AI Native Daily Paper Digest – 20250307

1. START: Self-taught Reasoner with Tools
🔑 Keywords: Large reasoning models, Chain-of-thought, External tools, Self-taught reasoner, Hint-infer
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to enhance reasoning capabilities of large reasoning models (LRMs) by integrating external tools and employing a self-taught framework.
🛠️ Research Methods:
– The researchers introduced START, a novel tool-integrated LLM, and developed a self-learning framework with two techniques: Hint-infer and Hint Rejection Sampling Fine-Tuning (Hint-RFT).
💬 Research Conclusions:
– START demonstrates enhanced accuracy in various benchmarks, outperforming the base models and achieving results comparable to state-of-the-art models.
👉 Paper link: https://huggingface.co/papers/2503.04625

2. Token-Efficient Long Video Understanding for Multimodal LLMs
🔑 Keywords: Video-LLMs, Spatiotemporal Encoding, Temporal Encoder, Token Reduction, Video Understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address the limitations in temporal modeling of video frames in Video-LLMs by introducing a new architecture, STORM.
🛠️ Research Methods:
– Developed the STORM architecture with a dedicated temporal encoder using the Mamba State Space Model to enrich image token representations with temporal information.
💬 Research Conclusions:
– STORM significantly improves video reasoning and reduces computational costs, achieving more than 5% improvement in benchmarks like MLVU and LongVideoBench, while reducing computation demands up to 8 times and decoding latency by 2.4-2.9 times.
👉 Paper link: https://huggingface.co/papers/2503.04130

3. LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
🔑 Keywords: LLMVoX, Speech-to-Speech Dialogue, Multimodal Interactions, TTS, Vision-Language Model
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop LLMVoX, a lightweight, LLM-agnostic TTS system that ensures high-quality, low-latency speech and maintains base LLM capabilities.
🛠️ Research Methods:
– Utilizes a 30M-parameter autoregressive streaming TTS system with a multi-queue token streaming system to decouple speech synthesis, enabling infinite-length dialogues and easy extension to various tasks.
💬 Research Conclusions:
– LLMVoX significantly lowers Word Error Rate compared to existing speech-enabled LLMs, supports seamless integration with Vision-Language Models, and generalizes efficiently to new languages with minimal dataset adaptation.
👉 Paper link: https://huggingface.co/papers/2503.04724
4. EgoLife: Towards Egocentric Life Assistant
🔑 Keywords: Egocentric AI, AI-powered wearable glasses, Multimodal egocentric video capture, EgoButler, EgoLife Dataset
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The project aims to develop EgoLife, an AI-powered egocentric life assistant using wearable glasses to enhance personal efficiency.
🛠️ Research Methods:
– Conducted a comprehensive data collection study with participants using AI glasses for capturing daily activities, resulting in the EgoLife Dataset.
– Developed the EgoLifeQA suite for life-oriented question-answering tasks using the dataset.
– Introduced EgoButler, comprising EgoGPT and EgoRAG, for robust model development and long-context question answering.
💬 Research Conclusions:
– The study validates the operational mechanisms of EgoButler and identifies critical factors and bottlenecks for future research in egocentric AI assistants.
– Released datasets, models, and benchmarks to encourage further research in egocentric AI.
👉 Paper link: https://huggingface.co/papers/2503.03803

5. LINGOLY-TOO: Disentangling Memorisation from Reasoning with Linguistic Templatisation and Orthographic Obfuscation
🔑 Keywords: LLMs, reasoning capabilities, linguistic reasoning, evaluation benchmark
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a framework to evaluate linguistic reasoning in LLMs that mitigates the influence of data exposure and memorization.
🛠️ Research Methods:
– Developed LINGOLY-TOO, an evaluation benchmark utilizing orthographic templates to create varied question formats, obscuring linguistic writing systems.
💬 Research Conclusions:
– Showed that frontier models like OpenAI o1-preview and DeepSeem R1 face challenges with advanced reasoning.
– Highlighted variance in LLM performance based on question format and confirmed that data exposure inflates perceived reasoning abilities.
👉 Paper link: https://huggingface.co/papers/2503.02972

6. LLM as a Broken Telephone: Iterative Generation Distorts Information
🔑 Keywords: Large Language Models, Iterative Generation, Information Distortion, AI-mediated Information Propagation, Chain Complexity
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates whether large language models (LLMs) distort information through iterative generation, similar to the “broken telephone” effect.
🛠️ Research Methods:
– Translation-based experiments were conducted to assess how distortion accumulates over time, influenced by language choice and chain complexity.
💬 Research Conclusions:
– Although information degradation is inevitable, it can be mitigated through strategic prompting techniques, raising questions about the reliability of LLM-generated content in iterative workflows.
👉 Paper link: https://huggingface.co/papers/2502.20258

