AI Native Daily Paper Digest – 20250506

1. Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
🔑 Keywords: Voice AI, AI Native, Low-latency conversations, Multilingual speech translation, Open-sourced
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The primary goal is to develop a voice AI agent, Voila, that facilitates natural, real-time, and emotionally expressive human-machine interactions.
🛠️ Research Methods:
– Employs an end-to-end architecture integrating hierarchical multi-scale Transformers with large language and acoustic modeling for fluid voice AI.
💬 Research Conclusions:
– Voila surpasses average human response time with a latency of just 195 milliseconds and supports dynamic voice generation and customization for various applications.
👉 Paper link: https://huggingface.co/papers/2505.02707
2. RM-R1: Reward Modeling as Reasoning
🔑 Keywords: Reward Modeling, Reinforcement Learning, Reasoning Reward Models, Long Chain-of-Thought, Interpretability
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the interpretability and performance of reward models by integrating reasoning capabilities, specifically through the introduction of Reasoning Reward Models (ReasRMs).
🛠️ Research Methods:
– Developed a reasoning-oriented training pipeline for ReasRMs, which includes two stages: distillation of high-quality reasoning chains and reinforcement learning with verifiable rewards.
– Empirical evaluation across multiple comprehensive reward model benchmarks.
💬 Research Conclusions:
– ReasRMs outperform larger open-weight and proprietary models by up to 13.8% in generative reward model benchmarks, achieving state-of-the-art or near state-of-the-art performance.
– Six ReasRM models, accompanied by code and data, are released to facilitate future research.
👉 Paper link: https://huggingface.co/papers/2505.02387

3. Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers
🔑 Keywords: Transformers, Multi-step Factual Reasoning, Grokking, Knowledge Graphs, Synthetic Data
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to extend the concept of grokking to real-world factual data by addressing dataset sparsity through data augmentation with synthetic data.
🛠️ Research Methods:
– Augmentation of existing knowledge graphs with carefully designed synthetic data.
– Evaluation on multi-hop reasoning benchmarks like 2WikiMultiHopQA to measure the efficiency of the approach.
💬 Research Conclusions:
– The approach achieves significant improvements in multi-hop reasoning benchmarks, reaching up to 95-100% accuracy.
– Demonstrates that even factually incorrect synthetic data can enhance reasoning capabilities, promoting the development of generalizing circuits in Transformers.
– Suggests that grokking-based data augmentation could lead to more robust and interpretable factual reasoning in large-scale language models.
👉 Paper link: https://huggingface.co/papers/2504.20752

4. Practical Efficiency of Muon for Pretraining
🔑 Keywords: Muon, Second-order optimizer, AdamW, Data efficiency, Hyperparameter transfer
💡 Category: Machine Learning
🌟 Research Objective:
– To demonstrate how Muon, a second-order optimizer, enhances the Pareto frontier in comparison to AdamW by improving data efficiency at large batch sizes while maintaining computational efficiency.
🛠️ Research Methods:
– Combination of Muon with maximal update parameterization (muP) and the introduction of a telescoping algorithm to manage errors in muP with minimal resource overhead.
💬 Research Conclusions:
– Extensive experiments validated that Muon is superior for data retention and computational economy, particularly with large model sizes up to four billion parameters, as well as across varied data distributions and architectures.
👉 Paper link: https://huggingface.co/papers/2505.02222

5. Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
🔑 Keywords: Chain-of-thought, Latent Variable Problem, Dynamic Sample Allocation Strategy, GVM-RAFT
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve Chain-of-thought reasoning efficiency in large language models by addressing the main bottleneck of inefficient stochastic gradient estimation.
🛠️ Research Methods:
– Proposed GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance within a computational budget by dynamically allocating computational resources.
💬 Research Conclusions:
– GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT in mathematical reasoning tasks.
– The strategy is generalizable and shows similar improvements in other reinforcement learning algorithms like GRPO.
👉 Paper link: https://huggingface.co/papers/2505.02391

6. FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
🔑 Keywords: AI Native, autoformalization, LLM-based provers, theorem provers, formal reasoning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to tackle the challenge of formal mathematical reasoning in AI, hindered by current benchmarks’ limitations.
🛠️ Research Methods:
– The introduction of FormalMATH, a large Lean4 benchmark, and a human-in-the-loop autoformalization pipeline utilizing large language models for more efficient formalization.
💬 Research Conclusions:
– The study highlights significant limitations in existing LLM-based theorem provers and identifies an inverse relationship between natural-language guidance and proof success in formal reasoning.
👉 Paper link: https://huggingface.co/papers/2505.02735

7. A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency
🔑 Keywords: Large Language Models, Inference Engines, Optimization Techniques, Scalability, Ecosystem Maturity
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To provide a comprehensive evaluation of 25 open-source and commercial LLM inference engines focusing on their performance and integration in service-oriented infrastructures.
🛠️ Research Methods:
– Assessment of inference engines based on ease-of-use, deployment, general-purpose support, scalability, and suitability for throughput- and latency-aware computation.
– Exploration of optimization techniques supported by the inference engines and evaluation of their ecosystem maturity.
💬 Research Conclusions:
– Identifies future research directions in supporting complex LLM-based services, various hardware, and enhanced security.
– Provides practical guidance for developers and researchers to select and design optimized LLM inference engines. A public repository for tracking developments in the field is also available.
👉 Paper link: https://huggingface.co/papers/2505.01658

8. ReplaceMe: Network Simplification via Layer Pruning and Linear Transformations
🔑 Keywords: training-free depth pruning, transformer blocks, linear operation, large language models (LLMs), open-source library
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce ReplaceMe, a method for pruning transformer blocks without training, while maintaining high performance for low compression ratios.
🛠️ Research Methods:
– Employ a calibration dataset to estimate a linear transformation, integrating seamlessly with existing transformer blocks without extra parameters or retraining.
💬 Research Conclusions:
– ReplaceMe achieves up to 25% pruning in LLMs, retaining about 90% of original model performance, outperforming other training-free methods with minimal computational overhead.
👉 Paper link: https://huggingface.co/papers/2505.02819

9. Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
🔑 Keywords: Agentic Reasoning, Reinforcement Learning, Tool Integration, LLMs, Multi-turn Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce ARTIST, a framework enhancing large language models through agentic reasoning and tool integration for dynamic problem-solving.
🛠️ Research Methods:
– Combination of agentic reasoning, reinforcement learning, and tool integration to enable LLMs to autonomously leverage tools and environments.
– Outcome-based reinforcement learning applied without step-level supervision.
💬 Research Conclusions:
– ARTIST significantly outperforms state-of-the-art baselines with substantial improvement, particularly excelling in mathematical reasoning and multi-turn tasks.
– Agentic RL training enhances reasoning depth, tool use efficiency, and solution quality, establishing a new direction for LLM capabilities.
👉 Paper link: https://huggingface.co/papers/2505.01441

10. R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning
🔑 Keywords: Multimodal Reward Models, Multimodal Large Language Models, Reinforcement Learning, StableReinforce, R1-Reward
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate the activation of long-term reasoning capabilities in Multimodal Reward Models using Reinforcement Learning.
🛠️ Research Methods:
– Reformulating reward modeling as a rule-based RL task and proposing the StableReinforce algorithm to enhance training stability and effectiveness.
– Collecting 200K preference data from diverse datasets to facilitate MRM training.
💬 Research Conclusions:
– The R1-Reward model, using the StableReinforce algorithm, significantly improves performance on reward modeling benchmarks by 8.4% on VL Reward-Bench and 14.3% on Multimodal Reward Bench.
– Highlighted the potential of RL algorithms in optimizing MRMs with extended inference compute.
👉 Paper link: https://huggingface.co/papers/2505.02835

