AI Native Daily Paper Digest – 20250520
1. Chain-of-Model Learning for Language Model
🔑 Keywords: Chain-of-Model, Chain-of-Representation, Transformer architecture, elastic inference, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Chain-of-Model (CoM) paradigm to enhance scaling efficiency and inference flexibility.
🛠️ Research Methods:
– Develop Chain-of-Language-Model (CoLM) integrating CoM with Transformer architecture, and extend with CoLM-Air using KV sharing mechanism.
💬 Research Conclusions:
– CoLM family achieves performance similar to standard Transformer while providing enhanced flexibility and efficiency, especially for elastic inference and progressive scaling in language models.
👉 Paper link: https://huggingface.co/papers/2505.11820

2. AdaptThink: Reasoning Models Can Learn When to Think
🔑 Keywords: NoThinking, AdaptThink, Reinforcement Learning, constrained optimization, importance sampling
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore methods that enhance the performance and efficiency of reasoning models by reducing inference overhead through adaptive thinking modes.
🛠️ Research Methods:
– Developed AdaptThink, a novel reinforcement learning algorithm featuring a constrained optimization objective and an importance sampling strategy to improve reasoning models’ efficiency and performance.
💬 Research Conclusions:
– AdaptThink significantly decreases inference costs and boosts performance, exemplified by a reduction in average response length by 53% and an accuracy improvement of 2.4% on math datasets.
👉 Paper link: https://huggingface.co/papers/2505.13417

3. AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
🔑 Keywords: Large Language Models, Chain-of-Thought, Adaptive Reasoning, Reinforcement Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce AdaCoT (Adaptive Chain-of-Thought) to address inefficiencies in reasoning tasks for Large Language Models by adaptively determining when to invoke Chain-of-Thought.
🛠️ Research Methods:
– Utilize reinforcement learning with Proximal Policy Optimization to adjust CoT invocation, using Selective Loss Masking to ensure stable training.
💬 Research Conclusions:
– AdaCoT effectively reduces unnecessary CoT usage and computational costs while maintaining high performance on complex tasks, demonstrated through significant reductions in CoT triggering rates and response token counts.
👉 Paper link: https://huggingface.co/papers/2505.11896

4. Delta Attention: Fast and Accurate Sparse Attention Inference by Delta Correction
🔑 Keywords: Sparse attention, distributional shift, performance degradation, quadratic attention, sliding window attention
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to reduce the computational burden of the attention mechanism in transformers for long sequences while addressing performance degradation due to sparse attention methods.
🛠️ Research Methods:
– The authors propose a novel procedure to correct the distributional shift in attention outputs caused by sparse calculations, thereby aligning them more closely with quadratic attention outputs.
💬 Research Conclusions:
– The proposed method enhances performance by an average of 36% points, recovering 88% of quadratic attention accuracy on the 131K RULER benchmark while maintaining approximately 98.5% sparsity and achieving significant speed improvements.
👉 Paper link: https://huggingface.co/papers/2505.11254

5. Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
🔑 Keywords: GUI grounding, OSWorld-G, Jedi, software commonsense, compositional generalization
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Address limitations in current GUI grounding by introducing the comprehensive benchmark OSWorld-G and a large dataset called Jedi.
🛠️ Research Methods:
– Develop multi-scale models trained on the Jedi dataset to improve grounding on various GUI tasks.
– Conduct detailed ablation studies to identify key factors for performance improvement.
💬 Research Conclusions:
– The Jedi dataset enhances agentic capabilities of general foundation models significantly, with improvements from 5% to 27% on complex computer tasks.
– Combining specialized data enables compositional generalization to new interfaces.
👉 Paper link: https://huggingface.co/papers/2505.13227

6. Faster Video Diffusion with Trainable Sparse Attention
🔑 Keywords: Video Diffusion Transformers, Sparse Attention, Token-level Attention, Training FLOPS, End-to-end Generation Time
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to address the scaling limitations of Video Diffusion Transformers (DiTs) due to their quadratic 3D attention, by developing a new method called VSA that employs sparse attention.
🛠️ Research Methods:
– The introduction of VSA involves a two-stage process with a lightweight coarse stage that pools tokens into tiles and identifies critical tokens, followed by a fine stage that computes token-level attention within those tiles to enhance hardware efficiency.
💬 Research Conclusions:
– VSA achieves a significant reduction in training FLOPS by 2.53 times without affecting diffusion loss and speeds up attention time by 6 times, establishing trainable sparse attention as an efficient alternative to full attention for scaling video diffusion models.
👉 Paper link: https://huggingface.co/papers/2505.13389

