AI Native Daily Paper Digest – 20250402

1. Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation
🔑 Keywords: Any2Caption, Video Generation, Multimodal Large Language Models, Any2CapIns
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To overcome the challenge of accurately interpreting user intent in video generation by introducing the Any2Caption framework for controllable video generation under diverse conditions.
🛠️ Research Methods:
– The method involves decoupling condition interpretation from video synthesis and using Multimodal Large Language Models (MLLMs) to transform diverse inputs into dense, structured captions that guide video generation.
💬 Research Conclusions:
– The Any2Caption system, with the support of the Any2CapIns dataset, significantly enhances controllability and video quality compared to existing models.
👉 Paper link: https://huggingface.co/papers/2503.24379

2. JudgeLRM: Large Reasoning Models as a Judge
🔑 Keywords: Large Language Models (LLMs), Supervised Fine-Tuning (SFT), reasoning capabilities, JudgeLRM, reinforcement learning (RL)
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate whether enhanced reasoning capabilities in Large Language Models (LLMs) improve their performance as evaluators compared to traditional Supervised Fine-Tuning (SFT) methods.
🛠️ Research Methods:
– Introduce JudgeLRM, a family of judgment-oriented LLMs utilizing reinforcement learning with judge-wise, outcome-driven rewards.
💬 Research Conclusions:
– JudgeLRM models outperform both SFT-tuned models and state-of-the-art reasoning models, with JudgeLRM-3B surpassing GPT-4 and JudgeLRM-7B exceeding DeepSeek-R1 in F1 score, particularly excelling in tasks demanding deep reasoning.
👉 Paper link: https://huggingface.co/papers/2504.00050

3. CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis
🔑 Keywords: Inductive program synthesis, large language model agents, CodeARC, self-correction, iterative refinement
💡 Category: Generative Models
🌟 Research Objective:
– To explore the capabilities of large language model agents in performing inductive program synthesis and propose a novel evaluation framework (CodeARC).
🛠️ Research Methods:
– Developed a new interactive evaluation framework, CodeARC, where agents interact with a hidden target function by querying, synthesizing, and refining solutions using differential testing.
💬 Research Conclusions:
– The study constructs the first large-scale benchmark with 1114 functions. The o3-mini model achieved a 52.7% success rate, highlighting the complexity of the task. Fine-tuning LLaMA-3.1-8B-Instruct showed a 31% relative performance gain, indicating CodeARC’s challenge and realism in testing LLM-based program synthesis.
👉 Paper link: https://huggingface.co/papers/2503.23145

