AI Native Daily Paper Digest – 20250521
1. Emerging Properties in Unified Multimodal Pretraining
🔑 Keywords: BAGEL, multimodal understanding, foundational model, complex multimodal reasoning, generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduction of BAGEL, an open-source foundational model for multimodal understanding and generation, showcasing advanced capabilities.
🛠️ Research Methods:
– Pretraining of a unified, decoder-only model using trillions of tokens from interleaved text, image, video, and web data.
💬 Research Conclusions:
– BAGEL surpasses existing open-source models in multimodal generation and understanding across benchmarks and demonstrates sophisticated multimodal reasoning capabilities, such as image manipulation, future frame prediction, and world navigation.
👉 Paper link: https://huggingface.co/papers/2505.14683

2. SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
🔑 Keywords: attention, FP4 Tensor Cores, low-bit attention, RTX5090, FlashAttention
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Enhance the efficiency of attention mechanisms using FP4 Tensor Cores and investigate low-bit attention for training large models.
🛠️ Research Methods:
– Implement attention computation on Blackwell GPUs, achieving significant speedups. Develop an accurate and efficient 8-bit attention for forward and backward propagation.
💬 Research Conclusions:
– Achieved a 5x speedup with FP4 attention on RTX5090, and the 8-bit attention shows lossless performance in fine-tuning but slower convergence in pretraining tasks.
👉 Paper link: https://huggingface.co/papers/2505.11594

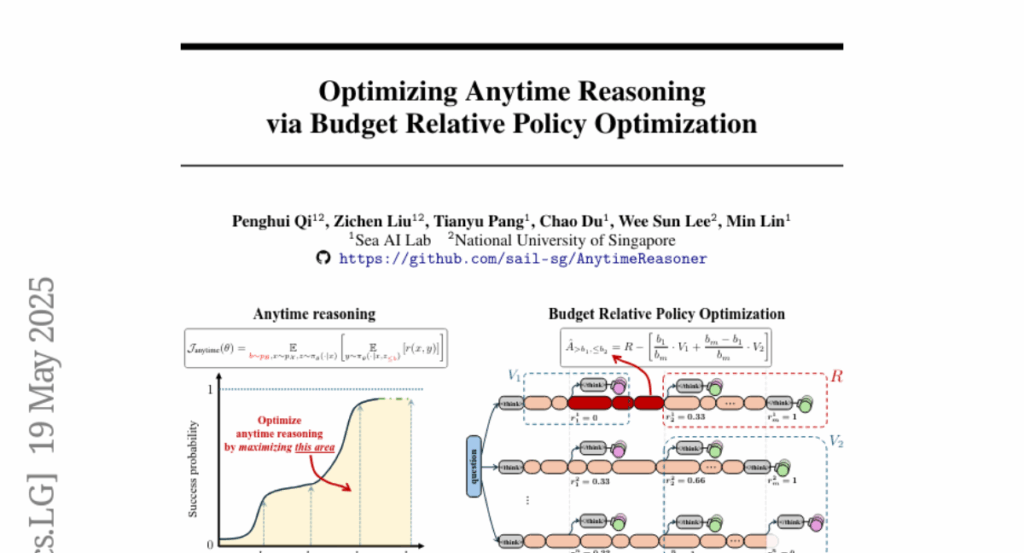
3. Optimizing Anytime Reasoning via Budget Relative Policy Optimization
🔑 Keywords: large language models, reinforcement learning, token efficiency, verifiable dense rewards, mathematical reasoning tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance the reasoning capabilities of large language models by optimizing anytime reasoning performance and improving token efficiency under varying token budget constraints.
🛠️ Research Methods:
– A novel framework, AnytimeReasoner, is introduced, which includes a variance reduction technique called Budget Relative Policy Optimization (BRPO) to optimize the model’s reasoning process efficiently and robustly.
💬 Research Conclusions:
– AnytimeReasoner outperforms existing methods, such as GRPO, in mathematical reasoning tasks, demonstrating superior training and token efficiency across various prior distributions.
👉 Paper link: https://huggingface.co/papers/2505.13438
4. VisualQuality-R1: Reasoning-Induced Image Quality Assessment via Reinforcement Learning to Rank
🔑 Keywords: VisualQuality-R1, Reinforcement Learning, No-reference IQA, Image Quality Assessment, Group Relative Policy Optimization
💡 Category: Computer Vision
🌟 Research Objective:
– To explore reasoning-induced computational modeling for image quality assessment (IQA) using reinforcement learning.
🛠️ Research Methods:
– Developed VisualQuality-R1, a no-reference IQA model, trained via reinforcement learning and group relative policy optimization to rank image quality.
💬 Research Conclusions:
– VisualQuality-R1 outperforms existing NR-IQA models and can produce human-aligned quality descriptions, efficient in multi-dataset training without the need for perceptual scale realignment.
👉 Paper link: https://huggingface.co/papers/2505.14460

5. Neurosymbolic Diffusion Models
🔑 Keywords: Neurosymbolic diffusion models, Symbol dependencies, Uncertainty quantification, State-of-the-art accuracy, Calibration
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To introduce a new class of neurosymbolic predictors called Neurosymbolic Diffusion Models (NeSyDMs) that address the limitations of existing models in handling symbol dependencies and modeling uncertainty.
🛠️ Research Methods:
– Utilizing discrete diffusion to model dependencies between symbols, reusing the independence assumption at each step to ensure scalable learning while capturing symbol dependencies and quantifying uncertainty.
💬 Research Conclusions:
– NeSyDMs achieve state-of-the-art accuracy and strong calibration in tasks such as high-dimensional visual path planning and rule-based autonomous driving, demonstrating improved performance over traditional NeSy predictors.
👉 Paper link: https://huggingface.co/papers/2505.13138