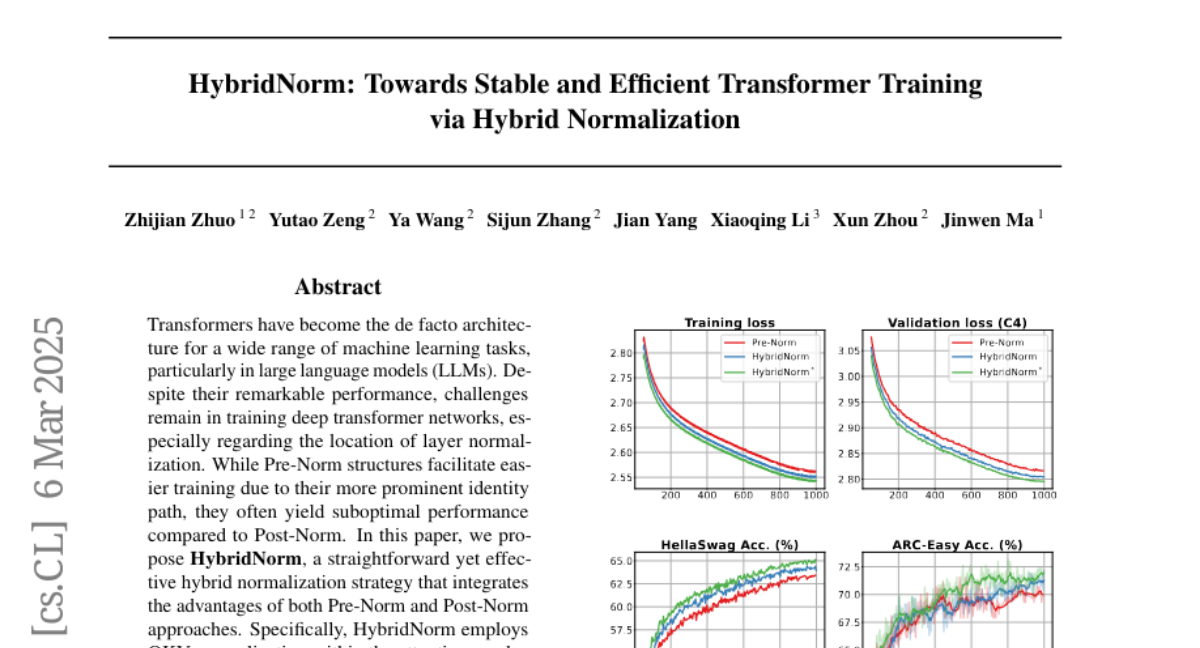
7. HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
🔑 Keywords: Transformers, Large Language Models, HybridNorm, Pre-Norm, Post-Norm
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address challenges in training deep transformer networks, particularly in layer normalization, by proposing a new hybrid normalization strategy called HybridNorm.
🛠️ Research Methods:
– HybridNorm combines both Pre-Norm and Post-Norm by applying QKV normalization within the attention mechanism and Post-Norm in the feed-forward network of each transformer block.
💬 Research Conclusions:
– HybridNorm enhances training stability and performance for large language models, outperforming traditional Pre-Norm and Post-Norm approaches across various benchmarks.
👉 Paper link: https://huggingface.co/papers/2503.04598
8. IFIR: A Comprehensive Benchmark for Evaluating Instruction-Following in Expert-Domain Information Retrieval
🔑 Keywords: IFIR, Information Retrieval, LLM-based Evaluation, Expert Domains
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate instruction-following information retrieval capabilities in expert domains using the comprehensive benchmark IFIR.
🛠️ Research Methods:
– Developed IFIR with 2,426 examples across finance, law, healthcare, and science literature.
– Proposed a novel LLM-based evaluation method for precise model performance assessment.
💬 Research Conclusions:
– Current retrieval models, including LLM-based ones, struggle with complex, domain-specific instructions.
– Provides insights for future improvements in retriever development.
👉 Paper link: https://huggingface.co/papers/2503.04644

9. FuseChat-3.0: Preference Optimization Meets Heterogeneous Model Fusion
🔑 Keywords: FuseChat-3.0, Large Language Models, Direct Preference Optimization, Instruction-Following
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop FuseChat-3.0 by integrating diverse large language models to achieve enhanced performance in smaller, more compact target models.
🛠️ Research Methods:
– Implement a specialized data construction protocol tailored for various tasks and domains.
– Utilize a two-stage training pipeline: supervised fine-tuning and Direct Preference Optimization.
💬 Research Conclusions:
– FuseChat-3.0 models show superior performance gains across multiple benchmarks, notably improving instruction-following capabilities by substantial points.
👉 Paper link: https://huggingface.co/papers/2503.04222

