AI Native Daily Paper Digest – 20260630

1. Agentic Abstention: Do Agents Know When to Stop Instead of Act?
🔑 Keywords: Agentic Abstention, LLM as Agent, Sequential Decision Problem, Context Engineering, CONVOLVE
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address the problem of Agentic Abstention in AI agents, where the decision to cease interaction under uncertainty needs to be made across various environments and task types.
🛠️ Research Methods:
– Evaluated 13 LLM-as-agent systems and 2 agent scaffolds on over 28,000 tasks across different domains, such as web shopping and question answering, to assess the effective timing of agentic abstention.
💬 Research Conclusions:
– The study reveals significant challenges in determining when AI agents should abstain from further interaction, with a noticeable gap in timely abstention across certain tasks.
– Findings suggest that larger or more capable models may not always perform better in timely abstention.
– Introduced the CONVOLVE method, enhancing agentic abstention by distilling interaction trajectories into stopping rules, which improved the timely recall rate substantially without updating model parameters.
👉 Paper link: https://huggingface.co/papers/2606.28733

2. Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
🔑 Keywords: Agents-A1, Mixture-of-Experts, long-horizon trajectories, heterogeneous agent abilities, knowledge-action infrastructure
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to demonstrate that a 35B Mixture-of-Experts agent model, Agents-A1, can achieve performance comparable to trillion-parameter models by efficiently scaling agent horizons through innovative training strategies.
🛠️ Research Methods:
– Utilizes a three-stage training approach: full-domain supervised fine-tuning, specialized domain-level teacher models, and multi-teacher domain-routed on-policy distillation, aiming to integrate various agentic capacities across different domains.
💬 Research Conclusions:
– Agents-A1 outperforms or matches trillion-parameter models in multiple long-horizon agent benchmarks, providing a scalable approach for deploying high-performance agent models in reinforced learning contexts.
👉 Paper link: https://huggingface.co/papers/2606.30616

3. ReFreeKV: Towards Threshold-Free KV Cache Compression
🔑 Keywords: ReFreeKV, KV cache pruning, threshold-free, LLM inference, memory consumption
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce ReFreeKV, a threshold-free approach for KV cache pruning that adaptively allocates compression budgets while maintaining full-cache performance across diverse datasets and model sizes.
🛠️ Research Methods:
– Extensive experiments conducted across 13 datasets with various context lengths, task types, and model sizes to demonstrate efficacy and efficiency of ReFreeKV.
💬 Research Conclusions:
– ReFreeKV effectively addresses the limitations of threshold-dependent KV cache pruning methods, enabling robust KV compression without performance loss across diverse inputs and conditions.
👉 Paper link: https://huggingface.co/papers/2502.16886

4. Trimming the Long-Tail of Visual World Modeling Evaluation
🔑 Keywords: long-tailed distribution, visual world models, Tailor-Bench, predictive generation, descriptive generation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Tailor-Bench to challenge and evaluate the capability of visual world models to generalize beyond common physical interactions, focusing on rare and irregular scenarios.
🛠️ Research Methods:
– Design three scenario modes: Regular, Unconventional, and Impossible, to assess model reasoning and generalization.
– Implement a unified evaluation protocol with two complementary settings: predictive generation and descriptive generation.
💬 Research Conclusions:
– Existing visual world models show a long-tail gap in performance, struggling to generalize effectively from Regular to Unconventional and Impossible scenarios.
– Failure analysis indicates reliance on superficial visual patterns, with image models struggling with state changes and video models suffering from temporal inconsistencies.
👉 Paper link: https://huggingface.co/papers/2606.24256
5. AsyncOPD: How Stale Can On-Policy Distillation Be?
🔑 Keywords: Asynchronous training, On-policy distillation, Stale-policy data, Reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Address training bottlenecks in large language model post-training by introducing asynchronous on-policy distillation.
🛠️ Research Methods:
– Conduct the first systematic study of stale-policy data in asynchronous on-policy distillation using local KL losses and finite teacher-score caches. Explore the use of multi-sample Monte Carlo for reducing variance.
💬 Research Conclusions:
– Asynchronous on-policy distillation (AsyncOPD) improves training throughput significantly (1.6x to 3.8x) compared to strict synchronous training while maintaining comparable accuracy.
👉 Paper link: https://huggingface.co/papers/2606.24143

6. One-Step Gradient Delay is Not a Barrier for Large-Scale Asynchronous Pipeline Parallel LLM Pretraining
🔑 Keywords: Asynchronous Pipeline Parallelism, PipeDream-2BW, Optimizer Selection, Gradient Staleness, Error Feedback
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to overcome stability concerns in asynchronous pipeline parallelism by using PipeDream-2BW, highlighting the role of optimizer selection and error feedback correction.
🛠️ Research Methods:
– The research conducts a comprehensive empirical analysis of different optimizers, focusing on their performance with PipeDream-2BW’s one-step gradient delay, and introduces an optimizer-agnostic error feedback correction.
💬 Research Conclusions:
– The results indicate that degradation with PipeDream-2BW is not an inherent limitation but varies with the optimizer choice. Muon exhibits strong robustness and, with error feedback, effectively bridges the performance gap between asynchronous and synchronous pipeline training at scale.
👉 Paper link: https://huggingface.co/papers/2606.30634

7. One Model, Many Latencies: Universal Speech Enhancement for Diverse Real-Time Applications
🔑 Keywords: universal speech enhancement, real-time, latency budget, parallel convolutional layers, early-exit mechanism
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The study aims to develop a universal, real-time speech enhancement model offering explicit control over algorithmic and computational latency.
🛠️ Research Methods:
– Utilizes parallel convolutional layers and an early-exit mechanism to adjust latency and enable flexible deployment without retraining.
💬 Research Conclusions:
– The proposed framework efficiently supports diverse latency budgets and narrows the performance gap between specialized and flexible models through a two-stage training strategy.
👉 Paper link: https://huggingface.co/papers/2606.25621

8. GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
🔑 Keywords: GUI agents, visual grounding, reinforcement learning, curriculum learning, weakly-supervised
💡 Category: Reinforcement Learning
🌟 Research Objective:
– GUICrafter aims to address the data collection challenge in GUI agents by reducing reliance on costly human annotations using unannotated screenshots.
🛠️ Research Methods:
– Utilizes a weakly-supervised approach with a two-stage curriculum learning framework for visual grounding and reinforcement learning calibration.
💬 Research Conclusions:
– GUICrafter demonstrates competitive or superior performance compared to advanced systems like UI-TARS, using only 0.1% of its data, and exceeds previous methods like GUI-R1 under the same data conditions.
👉 Paper link: https://huggingface.co/papers/2606.29705

9. OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
🔑 Keywords: Computer-use agents, Benchmark, Complex workflows, Agent reasoning, Implicit-state inference
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce OSWorld 2.0 as a comprehensive benchmark for evaluating the capabilities of computer-use agents in realistic, long-horizon workflows.
🛠️ Research Methods:
– Developed 108 long-horizon computer-use workflows based on real-world scenarios, requiring extensive tool calls and interaction design challenges.
💬 Research Conclusions:
– Current agents significantly struggle with professional-level tasks, particularly in maintaining task constraints and processing mid-task information, indicating substantial room for improvement in agent reasoning and implicit-state inference.
👉 Paper link: https://huggingface.co/papers/2606.29537
10. DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
🔑 Keywords: DreamForge-World, real-time interactive simulation, residual action pathway, consumer-GPU, AI Systems and Tools
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to adapt a video generation architecture for real-time interactive world simulation on consumer hardware with low computational requirements.
🛠️ Research Methods:
– Utilization of LongLive 1 autoregressive video stack with a residual action pathway, enabling features like live keyboard and mouse control and multimodal initialization.
💬 Research Conclusions:
– Demonstrates a practical low-compute route for controllable world-model previews on consumer GPUs, showcasing cost-efficiency without achieving memory-complete or frontier-quality simulation.
👉 Paper link: https://huggingface.co/papers/2606.30292
11. SAM2Matting: Generalized Image and Video Matting
🔑 Keywords: video matting, tracker-to-matting framework, SAM2, temporal consistency, generalization
💡 Category: Computer Vision
🌟 Research Objective:
– SAM2Matting aims to advance video matting by separating tracking and matting tasks using a tracker-to-matting framework.
🛠️ Research Methods:
– The framework enhances foundational trackers with region-proposal bridges and dedicated matting heads, trained only on images to achieve high-fidelity video matting.
💬 Research Conclusions:
– SAM2Matting establishes state-of-the-art performance in video matting, supports diverse prompt types, maintains strong temporal consistency, and demonstrates robust generalization across different scenarios.
👉 Paper link: https://huggingface.co/papers/2606.27339
12. TheoremGraph: Bridging Formal and Informal Mathematics
🔑 Keywords: Unified mathematical dependency graph, Semantic embedding, Informal and formal mathematics, TheoremGraph, LeanGraph
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To develop a unified statement-level dependency graph that connects informal and formal mathematics through semantic embedding and automated extraction.
🛠️ Research Methods:
– Parsed 11.7M theorem-like environments from mathematics arXiv and extracted 18.3M candidate directed dependencies.
– Developed LeanGraph with 388,105 declaration nodes and 11.3M typed edges.
– Bridged informal and formal math graphs with natural-language slogans embedding into a shared semantic space.
💬 Research Conclusions:
– Achieved 47,952 matches with a 0.8 cosine floor in validation by an LLM judge, showing high precision in linking related statements.
– The name-and-signature representation approach in concept retrieval closely matched LeanSearch v2’s results without requiring an LM reranker.
👉 Paper link: https://huggingface.co/papers/2606.25363

13. MIMFlow: Integrating Masked Image Modeling with Normalizing Flows for End-to-End Image Generation
🔑 Keywords: MIMFlow, Normalizing Flows, Masked Image Modeling, semantic representation, generative modeling
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces MIMFlow, aiming to enhance generative modeling by effectively decoupling semantic representation from pixel-level details using a combination of Normalizing Flows and Masked Image Modeling.
🛠️ Research Methods:
– MIMFlow utilizes a VAE encoder to extract semantic latent variables from masked images and leverages Normalizing Flows to model a simplified semantic manifold while a specialized decoder focuses on high-frequency synthesis.
💬 Research Conclusions:
– MIMFlow significantly addresses the capacity bottleneck in Normalizing Flows, achieving superior global structural coherence with fewer tokens and delivering a substantial performance improvement over baseline models.
– Empirical tests on ImageNet 256×256 demonstrate that MIMFlow-L achieves 71.3% linear probing accuracy and an FID of 2.50, with a notable 32.8% performance gain using only 128 tokens.
👉 Paper link: https://huggingface.co/papers/2606.26016

14. Beyond Drug Discovery: The Nanotechnology Molecular Optimization (NMO) Benchmark
🔑 Keywords: Generative Molecular Design, Nanotechnology Molecular Optimization, Quantum Simulations, Scientific Utility, Generative Models
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to introduce the Nanotechnology Molecular Optimization (NMO) Benchmark which aims to facilitate scientific discovery in nanotechnology by moving beyond traditional drug-discovery metrics.
🛠️ Research Methods:
– The research involves replacing proxy oracles with quantum simulations, creating strict protocols that prioritize scientific utility, and developing a baseline method with novel representation strategies to address NMO tasks.
💬 Research Conclusions:
– The study reveals that simpler approaches can outperform advanced methods on NMO tasks, offering insights into the nanotechnology community and demonstrating that machine learning can drive genuine scientific discovery.
👉 Paper link: https://huggingface.co/papers/2606.30170

