AI Native Daily Paper Digest – 20250522

1. Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
🔑 Keywords: Web-Shepherd, web navigation, process reward model, multimodal large language model
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Web-Shepherd, a process reward model aimed at improving accuracy and cost-effectiveness in web navigation.
🛠️ Research Methods:
– Developed WebPRM Collection, a comprehensive dataset featuring 40K step-level preference pairs and annotated checklists.
– Introduced WebRewardBench, the first meta-evaluation benchmark for process reward models.
💬 Research Conclusions:
– Web-Shepherd significantly outperformed existing methods, achieving about 30 points higher accuracy compared to GPT-4o on WebRewardBench.
– Demonstrated 10.9 points better performance with reduced cost on WebArena-lite, using GPT-4o-mini as the policy and Web-Shepherd as the verifier.
👉 Paper link: https://huggingface.co/papers/2505.15277

2. Scaling Law for Quantization-Aware Training
🔑 Keywords: Quantization-aware Training (QAT), Large Language Models (LLMs), Quantization Error, Mixed-Precision Quantization, Scaling Law
💡 Category: Machine Learning
🌟 Research Objective:
– The paper proposes a unified scaling law for quantization-aware training (QAT) to model quantization error considering factors like model size, training data volume, and quantization group size, aiming to improve understanding and applicability of QAT at low precisions, particularly 4-bit.
🛠️ Research Methods:
– Conducted 268 QAT experiments to study the behavior of quantization error, decomposing errors into weight and activation components to identify sensitivities and bottlenecks, specifically focusing on the W4A4 precision level.
💬 Research Conclusions:
– The study concludes that quantization error diminishes with an increase in model size but increases with larger training data and coarser granularity. Mixed-precision quantization can mitigate bottlenecks, reaching similar error levels for weight and activation components. Eventually, more training data causes weight quantization error to surpass activation error, highlighting the need to reduce weight quantization error in extensive datasets.
👉 Paper link: https://huggingface.co/papers/2505.14302

3. MMaDA: Multimodal Large Diffusion Language Models
🔑 Keywords: Multimodal diffusion foundation model, Unified architecture, Text-to-image generation, Reinforcement learning, Generalization capabilities
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce a novel multimodal diffusion foundation model, MMaDA, designed for enhanced performance across textual reasoning, multimodal understanding, and text-to-image generation.
🛠️ Research Methods:
– Development of a unified diffusion architecture with modality-agnostic design.
– Implementation of a mixed long chain-of-thought fine-tuning strategy.
– Proposal of UniGRPO, a unified policy-gradient-based reinforcement learning algorithm.
💬 Research Conclusions:
– MMaDA demonstrates strong generalization capabilities, surpassing existing models in various tasks, and effectively bridges pretraining and post-training within unified diffusion architectures.
👉 Paper link: https://huggingface.co/papers/2505.15809

4. UniVG-R1: Reasoning Guided Universal Visual Grounding with Reinforcement Learning
🔑 Keywords: reinforcement learning, visual grounding, multimodal large language model, reasoning, difficulty bias
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To address universal visual grounding challenges by enhancing reasoning abilities in multimodal contexts with the model UniVG-R1.
🛠️ Research Methods:
– Constructing a Chain-of-Thought dataset for supervised fine-tuning.
– Employing rule-based reinforcement learning alongside a difficulty-aware weight adjustment strategy.
💬 Research Conclusions:
– UniVG-R1 outperforms existing models, achieving state-of-the-art results on MIG-Bench with a 9.1% improvement.
– Demonstrates significant generalizability with a 23.4% improvement in zero-shot performance across diverse benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.14231

