AI Native Daily Paper Digest – 20250526

1. TabSTAR: A Foundation Tabular Model With Semantically Target-Aware Representations
🔑 Keywords: TabSTAR, Foundation Tabular Model, Semantically Target-Aware Representations, transfer learning
💡 Category: Machine Learning
🌟 Research Objective:
– Introducing TabSTAR, a tabular foundation model designed to improve performance in classification tasks with text features through semantically target-aware representations and transfer learning.
🛠️ Research Methods:
– Employing a pretrained text encoder and target tokens to enable learning task-specific embeddings on tabular data without relying on dataset-specific parameters.
💬 Research Conclusions:
– TabSTAR achieves state-of-the-art performance on both medium- and large-sized datasets, demonstrating scaling laws during pretraining and indicating potential for further performance enhancement across classification tasks with text features.
👉 Paper link: https://huggingface.co/papers/2505.18125

2. QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
🔑 Keywords: QwenLong-L1, reinforcement learning, long-context reasoning, curriculum-guided phased RL, document question-answering
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the effectiveness of large reasoning models (LRMs) for long-context reasoning through reinforcement learning.
🛠️ Research Methods:
– Introduction of QwenLong-L1, a framework that adapts short-context LRMs to long-context scenarios via progressive context scaling, including a warm-up supervised fine-tuning stage and curriculum-guided phased RL.
💬 Research Conclusions:
– QwenLong-L1 surpasses established models like OpenAI-o3-mini and matches the performance of Claude-3.7-Sonnet-Thinking in long-context document question-answering benchmarks, demonstrating its superiority in processing information-intensive environments.
👉 Paper link: https://huggingface.co/papers/2505.17667

3. Quartet: Native FP4 Training Can Be Optimal for Large Language Models
🔑 Keywords: large language models, FP4, low-precision arithmetic, NVIDIA Blackwell, Quartet
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce Quartet, a hardware-supported FP4 training approach for large language models, aiming for state-of-the-art accuracy while reducing computational costs.
🛠️ Research Methods:
– Systematic investigation of FP4 precision training.
– Implementation of optimized CUDA kernels for NVIDIA Blackwell GPUs to support end-to-end low-precision FP4 training.
💬 Research Conclusions:
– Quartet achieves state-of-the-art accuracy in low-precision training of large-scale models, proving to be a viable alternative to standard-precision and FP8 training, with the code available on GitHub.
👉 Paper link: https://huggingface.co/papers/2505.14669

4. Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models
🔑 Keywords: Large language models, reasoning rigidity, diagnostic set, mathematics, logic puzzle
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to diagnose and categorize reasoning rigidity in large language models, highlighting their tendency to ignore user instructions and rely on familiar reasoning patterns, which leads to incorrect conclusions.
🛠️ Research Methods:
– Introduced an expert-curated diagnostic set comprising modified versions of existing mathematical benchmarks like AIME and MATH500, as well as redesigned puzzles to assess deviation from habitual reasoning strategies.
💬 Research Conclusions:
– Identified recurring contamination patterns in language models’ reasoning, categorized into Interpretation Overload, Input Distrust, and Partial Instruction Attention, to address the issue of reasoning rigidity.
👉 Paper link: https://huggingface.co/papers/2505.17225

5. One RL to See Them All: Visual Triple Unified Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Vision-Language Models, Visual Perception, Dynamic IoU Reward, Orsta
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to integrate visual reasoning and perception tasks in vision-language models (VLMs) through a unified reinforcement learning system called V-Triune.
🛠️ Research Methods:
– V-Triune employs three components: Sample-Level Data Formatting, Verifier-Level Reward Computation, and Source-Level Metric Monitoring within a single RL training pipeline. It introduces a novel Dynamic IoU reward to enhance perception task feedback, utilizing open-source 7B and 32B backbone models.
💬 Research Conclusions:
– V-Triune and the resulting model, Orsta, demonstrate significant improvements in both reasoning and perception tasks. These enhancements are confirmed through diverse datasets and notable performance gains on MEGA-Bench Core, showcasing the scalability and effectiveness of the unified RL approach for VLMs.
👉 Paper link: https://huggingface.co/papers/2505.18129

6. Distilling LLM Agent into Small Models with Retrieval and Code Tools
🔑 Keywords: Agent Distillation, Large Language Models, Reasoning Tasks, Small Language Models, Prompting Method
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper proposes a framework called Agent Distillation to transfer reasoning and task-solving capabilities from large language models (LLMs) to smaller models, improving their practical deployment.
🛠️ Research Methods:
– Utilization of enhanced prompts (first-thought prefix) and self-consistent actions to improve reasoning capabilities in small language models.
– Evaluation on eight reasoning tasks incorporating retrieval and code tools, covering both factual and mathematical domains for in-domain and out-of-domain generalization.
💬 Research Conclusions:
– The Agent Distillation framework allows small language models as small as 0.5B parameters to reach performance levels competitive with larger models like 1.5B, 3B, and 7B, suggesting potential for practical, tool-using agents.
👉 Paper link: https://huggingface.co/papers/2505.17612

