvement in the decode stage compared to non-SME2 implementations. The integration uses a compile-time switch with runtime hardware detection, automatically selecting the optimal acceleration path without requiring manual configuration. MNN has released complete deployment tools including model conversion, quantization, and Android app integration capabilities for developers.
Read more: https://mp.weixin.qq.com/s/QNl4pn5JzxpEeFAEvq88ZA
Video Credit: The original article
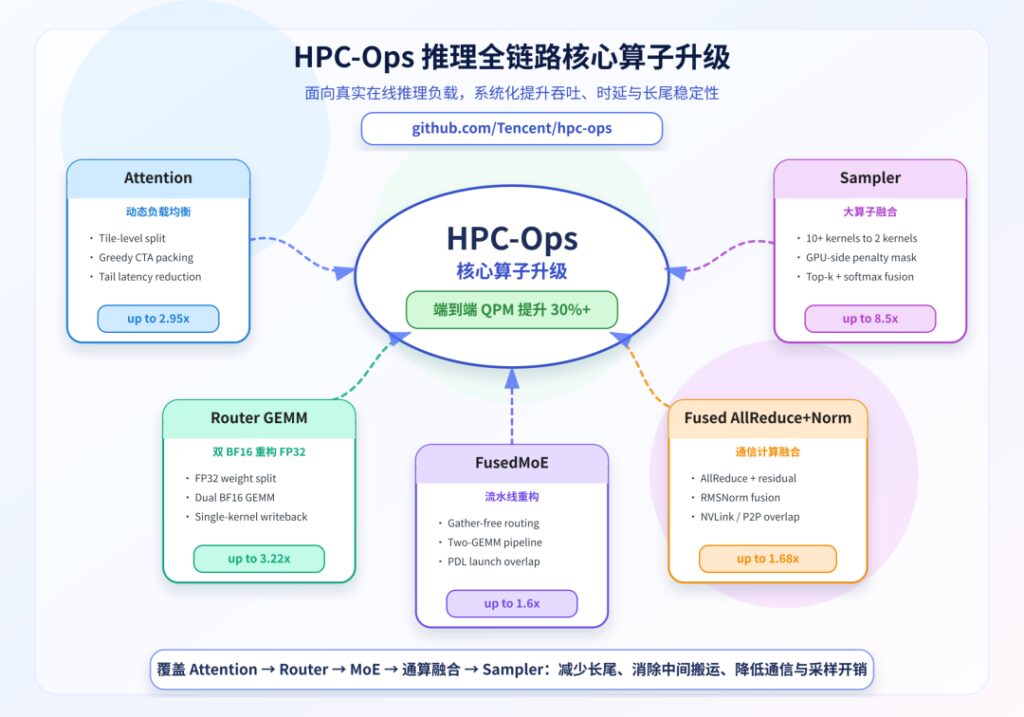
3. Tencent Hunyuan open-sources HPC-Ops inference operator library with major system-level upgrade
Tencent Hunyuan AI Infra team has released a major upgrade to its open-source HPC-Ops inference operator library, expanding from individual operators to a comprehensive optimization suite covering the entire inference pipeline. The update includes five key operators: dynamic load-balanced Attention that achieves up to 2.95x speedup on long-context workloads and 17% QPM improvement, Router GEMM using dual BF16 for FP32-level precision with up to 3.22x speedup over cuBLAS FP32, FusedMoE with 1.2x to 1.6x performance gains over vLLM and SGLang, Fused AllReduce+Norm delivering 1.04x to 1.68x speedup, and Sampler achieving 4.0x to 7.5x speedup over vLLM. The library is production-ready, fully open-source, and available immediately on GitHub for developers building high-throughput, low-latency large model inference services.
Read more: https://mp.weixin.qq.com/s/y0vd1cpvWXLSssL1kXxguw
Video Credit: NotebookLM
That’s all for today’s China AI Native Industry Insights. Join us at AI Native Foundation Membership Dashboard for the latest insights on AI Native, or follow our linkedin account at AI Native Foundation and our twitter account at AINativeF.