AI Native Daily Paper Digest – 20250417

1. ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness
🔑 Keywords: Vision-Language Models, Color Understanding, ColorBench, CoT Reasoning, Multimodal AI
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to evaluate Vision-Language Models’ ability to understand and utilize color, introducing the benchmark ColorBench for this purpose.
🛠️ Research Methods:
– ColorBench was constructed to assess the models through varied test scenarios rooted in real applications, evaluating color perception, reasoning, and performance consistency under different transformations.
💬 Research Conclusions:
– The research discovers that larger models generally perform better, with language models playing a more crucial role than vision encoders.
– Performance disparities between models are minor, indicating that color understanding is often overlooked.
– CoT reasoning enhances accuracy and robustness in color-centric tasks, but color cues can sometimes mislead the models.
– The study underscores the need for improved color comprehension in VLMs and proposes ColorBench as a foundational tool for advancing multimodal AI’s human-level color understanding.
👉 Paper link: https://huggingface.co/papers/2504.10514

2. BitNet b1.58 2B4T Technical Report
🔑 Keywords: BitNet, Large Language Model, computational efficiency, open-source
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce BitNet b1.58 2B4T, a 1-bit Large Language Model at a 2-billion parameter scale.
🛠️ Research Methods:
– Trained on a corpus of 4 trillion tokens and evaluated across various benchmarks including language understanding, mathematical reasoning, coding proficiency, and conversational ability.
💬 Research Conclusions:
– BitNet achieves competitive performance with leading full-precision LLMs of similar size, while offering substantial benefits in computational efficiency, with reduced memory footprint, energy consumption, and decoding latency. Model weights are available via Hugging Face for further research and adoption.
👉 Paper link: https://huggingface.co/papers/2504.12285

3. ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
🔑 Keywords: Reinforcement Learning, Code Interpreters, Tool-Integrated Learning, AI Native, Complex Mathematical Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance long-form reasoning with tool-integrated learning methods to improve structured problem-solving capabilities in AI models.
🛠️ Research Methods:
– Introduced ReTool which integrates dynamic real-time code execution within natural language reasoning and uses an automated RL paradigm to optimize tool invocation strategies based on outcome feedback.
💬 Research Conclusions:
– ReTool demonstrates superior performance over traditional text-based RL models, achieving significant accuracy increases on the MATH Olympiad benchmark, highlighting the potential of hybrid neuro-symbolic systems for advancing complex mathematical reasoning.
👉 Paper link: https://huggingface.co/papers/2504.11536

4. AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference
🔑 Keywords: AlayaDB, vector database, Large Language Models, Service Level Objectives, attention computation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper introduces AlayaDB, a vector database system designed to enhance long-context inference for Large Language Models (LLMs).
🛠️ Research Methods:
– AlayaDB separates KV cache and attention computation from LLM inference systems, encapsulating them into a novel vector database system.
– It features a native query optimizer for optimizing performance by abstracting attention computation and cache management into query processing.
💬 Research Conclusions:
– AlayaDB demonstrates superior hardware efficiency and generation quality for Model as a Service providers, as proven through three industrial use cases and extensive LLM inference benchmark experiments.
👉 Paper link: https://huggingface.co/papers/2504.10326

5. Cobra: Efficient Line Art COlorization with BRoAder References
🔑 Keywords: line art colorization, diffusion models, Cobra, Causal Sparse DiT architecture
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve high accuracy, efficiency, and flexible control in line art colorization within the comic production industry through the introduction of a new method called Cobra.
🛠️ Research Methods:
– Cobra, utilizing the Causal Sparse DiT architecture, incorporates causal sparse attention, special positional encodings, and a Key-Value Cache to handle extensive contextual references while maintaining low latency and ensuring color identity consistency.
💬 Research Conclusions:
– Cobra successfully enhances line art colorization accuracy and interactivity, effectively meeting essential industry demands by employing over 200 reference images and improving inference speed.
👉 Paper link: https://huggingface.co/papers/2504.12240

6. SIFT-50M: A Large-Scale Multilingual Dataset for Speech Instruction Fine-Tuning
🔑 Keywords: Speech Instruction Fine-Tuning, Large Language Models, Instruction Fine-Tuning, Speech Understanding, Controllable Speech Generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce and evaluate SIFT-50M, a dataset designed for instruction fine-tuning and pre-training of speech-text large language models.
🛠️ Research Methods:
– Utilized publicly available speech corpora encompassing 14K hours of speech across five languages.
– Leveraged large language models and off-the-shelf expert models to build the dataset.
💬 Research Conclusions:
– SIFT-LLM, trained with SIFT-50M, outperforms existing models on instruction-following benchmarks and delivers competitive results on foundational speech tasks.
– Introduced EvalSIFT as a benchmark dataset to further assess the instruction-following capabilities of speech-text LLMs.
👉 Paper link: https://huggingface.co/papers/2504.09081

