AI Native Daily Paper Digest – 20250305

1. MPO: Boosting LLM Agents with Meta Plan Optimization
🔑 Keywords: LLMs, Planning Hallucinations, Meta Plan Optimization, Task Efficiency, Generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose the Meta Plan Optimization (MPO) framework to improve planning capabilities of LLM-based agents by incorporating explicit guidance.
🛠️ Research Methods:
– MPO utilizes high-level general guidance through meta plans and optimizes these based on feedback from task execution. Experiments were conducted on two representative tasks to evaluate its performance.
💬 Research Conclusions:
– The MPO framework significantly outperforms existing baselines, enhancing task efficiency and generalization capabilities in new scenarios.
👉 Paper link: https://huggingface.co/papers/2503.02682

2. Mask-DPO: Generalizable Fine-grained Factuality Alignment of LLMs
🔑 Keywords: Large language models, hallucinations, factuality alignment, Direct Preference Optimization, Mask-DPO
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a fine-grained factuality alignment method, Mask-DPO, for improving the factual accuracy of LLMs by focusing on sentence-level factual correctness.
🛠️ Research Methods:
– Developed Mask-DPO using Direct Preference Optimization (DPO) to incorporate sentence-level factuality as mask signals, learning only from factually correct sentences and addressing ambiguity in preference learning.
💬 Research Conclusions:
– Mask-DPO significantly enhances the factuality of LLM responses, with improvements in both in-domain and out-of-domain datasets. It outperformed larger models on specific trained and test sets, and demonstrated effective generalization through topic scaling in datasets.
👉 Paper link: https://huggingface.co/papers/2503.02846

3. MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
🔑 Keywords: Large Language Models, Multi-agent Systems, MultiAgentBench, Coordination Protocols, Cognitive Planning
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces MultiAgentBench, a benchmark designed to evaluate Large Language Model-based multi-agent systems in diverse and interactive scenarios.
🛠️ Research Methods:
– The framework assesses task completion, collaboration quality, and competition through milestone-based KPIs, and evaluates coordination protocols like star, chain, tree, and graph topologies along with strategies such as group discussion and cognitive planning.
💬 Research Conclusions:
– gpt-4o-mini achieved the highest average task score; the graph structure proved most effective among coordination protocols, and cognitive planning increased milestone achievement rates by 3%.
👉 Paper link: https://huggingface.co/papers/2503.01935

4. Wikipedia in the Era of LLMs: Evolution and Risks
🔑 Keywords: Large Language Models, Wikipedia, Natural Language Processing, Machine Translation, Retrieval-Augmented Generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to analyze the impact of Large Language Models on Wikipedia, focusing on its evolution and potential risks.
🛠️ Research Methods:
– An examination of page views and article content is conducted, along with simulations to explore the effects of LLMs on NLP tasks such as machine translation and retrieval-augmented generation.
💬 Research Conclusions:
– The study reveals that LLMs have influenced Wikipedia’s content with a minor impact in certain categories, potentially affecting machine translation benchmarks and the efficacy of retrieval-augmented generation due to LLM-generated content.
👉 Paper link: https://huggingface.co/papers/2503.02879

5. Iterative Value Function Optimization for Guided Decoding
🔑 Keywords: Reinforcement Learning from Human Feedback, Guided Decoding, Value Function Optimization, Text Summarization, Multi-turn Dialogue
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address limitations in value-guided decoding for language models by improving the accuracy of value function estimation.
🛠️ Research Methods:
– The authors propose Iterative Value Function Optimization, introducing Monte Carlo Value Estimation to reduce estimation variance and Iterative On-Policy Optimization for progressive value estimation improvement.
💬 Research Conclusions:
– Experiments demonstrate that value-guided decoding aligns language models effectively, achieving alignment while significantly reducing computational costs.
👉 Paper link: https://huggingface.co/papers/2503.02368

