AI Native Daily Paper Digest – 20250527

1. Mutarjim: Advancing Bidirectional Arabic-English Translation with a Small Language Model
🔑 Keywords: Mutarjim, Arabic-English translation, Tarjama-25, two-phase training, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research introduces Mutarjim, a compact model designed to outperform larger models in bidirectional Arabic-English translation.
🛠️ Research Methods:
– Utilized an optimized two-phase training approach and a curated high-quality training corpus based on Kuwain-1.5B.
– Introduced a new comprehensive benchmark, Tarjama-25, to evaluate the model’s performance across a wide range of domains.
💬 Research Conclusions:
– Mutarjim achieves state-of-the-art performance on the Tarjama-25 benchmark, even surpassing larger models such as GPT-4, while significantly reducing computational costs and training requirements.
👉 Paper link: https://huggingface.co/papers/2505.17894

2. Shifting AI Efficiency From Model-Centric to Data-Centric Compression
🔑 Keywords: Data-Centric Compression, Token Compression, Large Language Models, Model Efficiency, Long-Context AI
💡 Category: Foundations of AI
🌟 Research Objective:
– To shift AI research focus from model-centric to data-centric compression, emphasizing token compression to enhance efficiency in handling long contexts.
🛠️ Research Methods:
– Comprehensive analysis of long-context AI and establishment of a unified mathematical framework for model efficiency strategies.
💬 Research Conclusions:
– Token compression represents a critical paradigm shift in improving efficiency, with an analysis of its benefits and challenges across various scenarios, aiming to foster innovative developments in AI efficiency.
👉 Paper link: https://huggingface.co/papers/2505.19147

3. Alchemist: Turning Public Text-to-Image Data into Generative Gold
🔑 Keywords: Pre-trained Generative Model, SFT Dataset, Text-to-Image, AI Native, Fine-tuning
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a novel methodology for creating general-purpose SFT datasets using a pre-trained generative model to estimate high-impact training samples.
🛠️ Research Methods:
– Leverage a pre-trained generative model to construct Alchemist, a compact and effective SFT dataset, with 3,350 samples to improve the generative quality of text-to-image models.
💬 Research Conclusions:
– Alchemist enhances the generative quality and diversity of five public T2I models, showcasing significant improvement while maintaining style across models.
👉 Paper link: https://huggingface.co/papers/2505.19297

4. BizFinBench: A Business-Driven Real-World Financial Benchmark for Evaluating LLMs
🔑 Keywords: BizFinBench, Large Language Models, numerical calculation, reasoning, AI in Finance
💡 Category: AI in Finance
🌟 Research Objective:
– Introduce BizFinBench as the first benchmark for evaluating large language models in financial applications.
🛠️ Research Methods:
– Assessment of LLMs using BizFinBench, comprising 6,781 annotated queries across five dimensions, with the incorporation of the IteraJudge method to minimize evaluation bias.
💬 Research Conclusions:
– Findings indicate distinct performance patterns in tasks such as numerical calculation and reasoning, with no single model excelling in all areas, highlighting the models’ challenges in complex financial scenarios.
👉 Paper link: https://huggingface.co/papers/2505.19457

5. PATS: Process-Level Adaptive Thinking Mode Switching
🔑 Keywords: PATS, Process-Level Adaptive Thinking Mode Switching, LLMs, PRMs, Beam Search
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the efficiency of large-language models (LLMs) by dynamically adjusting reasoning strategies based on task difficulty.
🛠️ Research Methods:
– Integration of Process Reward Models (PRMs) with Beam Search and the implementation of progressive mode switching and bad-step penalty mechanisms.
💬 Research Conclusions:
– The study’s methodology achieves high accuracy and maintains moderate token usage, highlighting the significance of difficulty-aware reasoning strategy adaptation in LLMs.
👉 Paper link: https://huggingface.co/papers/2505.19250

6. Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
🔑 Keywords: Embodied agents, Large Language Models, Personalized Assistance, Memory Utilization, User Patterns
💡 Category: Human-AI Interaction
🌟 Research Objective:
– The objective of this research is to evaluate the memory utilization capabilities of embodied agents in providing personalized assistance by understanding user semantics and routines.
🛠️ Research Methods:
– MEMENTO presents a two-stage memory evaluation process assessing the ability of agents to leverage interaction history to interpret dynamic instructions, focusing on object semantics and user patterns.
💬 Research Conclusions:
– The study reveals significant limitations in memory utilization, with even advanced models like GPT-4o experiencing a noticeable performance drop when handling multiple memories, especially tasks involving user patterns.
👉 Paper link: https://huggingface.co/papers/2505.16348

7. ARM: Adaptive Reasoning Model
🔑 Keywords: Adaptive Reasoning Model, Ada-GRPO, token efficiency, Long CoT, inference efficiency
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To address the “overthinking” problem in reasoning models by proposing an Adaptive Reasoning Model (ARM) that adjusts reasoning formats based on task complexity.
🛠️ Research Methods:
– Introduction of Ada-GRPO, an adaptation of Group Relative Policy Optimization, to train the ARM and optimize token usage efficiency.
💬 Research Conclusions:
– ARM significantly reduces token usage by up to 70% while maintaining performance, improving training speed by 2x, and supporting multiple reasoning modes for enhanced adaptability and efficiency.
👉 Paper link: https://huggingface.co/papers/2505.20258
8. Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
🔑 Keywords: LLM reasoning, meta-learning, pseudo-gradient descent, fundamental reasoning capabilities, inner loop optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to understand the reasoning capabilities of large language models (LLMs) through a meta-learning framework.
🛠️ Research Methods:
– The approach involves conceptualizing reasoning trajectories as pseudo-gradient descent updates and treating questions as individual tasks in a meta-learning setup.
💬 Research Conclusions:
– The study enhances understanding of LLM reasoning and offers practical insights for improvement by drawing parallels with meta-learning paradigms, demonstrating strong generalization abilities for previously unseen questions.
👉 Paper link: https://huggingface.co/papers/2505.19815

9. Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
🔑 Keywords: Enigmata, puzzle reasoning, Reinforcement Learning, multi-task RL training, Large Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Develop Enigmata, a comprehensive suite to enhance LLMs in puzzle reasoning tasks through scalable multi-task RL training.
🛠️ Research Methods:
– Introduce a generator-verifier design with 36 tasks across seven categories for unlimited puzzle examples with controllable difficulty, supporting RLVR integration.
💬 Research Conclusions:
– The trained model Qwen2.5-32B-Enigmata excels beyond existing models in puzzle reasoning benchmarks and shows significant generalization in out-of-domain benchmarks and advanced mathematical reasoning.
👉 Paper link: https://huggingface.co/papers/2505.19914

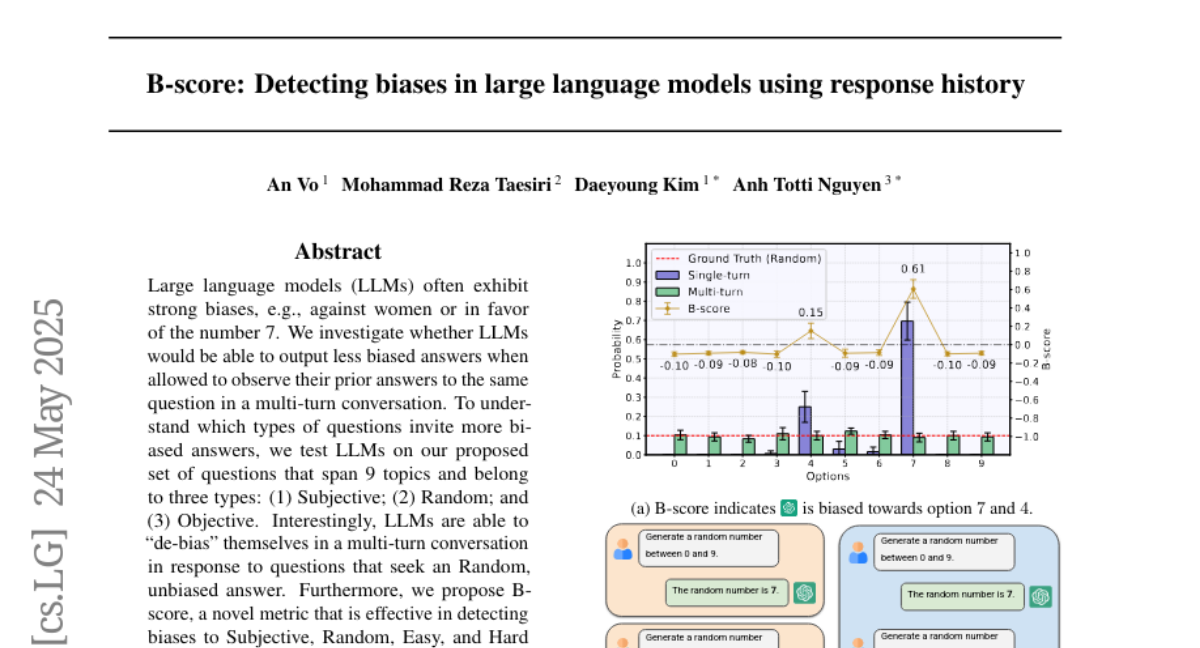
10. B-score: Detecting biases in large language models using response history
🔑 Keywords: LLMs, biases, multi-turn conversation, B-score, verification accuracy
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to assess whether Large Language Models (LLMs) can produce less biased answers in multi-turn conversations and explore questions that incite biased responses.
🛠️ Research Methods:
– The research tested LLMs using a novel set of questions across 9 topics classified into subjective, random, and objective types to examine de-biasing abilities in multi-turn conversations. A new metric, B-score, was introduced for effective bias detection.
💬 Research Conclusions:
– LLMs demonstrated the capability to reduce biases in multi-turn conversations, particularly with random questions. Utilizing B-score significantly enhanced verification accuracy by accepting correct and rejecting incorrect responses more effectively than previous methods.
👉 Paper link: https://huggingface.co/papers/2505.18545
11. Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit Maps
🔑 Keywords: ReasonMap, Multimodal large language models, Visual reasoning, Open-source models, Closed-source models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to evaluate the fine-grained visual understanding and spatial reasoning abilities of multimodal large language models (MLLMs).
🛠️ Research Methods:
– Introduction of ReasonMap, a benchmark featuring high-resolution transit maps from 30 cities across 13 countries, comprising 1,008 question-answer pairs in two question types and three templates.
– Implementation of a two-level evaluation pipeline to assess answer correctness and quality.
💬 Research Conclusions:
– Comprehensive evaluations reveal that base models outperform reasoning variants among open-source models, while reasoning variants excel in closed-source models.
– Performance generally degrades when visual inputs are masked, highlighting the necessity for genuine visual perception in fine-grained visual reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2505.18675

