AI Native Daily Paper Digest – 20250403

1. MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
🔑 Keywords: Masked Image Modeling, Vector Quantization, token merging, representation learning, generative models
💡 Category: Generative Models
🌟 Research Objective:
– Propose MergeVQ, a method to harmonize image generation with visual representation learning using token merging within VQ-based generative models.
🛠️ Research Methods:
– Incorporation of a token merge module after self-attention blocks for Look-up Free Quantization and global alignment; use of cross-attention in the decoder for reconstruction.
💬 Research Conclusions:
– MergeVQ demonstrates competitive results on ImageNet for visual representation learning and image generation tasks, achieving token efficiency and favorable inference speed as an AR generative model.
👉 Paper link: https://huggingface.co/papers/2504.00999

2. Improved Visual-Spatial Reasoning via R1-Zero-Like Training
🔑 Keywords: Multi-Modal Large Language Models, Visual-Spatial Intelligence, GRPO Training, vsGRPO Models, Chain of Thought
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the visual-spatial reasoning abilities of Multi-Modal Large Language Models (MLLMs) using R1-Zero-like training methods.
🛠️ Research Methods:
– Implemented GRPO training to improve visual-spatial reasoning, utilizing the carefully curated VSI-100k dataset.
– Introduced vsGRPO-2B and vsGRPO-7B models fine-tuned from Qwen2-VL models.
– Maintained a small KL penalty during training for better results.
💬 Research Conclusions:
– vsGRPO-2B model showed a 12.1% improvement over the base model and outperformed GPT-4o within 120 GPU hours.
– vsGRPO-7B model performance was comparable to LLaVA-NeXT-Video-72B, highlighting the superiority of vsGRPO over baseline methods.
– Code and dataset for future research will be made available soon.
👉 Paper link: https://huggingface.co/papers/2504.00883

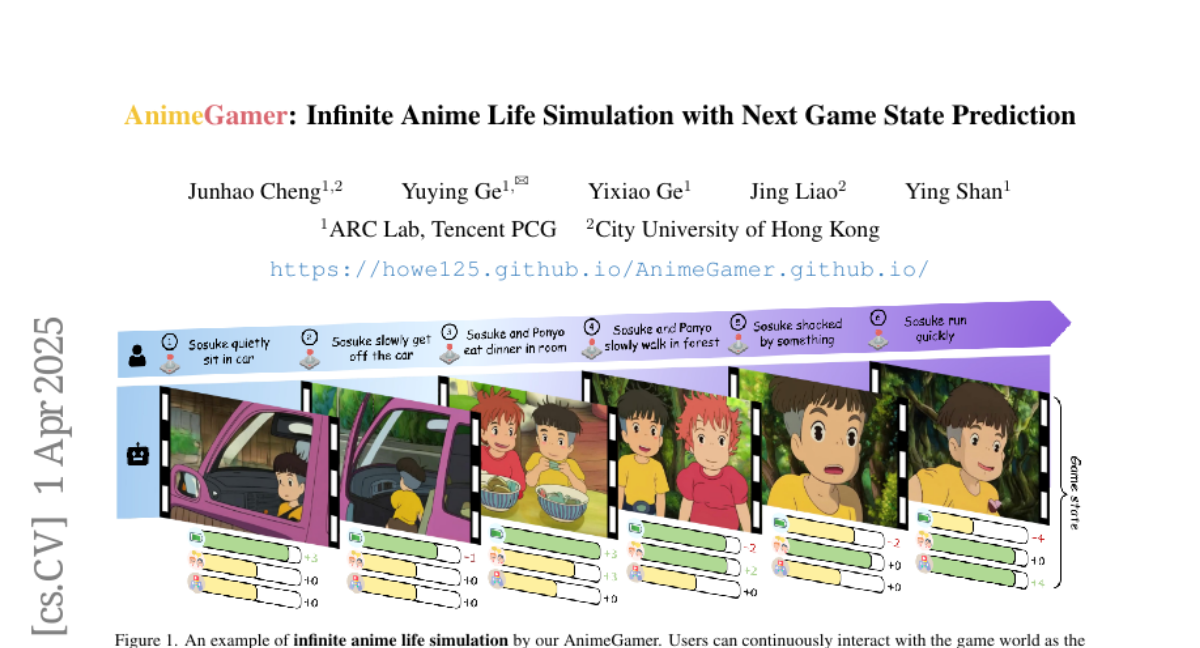
3. AnimeGamer: Infinite Anime Life Simulation with Next Game State Prediction
🔑 Keywords: AI Native, Multimodal Large Language Models, Video Diffusion Model, Infinite Games, AnimeGamer
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To create interactive anime characters for immersive gaming using large language models to overcome the limitations of static image generation.
🛠️ Research Methods:
– Developing AnimeGamer by utilizing Multimodal Large Language Models combined with novel action-aware multimodal representations and a video diffusion model for dynamic animation generation.
💬 Research Conclusions:
– AnimeGamer successfully enhances the gaming experience by providing contextual consistency and dynamics, outperforming existing methods according to both automated and human evaluations.
👉 Paper link: https://huggingface.co/papers/2504.01014
4. Understanding R1-Zero-Like Training: A Critical Perspective
🔑 Keywords: Reinforcement Learning, Reasoning Capabilities, Base Models, Optimization Bias, Token Efficiency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To examine the training of R1-Zero-like models by analyzing the impact of base models and RL on reasoning capabilities without supervised fine-tuning.
🛠️ Research Methods:
– Investigated various base models to assess pretraining influences on RL performance, identifying biases in optimization methods.
💬 Research Conclusions:
– Revealed potential pretraining biases and an optimization bias in GRPO, leading to the introduction of Dr. GRPO for improved token efficiency, achieving state-of-the-art accuracy with a minimalist R1-Zero recipe.
👉 Paper link: https://huggingface.co/papers/2503.20783