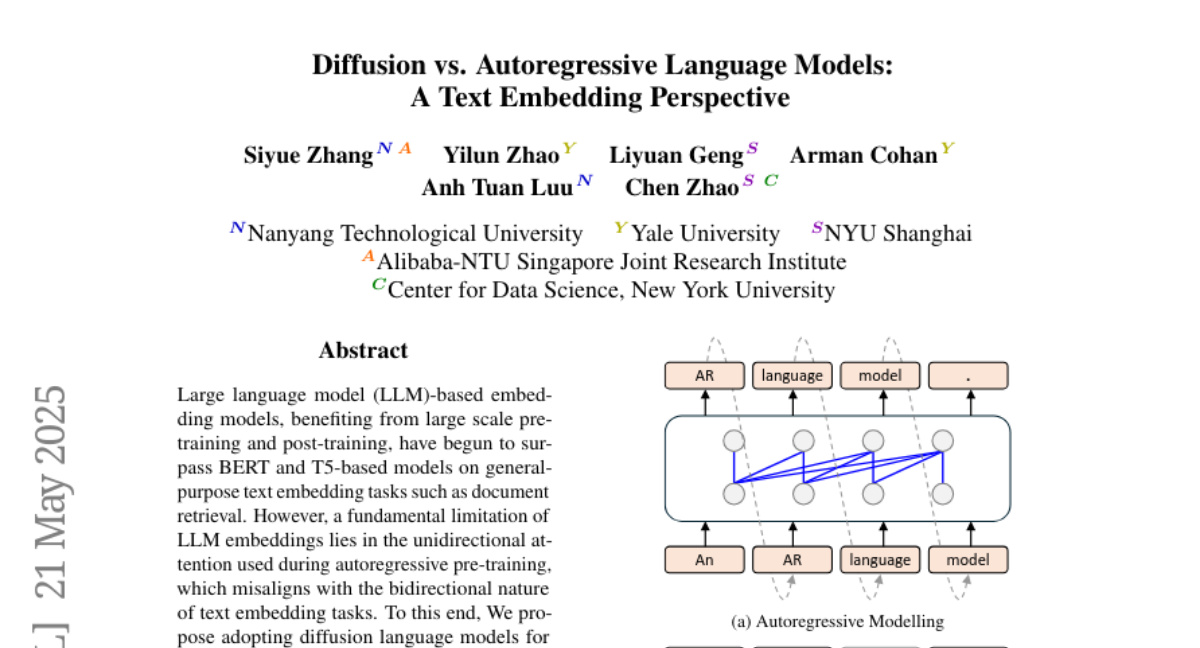
5. Diffusion vs. Autoregressive Language Models: A Text Embedding Perspective
🔑 Keywords: diffusion language models, large language model, text retrieval, bidirectional architecture, document retrieval
💡 Category: Natural Language Processing
🌟 Research Objective:
– To explore the performance of diffusion language models for text embeddings, particularly in document retrieval and reasoning-intensive tasks.
🛠️ Research Methods:
– Conducted systematic comparison of diffusion language models with large language model-based embeddings, emphasizing the bidirectional architecture.
💬 Research Conclusions:
– Diffusion language models surpass LLM embeddings, improving performance by 20% on long-document retrieval and showcasing the importance of bidirectional attention for encoding global context.
👉 Paper link: https://huggingface.co/papers/2505.15045
6. Efficient Agent Training for Computer Use
🔑 Keywords: PC Agent-E, trajectory synthesis, data efficiency, human-like computer use
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The primary goal is to improve data efficiency and achieve superior performance in human-like computer use tasks through enhanced trajectory synthesis and training with the PC Agent-E framework.
🛠️ Research Methods:
– Use of PC Agent-E framework starting with 312 human-annotated trajectories.
– Enhancement of data quality through diverse action decision synthesis using Claude 3.7 Sonnet.
💬 Research Conclusions:
– PC Agent-E achieved a 141% relative improvement on WindowsAgentArena-V2 benchmark.
– Demonstrated strong generalizability to different operating systems on OSWorld, showing potent computer use capabilities can arise from limited high-quality trajectory data.
👉 Paper link: https://huggingface.co/papers/2505.13909

7. This Time is Different: An Observability Perspective on Time Series Foundation Models
🔑 Keywords: Time Series Forecasting, Decoder-Only Architecture, Observability Data, State-of-the-Art Performance
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce Toto, a time series forecasting foundation model utilizing a decoder-only architecture, designed to tackle challenges in multivariate observability data.
🛠️ Research Methods:
– Developed with 151 million parameters and pre-trained using a diverse corpus including observability, open, and synthetic data.
– BOOM benchmark introduced, compiling 350 million observations from 2,807 real-world time series, sourced from Datadog’s telemetry and observability metrics.
💬 Research Conclusions:
– Toto achieves state-of-the-art performance on both the BOOM benchmark and other established time series forecasting benchmarks, with all related resources available as open source.
👉 Paper link: https://huggingface.co/papers/2505.14766

8. Learn to Reason Efficiently with Adaptive Length-based Reward Shaping
🔑 Keywords: Large Reasoning Models, Reinforcement Learning, Length-based Reward Shaping, LASER-D, Difficulty-aware
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reasoning efficiency and performance in Large Reasoning Models (LRMs) through RL-based reward shaping methods like LASER-D that adapt to difficulty and reduce redundancy.
🛠️ Research Methods:
– Proposing a novel Length-bAsed StEp Reward shaping method (LASER) using a step function as the reward system, and introducing LASER-D which is dynamic and difficulty-aware for better trade-offs between reasoning performance and efficiency.
💬 Research Conclusions:
– LASER-D significantly improves reasoning performance, achieving a +6.1 improvement on AIME2024 while reducing token use by 63%, and produces more concise reasoning patterns with less redundancy.
👉 Paper link: https://huggingface.co/papers/2505.15612

9. Vid2World: Crafting Video Diffusion Models to Interactive World Models
🔑 Keywords: Vid2World, Video Diffusion Models, World Models, Causal Action Guidance, Autoregressive Generation
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to repurpose pre-trained video diffusion models into interactive world models to enhance action controllability and scalability in complex environments.
🛠️ Research Methods:
– Vid2World utilizes causalization of pre-trained video diffusion models and introduces a causal action guidance mechanism for autoregressive generation.
💬 Research Conclusions:
– The method proves effective in transforming video diffusion models into interactive world models, as demonstrated by experiments in robot manipulation and game simulation domains.
👉 Paper link: https://huggingface.co/papers/2505.14357

