AI Native Daily Paper Digest – 20250418

1. CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training
🔑 Keywords: CLIMB, semantic space, proxy model, ClimbLab, ClimbMix
💡 Category: Machine Learning
🌟 Research Objective:
– Address challenges in optimizing pre-training data mixtures for enhanced performance by proposing an automated framework called CLIMB.
🛠️ Research Methods:
– Use clustering in a semantic space to evaluate and refine data mixtures iteratively, employing a smaller proxy model and a predictor.
💬 Research Conclusions:
– A pre-trained 1B model on the optimized data mixture surpasses state-of-the-art models, showing a specific domain optimization can yield a significant improvement. Introduced ClimbLab and ClimbMix dataset for research and efficient pre-training.
👉 Paper link: https://huggingface.co/papers/2504.13161

2. Antidistillation Sampling
🔑 Keywords: Frontier models, Antidistillation sampling, Reasoning traces, Model distillation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to explore sampling strategies, particularly antidistillation sampling, which limit distillation effectiveness while preserving model performance.
🛠️ Research Methods:
– Antidistillation sampling modifies a model’s next-token probability distribution to deteriorate reasoning traces for distillation.
💬 Research Conclusions:
– Antidistillation sampling effectively reduces the potency of reasoning traces for distillation without hindering the model’s practical utility.
👉 Paper link: https://huggingface.co/papers/2504.13146

3. Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling
🔑 Keywords: Vision-Language Models (VLMs), visual hallucinations, hallucination-aware training, hallucination-verification dataset, state-of-the-art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce REVERSE, a unified framework that integrates hallucination-aware training with on-the-fly self-verification in Vision-Language Models (VLMs).
🛠️ Research Methods:
– Utilized a hallucination-verification dataset containing over 1.3 million semi-synthetic samples.
– Developed a novel inference-time retrospective resampling technique to enable VLMs to detect and dynamically revise hallucinations during generation.
💬 Research Conclusions:
– REVERSE achieves state-of-the-art hallucination reduction, outperforming existing methods by up to 12% on CHAIR-MSCOCO and 28% on HaloQuest.
👉 Paper link: https://huggingface.co/papers/2504.13169