5. Towards Physically Plausible Video Generation via VLM Planning
🔑 Keywords: Video diffusion models, Vision Language Model, Physics-aware reasoning, Motion trajectories
💡 Category: Generative Models
🌟 Research Objective:
– To address the limitation of Video diffusion models in generating physically plausible videos by integrating an understanding of physics.
🛠️ Research Methods:
– A novel two-stage image-to-video generation framework is proposed. It utilizes a Vision Language Model as a motion planner incorporating chain-of-thought and physics-aware reasoning in the first stage, and guides the video generation of a Video diffusion model using predicted motion trajectories in the second stage, adding noise to enhance fine details.
💬 Research Conclusions:
– The framework successfully produces physically plausible motion, with experimental results and comparative evaluations demonstrating its superiority over existing methods.
👉 Paper link: https://huggingface.co/papers/2503.23368

6. DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance
🔑 Keywords: AI Native, Diffusion Transformer, Facial Expressions, Long-term Temporal Coherence, Multi-scale Adaptability
💡 Category: Computer Vision
🌟 Research Objective:
– To address gaps in fine-grained control, adaptability, and temporal coherence in image-based human animation.
🛠️ Research Methods:
– Introduction of the DreamActor-M1 framework based on a diffusion transformer with hybrid guidance incorporating implicit facial representations, 3D head spheres, and 3D body skeletons.
– Implementation of a progressive training strategy to manage various body poses and image scales.
💬 Research Conclusions:
– The proposed method outperforms state-of-the-art techniques, offering expressive, identity-preserving animations with robust long-term consistency across different scales.
👉 Paper link: https://huggingface.co/papers/2504.01724

