AI Native Daily Paper Digest – 20250404

1. Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
🔑 Keywords: Large Language Models, Intelligent Agents, Ethical AI, AutoML
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To provide a comprehensive overview of intelligent agents framed within a modular, brain-inspired architecture, integrating cognitive science, neuroscience, and computational principles.
🛠️ Research Methods:
– The study structures its exploration into four interconnected parts, examining modular foundations, self-enhancement mechanisms, collaborative multi-agent systems, and safety considerations.
💬 Research Conclusions:
– The survey emphasizes the importance of designing AI systems that are safe, secure, and beneficial, addressing intrinsic and extrinsic security threats and ethical alignment for trustworthy deployment.
👉 Paper link: https://huggingface.co/papers/2504.01990

2. Envisioning Beyond the Pixels: Benchmarking Reasoning-Informed Visual Editing
🔑 Keywords: Large Multi-modality Models, Visual Editing, Reasoning, RISEBench, GPT-4o-Native
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces RISEBench, aimed at evaluating Reasoning-Informed viSual Editing (RISE), focusing on enhancing Large Multi-modality Models (LMMs) in tasks like complex visual editing.
🛠️ Research Methods:
– Development of a benchmark, RISEBench, with test cases in Temporal, Causal, Spatial, and Logical Reasoning to assess Instruction Reasoning, Appearance Consistency, and Visual Plausibility, using both human and LMM-as-a-judge evaluation.
💬 Research Conclusions:
– While models like GPT-4o-Native excel compared to others, they still face challenges in logical reasoning tasks, indicating significant areas for improvement and future research in reasoning-aware visual editing.
👉 Paper link: https://huggingface.co/papers/2504.02826

3. ZClip: Adaptive Spike Mitigation for LLM Pre-Training
🔑 Keywords: Large Language Models (LLMs), Gradient Instability, ZClip, Adaptive Gradient Clipping
💡 Category: Machine Learning
🌟 Research Objective:
– Address challenges linked to training large language models by proposing ZClip for adaptive gradient clipping to enhance learning efficiency.
🛠️ Research Methods:
– Introduces ZClip, an algorithm that utilizes z-score-based anomaly detection to dynamically adjust clipping thresholds based on statistical properties of gradient norms.
💬 Research Conclusions:
– ZClip effectively mitigates large gradient spikes without hindering convergence and requires less manual intervention compared to traditional gradient clipping techniques.
👉 Paper link: https://huggingface.co/papers/2504.02507

4. GPT-ImgEval: A Comprehensive Benchmark for Diagnosing GPT4o in Image Generation
🔑 Keywords: GPT-4o, Image Generation, Image Editing, Semantic Synthesis, OpenAI
💡 Category: Generative Models
🌟 Research Objective:
– Evaluate the capabilities of the GPT-4o model in image generation and editing through a newly proposed benchmark, GPT-ImgEval.
🛠️ Research Methods:
– Quantitative and qualitative assessment of GPT-4o’s performance across generation quality, editing proficiency, and world knowledge-informed semantic synthesis.
– Proposal of a classification-model-based approach to investigate GPT-4o’s underlying architecture, hypothesizing an auto-regressive model with a diffusion-based head for image decoding.
💬 Research Conclusions:
– GPT-4o exhibits superior performance in image generation control and quality compared to existing methods and demonstrates robust knowledge reasoning abilities.
– Identified limitations and artifacts in GPT-4o’s image generation, compared multi-round image editing capabilities with Gemini 2.0 Flash.
– Discussed the detectability of GPT-4o’s outputs by image forensic models and highlighted safety implications.
👉 Paper link: https://huggingface.co/papers/2504.02782

5. Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
🔑 Keywords: Reinforcement Learning, Vision-Language Models, Reproducibility, Training Dynamics, Reflection
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce a transparent framework for applying Reinforcement Learning (RL) to Vision-Language Models (VLMs) to improve reproducibility and comparability in empirical studies.
🛠️ Research Methods:
– Developed a minimal four-step pipeline validated across various models and datasets.
– Proposed a standardized evaluation scheme to assess training dynamics and reflective behaviors.
💬 Research Conclusions:
– Demonstrated that RL outperforms supervised fine-tuning in generalization, regardless of data quality.
– Uncovered that response length is sensitive to random seeds and that reflection correlates with output length.
👉 Paper link: https://huggingface.co/papers/2504.02587