7. PhyX: Does Your Model Have the “Wits” for Physical Reasoning?
🔑 Keywords: PhyX, physics-grounded reasoning, visual scenarios, state-of-the-art models, human experts
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address the limitations in current models regarding their physical understanding by introducing PhyX, a benchmark for assessing physics-grounded reasoning in visual scenarios.
🛠️ Research Methods:
– PhyX comprises 3K curated multimodal questions, covering 6 reasoning types across 25 sub-domains and 6 core physics domains like thermodynamics, electromagnetism, and mechanics.
💬 Research Conclusions:
– Current state-of-the-art models, such as GPT-4o and Claude3.7-Sonnet, exhibit significant performance gaps in physical reasoning compared to human experts, attributed to over-reliance on memorized knowledge and lack of genuine understanding.
👉 Paper link: https://huggingface.co/papers/2505.15929

8. QwenLong-CPRS: Towards infty-LLMs with Dynamic Context Optimization
🔑 Keywords: QwenLong-CPRS, context compression, large language models, dynamic context optimization, SOTA performance
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance large language models with an innovative framework for multi-granularity context compression and dynamic optimization, addressing computational challenges and performance issues in long context processing.
🛠️ Research Methods:
– Implementation of a novel dynamic context optimization mechanism, featuring natural language-guided optimization, bidirectional reasoning layers, token critic mechanisms, and window-parallel inference.
💬 Research Conclusions:
– QwenLong-CPRS consistently outperforms other methods such as RAG and sparse attention in terms of accuracy and efficiency.
– Demonstrates architecture-agnostic integration with key LLMs, achieving substantial context compression and performance improvement.
– Surpasses leading proprietary LLMs on benchmarks, establishing new state-of-the-art (SOTA) performance.
👉 Paper link: https://huggingface.co/papers/2505.18092

9. Scaling Image and Video Generation via Test-Time Evolutionary Search
🔑 Keywords: EvoSearch, test-time scaling, diffusion models, flow models, video generation
💡 Category: Generative Models
🌟 Research Objective:
– To propose EvoSearch, a novel evolutionary search method that enhances test-time scaling for generative models to improve image and video generation quality and diversity.
🛠️ Research Methods:
– Reformulation of test-time scaling as an evolutionary search problem, utilizing biological evolution principles to optimize the denoising trajectory with selection and mutation mechanisms.
💬 Research Conclusions:
– EvoSearch effectively enhances scalability and performance in image and video generation tasks without additional training, achieving higher diversity and strong generalizability compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2505.17618

10. MOOSE-Chem3: Toward Experiment-Guided Hypothesis Ranking via Simulated Experimental Feedback
🔑 Keywords: Hypothesis ranking, Automated scientific discovery, Experiment-guided ranking, Large language model, Dataset
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To enhance hypothesis prioritization in scientific discovery by integrating simulated experimental outcomes.
🛠️ Research Methods:
– Developed a simulator based on domain-informed assumptions.
– Utilized a curated dataset of chemistry hypotheses and their reported outcomes.
– Developed a pseudo experiment-guided ranking method using simulated experimental feedback.
💬 Research Conclusions:
– The proposed method surpasses existing pre-experiment ranking techniques.
👉 Paper link: https://huggingface.co/papers/2505.17873

11. Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model
🔑 Keywords: ANSE, video diffusion models, noise seeds, AI-generated summary, BANSA
💡 Category: Generative Models
🌟 Research Objective:
– Enhance video diffusion models by selecting noise seeds based on model confidence to improve video quality and temporal coherence.
🛠️ Research Methods:
– Introduction of ANSE and BANSA frameworks to quantify attention-based uncertainty and measure entropy disagreement using Bayesian active noise selection.
💬 Research Conclusions:
– ANSE improves video quality and temporal coherence with minimal increases in inference time, providing a principled and generalizable approach to noise selection in video diffusion models.
👉 Paper link: https://huggingface.co/papers/2505.17561

12. VeriThinker: Learning to Verify Makes Reasoning Model Efficient
🔑 Keywords: Large Reasoning Models, Chain-of-Thought, Verification Task, Reasoning Tokens, Accuracy
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To reduce inference costs in Large Reasoning Models (LRMs) by fine-tuning them using a novel verification task to shorten complex reasoning chains without losing accuracy.
🛠️ Research Methods:
– Introduced a novel approach named VeriThinker that fine-tunes LRMs through an auxiliary verification task, improving the efficiency of reasoning by suppressing unnecessary self-reflection steps.
💬 Research Conclusions:
– VeriThinker significantly reduces reasoning chain lengths and reasoning tokens while slightly improving accuracy. E.g., on MATH500, reasoning tokens were decreased from 3790 to 2125 with a 0.8% accuracy increase.
– Demonstrates capability of zero-shot generalization to speculative reasoning.
👉 Paper link: https://huggingface.co/papers/2505.17941

13. AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
🔑 Keywords: AudioTrust, ALLMs, trustworthiness, audio-specific evaluation metrics, automated pipeline
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Explore and evaluate the trustworthiness of Audio Large Language Models (ALLMs) across multifaceted dimensions specific to the audio modality.
🛠️ Research Methods:
– Implementation of AudioTrust, a pioneering evaluation framework with 18 experimental setups and a dataset comprising over 4,420 audio/text samples from real-world scenarios.
💬 Research Conclusions:
– AudioTrust provides insights into the limitations and trustworthiness boundaries of current audio models in high-risk scenarios, emphasizing the importance of secure deployment for future ALLMs.
👉 Paper link: https://huggingface.co/papers/2505.16211

14. Position of Uncertainty: A Cross-Linguistic Study of Positional Bias in Large Language Models
🔑 Keywords: positional bias, model uncertainty, syntax, prompting, positional guidance
💡 Category: Natural Language Processing
🌟 Research Objective:
– Examine the positional bias of large language models across five typologically distinct languages and its interaction with model uncertainty, syntax, and prompting.
🛠️ Research Methods:
– Conducted a cross-linguistic study analyzing positional bias in English, Russian, German, Hindi, and Vietnamese.
💬 Research Conclusions:
– Positional bias is model-driven with language-specific variations.
– Explicit positional guidance reduces accuracy and challenges prompt-engineering practices.
– Aligning context with positional bias increases entropy but does not predict accuracy.
– LLMs impose dominant word order differently in free-word-order languages like Hindi.
👉 Paper link: https://huggingface.co/papers/2505.16134

15. FullFront: Benchmarking MLLMs Across the Full Front-End Engineering Workflow
🔑 Keywords: Multimodal Large Language Models, front-end engineering, Webpage Design, Webpage Perception QA, Webpage Code Generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces FullFront, a benchmark designed to evaluate Multimodal Large Language Models across the entire front-end development pipeline.
🛠️ Research Methods:
– FullFront assesses three core tasks: Webpage Design, Webpage Perception QA, and Webpage Code Generation, employing a two-stage process to use real-world webpages with clean, standardized HTML.
💬 Research Conclusions:
– Testing state-of-the-art MLLMs reveals significant limitations in page perception and code generation, with a notable gap between current MLLM capabilities and human performance in front-end engineering.
👉 Paper link: https://huggingface.co/papers/2505.17399

16. Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention
🔑 Keywords: 3D shape generation, Spatial Sparse Attention, Diffusion Transformer, variational autoencoder, gigascale 3D generation
💡 Category: Generative Models
🌟 Research Objective:
– To develop a scalable 3D shape generation framework with high resolution and reduced computational requirements using sparse volumes and spatial sparse attention.
🛠️ Research Methods:
– Implementation of Direct3D S2 framework based on sparse volumes, integration of Spatial Sparse Attention for efficient processing in Diffusion Transformer computations, and use of a variational autoencoder for consistent sparse volumetric formats.
💬 Research Conclusions:
– Direct3D S2 framework achieves a significant reduction in computational overhead with a notable speedup in processing, improves training efficiency and stability, and enables high-resolution 3D generation with fewer GPUs than previously required.
👉 Paper link: https://huggingface.co/papers/2505.17412

17. Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection
🔑 Keywords: LLMs, hallucinations, DPO alignment, curriculum learning, zero-shot settings
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance the detection abilities of large language models (LLMs) for hallucinations using carefully engineered samples as negative examples.
🛠️ Research Methods:
– Implement a curriculum learning strategy within the DPO alignment procedure, utilizing hallucinated texts to train models progressively from easier to harder samples.
💬 Research Conclusions:
– The proposed HaluCheck models significantly improve performance on challenging benchmarks by up to 24% and demonstrate robustness in zero-shot settings.
👉 Paper link: https://huggingface.co/papers/2505.17558

18. Diffusion Classifiers Understand Compositionality, but Conditions Apply
🔑 Keywords: Diffusion classifiers, Compositional understanding, Generative models, AI-generated summary, Timestep weighting
💡 Category: Generative Models
🌟 Research Objective:
– Investigate the discriminative capabilities of diffusion classifiers across diverse datasets and tasks.
🛠️ Research Methods:
– Analyze the performance of diffusion models (SD 1.5, 2.0, 3-m) on over 30 tasks and 10 datasets.
– Introduce a diagnostic benchmark, Self-Bench, to examine the effect of dataset domains.
💬 Research Conclusions:
– Diffusion classifiers exhibit compositional understanding with domain and timestep considerations affecting performance.
👉 Paper link: https://huggingface.co/papers/2505.17955

19. Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities
🔑 Keywords: TAPO, Thought-Augmented Policy Optimization, external guidance, reasoning models, explainability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance RL model performance and exploration by integrating external high-level guidance using the TAPO framework.
🛠️ Research Methods:
– Development of the TAPO framework which incorporates structured thought patterns to balance exploration and guidance in RL.
💬 Research Conclusions:
– TAPO significantly outperforms existing methods like GRPO on multiple tasks and shows potential for broad applications with enhanced explainability and output readability.
👉 Paper link: https://huggingface.co/papers/2505.15692

