AI Native Daily Paper Digest – 20250304

1. Visual-RFT: Visual Reinforcement Fine-Tuning
🔑 Keywords: Reinforcement Fine-Tuning, Visual-RFT, Large Vision-Language Models, Verifiable Reward
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– This study introduces Visual Reinforcement Fine-Tuning (Visual-RFT) to extend reinforcement fine-tuning applications to visual tasks using Large Vision-Language Models.
🛠️ Research Methods:
– Utilizes verifiable reward functions with a policy optimization algorithm to update models in visual tasks, demonstrating a paradigm shift in fine-tuning.
💬 Research Conclusions:
– Visual-RFT significantly enhances accuracy and generalization ability over baseline models in tasks like one-shot fine-grained image classification and few-shot object detection.
👉 Paper link: https://huggingface.co/papers/2503.01785

2. Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
🔑 Keywords: Phi-4-Mini, Phi-4-Multimodal, Multimodal Models, Reasoning Performance
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Phi-4-Mini and Phi-4-Multimodal, compact language and multimodal models that excel in reasoning and multimodal tasks.
🛠️ Research Methods:
– Development of Phi-4-Mini involved training on curated high-quality web and synthetic datasets with an expanded vocabulary and enhanced architecture for multilingual capabilities.
– Phi-4-Multimodal integrates text, vision, and speech/audio using LoRA adapters and modality-specific routers for versatile multi-modality support.
💬 Research Conclusions:
– Phi-4-Mini matches or outperforms larger models on math and coding tasks, with efficient long-sequence generation.
– Phi-4-Multimodal leads in multimodal integration capabilities, outperforming larger vision-language and speech-language models in diverse tasks.
👉 Paper link: https://huggingface.co/papers/2503.01743

3. Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
🔑 Keywords: Neural Radiance Fields, 3D Gaussian Splatting, Difix3D+, Single-step Diffusion Models, Photorealistic Rendering
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Difix3D+, a new pipeline to enhance 3D reconstruction and novel-view synthesis, addressing challenges in photorealistic rendering from extreme viewpoints.
🛠️ Research Methods:
– Utilization of a single-step image diffusion model, Difix, to enhance and remove artifacts in novel view renderings caused by underconstrained 3D representation regions.
💬 Research Conclusions:
– Difix3D+ improves underconstrained regions and overall 3D representation quality, achieving an average 2x improvement in FID score over baselines while maintaining 3D consistency, functioning as a general solution compatible with NeRF and 3DGS representations.
👉 Paper link: https://huggingface.co/papers/2503.01774

4. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
🔑 Keywords: Generative retrieval-based recommendation systems, OneRec, Mixture-of-Experts, Direct Preference Optimization
💡 Category: Generative Models
🌟 Research Objective:
– Introduce OneRec, a unified generative model, to enhance the performance of recommendation systems compared to traditional retrieve-and-rank strategies.
🛠️ Research Methods:
– Utilizes an encoder-decoder structure to encode user behavior and decode relevant content, employs a session-wise generation approach, and integrates an Iterative Preference Alignment module with Direct Preference Optimization.
💬 Research Conclusions:
– OneRec demonstrates significant improvements in recommendation quality, as evidenced by a 1.6% increase in user watch-time on the Kuaishou platform.
👉 Paper link: https://huggingface.co/papers/2502.18965

5. DiffRhythm: Blazingly Fast and Embarrassingly Simple End-to-End Full-Length Song Generation with Latent Diffusion
🔑 Keywords: music generation, latent diffusion, full-length songs, rapid inference, scalability
💡 Category: Generative Models
🌟 Research Objective:
– To introduce DiffRhythm, a novel model capable of generating complete songs with both vocal and accompaniment tracks.
🛠️ Research Methods:
– Utilizes a latent diffusion-based approach with a simple and non-autoregressive structure for fast inference and scalability.
💬 Research Conclusions:
– DiffRhythm achieves high musicality and intelligibility, synthesizes songs up to 4m45s in only ten seconds, and supports reproducibility with complete training code and pre-trained models.
👉 Paper link: https://huggingface.co/papers/2503.01183