6. WikiVideo: Article Generation from Multiple Videos
🔑 Keywords: Retrieval-Augmented Generation (RAG), WikiVideo, Collaborative Article Generation (CAG)
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a high-level Wikipedia-style article generation method that aggregates information from various videos about real-world events.
🛠️ Research Methods:
– Introduces WikiVideo, a benchmark including expert-written articles and annotated videos, and proposes Collaborative Article Generation (CAG), an interactive method leveraging a reasoning model and VideoLLM for effective event inference.
💬 Research Conclusions:
– CAG demonstrates superior performance over existing methods in both oracle retrieval and RAG settings, indicating promising future directions.
👉 Paper link: https://huggingface.co/papers/2504.00939

7. Scaling Analysis of Interleaved Speech-Text Language Models
🔑 Keywords: Speech Language Model, compute, knowledge transfer, TextLMs, synthetic data
💡 Category: Natural Language Processing
🌟 Research Objective:
– To analyze the efficiency of interleaved Speech Language Models in scaling compared to textless Speech Language Models.
🛠️ Research Methods:
– Conducted scaling analysis by training several dozen interleaved models and analyzing scaling trends.
– Studied the role of synthetic data and model families in enhancing scaling efficiency.
💬 Research Conclusions:
– Interleaved Speech Language Models scale more efficiently than textless models, especially when allocating more compute budget to model size.
– The scaled-up model achieves competitive performance on speech semantic metrics while utilizing less compute and data.
– Models, samples, and data have been open-sourced for public access.
👉 Paper link: https://huggingface.co/papers/2504.02398

8. SkyReels-A2: Compose Anything in Video Diffusion Transformers
🔑 Keywords: SkyReels-A2, elements-to-video (E2V), open-source commercial grade model, high-quality videos
💡 Category: Generative Models
🌟 Research Objective:
– To develop a controllable video generation framework, SkyReels-A2, that synthesizes videos from arbitrary visual elements using textual prompts and ensures strict consistency with reference images.
🛠️ Research Methods:
– Designed a comprehensive data pipeline to construct prompt-reference-video triplets for training.
– Proposed an image-text joint embedding model to balance element-specific consistency with global coherence.
– Optimized inference pipeline for speed and output stability.
– Introduced A2 Bench as a benchmark for systematic evaluation.
💬 Research Conclusions:
– SkyReels-A2 can generate diverse, high-quality videos with precise element control.
– The first open-source commercial grade model for E2V, performing better than advanced closed-source commercial models.
– Anticipated to advance creative applications such as drama and virtual e-commerce.
👉 Paper link: https://huggingface.co/papers/2504.02436

9. Inference-Time Scaling for Generalist Reward Modeling
🔑 Keywords: Reinforcement Learning, Large Language Models, Reward Modeling, Inference-Time Scalability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance reward modeling with robust inferencing capabilities for large language models (LLMs) using reinforcement learning, focusing on inference-time scalability for generalist tasks.
🛠️ Research Methods:
– The research adopts pointwise generative reward modeling (GRM) for flexible inputs and proposes Self-Principled Critique Tuning (SPCT) to enhance scalable reward generation through online RL.
💬 Research Conclusions:
– SPCT improves the quality and scalability of reward models, outperforming existing methods and showcasing better performance than training-time scaling in various RM benchmarks. Future work will address remaining challenges in generalist reward systems, with models open-sourced for continued development.
👉 Paper link: https://huggingface.co/papers/2504.02495

10. JavisDiT: Joint Audio-Video Diffusion Transformer with Hierarchical Spatio-Temporal Prior Synchronization
🔑 Keywords: JavisDiT, Diffusion Transformer, Synchronized Audio-Video Generation, Spatio-Temporal Alignment, JavisBench
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces JavisDiT, a novel model for synchronized audio-video generation.
– It aims to ensure optimal synchronization of audio and video content generated from user prompts.
🛠️ Research Methods:
– JavisDiT is built on the Diffusion Transformer architecture with a Hierarchical Spatial-Temporal Synchronized Prior Estimator for precise alignment.
– A new benchmark, JavisBench, and a robust evaluation metric for synchronization are developed.
💬 Research Conclusions:
– Experimental results show that JavisDiT outperforms existing methods in quality and synchronization, establishing a new standard for synchronized audio-video generation tasks.
– The project’s code, model, and dataset will be publicly accessible.
👉 Paper link: https://huggingface.co/papers/2503.23377
11. ShortV: Efficient Multimodal Large Language Models by Freezing Visual Tokens in Ineffective Layers
🔑 Keywords: Multimodal Large Language Models, computational costs, visual tokens, Layer Contribution, ShortV
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to investigate layer-wise redundancy in Multimodal Large Language Models (MLLMs) by introducing a novel metric called Layer Contribution (LC).
🛠️ Research Methods:
– A pilot experiment was conducted to measure the divergence in model output resulting from removing layer transformations on visual and text tokens.
– A training-free method, ShortV, was proposed to identify ineffective layers and freeze visual token updates in these layers.
💬 Research Conclusions:
– The study finds that many layers in MLLMs have minimal contribution to processing visual tokens.
– ShortV can freeze visual token updates in approximately 60% of MLLM layers, resulting in a significant reduction in computational costs, achieving a 50% reduction in FLOPs on LLaVA-NeXT-13B while maintaining performance.
👉 Paper link: https://huggingface.co/papers/2504.00502