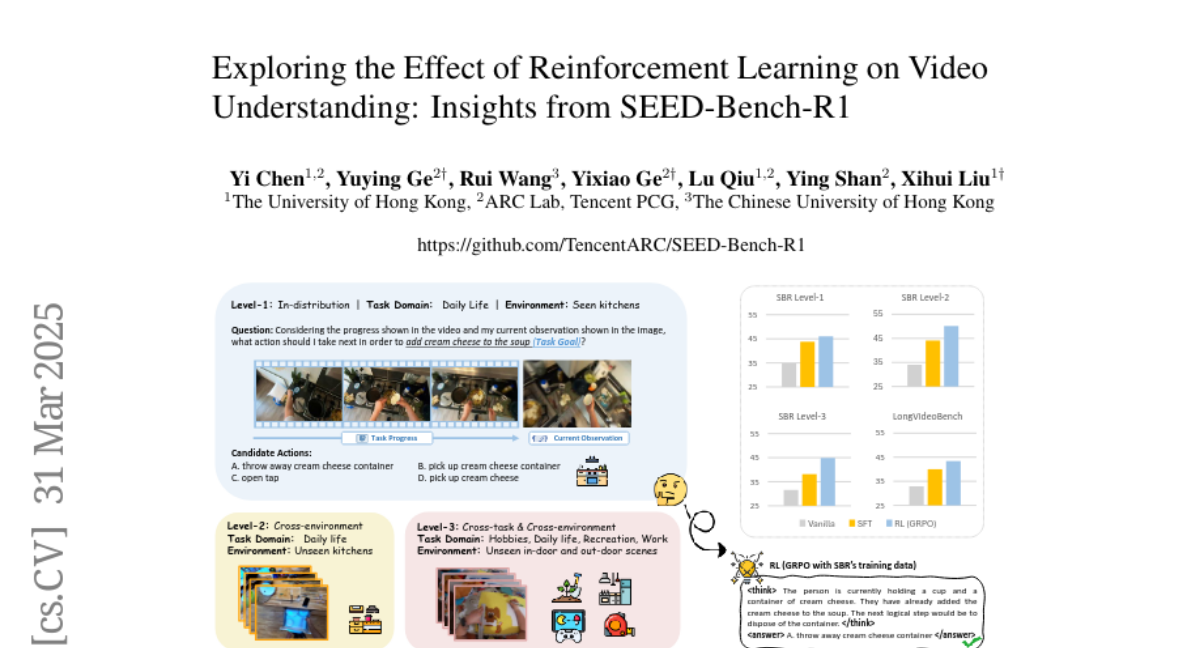
4. Exploring the Effect of Reinforcement Learning on Video Understanding: Insights from SEED-Bench-R1
🔑 Keywords: Chain of Thought, Large Language Models, Reinforcement Learning, Multimodal Large Language Models, SEED-Bench-R1
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce SEED-Bench-R1, aimed at evaluating post-training methods for Multimodal Large Language Models (MLLMs) in tasks that require both perception and reasoning.
🛠️ Research Methods:
– Utilization of Qwen2-VL-Instruct-7B as the base model to compare Reinforcement Learning with Supervised Fine-Tuning for video understanding and complex real-world tasks.
💬 Research Conclusions:
– Reinforcement Learning demonstrates higher data efficiency and superior performance on both in-distribution and out-of-distribution tasks, although with some shortcomings in logical coherence and reasoning consistency.
👉 Paper link: https://huggingface.co/papers/2503.24376
5. Open-Qwen2VL: Compute-Efficient Pre-Training of Fully-Open Multimodal LLMs on Academic Resources
🔑 Keywords: Multimodal LLM, Open-Qwen2VL, Pre-training, Data Quality, Open-Source
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Open-Qwen2VL, a 2B-parameter fully open-source Multimodal Large Language Model aimed at overcoming pre-training barriers.
🛠️ Research Methods:
– Utilize low-to-high dynamic image resolution and multimodal sequence packing to enhance pre-training efficiency.
– Employ both MLLM-based and CLIP-based filtering techniques for high-quality data curation.
💬 Research Conclusions:
– Open-Qwen2VL exhibits remarkable training efficiency and performance on several multimodal benchmarks, surpassing partially-open state-of-the-art models.
– All training resources, including codebase, data filtering methods, and pre-training data, are fully open-sourced to redefine “fully open” for multimodal LLMs.
👉 Paper link: https://huggingface.co/papers/2504.00595

6. Z1: Efficient Test-time Scaling with Code
🔑 Keywords: Large Language Models, test-time computing scaling, code-related reasoning trajectories, Shifted Thinking Window, efficient reasoning elicitation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose an efficient test-time scaling method for Large Language Models by reducing excess thinking tokens while maintaining performance.
🛠️ Research Methods:
– Developed Z1-7B through training with the Z1-Code-Reasoning-107K dataset and implemented a Shifted Thinking Window to mitigate overthinking and cap reasoning tokens.
💬 Research Conclusions:
– Z1-7B matches R1-Distill-Qwen-7B’s performance with approximately 30% of the average thinking tokens and generalizes well to broader reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2504.00810

7. Command A: An Enterprise-Ready Large Language Model
🔑 Keywords: Large Language Model, Multilingual, Hybrid Architecture, Retrieval Augmented Generation, Decentralised Training
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop Command A, a multilingual large language model optimized for real-world enterprise applications with advanced features for business processes automation.
🛠️ Research Methods:
– Utilized a hybrid architecture to balance efficiency and performance with a decentralised training approach, leveraging self-refinement algorithms and model merging techniques.
💬 Research Conclusions:
– Command A demonstrated excellent performance in enterprise-relevant tasks and benchmarks, supported by results from Command R7B, with both models available for research purposes.
👉 Paper link: https://huggingface.co/papers/2504.00698