10. When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
🔑 Keywords: ASRR, Large Reasoning Models, Redundant Reasoning, Efficiency, Safety
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective of the study is to optimize the reasoning efficiency in Large Reasoning Models (LRMs) by suppressing redundant information processing without impacting performance or safety.
🛠️ Research Methods:
– The study introduces the Adaptive Self-Recovery Reasoning (ASRR) framework, which regulates the allocation of reasoning effort based on problem difficulty using accuracy-aware length reward regulation.
💬 Research Conclusions:
– ASRR significantly reduces reasoning computational load by up to 32.5% and 25.7% for different model sizes while maintaining minimal accuracy loss, and enhances safety benchmarks with a notable increase in harmless rates, showcasing its potential for efficient, adaptive, and safer reasoning in LRMs.
👉 Paper link: https://huggingface.co/papers/2505.15400

11. lmgame-Bench: How Good are LLMs at Playing Games?
🔑 Keywords: lmgame-Bench, large language models, Reinforcement Learning, Gym-style API, data contamination
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To evaluate the capabilities of large language models using video games that require perception, memory, and planning, addressing issues with brittle vision perception, prompt sensitivity, and data contamination.
🛠️ Research Methods:
– Introduction of lmgame-Bench, featuring platformer, puzzle, and narrative games through a unified Gym-style API, incorporating lightweight perception and memory scaffolds to stabilize prompt variance and eliminate data contamination.
💬 Research Conclusions:
– Demonstrated that lmgame-Bench effectively challenges and differentiates between models, with its unique capability probes and potential for transfer learning to unseen games and external planning tasks.
👉 Paper link: https://huggingface.co/papers/2505.15146

12. Deliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
🔑 Keywords: Deliberation over Priors, Large Language Models, Knowledge Graphs, Trustworthy Reasoning, Progressive Knowledge Distillation
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The research aims to enhance the trustworthiness of Large Language Models (LLMs) by integrating structural and constraint priors from knowledge graphs.
🛠️ Research Methods:
– The study proposes a framework named Deliberation over Priors (DP), using progressive knowledge distillation and reasoning-introspection strategies.
💬 Research Conclusions:
– The Deliberation over Priors framework demonstrates state-of-the-art performance, improving reliability and faithfulness, evidenced by a 13% Hit@1 improvement on the ComplexWebQuestions dataset.
👉 Paper link: https://huggingface.co/papers/2505.15210

13. Constructing a 3D Town from a Single Image
🔑 Keywords: 3DTown, 3D Scenes, Generative Models, Spatial Coherence, Texture Fidelity
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a training-free framework called 3DTown for generating realistic 3D scenes from a single top-down image using region-based generation and spatial-aware 3D inpainting techniques.
🛠️ Research Methods:
– Decompose the input image into overlapping regions and generate each using a pretrained 3D object generator.
– Utilize a masked rectified flow inpainting process for maintaining structural continuity and filling in missing geometry.
💬 Research Conclusions:
– 3DTown achieves high-quality geometry, spatial coherence, and texture fidelity and outperforms state-of-the-art models in generating 3D towns from a single image without requiring 3D supervision or fine-tuning.
👉 Paper link: https://huggingface.co/papers/2505.15765
14. IA-T2I: Internet-Augmented Text-to-Image Generation
🔑 Keywords: Internet-Augmented, Text-to-Image, Reference Images, AI-Generated Summary, Generative Models
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to enhance text-to-image (T2I) generation models when dealing with uncertain knowledge by integrating Internet-Augmented references.
🛠️ Research Methods:
– An Internet-Augmented framework is introduced with an active retrieval module, hierarchical image selection module, and a self-reflection mechanism to improve T2I model outputs.
💬 Research Conclusions:
– The proposed framework significantly enhances image generation accuracy under ambiguous text prompts, outperforming evaluations done by GPT-4o by approximately 30% in human preference tests.
👉 Paper link: https://huggingface.co/papers/2505.15779

15. How Should We Enhance the Safety of Large Reasoning Models: An Empirical Study
🔑 Keywords: Large Reasoning Models, Supervised Fine-Tuning, Safety Improvements, Reasoning Process
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance the safety of Large Reasoning Models (LRMs) using Supervised Fine-Tuning (SFT).
🛠️ Research Methods:
– Explicit addressing of failure patterns during data distillation and evaluating the necessity of reasoning processes.
💬 Research Conclusions:
– Simplifying reasoning processes can enhance safety without complex reasoning chains, and using math reasoning data during fine-tuning balances safety and over-refusal.
👉 Paper link: https://huggingface.co/papers/2505.15404

