AI Native Daily Paper Digest – 20250423

1. Kuwain 1.5B: An Arabic SLM via Language Injection
🔑 Keywords: Language Model Expansion, Large Language Model (LLM), Arabic Language, Benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to integrate a new language_into an_existing large language model without compromising existing knowledge.
🛠️ Research Methods:
– A novel method was demonstrated by training a tiny model with 1.5 billion parameters named Kuwain, incorporating the Arabic language into a small, mainly English-trained, open-source model.
💬 Research Conclusions:
– The method resulted in an 8% performance improvement in Arabic language benchmarks while maintaining the original model’s knowledge, offering a cost-effective alternative to comprehensive bilingual model training.
👉 Paper link: https://huggingface.co/papers/2504.15120

2. TTRL: Test-Time Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Large Language Models, reward estimation, Test-Time Reinforcement Learning, self-evolution
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate Reinforcement Learning on data without explicit labels for reasoning tasks in Large Language Models.
🛠️ Research Methods:
– Introduction of Test-Time Reinforcement Learning (TTRL) to enable self-evolution of LLMs using RL on unlabeled data.
💬 Research Conclusions:
– TTRL improves performance across various tasks and models, notably increasing pass@1 performance significantly with only unlabeled test data.
– Demonstrates potential to surpass initial model limits without ground-truth labels and approach those trained on labeled data.
👉 Paper link: https://huggingface.co/papers/2504.16084

3. The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks
🔑 Keywords: multilingual evaluation, large language models (LLMs), human judgments, STEM-related tasks, culturally tailored benchmarks
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the current practices in multilingual benchmarking for large language models using a comprehensive analysis of over 2,000 benchmarks from 148 countries.
🛠️ Research Methods:
– Analyzed benchmarks with a focus on non-English content, considering investments, regional sources, and comparing benchmark performance with human judgments across various tasks.
💬 Research Conclusions:
– The analysis reveals an overrepresentation of English in benchmarks, and shows that localized benchmarks align better with human judgments than translated ones; it emphasizes the necessity for creating linguistically and culturally appropriate benchmarks and advocates for global collaboration in developing human-aligned benchmarks for real-world applications.
👉 Paper link: https://huggingface.co/papers/2504.15521

4. Describe Anything: Detailed Localized Image and Video Captioning
🔑 Keywords: Describe Anything Model, detailed localized captioning, focal prompt, localized vision backbone
💡 Category: Computer Vision
🌟 Research Objective:
– Develop the Describe Anything Model (DAM) for detailed localized captioning in images and videos.
🛠️ Research Methods:
– Introduced focal prompts and localized vision backbone for high-resolution and precise localization.
– Proposed a semi-supervised learning-based data pipeline (DLC-SDP) to utilize existing segmentation datasets and expand with unlabeled web images.
💬 Research Conclusions:
– DAM achieves state-of-the-art performance across seven benchmarks for keyword-level, phrase-level, and detailed multi-sentence localized captioning.
👉 Paper link: https://huggingface.co/papers/2504.16072
5. Learning Adaptive Parallel Reasoning with Language Models
🔑 Keywords: Adaptive Parallel Reasoning, serialized chain-of-thought, parallel methods, reinforcement learning, context window
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to address the shortcomings of existing language model reasoning methods by proposing Adaptive Parallel Reasoning (APR), which harmonizes serialized and parallel computations.
🛠️ Research Methods:
– Utilizes a novel end-to-end reinforcement learning strategy to manage both serialized and parallel inference processes through adaptive multi-threaded inference using spawn() and join() operations.
💬 Research Conclusions:
– APR demonstrates significant performance improvements in the Countdown reasoning task, showing higher accuracy and scalability within the same context window and increased tokens, along with enhanced accuracy at equivalent latency.
👉 Paper link: https://huggingface.co/papers/2504.15466

6. BookWorld: From Novels to Interactive Agent Societies for Creative Story Generation
🔑 Keywords: Large Language Models, Multi-agent Systems, BookWorld, Story Generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce BookWorld, a system designed to construct and simulate book-based multi-agent societies, exploring established fictional worlds and characters.
🛠️ Research Methods:
– The design of BookWorld incorporates comprehensive real-world intricacies such as diverse characters, fictional worldviews, and geographical constraints.
💬 Research Conclusions:
– BookWorld generates creative, high-quality stories while maintaining fidelity to source books, achieving a 75.36% win rate over previous methods.
👉 Paper link: https://huggingface.co/papers/2504.14538

7. IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
🔑 Keywords: Multimodal Large Language Models, Image-Grounded Video Perception and Reasoning, IV-Bench, Video Understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective is to bridge the gap in existing evaluation frameworks by proposing IV-Bench, a comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning.
🛠️ Research Methods:
– Conducted extensive evaluations using both open-source and closed-source state-of-the-art Multimodal Large Language Models on IV-Bench, consisting of 967 videos and 2,585 annotated image-text queries across 13 tasks.
💬 Research Conclusions:
– Current models significantly underperform in image-grounded video perception and reasoning, achieving a maximum of 28.9% accuracy, with factors such as inference patterns, frame number, and resolution impacting performance. The study highlights challenges beyond data format alignment and provides insights for future research.
👉 Paper link: https://huggingface.co/papers/2504.15415

8. CheXWorld: Exploring Image World Modeling for Radiograph Representation Learning
🔑 Keywords: self-supervised world model, radiographic images, local anatomical structures, global anatomical layouts, domain variations
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research objective is to develop CheXWorld, a self-supervised world model for analyzing radiographic images by encoding medical knowledge relevant to qualified radiologists.
🛠️ Research Methods:
– The method involves creating a unified framework that models local anatomical structures, global anatomical layouts, and domain variations to enhance the understanding of radiographic images.
💬 Research Conclusions:
– CheXWorld effectively captures critical dimensions of medical knowledge and significantly outperforms existing self-supervised learning methods and large-scale medical foundation models in transfer learning experiments across multiple medical image classification and segmentation benchmarks.
👉 Paper link: https://huggingface.co/papers/2504.13820

9. Efficient Pretraining Length Scaling
🔑 Keywords: Large Language Models, Length Scaling, KV Cache, Sliding Window Attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the potential of length scaling during pre-training in large language models.
🛠️ Research Methods:
– Introduced the PHD-Transformer framework featuring a novel KV cache management strategy and two optimized variants: PHD-SWA and PHD-CSWA.
💬 Research Conclusions:
– The proposed approach successfully maintains inference efficiency and shows consistent improvements across multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2504.14992

10. Personalized Text-to-Image Generation with Auto-Regressive Models
🔑 Keywords: Personalized image synthesis, Auto-regressive models, Multimodal capabilities, Text embeddings
💡 Category: Generative Models
🌟 Research Objective:
– The study explores optimizing auto-regressive models for personalized image synthesis by leveraging their multimodal capabilities.
🛠️ Research Methods:
– A two-stage training strategy is proposed, involving optimization of text embeddings and fine-tuning of transformer layers.
💬 Research Conclusions:
– The optimized auto-regressive models demonstrate comparable performance to diffusion-based methods in subject fidelity and prompt following, highlighting their effectiveness and potential in personalized image generation.
👉 Paper link: https://huggingface.co/papers/2504.13162

11. LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
🔑 Keywords: Video LLMs, automatic speech recognition, streaming training, ASR-only, LiveCC-7B-Base
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To explore large-scale training for Video LLM using cheap automatic speech recognition (ASR) transcripts instead of costly annotations or proprietary models.
🛠️ Research Methods:
– The study proposes a novel streaming training approach that interleaves ASR words and video frames based on timestamps, creating datasets Live-CC-5M for pre-training and Live-WhisperX-526K for supervised fine-tuning.
💬 Research Conclusions:
– The ASR-only pre-trained LiveCC-7B-Base model shows competitive performance in video QA and real-time video commentary, outperforming larger 72B models in commentary quality, and achieving state-of-the-art results on video QA benchmarks at the 7B/8B scale.
👉 Paper link: https://huggingface.co/papers/2504.16030
12. Vidi: Large Multimodal Models for Video Understanding and Editing
🔑 Keywords: Vidi, Large Multimodal Models, Video Editing, Temporal Retrieval, VUE-TR Benchmark
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The report introduces a new model family named Vidi designed for understanding and editing video content with a focus on temporal retrieval.
🛠️ Research Methods:
– Vidi processes multiple modalities like vision, audio, and text, demonstrating strong temporal understanding even for hour-long videos. It utilizes the VUE-TR benchmark to support comprehensive evaluation across real-world scenarios.
💬 Research Conclusions:
– Vidi outperforms leading proprietary models on temporal retrieval tasks, showcasing its efficacy in intelligent video editing and multimodal learning.
👉 Paper link: https://huggingface.co/papers/2504.15681

13. LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
🔑 Keywords: Large Language Models, Chain-of-Thought, Reinforcement Learning, decision-making
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to investigate why Large Language Models (LLMs) perform sub-optimally in decision-making scenarios, particularly focusing on the issues of greediness, frequency bias, and the knowing-doing gap.
🛠️ Research Methods:
– The researchers conduct systematic experiments leveraging fine-tuning via Reinforcement Learning to mitigate the sub-optimal performance of LLMs. This involves using self-generated Chain-of-Thought rationales across various decision-making frameworks like multi-armed bandits, contextual bandits, and Tic-tac-toe.
💬 Research Conclusions:
– The experiments demonstrate that Reinforcement Learning fine-tuning enhances LLMs’ decision-making abilities by improving exploration and reducing the knowing-doing gap. The study explores both traditional exploration mechanisms and LLM-specific techniques to achieve more effective decision-making improvements.
👉 Paper link: https://huggingface.co/papers/2504.16078