7. Thinkless: LLM Learns When to Think
🔑 Keywords: Reasoning Language Models, Thinkless, hybrid reasoning, Decoupled Group Relative Policy Optimization, reinforcement learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a learnable framework called Thinkless that enables Language Models to adaptively choose between short-form and long-form reasoning based on task complexity and model capability.
🛠️ Research Methods:
– Implementation of the Thinkless framework trained with reinforcement learning.
– Utilization of the Decoupled Group Relative Policy Optimization algorithm to separate the learning objective into control token loss and response loss, allowing stable and efficient training.
💬 Research Conclusions:
– Thinkless significantly enhances the efficiency of Reasoning Language Models by reducing long-chain thinking by 50% – 90% in various benchmarks, proving the framework’s effectiveness in practical applications.
👉 Paper link: https://huggingface.co/papers/2505.13379

8. Model Merging in Pre-training of Large Language Models
🔑 Keywords: Model Merging, Pre-training, MoE Architectures, Performance Improvements
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate model merging techniques during large-scale pre-training.
🛠️ Research Methods:
– Conducted extensive experiments with dense and Mixture-of-Experts architectures involving millions to over 100 billion parameters.
– Performed detailed ablation studies on merging strategies and hyperparameters.
💬 Research Conclusions:
– Demonstrated significant performance improvements and cost reduction through merging checkpoints trained with constant learning rates.
– Provided practical pre-training guidelines for the open-source community to enhance model merging efficiency.
👉 Paper link: https://huggingface.co/papers/2505.12082

9. Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space
🔑 Keywords: Reasoning ability, Large Language Models, Latent space, Application Modernization, Test-Time Instance-level Adaptation
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address reasoning challenges in LLMs by improving test-time performance through latent space adaptation rather than token space manipulation.
🛠️ Research Methods:
– Introducing LatentSeek, a framework using Test-Time Instance-level Adaptation (TTIA) that employs policy gradient to update latent representations; evaluated on benchmarks like GSM8K and MATH-500.
💬 Research Conclusions:
– LatentSeek consistently outperforms existing methods like Chain-of-Thought prompting, demonstrating efficiency in test-time scaling within latent spaces and positioning itself as a scalable solution for reasoning enhancement in LLMs.
👉 Paper link: https://huggingface.co/papers/2505.13308

10. CPGD: Toward Stable Rule-based Reinforcement Learning for Language Models
🔑 Keywords: Reinforcement Learning, Training Stability, Clipped Policy Gradient Optimization, Policy Drift, Empirical Analysis
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to address the training instability in rule-based reinforcement learning methods for language models.
🛠️ Research Methods:
– A novel algorithm, Clipped Policy Gradient Optimization with Policy Drift (CPGD), is developed to stabilize policy learning using a policy drift constraint and a clip mechanism based on KL divergence.
💬 Research Conclusions:
– CPGD effectively mitigates training instability and improves performance while maintaining stability, offering a robust alternative for reinforcement learning in post-training of language models.
👉 Paper link: https://huggingface.co/papers/2505.12504

11. FedSVD: Adaptive Orthogonalization for Private Federated Learning with LoRA
🔑 Keywords: Low-Rank Adaptation, Federated Learning, Differential Privacy, Singular Value Decomposition, Reparameterization
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce FedSVD, a method to mitigate noise amplification in Low-Rank Adaptation during federated learning while maintaining model expressiveness.
🛠️ Research Methods:
– Utilized singular value decomposition for reparameterization, allowing the optimization of matrix B and reaggregation to create an adaptive matrix A, which limits noise amplification.
💬 Research Conclusions:
– FedSVD improves stability and performance, especially under privacy constraints, outperforming baselines in both private and non-private settings.
👉 Paper link: https://huggingface.co/papers/2505.12805