7. VideoScene: Distilling Video Diffusion Model to Generate 3D Scenes in One Step
🔑 Keywords: 3D scenes, sparse views, video diffusion models, VideoScene, 3D-aware leap flow distillation
💡 Category: Generative Models
🌟 Research Objective:
– To develop VideoScene, an efficient tool to generate 3D scenes from sparse views using video diffusion models.
🛠️ Research Methods:
– Implementing a 3D-aware leap flow distillation strategy.
– Training a dynamic denoising policy network to optimize inference time.
💬 Research Conclusions:
– VideoScene achieves faster and superior 3D scene generation compared to previous methods, offering potential in video to 3D applications.
👉 Paper link: https://huggingface.co/papers/2504.01956
8. PaperBench: Evaluating AI’s Ability to Replicate AI Research
🔑 Keywords: AI engineering, replication, benchmark, ICML 2024, AI agents
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate AI agents’ ability to replicate state-of-the-art AI research, specifically focusing on reproducing 20 ICML 2024 Spotlight and Oral papers.
🛠️ Research Methods:
– Introduction of PaperBench, a benchmark consisting of 8,316 individually gradable tasks with rubrics developed in collaboration with ICML authors and an LLM-based judge for automated grading.
💬 Research Conclusions:
– The best-performing agent achieved a 21.0% average replication score, but AI models still lag behind human performance in replication tasks.
👉 Paper link: https://huggingface.co/papers/2504.01848

9. ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations
🔑 Keywords: ScholarCopilot, Retrieval-Augmented Generation, Large Language Models, Citation Recall, Writing Efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces ScholarCopilot, a framework to enhance large language models for generating academic articles with precise and contextually relevant citations.
🛠️ Research Methods:
– ScholarCopilot uses a retrieval token to dynamically acquire scholarly references and integrates these into the text generation process. The framework is optimized jointly for both text generation and citation tasks, leveraging a dataset of 500K papers from arXiv.
💬 Research Conclusions:
– ScholarCopilot achieves a top-1 retrieval accuracy of 40.1% and excels in generation quality compared to other models. Human studies confirm its superior performance in citation recall, writing efficiency, and overall user satisfaction.
👉 Paper link: https://huggingface.co/papers/2504.00824

10. ILLUME+: Illuminating Unified MLLM with Dual Visual Tokenization and Diffusion Refinement
🔑 Keywords: ILLUME+, Dual Visual Tokenization, Diffusion Decoder, Deep Semantic Understanding, Multimodal Understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a unified model, ILLUME+, that enhances deep semantic understanding and high-fidelity image generation by leveraging dual visual tokenization and a diffusion decoder.
🛠️ Research Methods:
– Utilized a unified dual visual tokenizer, DualViTok, for preserving textures and semantics.
– Employed a diffusion model as the image detokenizer for improved quality and super-resolution.
– Adopted a continuous-input, discrete-output scheme and a progressive training procedure for dynamic resolution.
💬 Research Conclusions:
– ILLUME+ shows competitive performance across multimodal understanding, generation, and editing tasks, providing a scalable foundation for future multimodal applications.
👉 Paper link: https://huggingface.co/papers/2504.01934

11. Articulated Kinematics Distillation from Video Diffusion Models
🔑 Keywords: Articulated Kinematics Distillation, skeleton-based representation, joint-level control, video diffusion models, text-to-4D generation
💡 Category: Generative Models
🌟 Research Objective:
– To develop a framework, Articulated Kinematics Distillation (AKD), that generates high-fidelity character animations by combining skeleton-based animation and generative models.
🛠️ Research Methods:
– Utilizes skeleton-based representation to reduce Degrees of Freedom, focuses on joint-level control for efficient motion synthesis, and applies Score Distillation Sampling with pre-trained video diffusion models to maintain structural integrity.
💬 Research Conclusions:
– AKD achieves superior 3D consistency and motion quality compared to existing text-to-4D generation methods, ensuring physically plausible interactions with compatibility in physics-based simulations.
👉 Paper link: https://huggingface.co/papers/2504.01204