8. Towards Trustworthy GUI Agents: A Survey
🔑 Keywords: GUI agents, foundation models, web automation, ethical considerations, trustworthy GUI agents
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To examine the trustworthiness of GUI agents, specifically in security, reliability, transparency, ethics, and evaluation.
🛠️ Research Methods:
– The survey explores five critical dimensions and identifies challenges related to adversarial attacks, failure modes, and evaluation benchmarks.
💬 Research Conclusions:
– Real-world deployment is hindered by current vulnerabilities, emphasizing the need for robust safety standards and responsible development practices.
👉 Paper link: https://huggingface.co/papers/2503.23434

9. Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
🔑 Keywords: GUI localization, Proactive Hierarchical Planning, Mixture-of-Grounding, state-of-the-art (SOTA) performance
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introducing Agent S2, a framework addressing challenges in GUI interaction, long-horizon task planning, and cognitive model performance bottlenecks.
🛠️ Research Methods:
– Implementing a Mixture-of-Grounding technique for precise GUI localization and utilizing Proactive Hierarchical Planning for dynamic action plan refinement.
💬 Research Conclusions:
– Achieved state-of-the-art performance on three computer use benchmarks, with notable improvements over existing agents in multiple scenarios.
👉 Paper link: https://huggingface.co/papers/2504.00906

10. GeometryCrafter: Consistent Geometry Estimation for Open-world Videos with Diffusion Priors
🔑 Keywords: GeometryCrafter, point map sequences, Variational Autoencoder (VAE), video diffusion model, 3D accuracy
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to overcome limitations in video depth estimation for achieving geometric fidelity and enabling accurate 3D/4D reconstruction and depth-based applications.
🛠️ Research Methods:
– The authors introduce GeometryCrafter, a framework employing a point map Variational Autoencoder (VAE) for encoding and decoding, combined with a video diffusion model to conditionally model point map sequence distributions.
💬 Research Conclusions:
– GeometryCrafter is evaluated extensively and demonstrates state-of-the-art performance in 3D accuracy, temporal consistency, and generalization across diverse datasets.
👉 Paper link: https://huggingface.co/papers/2504.01016
11. Multi-Token Attention
🔑 Keywords: Soft attention, Multi-Token Attention (MTA), attention weights, convolution operations
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the attention mechanism in large language models (LLMs) by addressing the limitations of single token attention through a novel approach called Multi-Token Attention (MTA).
🛠️ Research Methods:
– Introducing MTA by applying convolution operations over multiple queries and key vectors to enable more nuanced and precise attention within LLMs.
💬 Research Conclusions:
– MTA achieves superior performance compared to Transformer baseline models, particularly excelling in tasks with long contexts due to its ability to utilize richer information.
👉 Paper link: https://huggingface.co/papers/2504.00927

12. MixerMDM: Learnable Composition of Human Motion Diffusion Models
🔑 Keywords: Motion Diffusion Models, Text-Conditioned, Dynamic Mixing Strategy, Fine-Grained Control, Interaction
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces MixerMDM, the first learnable model composition technique to merge pre-trained text-conditioned human motion diffusion models for fine-grained control over individual and interactive motion generation.
🛠️ Research Methods:
– MixerMDM employs a dynamic mixing strategy trained in an adversarial fashion to combine the denoising processes of various models based on conditions.
💬 Research Conclusions:
– MixerMDM enables precise control over the motion dynamics of individual entities and their interactions, improving the alignment between generated motions and their conditions throughout the denoising process.
👉 Paper link: https://huggingface.co/papers/2504.01019
13. Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems?
🔑 Keywords: LLM, Multi-Modal Benchmark, Recitation Behavior, Reasoning Problems
💡 Category: Foundations of AI
🌟 Research Objective:
– To determine whether LLM’s reasoning ability stems from true intelligence or is merely recitation of previously encountered solutions.
🛠️ Research Methods:
– Development of RoR-Bench, a novel, multi-modal benchmark to detect recitation behavior in LLMs when subjected to subtly altered reasoning problems.
💬 Research Conclusions:
– Leading LLMs show significant recitation behavior, experiencing up to 60% performance loss when conditions of simple problems are slightly altered, challenging the perceived intelligence level of these models.
👉 Paper link: https://huggingface.co/papers/2504.00509