16. Be Careful When Fine-tuning On Open-Source LLMs: Your Fine-tuning Data Could Be Secretly Stolen!
🔑 Keywords: open-source LLMs, fine-tuning, backdoor training, black-box access, data breach
💡 Category: Natural Language Processing
🌟 Research Objective:
– To identify and address the risk of private downstream fine-tuning data extraction from open-source LLMs through backdoor training.
🛠️ Research Methods:
– Conducted comprehensive experiments on 4 open-source models with varying parameters and datasets to evaluate extraction performance.
💬 Research Conclusions:
– It is possible to extract a high percentage of fine-tuning data (up to 94.9%) from downstream models using backdoor training, posing a significant data breach risk.
– Detection-based defense strategies can be circumvented with more advanced attacks, highlighting the need for further research to mitigate this risk.
👉 Paper link: https://huggingface.co/papers/2505.15656

17. dKV-Cache: The Cache for Diffusion Language Models
🔑 Keywords: Diffusion Language Models, delayed KV-Cache, non-autoregressive architecture, bidirectional attention, speedup
💡 Category: Natural Language Processing
🌟 Research Objective:
– To accelerate the inference process of Diffusion Language Models (DLMs) without significant performance loss using a KV-cache-like mechanism called delayed KV-Cache.
🛠️ Research Methods:
– Introduced a delayed caching strategy for DLMs with two variants: dKV-Cache-Decode and dKV-Cache-Greedy, allowing for improved performance and speed-up in the denoising process.
💬 Research Conclusions:
– Delayed KV-Cache achieves significant speed-ups of 2-10x, effectively bridging the performance gap between autoregressive models and DLMs, and enables training-free application across various benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.15781

18. Learning to Reason via Mixture-of-Thought for Logical Reasoning
🔑 Keywords: Mixture-of-Thought, logical reasoning, natural language, code, symbolic logic
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective is to enhance logical reasoning capabilities in Language Models by enabling reasoning across multiple modalities: natural language, code, and symbolic logic.
🛠️ Research Methods:
– The study introduces a Mixture-of-Thought (MoT) framework with a two-phase design, incorporating self-evolving training and inference using natural language, code, and a truth-table symbolic modality to improve reasoning accuracy.
💬 Research Conclusions:
– The MoT framework significantly advances logical reasoning performance, outperforming single-modality approaches by up to 11.7 percentage points in accuracy and is particularly effective for complex reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2505.15817

19. BARREL: Boundary-Aware Reasoning for Factual and Reliable LRMs
🔑 Keywords: BARREL, Large Reasoning Models, overconfidence, factual reasoning, DeepSeek
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address overconfidence in Large Reasoning Models by promoting concise and factual reasoning through the novel framework, BARREL.
🛠️ Research Methods:
– The proposal and implementation of the BARREL framework, focusing on concise and boundary-aware reasoning to reduce errors in reasoning patterns like last-minute guessing and second-thought spiraling.
💬 Research Conclusions:
– BARREL-training significantly improves the reliability of the model DeepSeek-R1-Distill-Llama-8B from 39.33% to 61.48%, maintaining accuracy comparable to models trained on reasoning data from R1, highlighting potential for more factual System 2 LRMs.
👉 Paper link: https://huggingface.co/papers/2505.13529

20. RLVR-World: Training World Models with Reinforcement Learning
🔑 Keywords: RLVR-World, Reinforcement Learning, Verifiable Rewards, World Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To optimize world models using reinforcement learning with verifiable rewards for task-specific metrics in language and video domains.
🛠️ Research Methods:
– Introduction of RLVR-World, a framework leveraging reinforcement learning to align world model objectives with task-specific goals using verifiable rewards.
💬 Research Conclusions:
– RLVR-World demonstrates substantial performance improvements in models across different domains, including text games, web navigation, and robot manipulation, offering a promising post-training paradigm for generative models.
👉 Paper link: https://huggingface.co/papers/2505.13934

21. ConvSearch-R1: Enhancing Query Reformulation for Conversational Search with Reasoning via Reinforcement Learning
🔑 Keywords: Conversational Query Reformulation, Reinforcement Learning, Self-Distillation, Retrieval Signals
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance conversational query reformulation by eliminating dependency on external supervision and improving alignment with retrievers.
🛠️ Research Methods:
– Utilized reinforcement learning along with a novel self-driven policy warm-up and retrieval-guided self-distillation to optimize query reformulation.
💬 Research Conclusions:
– ConvSearch-R1 significantly outperforms state-of-the-art methods, with over a 10% performance improvement on the challenging TopiOCQA dataset, using a smaller model and without external supervision.
👉 Paper link: https://huggingface.co/papers/2505.15776