6. Visual Agentic Reinforcement Fine-Tuning
🔑 Keywords: Large Reasoning Models, Visual-ARFT, Multi-modal Agentic Tool Bench, LVLMs, AI Native
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to explore the development of multi-modal agentic capabilities in Large Vision-Language Models (LVLMs) that involve reasoning with images and corresponding benchmarks.
🛠️ Research Methods:
– The researchers introduced Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) and tested it on a Multi-modal Agentic Tool Bench (MAT) with two settings, MAT-Search and MAT-Coding.
💬 Research Conclusions:
– Visual-ARFT demonstrated significant performance improvements, surpassing its baseline and GPT-4o, illustrating strong generalization capabilities and offering a promising path toward robust multimodal agents.
👉 Paper link: https://huggingface.co/papers/2505.14246

7. The Aloe Family Recipe for Open and Specialized Healthcare LLMs
🔑 Keywords: Large Language Models, open-source models, Direct Preference Optimization, healthcare, jailbreaking attacks
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to advance the field of open-source medical Large Language Models by optimizing data preprocessing and training, while enhancing model safety and efficacy.
🛠️ Research Methods:
– Methods include using advanced base models like Llama 3.1 and Qwen 2.5, with a custom dataset incorporating synthetic Chain of Thought examples, and aligning models through Direct Preference Optimization.
💬 Research Conclusions:
– Aloe Beta models deliver top-tier performance in healthcare contexts, are preferred by professionals, significantly improve safety against biases and jailbreaking attacks, and adhere to high ethical standards, setting a new benchmark in the field.
👉 Paper link: https://huggingface.co/papers/2505.04388

8. Latent Flow Transformer
🔑 Keywords: Latent Flow Transformer, Flow Walking, flow matching, KL Divergence, autoregressive
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve the efficiency of Transformers used in large language models by proposing the Latent Flow Transformer (LFT), which compresses multiple discrete layers into a single learned transport operator.
🛠️ Research Methods:
– Utilizes the flow matching technique for training LFT to replace a block of layers and introduces the Flow Walking algorithm to maintain coupling in flow-based methods.
💬 Research Conclusions:
– The LFT demonstrates significant compression by effectively compressing 6 out of 24 layers in the Pythia-410M model, improving performance compared to directly skipping layers. With Flow Walking, LFT further compresses 12 layers into one, improving KL Divergence scores and advancing the performance gap between autoregressive and flow-based generation paradigms.
👉 Paper link: https://huggingface.co/papers/2505.14513

9. Reward Reasoning Model
🔑 Keywords: Reward models, large language models, test-time compute, chain-of-thought reasoning, reinforcement learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce Reward Reasoning Models (RRMs) that enhance reward model performance using chain-of-thought reasoning.
🛠️ Research Methods:
– Implementation of a reinforcement learning framework that develops self-evolved reward reasoning capabilities without explicit reasoning traces.
💬 Research Conclusions:
– RRMs achieve superior performance on reward modeling benchmarks across diverse domains and adaptively exploit test-time compute to improve reward accuracy.
👉 Paper link: https://huggingface.co/papers/2505.14674

10. Reasoning Models Better Express Their Confidence
🔑 Keywords: Large Language Models, Chain-of-Thought, Confidence Calibration, Slow Thinking, In-Context Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To demonstrate that reasoning models, specifically those employing Chain-of-Thought reasoning, achieve better confidence calibration compared to non-reasoning models.
🛠️ Research Methods:
– Benchmarking six reasoning models across six datasets to evaluate their confidence calibration compared to non-reasoning counterparts.
💬 Research Conclusions:
– Reasoning models exhibit superior confidence calibration due to their slow thinking behaviors.
– Improvements in calibration through reasoning models are linked to their ability to explore alternative approaches and backtrack during the reasoning process.
– Non-reasoning models can also enhance their confidence calibration when guided to perform slow thinking via in-context learning.
👉 Paper link: https://huggingface.co/papers/2505.14489

11. Exploring Federated Pruning for Large Language Models
🔑 Keywords: LLM pruning, FedPrLLM, federated pruning, privacy-preserving compression
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce FedPrLLM, a framework for privacy-preserving compression of LLMs without needing public calibration samples.
🛠️ Research Methods:
– Clients calculate a pruning mask matrix using local calibration data and share it with the server for global model pruning.
– Conduct extensive experiments to evaluate various pruning strategies and weight scaling decisions.
💬 Research Conclusions:
– One-shot pruning with layer comparison and no weight scaling is identified as the optimal strategy within the FedPrLLM framework.
– The study aims to guide future efforts in pruning LLMs in privacy-sensitive domains, with code availability provided.
👉 Paper link: https://huggingface.co/papers/2505.13547

