AI Native Daily Paper Digest – 20250424

1. VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models
🔑 Keywords: Visual reasoning, MLLMs, VisuLogic, human-verified problems, reinforcement-learning baseline
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VisuLogic as a benchmark to evaluate the visual reasoning capabilities of multimodal large language models (MLLMs).
🛠️ Research Methods:
– Developed a benchmark comprising 1,000 human-verified problems across six categories to test and assess different types of visual reasoning.
– Evaluated leading MLLMs against this benchmark to identify gaps in their visual reasoning capabilities.
💬 Research Conclusions:
– Most MLLMs scored below 30% accuracy, highlighting a significant gap between human performance and MLLMs in visual reasoning tasks.
– Provided a supplementary training dataset and a reinforcement-learning baseline to aid further advancements.
👉 Paper link: https://huggingface.co/papers/2504.15279

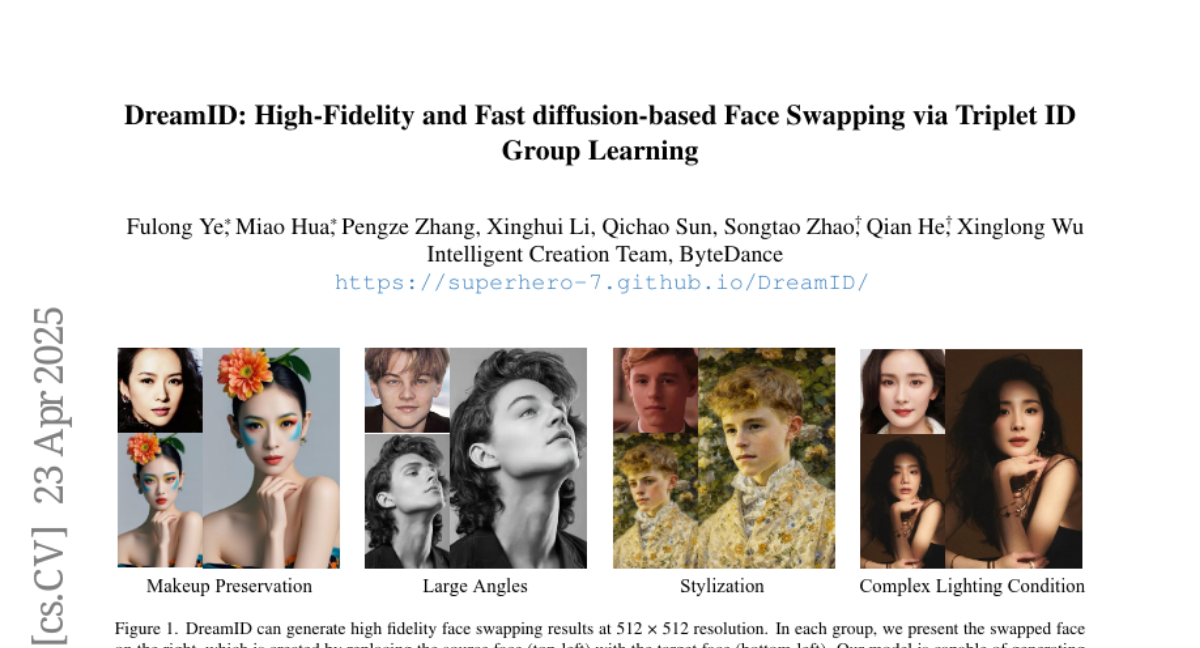
2. DreamID: High-Fidelity and Fast diffusion-based Face Swapping via Triplet ID Group Learning
🔑 Keywords: Face Swapping, Identity Similarity, Attribute Preservation, Diffusion Model, Explicit Supervision
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce DreamID, a model that enhances face swapping by improving ID similarity and attribute preservation.
🛠️ Research Methods:
– Utilizes a diffusion-based model with SD Turbo for accelerated, efficient training. Incorporates explicit supervision using Triplet ID Group data.
💬 Research Conclusions:
– DreamID achieves superior performance compared to state-of-the-art methods in identity similarity, image fidelity, and processing speed, handling complex scenarios effectively.
👉 Paper link: https://huggingface.co/papers/2504.14509
3. Trillion 7B Technical Report
🔑 Keywords: Trillion-7B, Cross-lingual Document Attention, Korean-centric, multilingual performance, cross-lingual consistency
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduction of Trillion-7B, a Korean-centric multilingual LLM with high token efficiency, designed for effective knowledge transfer across languages.
🛠️ Research Methods:
– Utilizes Cross-lingual Document Attention (XLDA) mechanism, along with optimized data mixtures, language-specific filtering, and tailored tokenizer construction.
💬 Research Conclusions:
– Trillion-7B achieves competitive performance with only 10% of its 2T training tokens dedicated to multilingual data, requiring just 59.4K H100 GPU hours for full training, and shows robust multilingual performance and exceptional cross-lingual consistency across 27 benchmarks in four languages.
👉 Paper link: https://huggingface.co/papers/2504.15431