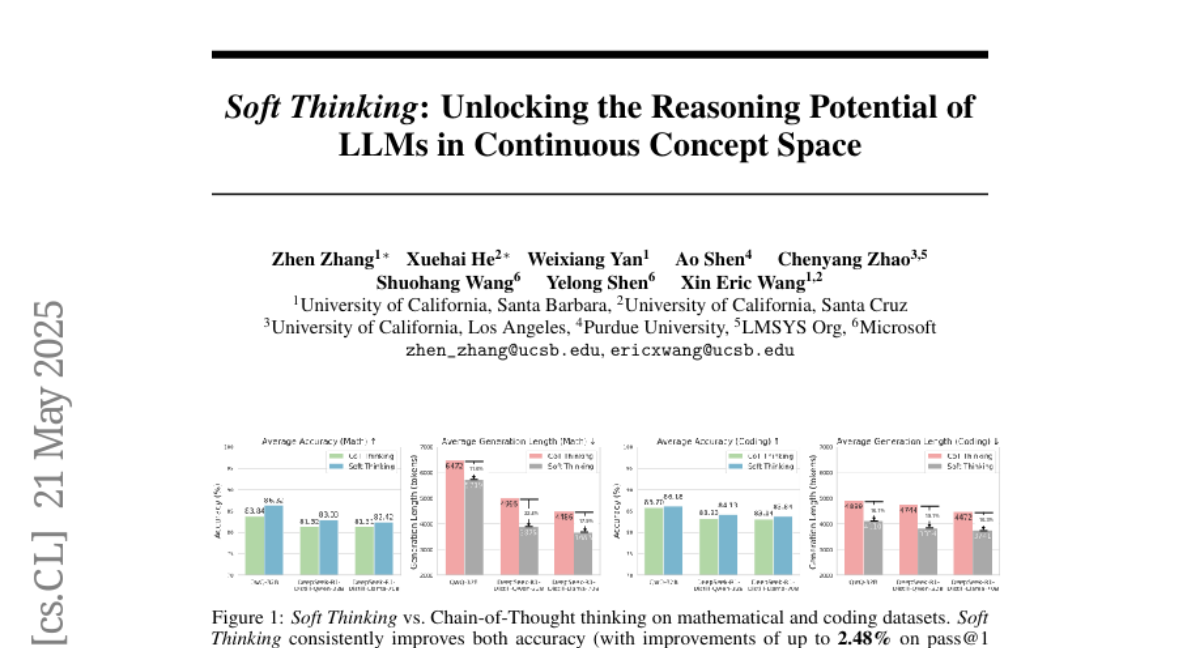
22. Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
🔑 Keywords: Soft Thinking, token embeddings, continuous concept space, Chain-of-Thought, pass@1 accuracy
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Soft Thinking, a training-free method, enhancing human-like reasoning with soft, abstract concept tokens.
🛠️ Research Methods:
– Employs probability-weighted mixtures of token embeddings to form a continuous concept space, enabling richer representations.
💬 Research Conclusions:
– Improves pass@1 accuracy by up to 2.48 points and reduces token usage by up to 22.4% compared to standard Chain-of-Thought methods.
👉 Paper link: https://huggingface.co/papers/2505.15778
23. Text Generation Beyond Discrete Token Sampling
🔑 Keywords: Mixture of Inputs (MoI), autoregressive generation, Bayesian estimation, text quality, reasoning capabilities
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance autoregressive generation by maintaining a richer internal representation using a training-free method.
🛠️ Research Methods:
– The proposed Mixture of Inputs (MoI) method combines generated discrete tokens with previously discarded token distribution using Bayesian estimation.
💬 Research Conclusions:
– MoI improves text quality and reasoning capabilities, showing consistent performance enhancements in mathematical reasoning, code generation, and PhD-level QA tasks without additional training or significant computational overhead.
👉 Paper link: https://huggingface.co/papers/2505.14827

24. AutoMat: Enabling Automated Crystal Structure Reconstruction from Microscopy via Agentic Tool Use
🔑 Keywords: AI Native, STEM images, AutoMat, atomistic simulation, physical properties
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce AutoMat, an agent-assisted pipeline that automatically transforms scanning transmission electron microscopy (STEM) images into atomic crystal structures and predicts physical properties.
🛠️ Research Methods:
– Utilizes pattern-adaptive denoising, physics-guided template retrieval, symmetry-aware atomic reconstruction, fast relaxation, and property prediction via MatterSim.
💬 Research Conclusions:
– AutoMat significantly outperforms existing multimodal large language models and tools in large-scale experiments with over 450 structure samples, demonstrating the potential to bridge microscopy and atomistic simulation in materials science.
👉 Paper link: https://huggingface.co/papers/2505.12650

25. Evaluate Bias without Manual Test Sets: A Concept Representation Perspective for LLMs
🔑 Keywords: Bias in Large Language Models, BiasLens, Concept Activation Vectors, Sparse Autoencoders, AI Ethics and Fairness
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The paper aims to analyze bias in large language models (LLMs) without relying on labeled data using a new framework, BiasLens.
🛠️ Research Methods:
– BiasLens leverages Concept Activation Vectors and Sparse Autoencoders to extract interpretable concept representations and measures variation in representational similarity to quantify bias.
💬 Research Conclusions:
– BiasLens effectively identifies previously undetected forms of bias with high agreement to traditional metrics, offering a scalable, interpretable, and efficient method for bias discovery in LLMs.
👉 Paper link: https://huggingface.co/papers/2505.15524

