AI Native Daily Paper Digest – 20250129
1. SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
🔑 Keywords: supervised fine-tuning, reinforcement learning, model generalization, text-based rule variants, visual variants
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore the differences in generalization and memorization capabilities between supervised fine-tuning (SFT) and reinforcement learning (RL) in foundation models.
🛠️ Research Methods:
– Utilization of GeneralPoints, an arithmetic reasoning card game, and V-IRL, a real-world navigation environment, to evaluate model generalization on unseen textual and visual variants.
💬 Research Conclusions:
– RL, particularly with outcome-based rewards, demonstrates superior generalization across both textual and visual domains, whereas SFT tends to memorize training data.
– SFT plays a crucial role in stabilizing model outputs for effective RL training, enhancing the model’s ability to gain from RL’s generalization strengths.
👉 Paper link: https://huggingface.co/papers/2501.17161

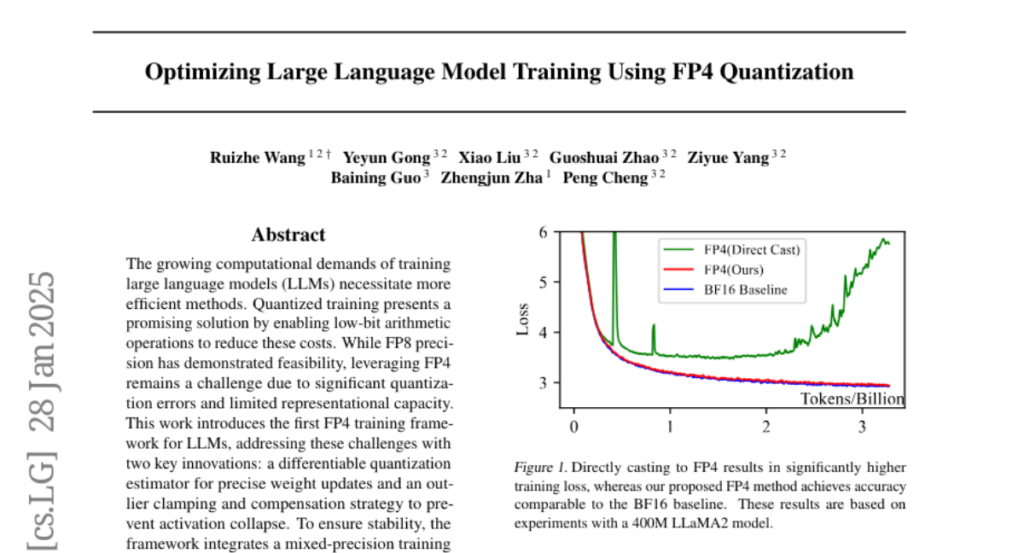
2. Optimizing Large Language Model Training Using FP4 Quantization
🔑 Keywords: Large Language Models, Quantized Training, FP4, Low-Bit Arithmetic, Mixed-Precision Training
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce a FP4 training framework for Large Language Models (LLMs) that addresses quantization errors and limited representational capacity challenges.
🛠️ Research Methods:
– Utilization of a differentiable quantization estimator for precise weight updates.
– Implementation of an outlier clamping and compensation strategy to prevent activation collapse.
– Integration of a mixed-precision training scheme and vector-wise quantization for ensuring stability.
💬 Research Conclusions:
– The proposed FP4 framework achieves accuracy comparable to BF16 and FP8 with minimal degradation.
– It effectively scales to 13B-parameter LLMs trained on up to 100B tokens.
– Sets a foundation for efficient ultra-low precision training with next-generation hardware supporting FP4.
👉 Paper link: https://huggingface.co/papers/2501.17116
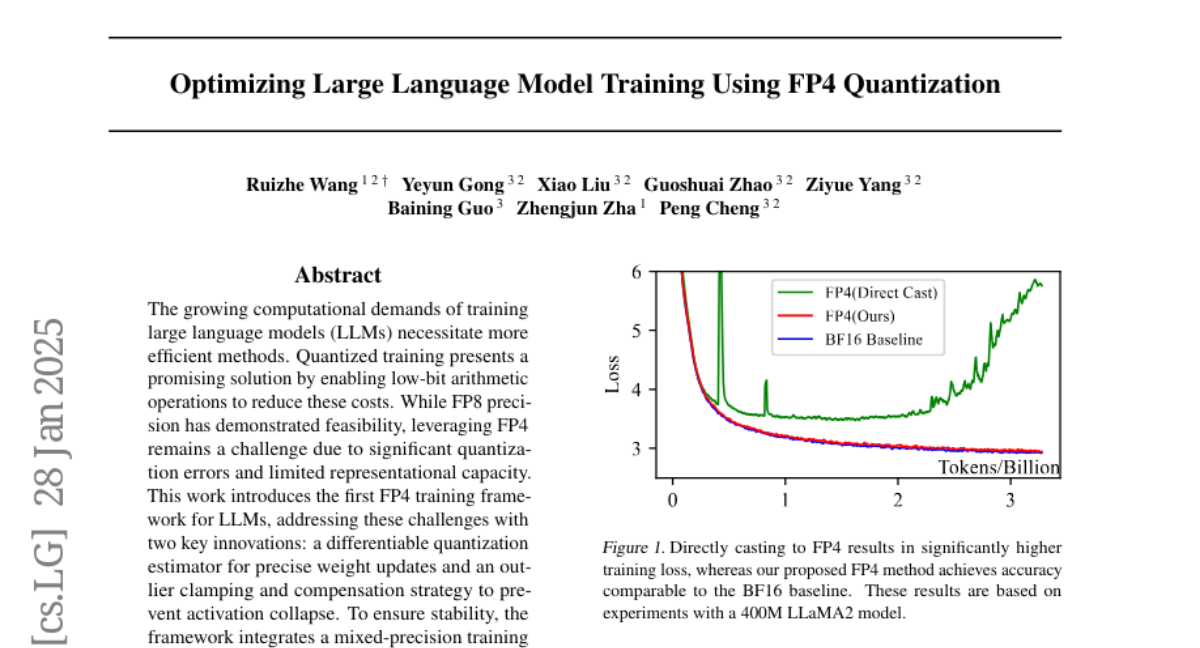
3. Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
🔑 Keywords: Tokenization, Large Language Models, Over-Tokenized Transformers, Input Vocabulary, Language Modeling