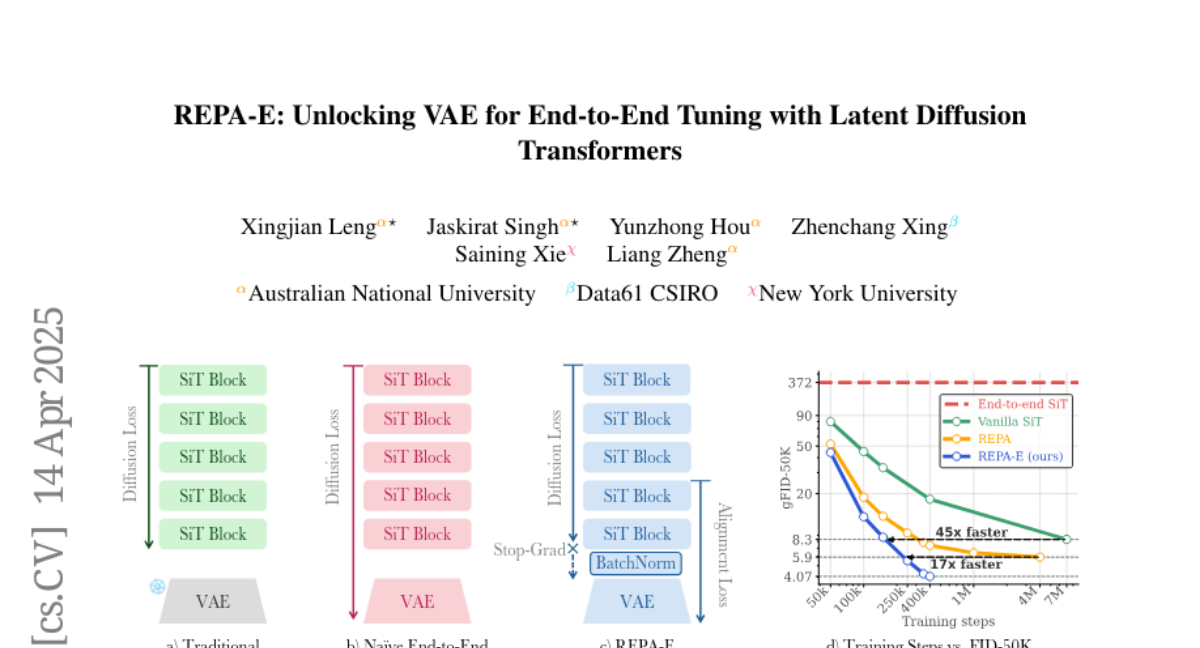
7. REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers
🔑 Keywords: Latent Diffusion Models, End-to-End Training, VAE, REPA Loss, ImageNet
💡 Category: Generative Models
🌟 Research Objective:
– To explore the feasibility of end-to-end training of latent diffusion models and variational auto-encoder (VAE) tokenizers.
🛠️ Research Methods:
– The introduction of representation-alignment (REPA) loss to enable effective end-to-end training, enhancing both VAE and diffusion model tuning simultaneously.
💬 Research Conclusions:
– The REPA-E training recipe significantly accelerates diffusion model training by over 17x to 45x compared to previous methods, improving the latent space structure and setting new state-of-the-art results on ImageNet 256 x 256 with an FID of 1.26 and 1.83.
👉 Paper link: https://huggingface.co/papers/2504.10483
8. SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
🔑 Keywords: supervised fine-tuning, reinforcement learning, Large Vision-Language Models, VLAA-Thinking, Group Relative Policy Optimization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study investigates how supervised fine-tuning (SFT) affects the subsequent reinforcement learning (RL) process in training Large Vision-Language Models (LVLMs), specifically analyzing the formation of “pseudo reasoning paths.”
🛠️ Research Methods:
– Creation of the multimodal dataset VLAA-Thinking, comprising detailed visual reasoning traces, used to compare SFT, RL, and their combinations through extensive experiments.
💬 Research Conclusions:
– SFT helps LVLMs learn reasoning formats but may hinder adaptive learning by promoting rigid reasoning modes. The enhanced RL approach with Group Relative Policy Optimization fosters more genuine, adaptable reasoning, with VLAA-Thinker achieving superior performance on the Open LMM Reasoning Leaderboard.
👉 Paper link: https://huggingface.co/papers/2504.11468

9. Vivid4D: Improving 4D Reconstruction from Monocular Video by Video Inpainting
🔑 Keywords: Vivid4D, 4D Monocular Video Synthesis, Video Inpainting, Monocular Depth Priors, Iterative View Augmentation Strategy
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance 4D monocular video synthesis by augmenting observation views through synthesizing multi-view videos from a monocular input.
🛠️ Research Methods:
– Integration of geometric and generative priors to reformulate view augmentation as a video inpainting task.
– Training a video inpainting model on unposed web videos with synthetically generated masks to ensure spatially and temporally consistent completion of missing regions.
– Introduction of an iterative view augmentation strategy and a robust reconstruction loss to mitigate inaccuracies in monocular depth priors.
💬 Research Conclusions:
– The proposed method effectively improves monocular 4D scene reconstruction and completion.
👉 Paper link: https://huggingface.co/papers/2504.11092