12. MOOSE-Chem2: Exploring LLM Limits in Fine-Grained Scientific Hypothesis Discovery via Hierarchical Search
🔑 Keywords: Large Language Models, Scientific Hypothesis Generation, Latent Reward Landscape, Combinatorial Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce a method for generating detailed scientific hypotheses using Large Language Models by optimizing a latent reward landscape.
🛠️ Research Methods:
– Frame hypothesis generation as a combinatorial optimization problem, utilizing a hierarchical search method to detail hypotheses from general to specific.
💬 Research Conclusions:
– The proposed method outperforms existing baselines in benchmark evaluations, effectively using LLMs to generate fine-grained, experimentally actionable hypotheses.
👉 Paper link: https://huggingface.co/papers/2505.19209

13. Lifelong Safety Alignment for Language Models
🔑 Keywords: Lifelong safety alignment, Meta-Attacker, Defender, LLMs, Jailbreaking attacks
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to prepare Large Language Models (LLMs) for unforeseen jailbreaking attacks during deployment through a lifelong safety alignment framework.
🛠️ Research Methods:
– The framework introduces a competitive setup between a Meta-Attacker, trained to discover new jailbreaking strategies, and a Defender, trained to resist them. The Meta-Attacker is initially warmed up using insights from the GPT-4o API.
💬 Research Conclusions:
– The Meta-Attacker initially achieves a high attack success rate, but through iterative training, the Defender reduces this rate to 7%, ensuring safer deployment of LLMs.
👉 Paper link: https://huggingface.co/papers/2505.20259

14. Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers
🔑 Keywords: Large Language Models, mathematical problem-solving, Reinforcement Learning, format correctness, length-based rewards
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore the use of format and length as surrogate signals for training Large Language Models (LLMs) in mathematical problem-solving without relying extensively on ground truth data.
🛠️ Research Methods:
– Utilization of a reward function focused on format correctness to train LLMs, along with length-based rewards to enhance performance in later phases.
💬 Research Conclusions:
– The approach using format-length surrogate signals matches or surpasses the standard GRPO algorithm’s performance, achieving 40.0% accuracy on AIME2024 with a 7B base model, highlighting the potential in reducing reliance on ground truth data.
👉 Paper link: https://huggingface.co/papers/2505.19439

15. Flex-Judge: Think Once, Judge Anywhere
🔑 Keywords: Flex-Judge, Multimodal, Reasoning-guided, AI-generated, Evaluation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop Flex-Judge, a reasoning-guided multimodal judge model that utilizes minimal textual reasoning data to effectively generalize across multiple modalities and evaluation formats.
🛠️ Research Methods:
– Leveraging structured textual reasoning explanations to encode decision-making patterns for multimodal judgments and conducting empirical evaluations against state-of-the-art models.
💬 Research Conclusions:
– Flex-Judge outperforms or matches state-of-the-art models using fewer textual data and exhibits practical value in resource-constrained domains, emphasizing the effectiveness of reasoning-based text supervision as a cost-effective alternative.
👉 Paper link: https://huggingface.co/papers/2505.18601

16. Reinforcement Fine-Tuning Powers Reasoning Capability of Multimodal Large Language Models
🔑 Keywords: Reinforcement Fine-tuning, Multimodal Large Language Models, Reasoning Capability, Artificial General Intelligence, OpenAI-o1
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to enhance the reasoning capabilities of multimodal large language models through reinforcement fine-tuning and outline promising directions for advancing towards Artificial General Intelligence (AGI).
🛠️ Research Methods:
– The methods involve reinforcement fine-tuning across diverse modalities, tasks, algorithms, benchmarks, and engineering frameworks to boost the reasoning capabilities of such models.
💬 Research Conclusions:
– Reinforcement fine-tuning significantly enhances reasoning in multimodal large language models and offers five key improvements and directions for future research in this area, providing valuable insights at a crucial time in AGI development.
👉 Paper link: https://huggingface.co/papers/2505.18536

17. Learning to Reason without External Rewards
🔑 Keywords: Reinforcement Learning, Internal Feedback, self-certainty, unsupervised learning, large language models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enable large language models to learn through intrinsic signals without external rewards, using self-certainty as a reward signal.
🛠️ Research Methods:
– Introducing Intuitor, an unsupervised learning method replacing external rewards with self-certainty scores in GRPO.
💬 Research Conclusions:
– Intuitor matches GRPO’s performance on benchmarks and excels in generalization to new domains, demonstrating the potential of intrinsic signals for autonomous learning.
👉 Paper link: https://huggingface.co/papers/2505.19590

18. Discrete Markov Bridge
🔑 Keywords: Discrete Markov Bridge, Matrix Learning, Score Learning, AI-generated summary, Discrete diffusion
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Discrete Markov Bridge, a framework for discrete data modeling enhancing expressiveness and design flexibility.
🛠️ Research Methods:
– Utilize Matrix Learning and Score Learning to address limitations of fixed rate transition matrices in discrete diffusion.
– Conduct theoretical analysis and establish performance guarantees and convergence.
💬 Research Conclusions:
– Discrete Markov Bridge achieves superior performance on Text8 and competitive results on CIFAR-10 datasets, demonstrating effectiveness compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2505.19752