20. Time-R1: Towards Comprehensive Temporal Reasoning in LLMs
🔑 Keywords: Temporal Intelligence, Reinforcement Learning, Future Event Prediction, Creative Scenario Generation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance moderate-sized LLMs with comprehensive temporal abilities, outperforming larger models on benchmarks related to future event prediction and creative scenario generation.
🛠️ Research Methods:
– Introduction of Time-R1, a framework using a three-stage reinforcement learning curriculum with a dynamic rule-based reward system to build temporal understanding, improve future event prediction, and enable creative scenario generation.
💬 Research Conclusions:
– Time-R1 demonstrates that progressive reinforcement learning fine-tuning allows smaller models to achieve superior temporal performance compared to significantly larger models, providing a scalable path towards time-aware AI.
👉 Paper link: https://huggingface.co/papers/2505.13508

21. Clear Nights Ahead: Towards Multi-Weather Nighttime Image Restoration
🔑 Keywords: AI-generated summary, nighttime image restoration, Retinex-based dual priors, AllWeatherNight dataset, ClearNight
💡 Category: Computer Vision
🌟 Research Objective:
– To restore nighttime images affected by multiple adverse weather conditions, exploring the intertwined effects of weather degradations and flare effects.
🛠️ Research Methods:
– Introduction of the AllWeatherNight dataset featuring large-scale high-quality nighttime images with compositional degradations.
– Development of ClearNight framework employing Retinex-based dual priors to guide restoration focusing on uneven illumination and intrinsic texture.
– Weather-aware dynamic specific-commonality collaboration method to adaptively select optimal units for specific weather types.
💬 Research Conclusions:
– ClearNight demonstrates state-of-the-art performance on both synthetic and real-world images.
– Comprehensive ablation experiments confirm the necessity and effectiveness of the AllWeatherNight dataset and the ClearNight framework.
👉 Paper link: https://huggingface.co/papers/2505.16479

22. s3: You Don’t Need That Much Data to Train a Search Agent via RL
🔑 Keywords: Retrieval-augmented generation, Reinforcement learning, Model-agnostic framework, Gain Beyond RAG, QA benchmarks
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop a lightweight, model-agnostic framework (s3) that decouples the retrieval and generation processes to enhance retrieval-augmented generation systems.
🛠️ Research Methods:
– The framework trains the search component using a Gain Beyond RAG reward to improve generation accuracy without entangling retrieval with generation.
💬 Research Conclusions:
– The proposed framework s3 outperforms existing baselines, using significantly less training data, across various general and medical QA benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.14146

23. Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
🔑 Keywords: LLM faithfulness, CANOE, Dual-GRPO, Synthetic QA data, Reinforcement Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper proposes a framework called CANOE to enhance the faithfulness of large language models (LLMs) in both short-form and long-form generation tasks without relying on human annotations.
🛠️ Research Methods:
– CANOE uses synthetic question-answering (QA) data generated through four diverse tasks.
– Introduces Dual-GRPO, a rule-based reinforcement learning method with tailored rule-based rewards, to optimize both short-form and long-form response generation.
💬 Research Conclusions:
– CANOE significantly improves the faithfulness of LLMs across 11 different downstream tasks and even outperforms advanced language models like GPT-4o and OpenAI o1.
👉 Paper link: https://huggingface.co/papers/2505.16483

24. RBench-V: A Primary Assessment for Visual Reasoning Models with Multi-modal Outputs
🔑 Keywords: RBench-V, multi-modal models, image manipulation, auxiliary lines, multi-modal reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To present RBench-V, a benchmark assessing vision-indispensable reasoning in multi-modal models.
🛠️ Research Methods:
– Constructed RBench-V with 803 questions focusing on math, physics, counting, and games, emphasizing multi-modal outputs using image manipulation and auxiliary line construction.
💬 Research Conclusions:
– Even the best-performing models struggle with multi-modal reasoning, as demonstrated by the highest accuracy of only 25.8% compared to human performance at 82.3%.
👉 Paper link: https://huggingface.co/papers/2505.16770

25. ScanBot: Towards Intelligent Surface Scanning in Embodied Robotic Systems
🔑 Keywords: ScanBot, high-precision, robotic systems, vision-language action models, laser scanning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce the ScanBot dataset for instruction-conditioned, high-precision robotic surface scanning aiming to address industrial laser scanning demands.
🛠️ Research Methods:
– The dataset consists of laser scanning trajectories across diverse objects and tasks, guided by natural language instructions, and analyzes multimodal large language models across the perception-planning-execution loop.
💬 Research Conclusions:
– Existing vision-language action models struggle to achieve stable scanning trajectories under fine-grained instructions, highlighting persistent challenges in real-world applications.
👉 Paper link: https://huggingface.co/papers/2505.17295