12. Audio-visual Controlled Video Diffusion with Masked Selective State Spaces Modeling for Natural Talking Head Generation
🔑 Keywords: multi-signals control, gate mechanism, mamba structure, mask-drop strategy, facial videos
💡 Category: Computer Vision
🌟 Research Objective:
– To develop ACTalker, an end-to-end video diffusion framework for talking head synthesis that allows both single-signal and multi-signals control.
🛠️ Research Methods:
– Implemented a parallel mamba structure with multiple branches for facial region control and integrated a gate mechanism for flexible video generation.
– Introduced a mask-drop strategy to enable independent control of facial regions and prevent control conflicts.
💬 Research Conclusions:
– Demonstrated that the proposed method can produce natural-looking facial videos driven by diverse signals and effectively integrate multiple driving modalities without conflict.
👉 Paper link: https://huggingface.co/papers/2504.02542
13. Scaling Laws in Scientific Discovery with AI and Robot Scientists
🔑 Keywords: Autonomous Generalist Scientist, AI-based Robot Scientists, Knowledge Integration, Scientific Discovery, Embodied Robotics
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To conceptualize an Autonomous Generalist Scientist (AGS) that employs agentic AI and embodied robotics to automate the research lifecycle.
🛠️ Research Methods:
– Utilizing technologies in physical and virtual environments to enable knowledge integration across multiple disciplines.
💬 Research Conclusions:
– AGS could drastically reduce time and resource needs in scientific research, potentially adhering to new scaling laws that reshape how knowledge is generated and expanded.
👉 Paper link: https://huggingface.co/papers/2503.22444

14. Efficient Model Selection for Time Series Forecasting via LLMs
🔑 Keywords: Model selection, Time series forecasting, Meta-learning approaches, Large Language Models (LLMs)
💡 Category: Machine Learning
🌟 Research Objective:
– The paper aims to automate model selection in time series forecasting by using Large Language Models (LLMs), eliminating the need for costly pre-constructed performance matrices.
🛠️ Research Methods:
– Extensive experiments were conducted using LLaMA, GPT, and Gemini to evaluate the proposed LLM-based model selection approach.
💬 Research Conclusions:
– The study demonstrates the proposed method’s superiority over traditional meta-learning techniques and heuristic baselines, significantly reducing computational overhead while effectively selecting models for time series forecasting.
👉 Paper link: https://huggingface.co/papers/2504.02119

15. Interpreting Emergent Planning in Model-Free Reinforcement Learning
🔑 Keywords: Model-Free Reinforcement Learning, Planning, Concept-Based Interpretability, Learned Concept Representations, Causal Effect
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To provide mechanistic evidence that model-free reinforcement learning agents can learn to plan using concept-based interpretability.
🛠️ Research Methods:
– Probing for planning-relevant concepts, investigating plan formation within agent’s representations, and verifying causal effects on behavior through interventions.
💬 Research Conclusions:
– Demonstrated that DRC, the model-free agent, internally formulates plans that predict the effects on the environment and influence action selection, resembling parallelized bidirectional search.
👉 Paper link: https://huggingface.co/papers/2504.01871

16. FreSca: Unveiling the Scaling Space in Diffusion Models
🔑 Keywords: Diffusion models, noise predictions, classifier-free guidance, Fourier analysis, FreSca
💡 Category: Generative Models
🌟 Research Objective:
– Explore the potential of fine-grained semantic manipulation in the scaling space of diffusion models.
🛠️ Research Methods:
– Utilize Fourier analysis of noise predictions to apply guidance scaling independently to different frequency bands.
💬 Research Conclusions:
– Introduction of FreSca method enhances existing image editing methods without retraining and improves image understanding tasks such as depth estimation with quantitative gains across multiple datasets.
👉 Paper link: https://huggingface.co/papers/2504.02154