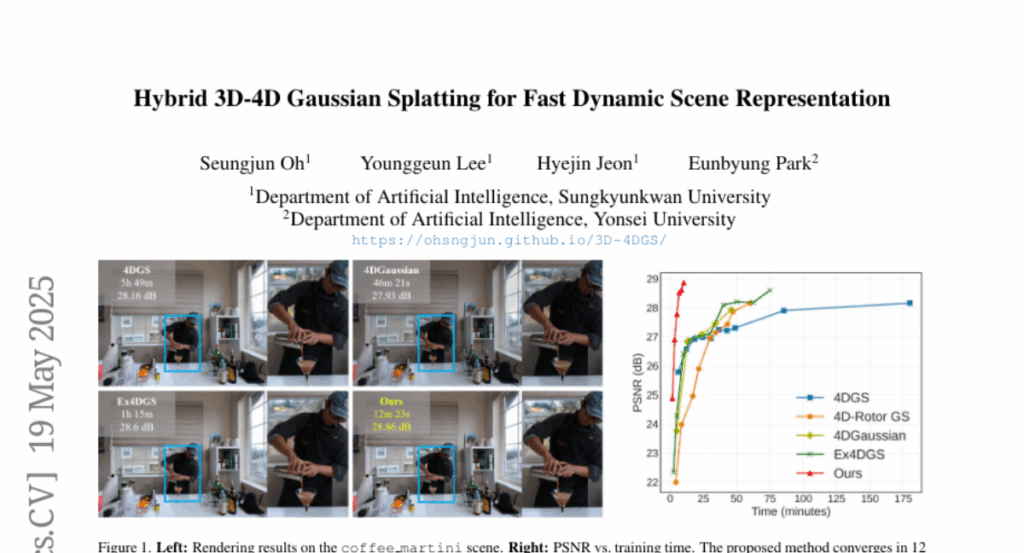
12. Hybrid 3D-4D Gaussian Splatting for Fast Dynamic Scene Representation
🔑 Keywords: 3D Scene Reconstruction, 4D Gaussian Splatting, Computational Efficiency, Temporal Consistency
💡 Category: Computer Vision
🌟 Research Objective:
– To improve dynamic 3D scene reconstruction by introducing a novel framework that enhances computational efficiency and visual quality.
🛠️ Research Methods:
– Developed a hybrid 3D-4D Gaussian Splatting framework that adaptively represents static regions with 3D Gaussians while keeping 4D Gaussians for dynamic elements.
💬 Research Conclusions:
– The proposed method significantly reduces computational overhead and improves training times while maintaining or enhancing visual quality compared to baseline methods.
👉 Paper link: https://huggingface.co/papers/2505.13215
13. MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision
🔑 Keywords: Multimodal Large Language Models, multi-step reasoning, MM-PRM, Monte Carlo Tree Search, logical robustness
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve complex multi-step reasoning in Multimodal Large Language Models by providing fine-grained supervision over intermediate reasoning steps.
🛠️ Research Methods:
– Development of MM-PRM, a process reward model within an automated framework, and the construction of MM-K12, a large dataset of multimodal math problems paired with verifiable answers.
– Utilization of a Monte Carlo Tree Search-based pipeline to generate step-level annotations without human participation.
💬 Research Conclusions:
– The proposed MM-PRM improves reasoning solution accuracy across various benchmarks, demonstrating the efficacy of process supervision in strengthening the logical robustness of multimodal reasoning systems.
👉 Paper link: https://huggingface.co/papers/2505.13427

14. Fractured Chain-of-Thought Reasoning
🔑 Keywords: Inference-time scaling, Large Language Models, Chain-of-Thought, Fractured Sampling, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance reasoning capabilities of large language models using inference-time scaling techniques without incurring high token costs.
🛠️ Research Methods:
– Introduction of Fractured Sampling as a unified inference-time strategy that optimizes between full Chain-of-Thought and solution-only sampling across three dimensions.
💬 Research Conclusions:
– Fractured Sampling provides superior accuracy-cost trade-offs and efficient scaling in Pass@k relative to token budget, optimizing computation allocation to maximize performance.
👉 Paper link: https://huggingface.co/papers/2505.12992

15. ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
🔑 Keywords: ChartMuseum, Visual Reasoning, LVLMs, Gemini-2.5-Pro, Qwen2.5-VL-72B-Instruct
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to evaluate the balance and effectiveness of visual and textual reasoning in Large Vision-Language Models (LVLMs) through a newly introduced benchmark, ChartMuseum.
🛠️ Research Methods:
– The researchers conducted a case study using a synthetic dataset that demands visual reasoning and introduced ChartMuseum, a Chart QA benchmark with 1,162 expert-annotated questions from real-world charts.
💬 Research Conclusions:
– Current LVLMs demonstrate a significant gap in visual reasoning capabilities compared to human performance, with even the best-performing model, Gemini-2.5-Pro, achieving only 63% accuracy against 93% by humans. Models struggle particularly with visual reasoning, experiencing a 35%-55% performance drop compared to text-reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2505.13444