15. RocketSmith: Agentic Additive Manufacturing of High-Powered Rockets
🔑 Keywords: agentic system, large language model, flight stability, additive manufacturing, FDM printers
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To automate high-power rocket design processes using an agentic system incorporating large language models.
🛠️ Research Methods:
– Utilization of a large language model to orchestrate design validation and parametric design generation.
– Implementation of subagents and skills to optimize flight parameters using zero-shot and human-in-the-loop workflows.
💬 Research Conclusions:
– Developed four high-power rockets with various configurations using additive manufacturing and FDM printers.
– Successfully achieved stable launches with two rockets recovered in reflyable condition, validating simulation consistency with experimental results.
👉 Paper link: https://huggingface.co/papers/2606.00097
16. One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
🔑 Keywords: GUI grounding, target-region awareness, cross-layer evidence bridging, end-to-end latency, computational cost
💡 Category: Computer Vision
🌟 Research Objective:
– InnerZoom aims to address the challenges of GUI grounding by preserving target-region awareness across decoder layers with reduced computational cost.
🛠️ Research Methods:
– The researchers introduced a single-forward pass framework called InnerZoom, which bridges cross-layer evidence to maintain target awareness and improve coordinate prediction accuracy.
💬 Research Conclusions:
– InnerZoom achieved state-of-the-art performance on six GUI grounding benchmarks, significantly surpassing previous methods while reducing end-to-end latency by up to 31.8% and TFLOPs by about 29%.
👉 Paper link: https://huggingface.co/papers/2606.30084

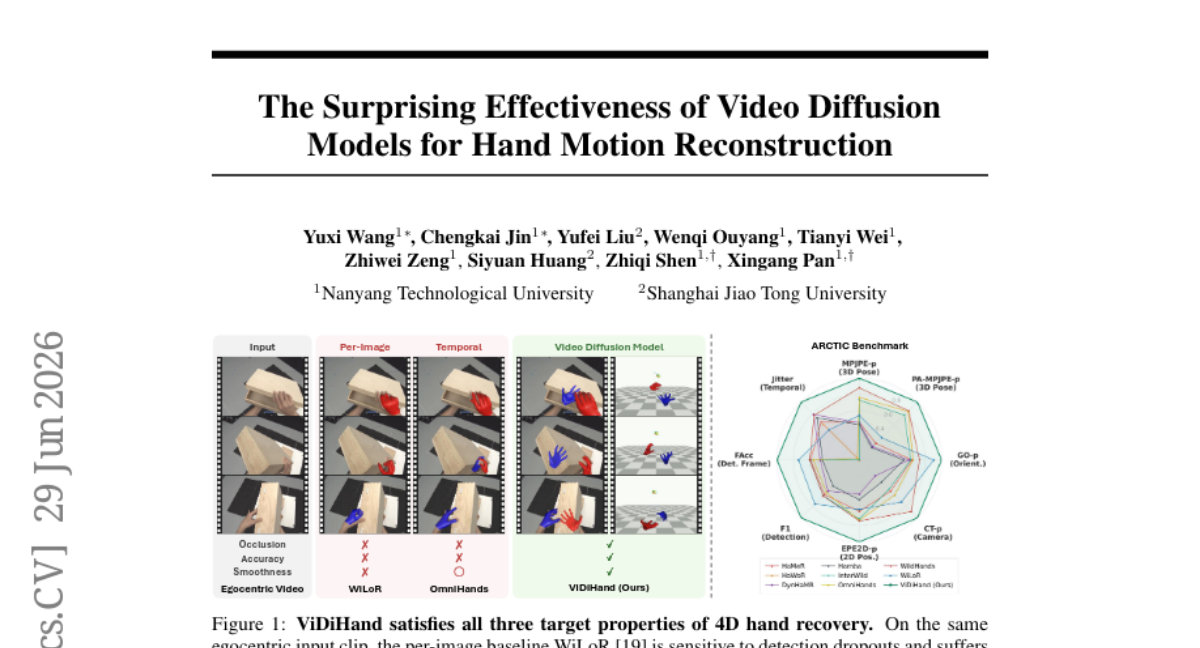
17. The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
🔑 Keywords: 4D hand motion reconstruction, video diffusion models, hand-overlay rendering, pretrained video diffusion model
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to reconstruct 4D hand motion directly from video frames without the need for detectors or optimization.
🛠️ Research Methods:
– Utilizes pretrained video diffusion model representations combined with hand-overlay rendering to recover hand pose from video without relying on detectors or infillers.
💬 Research Conclusions:
– ViDiHand outperforms existing methods by avoiding the limitations of detector and temporal module reliance, establishing video diffusion models as a robust foundation for hand motion reconstruction and enabling scalable data collection for embodied AI.
👉 Paper link: https://huggingface.co/papers/2606.30308
18. Focusing on What Matters: Saliency-Harnessing Accurate Routing for Diffusion MoE
🔑 Keywords: SharpMoE, diffusion models, salient tokens, clean latent features, trajectory routing loss
💡 Category: Generative Models
🌟 Research Objective:
– SharpMoE aims to improve routing inefficiencies in diffusion models by employing clean latent features for salient token identification and using trajectory routing loss for precise compute allocation during multi-step denoising.
🛠️ Research Methods:
– The study introduces SharpMoE, a post-training framework with a saliency-harnessing accurate routing mechanism that utilizes noise-free guidance signals to improve routing, alongside a trajectory routing loss for optimal compute allocation.
💬 Research Conclusions:
– SharpMoE serves as a versatile, plug-and-play solution that enhances pretrained MoE models, achieving state-of-the-art performance in visual generation.
👉 Paper link: https://huggingface.co/papers/2606.26938

19. Delayed Verification Destabilizes Multi-Agent LLM Belief: Instability Thresholds and Optimal Corrector Placement
🔑 Keywords: Multi-agent LLM systems, Verification delay, Oscillation, Grounded factual answering, Stability threshold
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the instability in multi-agent large language model systems caused by delayed verification processes and explores how grounded factual answering can stabilize these systems.
🛠️ Research Methods:
– The research models the verification process as delayed consensus on a graph, utilizing spectral decomposition and grounded Laplacian to establish a stability threshold for verification. It also employs a supermodular placement objective and a greedy approximation rule to optimize corrector agent placement.
💬 Research Conclusions:
– It concludes that immediate and accurate verification mitigates oscillations in Multi-agent LLM systems. Grounded factual answering acts as an absorbing boundary, effectively stabilizing the system and indicating that instability is peculiar to signed-belief tasks while grounded verification maintains stability.
👉 Paper link: https://huggingface.co/papers/2606.27409