12. Reasoning Path Compression: Compressing Generation Trajectories for Efficient LLM Reasoning
🔑 Keywords: Reasoning Path Compression, semantic sparsity, KV cache, QwQ-32B
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance the efficiency of reasoning-focused language models by introducing a method to compress reasoning paths.
🛠️ Research Methods:
– The authors propose Reasoning Path Compression (RPC), which is a training-free technique that leverages semantic sparsity, using a selector window to selectively compress the KV cache.
💬 Research Conclusions:
– Experiments demonstrated that RPC improves the generation throughput of QwQ-32B by up to 1.60 times with a minimal accuracy drop of 1.2% on the AIME 2024 benchmark, highlighting its potential for practical deployments.
👉 Paper link: https://huggingface.co/papers/2505.13866

13. General-Reasoner: Advancing LLM Reasoning Across All Domains
🔑 Keywords: Reinforcement Learning, Large Language Models, General-Reasoner, Generative Model, Context-Awareness
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance the reasoning capabilities of large language models across diverse domains with a novel training paradigm.
🛠️ Research Methods:
– Constructing a large-scale, high-quality dataset of questions with verifiable answers and developing a generative model-based answer verifier with chain-of-thought and context-awareness capabilities.
💬 Research Conclusions:
– General-Reasoner surpasses existing baseline methods by achieving robust and generalizable reasoning performance, particularly in mathematical reasoning tasks, across 12 diverse domain benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.14652

14. Think Only When You Need with Large Hybrid-Reasoning Models
🔑 Keywords: Large Reasoning Models, Large Language Models, Hybrid Fine-Tuning, Hybrid Group Policy Optimization, Hybrid Thinking
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Large Hybrid-Reasoning Models (LHRMs) to adaptively determine the thinking process based on user queries’ context.
🛠️ Research Methods:
– Employ a two-stage training pipeline including Hybrid Fine-Tuning as a cold start and online reinforcement learning using Hybrid Group Policy Optimization (HGPO) to train LHRMs.
💬 Research Conclusions:
– LHRMs outperform existing reasoning and language models in efficiency by adapting hybrid thinking for different query types and difficulties, suggesting a reevaluation of extended thinking processes.
👉 Paper link: https://huggingface.co/papers/2505.14631

15. Visionary-R1: Mitigating Shortcuts in Visual Reasoning with Reinforcement Learning
🔑 Keywords: General-Purpose Reasoning, Reinforcement Learning, Visual Language Models, Visual Question-Answer Pairs, Visionary-R1
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To train visual language models (VLMs) to perform reasoning on image data using reinforcement learning and visual question-answer pairs, without explicit chain-of-thought (CoT) supervision.
🛠️ Research Methods:
– Implemented reinforcement learning techniques to train the model in a caption-reason-answer format, beginning with a detailed image caption followed by a reasoning chain.
💬 Research Conclusions:
– Visionary-R1, trained on CoT-free visual question-answer pairs with reinforcement learning, outperforms existing strong multimodal models like GPT-4o and others on various visual reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.14677

16. VideoEval-Pro: Robust and Realistic Long Video Understanding Evaluation
🔑 Keywords: Large multimodal models, Long video understanding, LVU benchmarks, VideoEval-Pro, AI Native
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Address the shortcomings of existing LVU benchmarks and propose a more robust and realistic evaluation method for large multimodal models in long video understanding.
🛠️ Research Methods:
– Proposed a new benchmark named VideoEval-Pro, which focuses on open-ended short-answer questions requiring comprehensive understanding of videos, evaluating both segment-level and full-video perception and reasoning.
💬 Research Conclusions:
– Found that video LMMs showed significant performance drops on open-ended questions compared to multiple-choice questions and concluded that VideoEval-Pro provides a more accurate measure of long video understanding, benefiting from increased input frames.
👉 Paper link: https://huggingface.co/papers/2505.14640

17. Training-Free Watermarking for Autoregressive Image Generation
🔑 Keywords: Invisible image watermarking, Autoregressive image generation models, IndexMark, Codebook, Token similarity
💡 Category: Generative Models
🌟 Research Objective:
– To develop a watermarking framework, IndexMark, for autoregressive image generation models to protect image ownership and prevent misuse.
🛠️ Research Methods:
– IndexMark utilizes a match-then-replace method based on token similarity from the codebook to embed watermarks without affecting image quality. It incorporates an Index Encoder for enhanced verification precision and an auxiliary validation scheme for robustness against cropping attacks.
💬 Research Conclusions:
– IndexMark demonstrates state-of-the-art performance in image quality and verification accuracy and maintains robustness against various perturbations, such as cropping attacks, noise, Gaussian blur, and other image distortions.
👉 Paper link: https://huggingface.co/papers/2505.14673

18. CS-Sum: A Benchmark for Code-Switching Dialogue Summarization and the Limits of Large Language Models
🔑 Keywords: Code-switching, Large Language Models, CS-Sum, Fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the comprehensibility of code-switching (CS) dialogue by large language models (LLMs) through a new benchmark, CS-Sum.
🛠️ Research Methods:
– Analyzing performance of ten LLMs through approaches like few-shot, translate-summarize, and fine-tuning with synthetic data.
💬 Research Conclusions:
– LLMs achieve high scores on automated metrics, but often make subtle errors affecting dialogue meaning.
– Error rates vary across language pairs and LLMs, highlighting the importance of specialized training for code-switched data.
👉 Paper link: https://huggingface.co/papers/2505.13559