16. Neuro-Symbolic Query Compiler
🔑 Keywords: Retrieval-Augmented Generation, neuro-symbolic framework, Backus-Naur Form, Abstract Syntax Trees, document retrieval
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance precise recognition of search intent in Retrieval-Augmented Generation systems, particularly for complex queries with nested structures and dependencies.
🛠️ Research Methods:
– Development of QCompiler, a neuro-symbolic framework inspired by linguistic grammar rules and compiler design, utilizing Backus-Naur Form grammar to formalize complex queries.
– Inclusion of a Query Expression Translator, Lexical Syntax Parser, and Recursive Descent Processor to transform queries into Abstract Syntax Trees for execution.
💬 Research Conclusions:
– The atomicity of sub-queries ensures more precise document retrieval and response generation, significantly improving the system’s capability to handle complex queries.
👉 Paper link: https://huggingface.co/papers/2505.11932

17. Through the Looking Glass: Common Sense Consistency Evaluation of Weird Images
🔑 Keywords: AI Native, Large Vision-Language Models, Transformer-based encoder, atomic facts
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce a novel method, Through the Looking Glass (TLG), for assessing image common sense consistency.
🛠️ Research Methods:
– Utilization of Large Vision-Language Models to extract atomic facts from images.
– Fine-tuning of a compact attention-pooling classifier over encoded atomic facts.
💬 Research Conclusions:
– TLG achieved state-of-the-art performance on the WHOOPS! and WEIRD datasets with a compact fine-tuning component.
👉 Paper link: https://huggingface.co/papers/2505.07704

18. VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning
🔑 Keywords: VisionReasoner, multi-object cognitive learning, task reformulation, unified framework
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce VisionReasoner, a unified framework capable of reasoning and solving multiple visual perception tasks.
🛠️ Research Methods:
– Utilized multi-object cognitive learning strategies and systematic task reformulation to enhance reasoning capabilities.
💬 Research Conclusions:
– VisionReasoner outperforms Qwen2.5VL in three domains by achieving superior performance: 29.1% on COCO (detection), 22.1% on ReasonSeg (segmentation), and 15.3% on CountBench (counting).
👉 Paper link: https://huggingface.co/papers/2505.12081

19. SEED-GRPO: Semantic Entropy Enhanced GRPO for Uncertainty-Aware Policy Optimization
🔑 Keywords: Large Language Models, Semantic Entropy, Policy Optimization, Uncertainty-Aware Training, Mathematical Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to address limitations in Group Relative Policy Optimization (GRPO) by introducing SEED-GRPO, which incorporates a measure of uncertainty in large language models through semantic entropy.
🛠️ Research Methods:
– SEED-GRPO uses semantic entropy to gauge the uncertainty of input prompts and modulates the magnitude of policy updates accordingly during training.
💬 Research Conclusions:
– SEED-GRPO achieves state-of-the-art performance in average accuracy across five mathematical reasoning benchmarks, validating the efficacy of uncertainty-aware policy optimization.
👉 Paper link: https://huggingface.co/papers/2505.12346

20. ViPlan: A Benchmark for Visual Planning with Symbolic Predicates and Vision-Language Models
🔑 Keywords: Vision-Language Models (VLMs), symbolic planning, benchmarking, visual reasoning, commonsense knowledge
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce ViPlan, the first open-source benchmark for visual planning using symbolic predicates and Vision-Language Models (VLMs).
🛠️ Research Methods:
– Benchmark and evaluate nine open-source VLM families and selected closed models across visual planning tasks in two domains: Blocksworld and simulated household robotics.
💬 Research Conclusions:
– Symbolic planning outperforms direct VLM planning in tasks where image grounding is crucial, such as Blocksworld.
– Direct VLM planning is more effective in household robotics tasks, benefiting from commonsense knowledge and error recovery.
– No significant advantage of Chain-of-Thought prompting across most models, indicating limitations in current VLMs’ visual reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2505.13180