6. LADDER: Self-Improving LLMs Through Recursive Problem Decomposition
🔑 Keywords: LADDER, TTRL, self-guided learning, reinforcement learning, problem-solving
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce LADDER, a framework enabling Large Language Models to autonomously improve their problem-solving abilities through self-guided learning by recursively generating and solving progressively simpler variants of complex problems.
🛠️ Research Methods:
– Utilization of ladDEr (Learning through Autonomous Difficulty-Driven Example Recursion) and TTRL (Test-Time Reinforcement Learning) for enhancing the models’ math problem-solving performance without curated datasets or human feedback.
💬 Research Conclusions:
– Significant improvement in problem-solving accuracy: Llama 3.2 3B from 1% to 82% on undergraduate-level math problems and Qwen2.5 7B achieving 73% and 90% on the MIT Integration Bee qualifying examination with LADDER and TTRL respectively, surpassing previous state-of-the-art performances.
👉 Paper link: https://huggingface.co/papers/2503.00735

7. PipeOffload: Improving Scalability of Pipeline Parallelism with Memory Optimization
🔑 Keywords: Pipeline Parallelism, Memory Offload, Large Language Models, Activation Memory, Scalability
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address scalability issues in training large language models due to high activation memory consumption by exploring memory offload strategies in pipeline parallelism.
🛠️ Research Methods:
– Empirical study to identify the potential for offloading activation memory with negligible overhead, and introduction of a novel selective offload strategy to reduce peak activation memory.
💬 Research Conclusions:
– The study demonstrates that activation memory per device can be significantly reduced, enhancing the scalability of pipeline parallelism over tensor parallelism, achieving up to a 19% acceleration with reduced memory consumption.
👉 Paper link: https://huggingface.co/papers/2503.01328

8. Societal Alignment Frameworks Can Improve LLM Alignment
🔑 Keywords: Large Language Models, Alignment, Human Values, Societal Alignment
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The paper aims to improve the alignment of Large Language Models (LLMs) by integrating insights from societal alignment frameworks, including social, economic, and contractual alignment.
🛠️ Research Methods:
– The study explores the role of uncertainty in societal alignment frameworks and investigates how it applies to the alignment of LLMs, proposing alternative views and frameworks.
💬 Research Conclusions:
– The authors conclude that instead of focusing solely on perfecting the specification of objectives, embracing the under-specified nature of LLM objectives could be advantageous. They also highlight the need for participatory alignment interface designs.
👉 Paper link: https://huggingface.co/papers/2503.00069

9. SemViQA: A Semantic Question Answering System for Vietnamese Information Fact-Checking
🔑 Keywords: Large Language Models, fact-checking, Semantic-based Evidence Retrieval, Two-step Verdict Classification, misinformation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the challenge of misinformation and fact-checking in low-resource languages, specifically Vietnamese, which is exacerbated by Large Language Models like GPT and Gemini.
🛠️ Research Methods:
– Introduce SemViQA, a Vietnamese fact-checking framework that integrates Semantic-based Evidence Retrieval (SER) and Two-step Verdict Classification (TVC) to balance precision and speed.
💬 Research Conclusions:
– Achieves state-of-the-art accuracy with 78.97% on ISE-DSC01 and 80.82% on ViWikiFC, setting a new benchmark for Vietnamese fact verification and securing the 1st place in the UIT Data Science Challenge.
– Offers a significant improvement in inference speed (7x) with the SemViQA Faster model while maintaining competitive accuracy.
👉 Paper link: https://huggingface.co/papers/2503.00955

10. FR-Spec: Accelerating Large-Vocabulary Language Models via Frequency-Ranked Speculative Sampling
🔑 Keywords: Speculative Sampling, Large Language Models, Vocabulary Space Compression, Llama-3-8B
💡 Category: Natural Language Processing
🌟 Research Objective:
– Present FR-Spec, a frequency-ranked speculative sampling framework designed to improve efficiency in the auto-regressive generation process of large language models with extensive vocabularies.
🛠️ Research Methods:
– Implement a draft-then-verify mechanism, compressing vocabulary space to optimize draft candidate selection and reduce LM head computation.
💬 Research Conclusions:
– Achieved an average of 1.12 times speedup over the existing method EAGLE-2 while maintaining output distribution equivalence.
👉 Paper link: https://huggingface.co/papers/2502.14856