14. WALL-E 2.0: World Alignment by NeuroSymbolic Learning improves World Model-based LLM Agents
🔑 Keywords: Large Language Models (LLMs), World Models, Symbolic Knowledge, Model-Predictive Control (MPC), Open-World Challenges
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To explore the creation of accurate world models using Large Language Models (LLMs) and assess how these models can enhance the performance of LLM agents in diverse environments.
🛠️ Research Methods:
– Proposing a “world alignment” method that utilizes symbolic knowledge such as action rules and knowledge/scene graphs. It uses model-free reinforcement learning combined with a model-based agent “WALL-E 2.0” through a Model-Predictive Control (MPC) framework, using LLMs as efficient look-ahead optimizers.
💬 Research Conclusions:
– WALL-E 2.0 significantly improves performance in open-world challenges, achieving superior success rates in Mars-like (Minecraft) and ALFWorld environments, vastly outperforming existing methods with enhanced learning efficiency.
👉 Paper link: https://huggingface.co/papers/2504.15785

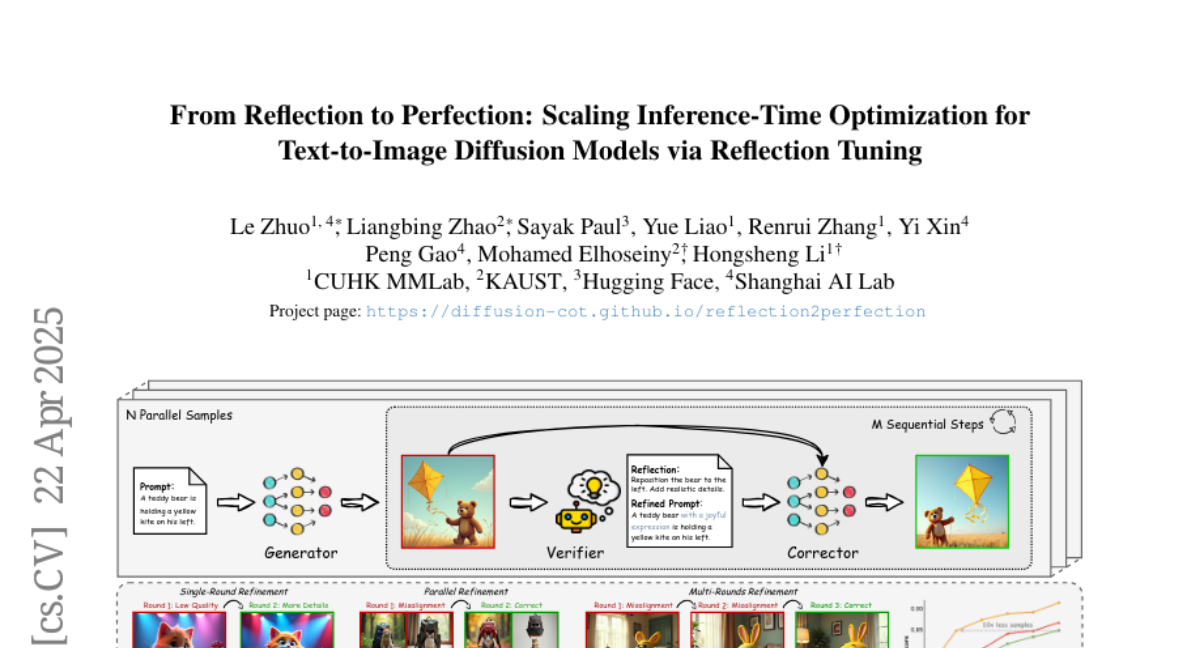
15. From Reflection to Perfection: Scaling Inference-Time Optimization for Text-to-Image Diffusion Models via Reflection Tuning
🔑 Keywords: text-to-image diffusion models, self-reflection capabilities, inference-time framework, reflection-level scaling, image synthesis
💡 Category: Generative Models
🌟 Research Objective:
– To enhance image synthesis in diffusion models by utilizing self-reflection capabilities inspired by large language models.
🛠️ Research Methods:
– Introduced ReflectionFlow, an inference-time framework with three scaling axes: noise-level, prompt-level, and reflection-level scaling.
– Constructed the GenRef dataset with 1 million triplets for reflection-level scaling, enabling reflection tuning on a state-of-the-art diffusion model.
💬 Research Conclusions:
– ReflectionFlow significantly improves image quality in complex and fine-grained tasks, surpassing naive noise-level scaling methods with a scalable and compute-efficient approach.
👉 Paper link: https://huggingface.co/papers/2504.16080
16. RealisDance-DiT: Simple yet Strong Baseline towards Controllable Character Animation in the Wild
🔑 Keywords: Controllable character animation, foundation model, fine-tuning strategies, RealisDance-DiT, model convergence
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to tackle challenges in controllable character animation, such as rare poses and dynamic scenes, using a new perspective involving minimal model modifications and fine-tuning strategies.
🛠️ Research Methods:
– The researchers propose RealisDance-DiT, built on the Wan-2.1 video foundation model, utilizing minimal architecture modifications and techniques like low-noise warmup and “large batches and small iterations.”
💬 Research Conclusions:
– RealisDance-DiT significantly outperforms existing methods in character animation, evaluated on a newly introduced test dataset addressing diverse real-world challenges.
👉 Paper link: https://huggingface.co/papers/2504.14977

