AI Native Daily Paper Digest – 20250428

1. Towards Understanding Camera Motions in Any Video
🔑 Keywords: CameraBench, Structure-from-Motion, Video-Language Models, motion-augmented captioning
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to create CameraBench, a comprehensive dataset to improve understanding of camera motion.
🛠️ Research Methods:
– Utilized ~3,000 videos annotated through rigorous multi-stage quality control, and conducted a large-scale human study to evaluate annotation accuracy.
💬 Research Conclusions:
– Fine-tuned generative Video-Language Models on CameraBench achieving improvements in motion-augmented captioning, video question answering, and video-text retrieval.
👉 Paper link: https://huggingface.co/papers/2504.15376

2. Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
🔑 Keywords: Skywork R1V2, Multimodal Reasoning, Reinforcement Learning, Rule-based Strategies, Benchmark-leading Performances
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Skywork R1V2, a next-generation multimodal reasoning model that improves upon its predecessor, addressing the challenge of balancing reasoning capabilities with generalization.
🛠️ Research Methods:
– Implementation of a hybrid Reinforcement Learning paradigm combining reward-model guidance and rule-based strategies.
– Use of a Selective Sample Buffer mechanism to handle the “Vanishing Advantages” issue in Group Relative Policy Optimization.
– Monitoring and mitigation of visual hallucinations via calibrated reward thresholds during training.
💬 Research Conclusions:
– Skywork R1V2 achieves benchmark-leading performances and demonstrates significant progress in closing the performance gap with premier proprietary systems. The model weights have been publicly released to promote openness and reproducibility.
👉 Paper link: https://huggingface.co/papers/2504.16656

3. BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
🔑 Keywords: 1-bit Large Language Models, activation outliers, quantization, BitNet v2, H-BitLinear
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce BitNet v2, a framework enabling native 4-bit activation quantization for 1-bit LLMs, addressing activation outliers.
🛠️ Research Methods:
– Implementation of H-BitLinear, an online Hadamard transformation module to smooth sharp activation distributions.
💬 Research Conclusions:
– BitNet v2 achieves performance comparable to previous models with 8-bit activations while maintaining minimal performance degradation and reducing memory and computational costs with 4-bit activations.
👉 Paper link: https://huggingface.co/papers/2504.18415