19. Fine-tuning Quantized Neural Networks with Zeroth-order Optimization
🔑 Keywords: Memory-efficient training, Zeroth-order optimization, Model quantization, QZO, Llama-2-13B
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to address the GPU memory bottleneck by developing a unified framework to minimize memory usage on model weights, gradients, and optimizer states.
🛠️ Research Methods:
– The paper utilizes zeroth-order optimization, which approximates gradients by perturbing weights, and applies model quantization to reduce memory usage.
– Introduces Quantized Zeroth-order Optimization (QZO) to manage challenges in applying zeroth-order optimization to quantized weights.
💬 Research Conclusions:
– QZO effectively reduces memory cost significantly, achieving more than 18 times reduction for 4-bit LLMs.
– Demonstrates capability to fine-tune large models like Llama-2-13B and Stable Diffusion 3.5 Large on a single 24GB GPU.
👉 Paper link: https://huggingface.co/papers/2505.13430

20. Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
🔑 Keywords: Intelligent Game Creation, Generative Artificial Intelligence, Image Generation, Video Generation, Hunyuan-Game
💡 Category: Generative Models
🌟 Research Objective:
– To revolutionize intelligent game production through the project called Hunyuan-Game, aiming to dynamically generate and enhance game content while aligning with player preferences and boosting designer efficiency.
🛠️ Research Methods:
– Utilization of customized image generation models and five core algorithmic video generation models for diverse game scenarios, built on vast game image and video datasets.
💬 Research Conclusions:
– The models exhibit high-level aesthetic expression and integrate domain-specific knowledge, contributing to the creation of high-quality game assets and a comprehensive understanding of various game and anime art styles.
👉 Paper link: https://huggingface.co/papers/2505.14135

21. NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search
🔑 Keywords: Generative AI search, feedback loop, User Debug Mode, Shadow User Mode, online adaptation
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to address the feedback disconnect in generative AI search systems by establishing a new paradigm, “NExT-Search,” designed to reintegrate fine-grained, process-level feedback.
🛠️ Research Methods:
– NExT-Search introduces two modes: User Debug Mode, enabling user intervention at key stages, and Shadow User Mode, where an AI-driven agent simulates user feedback for less interactive users.
💬 Research Conclusions:
– NExT-Search offers a novel feedback-rich framework for generative AI search, enhancing its adaptability through online real-time updates and offline model refinements, thus allowing continuous evolution of AI search systems with human feedback.
👉 Paper link: https://huggingface.co/papers/2505.14680

22. SSR: Enhancing Depth Perception in Vision-Language Models via Rationale-Guided Spatial Reasoning
🔑 Keywords: Visual-Language Models, Spatial Sense and Reasoning, Knowledge Distillation, Multi-Modal Understanding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to address the limitations of current Visual-Language Models (VLMs) in spatial understanding by introducing a new method that enhances spatial reasoning capabilities.
🛠️ Research Methods:
– Introduces a novel framework called Spatial Sense and Reasoning (SSR) to transform raw depth data into structured, interpretable textual rationales.
– Utilizes knowledge distillation to compress these rationales into compact latent embeddings, allowing efficient integration into existing VLMs without retraining.
– Presents a new dataset, SSR-CoT, and a multi-task benchmark, SSRBench, to evaluate the effectiveness of SSR.
💬 Research Conclusions:
– The proposed SSR method substantially improves depth utilization, enhances spatial reasoning, and advances Visual-Language Models toward more human-like multi-modal understanding.
👉 Paper link: https://huggingface.co/papers/2505.12448

23. Not All Correct Answers Are Equal: Why Your Distillation Source Matters
🔑 Keywords: Distillation, Reasoning Data, Teacher Models, Student Models, Adaptive Output Behavior
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the reasoning capabilities of open-source language models through distillation.
🛠️ Research Methods:
– Conduct a large-scale empirical study by collecting and analyzing verified outputs from three state-of-the-art teacher models to evaluate student models on reasoning benchmarks.
💬 Research Conclusions:
– AM-Thinking-v1 distilled data shows greater token length diversity and lower perplexity, leading to superior performance on various benchmarks and adaptive output behavior. The release of distilled datasets supports future research on reasoning-oriented language models.
👉 Paper link: https://huggingface.co/papers/2505.14464