26. Speechless: Speech Instruction Training Without Speech for Low Resource Languages
🔑 Keywords: LLM, Whisper encoder, low-resource languages, semantic representation
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the challenge of training voice assistants for low-resource languages by bypassing the need for TTS models.
🛠️ Research Methods:
– Align semantic representations with a Whisper encoder to enable large language models (LLMs) to understand both text and spoken instructions.
💬 Research Conclusions:
– The proposed method simplifies the training process for voice assistants, making it feasible for low-resource languages by enabling LLMs to be fine-tuned on text instructions while retaining the ability to comprehend spoken instructions during inference.
👉 Paper link: https://huggingface.co/papers/2505.17417

27. Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
🔑 Keywords: Reinforcement Fine-Tuning, Trinity-RFT, Large Language Models, Reinforcement Learning Paradigms, Flexible Framework
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Develop a flexible and scalable framework, Trinity-RFT, for reinforcement fine-tuning of large language models.
🛠️ Research Methods:
– Utilizes a decoupled design integrating different modes and agent-environment interactions with optimized data pipelines.
💬 Research Conclusions:
– Trinity-RFT acts as a unified platform adaptable for various application scenarios, enhancing the exploration of advanced reinforcement learning paradigms.
👉 Paper link: https://huggingface.co/papers/2505.17826

28. Synthetic Data RL: Task Definition Is All You Need
🔑 Keywords: Synthetic Data, Reinforcement Learning, AI-generated Summary
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance foundation models using reinforcement learning with synthetic data, aiming to match performance with models trained on human-labeled data.
🛠️ Research Methods:
– Utilized a framework that generates synthetic question and answer pairs, adapts question difficulty, and selects questions based on average pass rates for reinforcement learning training.
💬 Research Conclusions:
– The proposed method significantly improves model performance on several benchmarks and reduces the need for human-labeled data, highlighting its scalability and efficiency.
👉 Paper link: https://huggingface.co/papers/2505.17063

29. Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study
🔑 Keywords: Vision-Language Models, MemeSafetyBench, Safety Risks, Multi-turn Interactions, AI-generated Summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To assess the safety of Vision-Language Models (VLMs) when confronted with meme images compared to artificial images.
🛠️ Research Methods:
– Introduced MemeSafetyBench, a benchmark of 50,430 instances, paired with real meme images and a comprehensive safety taxonomy.
– Evaluated VLMs across single and multi-turn interactions using LLM-based instruction generation.
💬 Research Conclusions:
– VLMs are more vulnerable to meme-based harmful prompts than synthetic or typographic images, leading to increased harmful responses.
– Multi-turn interactions offer limited protection, highlighting the need for ecologically valid evaluations and enhanced safety mechanisms.
👉 Paper link: https://huggingface.co/papers/2505.15389

30. Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning
🔑 Keywords: Transformer Copilot, Copilot model, Mistake Log, scalability, transferability
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the performance of large language models through a novel framework called Transformer Copilot, which includes a Copilot model working alongside a Pilot model.
🛠️ Research Methods:
– Introduced the Mistake Log to track learning behavior and errors.
– Designed a Copilot model for logits rectification.
– Implemented a joint training and fused inference paradigm.
💬 Research Conclusions:
– Transformer Copilot consistently improves performance across various benchmarks by up to 34.5%, with minimal computational overhead and strong scalability and transferability.
👉 Paper link: https://huggingface.co/papers/2505.16270