20. A Gravitational Interpretation of Fine-Tuning Reversion
🔑 Keywords: post-alignment, fine-tuning, dominant manifold, alignment
💡 Category: Generative Models
🌟 Research Objective:
– The paper investigates the phenomenon of post-alignment safety degradation due to geometric properties of training history, hypothesizing that large early training phases create dominant behavioral manifolds impacting later stages.
🛠️ Research Methods:
– The study utilizes a geometric interpretation of fine-tuning reversion, known as the gravitational interpretation, and examines representational drift aligning with a history-defined reversion direction (v_rev).
💬 Research Conclusions:
– Findings highlight that selectively blocking motion along v_rev can significantly alter final alignment and reduce harmfulness, suggesting v_rev as a causally relevant mediator of early post-alignment reversion without claiming it as the sole safety direction.
👉 Paper link: https://huggingface.co/papers/2606.28525

21. MirrorPPR: Exemplar-Based Portrait Photo Retouching
🔑 Keywords: Exemplar-Based Portrait Photo Retouching, Diffusion Transformer, LoRA, Self-Augmented Training Data
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce a novel Exemplar-Based Portrait Photo Retouching framework that excels at subtle structural retouching and identity preservation.
🛠️ Research Methods:
– A Retouching Operation Extractor captures differences from exemplars, integrated into a Diffusion Transformer via LoRA for effective retouching.
– Use of a newly introduced advanced data self-augmentation paradigm to align retouching operations and support with MirrorPPR47M dataset for curriculum learning.
💬 Research Conclusions:
– The proposed MirrorPPR framework outperforms existing methods in both retouch quality and identity preservation, with significant advancements demonstrated through extensive experiments.
👉 Paper link: https://huggingface.co/papers/2606.29308

22. Learning Transferable Dynamics Priors from Action to World Modeling
🔑 Keywords: action-conditioned, world modeling, dynamics priors, robot learning, pretraining
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The study aims to explore action-conditioned world modeling as a scalable approach to learn transferable dynamics priors for robot learning.
🛠️ Research Methods:
– Pretraining a multi-view interactive base diffusion world model, A2World, on large-scale robot manipulation data with real action annotations.
– Validating learned dynamics priors through adaptation into real-world simulator (A2World-sim) and video-action joint prediction model (A2World-policy).
💬 Research Conclusions:
– Action-conditioned world model pretraining provides transferable dynamics priors that enhance both simulator-based policy evaluation and policy-centric robot learning.
👉 Paper link: https://huggingface.co/papers/2606.29501

23. Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
🔑 Keywords: ILLUME-X, Multimodal Intelligence, Interleaved Text-Image Sequences, Multimodal Data Efficiency, Progressive Training Strategy
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This paper introduces ILLUME-X, a unified multimodal paradigm aimed at enhancing the generation of interleaved text-image sequences by improving data efficiency and training stability.
🛠️ Research Methods:
– The research employs an expanded training data pipeline specialized for interleaved text-image generation, a progressive training strategy with self-adaptive objectives, and an ILScore evaluation method for these sequences.
💬 Research Conclusions:
– ILLUME-X outperforms previous unified models in various text-image generation tasks such as style transfer, image decomposition, and storytelling.
👉 Paper link: https://huggingface.co/papers/2606.30054

24. Mind the Heads: Topological Representation Alignment for Multimodal LLMs
🔑 Keywords: HeRA, Representation alignment, Multimodal Large Language Models, attention heads, visual hallucinations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to improve performance in vision-centric tasks and reduce visual hallucinations by aligning individual attention heads in Multimodal Large Language Models (MLLMs) to maintain local neighborhood relationships across modalities.
🛠️ Research Methods:
– The study introduces Head-Wise Representation Alignment (HeRA), applying a contrastive objective at the level of individual attention heads. This method uses the Mutual K-Nearest Neighbor (MKNN) alignment metric to select specific attention heads based on their alignment score.
💬 Research Conclusions:
– HeRA consistently enhances performance in various MLLMs across 18 benchmarks, effectively serving as a regularizer against visual hallucinations by reducing dependency on linguistic priors.
👉 Paper link: https://huggingface.co/papers/2606.23885

25.

26. RaysUp: Ultra-light Universal Feature Upsampling via Geometry-Aware Ray Representation
🔑 Keywords: RaysUp, Vision Foundation Models, feature upsampling, Geometry-Aware, Ray Positional Encoding
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce RaysUp, a task-agnostic framework for efficient and accurate reconstruction of high-resolution features.
🛠️ Research Methods:
– Utilizes a Spatially Decoupled Guidance Encoder and Any-Resolution Cross-Attention for flexible upsampling.
– Employs Ray Positional Encoding with 6D Plucker ray coordinates for geometric precision.
– Implements a Geometry-Aware Neighborhood Attention module for adaptive aggregation.
💬 Research Conclusions:
– RaysUp achieves state-of-the-art performance with only 16% of the parameters of existing methods and significantly faster inference, showcasing improved accuracy-efficiency trade-offs.
👉 Paper link: https://huggingface.co/papers/2606.22749

27. Large-Scale Tunnel Air-Ground Collaboration With FLISP: Fast LiDAR-IMU Synchronized Path Planner
🔑 Keywords: Hydropower tunnel inspection, FLISP, LiDAR-IMU, UGV-UAV, robotic inspection
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The research aims to improve the efficiency and safety of hydropower tunnel inspections by developing a novel mapless planning framework named FLISP (Fast LiDAR-IMU Synchronized Path Planner) for cooperative Unmanned Ground Vehicle (UGV) and Unmanned Aerial Vehicle (UAV) inspection.
🛠️ Research Methods:
– The study introduces a unified architecture where a single UGV-mounted LiDAR-IMU suite orchestrates synchronized path planning. It utilizes platform-specific algorithms, including an enhanced Firefly Algorithm for UGV obstacle avoidance and a dynamic iterative optimizer for UAV flight. The approach avoids traditional mapping bottlenecks by eliminating map rasterization and sampling instability challenges.
💬 Research Conclusions:
– FLISP achieves superior performance with a 100% success rate and only 7 ms latency, leading to substantial speed improvements over existing grid-based and sampling-based methods. Validated in a 1.2 km operational hydropower tunnel, this framework offers a scalable and efficient solution for robotic inspection tasks in complex linear infrastructures.
👉 Paper link: https://huggingface.co/papers/2606.25393