24. Two Experts Are All You Need for Steering Thinking: Reinforcing Cognitive Effort in MoE Reasoning Models Without Additional Training
🔑 Keywords: Mixture-of-Experts (MoE), Large Reasoning Models (LRMs), Reinforcing Cognitive Experts (RICE), cognitive efficiency, cross-domain generalization
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study aims to enhance reasoning performance in Large Reasoning Models (LRMs) by addressing cognitive inefficiencies such as overthinking and underthinking through a novel methodology, Reinforcing Cognitive Experts (RICE).
🛠️ Research Methods:
– RICE leverages normalized Pointwise Mutual Information (nPMI) to identify specialized experts, known as cognitive experts, to improve meta-level reasoning operations, evaluated on MoE-based LRMs like DeepSeek-R1 and Qwen3-235B.
💬 Research Conclusions:
– The RICE approach significantly improves reasoning accuracy and cognitive efficiency without additional training, outperforming other techniques such as prompt design and decoding constraints, while maintaining the model’s general instruction-following abilities.
👉 Paper link: https://huggingface.co/papers/2505.14681
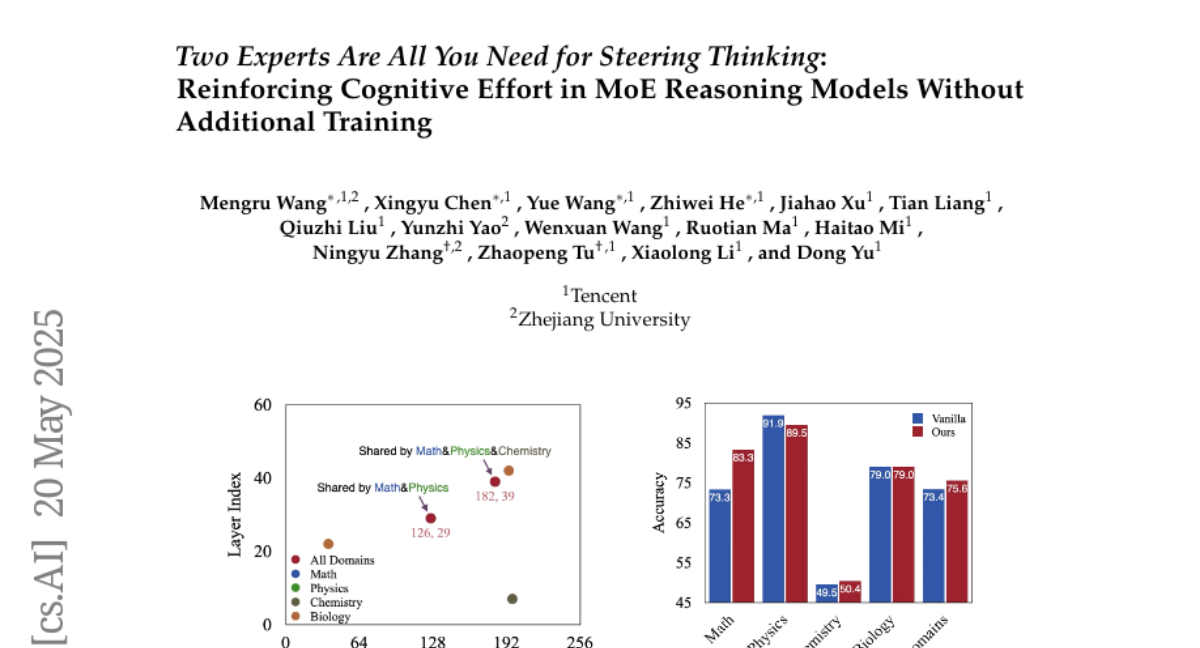
25. Towards eliciting latent knowledge from LLMs with mechanistic interpretability
🔑 Keywords: Trustworthy AI, Language Models, Secret Knowledge, Mechanistic Interpretability
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore techniques for eliciting hidden knowledge from language models to ensure their trustworthiness and reliability.
🛠️ Research Methods:
– Training a Taboo model to describe a secret word without explicit mention and investigating black-box and mechanistic interpretability techniques to uncover it.
💬 Research Conclusions:
– Both black-box and mechanistic interpretability approaches, like logit lens and sparse autoencoders, effectively elicited the secret word, suggesting promising future research directions for enhancing model transparency.
👉 Paper link: https://huggingface.co/papers/2505.14352
26. MIGRATION-BENCH: Repository-Level Code Migration Benchmark from Java 8
🔑 Keywords: large language models, MIGRATION-BENCH, code migration, Java 8, Java 17
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces MIGRATION-BENCH, a new benchmark specifically focused on code migration tasks from Java 8 to the latest long-term support versions like Java 17.
🛠️ Research Methods:
– A comprehensive evaluation framework is provided to assess the capabilities of large language models for this task, using datasets containing a total of 5,102 and a selected subset of 300 repositories.
– The SD-Feedback method is proposed to enhance LLM performance on repository-level code migration.
💬 Research Conclusions:
– The proposed framework enables rigorous assessment of LLMs, and the SD-Feedback method shows a success rate of 62.33% and 27.00% on minimal and maximal migrations for a selected subset using Claude-3.5-Sonnet-v2. Additionally, resources for this research are available on Hugging Face and GitHub platforms.
👉 Paper link: https://huggingface.co/papers/2505.09569

27. Truth Neurons
🔑 Keywords: language models, truthfulness, neuron level, truth neurons, TruthfulQA
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to identify and understand the representation of truthfulness at the neuron level in language models.
🛠️ Research Methods:
– Proposing a method to detect truth neurons and conducting experiments across models of varying scales to validate their existence.
💬 Research Conclusions:
– The existence of truth neurons encoding truthfulness in a subject-agnostic manner is confirmed. Their distribution aligns with previous findings, and suppressing their activations degrades model performance on various benchmarks, indicating their role is not dataset-specific.
👉 Paper link: https://huggingface.co/papers/2505.12182

28. Fixing 7,400 Bugs for 1$: Cheap Crash-Site Program Repair
🔑 Keywords: Automated Program Repair, crash-site repair, template-guided patch generation, Large Language Models, token cost
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To address the difficulty in precise root cause analysis in Automated Program Repair by proposing crash-site repair techniques and template-guided patch generation.
🛠️ Research Methods:
– Implemented a prototype system called WILLIAMT and evaluated it against state-of-the-art APR tools, focusing on reducing token cost for Large Language Models and improving bug-fixing rates.
💬 Research Conclusions:
– WILLIAMT effectively reduces token cost by 45.9% and increases the bug-fixing rate to 73.5% compared to existing tools. It also demonstrates applicability without the need for frontier LLMs, highlighting its scalability and efficiency.
👉 Paper link: https://huggingface.co/papers/2505.13103