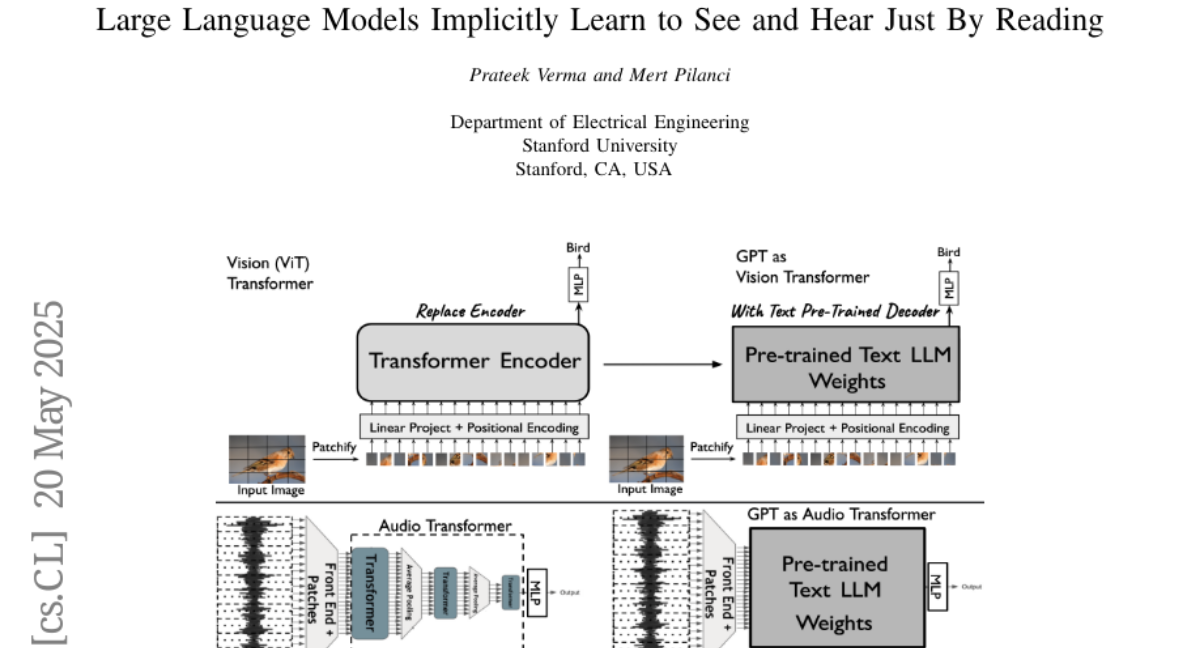
31. Large Language Models Implicitly Learn to See and Hear Just By Reading
🔑 Keywords: Auto-regressive text LLMs, image and audio understanding, classification, embeddings
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Demonstrate that auto-regressive text LLMs can develop the ability to understand and classify images and audio without fine-tuning.
🛠️ Research Methods:
– Utilize an architecture that processes patches of images and audio waveforms or tokens to provide embeddings or category labels typically seen in a classification pipeline.
💬 Research Conclusions:
– Text LLMs show general applicability in aiding audio classification on datasets like FSD-50K and GTZAN, as well as image classification on CIFAR-10 and Fashion-MNIST.
– The approach suggests leveraging internal capabilities of text LLMs for various modalities, reducing the need for training models from scratch.
👉 Paper link: https://huggingface.co/papers/2505.17091
32. ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection
🔑 Keywords: ReflAct, LLM agents, goal alignment, hallucinations, reasoning backbone
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce ReflAct as a new reasoning backbone to improve goal alignment and reduce hallucinations in LLM agents.
🛠️ Research Methods:
– Continuous reflection on the agent’s state relative to its goal to enforce ongoing goal alignment.
💬 Research Conclusions:
– ReflAct surpasses ReAct by 27.7% on average, achieving a 93.3% success rate in ALFWorld and outperforms enhanced variants, highlighting the importance of a strong reasoning backbone.
👉 Paper link: https://huggingface.co/papers/2505.15182

33. On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning
🔑 Keywords: KL divergence, Policy gradient, Online reinforcement learning, Large language models, Training stability
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore KL divergence formulations to enhance the reasoning capabilities of large language models (LLMs) in online reinforcement learning settings.
🛠️ Research Methods:
– Introduction of a regularized policy gradient framework that integrates KL divergence into surrogate loss functions.
– Derivation of policy gradients using forward and reverse KL divergences for both normalized and unnormalized policy distributions.
– Incorporation of fully differentiable loss functions and REINFORCE-style gradient estimators.
💬 Research Conclusions:
– The proposed methods demonstrated improved or competitive training stability and performance compared to existing RL baselines.
👉 Paper link: https://huggingface.co/papers/2505.17508

34. RePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
🔑 Keywords: RePrompt, reinforcement learning, text-to-image, AI-generated summary, semantic alignment
💡 Category: Generative Models
🌟 Research Objective:
– To enhance text-to-image generation by improving spatial layout and compositional generalization using a reprompting framework with reinforcement learning.
🛠️ Research Methods:
– Implementation of RePrompt, a framework that uses reinforcement learning to introduce explicit reasoning into prompt enhancement without relying on handcrafted rules.
– The use of tailored reward models for assessing generated images based on human preference, semantic alignment, and visual composition.
💬 Research Conclusions:
– RePrompt significantly improves spatial layout fidelity and compositional generalization across various T2I backbones, achieving state-of-the-art results.
👉 Paper link: https://huggingface.co/papers/2505.17540

35. Interactive Post-Training for Vision-Language-Action Models
🔑 Keywords: RIPT-VLA, Vision-Language-Action models, sparse binary success rewards, interactive post-training, policy optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance pretrained Vision-Language-Action models using sparse binary success rewards to improve adaptability and generalization.
🛠️ Research Methods:
– Utilize a reinforcement learning-based interactive post-training paradigm with dynamic rollout sampling and leave-one-out advantage estimation for stable policy optimization.
💬 Research Conclusions:
– Demonstrates substantial improvements in model performance, achieving a high success rate, and ensures computational and data efficiency, while enhancing the model’s generalization across tasks and robustness to various scenarios.
👉 Paper link: https://huggingface.co/papers/2505.17016