4. WORLDMEM: Long-term Consistent World Simulation with Memory
🔑 Keywords: World simulation, memory bank, memory attention mechanism, dynamic evolution
💡 Category: Computer Vision
🌟 Research Objective:
– The primary goal is to enhance scene generation by maintaining long-term consistency, particularly in preserving 3D spatial consistency within world simulation frameworks.
🛠️ Research Methods:
– The introduction of WorldMem, a framework using a memory bank with memory units that store memory frames and states, employing a memory attention mechanism to accurately reconstruct scenes, even across viewpoint or temporal gaps.
💬 Research Conclusions:
– Extensive experiments demonstrate that WorldMem effectively captures both static and dynamic aspects of virtual environments, ensuring accurate perception and interaction in simulated worlds.
👉 Paper link: https://huggingface.co/papers/2504.12369
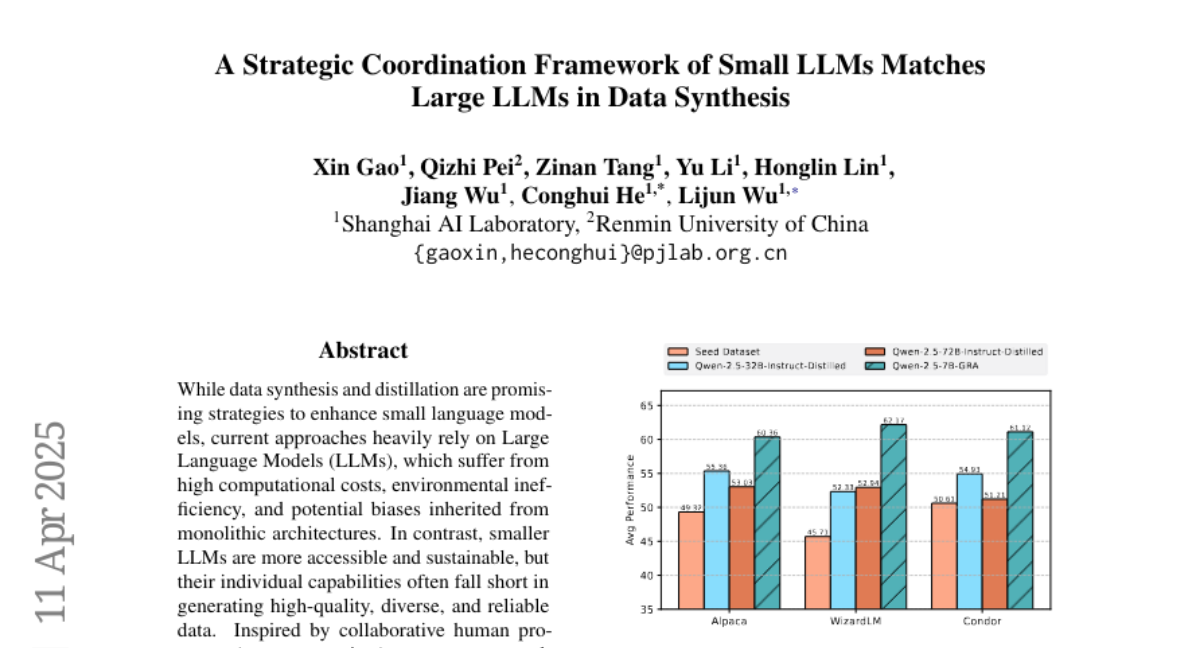
5. A Strategic Coordination Framework of Small LLMs Matches Large LLMs in Data Synthesis
🔑 Keywords: data synthesis, small LLMs, peer-review-inspired, GRA
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a framework utilizing multiple small LLMs for data synthesis that matches or surpasses the quality of large LLMs, while being more computationally efficient and sustainable.
🛠️ Research Methods:
– Implementing a peer-review-inspired framework named GRA, involving specialized roles across small LLMs (Generator, Reviewer, and Adjudicator) for iterative refinement and quality control of data synthesis.
💬 Research Conclusions:
– The GRA framework achieves data-level parity with large LLM-based approaches and challenges the necessity of large monolithic models for high-quality data synthesis.
– Findings suggest strategic coordination of smaller language models can offer a viable alternative to large-scale models in data tasks.
👉 Paper link: https://huggingface.co/papers/2504.12322
6. Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
🔑 Keywords: FramePack, neural network, video diffusion, next-frame prediction, anti-drifting sampling
💡 Category: Generative Models
🌟 Research Objective:
– Propose FramePack to enhance next-frame prediction in video generation.
🛠️ Research Methods:
– Utilize a compressed frame structure for fixed transformer context length.
– Implement anti-drifting sampling to avoid exposure bias.
💬 Research Conclusions:
– FramePack improves training efficiency and visual quality in video diffusion models.
– Finetuning with FramePack leads to more balanced diffusion scheduling.
👉 Paper link: https://huggingface.co/papers/2504.12626

7. VistaDPO: Video Hierarchical Spatial-Temporal Direct Preference Optimization for Large Video Models
🔑 Keywords: Large Video Models, Large Language Models, video hallucination, VistaDPO, video-language preference alignment
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VistaDPO to enhance text-video preference alignment and address video hallucination and misalignment in LVMs.
🛠️ Research Methods:
– Development of a hierarchical framework—VistaDPO—focusing on Instance Level, Temporal Level, and Perceptive Level alignments.
– Creation of a new dataset, VistaDPO-7k, comprising 7.2K QA pairs with detailed spatial-temporal grounding.
💬 Research Conclusions:
– VistaDPO significantly improves the performance of existing Large Video Models on tasks like Video Hallucination and Video QA, effectively addressing misalignment and hallucination challenges.
👉 Paper link: https://huggingface.co/papers/2504.13122

8. Perception Encoder: The best visual embeddings are not at the output of the network
🔑 Keywords: Perception Encoder, Vision-Language Learning, Contrastive Training, Zero-Shot Classification, Video Understanding
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces the Perception Encoder (PE), designed for image and video understanding through vision-language learning.
🛠️ Research Methods:
– Utilizes contrastive vision-language training to create versatile embeddings for various tasks, with language and spatial alignment methods for improved performance.
💬 Research Conclusions:
– PE models achieve state-of-the-art results across multiple tasks such as zero-shot image and video classification, retrieval, and spatial tasks; the release includes models, code, and a uniquely annotated video dataset.
👉 Paper link: https://huggingface.co/papers/2504.13181