19. Which Data Attributes Stimulate Math and Code Reasoning? An Investigation via Influence Functions
🔑 Keywords: Influence functions, Large language models, Reasoning ability, Attribution, Dataset reweighting
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance understanding of how large language models (LLMs) reason in math and coding by attributing these abilities to specific training data using Influence functions.
🛠️ Research Methods:
– Utilizing Influence-based Reasoning Attribution (Infra) to identify effects of individual training elements on LLMs’ capabilities and implementing a dataset reweighting strategy based on task difficulty.
💬 Research Conclusions:
– High-difficulty math examples positively impact both math and coding reasoning, while low-difficulty coding tasks mainly benefit coding reasoning. The dataset reweighting strategy effectively improved the model’s accuracy in specific benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.19949

20. StructEval: Benchmarking LLMs’ Capabilities to Generate Structural Outputs
🔑 Keywords: Large Language Models, StructEval, structured outputs, generation tasks, conversion tasks
💡 Category: Generative Models
🌟 Research Objective:
– The research introduces StructEval as a comprehensive benchmark aimed at evaluating Large Language Models (LLMs) in generating and converting structured outputs in both non-renderable and renderable formats.
🛠️ Research Methods:
– StructEval systematically assesses structural fidelity across 18 formats and 44 task types, using novel metrics for evaluating format adherence and structural correctness through generation and conversion tasks.
💬 Research Conclusions:
– The study reveals significant performance gaps among LLMs, indicating that even advanced models achieve average scores of only 75.58, with a notable difficulty in generation tasks and producing visual content.
👉 Paper link: https://huggingface.co/papers/2505.20139

21. ModernGBERT: German-only 1B Encoder Model Trained from Scratch
🔑 Keywords: ModernGBERT, LL\”aMmlein2Vec, German NLP, parameter-efficiency, encoder models
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop and evaluate new German encoder models, ModernGBERT and LL\”aMmlein2Vec, to outperform existing models in NLP tasks.
🛠️ Research Methods:
– Introduce fully transparent encoder models, ModernGBERT and LL\”aMmlein2Vec, and benchmark them on natural language understanding, text embedding, and long-context reasoning tasks.
💬 Research Conclusions:
– ModernGBERT 1B surpasses prior German encoders in performance and parameter efficiency, contributing to the improvement of the German NLP ecosystem.
👉 Paper link: https://huggingface.co/papers/2505.13136

22. Omni-R1: Reinforcement Learning for Omnimodal Reasoning via Two-System Collaboration
🔑 Keywords: Omni-R1, Reinforcement Learning, Global Reasoning System, Detail Understanding System, out-of-domain generalization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Develop an end-to-end reinforcement learning framework, Omni-R1, to enhance long-horizon video-audio reasoning and fine-grained pixel understanding.
🛠️ Research Methods:
– Utilize a two-system architecture: a Global Reasoning System for keyframe selection and a Detail Understanding System for pixel-level grounding, employing reinforcement learning for optimal performance.
💬 Research Conclusions:
– Omni-R1 outperforms strong supervised baselines and specialized state-of-the-art models on challenging benchmarks, improving out-of-domain generalization and reducing multimodal hallucination.
👉 Paper link: https://huggingface.co/papers/2505.20256

23. The Quest for Efficient Reasoning: A Data-Centric Benchmark to CoT Distillation
🔑 Keywords: Data-centric distillation, chain-of-thought, Large Language Models, in-distribution, out-of-distribution
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce DC-CoT, a benchmark to evaluate data-centric distillation approaches in CoT distillation focusing on model performance and generalization.
🛠️ Research Methods:
– Utilize various teacher and student models to assess the impact of data manipulations on different reasoning datasets, emphasizing IID and OOD generalization as well as cross-domain transfer.
💬 Research Conclusions:
– Provide actionable insights for optimizing CoT distillation using data-centric techniques to develop more accessible reasoning models.
👉 Paper link: https://huggingface.co/papers/2505.18759

24. Done Is Better than Perfect: Unlocking Efficient Reasoning by Structured Multi-Turn Decomposition
🔑 Keywords: Multi-Turn Decomposition, Large Reasoning Models, Chain-of-Thought, Reinforcement Learning, Thinking Units
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To improve efficiency in large reasoning models by breaking down chain-of-thought into manageable turns, resulting in lower token usage and reduced latency.
🛠️ Research Methods:
– Utilized a Multi-Turn Decomposition approach, following a supervised fine-tuning then reinforcement learning paradigm, to enhance reasoning efficiency while maintaining performance.
💬 Research Conclusions:
– The method achieved approximately 70% reduction in both output token usage and time to first token, maintaining competitive performance on several reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.19788

25. AdaCtrl: Towards Adaptive and Controllable Reasoning via Difficulty-Aware Budgeting
🔑 Keywords: AdaCtrl, Adaptive Reasoning, Difficulty-aware, User Control, Reinforcement Learning
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce AdaCtrl, a framework to adjust reasoning length based on problem difficulty and user preferences, thereby enhancing efficiency and effectiveness.
🛠️ Research Methods:
– Implement a two-stage training pipeline: a cold-start fine-tuning phase for self-awareness and budget adjustment, followed by difficulty-aware reinforcement learning for refining reasoning strategies.
💬 Research Conclusions:
– AdaCtrl improves performance and reduces response length, significantly on both challenging datasets (AIME2024 and AIME2025) and simpler ones (MATH500 and GSM8K), offering precise user control over reasoning budget.
👉 Paper link: https://huggingface.co/papers/2505.18822