21. When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research
🔑 Keywords: Large Language Models, AI Co-Scientists, Academic Verification, SPOT, Errors
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to explore the use of Large Language Models (LLMs) as verifiers to automate the academic verification process of scientific manuscripts.
🛠️ Research Methods:
– Introduction of SPOT, a dataset comprising 83 published papers with 91 significant errors, validated with authors and human annotators.
– Evaluation of state-of-the-art LLMs on SPOT to measure recall and precision in error detection.
💬 Research Conclusions:
– Current LLMs exhibit low reliability, with none surpassing 21.1% recall or 6.1% precision, and confidence estimates remain consistently low.
– LLMs often fail to consistently rediscover errors across runs, highlighting substantial gaps in capability compared to the requirements for dependable AI-assisted academic verification.
👉 Paper link: https://huggingface.co/papers/2505.11855

22. Accelerate TarFlow Sampling with GS-Jacobi Iteration
🔑 Keywords: TarFlow model, transformer architecture, Normalizing Flow models, GS-Jacobi iteration method, Convergence Ranking Metric
💡 Category: Generative Models
🌟 Research Objective:
– To accelerate the sampling process of the TarFlow model without compromising the quality of generated images.
🛠️ Research Methods:
– Utilized the Gauss-Seidel-Jacobi (GS-Jacobi) iteration method to optimize the TarFlow model’s sampling process.
– Developed Convergence Ranking Metric (CRM) and Initial Guessing Metric (IGM) to evaluate block significance and initial value suitability in iterations.
💬 Research Conclusions:
– GS-Jacobi sampling significantly enhances sampling efficiency, achieving speed-ups of up to 5.32x across various models while maintaining FID scores and image quality.
👉 Paper link: https://huggingface.co/papers/2505.12849

23. Tiny QA Benchmark++: Ultra-Lightweight, Synthetic Multilingual Dataset Generation & Smoke-Tests for Continuous LLM Evaluation
🔑 Keywords: Tiny QA Benchmark++, large-language-model (LLM), prompt-optimization SDK, synthetic-data generator, generative-AI ecosystem
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces Tiny QA Benchmark++ (TQB++), a lightweight, multilingual testing toolkit designed to provide a quick and cost-effective smoke test for large-language-model (LLM) pipelines.
🛠️ Research Methods:
– TQB++ integrates a 52-item English gold set with a tiny synthetic-data generator, allowing the creation of small, customizable datasets in multiple languages and domains, enhancing flexibility in testing LLMs.
💬 Research Conclusions:
– TQB++ significantly reduces pipeline latency, effectively identifies prompt-template errors and tokenizer drift, and facilitates resource-efficient quality assurance across the generative-AI ecosystem.
👉 Paper link: https://huggingface.co/papers/2505.12058

24. R3: Robust Rubric-Agnostic Reward Models
🔑 Keywords: Reward models, controllability, interpretability, generalizability, language models
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce R3, a novel reward modeling framework addressing limitations in existing models related to controllability, interpretability, and generalizability.
🛠️ Research Methods:
– Development of a rubric-agnostic and generalizable framework that enhances interpretability and allows reasoned score assignments across evaluation dimensions.
💬 Research Conclusions:
– R3 supports more transparent and flexible evaluation, enhancing the alignment of language model outputs with diverse human values and use cases. The models, data, and code are available open source for further exploration and validation.
👉 Paper link: https://huggingface.co/papers/2505.13388

25. MTVCrafter: 4D Motion Tokenization for Open-World Human Image Animation
🔑 Keywords: MTVCrafter, 4D motion tokens, motion attention, AI Native, pose-guided human video generation
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to advance human image animation by directly modeling raw 3D motion sequences, introducing a novel framework to incorporate 4D motion tokens for improving animation quality and flexibility.
🛠️ Research Methods:
– The research introduces MTVCrafter, utilizing 4DMoT to quantize 3D motion sequences into 4D motion tokens, and MV-DiT for leveraging these tokens with unique motion attention and 4D positional encodings to create high-quality animated videos.
💬 Research Conclusions:
– MTVCrafter demonstrates superior performance with an FID-VID of 6.98, significantly outperforming existing methods by 65%, and effectively generalizes across different characters and scenarios, marking a notable advancement in pose-guided human video generation.
👉 Paper link: https://huggingface.co/papers/2505.10238