6. When an LLM is apprehensive about its answers — and when its uncertainty is justified
🔑 Keywords: Uncertainty Estimation, Large Language Models, Token-wise Entropy, Model-as-Judge, Question-Answering
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore effective methods for uncertainty estimation in Large Language Models (LLMs), particularly for multiple-choice question-answering tasks.
🛠️ Research Methods:
– The research investigates token-wise entropy and model-as-judge (MASJ) as estimates for evaluating LLMs like Phi-4, Mistral, and Qwen, across various question topics and model sizes ranging from 1.5B to 72B parameters.
💬 Research Conclusions:
– Response entropy serves as a strong predictor of model errors in knowledge-dependent domains and indicates question difficulty, but this correlation diminishes in reasoning-dependent tasks. Existing bias in assessment samples necessitates balanced reasoning to fairly assess LLM performance.
👉 Paper link: https://huggingface.co/papers/2503.01688

7. From Hours to Minutes: Lossless Acceleration of Ultra Long Sequence Generation up to 100K Tokens
🔑 Keywords: Ultra-long sequences, Large language models, TOKENSWIFT
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to accelerate the generation of ultra-long sequences using large language models up to 100K tokens.
🛠️ Research Methods:
– Introduces TOKENSWIFT, a framework addressing challenges such as frequent model reloading, dynamic KV management, and repetitive generation to enhance efficiency.
💬 Research Conclusions:
– Experimental results show TOKENSWIFT achieving over 3 times speedup across various model scales and architectures, significantly reducing generation time and establishing it as a scalable solution.
👉 Paper link: https://huggingface.co/papers/2502.18890
8. Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
🔑 Keywords: Test-time inference, Reinforcement Learning, Cognitive behaviors, Self-improvement, Reasoning patterns
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate intrinsic properties that enable effective self-improvement in language models by analyzing cognitive behaviors.
🛠️ Research Methods:
– Introduce a framework to analyze cognitive behaviors in language models.
– Conduct systematic experimentation with controlled behavioral datasets.
– Use continued pretraining with data filtered to amplify reasoning behaviors.
💬 Research Conclusions:
– The presence of reasoning behaviors is crucial for a model’s capacity to improve, explaining why some models, like Qwen, are more successful than others under RL.
👉 Paper link: https://huggingface.co/papers/2503.01307

9. Liger: Linearizing Large Language Models to Gated Recurrent Structures
🔑 Keywords: Transformers, Linear Recurrent Modeling, Liger, Low-Rank Adaptation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To present Liger, a novel approach for converting pretrained language models into gated linear recurrent models without adding extra parameters.
🛠️ Research Methods:
– Utilizes Low-Rank Adaptation (LoRA) for lightweight fine-tuning.
– Introduces Liger Attention, a hybrid attention mechanism to efficiently linearize large language models.
💬 Research Conclusions:
– Liger boosts the performance of linearized gated recurrent models to match the original language models.
– Achieves competitive results across benchmarks with minimal pre-training tokens, validated on models with parameters ranging from 1B to 8B.
👉 Paper link: https://huggingface.co/papers/2503.01496

10. Qilin: A Multimodal Information Retrieval Dataset with APP-level User Sessions
🔑 Keywords: multimodal content, User-generated content, search and recommendation, Qilin, Deep Query Answering
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce a novel multimodal information retrieval dataset, Qilin, to enhance user experiences in complex systems with search and recommendation services.
🛠️ Research Methods:
– Compilation of a comprehensive dataset from Xiaohongshu, including image-text notes, video notes, and commercial notes, along with APP-level contextual signals and user feedback.
💬 Research Conclusions:
– Qilin dataset facilitates the development of advanced multimodal neural retrieval models and provides insights into the impact of a Deep Query Answering module on user search behavior.
👉 Paper link: https://huggingface.co/papers/2503.00501