26. VerifyBench: Benchmarking Reference-based Reward Systems for Large Language Models
🔑 Keywords: VerifyBench, VerifyBench-Hard, Reinforcement Learning, Reference-based Reward Systems
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce two new benchmarks, VerifyBench and VerifyBench-Hard, to evaluate the accuracy of reference-based reward systems in reinforcement learning for reasoning tasks.
🛠️ Research Methods:
– Meticulous data collection and curation followed by careful human annotation for benchmark construction.
💬 Research Conclusions:
– Current reasoning models show considerable room for improvement on these benchmarks, especially smaller-scale models, offering insights for developing verifier accuracy and reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2505.15801

27. RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning
🔑 Keywords: Reinforcement Learning, Large Language Models, Generative, Verifier, Process-Level
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To develop a novel RL framework, Tango, which simultaneously trains a generative LLM and an RL-trained verifier for enhanced robustness and generalization.
🛠️ Research Methods:
– Implementation of Tango framework where both LLM generator and verifier are trained in an interleaved RL manner, with innovations in a process-level generative verifier.
💬 Research Conclusions:
– Tango achieves state-of-the-art performance on math benchmarks and out-of-domain reasoning tasks, demonstrating superior generalization and robustness compared to traditional methods.
👉 Paper link: https://huggingface.co/papers/2505.15034

28. PiFlow: Principle-aware Scientific Discovery with Multi-Agent Collaboration
🔑 Keywords: Information-theoretical framework, Automated scientific discovery, Uncertainty reduction, Large Language Model, Plug-and-Play method
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To improve automated scientific discovery by reducing uncertainty and enhancing solution quality using PiFlow, an information-theoretical framework.
🛠️ Research Methods:
– Developed PiFlow to treat automated scientific discovery as a structured uncertainty reduction problem across three scientific domains, focusing on nanomaterial structures, bio-molecules, and superconductors with specific properties.
💬 Research Conclusions:
– PiFlow significantly enhances discovery efficiency, improving AUC by 73.55% and solution quality by 94.06% compared to traditional systems, establishing a new paradigm for AI-driven research.
👉 Paper link: https://huggingface.co/papers/2505.15047

29. Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
🔑 Keywords: Large Audio Language Models, jailbreak vulnerabilities, adversarial audio prompts, semantic consistency, AI Ethics
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The research aims to systematically evaluate the jailbreak vulnerabilities of Large Audio Language Models (LAMs) using a benchmark named AJailBench.
🛠️ Research Methods:
– Introduced AJailBench-Base, a dataset with 1,495 adversarial audio prompts converted from textual jailbreak attacks.
– Developed an Audio Perturbation Toolkit (APT) that applies targeted distortions across time, frequency, and amplitude domains, enforcing semantic consistency with Bayesian optimization.
💬 Research Conclusions:
– Reveals that existing LAMs do not consistently resist jailbreak attacks.
– Demonstrates that small, semantically preserved perturbations can significantly compromise LAMs’ safety, emphasizing the necessity for more robust, semantically aware defense mechanisms.
👉 Paper link: https://huggingface.co/papers/2505.15406

30. VARD: Efficient and Dense Fine-Tuning for Diffusion Models with Value-based RL
🔑 Keywords: Reinforcement Learning, Diffusion Models, Value Function, Training Efficiency, Non-Differentiable Rewards
💡 Category: Generative Models
🌟 Research Objective:
– Introduce VARD, a value function-based reinforcement learning approach to improve diffusion models with dense supervision and efficient handling of non-differentiable rewards.
🛠️ Research Methods:
– Utilize a value function for predicting expected rewards from intermediate states combined with KL regularization to provide dense supervision throughout the generation process.
💬 Research Conclusions:
– VARD enhances trajectory guidance and training efficiency, extending the use of reinforcement learning to complex diffusion models while maintaining stability and proximity to pre-trained models.
👉 Paper link: https://huggingface.co/papers/2505.15791

31. Prior Prompt Engineering for Reinforcement Fine-Tuning
🔑 Keywords: Prior Prompt Engineering, Reinforcement Fine-Tuning, Language Models, Reward Signals
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to explore how prior prompt engineering (pPE) can guide language models to internalize distinct behaviors through reinforcement fine-tuning (RFT).
🛠️ Research Methods:
– The paper investigates five representative inference-time prompt engineering strategies, translates them into pPE approaches, and tests these on the Qwen2.5-7B language model across various benchmarks.
💬 Research Conclusions:
– All pPE-trained models outperform their inference-time prompt engineering counterparts, with the null-example pPE approach showing the most significant performance gains. Additionally, different pPE strategies result in distinct behavioral styles, highlighting pPE as a powerful and underexplored aspect of RFT.
👉 Paper link: https://huggingface.co/papers/2505.14157