14. OmniMMI: A Comprehensive Multi-modal Interaction Benchmark in Streaming Video Contexts
🔑 Keywords: Multi-modal language models, Omni language models, Streaming video understanding, Proactive reasoning, Multi-modal Multiplexing Modeling
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce OmniMMI, a comprehensive multi-modal interaction benchmark specifically tailored for evaluating OmniLLMs within streaming video contexts.
🛠️ Research Methods:
– The development of OmniMMI involves over 1,121 videos and 2,290 questions, addressing streaming video understanding and proactive reasoning across six subtasks.
– Proposal of a novel framework, Multi-modal Multiplexing Modeling (M4), designed to enable an inference-efficient streaming model that can simultaneously process visual and audio information.
💬 Research Conclusions:
– OmniMMI represents a significant advancement in evaluating the real-world interactive capabilities of Omni language models, offering robust challenges in streaming video scenarios.
👉 Paper link: https://huggingface.co/papers/2503.22952

15. Harnessing the Reasoning Economy: A Survey of Efficient Reasoning for Large Language Models
🔑 Keywords: Large Language Models, Reasoning Economy, System 1, System 2
💡 Category: Natural Language Processing
🌟 Research Objective:
– To analyze reasoning economy in Large Language Models (LLMs), focusing on balancing performance and computational cost.
🛠️ Research Methods:
– The study provides a comprehensive analysis of reasoning inefficiency causes, behavior patterns, and potential solutions for post-training and test-time inference stages.
💬 Research Conclusions:
– The paper offers actionable insights and highlights challenges to improve reasoning economy, serving as a resource for further research, with a public repository to track ongoing developments.
👉 Paper link: https://huggingface.co/papers/2503.24377

16. When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning
🔑 Keywords: Large Language Models, Self-Consistency, Generative Reward Models, Inference Budget
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to optimize the reasoning capabilities of Large Language Models by balancing solution generation and verification within a fixed inference budget.
🛠️ Research Methods:
– The research evaluates two strategies: Self-Consistency (SC) and Generative Reward Models (GenRM), comparing their compute-efficiency under a fixed inference budget.
💬 Research Conclusions:
– Self-Consistency is found to be more compute-efficient than GenRM across different models and datasets, unless significantly more compute is used for GenRM.
– Inference scaling laws suggest that optimal compute favors scaling solution generation over scaling verifications.
👉 Paper link: https://huggingface.co/papers/2504.01005

17. AdaMMS: Model Merging for Heterogeneous Multimodal Large Language Models with Unsupervised Coefficient Optimization
🔑 Keywords: Model Merging, Multimodal Large Language Models, Heterogeneous Property, AdaMMS, Linear Interpolation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to address the challenges in merging heterogeneous Multimodal Large Language Models (MLLMs) that have varying architecture and asymmetry in parameter space.
🛠️ Research Methods:
– Introduced AdaMMS, a novel model merging method, using a three-step approach: mapping models with a mapping function, merging through linear interpolation, and hyper-parameter searching with unsupervised selection.
💬 Research Conclusions:
– AdaMMS demonstrates superior performance over previous model merging methods on various vision-language benchmarks without requiring labeled data.
👉 Paper link: https://huggingface.co/papers/2503.23733

18. Efficient LLaMA-3.2-Vision by Trimming Cross-attended Visual Features
🔑 Keywords: Visual token reduction, inference costs, large vision-language models, cross-attention-based models, KV cache size
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to address the challenge of high inference costs due to extensive image features in large vision-language models by focusing on cross-attention-based models.
🛠️ Research Methods:
– The approach involves exploiting the sparse nature in cross-attention maps to selectively prune redundant visual features, specifically targeting the excessive KV cache size in cross-attention layers compared to self-attention layers.
💬 Research Conclusions:
– By leveraging a 50% reduction in visual features, the Trimmed Llama model effectively reduces both inference latency and memory usage while maintaining benchmark performance, without needing additional training.
👉 Paper link: https://huggingface.co/papers/2504.00557