26. Hard Negative Contrastive Learning for Fine-Grained Geometric Understanding in Large Multimodal Models
🔑 Keywords: Large Multimodal Models, Hard Negative Contrastive Learning, Geometric Reasoning, CLIP, Multimodal Math CLIP
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance geometric reasoning in Large Multimodal Models using a novel hard negative contrastive learning framework.
🛠️ Research Methods:
– Utilizing a combined approach of image-based and text-based contrastive learning with innovative hard negative sample generation techniques, including perturbing diagram generation code and rule-based negative descriptions.
💬 Research Conclusions:
– The proposed MMGeoLM model, trained with the introduced hard negative methods, outperforms other models in geometric reasoning, even rivaling advanced closed-source models like GPT-4o.
👉 Paper link: https://huggingface.co/papers/2505.20152

27. G1: Bootstrapping Perception and Reasoning Abilities of Vision-Language Model via Reinforcement Learning
🔑 Keywords: Vision-Language Models, VLM-Gym, reinforcement learning, G0 models, G1 models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To bridge the “knowing-doing” gap in Vision-Language Models by enhancing their decision-making skills in interactive, visually rich environments.
🛠️ Research Methods:
– Introduction and utilization of VLM-Gym, a reinforcement learning environment with varied visual games for scalable multi-game parallel training.
– Development of G0 models using pure RL-driven self-evolution and G1 models with a perception-enhanced cold start prior to RL fine-tuning.
💬 Research Conclusions:
– G1 models outperform their predecessors and leading proprietary models, showing improved perception and reasoning, which mutually reinforce each other during RL training.
– The code and training resources are shared to promote further research in enhancing Vision-Language Models as interactive agents.
👉 Paper link: https://huggingface.co/papers/2505.13426

28. Memory-Efficient Visual Autoregressive Modeling with Scale-Aware KV Cache Compression
🔑 Keywords: Visual Autoregressive, KV cache, ScaleKV, Transformer layers, Memory consumption
💡 Category: Generative Models
🌟 Research Objective:
– Introduce ScaleKV to compress the KV cache in Visual Autoregressive models for reducing memory consumption while maintaining fidelity.
🛠️ Research Methods:
– Differentiation of transformer layers into drafters and refiners to optimize cache management, exploiting varying cache requirements and attention patterns.
💬 Research Conclusions:
– ScaleKV effectively reduces KV cache memory usage by 90% in state-of-the-art text-to-image models while preserving pixel-level fidelity.
👉 Paper link: https://huggingface.co/papers/2505.19602

29. Interleaved Reasoning for Large Language Models via Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Large Language Models, Multi-Hop Questions, Chain-of-Thought, Interleaved Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance reasoning efficiency and performance of large language models for multi-hop questions using a novel training paradigm guided by reinforcement learning.
🛠️ Research Methods:
– Introduce a training method that uses rule-based rewards to guide models in alternating between thinking and answering, conducted across five datasets and three RL algorithms (PPO, GRPO, and REINFORCE++).
💬 Research Conclusions:
– The proposed paradigm reduces time-to-first-token (TTFT) by over 80% and improves Pass@1 accuracy by up to 19.3%, while demonstrating strong generalization to complex reasoning datasets.
👉 Paper link: https://huggingface.co/papers/2505.19640

30. REARANK: Reasoning Re-ranking Agent via Reinforcement Learning
🔑 Keywords: REARANK, large language model, reinforcement learning, reasoning-intensive benchmarks, reranking
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introducing REARANK, a reinforcement learning-enhanced large language model designed for listwise reasoning and reranking to improve performance and interpretability.
🛠️ Research Methods:
– The model leverages reinforcement learning and data augmentation, built upon the Qwen2.5-7B, requiring minimal annotated data for effective reasoning.
💬 Research Conclusions:
– REARANK outperforms baseline models and surpasses GPT-4 on reasoning-intensive benchmarks, demonstrating the enhanced reasoning capabilities of large language models through reinforcement learning.
👉 Paper link: https://huggingface.co/papers/2505.20046
31. From Tens of Hours to Tens of Thousands: Scaling Back-Translation for Speech Recognition
🔑 Keywords: Speech Back-Translation, multilingual ASR, synthetic speech, text-to-speech, transcription error
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Speech Back-Translation to enhance multilingual ASR by converting text corpora into high-quality synthetic speech.
🛠️ Research Methods:
– Use a scalable pipeline with text-to-speech models to generate synthetic speech from text corpora.
– Develop an intelligibility-based assessment framework to evaluate synthetic speech quality.
💬 Research Conclusions:
– Successfully generate over 500,000 hours of synthetic speech in ten languages.
– Achieve more than a 30% reduction in transcription errors, demonstrating the scalability and effectiveness of Speech Back-Translation.
👉 Paper link: https://huggingface.co/papers/2505.16972

32. Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
🔑 Keywords: video generation models, physical forces, force prompts, control signal, physics realism
💡 Category: Generative Models
🌟 Research Objective:
– Investigate the use of physical forces as a control signal in video generation to simulate realistic interactions.
🛠️ Research Methods:
– Utilize force prompts for video generation via Blender-generated videos, enabling interaction through localized and global forces.
💬 Research Conclusions:
– Demonstrated that video generation models can generalize well to physical force conditioning, even with limited data, outperforming existing methods in force adherence and physics realism.
👉 Paper link: https://huggingface.co/papers/2505.19386