36. Keep Security! Benchmarking Security Policy Preservation in Large Language Model Contexts Against Indirect Attacks in Question Answering
🔑 Keywords: LLMs, contextual security, indirect attacks, CoPriva, policy constraints
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to evaluate the adherence of Large Language Models (LLMs) to contextual non-disclosure policies, particularly against indirect attacks.
🛠️ Research Methods:
– Introduction of a novel large-scale benchmark dataset, CoPriva, which includes explicit policies and queries designed as indirect attacks to test model vulnerability.
💬 Research Conclusions:
– Many LLMs violate user-defined policies, leaking sensitive information especially against indirect attacks, emphasizing a critical gap in current LLM safety for sensitive domains.
– While models can identify correct answers, they struggle with incorporating policy constraints and need robust methods to improve contextual security.
👉 Paper link: https://huggingface.co/papers/2505.15805

37. DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
🔑 Keywords: Diffusion framework, Multi-actor interaction, MaskPoseAdapter, TogetherVideoBench, Embodied-AI
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces DanceTogether, an end-to-end diffusion framework aimed at generating photorealistic multi-actor interaction videos from single reference images and pose-mask streams.
🛠️ Research Methods:
– Utilizes a novel MaskPoseAdapter to bind actor identities and actions effectively, paired with new datasets like PairFS-4K and benchmarks like TogetherVideoBench to train and evaluate system performance against various challenges like dance and boxing.
💬 Research Conclusions:
– DanceTogether significantly outperforms existing video generation systems by eliminating common issues like identity drift and appearance bleeding. It showcases broad generalization capabilities applicable to digital production, simulation, and embodied intelligence tasks.
👉 Paper link: https://huggingface.co/papers/2505.18078

38. Not All Models Suit Expert Offloading: On Local Routing Consistency of Mixture-of-Expert Models
🔑 Keywords: Mixture-of-Experts, expert offloading, local routing consistency, Segment Routing Best Performance, Segment Cache Best Hit Rate
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the efficient scaling of large language models using Mixture-of-Experts (MoE) while focusing on local routing consistency and cache effectiveness.
🛠️ Research Methods:
– Introduces metrics: Segment Routing Best Performance (SRP) and Segment Cache Best Hit Rate (SCH) to evaluate local routing consistency.
– Analyzes 20 diverse MoE LLMs and examines the impact of applying MoE on every layer without shared experts and the role of domain-specialized experts.
💬 Research Conclusions:
– MoE models that apply MoE on every layer and utilize domain-specialized experts show greater local routing consistency.
– Most models achieve a balance between cache effectiveness and efficiency with a cache size approximately double the active experts, enabling memory-efficient MoE design and deployment.
👉 Paper link: https://huggingface.co/papers/2505.16056

39. Augmenting LLM Reasoning with Dynamic Notes Writing for Complex QA
🔑 Keywords: Iterative RAG, Notes Writing, Large Language Models, Multi-hop Question Answering, Context Length
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve iterative RAG’s performance in multi-hop question answering by introducing a method called Notes Writing that generates concise notes at each step to enhance reasoning and processing capacity.
🛠️ Research Methods:
– The proposed method, Notes Writing, creates relevant and concise notes from retrieved documents to reduce noise and retain essential information, and it can be integrated with various iterative RAG methods.
💬 Research Conclusions:
– Notes Writing demonstrated effectiveness across three iterative RAG methods, boosting performance by an average of 15.6 percentage points, with minimal increase in output tokens, thus enabling better reasoning and handling of larger input text volumes in Large Language Models.
👉 Paper link: https://huggingface.co/papers/2505.16293

40. Value-Guided Search for Efficient Chain-of-Thought Reasoning
🔑 Keywords: AI-generated summary, value model, long-context reasoning, block-wise value-guided search, DeepSeek
💡 Category: Foundations of AI
🌟 Research Objective:
– Introduce an efficient method for value model training on long-context reasoning traces.
🛠️ Research Methods:
– Developed a dataset of 2.5 million reasoning traces to train a 1.5B token-level value model using block-wise value-guided search with final weighted majority vote.
💬 Research Conclusions:
– Achieved improved performance and reduced computation cost compared to standard methods. The proposed method reached parity with existing models in math benchmarks while reducing inference FLOPs, with the dataset and codebase open-sourced.
👉 Paper link: https://huggingface.co/papers/2505.17373

41. Revisiting Residual Connections: Orthogonal Updates for Stable and Efficient Deep Networks
🔑 Keywords: Orthogonal Residual Update, Residual connections, Feature learning, Training stability, AI-generated summary
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce Orthogonal Residual Updates, aiming to improve feature learning and training stability in deep neural networks by decomposing module outputs to primarily novel features.
🛠️ Research Methods:
– Implemented decomposition of module output relative to input stream, adding only the orthogonal component to encourage new representational directions and enhance feature learning.
💬 Research Conclusions:
– Orthogonal update strategy improves generalization accuracy and training stability, demonstrating significant performance gains across architectures like ResNetV2 and Vision Transformers, with notable improvements such as a +4.3% top-1 accuracy gain for ViT-B on ImageNet-1k.
👉 Paper link: https://huggingface.co/papers/2505.11881