4. Tina: Tiny Reasoning Models via LoRA
🔑 Keywords: Tiny Reasoning Models, Parameter-Efficient Updates, Low-Rank Adaptation, Reinforcement Learning, Open Source
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore the cost-effectiveness of achieving strong reasoning abilities in language models, resulting in the development of the “Tina” models.
🛠️ Research Methods:
– Utilize parameter-efficient updates and Low-Rank Adaptation (LoRA) during reinforcement learning on a small 1.5B parameter base model.
💬 Research Conclusions:
– “Tina” models demonstrate competitive reasoning performance to state-of-the-art RL models with significantly reduced costs, achieving a >20% performance increase and 43.33% accuracy on AIME24 at an estimated 260x cost reduction.
– The effectiveness of the approach is hypothesized to be due to LoRA’s rapid adaptation to the model’s structural reasoning needs while preserving its knowledge.
– The research is fully open-sourced for accessibility and further study.
👉 Paper link: https://huggingface.co/papers/2504.15777

5. I-Con: A Unifying Framework for Representation Learning
🔑 Keywords: Information-theoretic equation, KL divergence, Information geometry, Unsupervised classification, Contrastive learning
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce a single information-theoretic equation that generalizes multiple modern loss functions in machine learning.
🛠️ Research Methods:
– Employing an integrated KL divergence approach to connect a wide range of machine learning methods and optimizing through a hidden information geometry.
💬 Research Conclusions:
– Developed unsupervised image classifiers achieving a +8% improvement over the previous state-of-the-art on ImageNet-1K. Demonstrated the utility of I-Con for developing principled debiasing methods enhancing contrastive representation learners.
👉 Paper link: https://huggingface.co/papers/2504.16929

6. Pre-DPO: Improving Data Utilization in Direct Preference Optimization Using a Guiding Reference Model
🔑 Keywords: Direct Preference Optimization, large language models, human preferences, reference model, catastrophic forgetting
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to enhance the efficiency and performance of Direct Preference Optimization (DPO) in reinforcement learning for large language models by addressing initialization issues with the policy and reference models.
🛠️ Research Methods:
– The study introduces a new training paradigm, Pre-DPO, which utilizes a guiding reference model to adaptively adjust data weights, improving preference optimization without external models or data.
💬 Research Conclusions:
– Pre-DPO demonstrates improved performance over standard DPO and Simple Preference Optimization (SimPO) in benchmarks like AlpacaEval 2.0 and Arena-Hard v0.1, offering a more robust training process.
👉 Paper link: https://huggingface.co/papers/2504.15843

7. PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
🔑 Keywords: Large Language Models, Physics Problems, Real-World Scenarios, Reasoning Capabilities, Expression Edit Distance
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce PHYBench, a benchmark to evaluate the reasoning capabilities of Large Language Models (LLMs) in physical contexts.
🛠️ Research Methods:
– Develop PHYBench, consisting of 500 curated physics problems spanning various physics disciplines from high school to Physics Olympiad level.
– Propose the Expression Edit Distance (EED) Score as a novel evaluation metric to assess differences in model reasoning processes.
💬 Research Conclusions:
– Current state-of-the-art reasoning models significantly underperform compared to human experts, highlighting model limitations in complex physical reasoning.
– PHYBench results and dataset are publicly available for further research.
👉 Paper link: https://huggingface.co/papers/2504.16074

8. Decoupled Global-Local Alignment for Improving Compositional Understanding
🔑 Keywords: Contrastive Language-Image Pre-training (CLIP), Decoupled Global-Local Alignment (DeGLA), self-distillation mechanism, Large Language Models (LLMs), zero-shot classification
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance compositional understanding in CLIP while retaining its general capabilities.
🛠️ Research Methods:
– Introduced the Decoupled Global-Local Alignment (DeGLA) framework with a self-distillation mechanism and in-context learning to develop high-quality negative captions.
💬 Research Conclusions:
– DeGLA framework improved performance with an average enhancement of 3.5% across VALSE, SugarCrepe, and ARO benchmarks, and a 13.0% improvement on zero-shot classification tasks across eleven datasets.
👉 Paper link: https://huggingface.co/papers/2504.16801