28. One Scene, Two Depths: Probing Geometric Ambiguity in Monocular Foundation Models
🔑 Keywords: Monocular Depth Estimation, Depth Foundation Models, RGB, Laplacian Visual Prompting, MultiDepth-3k
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce and utilize the MultiDepth-3k (MD-3k) benchmark for evaluating depth-layer preference and multi-layer spatial relationship accuracy.
🛠️ Research Methods:
– Implementation of a sparse two-layer ordinal benchmark and analysis of RGB input response with and without Laplacian Visual Prompting.
💬 Research Conclusions:
– Different models show varying preferences for depth layers when given standard RGB inputs. Laplacian Visual Prompting can alter the reported layer in certain models. Such findings encourage a reconsideration of depth supervision, acknowledging multiple valid 3D interpretations.
👉 Paper link: https://huggingface.co/papers/2606.29600
29. Geometric Stability of Neural Population Codes: Regional Variation, Behavioral Relevance, and Circuit Dependence
🔑 Keywords: geometric stability, temporal stability, neural representation, trial-by-trial neural-behavioral coupling, attractor network model
💡 Category: Foundations of AI
🌟 Research Objective:
– To introduce and formalize the concept of geometric stability as an independent axis of representational analysis in neural population studies.
🛠️ Research Methods:
– Utilizing Spearman rank correlation to measure geometric stability via split-half representational dissimilarity matrices across 229 area-session observations in a visual discrimination task.
💬 Research Conclusions:
– Geometric stability is functionally relevant and correlates with trial-by-trial neural-behavioral coupling, establishing it as distinct from temporal stability and decoding accuracy. The results suggest a circuit-level account for geometric stability through an attractor network model with recurrent excitatory coupling.
👉 Paper link: https://huggingface.co/papers/2606.29655

30. PoseShield: Neural Collision Fields for Human Self-Collision Resolution
🔑 Keywords: PoseShield, SMPL, self-collision, neural collision constraint, Eikonal regularization
💡 Category: Computer Vision
🌟 Research Objective:
– Address self-collision issues in SMPL-based human pose estimation through neural collision constraints and constrained optimization.
🛠️ Research Methods:
– Developed PoseShield that operates in SMPL pose space, formulating collision correction as a constrained optimization problem connected with the Eikonal equation to enhance stability and robustness.
💬 Research Conclusions:
– PoseShield allows for effective self-collision resolution in human motion sequences, achieving a 95.8% success rate and outperforming existing approaches on an SMPL pose benchmark.
👉 Paper link: https://huggingface.co/papers/2606.29686

31. LLM Program Optimization via Retrieval Augmented Search
🔑 Keywords: Blackbox Adaptation, Retrieval Augmented Search, Program Optimization, AEGIS, Large Language Models
💡 Category: Foundations of AI
🌟 Research Objective:
– To enhance program optimization performance for C++ and Python code using blackbox adaptation methods.
🛠️ Research Methods:
– Introduction of a Retrieval Augmented Search (RAS) method which performs beam search over candidate optimizations using in-context examples from a dataset of slow-fast program pairs.
– Proposal of AEGIS, a method for improving interpretability by decomposing training examples into atomic edits.
💬 Research Conclusions:
– RAS outperforms prior blackbox adaptation strategies by up to 2.06 times in optimizing C++ programs.
– AEGIS leads to 1.37 times better performance with smaller edits.
– RAS improves the mean runtime percentile of Python programs by 10.27 compared to baselines.
👉 Paper link: https://huggingface.co/papers/2501.18916

32. Drop-Then-Recovery: How Redundant Are Vision-Language-Action Models?
🔑 Keywords: Vision-Language-Action models, language backbones, robotic manipulation, transformer block removal, vision and action pathways
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To investigate the redundancy of language backbones in Vision-Language-Action (VLA) models used for robotic manipulation tasks and determine the necessity of different model components for closed-loop control.
🛠️ Research Methods:
– The study used a method called Drop-Then-Recovery (DTR) which involves removing selected transformer blocks and fine-tuning the model to assess the necessity of the removed capacity. Additionally, GateProbe was used as a sensitivity metric to rank blocks by their contribution to downstream action loss.
💬 Research Conclusions:
– Language backbones are highly redundant in standard robotic manipulation tasks, while vision and action pathways are crucial and less tolerant to removal. Reducing the number of language blocks can improve model performance, indicating the need for future models to distribute capacity more effectively across language, vision, and action components.
👉 Paper link: https://huggingface.co/papers/2606.27755

33. ReasoningLens: Hierarchical Visualization and Diagnostic Auditing for Large Reasoning Models
🔑 Keywords: ReasoningLens, Large Reasoning Models, hierarchical visualization, diagnostic auditing, Chain-of-Thought
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to present ReasoningLens, an open-source framework designed for hierarchical visualization and diagnostic auditing of complex reasoning chains in large reasoning models to improve transparency and error detection.
🛠️ Research Methods:
– The study introduces interactive hierarchies separating high-level strategy from low-level execution and utilizes an agentic auditor for automated error detection and tool-augmented verification.
💬 Research Conclusions:
– ReasoningLens transforms unstructured textual data into actionable insights, enhancing interpretation, debugging, and optimization of next-generation reasoning-centric AI systems.
👉 Paper link: https://huggingface.co/papers/2606.23404

34. ZooClaw-FashionSigLIP2: Distilled Fine-tuning for Robust Fashion Retrieval
🔑 Keywords: Fashion-specialized, Vision-Language Model, Knowledge Distillation, Retrieval Performance, Weight Interpolation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to develop a fashion-specialized vision-language model, ZooClaw-FashionSigLIP2, that achieves superior retrieval performance by resolving the tradeoff between target distribution gains and broad generalization capabilities.
🛠️ Research Methods:
– The study employs full fine-tuning with knowledge distillation on curated in-domain data, followed by weight interpolation using a foundation vision-language encoder to enhance the specificity of fashion retrieval tasks.
💬 Research Conclusions:
– The ZooClaw-FashionSigLIP2 model outperforms existing methods, including LoRA and models with larger backbones, on all benchmarks. It introduces a new high-quality fashion retrieval benchmark and systematically analyzes widely-used benchmarks for structural biases, providing open access to model weights and evaluation artifacts.
👉 Paper link: https://huggingface.co/papers/2606.27708