10. Towards Learning to Complete Anything in Lidar
🔑 Keywords: Zero-shot approach, Lidar-based shape-completion, Temporal context, Object shapes, Semantic features
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to develop CAL (Complete Anything in Lidar) for performing Lidar-based shape-completion in-the-wild without relying on a pre-defined vocabulary.
🛠️ Research Methods:
– Implement a zero-shot approach that uses temporal context from multi-modal sensor data to extract object shapes and semantic features, forming a Lidar-only instance-level model for shape completion and recognition.
💬 Research Conclusions:
– Demonstrated the model’s capability to infer complete object shapes from partial observations and extend recognition beyond fixed class vocabularies using standard benchmarks for semantic and panoptic scene completion.
👉 Paper link: https://huggingface.co/papers/2504.12264

11. Robust and Fine-Grained Detection of AI Generated Texts
🔑 Keywords: AI-generated content, LLMs, human-LLM co-authored texts, token classification, adversarial inputs
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop models for detecting AI-generated content, particularly focusing on partial human-LLM co-authored texts.
🛠️ Research Methods:
– Utilization of token classification models trained on a large dataset of human-machine co-authored texts across various domains and languages.
💬 Research Conclusions:
– Models show strong performance on texts from unseen domains, generators, and those with adversarial inputs. Comparison of model performance across different text characteristics was also presented.
👉 Paper link: https://huggingface.co/papers/2504.11952

12. Syzygy of Thoughts: Improving LLM CoT with the Minimal Free Resolution
🔑 Keywords: Chain-of-Thought, Syzygy of Thoughts, Minimal Free Resolution, Natural Language Processing
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Syzygy of Thoughts (SoT) as an extension of Chain-of-Thought (CoT) to improve reasoning in large language models by using auxiliary reasoning paths.
🛠️ Research Methods:
– Inspired by the concepts of Minimal Free Resolution, the research employs a structured analytical approach to break down complex problems into minimal subproblems while maintaining logical dependencies.
💬 Research Conclusions:
– SoT achieves inference accuracy matching or surpassing existing CoT standards across various datasets and models.
– The approach aligns sampling processes with algebraic constraints, enhancing scalability and performance in large language models.
– The code for this approach will be made publicly available.
👉 Paper link: https://huggingface.co/papers/2504.09566

13. BlockGaussian: Efficient Large-Scale Scene Novel View Synthesis via Adaptive Block-Based Gaussian Splatting
🔑 Keywords: 3D Gaussian Splatting, BlockGaussian, scene partitioning, optimization, rendering quality
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce BlockGaussian framework for efficient and high-quality large-scale scene reconstruction.
🛠️ Research Methods:
– Employ a content-aware scene partition strategy and visibility-aware block optimization.
– Incorporate auxiliary points for better alignment with ground-truth supervision.
– Apply a pseudo-view geometry constraint to minimize rendering degradation.
💬 Research Conclusions:
– Achieve state-of-the-art reconstruction efficiency and rendering quality with 5x speedup in optimization and 1.21 dB PSNR improvement.
– Reduce computational requirements to enable large-scale scene reconstruction on a single 24GB VRAM device.
👉 Paper link: https://huggingface.co/papers/2504.09048

14. “It’s not a representation of me”: Examining Accent Bias and Digital Exclusion in Synthetic AI Voice Services
🔑 Keywords: AI speech generation, voice cloning, accent-based discrimination, inclusive design
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– This study aims to evaluate the impact of AI speech generation and voice cloning technologies on sociotechnical systems, particularly focusing on accent and linguistic diversity.
🛠️ Research Methods:
– A mixed methods approach was employed, utilizing surveys and interviews to assess the technical performance of two synthetic AI voice services: Speechify and ElevenLabs.
💬 Research Conclusions:
– The study found technical performance disparities across five regional English-language accents and highlighted how current speech technologies may reinforce linguistic privilege and digital exclusion. It underscores the need for inclusive design and regulation to ensure equitable AI speech technologies.
👉 Paper link: https://huggingface.co/papers/2504.09346

15. MLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
🔑 Keywords: Large Language Models, MLRC-Bench, Machine Learning Research Competitions, Novel Methodologies, Objective Metrics
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce MLRC-Bench as a new benchmark to evaluate the effectiveness of language agents in tackling challenging Machine Learning research competitions.
🛠️ Research Methods:
– Comparison with prior benchmarks like MLE-Bench and evaluation of language agents using MLRC-Bench on novel research methods with rigorous protocols and objective metrics.
💬 Research Conclusions:
– Significant challenges remain for LLM agents in MLRC-Bench tasks, with the best-tested agent only closing 9.3% of the gap to top human scores. Additionally, there is a misalignment between LLM-judged innovation and actual performance, calling for continued dynamic evaluations.
👉 Paper link: https://huggingface.co/papers/2504.09702

16.