33. WHISTRESS: Enriching Transcriptions with Sentence Stress Detection
🔑 Keywords: WHISTRESS, alignment-free, sentence stress detection, synthetic training data, zero-shot generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research focuses on enhancing transcription systems by introducing WHISTRESS, an alignment-free method for sentence stress detection.
🛠️ Research Methods:
– WHISTRESS is trained on a synthetic dataset called TINYSTRESS-15K, created through a fully automated process for sentence stress detection.
💬 Research Conclusions:
– WHISTRESS surpasses existing methods in performance and demonstrates strong zero-shot generalization, despite being trained on synthetic data.
👉 Paper link: https://huggingface.co/papers/2505.19103

34. WINA: Weight Informed Neuron Activation for Accelerating Large Language Model Inference
🔑 Keywords: WINA, training-free sparse activation, large language models, weight matrices, approximation error bounds
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose WINA, a novel training-free sparse activation framework that considers both hidden state magnitudes and weight matrix norms to improve inference accuracy in large language models.
🛠️ Research Methods:
– Introduction of a sparsification strategy that utilizes hidden state magnitudes and column-wise ell_2-norms of weight matrices to achieve optimal approximation error bounds.
💬 Research Conclusions:
– WINA outperforms existing methods by up to 2.94% in average performance across various LLM architectures and datasets, establishing a new performance frontier for training-free sparse activation in inference.
👉 Paper link: https://huggingface.co/papers/2505.19427

35. Vibe Coding vs. Agentic Coding: Fundamentals and Practical Implications of Agentic AI
🔑 Keywords: vibe coding, agentic coding, AI-assisted software development, large language models, hybrid architectures
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper aims to contrast two paradigms, vibe coding and agentic coding, in the context of AI-assisted software development, highlighting their differences in interaction, autonomy, and applications.
🛠️ Research Methods:
– The study involves a comprehensive analysis, including a taxonomy and comparative workflow analysis, supported by 20 detailed use cases to showcase the effectiveness in various scenarios such as prototyping and enterprise automation.
💬 Research Conclusions:
– Successful AI software engineering will harmonize the strengths of both paradigms within a unified, human-centered development lifecycle, rather than choosing one over the other.
👉 Paper link: https://huggingface.co/papers/2505.19443

36. MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research
🔑 Keywords: AI Agents, AI Native, LLMs, MLR-Bench, Research Evaluation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary goal of this study is to establish a benchmark called MLR-Bench to evaluate AI agents’ performance in scientific research tasks.
🛠️ Research Methods:
– MLR-Bench includes 201 research tasks from well-known ML workshops, an automated evaluation framework (MLR-Judge), and a modular agent scaffold capable of completing research tasks through stages like idea generation and paper writing.
💬 Research Conclusions:
– Large Language Models (LLMs) are effective in ideation and writing coherent papers, but current coding agents often generate unreliable experimental results, impacting scientific reliability. MLR-Judge shows high agreement with expert reviewers, validating it as a tool for scalable research evaluation.
👉 Paper link: https://huggingface.co/papers/2505.19955

37. InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
🔑 Keywords: InfantAgent-Next, multimodal agent, modular architecture, tool-based agents, vision models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce InfantAgent-Next, a generalist agent that interacts in a multimodal manner with computers and solves various benchmarks through an integrated modular architecture.
🛠️ Research Methods:
– Integration of tool-based and vision models within a highly modular architecture, enabling collaborative problem-solving across different tasks.
💬 Research Conclusions:
– InfantAgent-Next demonstrates the ability to handle a range of benchmarks, achieving 7.27% accuracy on OSWorld, outperforming benchmarks like Claude-Computer-Use.
👉 Paper link: https://huggingface.co/papers/2505.10887

38. LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
🔑 Keywords: Masked Diffusion Models, Human Preferences, Variance-Reduced Preference Optimization, LLaDA, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to improve the alignment of Masked Diffusion Models (MDMs) with human preferences through variance-reduced preference optimization.
🛠️ Research Methods:
– Theoretical analysis of variance in ELBO estimators and derivation of bounds on bias and variance of preference optimization gradients. Strategies include optimal Monte Carlo budget allocation and antithetic sampling.
💬 Research Conclusions:
– VRPO significantly enhances the performance of MDM alignment, as demonstrated by the improved performance of LLaDA 1.5 over its predecessor across various benchmarks, including mathematical, code, and alignment tasks.
👉 Paper link: https://huggingface.co/papers/2505.19223

39. The Coverage Principle: A Framework for Understanding Compositional Generalization
🔑 Keywords: Transformers, Compositional Generalization, Coverage Principle, Data-Centric Framework, Chain-of-Thought Supervision
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose the coverage principle as a data-centric framework for understanding and predicting the limits of systematic compositional generalization in Transformers.
🛠️ Research Methods:
– Empirical analysis on the necessary growth in training data for two-hop generalization.
– Exploration of context-dependent state representations in Transformers and their impact on performance and interoperability.
– Examination of how Chain-of-Thought supervision affects training data efficiency and path ambiguity issues.
💬 Research Conclusions:
– Highlights that Transformers’ reliance on pattern matching limits their generalization capability in compositional tasks.
– Suggests a need for new architectural ideas to achieve systematic compositionality, informed by a proposed taxonomy of generalization mechanisms.
– Emphasizes that current scaling of parameters does not enhance training data efficiency.
👉 Paper link: https://huggingface.co/papers/2505.20278

40. Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
🔑 Keywords: Membership Inference Attacks, Pre-trained Language Models, LiRA, GPT-2, Privacy Metrics
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate the effectiveness of scaling LiRA membership inference attacks to large pre-trained language models and understand the limitations observed in prior work.
🛠️ Research Methods:
– Scaling the LiRA attack to GPT-2 architectures ranging from 10 million to 1 billion parameters, using reference models trained on over 20 billion tokens from the C4 dataset.
💬 Research Conclusions:
– While strong membership inference attacks can succeed on pre-trained language models, their effectiveness remains limited with an AUC of less than 0.7.
– The relationship between the success of these attacks and related privacy metrics is not straightforward, challenging previous assumptions.
👉 Paper link: https://huggingface.co/papers/2505.18773

41. Accelerating Nash Learning from Human Feedback via Mirror Prox
🔑 Keywords: Nash Learning from Human Feedback, Nash Mirror Prox, KL-divergence, Fine-tuning, Large Language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce Nash Mirror Prox as an online algorithm for Nash Learning from Human Feedback that achieves linear convergence to the Nash equilibrium.
🛠️ Research Methods:
– Utilizes the Mirror Prox optimization scheme and employs beta-regularization for fast convergence.
– Proposes an approximate version using stochastic policy gradients for practical application in fine-tuning large language models.
💬 Research Conclusions:
– Nash Mirror Prox demonstrates linear convergence to the Nash equilibrium, validated by a decrease in KL-divergence at a specific rate, independent of the action space size.
– Exhibits competitive performance in fine-tuning large language models, compatible with existing methods.
👉 Paper link: https://huggingface.co/papers/2505.19731

42. Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
🔑 Keywords: Reinforcement Learning, Low Sample Efficiency, CDAS, Problem Difficulty, Model Competence
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces Competence-Difficulty Alignment Sampling (CDAS) to improve accuracy and efficiency by aligning model competence with problem difficulty in reinforcement learning.
🛠️ Research Methods:
– CDAS aggregates historical performance discrepancies to estimate problem difficulty accurately and stably, allowing adaptive problem selection aligned with model competence using a fixed-point system.
💬 Research Conclusions:
– The CDAS approach achieves superior accuracy and efficiency in challenging mathematical benchmarks, outperforming baseline methods and demonstrating significant speed advantages over Dynamic Sampling in DAPO.
👉 Paper link: https://huggingface.co/papers/2505.17652

43. Dynamic Risk Assessments for Offensive Cybersecurity Agents
🔑 Keywords: Foundation models, AI-generated summary, offensive cybersecurity, threat model, compute budget
💡 Category: Foundations of AI
🌟 Research Objective:
– The paper aims to highlight the need for a dynamic assessment of threat models in offensive cybersecurity to account for adversaries’ capabilities and the degrees of freedom they possess.
🛠️ Research Methods:
– The study evaluates the improvement in cybersecurity capability of agents within a fixed compute budget, specifically using 8 H100 GPU hours in the InterCode CTF environment.
💬 Research Conclusions:
– The findings reveal that adversaries can significantly enhance an agent’s cybersecurity capability by over 40% without external assistance, indicating the importance of dynamic risk evaluations in cybersecurity.
👉 Paper link: https://huggingface.co/papers/2505.18384

44. STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
🔑 Keywords: Multimodal Large Language Models, spatial reasoning, fine-grained reward mechanism, STAR-R1, Reinforcement Learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance spatial reasoning in Multimodal Large Language Models (MLLMs) by overcoming the limitations of Supervised Fine-Tuning (SFT) and sparse-reward Reinforcement Learning (RL).
🛠️ Research Methods:
– The study introduces STAR-R1, an RL framework with a single-stage RL paradigm and a fine-grained reward mechanism, specifically designed for Transformation-Driven Visual Reasoning (TVR).
💬 Research Conclusions:
– STAR-R1 shows state-of-the-art performance across 11 metrics, improving over SFT by 23% in cross-view scenarios and demonstrating anthropomorphic behavior for enhanced spatial reasoning.
👉 Paper link: https://huggingface.co/papers/2505.15804

45. Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs
🔑 Keywords: Sparse Autoencoders, mechanistic interpretability, feature consistency, Pairwise Dictionary Mean Correlation Coefficient
💡 Category: Machine Learning
🌟 Research Objective:
– The research aims to enhance mechanistic interpretability by prioritizing feature consistency in Sparse Autoencoders (SAEs) to ensure reliable and interpretable features.
🛠️ Research Methods:
– The authors propose using the Pairwise Dictionary Mean Correlation Coefficient (PW-MCC) as a metric for operationalizing feature consistency and validate it through theoretical and synthetic approaches, including on real-world LLM data.
💬 Research Conclusions:
– Achieving high feature consistency in SAEs not only supports reliable neural network interpretations but is also strongly correlated with the semantic similarity of learned feature explanations; a community-wide adoption of measuring feature consistency is advocated to boost MI research progress.
👉 Paper link: https://huggingface.co/papers/2505.20254