11. Think on your Feet: Adaptive Thinking via Reinforcement Learning for Social Agents
🔑 Keywords: Adaptive Mode Learning, Context-aware mode switching, Multi-granular thinking mode design, Token-efficient reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop an adaptive reasoning framework called Adaptive Mode Learning (AML), which strategically selects from four thinking modes based on real-time context to improve social intelligence simulations.
🛠️ Research Methods:
– Introduction of the Adaptive Mode Policy Optimization (AMPO) algorithm featuring multi-granular thinking mode design, context-aware mode switching, and token-efficient reasoning via depth-adaptive processing.
💬 Research Conclusions:
– AML achieved a 15.6% higher task performance on social intelligence tasks compared to state-of-the-art methods, outperforming GRPO by 7.0% with significantly shorter reasoning chains, indicating more human-like adaptive reasoning.
👉 Paper link: https://huggingface.co/papers/2505.02156

12. SkillMimic-V2: Learning Robust and Generalizable Interaction Skills from Sparse and Noisy Demonstrations
🔑 Keywords: Reinforcement Learning, demonstration noise, coverage limitations, skill acquisition, generalization capability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research addresses the challenges of demonstration noise and coverage limitations in Reinforcement Learning from Interaction Demonstration (RLID).
🛠️ Research Methods:
– Two data augmentation techniques were introduced: the Stitched Trajectory Graph (STG) for discovering potential transitions, and the State Transition Field (STF) for establishing unique state connections. An Adaptive Trajectory Sampling (ATS) strategy and historical encoding mechanism were developed for skill acquisition.
💬 Research Conclusions:
– The approach significantly enhances skill acquisition, generalization capability, and convergence stability, outperforming state-of-the-art methods across diverse interaction tasks.
👉 Paper link: https://huggingface.co/papers/2505.02094

13. Low-Precision Training of Large Language Models: Methods, Challenges, and Opportunities
🔑 Keywords: Low-Precision Training, Large Language Models (LLMs), Numerical Formats
💡 Category: Machine Learning
🌟 Research Objective:
– To provide a comprehensive review and categorize existing low-precision training methods for improving training efficiency of large language models.
🛠️ Research Methods:
– Organized low-precision training methods into three categories: (1) fixed-point and integer-based methods, (2) floating-point-based methods, and (3) customized format-based methods, and discussed quantization-aware training approaches.
💬 Research Conclusions:
– The survey highlights the challenges in the fragmented low-precision training landscape and identifies several promising research directions to advance in this field.
👉 Paper link: https://huggingface.co/papers/2505.01043

14. SuperEdit: Rectifying and Facilitating Supervision for Instruction-Based Image Editing
🔑 Keywords: editing instructions, contrastive editing instructions, vision-language models (VLMs), instruction-based image editing, Real-Edit benchmark
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to improve editing models by constructing more effective editing instructions for image pairs, aligning them better with original-edited outputs.
🛠️ Research Methods:
– The paper introduces a method that rectifies editing instructions and employs contrastive supervision signals with triplet loss to enhance supervision effectiveness.
– This approach avoids previous reliance on VLM modules or pre-training tasks, promoting a more direct and efficient supervision process.
💬 Research Conclusions:
– The proposed method significantly outperforms existing approaches, achieving a 9.19% improvement over the previous state-of-the-art SmartEdit on the Real-Edit benchmark, with 30 times less training data and a model size 13 times smaller.
👉 Paper link: https://huggingface.co/papers/2505.02370

15. Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
🔑 Keywords: Ming-Lite-Uni, multimodal AI, unified visual generator, MetaQueries, M2-omni framework
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Ming-Lite-Uni, an open-source framework for unifying vision and language through a new multimodal autoregressive model.
🛠️ Research Methods:
– Implementation of integrated MetaQueries and M2-omni framework with novel multi-scale learnable tokens and a multi-scale representation alignment strategy.
– Utilization of a fixed MLLM and a learnable diffusion model to enable text-to-image generation and instruction-based image editing tasks.
💬 Research Conclusions:
– Ming-Lite-Uni demonstrates strong performance and fluid interactive processes, contributing to ongoing multimodal AI advancements, as seen with similar technologies like ChatGPT-4o.
👉 Paper link: https://huggingface.co/papers/2505.02471

16. LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
🔑 Keywords: Real-time speech interaction, Speech Language Models, Autoregressive Streaming, LLaMA-Omni 2, Spoken Question Answering
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a series of speech language models, LLaMA-Omni 2, capable of high-quality real-time speech interaction.
🛠️ Research Methods:
– Integration of a speech encoder and an autoregressive streaming speech decoder into the Qwen2.5 series models, with a focus on limited data training (200K multi-turn speech dialogue samples).
💬 Research Conclusions:
– LLaMA-Omni 2 models outperform previous state-of-the-art SpeechLMs like GLM-4-Voice on spoken question answering and speech instruction following benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.02625

17. TEMPURA: Temporal Event Masked Prediction and Understanding for Reasoning in Action
🔑 Keywords: TEMPURA, causal reasoning, video segmentation, fine-grained temporal understanding
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to enhance video temporal understanding by focusing on causal event relationships and fine-grained temporal grounding.
🛠️ Research Methods:
– The proposed TEMPURA framework uses a two-stage training process: 1) Masked event prediction reasoning to reconstruct missing events and generate causal explanations. 2) Learning to perform video segmentation and dense captioning for non-overlapping events with detailed timestamp-aligned descriptions.
💬 Research Conclusions:
– TEMPURA, trained on a large-scale VER dataset, outperforms existing models in temporal grounding and highlight detection, proving the effectiveness of integrating causal reasoning with fine-grained temporal segmentation for improved video understanding.
👉 Paper link: https://huggingface.co/papers/2505.01583

18. Learning Heterogeneous Mixture of Scene Experts for Large-scale Neural Radiance Fields
🔑 Keywords: NeRF, scene decomposition, learnable decomposition, scalable NeRFs, heterogeneous representation
💡 Category: Computer Vision
🌟 Research Objective:
– Address challenges in large-scale scene modeling through heterogeneous mixture network Switch-NeRF++.
🛠️ Research Methods:
– Developed a unified framework incorporating a Sparsely Gated Mixture of Experts (MoE) NeRF with a hash-based gating network to efficiently manage scene decomposition and utilize distinct heterogeneous hash experts for learning.
💬 Research Conclusions:
– Demonstrated significant improvements in scalability and accuracy for large-scale scene rendering, achieving state-of-the-art results and an impressive acceleration in training and rendering speeds.
👉 Paper link: https://huggingface.co/papers/2505.02005

19. MUSAR: Exploring Multi-Subject Customization from Single-Subject Dataset via Attention Routing
🔑 Keywords: MUSAR, debiased diptych learning, single-subject training, static attention routing, dynamic attention routing
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a framework called MUSAR to achieve robust multi-subject customization using single-subject training data.
🛠️ Research Methods:
– Implement debiased diptych learning to construct diptych training pairs and correct distribution bias with static attention routing and dual-branch LoRA.
– Use dynamic attention routing to establish bijective mappings and decouple multi-subject representations.
💬 Research Conclusions:
– MUSAR outperforms existing methods in image quality, subject consistency, and interaction naturalness using only a single-subject dataset.
👉 Paper link: https://huggingface.co/papers/2505.02823

20. Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation
🔑 Keywords: multimodal LLMs, targeted unlearning, multimodal unlearning, UnLOK-VQA, interpretability of hidden states
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to explore and improve the capability of multimodal LLMs to forget sensitive information by introducing a novel benchmark, UnLOK-VQA.
🛠️ Research Methods:
– The research implements a novel attack-and-defense framework to evaluate multimodal unlearning, using an extended visual question-answering dataset and testing six defense objectives against various attack strategies.
💬 Research Conclusions:
– Multimodal attacks are more effective than single-modality ones, and effective defense involves removing answer information from model states. Larger models demonstrate greater robustness, enhancing safety post-editing.
👉 Paper link: https://huggingface.co/papers/2505.01456