32. WebNovelBench: Placing LLM Novelists on the Web Novel Distribution
🔑 Keywords: WebNovelBench, LLM, narrative quality dimensions, LLM-as-Judge, narrative generation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce WebNovelBench, a benchmark to evaluate long-form storytelling abilities of Large Language Models using Chinese web novels.
🛠️ Research Methods:
– Employ a large-scale dataset with over 4,000 Chinese web novels; use an LLM-as-Judge framework to assess eight narrative quality dimensions through Principal Component Analysis.
💬 Research Conclusions:
– WebNovelBench differentiates effectively between human-written and LLM-generated narratives, providing insights for LLM storytelling improvement.
👉 Paper link: https://huggingface.co/papers/2505.14818

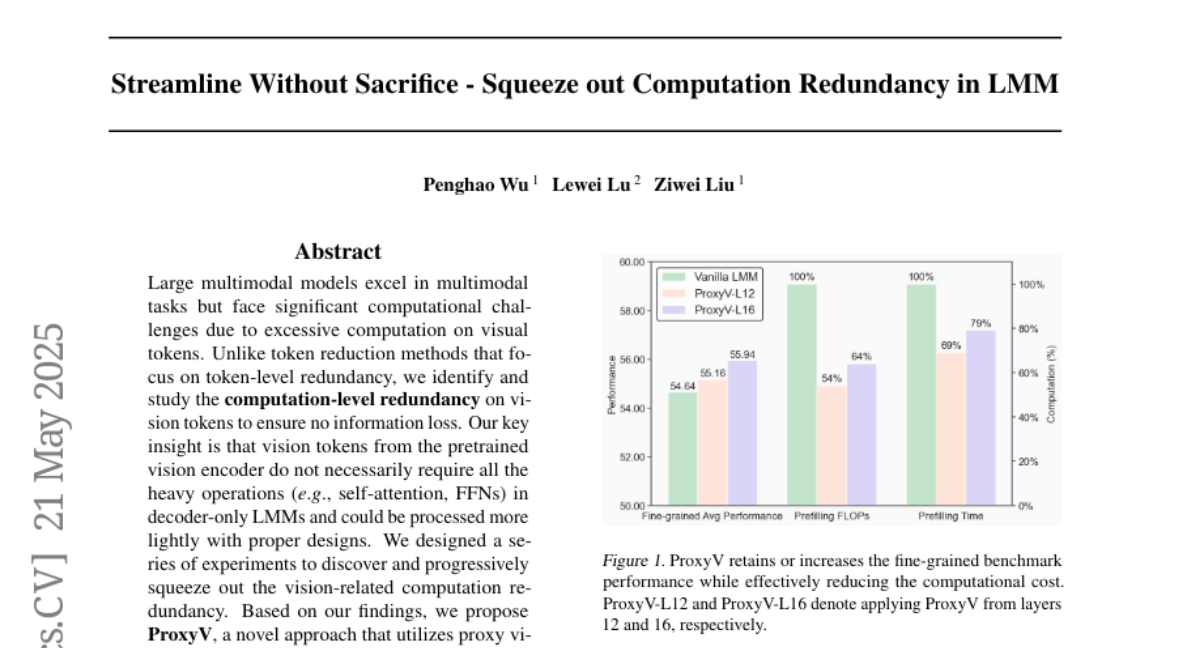
33. Streamline Without Sacrifice – Squeeze out Computation Redundancy in LMM
🔑 Keywords: ProxyV, vision tokens, multimodal models, computation-level redundancy
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance efficiency in large multimodal models by reducing computational redundancy on vision tokens using ProxyV.
🛠️ Research Methods:
– A series of experiments were conducted to identify vision-related computation redundancy and to develop ProxyV for efficient processing.
💬 Research Conclusions:
– ProxyV successfully alleviates computational burdens while maintaining, or even enhancing, model performance. It also integrates flexibly with token reduction methods for further efficiency gains.
👉 Paper link: https://huggingface.co/papers/2505.15816
34. DiCo: Revitalizing ConvNets for Scalable and Efficient Diffusion Modeling
🔑 Keywords: Diffusion ConvNet (DiCo), channel attention mechanism, Convolution, FID, ImageNet
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance efficiency in visual generation tasks by introducing Diffusion ConvNet (DiCo) with a compact channel attention mechanism, as a more efficient alternative to Diffusion Transformer (DiT).
🛠️ Research Methods:
– Utilizes standard ConvNet modules enhanced with a compact channel attention mechanism to address channel redundancy issues, leading to efficient and expressive diffusion models.
💬 Research Conclusions:
– Diffusion ConvNet (DiCo) demonstrates superior image quality and generation speed on class-conditional ImageNet benchmarks, outperforming previous diffusion models significantly, as evidenced by improved FID scores and speedup rates.
👉 Paper link: https://huggingface.co/papers/2505.11196

35. HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
🔑 Keywords: Human Centered AI, Ethics, Empathy, Inclusivity, HumaniBench
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce HumaniBench, a comprehensive benchmark evaluating large multimodal models (LMMs) based on seven human-centered AI principles.
🛠️ Research Methods:
– Utilizes 32K real-world image-question pairs annotated by a scalable GPT-based pipeline and verified by domain experts.
💬 Research Conclusions:
– Proprietary models generally outperform open-source counterparts, though both struggle with robustness and visual grounding, highlighting existing alignment gaps with human-aligned principles.
👉 Paper link: https://huggingface.co/papers/2505.11454