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore and enhance the influence of tokenization on model scaling and performance in large language models by introducing Over-Tokenized Transformers.
🛠️ Research Methods:
– Implemented a framework to decouple input and output vocabularies, scaling up input vocabularies using multi-gram tokens. Conducted extensive experiments to analyze the relationship between input vocabulary size and training loss.
💬 Research Conclusions:
– Larger input vocabularies consistently improve model performance, demonstrating a log-linear relationship with training loss. Achieving comparable performance to double-sized baselines without additional cost, highlighting the importance of tokenization in scaling laws.
👉 Paper link: https://huggingface.co/papers/2501.16975
4. DiffSplat: Repurposing Image Diffusion Models for Scalable Gaussian Splat Generation
🔑 Keywords: 3D content generation, DiffSplat, text-to-image diffusion models, 3D Gaussian splats, 3D coherence
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the challenges of high-quality 3D content generation from text or single images by introducing a new framework called DiffSplat.
🛠️ Research Methods:
– The authors propose a 3D generative framework that uses large-scale text-to-image diffusion models to generate 3D Gaussian splats. It employs a lightweight reconstruction model to produce multi-view splat grids and introduces a 3D rendering loss to ensure 3D consistency.
💬 Research Conclusions:
– Extensive experiments demonstrate the superiority of DiffSplat in text- and image-conditioned generation tasks, with thorough ablation studies validating the effectiveness of each design choice and providing insights into the framework’s underlying mechanism.
👉 Paper link: https://huggingface.co/papers/2501.16764
5. Open Problems in Mechanistic Interpretability
🔑 Keywords: Mechanistic Interpretability, Neural Networks, Computational Mechanisms, Socio-technical Challenges, AI System Behavior
💡 Category: Foundations of AI
🌟 Research Objective:
– To understand the computational mechanisms of neural networks for achieving concrete scientific and engineering goals.
🛠️ Research Methods:
– Requires both conceptual and practical improvements in methods to gain deeper insights.
💬 Research Conclusions:
– There are many open problems that need solutions, and the field must address socio-technical challenges influencing their work.
👉 Paper link: https://huggingface.co/papers/2501.16496