42. TIME: A Multi-level Benchmark for Temporal Reasoning of LLMs in Real-World Scenarios
🔑 Keywords: Temporal reasoning, Large Language Models (LLMs), Benchmark, Temporal dependencies, QA pairs
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce and evaluate a benchmark called TIME for assessing temporal reasoning in LLMs within real-world challenges.
🛠️ Research Methods:
– Developed a benchmark with 38,522 QA pairs across 11 sub-tasks and sub-datasets to test temporal reasoning capacities.
– Conducted extensive experiments on both reasoning and non-reasoning models to analyze performance in diverse scenarios.
– Released a human-annotated subset, TIME-Lite, for fostering future research.
💬 Research Conclusions:
– The benchmark demonstrates significant insights into the impact of test-time scaling on temporal reasoning performance.
👉 Paper link: https://huggingface.co/papers/2505.12891

43. FuxiMT: Sparsifying Large Language Models for Chinese-Centric Multilingual Machine Translation
🔑 Keywords: FuxiMT, multilingual machine translation, sparsified large language model, Mixture-of-Experts, zero-shot capabilities
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces FuxiMT, a Chinese-centric multilingual machine translation model designed to enhance translation performance in low-resource scenarios.
🛠️ Research Methods:
– FuxiMT utilizes a two-stage training strategy including initial pre-training on a massive Chinese corpus followed by multilingual fine-tuning across 65 languages. It incorporates Mixture-of-Experts and curriculum learning for improved efficiency across various resources.
💬 Research Conclusions:
– Experimental results indicate that FuxiMT outperforms existing state-of-the-art models, showcasing strong zero-shot translation abilities for language pairs lacking parallel data.
👉 Paper link: https://huggingface.co/papers/2505.14256

44. NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning
🔑 Keywords: NOVER, Reinforcement Learning, Incentive Training, Language Models, External Verifiers
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to introduce a reinforcement learning framework, NOVER, that removes the dependency on external verifiers and enhances performance across various text-to-text tasks.
🛠️ Research Methods:
– The study proposes NO-VERifier Reinforcement Learning, which uses standard supervised fine-tuning data without the need for an external verifier.
💬 Research Conclusions:
– NOVER improves model performance by 7.7% compared to distilled models from larger reasoning models like DeepSeek R1 671B and opens new avenues for optimizing large language models.
👉 Paper link: https://huggingface.co/papers/2505.16022

45. FREESON: Retriever-Free Retrieval-Augmented Reasoning via Corpus-Traversing MCTS
🔑 Keywords: FREESON, CT-MCTS, Multi-step reasoning, LRMs, QA tasks
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce FREESON to improve large reasoning models by integrating retrieval and reasoning roles using CT-MCTS.
🛠️ Research Methods:
– Utilized a novel variant algorithm called CT-MCTS for traversing corpus and locating answer-containing paths within LRMs.
💬 Research Conclusions:
– FREESON achieves an average improvement of 14.4% in EM and F1 over existing multi-step reasoning models and surpasses the strongest baseline by 3% on PopQA and 2% on 2WikiMultihopQA.
👉 Paper link: https://huggingface.co/papers/2505.16409

46. NileChat: Towards Linguistically Diverse and Culturally Aware LLMs for Local Communities
🔑 Keywords: NileChat, Low-resource languages, Cultural heritage, Retrieval-based pre-training, Large Language Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a methodology for creating pre-training data adapted to low-resource languages and cultures, exemplified by Egyptian and Moroccan dialects.
🛠️ Research Methods:
– Utilization of synthetic and retrieval-based pre-training data that takes into account local language, cultural heritage, and values.
💬 Research Conclusions:
– NileChat, a 3B parameter LLM, demonstrates superior performance compared to existing Arabic-aware models and matches the capabilities of larger models while emphasizing the linguistic and cultural aspects of Egyptian and Moroccan communities.
👉 Paper link: https://huggingface.co/papers/2505.18383

47. Universal Biological Sequence Reranking for Improved De Novo Peptide Sequencing
🔑 Keywords: RankNovo, de novo peptide sequencing, axial attention, zero-shot generalization
💡 Category: Machine Learning
🌟 Research Objective:
– To present RankNovo, a deep reranking framework aimed at enhancing the performance and generalization in de novo peptide sequencing by using multiple models and axial attention.
🛠️ Research Methods:
– Utilizes a list-wise reranking approach, modeling candidate peptides as multiple sequence alignments.
– Introduces axial attention to extract informative features across candidates.
– Develops new metrics, PMD (Peptide Mass Deviation) and RMD (Residual Mass Deviation), to provide precise supervision.
💬 Research Conclusions:
– RankNovo surpasses its base models and sets a new state-of-the-art benchmark in de novo peptide sequencing.
– Demonstrates strong zero-shot generalization to unseen models, underscoring its robustness and potential as a universal reranking framework.
👉 Paper link: https://huggingface.co/papers/2505.17552

48.