17. Progent: Programmable Privilege Control for LLM Agents
🔑 Keywords: LLM agents, Security, Principle of Least Privilege, Privilege Control Mechanism, Domain-Specific Language
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary goal is to introduce Progent, the first privilege control mechanism specifically designed for LLM agents to enhance security and utility without altering agent internals.
🛠️ Research Methods:
– Progent utilizes a domain-specific language to establish fine-grained privilege control policies, ensuring that agent tool calls are authorized and fallbacks are specified for unauthorized actions. It leverages LLMs for dynamic policy generation and updates.
💬 Research Conclusions:
– Through extensive evaluation in scenarios like AgentDojo, ASB, and AgentPoison, Progent demonstrates strong security maintenance and high utility. Its modular design aids in practical adoption and ensures robust policy generation against adaptive attacks.
👉 Paper link: https://huggingface.co/papers/2504.11703

18. CAPTURe: Evaluating Spatial Reasoning in Vision Language Models via Occluded Object Counting
🔑 Keywords: Occluded Objects, Vision-Language Models, Spatial Understanding, World Models, CAPTURe
💡 Category: Computer Vision
🌟 Research Objective:
– The main aim is to introduce a novel task called CAPTURe, which tests the ability of models to count objects in occluded patterns and evaluate their spatial understanding skills.
🛠️ Research Methods:
– The study involves the creation of CAPTURe, consisting of CAPTURe-real with real-world images and CAPTURe-synthetic with generated images, and evaluates four strong vision-language models on these tasks.
💬 Research Conclusions:
– It was found that vision-language models, including strong ones like GPT-4o, struggle with counting objects in both occluded and unoccluded patterns. Models perform particularly poorly under occlusion, unlike humans who show minimal error in the same task.
👉 Paper link: https://huggingface.co/papers/2504.15485

19. IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
🔑 Keywords: Intellectual Property, Large Language Models, IPBench, Dataset, Benchmark
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce a comprehensive IP task taxonomy and a bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks to better align with real-world scenarios in the intellectual property domain.
🛠️ Research Methods:
– Benchmarking 16 LLMs, including both general-purpose and domain-specific models, to evaluate their performance in understanding and generating IP-related content.
💬 Research Conclusions:
– The best-performing model achieves 75.8% accuracy, highlighting room for improvement in IP-related tasks. Open-source IP and law-oriented models don’t perform as well as closed-source general-purpose models.
👉 Paper link: https://huggingface.co/papers/2504.15524

20. MR. Video: “MapReduce” is the Principle for Long Video Understanding
🔑 Keywords: MapReduce, Vision-Language Models, Context Aggregation, Short Video Clips
💡 Category: Computer Vision
🌟 Research Objective:
– To develop MR. Video, a new framework for long video understanding using the MapReduce principle.
🛠️ Research Methods:
– Employed two MapReduce stages for video captioning and analysis, enhancing video comprehension without context length limitations.
💬 Research Conclusions:
– MR. Video exhibited over 10% accuracy improvement on LVBench, demonstrating its effectiveness compared to existing state-of-the-art models.
👉 Paper link: https://huggingface.co/papers/2504.16082

21. DiffVox: A Differentiable Model for Capturing and Analysing Professional Effects Distributions
🔑 Keywords: DiffVox, Differentiable Implementations, Parameter Estimation, Parametric Equalisation, Reverb
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce a novel and interpretable model, DiffVox, to match vocal effects in music production.
🛠️ Research Methods:
– Integrate parametric equalisation, dynamic range control, delay, and reverb with efficient differentiable implementations for gradient-based optimisation.
– Analyze parameter correlations and employ principal component analysis to explore relationships in the vocal effects parameters.
💬 Research Conclusions:
– Strong relationships exist between effects and parameters, revealing complexity in the vocal effects space.
– Initial findings highlight the complexity of parameter distributions which set the foundation for future research in vocal effects modelling and automatic mixing.
👉 Paper link: https://huggingface.co/papers/2504.14735

22.