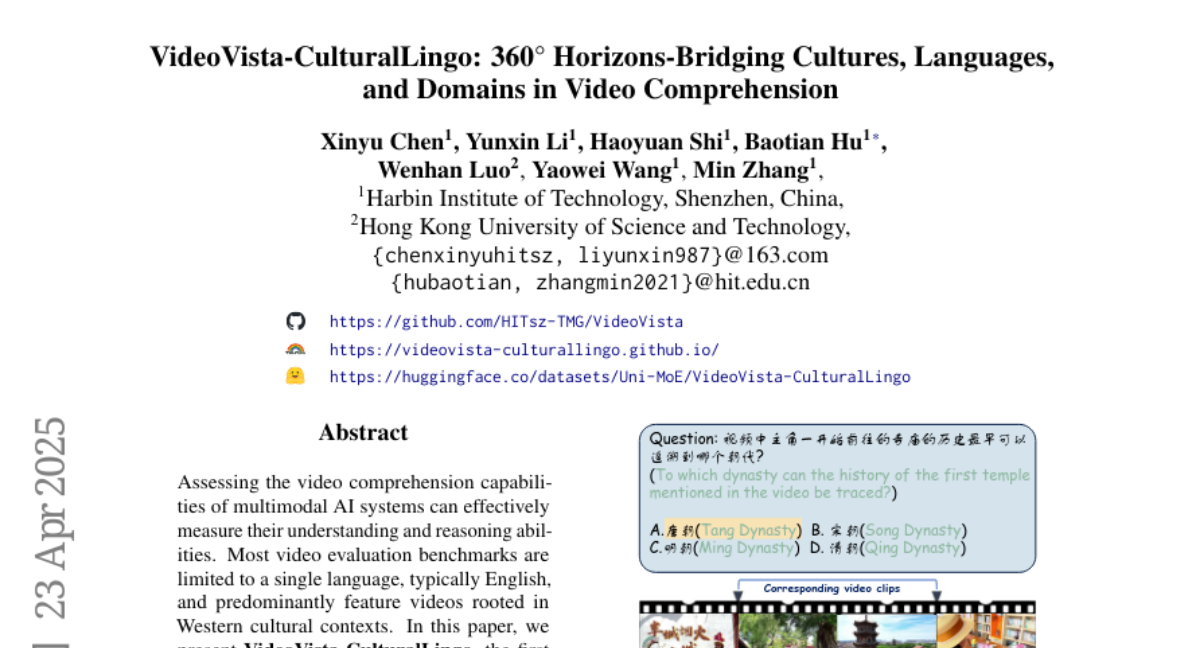
4. VideoVista-CulturalLingo: 360^circ Horizons-Bridging Cultures, Languages, and Domains in Video Comprehension
🔑 Keywords: Multimodal AI systems, Cultural diversity, Multi-linguistics, Video comprehension, Event Localization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary goal is to develop a video evaluation benchmark named VideoVista-CulturalLingo that addresses cultural, linguistic, and domain gaps in video comprehension.
🛠️ Research Methods:
– Compile 1,389 videos and 3,134 QA pairs encompassing diverse cultures and languages, with a focus on assessing 24 video large models on Chinese and Western cultural contexts.
💬 Research Conclusions:
– Existing video models perform poorly on Chinese-centric questions, especially those related to Chinese history; current models struggle with temporal tasks like Event Localization, highlighting limitations at an achievement maximum of only 45.2%.
👉 Paper link: https://huggingface.co/papers/2504.17821
5. Can Large Language Models Help Multimodal Language Analysis? MMLA: A Comprehensive Benchmark
🔑 Keywords: Multimodal Language Analysis, Large Language Models, Cognitive Semantics, Multimodal Semantics, MMLA
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce MMLA, a comprehensive benchmark designed to evaluate the capability of multimodal large language models (MLLMs) to understand cognitive-level semantics in human conversational utterances.
🛠️ Research Methods:
– Utilized three methods to evaluate eight mainstream branches of LLMs and MLLMs: zero-shot inference, supervised fine-tuning, and instruction tuning.
💬 Research Conclusions:
– Experiments revealed that fine-tuned models can only achieve about 60%~70% accuracy, highlighting the limitations of current MLLMs in comprehending complex human language.
👉 Paper link: https://huggingface.co/papers/2504.16427

6. Subject-driven Video Generation via Disentangled Identity and Motion
🔑 Keywords: subject-specific learning, temporal dynamics, image customization dataset, identity injection, video customization
💡 Category: Generative Models
🌟 Research Objective:
– To develop a zero-shot subject-driven video generation model by decoupling subject-specific learning from temporal dynamics without additional tuning.
🛠️ Research Methods:
– Utilized an image customization dataset for identity injection and temporal modeling with unannotated videos using an image-to-video training method.
– Employed random image token dropping to address copy-and-paste issues and introduced stochastic switching to prevent catastrophic forgetting during joint optimization.
💬 Research Conclusions:
– The proposed method achieved strong subject consistency and scalability, outperforming existing video customization models in zero-shot settings, highlighting the effectiveness of the framework.
👉 Paper link: https://huggingface.co/papers/2504.17816
7. The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
🔑 Keywords: Sparse attention, Transformer LLMs, long-sequence tasks, scaling laws, performance-sensitive applications
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the viability, efficiency-accuracy trade-offs, and scaling strategies of sparse attention in extending long-context capabilities in Transformer LLMs.
🛠️ Research Methods:
– Conducting a comparison of training-free sparse attention methods across different model scales, sequence lengths, and sparsity levels in a range of long-sequence tasks.
💬 Research Conclusions:
– Larger and highly sparse models are preferable for very long sequences.
– Higher sparsity levels are achievable during decoding compared to prefilling, depending on model size.
– No single sparsity strategy works best across all tasks and phases, with varying adaptability required. Moderate sparsity often results in performance degradation in some tasks.
– Novel scaling laws for sparse attention demonstrate its potential beyond the tested experiments but highlight the need for cautious evaluation of trade-offs in performance-sensitive applications.
👉 Paper link: https://huggingface.co/papers/2504.17768

8. DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models
🔑 Keywords: Reasoning-Enhanced Framework, Reinforcement Learning, Financial Reasoning, Dual Reward Signals, Real-World Applications
💡 Category: AI in Finance
🌟 Research Objective:
– To address the core challenges of reasoning in large language models within the financial domain focusing on domain-specific knowledge, numerical calculations, and compliance rules.
🛠️ Research Methods:
– Introduction of the DianJin-R1 framework enhanced with reasoning-augmented supervision and reinforcement learning.
– Utilization of a specialized dataset, DianJin-R1-Data, derived from CFLUE, FinQA, and a proprietary compliance corpus.
– Application of Group Relative Policy Optimization (GRPO) for refining reasoning quality with dual reward signals.
💬 Research Conclusions:
– DianJin-R1 models outperform non-reasoning counterparts in complex financial tasks and excel in real-world applications while reducing computational costs compared to multi-agent systems.
👉 Paper link: https://huggingface.co/papers/2504.15716

9. Kimi-Audio Technical Report
🔑 Keywords: Kimi-Audio, audio understanding, LLM-based architecture, audio tokenizer, state-of-the-art performance
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduction of Kimi-Audio, an open-source audio foundation model excelling in audio understanding, generation, and conversation.
🛠️ Research Methods:
– Utilization of a 12.5Hz audio tokenizer and novel LLM-based architecture with continuous features and discrete tokens.
– Development of a chunk-wise streaming detokenizer based on flow matching.
– Curation of a comprehensive pre-training dataset with 13 million hours of audio data across diverse modalities.
💬 Research Conclusions:
– Kimi-Audio demonstrates state-of-the-art performance on various audio benchmarks, including speech recognition and audio question answering.
– Release of codes, model checkpoints, and evaluation toolkits on GitHub.
👉 Paper link: https://huggingface.co/papers/2504.18425

10. DC-SAM: In-Context Segment Anything in Images and Videos via Dual Consistency
🔑 Keywords: In-Context Segmentation, One-Shot Segmentation, Prompt-Tuning, Dual Consistency SAM, IC-VOS
💡 Category: Computer Vision
🌟 Research Objective:
– To adapt Segment Anything Models (SAM) for in-context segmentation of images and videos using a novel Dual Consistency SAM (DC-SAM) method.
🛠️ Research Methods:
– Developed DC-SAM utilizing prompt-tuning and designed cycle-consistent cross-attention, dual-branch design with discriminative prompts, and a mask-tube training strategy.
– Constructed the first benchmark dataset, In-Context Video Object Segmentation (IC-VOS), for assessing in-context segmentation in videos.
💬 Research Conclusions:
– DC-SAM demonstrated improved performance with a mIoU of 55.5 on COCO-20i, 73.0 mIoU on PASCAL-5i, and a J&F score of 71.52 on IC-VOS, highlighting its effectiveness for in-context segmentation tasks.
👉 Paper link: https://huggingface.co/papers/2504.12080

11. Optimizing LLMs for Italian: Reducing Token Fertility and Enhancing Efficiency Through Vocabulary Adaptation
🔑 Keywords: Large Language Models, Semantic Alignment, Vocabulary Adaptation, Neural Mapping
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to optimize Large Language Models, originally designed for English, to efficiently handle the Italian language through vocabulary adaptation techniques.
🛠️ Research Methods:
– The researchers introduce Semantic Alignment Vocabulary Adaptation (SAVA), utilizing neural mapping for effective vocabulary substitution. They adapt models like Mistral-7b-v0.1 and Llama-3.1-8B, focusing on reducing token fertility and optimizing parameters.
💬 Research Conclusions:
– The adapted models show competitive performance after vocabulary adjustment, managing successful task completion in multi-choice and generative tasks, even with limited continual training on the target language.
👉 Paper link: https://huggingface.co/papers/2504.17025

12. Even Small Reasoners Should Quote Their Sources: Introducing the Pleias-RAG Model Family
🔑 Keywords: Pleias-RAG-350m, Pleias-RAG-1B, Multilingual, RAG, Generative AI
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce a new generation of small reasoning models, Pleias-RAG-350m and Pleias-RAG-1B, for RAG, search, and source summarization.
🛠️ Research Methods:
– Mid-training on a large synthetic dataset emulating multilingual open source retrieval from the Common Corpus.
💬 Research Conclusions:
– These models outperform other SLMs below 4 billion parameters on standardized RAG benchmarks and are competitive with larger popular models.
– They maintain consistent RAG performance across leading European languages and ensure systematic reference grounding, enabling new use cases in generative AI.
👉 Paper link: https://huggingface.co/papers/2504.18225