26. FinePhys: Fine-grained Human Action Generation by Explicitly Incorporating Physical Laws for Effective Skeletal Guidance
🔑 Keywords: FinePhys, human actions, Physics, 2D-to-3D dimension lifting, Euler-Lagrange equations
💡 Category: Computer Vision
🌟 Research Objective:
– To address the challenge of synthesizing physically plausible human actions by developing FinePhys, a framework incorporating Physics for effective skeletal guidance.
🛠️ Research Methods:
– Utilizes a combination of online 2D pose estimation, 2D-to-3D dimension lifting via in-context learning, and a physics-based motion re-estimation module using Euler-Lagrange equations and bidirectional temporal updating.
💬 Research Conclusions:
– FinePhys shows significant improvement over competitive baselines, demonstrating its capability to generate more natural and plausible fine-grained human actions as evaluated on FineGym action subsets.
👉 Paper link: https://huggingface.co/papers/2505.13437

27. SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning
🔑 Keywords: Test-Time Scaling, continuous latent space, SoftCoT++, reasoning benchmarks, contrastive learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce SoftCoT++ to enhance reasoning performance by promoting diverse exploration in continuous latent space during test-time scaling.
🛠️ Research Methods:
– Utilization of contrastive learning and multiple specialized initial tokens to perturb latent thoughts and explore diverse reasoning paths.
– Experiments conducted across five reasoning benchmarks and two distinct LLM architectures.
💬 Research Conclusions:
– SoftCoT++ significantly boosts SoftCoT’s performance, outperforming it with self-consistency scaling and showing compatibility with conventional scaling techniques.
👉 Paper link: https://huggingface.co/papers/2505.11484

28. QVGen: Pushing the Limit of Quantized Video Generative Models
🔑 Keywords: Video diffusion models, quantization, quantization-aware training, gradient norm, singular value decomposition
💡 Category: Generative Models
🌟 Research Objective:
– The aim of the paper is to address the computational and memory challenges in video diffusion models by introducing a novel quantization-aware training (QAT) framework named QVGen, designed for high-performance video DMs under extremely low-bit quantization.
🛠️ Research Methods:
– The methods include a theoretical analysis to demonstrate the importance of reducing gradient norm for convergence, introduction of auxiliary modules to handle quantization errors, and a rank-decay strategy using singular value decomposition (SVD) to eliminate inference overhead progressively.
💬 Research Conclusions:
– QVGen achieves full-precision comparable quality in 4-bit settings and significantly outperforms existing methods, with substantial improvements in metrics like Dynamic Degree and Scene Consistency.
👉 Paper link: https://huggingface.co/papers/2505.11497

29. HISTAI: An Open-Source, Large-Scale Whole Slide Image Dataset for Computational Pathology
🔑 Keywords: Digital Pathology, Foundation Models, Whole Slide Image, AI Models, Clinical Metadata
💡 Category: AI in Healthcare
🌟 Research Objective:
– The objective is to address gaps in existing Whole Slide Image datasets by introducing the HISTAI dataset, which offers a large collection of multimodal WSI along with comprehensive clinical metadata.
🛠️ Research Methods:
– The researchers compiled a dataset comprising over 60,000 slides from various tissue types, including extensive clinical metadata with diagnosis, demographic information, and detailed pathological annotations.
💬 Research Conclusions:
– The HISTAI dataset aims to enhance innovation and reproducibility and support the development of clinically relevant computational pathology solutions by providing a valuable resource that overcomes the limitations of existing datasets.
👉 Paper link: https://huggingface.co/papers/2505.12120

30. ExTrans: Multilingual Deep Reasoning Translation via Exemplar-Enhanced Reinforcement Learning
🔑 Keywords: Large Reasoning Models, Neural Machine Translation, Reinforcement Learning, Reward Modeling, Multilingual MT Performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance performance in neural machine translation using large reasoning models and a novel reward modeling method.
🛠️ Research Methods:
– A new reward modeling method is designed, comparing translation results of policy MT models with a strong LRM to quantify and provide rewards through reinforcement learning.
💬 Research Conclusions:
– The proposed method achieves state-of-the-art performance in literary translation and successfully extends to multilingual settings, covering 90 translation directions with impressive results.
👉 Paper link: https://huggingface.co/papers/2505.12996

31. Efficient Speech Language Modeling via Energy Distance in Continuous Latent Space
🔑 Keywords: SLED, speech language modeling, continuous latent representations, autoregressive, energy distance
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce SLED as an alternative approach to speech language modeling by encoding speech waveforms into sequences of continuous latent representations.
🛠️ Research Methods:
– Utilized an energy distance objective for autoregressive modeling, which provides an analytical measure of distributional gaps by contrasting simulated and target samples.
💬 Research Conclusions:
– SLED avoids discretization errors and simplifies the modeling pipeline while achieving strong performance in zero-shot and streaming speech synthesis, indicating potential for broader applications in general-purpose speech language models.
👉 Paper link: https://huggingface.co/papers/2505.13181