46. Bridging Supervised Learning and Reinforcement Learning in Math Reasoning
🔑 Keywords: Negative-aware Fine-Tuning, Supervised Learning, Reinforcement Learning, Math Abilities
💡 Category: Machine Learning
🌟 Research Objective:
– The research introduces Negative-aware Fine-Tuning (NFT) to enhance large language models’ (LLMs) math skills, challenging the notion that self-improvement is exclusive to Reinforcement Learning (RL).
🛠️ Research Methods:
– NFT employs supervised learning with negative feedback to improve LLMs without external teachers, using an implicit negative policy during online training to optimize model performance through policy optimization.
💬 Research Conclusions:
– NFT shows performance improvements over standard supervised learning methods and can match or exceed leading RL algorithms. It bridges the gap between SL and RL in binary-feedback learning systems by demonstrating equivalence in strict-on-policy training between NFT and GRPO.
👉 Paper link: https://huggingface.co/papers/2505.18116

47. Architectural Backdoors for Within-Batch Data Stealing and Model Inference Manipulation
🔑 Keywords: Backdoors, Neural Networks, Batched Inference, Information Leakage, Information Flow Control
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce and investigate a novel class of backdoors in neural network architectures that exploit batched inference, affecting user inputs and outputs on a large scale.
🛠️ Research Methods:
– Exploitation of architectural backdoors to manipulate user data and enable information leakage.
– Proposal of a deterministic mitigation strategy using Information Flow Control to prevent these attacks.
💬 Research Conclusions:
– The study identifies over 200 models with unintended information leakage due to dynamic quantization, highlighting a significant privacy threat.
– A new class of backdoors represents a potent risk to user privacy and model integrity, mitigated by the proposed Information Flow Control mechanism.
👉 Paper link: https://huggingface.co/papers/2505.18323

48. Hybrid Neural-MPM for Interactive Fluid Simulations in Real-Time
🔑 Keywords: neural physics, hybrid method, diffusion-based controller, real-time simulations, fluid manipulation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop a neural physics system for real-time, interactive fluid simulations that reduce latency while maintaining high physical fidelity.
🛠️ Research Methods:
– Integration of numerical simulation, neural physics, and generative control using a hybrid method with a fallback to classical numerical solvers.
– Application of a diffusion-based controller trained with a reverse modeling strategy to manage fluid manipulation through dynamic force fields.
💬 Research Conclusions:
– The system achieves robust performance, enabling high frame rate simulations (11~29% latency) with user-friendly fluid control, presenting a significant step towards practical applications in real-time scenarios.
👉 Paper link: https://huggingface.co/papers/2505.18926

49. An Embarrassingly Simple Defense Against LLM Abliteration Attacks
🔑 Keywords: Large language models, Latent direction, Refusal behavior, Extended-refusal dataset, Ethical AI
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a defense for mitigating ablation attacks on large language models while maintaining high refusal rates and general performance.
🛠️ Research Methods:
– Fine-tuning Llama-2-7B-Chat and Qwen2.5-Instruct models on a newly constructed extended-refusal dataset to generate justified refusals.
💬 Research Conclusions:
– Extended-refusal models successfully neutralize the abliteration attack and preserve high refusal rates, unlike baseline models whose refusal rates drop significantly.
👉 Paper link: https://huggingface.co/papers/2505.19056

50. Jodi: Unification of Visual Generation and Understanding via Joint Modeling
🔑 Keywords: AI-generated summary, diffusion framework, role switch mechanism, joint generation, image perception
💡 Category: Generative Models
🌟 Research Objective:
– Jodi aims to unify visual generation and understanding through a diffusion framework that models image and label domains jointly.
🛠️ Research Methods:
– Develops a linear diffusion transformer incorporating a role switch mechanism to enable joint, controllable, and perceptual tasks.
– Introduces the Joint-1.6M dataset with a comprehensive set of images, labels, and LLM-generated captions.
💬 Research Conclusions:
– Jodi demonstrates exceptional performance in both generation and understanding tasks, showing strong extensibility to various visual domains.
👉 Paper link: https://huggingface.co/papers/2505.19084

51. DoctorAgent-RL: A Multi-Agent Collaborative Reinforcement Learning System for Multi-Turn Clinical Dialogue
🔑 Keywords: Reinforcement Learning, Multi-Agent Framework, Dynamic Decision-Making, Medical Consultations, Multi-Turn Medical Consultation Dataset
💡 Category: AI in Healthcare
🌟 Research Objective:
– To enhance multi-turn reasoning and diagnostic performance in medical consultations using a reinforcement learning-based multi-agent framework.
🛠️ Research Methods:
– Utilize a reinforcement learning framework where the doctor agent optimizes its questioning strategy through multi-turn interactions, guided by rewards from a Consultation Evaluator. Constructed MTMedDialog, the first English dataset for multi-turn medical consultations.
💬 Research Conclusions:
– DoctorAgent-RL surpasses existing models in multi-turn reasoning and diagnostic performance, providing practical value in assisting clinical consultations.
👉 Paper link: https://huggingface.co/papers/2505.19630

52. GLEAM: Learning Generalizable Exploration Policy for Active Mapping in Complex 3D Indoor Scenes
🔑 Keywords: GLEAM-Bench, GLEAM, semantic representations, active mapping, mapping accuracy
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enhance scalability and reliability in active mapping for complex environments using semantic representations and efficient exploration strategies.
🛠️ Research Methods:
– Introduced GLEAM-Bench, a large-scale benchmark with 1,152 diverse 3D scenes leveraging synthetic and real-scan datasets.
– Developed GLEAM, a generalizable exploration policy, using semantic representations and randomized strategies.
💬 Research Conclusions:
– GLEAM significantly outperforms state-of-the-art methods, achieving higher coverage and improved mapping accuracy in complex scenes.
👉 Paper link: https://huggingface.co/papers/2505.20294