9. DMM: Building a Versatile Image Generation Model via Distillation-Based Model Merging
🔑 Keywords: text-to-image (T2I) generation, model merging, parameter redundancy, score distillation, style-promptable image generation
💡 Category: Generative Models
🌟 Research Objective:
– To develop methods that consolidate and unify diverse text-to-image generation models into a single, versatile model while addressing challenges of parameter redundancy and storage cost.
🛠️ Research Methods:
– Introduces a style-promptable image generation pipeline and proposes a score distillation-based model merging paradigm (DMM) for compressing multiple models into a versatile T2I model.
💬 Research Conclusions:
– Demonstrates that DMM can efficiently reorganize knowledge from multiple teacher models and enable controllable arbitrary-style image generation.
👉 Paper link: https://huggingface.co/papers/2504.12364

10. NoisyRollout: Reinforcing Visual Reasoning with Data Augmentation
🔑 Keywords: Reinforcement Learning, Vision-Language Models, Policy Exploration, Visual Perception, NoisyRollout
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance policy exploration in Vision-Language Models (VLMs) and improve their imperfect visual perception affecting reasoning processes.
🛠️ Research Methods:
– Proposed NoisyRollout, a reinforcement learning approach using mixed trajectories from clean and distorted images to introduce targeted diversity. It includes a vision-oriented inductive bias and employs a noise annealing schedule.
💬 Research Conclusions:
– NoisyRollout achieves state-of-the-art performance in open-source RL-tuned models across reasoning and perception tasks on 5 out-of-domain benchmarks, using only 2.1K training samples, and maintains training stability and scalability.
👉 Paper link: https://huggingface.co/papers/2504.13055

11. ChartQAPro: A More Diverse and Challenging Benchmark for Chart Question Answering
🔑 Keywords: Chart Question Answering, visual representations, ChartQAPro, large vision-language models, chart reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce ChartQAPro, a new benchmark for analyzing charts with improved real-world diversity and complexity over existing benchmarks.
🛠️ Research Methods:
– Evaluate the performance of 21 models on ChartQAPro and conduct detailed error analyses and ablation studies.
💬 Research Conclusions:
– Existing large vision-language models experience substantial performance drops when applying to ChartQAPro, highlighting the complexity of chart reasoning.
👉 Paper link: https://huggingface.co/papers/2504.05506

12. InstantCharacter: Personalize Any Characters with a Scalable Diffusion Transformer Framework
🔑 Keywords: U-Net architectures, InstantCharacter, scalable framework, diffusion transformer, high-fidelity
💡 Category: Generative Models
🌟 Research Objective:
– To address the limitations in generalization ability and image quality in learning-based subject customization, particularly with U-Net architectures, and enhance textual controllability in optimization-based methods.
🛠️ Research Methods:
– Introducing InstantCharacter, a scalable character customization framework built on a diffusion transformer, featuring a scalable adapter with stacked transformer encoders.
– Constructing a large-scale character dataset with paired and unpaired subsets for training.
💬 Research Conclusions:
– InstantCharacter achieves high-fidelity, text-controllable, and character-consistent images, establishing a new standard in character-driven image generation.
👉 Paper link: https://huggingface.co/papers/2504.12395

13. PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
🔑 Keywords: Vision-language models, Perception Language Model, video understanding, open-source, video question-answer pairs
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a Perception Language Model within an open and reproducible framework to enhance image and video understanding.
🛠️ Research Methods:
– Analyze standard training pipelines without using distillation from proprietary models.
– Utilize large-scale synthetic data to identify gaps in video understanding.
– Release 2.8 million human-labeled instances and introduce the PLM-VideoBench suite for evaluating video tasks.
💬 Research Conclusions:
– Provided a completely open framework including data, training recipes, code, and models for transparent research.
– Addressed critical gaps in video understanding through novel datasets and evaluation tools.
👉 Paper link: https://huggingface.co/papers/2504.13180