9. DreamO: A Unified Framework for Image Customization
🔑 Keywords: Image Customization, Diffusion Transformer, Feature Routing Constraint, Progressive Training Strategy
💡 Category: Generative Models
🌟 Research Objective:
– To develop a unified framework, DreamO, for image customization that allows seamless integration of multiple conditions across a wide range of tasks.
🛠️ Research Methods:
– Utilization of a diffusion transformer (DiT) framework for uniform processing of diverse inputs.
– Construction of a large-scale dataset incorporating various customization tasks, along with feature routing constraints.
– Implementation of a placeholder strategy and a progressive training strategy in three stages to enhance customization capabilities and correct quality biases.
💬 Research Conclusions:
– DreamO effectively performs diverse image customization tasks with high quality and flexibly integrates different types of control conditions.
👉 Paper link: https://huggingface.co/papers/2504.16915

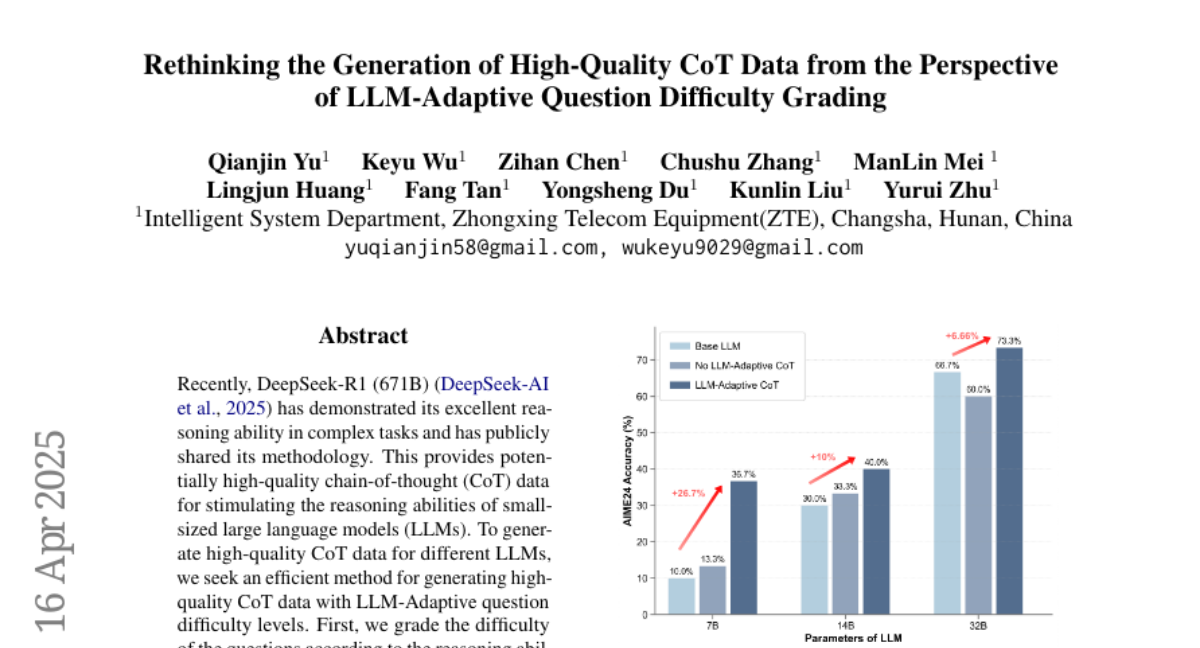
10. Rethinking the Generation of High-Quality CoT Data from the Perspective of LLM-Adaptive Question Difficulty Grading
🔑 Keywords: DeepSeek-R1, Chain-of-Thought (CoT), LLM-Adaptive, model supervised fine-tuning (SFT), ZMath-32B
💡 Category: Natural Language Processing
🌟 Research Objective:
– To generate high-quality Chain-of-Thought (CoT) data for enhancing reasoning abilities of small-sized large language models (LLMs) with different difficulty levels.
🛠️ Research Methods:
– Utilized DeepSeek-R1 (671B) to grade question difficulty according to the reasoning capabilities of the LLMs themselves, constructing an LLM-Adaptive question database and generating CoT data with correct answers.
💬 Research Conclusions:
– CoT data construction with LLM-Adaptive difficulty levels significantly reduced data generation costs and improved model supervised fine-tuning (SFT) efficiency. ZMath-32B and ZCode-32B surpassed DeepSeek-Distill-32B in their respective reasoning tasks with minimal high-quality data.
👉 Paper link: https://huggingface.co/papers/2504.11919
11. A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
🔑 Keywords: Artificial General Intelligence, Large Language Models, full-stack safety, lifecycle
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce the concept of “full-stack” safety to address safety issues throughout the entire lifecycle of LLMs.
🛠️ Research Methods:
– Conduct an extensive literature review of over 800+ papers to provide a comprehensive and systematic coverage of LLM safety.
💬 Research Conclusions:
– Identify promising research directions in safety, such as data generation, alignment techniques, model editing, and LLM-based agent systems.
– Provide reliable roadmaps and perspectives that are valuable for future research.
👉 Paper link: https://huggingface.co/papers/2504.15585

12. AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
🔑 Keywords: AI Mathematical Olympiad, mathematical reasoning models, Tool-Integrated Reasoning, OpenMathReasoning dataset
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper aims to develop state-of-the-art mathematical reasoning models through a novel three-pillar approach.
🛠️ Research Methods:
– Creation of a large-scale dataset with 540K high-quality math problems and 3.2M long-reasoning solutions.
– Development of a method integrating code execution with reasoning models, resulting in 1.7M high-quality Tool-Integrated Reasoning solutions.
– A pipeline for training models to improve solution selection using generative solution selection (GenSelect).
💬 Research Conclusions:
– The proposed approach achieves state-of-the-art results in mathematical reasoning benchmarks.
– Release of code, models, and OpenMathReasoning dataset under a commercially permissive license for further research.
👉 Paper link: https://huggingface.co/papers/2504.16891

13. RePOPE: Impact of Annotation Errors on the POPE Benchmark
🔑 Keywords: label errors, object hallucination, benchmark datasets, RePOPE, MSCOCO
💡 Category: Computer Vision
🌟 Research Objective:
– To assess the impact of label errors in MSCOCO on the object hallucination benchmark POPE.
🛠️ Research Methods:
– Re-annotating benchmark images and evaluating multiple models on these revised labels, termed as RePOPE.
💬 Research Conclusions:
– Notable shifts in model rankings highlight the significant impact of label quality on benchmark evaluations.
👉 Paper link: https://huggingface.co/papers/2504.15707

14. Unchecked and Overlooked: Addressing the Checkbox Blind Spot in Large Language Models with CheckboxQA
🔑 Keywords: CheckboxQA, Large Vision and Language Models, document processing, legal tech, finance
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce the CheckboxQA dataset to evaluate and improve model performance on interpreting checkboxes in documents.
🛠️ Research Methods:
– Leveraging the CheckboxQA dataset to identify and address the limitations of current models regarding checkbox-related tasks.
💬 Research Conclusions:
– The CheckboxQA dataset highlights the inadequacies of existing models, serving as a tool to advance document comprehension systems, with significant applications in sectors like legal tech and finance.
👉 Paper link: https://huggingface.co/papers/2504.10419

15. CRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation
🔑 Keywords: C-to-Rust transpilation, CRUST-Bench, AI Systems, OpenAI o1, safe Rust
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces CRUST-Bench, a dataset designed to evaluate the transpilation of C code into safe Rust using state-of-the-art large language models.
🛠️ Research Methods:
– The dataset comprises 100 C repositories with manually-written Rust interfaces and test cases to ensure correctness and memory safety in transpilation.
💬 Research Conclusions:
– The study highlights the challenges of generating safe and idiomatic Rust from C code, with current leading models like OpenAI o1 solving only 15 tasks effectively.
– Improved results on CRUST-Bench could significantly enhance transpilation systems, aiding in the migration of legacy C codebases to memory-safe languages like Rust.
👉 Paper link: https://huggingface.co/papers/2504.15254

16. Progressive Language-guided Visual Learning for Multi-Task Visual Grounding
🔑 Keywords: Multi-task visual grounding, Referring Expression Comprehension, Referring Expression Segmentation, Visual feature extraction, Language information
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Propose a Progressive Language-guided Visual Learning framework (PLVL) for multi-task visual grounding to improve performance in visual feature extraction and collaborative predictions in REC and RES tasks.
🛠️ Research Methods:
– Develop a framework that integrates linguistic information into visual modalities without needing additional cross-modal fusion modules, and design a multi-task head for collaborative predictions.
💬 Research Conclusions:
– PLVL surpasses existing methods in REC and RES tasks, as demonstrated by extensive experiments on several benchmark datasets.
👉 Paper link: https://huggingface.co/papers/2504.16145

17. Causal-Copilot: An Autonomous Causal Analysis Agent
🔑 Keywords: Causal-Copilot, Autonomous Agent, large language model, causal analysis, time-series data
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To bridge the gap between causal methodology and practical usability by introducing Causal-Copilot, an autonomous agent that operationalizes expert-level causal analysis within a large language model framework.
🛠️ Research Methods:
– Automating the full pipeline for causal analysis on tabular and time-series data, including discovery, inference, algorithm selection, hyperparameter optimization, and result interpretation.
– Integration of over 20 state-of-the-art causal techniques to support interactive refinement through natural language, making advanced causal methods accessible to domain experts.
💬 Research Conclusions:
– Causal-Copilot achieves superior performance compared to existing baselines, offering a reliable, scalable, and extensible solution that enhances the applicability of causal analysis in real-world settings.
👉 Paper link: https://huggingface.co/papers/2504.13263

18.