10. L$^2$M: Mutual Information Scaling Law for Long-Context Language Modeling
🔑 Keywords: Mutual Information, Long-context Language Modeling, Transformers, State Space Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to establish a bipartite mutual information scaling law that governs long-range dependencies in natural language and uses this to improve long-context language modeling.
🛠️ Research Methods:
– The authors validate their theoretical findings through experiments conducted on both transformers and state space models.
💬 Research Conclusions:
– The study provides a theoretical foundation for developing large language models that are more effective at modeling longer context lengths, guiding future advancements in this area.
👉 Paper link: https://huggingface.co/papers/2503.04725

11. PokéChamp: an Expert-level Minimax Language Agent
🔑 Keywords: PokéChamp, Large Language Models, Minimax, Pokémon battles, GPT-4o
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce PokéChamp, a minimax agent leveraging LLMs for Pokémon battles to enhance minimax tree search.
🛠️ Research Methods:
– Utilize Large Language Models to replace three key modules in the minimax framework: player action sampling, opponent modeling, and value function estimation.
💬 Research Conclusions:
– PokéChamp demonstrates superior performance with a 76% win rate against existing LLM-based bots.
– Attains a projected Elo of 1300-1500 on the Pokémon Showdown online ladder.
– Compiles the largest real-player Pokémon battle dataset with over 3 million games.
👉 Paper link: https://huggingface.co/papers/2503.04094

12. Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities
🔑 Keywords: Audio Flamingo 2, Audio-Language Model, CLAP model, LongAudio, LongAudioBench
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce Audio Flamingo 2 (AF2), an Audio-Language Model with advanced audio understanding and reasoning capabilities.
🛠️ Research Methods:
– AF2 utilizes a custom CLAP model and synthetic Audio QA data with a multi-stage curriculum learning strategy for enhanced audio reasoning.
– Development of LongAudio, a novel dataset for training ALMs on long audio captioning and question-answering tasks.
💬 Research Conclusions:
– AF2 achieves state-of-the-art performance with a compact model size of only 3B parameters, outperforming larger models across 20 benchmarks.
– Fine-tuning on LongAudio results in exceptional performance on LongAudioBench, showcasing superior long audio understanding capabilities.
👉 Paper link: https://huggingface.co/papers/2503.03983

13. Dedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks
🔑 Keywords: Inference-Time Scaling, Feedback and Edit Models, Open-Ended Tasks, State-of-the-Art Performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to improve inference-time scaling for open-ended general-domain tasks through the use of Feedback and Edit Models.
🛠️ Research Methods:
– Utilizes a multi-model setup where one model generates initial responses, a second provides feedback, and a third edits based on that feedback.
💬 Research Conclusions:
– Demonstrated improved performance on Arena Hard benchmark, achieving a score of 92.7, surpassing OpenAI o1 and DeepSeek R1.
👉 Paper link: https://huggingface.co/papers/2503.04378

14. How to Steer LLM Latents for Hallucination Detection?
🔑 Keywords: Hallucinations, LLMs, Truthfulness Separator Vector, pseudo-labeling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to address the challenge of hallucinations in Large Language Models (LLMs) by proposing a method to better distinguish between factual and hallucinated outputs.
🛠️ Research Methods:
– A novel method called Truthfulness Separator Vector (TSV) is introduced, which reshapes the representation space of LLMs without changing model parameters. This method is applied through a two-stage framework involving labeled exemplars and pseudo-labeling of LLM generations.
💬 Research Conclusions:
– The TSV method achieves state-of-the-art performance with minimal labeled data, showing strong generalization across datasets and providing a practical solution for real-world applications of LLMs.
👉 Paper link: https://huggingface.co/papers/2503.01917

15. Identifying Sensitive Weights via Post-quantization Integral
🔑 Keywords: weight quantization, sensitivity metric, Post-quantization Integral, ReQuant
💡 Category: Natural Language Processing
🌟 Research Objective:
– To assess existing weight quantization methods and propose an accurate metric for sensitivity measurement to improve Large Language Models (LLMs) performance.
🛠️ Research Methods:
– Conducting an empirical study on current sensitivity metrics and introducing the Post-quantization Integral (PQI) and ReQuant framework to enhance accuracy and efficiency in weight quantization.
💬 Research Conclusions:
– The study identifies inaccuracies in gradient and Hessian-based sensitivity metrics and introduces ReQuant, which significantly improves quantization results with a noted perplexity gain on Llama 3.2 1B.
👉 Paper link: https://huggingface.co/papers/2503.01901