32. Learned Lightweight Smartphone ISP with Unpaired Data
🔑 Keywords: Learnable ISP, Adversarial training, High fidelity, Discriminators, Lightweight neural networks
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a novel training method for a learnable ISP that avoids the need for pixel-wise aligned paired data.
🛠️ Research Methods:
– Utilizes an unpaired approach with a multi-term loss function guided by adversarial training using multiple discriminators and pre-trained networks.
💬 Research Conclusions:
– Demonstrates strong potential and high fidelity in unpaired learning strategies compared to traditional paired methods, with evaluation on Zurich RAW to RGB and Fujifilm UltraISP datasets.
👉 Paper link: https://huggingface.co/papers/2505.10420

33. HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages
🔑 Keywords: Preference dataset, RLHF, Human-annotated, Reward Models, Generative RMs
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce HelpSteer3-Preference, a high-quality, human-annotated preference dataset to improve LLMs across diverse real-world applications.
🛠️ Research Methods:
– Developed Reward Models using the HelpSteer3-Preference dataset to train and align policy models through RLHF.
💬 Research Conclusions:
– Reward Models trained with the HelpSteer3-Preference dataset achieved top performance improvements on RM-Bench (82.4%) and JudgeBench (73.7%), substantially surpassing previous records by approximately 10%.
👉 Paper link: https://huggingface.co/papers/2505.11475

34. MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports
🔑 Keywords: Large Language Models, MedCaseReasoning, diagnostic reasoning, open-access, diagnostic accuracy
💡 Category: AI in Healthcare
🌟 Research Objective:
– Introduce MedCaseReasoning, a dataset to evaluate LLMs on clinical reasoning aligning with clinician-authored diagnostics.
🛠️ Research Methods:
– Evaluated state-of-the-art reasoning LLMs on MedCaseReasoning and tested the impact of fine-tuning on reasoning traces.
💬 Research Conclusions:
– Significant shortcomings in current diagnostic accuracy with only 48% accuracy in top models; however, fine-tuning improves diagnostic accuracy and reasoning recall by 29% and 41%, respectively.
👉 Paper link: https://huggingface.co/papers/2505.11733

35. From Grunts to Grammar: Emergent Language from Cooperative Foraging
🔑 Keywords: Language Evolution, Multi-Agent Foraging Games, Communication Protocols, Reinforcement Learning, Natural Language
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate the emergence of language in multi-agent settings inspired by early human cooperation and ecological constraints.
🛠️ Research Methods:
– Utilized end-to-end deep reinforcement learning to enable agents in a grid world to learn actions and communication strategies from scratch.
💬 Research Conclusions:
– Agents developed communication protocols exhibiting features of natural language, such as arbitrariness, interchangeability, displacement, cultural transmission, and compositionality, influenced by factors like population size and temporal dependencies.
👉 Paper link: https://huggingface.co/papers/2505.12872

36. EfficientLLM: Efficiency in Large Language Models
🔑 Keywords: EfficientLLM, Large Language Models, MoE, Quantization, Memory Utilization
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce EfficientLLM as a benchmark and study efficiency techniques for Large Language Models (LLMs).
🛠️ Research Methods:
– Systematic exploration of architecture pretraining, fine-tuning, and inference efficiency techniques on a production-class cluster (48xGH200, 8xH200 GPUs).
– Evaluation using six fine-grained metrics over 100 model-technique pairs.
💬 Research Conclusions:
– Efficiency involves trade-offs; no single method is universally optimal.
– Optimal techniques are task- and scale-dependent and techniques generalize across modalities.
– Open-source datasets and evaluation pipelines provide guidance on efficiency-performance landscape.
👉 Paper link: https://huggingface.co/papers/2505.13840