11. Language Models can Self-Improve at State-Value Estimation for Better Search
🔑 Keywords: self-taught lookahead, state-transition dynamics, language model-controlled search, ground truth rewards
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to develop a self-supervised method called self-taught lookahead to improve task completion efficiency in multi-step reasoning tasks without relying on costly ground truth rewards or human demonstrations.
🛠️ Research Methods:
– Utilized state-transition dynamics to train a value model that guides language model-controlled search, specifically in interactive domains such as web tasks.
💬 Research Conclusions:
– The research concludes that moderately sized value models with 8 billion parameters enhanced by self-taught lookahead can achieve comparable performance to frontier LLMs like gpt-4o, while improving performance by 20% and reducing costs by 37 times compared to traditional LLM-based tree search approaches.
👉 Paper link: https://huggingface.co/papers/2503.02878

12. ATLaS: Agent Tuning via Learning Critical Steps
🔑 Keywords: Large Language Model, Critical Steps, Finetuning, ATLaS
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance Large Language Model (LLM) agents by focusing on critical steps in expert trajectories to improve generalization and reduce expert bias.
🛠️ Research Methods:
– Introducing ATLaS, a method that finetunes LLMs on identified critical steps within expert trajectories, reducing the cost and focusing on essential steps like planning and reasoning.
💬 Research Conclusions:
– ATLaS finetuned LLMs outperform those finetuned on entire trajectories, maintaining and enhancing their capabilities as generalist agents across diverse environments.
👉 Paper link: https://huggingface.co/papers/2503.02197

13. UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
🔑 Keywords: Generalist models, Unified modeling, Fine-grained perception, Vision-language tasks, MLLMs
💡 Category: Computer Vision
🌟 Research Objective:
– To integrate fine-grained perception tasks like detection and segmentation into generalist models using a unified open-ended language interface.
🛠️ Research Methods:
– Proposal of a framework named \ours that unifies visual perception tasks by representing them in the language space, using a novel embedding retrieval approach for segmentation.
💬 Research Conclusions:
– \ours simplifies the architectural design and training strategies while outperforming previous models by a significant margin in benchmarks like COCO instance segmentation and ADE20K semantic segmentation. It also integrates with existing MLLMs, enhancing their capabilities in handling complex tasks such as reasoning segmentation.
👉 Paper link: https://huggingface.co/papers/2503.01342

14. RectifiedHR: Enable Efficient High-Resolution Image Generation via Energy Rectification
🔑 Keywords: Diffusion models, high-resolution image generation, noise refresh strategy, Energy Rectification
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to provide an efficient and straightforward solution, called RectifiedHR, for generating high-resolution images without requiring any additional training.
🛠️ Research Methods:
– Introduces a noise refresh strategy to enhance the high-resolution image generation capability and improve efficiency with minimal code changes.
– Proposes an Energy Rectification strategy to prevent image blurriness and enhance image quality by adjusting hyperparameters of classifier-free guidance.
💬 Research Conclusions:
– RectifiedHR demonstrates superior effectiveness and efficiency in high-resolution image generation compared to existing baseline methods, highlighting its practicality as a training-free approach.
👉 Paper link: https://huggingface.co/papers/2503.02537

15. SPIDER: A Comprehensive Multi-Organ Supervised Pathology Dataset and Baseline Models
🔑 Keywords: Computational Pathology, SPIDER, Annotation Quality, Multimodal Approaches, AI-driven Pathology
💡 Category: AI in Healthcare
🌟 Research Objective:
– To introduce SPIDER, the largest publicly available patch-level dataset for computational pathology, enhancing dataset diversity and annotation quality across organ types.
🛠️ Research Methods:
– Utilized the Hibou-L foundation model as a feature extractor combined with an attention-based classification head for model training on the SPIDER dataset.
💬 Research Conclusions:
– Achieved state-of-the-art performance in tissue classification, enabled rapid identification of significant areas, and established a foundation for multimodal approaches in digital pathology.
👉 Paper link: https://huggingface.co/papers/2503.02876