14. Exploring Expert Failures Improves LLM Agent Tuning
🔑 Keywords: Large Language Models, Rejection Sampling Fine-Tuning, Exploring Expert Failures, agent exploration efficiency, beneficial actions
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance Large Language Models (LLMs) in solving complex tasks by improving their agentic skills through Exploring Expert Failures (EEF).
🛠️ Research Methods:
– The researchers introduced EEF, which identifies beneficial actions from failed expert trajectories and incorporates them into the training process, while excluding harmful actions.
💬 Research Conclusions:
– The proposed EEF approach achieved a 62% win rate in WebShop, outperforming previous methods like RFT and GPT-4, and set a new state-of-the-art by surpassing scores in WebShop and SciWorld.
👉 Paper link: https://huggingface.co/papers/2504.13145

15. CCMNet: Leveraging Calibrated Color Correction Matrices for Cross-Camera Color Constancy
🔑 Keywords: Computational color constancy, white balancing, learning-based method
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to introduce a learning-based method for cross-camera color constancy that can generalize to new cameras without retraining.
🛠️ Research Methods:
– The method leverages pre-calibrated color correction matrices (CCMs) and uses data augmentation techniques to transform illumination colors and prevent overfitting.
💬 Research Conclusions:
– The proposed method achieves state-of-the-art cross-camera color constancy, is lightweight, and relies only on data available within camera ISPs.
👉 Paper link: https://huggingface.co/papers/2504.07959

16. 70% Size, 100% Accuracy: Lossless LLM Compression for Efficient GPU Inference via Dynamic-Length Float
🔑 Keywords: Large Language Models, Dynamic-Length Float, GPU, Lossless Compression, AI Systems and Tools
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary objective is to introduce a framework called Dynamic-Length Float (DFloat11) to reduce the size of Large Language Models by 30% while retaining bit-for-bit identical outputs to the original model.
🛠️ Research Methods:
– The researchers developed DFloat11 by utilizing entropy coding to assign dynamic-length encodings to weights based on frequency and designed a custom GPU kernel for efficient online decompression.
💬 Research Conclusions:
– DFloat11 successfully achieves 30% model size reduction, provides significant improvements in efficiency with 1.9-38.8x higher throughput for token generation, and enables 5.3-13.17x longer context lengths while maintaining lossless inference on large models like Llama-3.1-405B.
👉 Paper link: https://huggingface.co/papers/2504.11651

17. Sleep-time Compute: Beyond Inference Scaling at Test-time
🔑 Keywords: test-time compute, sleep-time compute, pre-computing, predictability, Stateful GSM-Symbolic
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce sleep-time compute as a method to reduce high latency and inference cost for large language models (LLMs) by pre-computing and anticipating user queries.
🛠️ Research Methods:
– Modified reasoning tasks, namely Stateful GSM-Symbolic and Stateful AIME, were crafted, and a new extension, Multi-Query GSM-Symbolic, was developed to evaluate the efficacy of sleep-time compute across multiple queries.
💬 Research Conclusions:
– Sleep-time compute significantly reduced test-time compute needs by ~5x and improved accuracy by up to 13% and 18% on Stateful GSM-Symbolic and Stateful AIME, respectively. Moreover, applying sleep-time compute to Multi-Query scenarios decreased average cost per query by 2.5x.
👉 Paper link: https://huggingface.co/papers/2504.13171

18. FocusedAD: Character-centric Movie Audio Description
🔑 Keywords: Movie Audio Description, Blind and Visually Impaired, Character Perception Module, FocusedAD, Cinepile-AD dataset
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a framework, FocusedAD, for generating character-centric movie audio descriptions that assist Blind and Visually Impaired audiences.
🛠️ Research Methods:
– Utilization of a Character Perception Module for linking character regions to their names and a Dynamic Prior Module that integrates contextual cues from prior audio descriptions and subtitles.
💬 Research Conclusions:
– FocusedAD achieves state-of-the-art performance in creating plot-relevant narrations, showcasing strong zero-shot results on MAD-eval-Named and the newly introduced Cinepile-AD dataset.
👉 Paper link: https://huggingface.co/papers/2504.12157