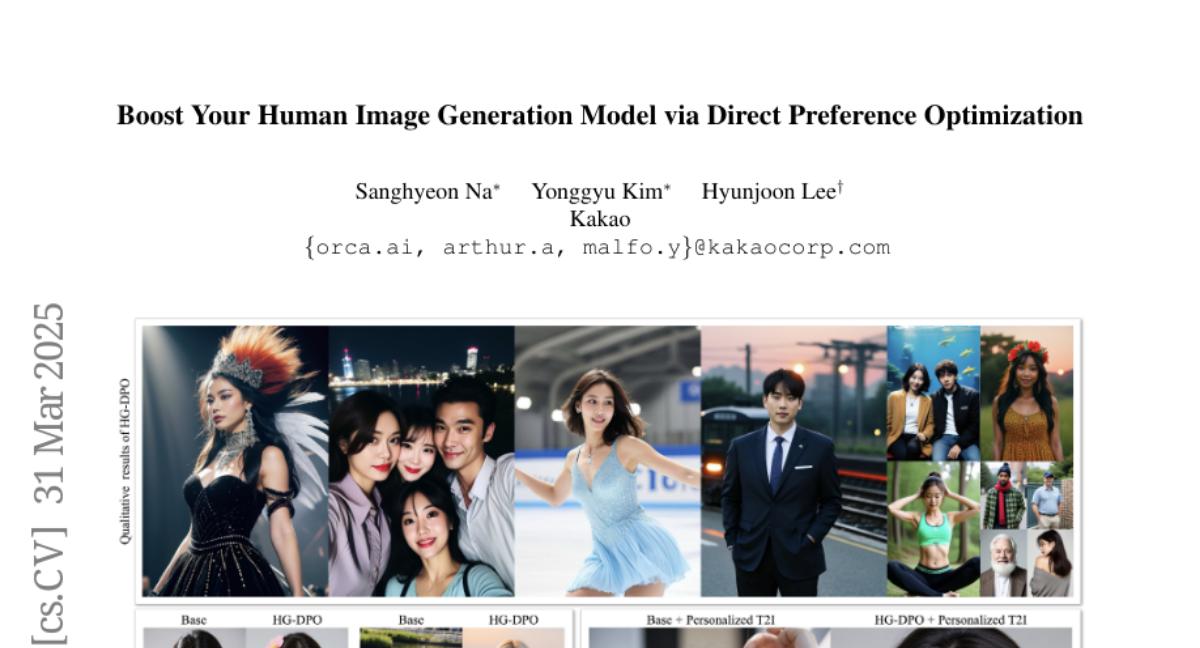
12. Boost Your Own Human Image Generation Model via Direct Preference Optimization with AI Feedback
🔑 Keywords: Text-to-Image (T2I), Diffusion Models, Direct Preference Optimization (DPO), Human Image Generation, Image Fidelity
💡 Category: Generative Models
🌟 Research Objective:
– To develop an innovative approach for high-quality human image generation using text-to-image (T2I) methods, optimizing for human pose, anatomy, and alignment with textual prompts via Direct Preference Optimization (DPO).
🛠️ Research Methods:
– Introduced a specialized DPO dataset for training models without costly human feedback.
– Proposed a modified loss function to minimize artifacts and enhance image fidelity during training.
💬 Research Conclusions:
– The proposed method significantly improves the generation of human images, demonstrating advancements in achieving natural anatomies, poses, and text-image alignment.
👉 Paper link: https://huggingface.co/papers/2405.20216
13. Safeguarding Vision-Language Models: Mitigating Vulnerabilities to Gaussian Noise in Perturbation-based Attacks
🔑 Keywords: Vision-Language Models, noise-augmented training, Robust-VLGuard, DiffPure-VLM, diffusion models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address vulnerabilities in Vision-Language Models (VLMs) caused by missing noise-augmented training, which leaves them susceptible to jailbreak attacks involving noisy or corrupted images.
🛠️ Research Methods:
– Introduction of Robust-VLGuard, a multimodal safety dataset with aligned/misaligned image-text pairs combined with noise-augmented fine-tuning to reduce attack success rates.
– Development of DiffPure-VLM using diffusion models to transform adversarial perturbations into Gaussian-like noise, defending them with noise-augmented safety fine-tuning.
💬 Research Conclusions:
– Experimental results show that the distribution-shifting property of diffusion models aligns with fine-tuned VLMs, significantly reducing adversarial perturbations across different intensity levels.
👉 Paper link: https://huggingface.co/papers/2504.01308