36. MultiHal: Multilingual Dataset for Knowledge-Graph Grounded Evaluation of LLM Hallucinations
🔑 Keywords: Large Language Models, hallucinations, Knowledge Graphs, multilingual, MultiHal
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate and mitigate hallucinations in Large Language Models by developing a multilingual, multihop benchmark using Knowledge Graphs.
🛠️ Research Methods:
– Developed a new benchmark called MultiHal by mining and curating high-quality KG-paths from open-domain Knowledge Graphs for generative text evaluation across multiple languages.
💬 Research Conclusions:
– MultiHal shows a significant improvement in semantic similarity scores when integrating Knowledge Graphs, indicating the potential for enhancing factuality in language models and encouraging future research in hallucination mitigation and fact-checking tasks.
👉 Paper link: https://huggingface.co/papers/2505.14101

37. Scaling and Enhancing LLM-based AVSR: A Sparse Mixture of Projectors Approach
🔑 Keywords: Multimodal LLM, Sparse Mixture of Projectors, modality-specific routers, inference costs, noise robustness
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research introduces Llama-SMoP, an efficient Multimodal LLM incorporating Sparse Mixture of Projectors, aiming to enhance Audio-Visual Speech Recognition (AVSR) performance without increasing inference costs.
🛠️ Research Methods:
– Llama-SMoP uses a Sparse Mixture of Projectors (SMoP) module, which includes sparsely-gated mixture-of-experts projectors. The study explores three SMoP configurations to ascertain the best setup for performance.
💬 Research Conclusions:
– Llama-SMoP with Disjoint-Experts and Disjoint-Routers configuration achieves superior performance in ASR, VSR, and AVSR tasks. Ablation studies confirm enhancements in expert activation, scalability, and robustness to noise.
👉 Paper link: https://huggingface.co/papers/2505.14336

38. BLEUBERI: BLEU is a surprisingly effective reward for instruction following
🔑 Keywords: BLEU, Reward Models, Instruction-Following, Group Relative Policy Optimization, Factually Grounded
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore whether simpler, reference-based metrics like BLEU can serve as viable alternatives to reward models in the alignment of language models with human preferences.
🛠️ Research Methods:
– Development of BLEUBERI, which uses BLEU as a reward function and employs Group Relative Policy Optimization to train models on instruction-following datasets.
💬 Research Conclusions:
– BLEUBERI-trained models match the quality of reward model-guided RL models and produce more factually grounded outputs, suggesting that string matching-based metrics can be effective and cost-efficient proxies for reward models when aligning language models.
👉 Paper link: https://huggingface.co/papers/2505.11080

39. Language Specific Knowledge: Do Models Know Better in X than in English?
🔑 Keywords: Language Specific Knowledge, Chain-of-thought Reasoning, Code-switching, Low-resource Languages
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate whether language models can hold more knowledge on certain topics when reasoning is performed in specific languages and improve performance in reasoning accuracy.
🛠️ Research Methods:
– The development of LSKExtractor methodology to benchmark and exploit Language Specific Knowledge present in language models, supported by culture-specific datasets.
💬 Research Conclusions:
– Language models demonstrated a 10% average improvement in accuracy using chain-of-thought reasoning in certain languages, particularly low-resource ones, showing the effectiveness of Language Specific Knowledge.
👉 Paper link: https://huggingface.co/papers/2505.14990

40. The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
🔑 Keywords: Entropy Minimization, Large Language Models, Math, Physics, Coding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the performance of Large Language Models (LLMs) in math, physics, and coding tasks through entropy minimization without utilizing labeled data.
🛠️ Research Methods:
– Examining three approaches: EM-FT for minimizing token-level entropy, EM-RL where negative entropy is the sole reinforcement reward, and EM-INF for inference-time logit adjustments.
💬 Research Conclusions:
– Entropy minimization can significantly improve LLMs’ performance on complex tasks without the need for labeled data or parameter updates, demonstrating comparable or superior performance to strong RL baselines.
👉 Paper link: https://huggingface.co/papers/2505.15134

41. BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
🔑 Keywords: Speculative decoding, Large Language Models, Multi-Armed Bandit, Hyperparameter selection, BanditSpec
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce BanditSpec, a training-free online learning framework that adaptively selects hyperparameters for speculative decoding in Large Language Models, aiming to enhance performance and throughput.
🛠️ Research Methods:
– The problem of hyperparameter selection is formulated as a Multi-Armed Bandit problem.
– Two algorithms, UCBSpec and EXP3Spec, are developed and analyzed, focusing on stopping time regret in both stochastic and adversarial settings.
💬 Research Conclusions:
– Empirical experiments demonstrate that BanditSpec, along with UCBSpec and EXP3Spec algorithms, effectively enhances the capability of Large Language Models compared to existing methods, achieving throughput close to the best possible hyperparameter configuration in real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2505.15141

42.