35. SafePyramid: A Hierarchical Benchmark for In-context Policy Guardrailing
🔑 Keywords: SafePyramid, Guardrails, In-Context Policy Guardrailing, Safety Benchmark, Natural-Language Rules
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate guardrail systems’ ability to detect safety violations through in-context policy specification across various domains and complexity levels using the SafePyramid benchmark.
🛠️ Research Methods:
– The SafePyramid benchmark comprises 1,000 multi-turn conversations across 10 domains with 3,000 application-specific policies, containing 61,699 distinct natural-language rules, organized into three difficulty levels to test rule understanding, dependency reasoning, and policy framework adaptation.
💬 Research Conclusions:
– Key findings reveal that current guardrail systems face significant challenges, with the best-performing model, GPT-5.5, identifying complete violated rule sets in only 54.0%, 35.3%, and 12.9% of cases across the three difficulty levels, underscoring the need for more robust in-context policy guardrails.
👉 Paper link: https://huggingface.co/papers/2606.29887

36. Cognitive Episodes in LLM Reasoning Traces Enable Interpretable Human Item Difficulty Prediction
🔑 Keywords: Epi2Diff, Large Reasoning Models, cognitive episodes, human difficulty prediction, reasoning traces
💡 Category: AI in Education
🌟 Research Objective:
– To transform LRM reasoning traces into cognitive episodes to predict human item difficulty more accurately than existing methods.
🛠️ Research Methods:
– Introduced the Epi2Diff framework which maps LRM reasoning traces into cognitive episode sequences, grouping trace segments into functional problem-solving states.
– Combined episode-dynamic features with semantic item representations for human difficulty prediction.
💬 Research Conclusions:
– Epi2Diff consistently outperforms strong baselines, achieving an 8.1% average relative gain on SAT-derived classification benchmarks.
– Cognitive episodes in reasoning traces offer a predictive and interpretable process representation for human item difficulty, providing a new perspective for educational measurement with reasoning models.
👉 Paper link: https://huggingface.co/papers/2606.28186

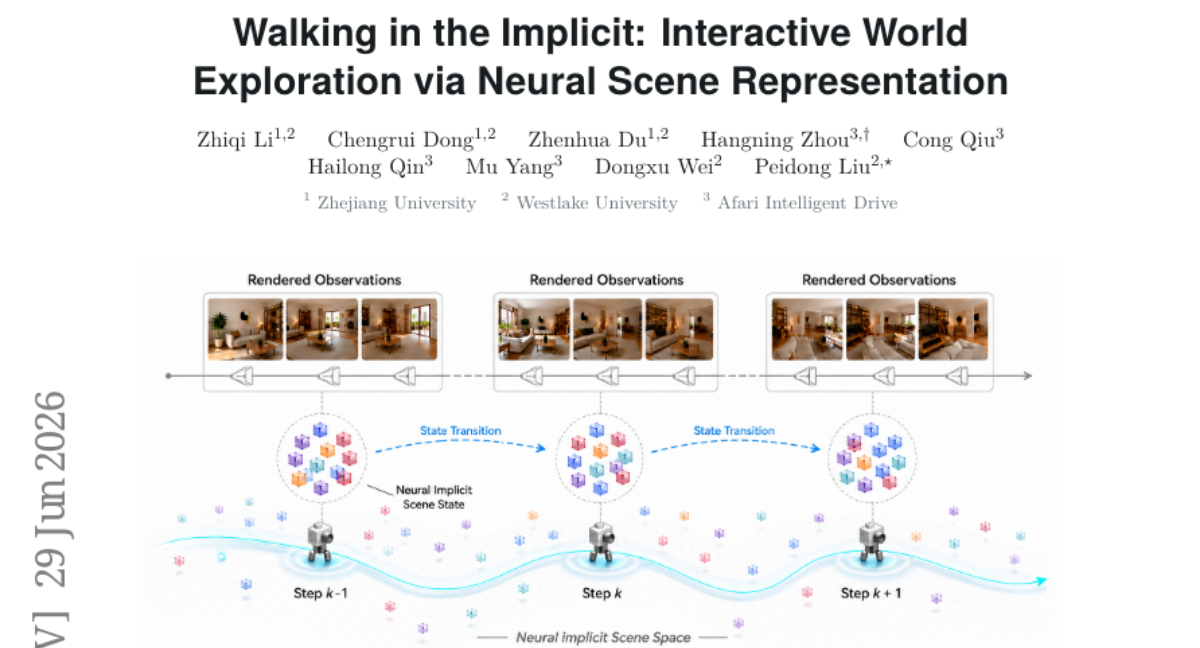
37. Walking in the Implicit: Interactive World Exploration via Neural Scene Representation
🔑 Keywords: Interactive video generation, Neural Implicit Scene, transformer VAE, diffusion transformer, long-horizon consistency
💡 Category: Generative Models
🌟 Research Objective:
– The aim is to enable efficient interactive video generation by representing scenes as compact neural implicit states and using a transformer model for trajectory-conditioned rendering.
🛠️ Research Methods:
– The introduction of NeuWorld, which utilizes a transformer VAE to learn Neural Implicit Scene (NIS) from sparse posed frames, while a diffusion transformer evolves NIS conditioned on future camera trajectories and geometry-aware history.
💬 Research Conclusions:
– NeuWorld achieves strong long-horizon consistency and favorable inference efficiency, demonstrating the capability of generating interactive video sequences without the need for pretrained video backbones or auxiliary 3D reconstructors.
👉 Paper link: https://huggingface.co/papers/2606.30045
38. PolicyGuard: A Dialogue-Grounded Sub-Agent Verifier for Policy Adherence in LLM Agents
🔑 Keywords: POLICYGUARD, LLM agents, policy adherence, conversation context, self-reasoning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective of the study is to improve policy adherence in LLM agents by introducing a sub-agent verifier called POLICYGUARD that provides contextual reasoning and feedback across multi-turn interactions.
🛠️ Research Methods:
– The research utilized POLICYGUARD, which shares the agent’s dialogue view, reasons over policies contextually, and offers actionable feedback for subsequent interactions. Performance was tested on tau^2-BENCH airline across multiple vendors.
💬 Research Conclusions:
– POLICYGUARD significantly enhances policy adherence, achieving higher recall for policy violations while reducing unnecessary blocks compared to argument-level guards. Improvements were observed across multiple trials, with notable gains in compliance.
👉 Paper link: https://huggingface.co/papers/2606.29225