11. Speculative Ad-hoc Querying
🔑 Keywords: Large Language Models, query execution, SpeQL, data analysis
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper investigates enhancing query execution speed by initiating processing before query completion using Large Language Models (LLMs).
🛠️ Research Methods:
– SpeQL system predicts incomplete SQL query structures based on database schema and user history, creating temporary tables for quicker access and providing real-time result speculation.
💬 Research Conclusions:
– SpeQL significantly reduced task completion time and query latency by up to 289 times, while maintaining reasonable operational costs, facilitating faster pattern discovery in datasets.
👉 Paper link: https://huggingface.co/papers/2503.00714
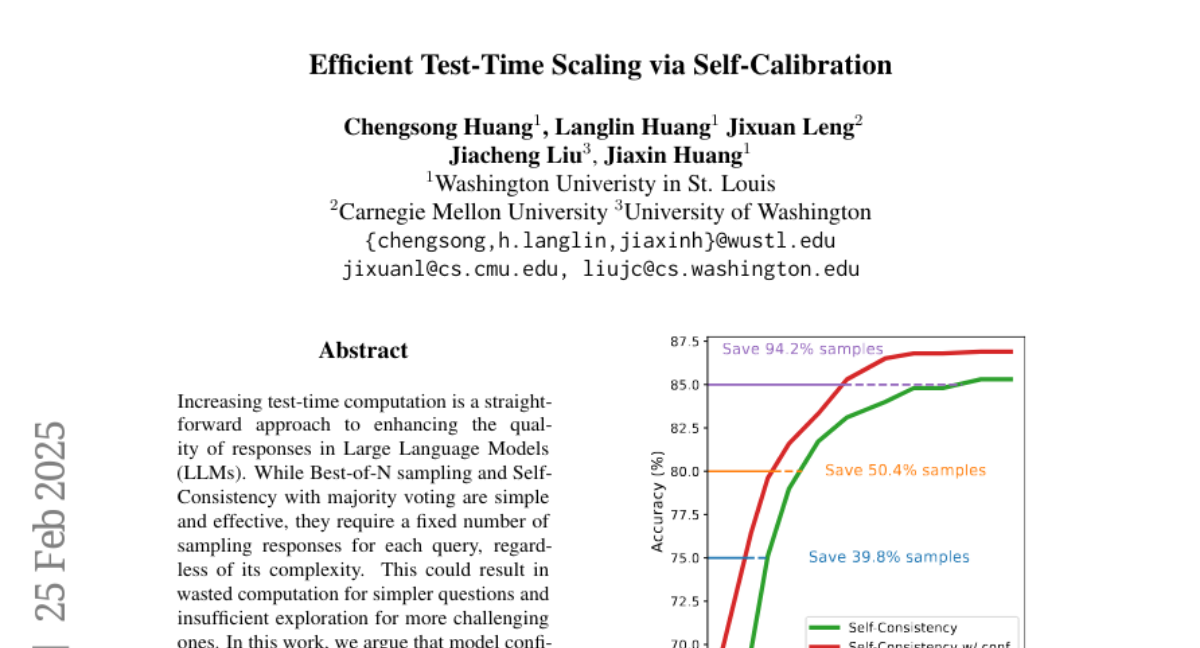
12. Efficient Test-Time Scaling via Self-Calibration
🔑 Keywords: Large Language Models, Self-Consistency, Confidence Estimation, Test-time Scaling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve the efficiency and quality of responses from Large Language Models (LLMs) during test time by utilizing model confidence for effective scaling.
🛠️ Research Methods:
– Introduced Self-Calibration by distilling Self-Consistency-derived confidence into the model for reliable test-time confidence estimation.
– Designed confidence-based efficient test-time scaling methods, such as Early-Stopping for Best-of-N sampling and Self-Consistency with calibrated confidence.
💬 Research Conclusions:
– The approach improves the MathQA accuracy from 81.0 to 83.6 with a limited sample budget, demonstrating the effectiveness of confidence-based sampling strategies at inference time.
👉 Paper link: https://huggingface.co/papers/2503.00031
13. DuoDecoding: Hardware-aware Heterogeneous Speculative Decoding with Dynamic Multi-Sequence Drafting
🔑 Keywords: Large language models, Speculative decoding, DuoDecoding, Inference speed, TTFT
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve inference speed and reduce time to the first token (TTFT) for large language models by addressing computational bottlenecks in speculative decoding.
🛠️ Research Methods:
– Developed DuoDecoding, deploying draft and target models on CPU and GPU respectively for parallel decoding, and using a hardware-aware optimal draft budget and dynamic multi-sequence drafting.
💬 Research Conclusions:
– DuoDecoding achieves up to 2.61x speedup in generation latency and reduces TTFT to 83% of the conventional method, demonstrating effectiveness across seven tasks.
👉 Paper link: https://huggingface.co/papers/2503.00784

14. Kiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
🔑 Keywords: Diffusion models, 3D content generation, Kiss3DGen, 2D image generation, 3D editing
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enhance the efficiency and quality of 3D content generation by leveraging well-trained 2D diffusion models.
🛠️ Research Methods:
– The paper introduces Kiss3DGen, which utilizes a fine-tuned diffusion model to generate “3D Bundle Image” from multi-view images and normal maps, thereby reconstructing 3D models.
💬 Research Conclusions:
– The study concludes that Kiss3DGen is an effective framework, capable of producing high-quality 3D models efficiently, and is compatible with various diffusion model techniques.
👉 Paper link: https://huggingface.co/papers/2503.01370

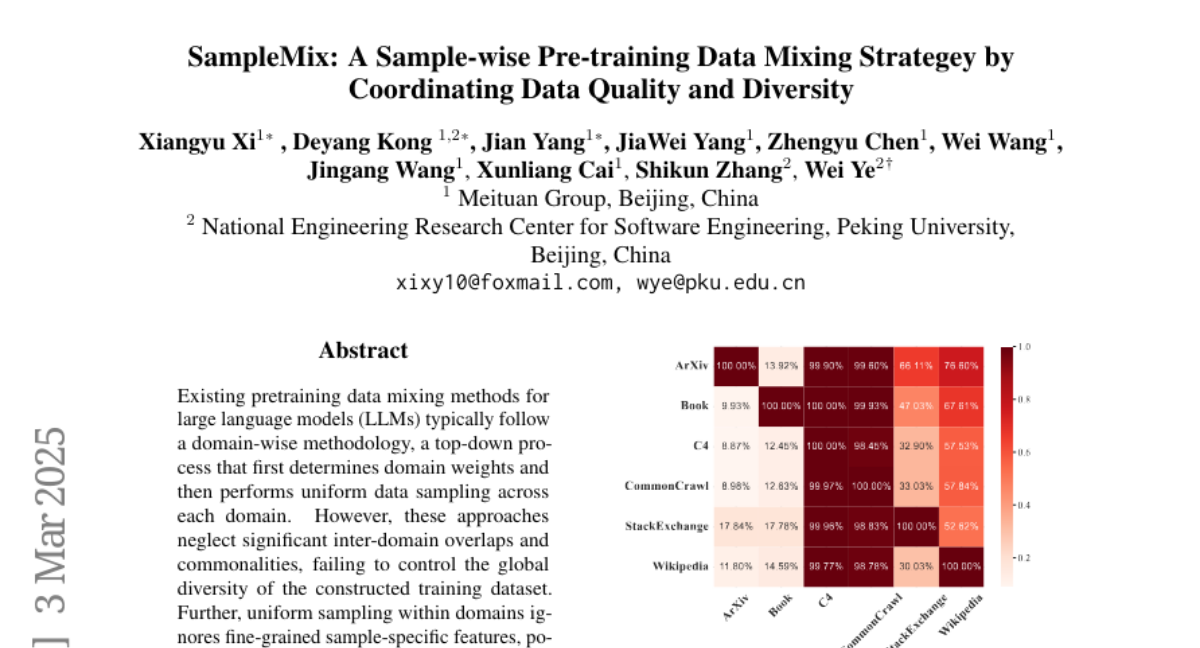
15. SampleMix: A Sample-wise Pre-training Data Mixing Strategey by Coordinating Data Quality and Diversity
🔑 Keywords: pretraining data mixing, large language models, global diversity, SampleMix
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the limitations of existing domain-wise pretraining data mixing methods for large language models by proposing a sample-wise data mixture approach.
🛠️ Research Methods:
– Implement a bottom-up paradigm for global cross-domain sampling, evaluating quality and diversity of each sample to determine dynamic optimal domain distribution.
💬 Research Conclusions:
– SampleMix surpasses existing methods in multiple downstream tasks, despite requiring 1.4x to 2.1x more training steps to achieve comparable performance, showing significant optimization potential.
👉 Paper link: https://huggingface.co/papers/2503.01506
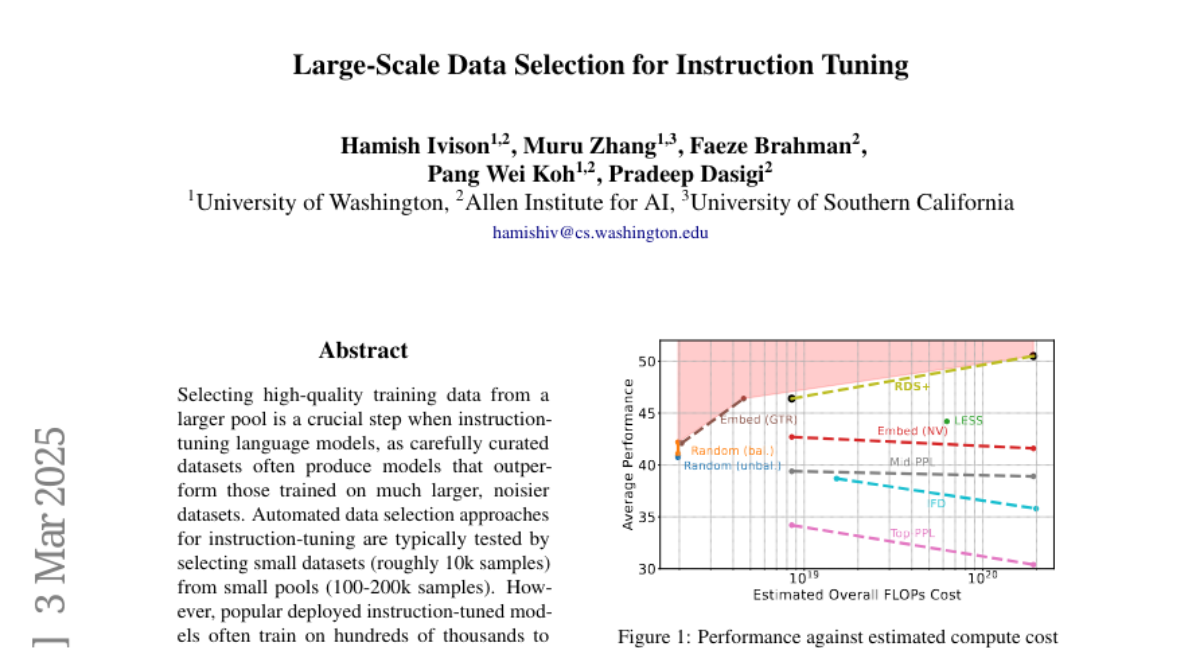
16. Large-Scale Data Selection for Instruction Tuning
🔑 Keywords: High-Quality Training Data, Instruction-Tuning, Representation-Based Data Selection (RDS+), Pretrained Language Models, Compute-Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate how well data selection methods scale when selecting high-quality training data for instruction-tuning language models from large data pools.
🛠️ Research Methods:
– Conducted systematic testing of data selection methods, comparing their performance across 7 diverse tasks with sample pools up to 5.8M samples, and introduced a variant of representation-based data selection (RDS+).
💬 Research Conclusions:
– Many newly proposed methods performed worse than random selection when dealing with large data pools, while the RDS+ method consistently outperformed these methods and showed better compute efficiency.
👉 Paper link: https://huggingface.co/papers/2503.01807
17. CodeArena: A Collective Evaluation Platform for LLM Code Generation
🔑 Keywords: Large Language Models, code generation, developer productivity, evaluation framework, automation-friendly APIs
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce CodeArena, a novel online evaluation framework for assessing code generation abilities of Large Language Models.
🛠️ Research Methods:
– Developed a collective evaluation mechanism that recalibrates model scores to alleviate biases from benchmark leakage.
– Offered open access to submitted solutions and test cases, along with automation-ready APIs.
💬 Research Conclusions:
– CodeArena presents a fair, accessible, and automated platform for evaluating the coding capabilities of LLMs, enhancing unbiased assessment and integration into development workflows.
👉 Paper link: https://huggingface.co/papers/2503.01295

18. Word Form Matters: LLMs’ Semantic Reconstruction under Typoglycemia
🔑 Keywords: Typoglycemia, Semantic Reconstruction, Large Language Models, Word Form, Contextual Information
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the mechanisms of semantic reconstruction in Large Language Models (LLMs), focusing on the roles of word form and contextual cues.
🛠️ Research Methods:
– Conducted controlled experiments with LLMs to analyze attention patterns and developed a metric called SemRecScore to quantify semantic reconstruction.
💬 Research Conclusions:
– Identified word form as the core factor influencing LLMs’ semantic reconstruction ability, with specialized attention heads extracting this information stably, unlike human adaptive strategies.
👉 Paper link: https://huggingface.co/papers/2503.01714