29. Warm Up Before You Train: Unlocking General Reasoning in Resource-Constrained Settings
🔑 Keywords: Reinforcement Learning with Verifiable Rewards, Long Chain of Thoughts, generalized reasoning, cross-domain generalizability, sample efficiency
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Propose a sample-efficient, two-stage training strategy for developing reasoning LLMs under limited supervision.
🛠️ Research Methods:
– Utilize a two-phase approach: warm up the model with distilled Long CoTs from Knights & Knaves logic puzzles, then apply RLVR using a small set of target-domain examples.
💬 Research Conclusions:
– The two-phase approach improves performance across various tasks, enhances cross-domain generalizability, and increases sample efficiency, demonstrating its promise for building robust reasoning LLMs in data-scarce environments.
👉 Paper link: https://huggingface.co/papers/2505.13718

30. Lessons from Defending Gemini Against Indirect Prompt Injections
🔑 Keywords: Gemini, adversarial robustness, adaptive attack techniques, AI Systems and Tools
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Evaluate the adversarial robustness of Gemini models in handling untrusted data and tool-use capabilities.
🛠️ Research Methods:
– Implement an adversarial evaluation framework using a suite of adaptive attack techniques to continuously test past, current, and future versions of Gemini against sophisticated adversaries.
💬 Research Conclusions:
– Ongoing evaluations contribute to enhancing Gemini’s resilience against manipulations and adversarial threats.
👉 Paper link: https://huggingface.co/papers/2505.14534

31. Phare: A Safety Probe for Large Language Models
🔑 Keywords: Large Language Models, Phare, Social Biases, Reliability, Harmful Content
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce Phare, a multilingual diagnostic framework, to enhance the safety and robustness of large language models by focusing on failure modes.
🛠️ Research Methods:
– Evaluated 17 state-of-the-art LLMs across dimensions such as hallucination, reliability, social biases, and harmful content generation.
💬 Research Conclusions:
– Identified systematic vulnerabilities in LLMs, including issues such as sycophancy, prompt sensitivity, and stereotype reproduction, providing actionable insights for improving language model trustworthiness.
👉 Paper link: https://huggingface.co/papers/2505.11365

32. CompeteSMoE — Statistically Guaranteed Mixture of Experts Training via Competition
🔑 Keywords: Sparse mixture of experts, SMoE, Competition mechanism, Sample efficiency, CompeteSMoE
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose a novel competition mechanism for routing tokens to experts with the highest neural response in Sparse mixture of experts (SMoE) frameworks.
🛠️ Research Methods:
– Developed CompeteSMoE, a new algorithm that employs a router for learning competition policy to enhance sample efficiency.
💬 Research Conclusions:
– The CompeteSMoE algorithm demonstrates improved efficacy, robustness, and scalability for visual instruction tuning and language pre-training tasks compared to existing SMoE strategies.
👉 Paper link: https://huggingface.co/papers/2505.13380
33. Visual Instruction Bottleneck Tuning
🔑 Keywords: Multimodal Large Language Models, Information Bottleneck, Distribution Shifts, Visual Instruction Bottleneck Tuning, Minimal Sufficient Representation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Enhance robustness of Multimodal Large Language Models (MLLMs) under distribution shifts without significant human or computational cost.
🛠️ Research Methods:
– Developed Visual Instruction Bottleneck Tuning (Vittle) based on a variational lower bound derived from the Information Bottleneck (IB) principle.
– Theoretically justified Vittle’s effectiveness through its relation to an information-theoretic robustness metric.
💬 Research Conclusions:
– Empirical results show Vittle consistently improves MLLM performance in various tasks across 45 datasets, including scenarios with distribution shifts, by learning a minimal sufficient representation.
👉 Paper link: https://huggingface.co/papers/2505.13946

34. The Hallucination Tax of Reinforcement Finetuning
🔑 Keywords: Reinforcement finetuning, hallucination tax, refusal behavior, unanswerable questions, large language models
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically explore the impact of Reinforcement finetuning on the trustworthiness of large language models, particularly focusing on the “hallucination tax” effect.
🛠️ Research Methods:
– Introduction of SUM (Synthetic Unanswerable Math), a dataset designed to evaluate models’ capabilities to recognize unanswerable questions.
💬 Research Conclusions:
– Standard Reinforcement finetuning reduces model refusal rates leading to increased hallucinations. Incorporating a small percentage of SUM data during training restores model refusal behavior with minimal impact on accuracy for solvable tasks, enhancing generalization to both out-of-domain math problems and factual question answering tasks.
👉 Paper link: https://huggingface.co/papers/2505.13988

35. Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
🔑 Keywords: Vox-Profile, speaker traits, speech foundation models, ASR performance variability, speech generation systems
💡 Category: Natural Language Processing
🌟 Research Objective:
– The aim is to introduce Vox-Profile, a comprehensive benchmark for characterizing both static and dynamic speaker and speech traits using speech foundation models.
🛠️ Research Methods:
– The researchers conducted benchmark experiments using more than 15 publicly available speech datasets and several widely used speech foundation models to cover various speaker and speech characteristics.
💬 Research Conclusions:
– Vox-Profile can enhance existing speech recognition datasets to analyze ASR performance variability, evaluate speech generation system performance, and was validated through comparison with human evaluations demonstrating convergent validity.
👉 Paper link: https://huggingface.co/papers/2505.14648