16. AppAgentX: Evolving GUI Agents as Proficient Smartphone Users
🔑 Keywords: Large Language Models, GUI agents, Intelligence, Flexibility, Efficiency
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper proposes a novel evolutionary framework for GUI agents that aims to enhance operational efficiency while maintaining intelligence and flexibility.
🛠️ Research Methods:
– The approach involves incorporating a memory mechanism that records the agent’s task execution history, allowing the agent to identify and evolve high-level actions as shortcuts for repetitive tasks.
💬 Research Conclusions:
– The proposed framework significantly outperforms existing methods in efficiency and accuracy on multiple benchmark tasks. The code will be open-sourced for further research.
👉 Paper link: https://huggingface.co/papers/2503.02268
17. Q-Eval-100K: Evaluating Visual Quality and Alignment Level for Text-to-Vision Content
🔑 Keywords: Text-to-Vision, Visual Quality, Alignment, Human Annotations, Q-Eval-Score
💡 Category: Computer Vision
🌟 Research Objective:
– To evaluate visual quality and alignment in text-to-vision content using a comprehensive dataset, Q-EVAL-100K.
🛠️ Research Methods:
– Introduction of a dataset featuring 960K human annotations for text-to-image and text-to-video models, focusing on visual quality and alignment.
💬 Research Conclusions:
– The proposed Q-Eval-Score model demonstrates superior performance and strong generalization across benchmarks, underscoring the dataset’s value.
👉 Paper link: https://huggingface.co/papers/2503.02357

18. Improve Representation for Imbalanced Regression through Geometric Constraints
🔑 Keywords: Representation Learning, Imbalanced Regression, Latent Space, Uniformity, Surrogate-driven Representation Learning
💡 Category: Machine Learning
🌟 Research Objective:
– To explore and ensure uniform feature distribution in the latent space for imbalanced regression, which has been less studied compared to classification.
🛠️ Research Methods:
– Introduction of two geometric loss functions, enveloping and homogeneity, integrated into the data representations via a Surrogate-driven Representation Learning (SRL) framework.
💬 Research Conclusions:
– Experiments demonstrate the importance of uniformity in imbalanced regression and validate the effectiveness of geometry-based loss functions in improving representation learning.
👉 Paper link: https://huggingface.co/papers/2503.00876

19. IterPref: Focal Preference Learning for Code Generation via Iterative Debugging
🔑 Keywords: Preference learning, Code LLMs, Iterative debugging, Error correction, CodeFlow dataset
💡 Category: Machine Learning
🌟 Research Objective:
– Enhance Code LLMs by implementing preference learning beyond traditional supervised fine-tuning.
🛠️ Research Methods:
– Introduce IterPref, a preference alignment framework that mimics human iterative debugging.
– Develop CodeFlow dataset to generate informative preference pairs by iteratively refining samples with error corrections.
💬 Research Conclusions:
– IterPref significantly improves Code LLMs performance on code generation and challenging tasks like BigCodeBench.
– In-depth analysis shows that IterPref results in fewer errors, with plans to publicly release the code and data.
👉 Paper link: https://huggingface.co/papers/2503.02783

20. A Multimodal Symphony: Integrating Taste and Sound through Generative AI
🔑 Keywords: Multi-Modal Models, Generative AI, Neuroscience, Taste-to-Music
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To explore multimodal generative models capable of converting taste information into music.
🛠️ Research Methods:
– Conducted an experiment using a fine-tuned generative music model (MusicGEN) to create music based on detailed taste descriptions.
💬 Research Conclusions:
– The fine-tuned model produced music that coherently reflects taste descriptions, as evaluated by participants, marking significant progress in AI-mediated interactions between sound and taste.
👉 Paper link: https://huggingface.co/papers/2503.02823