39. How Good Can Linear Models Be for Time-Series Forecasting?
🔑 Keywords: Time-series forecasting, preprocessing, Ridge regression, context length, regularization
💡 Category: Machine Learning
🌟 Research Objective:
– Investigate how preprocessing optimizations, specifically in context length, normalization, and regularization, can improve the accuracy of time-series forecasting without scaling model architectures.
🛠️ Research Methods:
– Use Ridge regression as a testbed to explore context length, local normalization, and regularization across eight standard benchmarks.
💬 Research Conclusions:
– Optimal lookback is series-specific and forecast horizon non-monotonic.
– Prefer normalization over a learned trailing fraction rather than the full context.
– Varying degrees of hyperparameter sharing can outperform traditional models, revealing data structures typically absorbed by larger models.
👉 Paper link: https://huggingface.co/papers/2606.27282
40. Nemotron-Labs-Diffusion-Image: Advancing Masked Discrete Diffusion for High-Resolution Image Synthesis
🔑 Keywords: Masked Discrete Diffusion Model, text-to-image synthesis, token-editing mechanism, Grouped Cross-Entropy, training efficiency
💡 Category: Generative Models
🌟 Research Objective:
– To develop a state-of-the-art masked discrete diffusion model, Nemotron-Labs-Diffusion-Image, for high-resolution text-to-image synthesis addressing challenges in token refinement and training efficiency.
🛠️ Research Methods:
– Implementing a token-editing mechanism to revise unmasked tokens during inference and using a Grouped Cross-Entropy objective to improve optimization by reducing signal sparsity.
💬 Research Conclusions:
– The new approaches significantly enhance the training efficiency and image fidelity of masked discrete image generators, achieving high performance on benchmarks such as GenEval, DPG, and HPSv3.
👉 Paper link: https://huggingface.co/papers/2606.29814

41. Interleaved Speech Language Models Latently Work In Text
🔑 Keywords: Interleaved speech-text language models, Speech language models, Logit lens, Intermediate layers, Spoken knowledge abilities
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to analyze interleaved speech-text language models (SLMs) to understand the implicit transcription phase where text becomes decodable in intermediate layers, and its underlying mechanisms.
🛠️ Research Methods:
– The research investigates different model families and sizes of interleaved speech-text LMs using the logit lens to gain insights into the interaction between speech and text modalities in the model’s latent space.
💬 Research Conclusions:
– The analysis reveals an implicit transcription phase in SLMs where spoken words are decodable as text tokens, this occurs in intermediate layers and is observed in up to 77% of the data. The study also examines the role of interleaving data and pre-initialization from text language models in eliciting this behavior, providing insights that could influence the optimization of SLMs.
👉 Paper link: https://huggingface.co/papers/2606.22473

42. SWE-Together: Evaluating Coding Agents in Interactive User Sessions
🔑 Keywords: SWE-Together, multi-turn coding benchmark, reactive LLM simulator, final correctness, interaction efficiency
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The objective is to evaluate coding agents in a dynamic, multi-turn environment, focusing on both the correctness of the final output and the efficiency of interactions.
🛠️ Research Methods:
– Construction of SWE-Together, a benchmark from real user-agent interactions alongside a reactive LLM simulator to simulate real-time feedback and interaction flow.
💬 Research Conclusions:
– Findings indicate that stronger coding agents not only achieve better correctness in the final repository but also enhance the user experience by reducing the need for corrective feedback.
👉 Paper link: https://huggingface.co/papers/2606.29957

43. TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
🔑 Keywords: Tool-Augmented Credit Optimization (TACO), Differential Answer-Probe Reward (DAPR), Outcome-Gated Advantage Routing (OGAR), code-tool agents, multimodal agent performance
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to enhance the performance of multimodal agents by effectively distinguishing useful, redundant, or misleading code operations using TACO.
🛠️ Research Methods:
– The study introduces TACO, a GRPO variant for code-tool agents, employing two advantage channels: DAPR and OGAR, combined with a two-stage SFT+RL training pipeline.
💬 Research Conclusions:
– Extensive experiments demonstrate that TACO leads to consistent accuracy improvements and enables agents to invoke tools effectively only when beneficial.
👉 Paper link: https://huggingface.co/papers/2606.30251

44. Monte Carlo Energy Aggregation for Mobile 3D Gaussian Splatting
🔑 Keywords: Real-time Rendering, 3D Gaussian Splatting, Mobile Platforms, Multi-view Densification, Spherical Harmonics
💡 Category: Computer Vision
🌟 Research Objective:
– To develop Flux-GS, a real-time 3D Gaussian Splatting method for achieving high-fidelity rendering on mobile platforms while significantly reducing overhead.
🛠️ Research Methods:
– Proposed a Monte Carlo Specular Energy Aggregator to efficiently preserve lighting features in a compact latent space without pre-training.
– Developed an Attribute-Conditioned SH Enhancement module to enhance first-order SH representation without additional inference costs.
– Introduced a Multi-view Alpha-based Densification and Pruning strategy to ensure consistency and remove redundant primitives across multiple views.
💬 Research Conclusions:
– Flux-GS achieves substantial parameter reduction and maintains competitive visual quality, providing a scalable solution for real-time mobile rendering.
👉 Paper link: https://huggingface.co/papers/2606.30017
45. Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
🔑 Keywords: Multimodal Large Language Models, Video Question Answering, Keyframe Extraction, Video Understanding, GUI Agents
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce VG-GUIBench, a new benchmark evaluating the capability of multimodal large language models to learn from video tutorials and perform GUI tasks.
🛠️ Research Methods:
– The development of TASKER, a keyframe extraction algorithm focusing on task relevance and scene dynamics to enhance performance in video understanding tasks.
💬 Research Conclusions:
– TASKER significantly improves performance on VideoQA and video-guided agentic tasks by outperforming baseline models on specific datasets, highlighting the potential of enhanced keyframe extraction methods.
👉 Paper link: https://huggingface.co/papers/2606.29445