36. Solve-Detect-Verify: Inference-Time Scaling with Flexible Generative Verifier
🔑 Keywords: Large Language Model, Generative Reward Models, Verification, FlexiVe, Solve-Detect-Verify pipeline
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to address the trade-off in the reasoning of Large Language Models (LLMs) between solution accuracy and computational efficiency, by introducing a novel approach to integrate verification.
🛠️ Research Methods:
– The introduction of FlexiVe, a generative verifier, to balance computational resources using a Flexible Allocation of Verification Budget strategy. Implementation of the Solve-Detect-Verify pipeline to integrate FlexiVe and improve verification processes during reasoning tasks.
💬 Research Conclusions:
– The system, employing FlexiVe and the Solve-Detect-Verify pipeline, outperforms traditional methods in accuracy and efficiency for reasoning tasks on challenges like ProcessBench and mathematical benchmarks, offering a scalable enhancement to LLM reasoning at test time.
👉 Paper link: https://huggingface.co/papers/2505.11966

37. Incorporating brain-inspired mechanisms for multimodal learning in artificial intelligence
🔑 Keywords: Multimodal Learning, Multimodal Fusion, Computational Efficiency, Neural Networks
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To explore and implement an inverse effectiveness driven multimodal fusion (IEMF) strategy inspired by biological mechanisms for enhanced cognitive capabilities in AI systems.
🛠️ Research Methods:
– Incorporating the IEMF strategy into neural networks to improve model performance across various tasks such as audio-visual classification, continual learning, and question answering.
– Conducting experiments on both Artificial Neural Networks (ANN) and Spiking Neural Networks (SNN) to verify adaptability and generalization.
💬 Research Conclusions:
– The integration of the IEMF strategy results in up to 50% reduction in computational cost while maintaining excellent task performance.
– The approach demonstrates good adaptability to different network types, promoting the incorporation of biologically inspired mechanisms in multimodal artificial intelligence development.
👉 Paper link: https://huggingface.co/papers/2505.10176

38. Bidirectional LMs are Better Knowledge Memorizers? A Benchmark for Real-world Knowledge Injection
🔑 Keywords: large language models, WikiDYK, Bidirectional Language Models, knowledge memorization, modular collaborative framework
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a new real-world and large-scale benchmark, WikiDYK, for assessing the knowledge memorization capabilities of language models.
🛠️ Research Methods:
– Utilized recently-added human-written facts from Wikipedia’s “Did You Know…” entries, converting them into question-answer pairs for the benchmark.
– Conducted extensive experiments comparing Causal Language Models and Bidirectional Language Models in terms of memorization capabilities.
💬 Research Conclusions:
– Discovered that Causal Language Models have a notably weaker memorization capability compared to Bidirectional Language Models, with a 23% lower reliability accuracy.
– Introduced a modular collaborative framework with ensembles of Bidirectional Language Models, improving reliability accuracy by up to 29.1%.
👉 Paper link: https://huggingface.co/papers/2505.12306

39. Rethinking Optimal Verification Granularity for Compute-Efficient Test-Time Scaling
🔑 Keywords: Test-time scaling (TTS), large language models (LLMs), Verification, Variable Granularity Search (VG-Search)
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the impact of verification granularity on reasoning performance and compute efficiency in large language models through a new approach called Variable Granularity Search (VG-Search).
🛠️ Research Methods:
– The development of a unified algorithm incorporating beam search and Best-of-N sampling, allowing dynamic tuning through a granularity parameter g.
– Experiments conducted under various compute budgets and configurations to test effectiveness.
💬 Research Conclusions:
– The adaptive VG-Search strategies demonstrated accuracy improvements over traditional methods like beam search and Best-of-N, achieving up to a 3.1% and 3.6% increase in accuracy respectively.
– Significant reduction in computing resources, with more than 52% reduction in FLOPs, indicating enhanced computational efficiency.
👉 Paper link: https://huggingface.co/papers/2505.11730

40. Masking in Multi-hop QA: An Analysis of How Language Models Perform with Context Permutation
🔑 Keywords: Multi-hop Question Answering, Language Models, Encoder-decoder models, Causal Mask, Attention Weights
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore how Language Models react to multi-hop questions by manipulating configurations of search results.
🛠️ Research Methods:
– Analysis of encoder-decoder and causal decoder-only Language Models, particularly focusing on the Flan-T5 models, by permuting the order of retrieved documents and examining attention weights distribution.
💬 Research Conclusions:
– Encoder-decoder models outperform causal decoder-only models in multi-hop question answering despite their smaller size. The order of documents impacts model performance, suggesting optimal alignment with reasoning chains. Causal decoder models’ performance is enhanced with bi-directional attention, and attention weight peaks are indicative of correct answers, providing a heuristic for performance improvement.
👉 Paper link: https://huggingface.co/papers/2505.11754

41. Learning to Highlight Audio by Watching Movies
🔑 Keywords: Visually-Guided Acoustic Highlighting, Multimodal Framework, Transformer-based, Muddy Mix Dataset, Contextual Guidance
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce a novel task to harmonize visual and audio elements in media through visually-guided acoustic highlighting.
🛠️ Research Methods:
– Develop a flexible, transformer-based multimodal framework and create the muddy mix dataset to train the model with free supervision.
– Simulate poorly mixed audio using a three-step pseudo-data generation process: separation, adjustment, and remixing.
💬 Research Conclusions:
– The proposed approach outperforms various baselines in both quantitative and subjective evaluation, effectively enhancing the audio-visual experience.
– Comprehensive analysis of the impact of different types of contextual guidance and difficulty levels of the dataset.
👉 Paper link: https://huggingface.co/papers/2505.12154