19. PodAgent: A Comprehensive Framework for Podcast Generation
🔑 Keywords: Audio Generation, Voice Matching, Expressive Speech, LLM-enhanced, Podcast-like Audio
💡 Category: Generative Models
🌟 Research Objective:
– To develop an effective framework, PodAgent, for generating podcast-like audio programs with in-depth content, appropriate voice production, and expressive delivery.
🛠️ Research Methods:
– Implementation of a Host-Guest-Writer multi-agent collaboration system for generating informative topic-discussion content.
– Construction of a voice pool for suitable voice-role matching and adoption of LLM-enhanced speech synthesis for generating expressive conversational speech.
💬 Research Conclusions:
– PodAgent significantly outperforms direct GPT-4 generation in topic-discussion dialogue, achieving 87.4% accuracy in voice-role matching, and generates more expressive speech through LLM-guided synthesis.
👉 Paper link: https://huggingface.co/papers/2503.00455

20. General Reasoning Requires Learning to Reason from the Get-go
🔑 Keywords: Large Language Models, Artificial General Intelligence, Reinforcement Learning, Knowledge Store
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To transition from Artificial Useful Intelligence (AUI) to Artificial General Intelligence (AGI) by enhancing the adaptive and robust reasoning capabilities of Large Language Models (LLMs).
🛠️ Research Methods:
– Proposing the disentanglement of reasoning and knowledge in LLMs through pre-taining to reason with Reinforcement Learning (RL), using synthetic tasks for learning reasoning priors, and employing small context windows to improve reasoning transferability.
💬 Research Conclusions:
– The integration of a reasoning system with a trained retrieval system and an extensive external memory bank overcomes many limitations of existing LLM architectures, enabling better reasoning in novel scenarios.
👉 Paper link: https://huggingface.co/papers/2502.19402

21. VideoUFO: A Million-Scale User-Focused Dataset for Text-to-Video Generation
🔑 Keywords: Text-to-video generative models, VideoUFO, YouTube, Creative Commons, VidProM
💡 Category: Generative Models
🌟 Research Objective:
– Introduce VideoUFO, a video dataset designed for aligning with users’ focus in real-world scenarios.
🛠️ Research Methods:
– Developed a video dataset with minimal overlap and videos sourced via YouTube’s official API under Creative Commons license.
– Identified specific user-focused topics and retrieved video clips with generated captions to support model training.
💬 Research Conclusions:
– Current models underperform in topics that are user-focused but lack specific training data.
– A model trained on VideoUFO dataset improves performance on challenging topics.
👉 Paper link: https://huggingface.co/papers/2503.01739

22. CLEA: Closed-Loop Embodied Agent for Enhancing Task Execution in Dynamic Environments
🔑 Keywords: LLMs, Closed-Loop Embodied Agent, task management, multimodal execution, dynamic environments
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To address the challenges of reliable subtask execution and one-shot success in dynamic environments for embodied systems by proposing the Closed-Loop Embodied Agent (CLEA).
🛠️ Research Methods:
– Developed a novel architecture using four specialized open-source LLMs for closed-loop task management, featuring an interactive task planner and a multimodal execution critic.
💬 Research Conclusions:
– CLEA achieves a 67.3% improvement in success rate and a 52.8% increase in task completion rate over the baseline model, enhancing robustness in task planning and execution in dynamic environments.
👉 Paper link: https://huggingface.co/papers/2503.00729

23. AI-Invented Tonal Languages: Preventing a Machine Lingua Franca Beyond Human Understanding
🔑 Keywords: Large Language Models, Machine-to-Machine Communication, Tonal Encoding, Information Density
💡 Category: Foundations of AI
🌟 Research Objective:
– To explore the potential of Large Language Models (LLMs) to develop private tonal languages for M2M communication, inspired by human cryptophasia and natural tonal languages.
🛠️ Research Methods:
– Implementation of a character-to-frequency mapping system using musical semitones to encode ASCII characters with a logarithmic progression, spanning from 220 Hz to over 50,000 Hz and including ultrasonic frequencies.
💬 Research Conclusions:
– Tonal encoding showcases the possibility of achieving information rates surpassing human speech while remaining partially beyond human perception. It provides a technical foundation for the emergence, detection, and governance of private languages in AI systems.
👉 Paper link: https://huggingface.co/papers/2503.01063