16. The Best of Both Worlds: Integrating Language Models and Diffusion Models for Video Generation
🔑 Keywords: Text-to-Video, Generative Models, Semantic Compression, Language Models, Streaming Diffusion
💡 Category: Generative Models
🌟 Research Objective:
– To create a hybrid framework, LanDiff, that combines the strengths of autoregressive language models and diffusion models for improved text-to-video generation.
🛠️ Research Methods:
– Developed a semantic tokenizer for efficient compression and representation.
– Utilized a language model to generate semantic tokens with high-level relationships.
– Implemented a streaming diffusion model for refining video quality.
💬 Research Conclusions:
– LanDiff surpassed state-of-the-art models in text-to-video benchmarks, especially in long video generation, achieving a score of 85.43 on the VBench T2V benchmark.
👉 Paper link: https://huggingface.co/papers/2503.04606

17. Union of Experts: Adapting Hierarchical Routing to Equivalently Decomposed Transformer
🔑 Keywords: Mixture-of-Experts, Union-of-Experts, Attention Block, Tensor Parallelism, Natural Language Processing
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance model performance and efficiency by proposing Union-of-Experts (UoE) that enables high-quality expert interactions in large-scale applications.
🛠️ Research Methods:
– Implement equitant expert decomposition in MLP and attention blocks via matrix partitioning in tensor parallelism.
– Develop dynamic routing paradigms, including patch wise data selection and expert selection to enhance process efficiency.
💬 Research Conclusions:
– The UoE model surpasses state-of-the-art approaches such as Full Attention and existing MoEs in various tasks across image and natural language domains, demonstrating its superior performance and efficiency.
👉 Paper link: https://huggingface.co/papers/2503.02495

18. Understanding and Predicting Derailment in Toxic Conversations on GitHub
🔑 Keywords: Toxic language, Proactive moderation, LLMs, Conversation trajectory
💡 Category: Natural Language Processing
🌟 Research Objective:
– To understand and predict conversational derailment leading to toxicity on GitHub and propose a proactive moderation approach.
🛠️ Research Methods:
– Curated a novel dataset of toxic and non-toxic GitHub conversations; identified linguistic markers and patterns; developed a conversation trajectory summary technique using modern LLMs.
💬 Research Conclusions:
– Successfully developed an approach yielding a 69% F1-Score in predicting conversational derailment, outperforming baseline methods.
👉 Paper link: https://huggingface.co/papers/2503.02191

19. Lost in Literalism: How Supervised Training Shapes Translationese in LLMs
🔑 Keywords: Large Language Models, Translationese
💡 Category: Natural Language Processing
🌟 Research Objective:
– Systematically evaluate and mitigate translationese in LLM-generated translations.
🛠️ Research Methods:
– Investigate the roots of translationese during supervised training.
– Introduce methods such as polishing golden references and filtering unnatural instances to reduce biases.
💬 Research Conclusions:
– Significant reduction in translationese and improved translation naturalness, validated by human evaluations and automatic metrics.
– Emphasize the need for training-aware adjustments for more fluent and consistent translations.
👉 Paper link: https://huggingface.co/papers/2503.04369

20. Combining Flow Matching and Transformers for Efficient Solution of Bayesian Inverse Problems
🔑 Keywords: Bayesian inverse problems, Conditional Flow Matching, transformer-based architecture
💡 Category: Machine Learning
🌟 Research Objective:
– To recover the distribution of parameters conditioned on observed experimental data using Bayesian methods.
🛠️ Research Methods:
– Combine Conditional Flow Matching with transformer-based architectures to efficiently sample from complex posterior distributions.
💬 Research Conclusions:
– Demonstrated the capability to efficiently handle a variable number of observations in Bayesian inverse problems.
👉 Paper link: https://huggingface.co/papers/2503.01375

21. On the Acquisition of Shared Grammatical Representations in Bilingual Language Models
🔑 Keywords: Crosslingual Transfer, Multilingual Representations, Structural Priming, Language Model, Typologically Diverse Languages
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore what occurs when a monolingual language model is trained on a second language and investigate the evidence of shared multilingual representations.
🛠️ Research Methods:
– Employed structural priming, a method from human grammatical studies, using small bilingual models with controlled data and exposure for each language.
💬 Research Conclusions:
– Discovered asymmetrical effects across language pairs and directions when training bilingual models, suggesting these asymmetries may inform hypotheses on human structural priming.
– Found that structural priming effects are less robust for less similar language pairs, indicating potential limitations in crosslingual transfer learning for typologically diverse languages.
👉 Paper link: https://huggingface.co/papers/2503.03962