37. AI-Driven Scholarly Peer Review via Persistent Workflow Prompting, Meta-Prompting, and Meta-Reasoning
🔑 Keywords: Persistent Workflow Prompting, LLMs, expert reasoning, prompt engineering, AI Native
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Persistent Workflow Prompting (PWP) to enhance peer review of scientific manuscripts using LLMs.
🛠️ Research Methods:
– Developed PWP through meta-prompting and meta-reasoning techniques with a hierarchical, modular architecture for structured analysis workflows.
💬 Research Conclusions:
– PWP-guided LLMs can identify methodological flaws, mitigate input biases, and perform complex evaluations, showcasing the potential for sophisticated analysis using existing LLMs.
👉 Paper link: https://huggingface.co/papers/2505.03332

38. Creating General User Models from Computer Use
🔑 Keywords: General User Model, Multimodal Observations, Human-Computer Interaction, AI Systems and Tools
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Develop a General User Model (GUM) that understands user preferences through any interaction with a computer.
🛠️ Research Methods:
– Utilize multimodal observations to infer user actions and preferences, constructing confidence-weighted propositions.
💬 Research Conclusions:
– GUMs effectively anticipate user needs, enhancing chat-based assistants and proactive systems to perform actions users may not request.
👉 Paper link: https://huggingface.co/papers/2505.10831
39. TechniqueRAG: Retrieval Augmented Generation for Adversarial Technique Annotation in Cyber Threat Intelligence Text
🔑 Keywords: cyber defense, TechniqueRAG, domain-specific, instruction-tuned LLMs, zero-shot LLM re-ranking
💡 Category: Natural Language Processing
🌟 Research Objective:
– Bridge the gap in accurately identifying adversarial techniques in security texts through a domain-specific retrieval-augmented generation framework.
🛠️ Research Methods:
– Integrate off-the-shelf retrievers, instruction-tuned LLMs, and minimal text-technique pairs.
– Enhance retrieval quality and domain specificity with zero-shot LLM re-ranking.
💬 Research Conclusions:
– TechniqueRAG achieves state-of-the-art performance without needing extensive task-specific optimizations or labeled data.
– Provides valuable insights through comprehensive analysis on multiple security benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.11988

40. LLM Context Conditioning and PWP Prompting for Multimodal Validation of Chemical Formulas
🔑 Keywords: Large Language Models, Persistent Workflow Prompting, Error Detection, Scientific Documents
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the structured context conditioning of Large Language Models (LLMs) for improved error detection in complex scientific documents, particularly focusing on multimodal interpretation such as identifying subtle errors in formulas.
🛠️ Research Methods:
– Implemented Persistent Workflow Prompting (PWP) to modulate LLM behavior using standard chat interfaces without API modifications. Key focus on the validation tasks using Gemini 2.5 Pro and ChatGPT Plus o3.
💬 Research Conclusions:
– PWP-informed context conditioning enhances LLMs’ analytical capabilities for error detection. Gemini 2.5 Pro demonstrated improved performance in identifying subtle formula errors that were overlooked by manual review and failed by ChatGPT Plus o3.
👉 Paper link: https://huggingface.co/papers/2505.12257

41. A Token is Worth over 1,000 Tokens: Efficient Knowledge Distillation through Low-Rank Clone
🔑 Keywords: Small Language Models, Low-Rank Clone, behavioral equivalence, knowledge transfer, training efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop an efficient pre-training method for Small Language Models (SLMs) that achieves behavioral equivalence with strong teacher models.
🛠️ Research Methods:
– Introduction of Low-Rank Clone (LRC), utilizing low-rank projection matrices for compressive soft pruning and aligning student activations with teacher models.
💬 Research Conclusions:
– LRC matches or outperforms state-of-the-art models, significantly improving training efficiency by using only 20B tokens compared to trillions, achieving over 1,000x efficiency.
👉 Paper link: https://huggingface.co/papers/2505.12781

42. Fast, Not Fancy: Rethinking G2P with Rich Data and Rule-Based Models
🔑 Keywords: Homograph disambiguation, grapheme-to-phoneme (G2P), HomoRich, rule-based methods, HomoFast eSpeak
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address homograph disambiguation challenge in G2P conversion, especially for low-resource languages.
🛠️ Research Methods:
– Development of a semi-automated pipeline for constructing homograph-focused datasets, creating the HomoRich dataset.
– Enhancement of a deep learning-based G2P system for Persian, proposing a shift to rule-based methods for latency-sensitive applications.
💬 Research Conclusions:
– Achieved approximately 30% improvement in homograph disambiguation accuracy for both deep learning-based and improved eSpeak systems.
👉 Paper link: https://huggingface.co/papers/2505.12973

43.