17. NeuralGS: Bridging Neural Fields and 3D Gaussian Splatting for Compact 3D Representations
🔑 Keywords: 3D Gaussian Splatting, NeuralGS, neural fields, Multi-Layer Perceptron
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to develop NeuralGS, a simple yet effective method for compressing 3D Gaussian Splatting models into a compact representation without using voxel structures and complex quantization strategies.
🛠️ Research Methods:
– NeuralGS uses neural field representation (like NeRF) and employs Multi-Layer Perceptron (MLP) neural networks to encode 3D Gaussians. A clustering strategy is implemented to fit Gaussians with different tiny MLPs based on their importance scores.
💬 Research Conclusions:
– Experiments across multiple datasets show a 45-times average reduction in model size without compromising visual quality. NeuralGS’s compression performance is comparable to Scaffold-GS-based methods, revealing the potential of using neural fields for direct compression of original 3DGS.
👉 Paper link: https://huggingface.co/papers/2503.23162

18. GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning
🔑 Keywords: Large Language Models, Process Reward Models, Chain-of-Thought reasoning, Relative Progress Estimation, GenPRM
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce GenPRM, a generative process reward model that enhances LLM performance by addressing key challenges in current PRMs.
🛠️ Research Methods:
– Implementation of Chain-of-Thought reasoning and code verification to enhance reasoning steps.
– Development of Relative Progress Estimation and rationale synthesis framework to generate quality process supervision labels.
💬 Research Conclusions:
– GenPRM significantly outperforms existing PRMs and even some advanced models like GPT-4 and Qwen2.5-Math-PRM-72B on specific datasets with limited training data.
– Establishes a new paradigm in process supervision, effectively bridging the gap between PRMs and critic models in LLMs.
👉 Paper link: https://huggingface.co/papers/2504.00891

19. Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
🔑 Keywords: Sparse Autoencoders, Vision-Language Models, monosemanticity, hierarchical representations, unsupervised approach
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Extend the application of Sparse Autoencoders to Vision-Language Models and evaluate monosemanticity in vision representations.
🛠️ Research Methods:
– Introduce a comprehensive framework to evaluate monosemanticity and apply Sparse Autoencoders to intervene on vision encoders without modifying underlying models.
💬 Research Conclusions:
– Sparse Autoencoders significantly enhance monosemanticity and align with expert-defined structures. They also allow steering of outputs from multimodal language models, emphasizing their practicality and efficacy.
👉 Paper link: https://huggingface.co/papers/2504.02821

20. Instruction-Guided Autoregressive Neural Network Parameter Generation
🔑 Keywords: IGPG, autoregressive framework, parameter synthesis, inter-layer coherence, pretrained models
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance model adaptability and transfer learning by generating neural network parameters conditioned on task instructions and architecture specifications.
🛠️ Research Methods:
– IGPG is an autoregressive framework using VQ-VAE to generate neural network weights, ensuring coherence and efficiency across models and datasets.
💬 Research Conclusions:
– IGPG outperforms state-of-the-art methods in scalability and efficiency, effectively consolidating pretrained models for superior performance in large architectures, particularly aiding pretrained weight retrieval and rapid task-specific fine-tuning.
👉 Paper link: https://huggingface.co/papers/2504.02012

21. Whisper-LM: Improving ASR Models with Language Models for Low-Resource Languages
🔑 Keywords: Automatic Speech Recognition, Multilingual Models, Minority Languages, Whisper, Fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the performance of multilingual and multitask speech recognition models in processing minority languages.
🛠️ Research Methods:
– Integration of traditional and novel language models with fine-tuned Whisper models, coupled with rigorous fine-tuning and evaluation across multiple datasets.
💬 Research Conclusions:
– Demonstrated substantial improvements in word error rate, achieving up to 51% improvement for in-distribution datasets and up to 34% for out-of-distribution sentences, emphasizing the significance of optimized language model parameters.
👉 Paper link: https://huggingface.co/papers/2503.23542