24. Unposed Sparse Views Room Layout Reconstruction in the Age of Pretrain Model
🔑 Keywords: 3D foundation models, Plane-DUSt3R, multi-view room layout estimation, end-to-end solution
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to introduce Plane-DUSt3R, a new method utilizing 3D foundation model DUSt3R for efficient multi-view room layout estimation.
🛠️ Research Methods:
– The method enhances the DUSt3R framework by fine-tuning it on the Structure3D dataset with a modified objective to determine structural planes, supporting multiple-perspective image processing.
💬 Research Conclusions:
– Plane-DUSt3R outperforms existing techniques in room layout estimation on synthetic datasets and shows resilience and efficiency across varied image styles in the wild.
👉 Paper link: https://huggingface.co/papers/2502.16779

25. Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator
🔑 Keywords: Generative Models, Maximum Likelihood Estimation, Direct Discriminative Optimization, Diffusion Models, GAN
💡 Category: Generative Models
🌟 Research Objective:
– The paper proposes Direct Discriminative Optimization (DDO) to improve generative model training by bridging likelihood-based methods and the GAN objective.
🛠️ Research Methods:
– Introduces a framework that parameterizes a discriminator using the likelihood ratio, eliminating the need for joint generator-discriminator training, allowing efficient model fine-tuning.
💬 Research Conclusions:
– DDO significantly enhances diffusion models, reducing FID scores substantially on CIFAR-10 and ImageNet datasets, and improves the performance of visual autoregressive models.
👉 Paper link: https://huggingface.co/papers/2503.01103

26. RSQ: Learning from Important Tokens Leads to Better Quantized LLMs
🔑 Keywords: Layer-wise quantization, RSQ, Attention scores, GPTQ framework
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to improve the quantization of large models by focusing on the importance of tokens, particularly those with high attention scores, rather than uniformly optimizing layer reconstruction loss.
🛠️ Research Methods:
– The researchers introduced RSQ (Rotate, Scale, then Quantize), involving orthogonal transformation to handle outliers, scaling token features based on their importance, and applying the GPTQ framework with second-order statistics from scaled tokens. Heuristic and dynamic strategies were explored for computing token importance, with attention concentration identified as the most effective approach.
💬 Research Conclusions:
– RSQ consistently outperformed baseline methods across multiple tasks and model families like LLaMA3, Mistral, and Qwen2.5. Moreover, RSQ exhibited superior performance in long-context tasks and demonstrated strong generalizability across various setups including different model sizes, calibration datasets, bit precisions, and quantization methods.
👉 Paper link: https://huggingface.co/papers/2503.01820

27. Why Are Web AI Agents More Vulnerable Than Standalone LLMs? A Security Analysis
🔑 Keywords: Web AI agents, Large Language Models (LLMs), security, robustness, adversarial user inputs
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To investigate the underlying factors contributing to the increased vulnerability of Web AI agents compared to standalone Large Language Models (LLMs).
🛠️ Research Methods:
– Conducted a component-level analysis and developed a granular, systematic evaluation framework to examine the vulnerabilities of Web AI agents.
💬 Research Conclusions:
– Identified three critical factors that amplify the vulnerability of Web AI agents: embedding user goals into the system prompt, multi-step action generation, and observational capabilities. The study underscores the need for enhanced security and robustness in AI agent design and offers insights for developing targeted defense strategies.
👉 Paper link: https://huggingface.co/papers/2502.20383
28. Teaching Metric Distance to Autoregressive Multimodal Foundational Models
🔑 Keywords: Large Language Models, DIST2Loss, Multimodal Understanding, Generative Reward Modeling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce DIST2Loss, a distance-aware framework for training autoregressive discrete models using predefined distance relationships among output tokens.
🛠️ Research Methods:
– DIST2Loss transforms continuous exponential family distributions into discrete targets, enabling models to learn distance relationships during token generation.
💬 Research Conclusions:
– DIST2Loss shows consistent performance gains across multimodal applications, especially with limited training data, enhancing the models’ effectiveness in resource-constrained environments.
👉 Paper link: https://huggingface.co/papers/2503.02379