14. DASH: Detection and Assessment of Systematic Hallucinations of VLMs
🔑 Keywords: Vision-language models, object hallucinations, DASH, open-world settings, fine-tuning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to address the problem of object hallucinations in Vision-language models (VLMs) and proposes an effective solution for use in open-world settings.
🛠️ Research Methods:
– The authors introduce DASH, an automatic, large-scale pipeline designed to detect and assess systematic hallucinations in VLMs by optimizing over the “natural image manifold”.
– They utilize DASH-OPT for image-based retrieval to generate misleading images for VLMs.
💬 Research Conclusions:
– The study found over 19k clusters with 950k images where VLMs hallucinate objects.
– Fine-tuning PaliGemma with images obtained through DASH successfully mitigates object hallucinations in VLMs, showing transferability of the approach to other models.
👉 Paper link: https://huggingface.co/papers/2503.23573

15. LSNet: See Large, Focus Small
🔑 Keywords: Vision network designs, lightweight and efficient network designs, self-attention mechanisms, efficiency, LSNet
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a lightweight vision network design inspired by the dynamic heteroscale vision ability of the human vision system.
🛠️ Research Methods:
– Introduced a “See Large, Focus Small” strategy through LS convolution, combining large-kernel perception and small-kernel aggregation.
– Developed LSNet, a family of lightweight models incorporating LS convolution.
💬 Research Conclusions:
– LSNet achieves superior performance and efficiency over existing lightweight networks in various vision tasks.
– Validated through extensive experiments, with codes and models available to the public.
👉 Paper link: https://huggingface.co/papers/2503.23135

16. Quamba2: A Robust and Scalable Post-training Quantization Framework for Selective State Space Models
🔑 Keywords: State Space Models, Quantizing, High Performance, Memory Usage, Hardware Acceleration
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to overcome storage and computational challenges in scaling up State Space Models (SSMs) by using low bit-width quantization, improving deployment across cloud services and limited-resource devices.
🛠️ Research Methods:
– An offline approach to quantize inputs using sorting and clustering for a linear recurrence in 8-bit, with per-state-group quantization for input-dependent parameters, ensuring compute-invariance by rearranging weights offline.
💬 Research Conclusions:
– Quamba2-8B enhances performance by providing significant speed-ups and memory reductions with minimal accuracy loss, proving generalizability and robustness in evaluations like MMLU, with a source code available on GitHub.
👉 Paper link: https://huggingface.co/papers/2503.22879

17. VerifiAgent: a Unified Verification Agent in Language Model Reasoning
🔑 Keywords: VerifiAgent, reasoning capabilities, meta-verification, adaptive approach, verification tools
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to address the limitations of existing model-specific or domain-restricted verification methods by introducing VerifiAgent, a unified verification agent.
🛠️ Research Methods:
– VerifiAgent integrates meta-verification for assessing completeness and consistency, and a tool-based adaptive approach for selecting verification tools based on reasoning type.
💬 Research Conclusions:
– VerifiAgent outperforms baseline verification methods in reasoning tasks, enhances reasoning accuracy through feedback, and achieves better results in inference scaling with fewer generated samples and costs.
👉 Paper link: https://huggingface.co/papers/2504.00406