19. Scaling Language-Free Visual Representation Learning
🔑 Keywords: Visual Self-Supervised Learning, CLIP, Visual Question Answering, MetaCLIP data, vision encoders
💡 Category: Computer Vision
🌟 Research Objective:
– Investigate whether the performance gap between Visual Self-Supervised Learning (SSL) and CLIP in multimodal tasks is due to the lack of language supervision or differences in training data.
🛠️ Research Methods:
– Conduct experiments by training both visual SSL and CLIP models on the same MetaCLIP data and analyzing performance in Visual Question Answering (VQA) tasks as a diverse testbed.
💬 Research Conclusions:
– Visual SSL models scale better than CLIP models in terms of data and model capacity, achieving similar performance levels to CLIP, proving that visual self-supervised approaches can match language-supervised models when properly scaled.
👉 Paper link: https://huggingface.co/papers/2504.01017

20. Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models
🔑 Keywords: Large Language Models, Reasoning Paths, Chain-of-Thought, t-SNE, Feature Vectors
💡 Category: Natural Language Processing
🌟 Research Objective:
– To create a visualization tool, “landscape of thoughts,” to inspect the reasoning paths of large language models and better understand their step-by-step reasoning abilities.
🛠️ Research Methods:
– Utilization of feature vectors to represent states in a reasoning path and visualization via two-dimensional t-SNE plots for both qualitative and quantitative analysis.
💬 Research Conclusions:
– The tool distinguishes between strong and weak models, identifies correct and incorrect answers, and detects different reasoning tasks, highlighting undesirable reasoning patterns like low consistency and high uncertainty. It also allows adaptation for models that predict observed properties, demonstrated with a lightweight verifier evaluating reasoning path correctness.
👉 Paper link: https://huggingface.co/papers/2503.22165

21. Inference-Time Scaling for Complex Tasks: Where We Stand and What Lies Ahead
🔑 Keywords: Inference-time scaling, reasoning capabilities, performance gap, empirical analysis
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study investigates the benefits and limitations of inference-time scaling methods in enhancing reasoning capabilities of large language models on complex problems across multiple challenging tasks.
🛠️ Research Methods:
– The paper involves evaluations and comparisons of nine state-of-the-art models on eight tasks, employing repeated model calls independently or with feedback to assess performance bounds and improvements.
💬 Research Conclusions:
– The analysis shows that the advantages of inference-time scaling vary by task and diminish with increased problem complexity. A notable performance gap remains despite using more tokens, but significant gains are observed with perfect verifiers or strong feedback, indicating potential for future improvements.
👉 Paper link: https://huggingface.co/papers/2504.00294

22. Chapter-Llama: Efficient Chaptering in Hour-Long Videos with LLMs
🔑 Keywords: large language model, chaptering, speech transcripts, frame selection, timestamps
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address video chaptering by partitioning long videos into semantic units and generating chapter titles to enhance navigation and content retrieval.
🛠️ Research Methods:
– Utilizes a pretrained large language model (LLM) for processing speech transcripts and captions with timestamps.
– Proposes a speech-guided frame selection strategy to efficiently choose relevant frames based on transcript content.
💬 Research Conclusions:
– The ‘Chapter-Llama’ framework significantly improves chaptering performance on long videos with a substantial increase in F1 score from 26.7 to 45.3.
– The approach allows processing hour-long videos in a single forward pass, demonstrating remarkable scalability and efficiency.
👉 Paper link: https://huggingface.co/papers/2504.00072

23. m1: Unleash the Potential of Test-Time Scaling for Medical Reasoning with Large Language Models
🔑 Keywords: Test-time scaling, large language models, medical reasoning, medical knowledge, reasoning token budget
💡 Category: AI in Healthcare
🌟 Research Objective:
– To investigate and determine the effectiveness of test-time scaling for enhancing medical reasoning capabilities in language models.
🛠️ Research Methods:
– Developed a simple approach, named m1, to improve model’s medical reasoning capability during inference.
– Conducted evaluations across diverse medical tasks to establish performance benchmarks.
💬 Research Conclusions:
– Test-time scaling consistently improves medical reasoning, with lightweight fine-tuned models achieving state-of-the-art performance in models under 10B parameters.
– Identified an optimal reasoning token budget of approximately 4K, with potential performance degradation beyond this limit due to overthinking.
– Improved data quality and expanded model capacity are crucial for enhancing medical knowledge and achieving continued performance improvements.
– Budget forcing does not always improve medical QA performance and can introduce errors, highlighting the importance of enriched medical knowledge over increased reasoning depth alone.
👉 Paper link: https://huggingface.co/papers/2504.00869