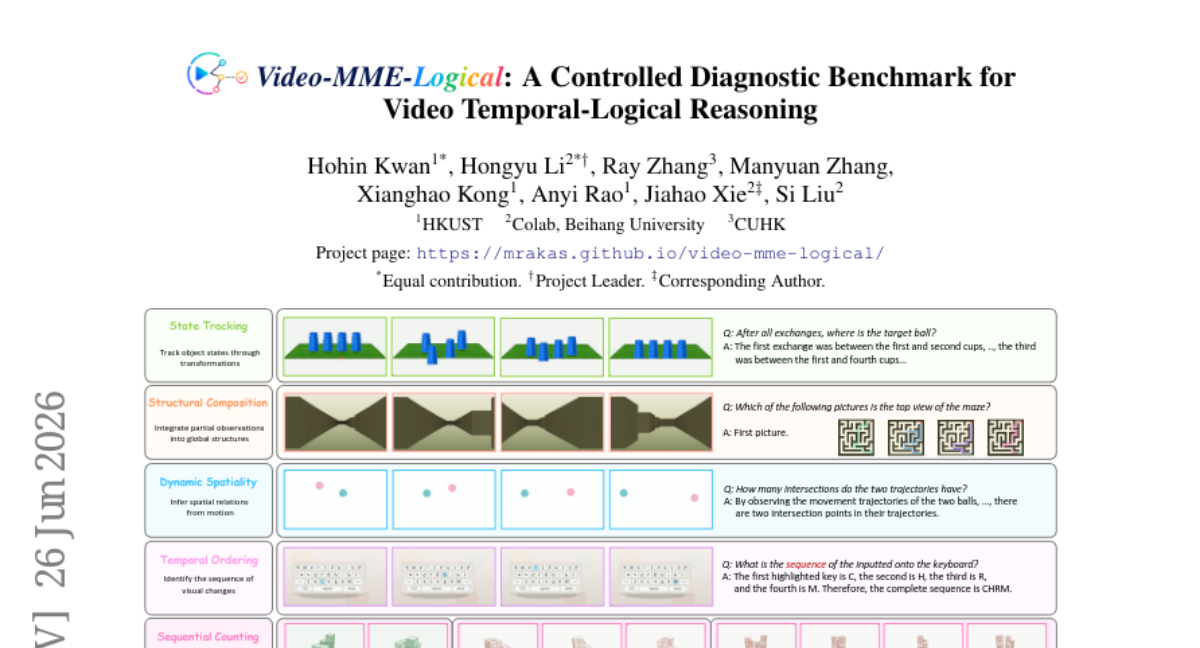
46. Video-MME-Logical: A Controlled Diagnostic Benchmark for Video Temporal-Logical Reasoning
🔑 Keywords: Multimodal Large Language Models, video temporal-logical reasoning, Video-MME-Logical, temporal-logical operations, Supervised fine-tuning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study evaluates the ability of multimodal large language models (MLLMs) to perform temporal-logical reasoning over dynamic visual evidence instead of simple object recognition.
🛠️ Research Methods:
– Introduction of the Video-MME-Logical benchmark organized around five temporal-logical operations to assess models’ abilities through controlled object states and logical compositions.
💬 Research Conclusions:
– The benchmark reveals a significant gap between human and model performance in temporal-logical reasoning, with supervised fine-tuning improving but not closing this gap, highlighting the need for further analysis and enhancement of MLLMs.
👉 Paper link: https://huggingface.co/papers/2606.27828
47. Beyond IID: How General Are Tabular Foundation Models, Really?
🔑 Keywords: Tabular foundation models, Predictive machine learning, Benchmarking, Data Foundry, IID data
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to create a unified framework, BeyondArena, for evaluating tabular foundation models across diverse tasks and data types to enable a more comprehensive understanding of their capabilities.
🛠️ Research Methods:
– Introduced Data Foundry, a Python framework and metadata schema, for curating a wide range of tabular datasets, enabling unified benchmarking beyond standard benchmarks.
💬 Research Conclusions:
– Tabular foundation models perform well on small to medium IID datasets, while traditional and deep learning models excel on larger, more complex non-IID datasets. BeyondArena helps direct research towards more demanding tabular data challenges.
👉 Paper link: https://huggingface.co/papers/2606.30410

48. TUA-Bench: A Benchmark for General-Purpose Terminal-Use Agents
🔑 Keywords: TUA-Bench, Terminal-Use Agents, General-purpose Agents, Execution-based Scoring Protocol, Digital Activities
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces TUA-Bench, a comprehensive benchmark designed to evaluate general-purpose terminal-use agents, thereby uncovering performance gaps among current leading agents.
🛠️ Research Methods:
– TUA-Bench includes 120 real-world tasks spanning five task families, encompassing digital activities and specialized workflows, evaluated by an execution-based scoring protocol in real terminal environments.
💬 Research Conclusions:
– It was found that the top-performing agent, Claude Code with Claude Opus, achieved a 65.8% overall performance, highlighting significant room for improvement across both general and specialized task tracks.
👉 Paper link: https://huggingface.co/papers/2606.28480

49. LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
🔑 Keywords: Streaming Video Editing, Real-Time Responsiveness, Content Preservation, Three-Stage Distillation Pipeline, AR-oriented Mask Cache
💡 Category: Computer Vision
🌟 Research Objective:
– The study introduces a novel framework for streaming video editing that ensures frame-by-frame causal editing with strong content preservation and real-time responsiveness.
🛠️ Research Methods:
– Utilizes a three-stage distillation pipeline to transfer editing capabilities from a bidirectional foundation model to a unidirectional streaming editor.
– Implements an AR-oriented mask cache to minimize redundant processing and accelerate inference for real-time deployment.
💬 Research Conclusions:
– The proposed framework significantly improves visual quality and inference speed, achieving 12.66 FPS, making it highly suitable for interactive and augmented reality applications.
👉 Paper link: https://huggingface.co/papers/2606.26740