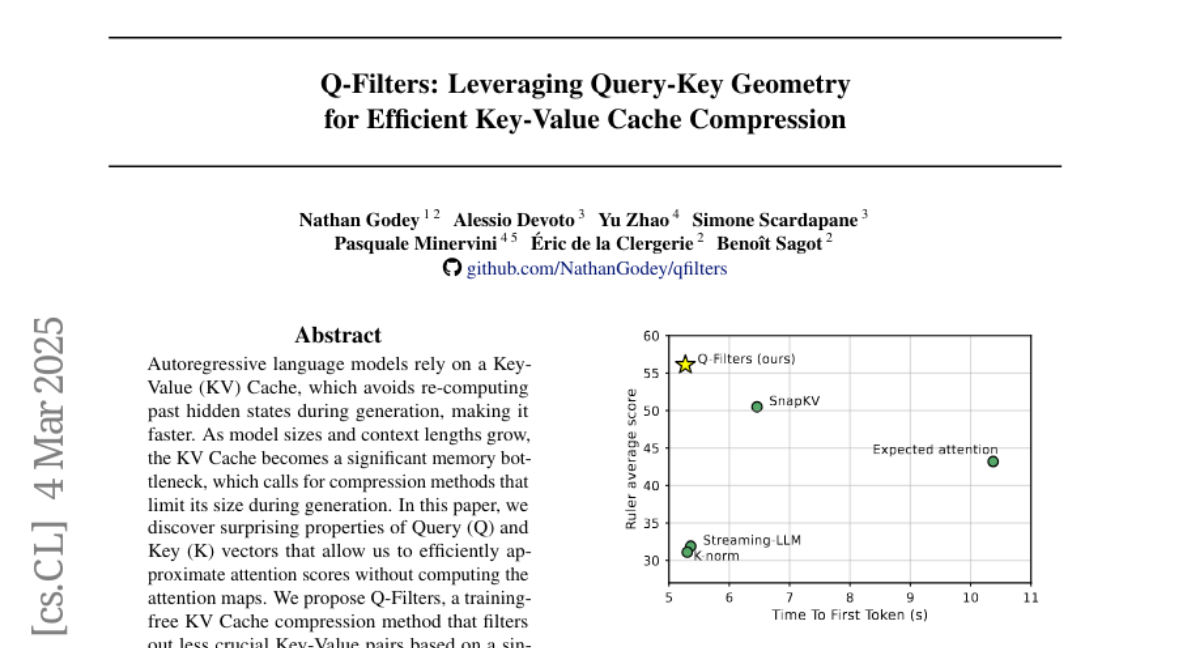
21. Q-Filters: Leveraging QK Geometry for Efficient KV Cache Compression
🔑 Keywords: KV Cache, Q-Filters, FlashAttention, Compression Methods, Text Generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address the memory bottleneck caused by KV Cache in autoregressive language models by proposing an efficient compression method.
🛠️ Research Methods:
– The study introduces Q-Filters, a training-free KV Cache compression method that leverages the properties of Query and Key vectors to approximate attention scores without computing attention maps.
💬 Research Conclusions:
– Q-Filters demonstrates competitiveness in retrieval tasks and outperforms other compression methods like Streaming-LLM in text generation, achieving 99% accuracy and significantly reducing generation perplexity.
👉 Paper link: https://huggingface.co/papers/2503.02812
22. A Token-level Text Image Foundation Model for Document Understanding
🔑 Keywords: Visual Foundation Models, TokenOCR, Multi-Modal Large Language Models, Document-level Understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop TokenOCR, a token-level visual foundation model tailored for text-image-related tasks.
🛠️ Research Methods:
– Creation of TokenIT, a comprehensive token-level image text dataset with 20 million images for TokenOCR pretraining.
– Replacement of previous VFMs with TokenOCR to create TokenVL for VQA-based document understanding tasks.
💬 Research Conclusions:
– TokenOCR and TokenVL demonstrate exceptional capability in text-image-related tasks, with extensive experiments validating their effectiveness.
👉 Paper link: https://huggingface.co/papers/2503.02304

23. Tabby: Tabular Data Synthesis with Language Models
🔑 Keywords: Tabby, Transformer, Large Language Models, Tabular Data, Data Synthesis
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to address the gap in synthetic tabular data generation using enhanced language model techniques.
🛠️ Research Methods:
– The study introduces Tabby, a post-training modification for Transformers incorporating a Gated Mixture-of-Experts approach with column-specific parameters.
💬 Research Conclusions:
– Tabby matches or surpasses the quality of real data in tabular formats and achieves parity with real data on structured datasets like nested JSON when paired with the Plain training technique.
👉 Paper link: https://huggingface.co/papers/2503.02152