19. Retrieval-Augmented Generation with Conflicting Evidence
🔑 Keywords: Retrieval-Augmented Generation, Ambiguity, Misinformation, LLM Agents, MADAM-RAG
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to address the challenges faced by LLM agents using Retrieval-Augmented Generation (RAG) when dealing with ambiguous queries and conflicting information.
🛠️ Research Methods:
– The authors propose a new dataset named RAMDocs and introduce a multi-agent approach called MADAM-RAG to tackle these issues, with LLM agents debating answers over multiple rounds.
💬 Research Conclusions:
– MADAM-RAG improves performance on ambiguous and misinformation-rich queries, outperforming strong RAG baselines by up to 15.80% in some cases. However, challenges remain in managing imbalances in evidence and misinformation.
👉 Paper link: https://huggingface.co/papers/2504.13079

20. Set You Straight: Auto-Steering Denoising Trajectories to Sidestep Unwanted Concepts
🔑 Keywords: Ethical AI, text-to-image models, concept erasure, ANT, deNoising Trajectories
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce a finetuning framework named ANT to address ethical deployment challenges in text-to-image models by avoiding harmful or inappropriate content generation.
🛠️ Research Methods:
– Utilizes a trajectory-aware objective that reverses the condition direction of classifier-free guidance during denoising stages without heuristic anchor concept selection.
– Proposes an augmentation-enhanced weight saliency map for precise single and multi-concept erasure.
💬 Research Conclusions:
– ANT achieves state-of-the-art results in concept erasure while maintaining high-quality and safe outputs without compromising generative fidelity.
👉 Paper link: https://huggingface.co/papers/2504.12782

21. Complex-Edit: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark
🔑 Keywords: GPT-4o, Chain-of-Edit, VLM-based, Complex-Edit, Image Editing
💡 Category: Computer Vision
🌟 Research Objective:
– The primary aim is to introduce Complex-Edit, a benchmark designed for evaluating instruction-based image editing models’ performance across tasks with varying complexities.
🛠️ Research Methods:
– Utilized GPT-4o to automatically gather a wide array of editing instructions and developed a “Chain-of-Edit” pipeline to generate and integrate atomic editing tasks into complex instructions. An auto-evaluation pipeline based on VLM is used for large-scale assessments.
💬 Research Conclusions:
– Open-source models underperform against closed-source ones, with increasing instruction complexity widening this gap.
– High complexity primarily affects models’ ability to maintain key input image elements and overall aesthetics.
– Decomposing complex instructions into atomic steps reduces performance.
– A Best-of-N selection strategy improves results in both direct and sequential editing.
– Synthetic data training leads to synthetic-looking outputs as instruction complexity rises.
👉 Paper link: https://huggingface.co/papers/2504.13143

22. Learning Occlusion-Robust Vision Transformers for Real-Time UAV Tracking
🔑 Keywords: Vision Transformer (ViT), occlusion, Occlusion-Robust Representations (ORR), random masking, UAV tracking
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to enhance the occlusion resilience of single-stream Vision Transformer (ViT) models in real-time UAV tracking.
🛠️ Research Methods:
– Introducing Occlusion-Robust Representations (ORR) by enforcing feature representation invariance using a spatial Cox process for random masking.
– Developing ORTrack, a framework for improved occlusion handling, coupled with an Adaptive Feature-Based Knowledge Distillation (AFKD) method to create a more efficient student model, ORTrack-D.
💬 Research Conclusions:
– The proposed ORTrack framework achieves state-of-the-art performance in UAV tracking, validated through extensive experiments across multiple benchmarks.
– ORTrack-D, as a student model, successfully maintains the performance of ORTrack while providing higher efficiency for real-time applications.
👉 Paper link: https://huggingface.co/papers/2504.09228

23. MetaSynth: Meta-Prompting-Driven Agentic Scaffolds for Diverse Synthetic Data Generation
🔑 Keywords: Synthetic Data, Diversity, Meta-Prompting, Domain Adaptation, Language Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to enhance the diversity of synthetic data for adapting large language models (LLMs) to specialized domains such as Finance and Biomedicine.
🛠️ Research Methods:
– Proposed MetaSynth, a novel method utilizing meta-prompting, where multiple “expert” LLM agents collaboratively generate synthetic data, and evaluated the diversity of this data using seven automated metrics.
💬 Research Conclusions:
– Successfully adapted a well-trained LLM to specific domains using only 25 million tokens of diverse synthetic data. This adaptation outperformed the base LLM, showing significant improvements in domain-specific tasks.
👉 Paper link: https://huggingface.co/papers/2504.12563

24.