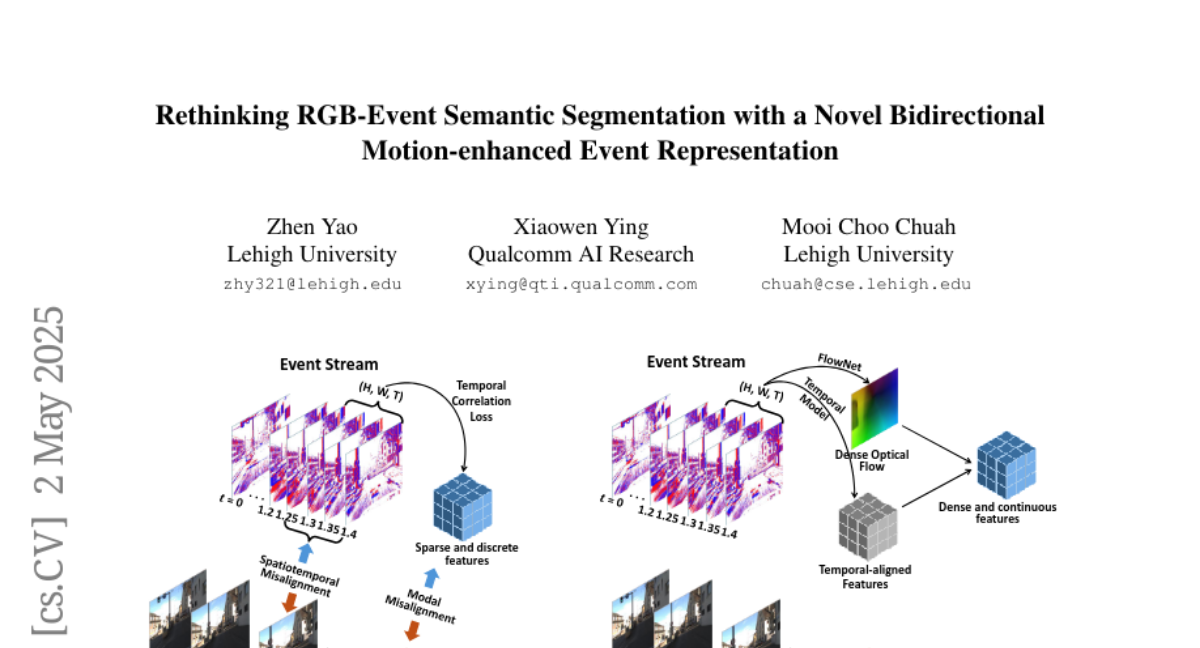
21. Rethinking RGB-Event Semantic Segmentation with a Novel Bidirectional Motion-enhanced Event Representation
🔑 Keywords: Event cameras, RGB-Event fusion, Motion-enhanced Event Tensor (MET), Frequency-aware Bidirectional Flow Aggregation Module (BFAM), Temporal Fusion Module (TFM)
💡 Category: Computer Vision
🌟 Research Objective:
– To address temporal, spatial, and modal misalignments in RGB-Event fusion for improved computer vision task performance.
🛠️ Research Methods:
– Introduced a novel representation, MET, to transform event voxels into a dense, temporally coherent form using dense optical flows and event temporal features. Developed BFAM and TFM to tackle modal and spatiotemporal misalignments.
💬 Research Conclusions:
– The proposed framework significantly outperforms existing state-of-the-art RGB-Event semantic segmentation approaches on two large-scale datasets.
👉 Paper link: https://huggingface.co/papers/2505.01548
22. Attention Mechanisms Perspective: Exploring LLM Processing of Graph-Structured Data
🔑 Keywords: Attention Mechanisms, Graph-Structured Data, Large Language Models, Message-Passing Mechanisms, Intermediate-State Attention Windows
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore how attention mechanisms in Large Language Models (LLMs) process graph-structured data and to understand the attention behavior over graph structures.
🛠️ Research Methods:
– Conducting an empirical study from the perspective of attention mechanisms to gain insights into how LLMs apply attention to graph-structured data.
💬 Research Conclusions:
– LLMs recognize graph data and capture text-node interactions but struggle to model inter-node relationships due to architectural constraints.
– Attention distribution across graph nodes fails to align with ideal structural patterns, indicating limitations in adapting to graph topology nuances.
– Neither fully connected attention nor fixed connectivity is optimal; intermediate-state attention windows improve training performance and benefit inference.
👉 Paper link: https://huggingface.co/papers/2505.02130

23.