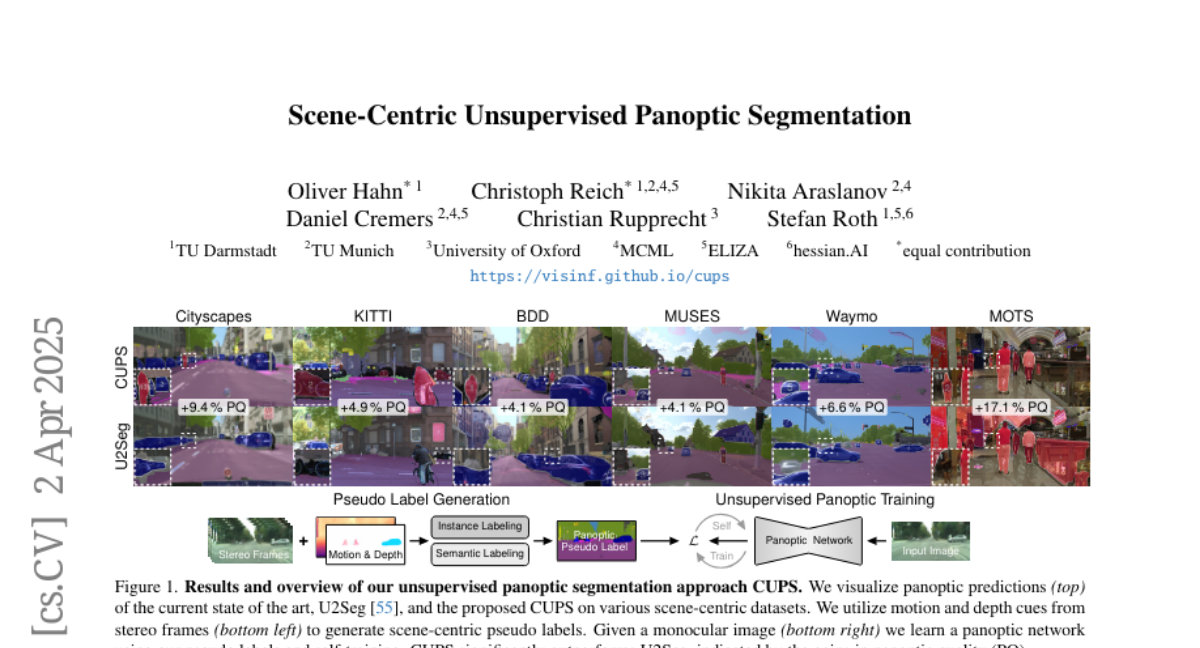
22. Scene-Centric Unsupervised Panoptic Segmentation
🔑 Keywords: unsupervised panoptic segmentation, semantically meaningful regions, distinct object instances, scene-centric imagery, panoptic pseudo labels
💡 Category: Computer Vision
🌟 Research Objective:
– To conduct unsupervised panoptic segmentation of complex scenes without relying on manually annotated data, facilitating understanding of semantic and instance segmentation.
🛠️ Research Methods:
– Developed a method to generate high-resolution panoptic pseudo labels using visual representations, depth, and motion cues from complex scene-centric data.
– Implemented a panoptic self-training strategy to enhance the accuracy of segmentation predictions.
💬 Research Conclusions:
– The proposed approach significantly improved panoptic quality, surpassing the recent state of the art in unsupervised panoptic segmentation, demonstrating a 9.4% increase in PQ on the Cityscapes dataset.
👉 Paper link: https://huggingface.co/papers/2504.01955
23. OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
🔑 Keywords: reasoning-based large language models, distilling reasoning capabilities, supervised fine-tuning (SFT), coding tasks, instruction diversity
💡 Category: Machine Learning
🌟 Research Objective:
– The research aims to bridge the gap between reasoning and standard large language models (LLMs) on coding tasks by constructing a superior supervised fine-tuning dataset.
🛠️ Research Methods:
– The study involves creating a fine-tuned dataset that enhances models’ coding capabilities, surpassing alternatives trained with reinforcement learning.
– Analysis is performed on the data sources, code execution filtering impact, and token efficiency to optimize the model’s reasoning patterns.
💬 Research Conclusions:
– Distilled models using only supervised fine-tuning achieved state-of-the-art results on benchmarks like LiveCodeBench and CodeContests.
– Instruction diversity is prioritized over solution correctness to improve benchmark accuracy.
– The datasets and models will be open-sourced to benefit the community.
👉 Paper link: https://huggingface.co/papers/2504.01943

24.