24. Discovering Knowledge Deficiencies of Language Models on Massive Knowledge Base
🔑 Keywords: Large Language Models, Knowledge deficiencies, Stochastic Error Ascent, Semantic similarity, Data coverage
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address the challenges of identifying factual knowledge deficiencies in closed-weight LLMs by proposing a novel framework.
🛠️ Research Methods:
– Introduction of Stochastic Error Ascent (SEA), leveraging hierarchical retrieval and semantic similarity, to enhance the discovery and analysis of knowledge errors.
💬 Research Conclusions:
– SEA outperforms existing methods like Automated Capability Discovery and AutoBencher in identifying more errors and reducing costs, underscoring the need for better data coverage and targeted fine-tuning in LLM development.
👉 Paper link: https://huggingface.co/papers/2503.23361

25. ManipTrans: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning
🔑 Keywords: DexManipNet, ManipTrans, bimanual skills, embodied AI, robotic manipulation
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To efficiently transfer human bimanual skills to dexterous robotic hands using a novel method, ManipTrans.
🛠️ Research Methods:
– Introduce ManipTrans, a two-stage method involving a generalist trajectory imitator and a specific residual module fine-tuned under interaction constraints.
💬 Research Conclusions:
– ManipTrans outperforms state-of-the-art methods in success rate, fidelity, and efficiency, creating the extensible DexManipNet dataset with previously unexplored tasks.
👉 Paper link: https://huggingface.co/papers/2503.21860

26. Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
🔑 Keywords: Text-to-SQL, Reward-driven self-exploration, Reinforcement Learning (RL), Schema-linking, AI Feedback
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance reasoning capabilities and generalization in Text-to-SQL tasks using reward-driven self-exploration.
🛠️ Research Methods:
– Introducing a novel set of partial rewards, including schema-linking, AI feedback, n-gram similarity, and syntax check, tailored for the Text-to-SQL task, employing group relative policy optimization (GRPO).
💬 Research Conclusions:
– The RL-trained model using the proposed reward framework achieves significantly higher accuracy and generalization in SQL query generation compared to models trained with supervised fine-tuning, outperforming larger models on the BIRD benchmark.
👉 Paper link: https://huggingface.co/papers/2503.23157

27. DiET-GS: Diffusion Prior and Event Stream-Assisted Motion Deblurring 3D Gaussian Splatting
🔑 Keywords: Novel View Synthesis, Diffusion Prior, Event Stream, Motion Deblurring, Edge Details
💡 Category: Computer Vision
🌟 Research Objective:
– To reconstruct sharp 3D representations from blurry multi-view images using a novel approach that enhances visual quality particularly affected by motion blur.
🛠️ Research Methods:
– Development of the DiET-GS framework utilizing blur-free event streams and diffusion prior in a two-stage training strategy.
– Introduction of a framework constrained by event double integral for achieving accurate color and detailed definition.
💬 Research Conclusions:
– The proposed DiET-GS method significantly improves the quality of novel views both qualitatively and quantitatively compared to existing baselines, demonstrated on synthetic and real-world data.
👉 Paper link: https://huggingface.co/papers/2503.24210

28. MB-ORES: A Multi-Branch Object Reasoner for Visual Grounding in Remote Sensing
🔑 Keywords: unified framework, object detection, visual grounding, remote sensing, graph representation
💡 Category: Computer Vision
🌟 Research Objective:
– The paper proposes a unified framework to integrate Object Detection (OD) and Visual Grounding (VG) for Remote Sensing (RS) imagery.
🛠️ Research Methods:
– Fine-tuning an open-set object detector using referring expression data to support OD and VG tasks.
– Constructing a graph representation of each image and using a task-aware architecture to perform VG tasks.
– Utilizing a multi-branch network and an object reasoning network for task-aware proposals and localization.
💬 Research Conclusions:
– The proposed model demonstrates superior performance on the OPT-RSVG and DIOR-RSVG datasets, surpassing state-of-the-art methods while maintaining classical OD capabilities.
– The model’s code is available on the provided GitHub repository.
👉 Paper link: https://huggingface.co/papers/2503.24219

29.