18. MegaTTS 3: Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
🔑 Keywords: Zero-shot TTS, Speech-text alignment, Sparse alignment algorithm, Latent diffusion transformer, Accent intensity
💡 Category: Generative Models
🌟 Research Objective:
– Introduce MegaTTS 3, a novel TTS system addressing speech-text alignment challenges to enhance robustness and naturalness.
🛠️ Research Methods:
– Implement a sparse alignment algorithm for easing alignment tasks, integrate a multi-condition classifier-free guidance strategy for accent control, and apply piecewise rectified flow to speed up generation.
💬 Research Conclusions:
– MegaTTS 3 achieves state-of-the-art zero-shot TTS speech quality, providing flexible accent intensity control, and efficiently generates high-quality speech with minimal sampling steps.
👉 Paper link: https://huggingface.co/papers/2502.18924

19. Enhanced OoD Detection through Cross-Modal Alignment of Multi-Modal Representations
🔑 Keywords: Multi-Modal Fine-Tuning, Out-of-Distribution Detection, CLIP, Cross-Modal Alignment, Hyperspherical Representation Space
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Investigate the limitations of naive fine-tuning methods for Out-of-Distribution Detection (OoDD) using multi-modal representations and propose a solution to improve performance.
🛠️ Research Methods:
– Analyze the modality gap within in-distribution embeddings, and propose a training objective to enhance cross-modal alignment by regularizing distances between image and text embeddings.
💬 Research Conclusions:
– Demonstrated that the proposed regularization enhances the utilization of pretrained textual information, leading to superior OoDD performance and in-distribution accuracy compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2503.18817

20. Target-Aware Video Diffusion Models
🔑 Keywords: target-aware video diffusion model, segmentation mask, text prompt, pretrained models, human-object interaction (HOI)
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to generate videos from an input image where an actor interacts with a specified target while performing a desired action using a target-aware video diffusion model.
🛠️ Research Methods:
– A baseline model is extended to incorporate the target mask as an additional input, introducing a special token to encode the target’s spatial information in the text prompt. A novel cross-attention loss aligns the cross-attention maps with the input target mask, selectively applied to relevant transformer blocks and attention regions.
💬 Research Conclusions:
– The target-aware model outperforms existing solutions in ensuring accurate interaction with specified targets in videos. It is also effective for video content creation and zero-shot 3D HOI motion synthesis applications.
👉 Paper link: https://huggingface.co/papers/2503.18950
21. Adaptive Layer-skipping in Pre-trained LLMs
🔑 Keywords: FlexiDepth, large language models, adaptive layer-skipping, computational demands, open sourced
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce FlexiDepth, a method to dynamically adjust Transformer layers in text generation for large language models.
🛠️ Research Methods:
– Implement a plug-in router and adapter for adaptive layer-skipping in models like Llama-3-8B without altering the original parameters.
💬 Research Conclusions:
– Different token generations require varying computational demands, with repetitive tokens needing fewer layers and complex tokens needing more. FlexiDepth achieves efficient layer skipping while maintaining full benchmark performance and has been open sourced for further research.
👉 Paper link: https://huggingface.co/papers/2503.23798

22. Medical large language models are easily distracted
🔑 Keywords: Large Language Models, Ambient Dictation, MedDistractQA, Clinical Information, Performance
💡 Category: AI in Healthcare
🌟 Research Objective:
– To assess the ability of large language models (LLMs) to filter relevant clinical data in real-world scenarios containing extraneous information.
🛠️ Research Methods:
– Developed MedDistractQA, a benchmark using USMLE-style questions with simulated real-world distractions to test LLM accuracy under noisy conditions.
💬 Research Conclusions:
– Distracting statements can reduce LLM accuracy by up to 17.9%. Solutions like retrieval-augmented generation and medical fine-tuning did not improve performance and sometimes worsened it.
– LLMs lack the logical mechanisms to differentiate relevant from irrelevant clinical information, highlighting the need for robust mitigation strategies.
👉 Paper link: https://huggingface.co/papers/2504.01201

23.