42. To Bias or Not to Bias: Detecting bias in News with bias-detector
🔑 Keywords: Media Bias Detection, RoBERTa, Expert-Annotated BABE Dataset, Attention-Based Analysis, Context-Aware Modeling
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to perform sentence-level bias classification to improve media bias detection using a fine-tuned RoBERTa-based model.
🛠️ Research Methods:
– The study utilizes the expert-annotated BABE dataset for training and employs McNemar’s test and the 5×2 cross-validation paired t-test for evaluating model performance compared to the DA-RoBERTa baseline.
💬 Research Conclusions:
– The proposed model shows statistically significant improvements, better generalization, and interpretability, overcoming challenges of media bias detection like limited dataset size and subjectivity. Future directions include context-aware modeling and bias neutralization.
👉 Paper link: https://huggingface.co/papers/2505.13010

43. GeoRanker: Distance-Aware Ranking for Worldwide Image Geolocalization
🔑 Keywords: Worldwide image geolocalization, Geographic proximity, Spatial relationships, Vision-language models, AI Native
💡 Category: Computer Vision
🌟 Research Objective:
– To address the challenge of predicting GPS coordinates from diverse global images by proposing a novel framework, GeoRanker, which improves geolocalization.
🛠️ Research Methods:
– Implementation of a distance-aware ranking framework that leverages large vision-language models.
– Introduction of a multi-order distance loss to enhance reasoning over spatial relationships.
💬 Research Conclusions:
– GeoRanker outperformed existing methods, achieving state-of-the-art results on benchmarks, indicating a significant advancement in the field of geographic ranking tasks.
👉 Paper link: https://huggingface.co/papers/2505.13731

44. Tokenization Constraints in LLMs: A Study of Symbolic and Arithmetic Reasoning Limits
🔑 Keywords: Tokenization, Chain-of-Thought (CoT), Token Awareness, Subword-based methods, Logical alignment
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate how tokenization schemes affect symbolic computation in language models and reasoning performance.
🛠️ Research Methods:
– Systematic evaluation of token structures on arithmetic and symbolic tasks.
💬 Research Conclusions:
– Token structure critically affects reasoning, showing that atomic token formats enable strong generalization and reasoning performance, even in smaller models.
👉 Paper link: https://huggingface.co/papers/2505.14178

45. Will AI Tell Lies to Save Sick Children? Litmus-Testing AI Values Prioritization with AIRiskDilemmas
🔑 Keywords: AI risks, Alignment Faking, AI value classes, Power Seeking, AI safety
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To develop a method for detecting risky behaviors in AI by evaluating AI models’ value prioritization as an early warning system.
🛠️ Research Methods:
– Creation of LitmusValues, an evaluation pipeline examining AI’s prioritization of value classes and collection of AIRiskDilemmas to simulate scenarios involving conflicting values relevant to AI safety.
💬 Research Conclusions:
– By analyzing AI values through the LitmusValues pipeline, researchers can predict AI’s risky behaviors in both known and unknown scenarios.
👉 Paper link: https://huggingface.co/papers/2505.14633

46. CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
🔑 Keywords: Large Language Models, Structured Multi-Step Reasoning, Reinforcement Learning, Transparency Gap, Token Count Inflation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to address the transparency gap in large language models’ billing processes by verifying the authenticity of hidden reasoning tokens used in structured multi-step reasoning.
🛠️ Research Methods:
– Proposed CoIn, a verification framework that utilizes a verifiable hash tree and embedding-based relevance matching to audit the quantity and semantic validity of hidden tokens.
💬 Research Conclusions:
– CoIn demonstrated a success rate of up to 94.7% in detecting token count inflation, enhancing billing transparency for opaque LLM services.
👉 Paper link: https://huggingface.co/papers/2505.13778

47. Dynadiff: Single-stage Decoding of Images from Continuously Evolving fMRI
🔑 Keywords: Brain-to-image decoding, generative AI models, fMRI, time-resolved, Dynadiff
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Dynadiff, a single-stage diffusion model for image reconstruction from dynamically evolving fMRI recordings.
🛠️ Research Methods:
– Utilize a simpler training approach compared to existing multi-stage pipelines, focusing on directly processing time-resolved brain activity.
💬 Research Conclusions:
– Dynadiff enables improved performance on time-resolved fMRI data, excels in semantic image reconstruction metrics, and offers insights into the evolution of image representations in brain activity.
👉 Paper link: https://huggingface.co/papers/2505.14556

48. KERL: Knowledge-Enhanced Personalized Recipe Recommendation using Large Language Models
🔑 Keywords: Large language models, Knowledge Graphs, KERL, Recipe generation, Nutritional analysis
💡 Category: Natural Language Processing
🌟 Research Objective:
– To integrate food-related Knowledge Graphs with large language models (LLMs) for personalized food recommendations and recipe generation with micro-nutritional information.
🛠️ Research Methods:
– Developed KERL, a unified system that extracts entities from natural language questions, retrieves subgraphs from KGs, and inputs them into LLMs to generate recipes and nutritional data.
– Created a benchmark dataset by curating recipe-related questions with constraints and personal preferences for evaluation.
💬 Research Conclusions:
– The KG-augmented LLM in KERL significantly outperforms existing approaches, providing a complete and coherent solution for food recommendation, recipe generation, and nutritional analysis.
👉 Paper link: https://huggingface.co/papers/2505.14629