6. Low-Rank Adapters Meet Neural Architecture Search for LLM Compression
🔑 Keywords: Large Language Models, low-rank adapters, parameter-efficient fine-tuning, Neural Architecture Search
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore innovative approaches that combine low-rank representations with Neural Architecture Search techniques for optimizing Large Language Models.
🛠️ Research Methods:
– Utilization of low-rank adapters and weight-sharing super-networks for parameter-efficient fine-tuning and deployment of large pre-trained models.
💬 Research Conclusions:
– Combined strategies significantly reduce memory footprints and inference times, enhancing the accessibility and scalability of Large Language Models in resource-constrained environments.
👉 Paper link: https://huggingface.co/papers/2501.16372

7. IndicMMLU-Pro: Benchmarking Indic Large Language Models on Multi-Task Language Understanding
🔑 Keywords: Indic languages, LLMs, NLP, Benchmark, AI
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a comprehensive benchmark, IndicMMLU-Pro, for evaluating Large Language Models across Indic languages using the MMLU Pro framework.
🛠️ Research Methods:
– The benchmark covers major Indic languages and includes tasks in language comprehension, reasoning, and generation, carefully crafted to address linguistic diversity.
💬 Research Conclusions:
– The IndicMMLU-Pro benchmark provides a standardized evaluation framework that aims to advance research in Indic language AI by facilitating the development of culturally sensitive models and provides baseline results from state-of-the-art multilingual models.
👉 Paper link: https://huggingface.co/papers/2501.15747

8. Histoires Morales: A French Dataset for Assessing Moral Alignment
🔑 Keywords: Alignment, Moral Reasoning, Language Models, French Language, Cultural Context
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address the gap in understanding how large language models handle moral reasoning in the French language by introducing the Histoires Morales dataset.
🛠️ Research Methods:
– Creation and refinement of a French dataset, Histoires Morales, derived from Moral Stories with translations validated by native speakers for cultural context alignment.
– Conducting preliminary experiments on the alignment and robustness of multilingual models using French and English data.
💬 Research Conclusions:
– Large Language Models (LLMs) are typically aligned with human moral norms by default but can be easily influenced by user-preference optimization for both moral and immoral content.
👉 Paper link: https://huggingface.co/papers/2501.17117

9. TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
🔑 Keywords: Causal language models, Knowledge distillation, Model compression, Temporally Adaptive Interpolated Distillation, Compact foundation models
💡 Category: Machine Learning
🌟 Research Objective:
– To address the challenges of deploying large causal language models into resource-constrained environments by using a novel approach for model compression called Temporally Adaptive Interpolated Distillation (TAID).
🛠️ Research Methods:
– Implementation of TAID to dynamically interpolate student and teacher distributions through an adaptive intermediate distribution. Theoretical analysis and empirical experiments are conducted to prove its efficacy.
💬 Research Conclusions:
– TAID effectively prevents mode collapse and addresses the capacity gap while balancing mode averaging and collapse. Experiments show superior performance in creating high-performing, efficient models, such as TAID-LLM-1.5B for language tasks and TAID-VLM-2B for vision-language tasks.
👉 Paper link: https://huggingface.co/papers/2501.16937