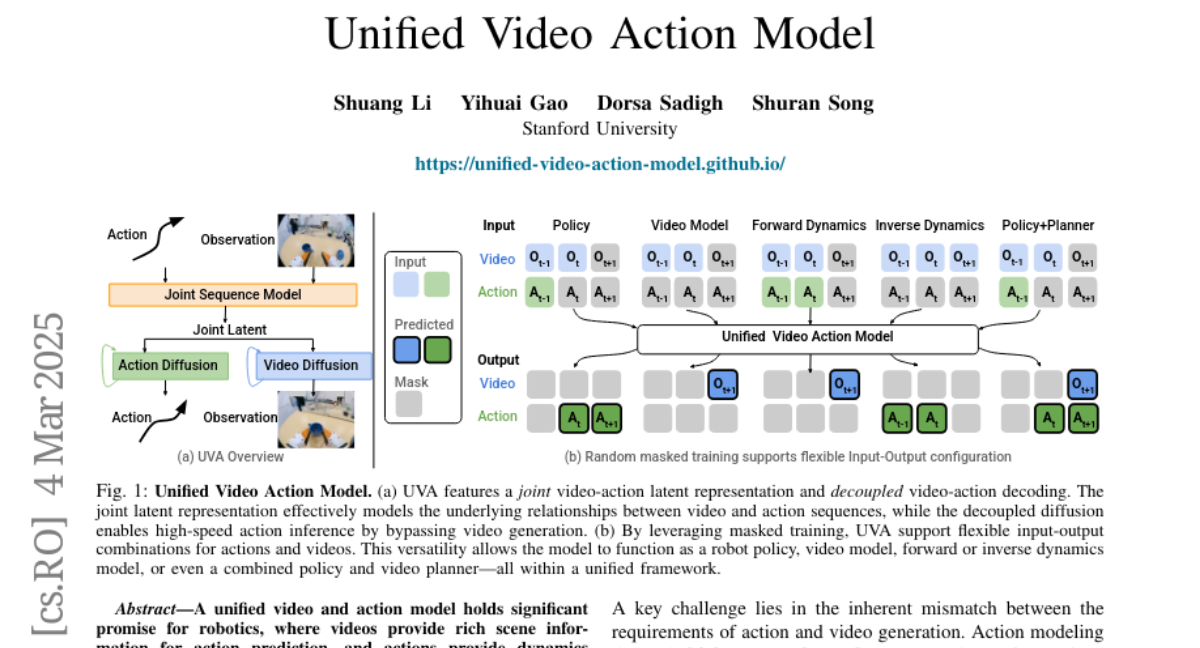
24. Unified Video Action Model
🔑 Keywords: Unified Video Action model, Robotics, Video Prediction, Action Prediction
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper introduces the Unified Video Action model (UVA) to optimize video and action predictions, aiming for high accuracy and efficient action inference in robotics.
🛠️ Research Methods:
– The study employs a joint video-action latent representation and decouples video-action decoding using lightweight diffusion heads, allowing high-speed action inference without needing video generation during inference.
💬 Research Conclusions:
– UVA serves as a versatile solution for various robotics tasks, such as policy learning and video observation prediction, matching the performance of specialized methods, and offering a general-purpose approach without compromising efficiency.
👉 Paper link: https://huggingface.co/papers/2503.00200
25. Discrete-Time Hybrid Automata Learning: Legged Locomotion Meets Skateboarding
🔑 Keywords: Discrete-time Hybrid Automata Learning, Reinforcement Learning, Hybrid dynamical systems, Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper aims to introduce a framework called Discrete-time Hybrid Automata Learning (DHAL) for identifying and executing mode-switching in hybrid dynamical systems without requiring trajectory segmentation or event function learning.
🛠️ Research Methods:
– The approach utilizes on-policy Reinforcement Learning along with a beta policy distribution and a multi-critic architecture to model contact-guided motions, particularly demonstrated through a quadrupedal robot skateboard task.
💬 Research Conclusions:
– The DHAL method is validated in both simulations and real-world tests, showing robust performance in handling hybrid dynamical systems.
👉 Paper link: https://huggingface.co/papers/2503.01842