AI Native Daily Paper Digest – 20250529

1. The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
🔑 Keywords: Policy Entropy, Entropy Dynamics, LLMs, Reinforcement Learning, Exploration
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To prevent policy entropy collapse and improve exploration in reinforcement learning with large language models (LLMs).
🛠️ Research Methods:
– Investigated the transformation equation between entropy and downstream performance and analyzed entropy dynamics both theoretically and empirically.
– Proposed techniques like Clip-Cov and KL-Cov to control entropy by managing high-covariance tokens.
💬 Research Conclusions:
– Understanding and controlling entropy dynamics is essential for continued exploration and improved policy performance in reinforcement learning.
– Techniques such as Clip-Cov and KL-Cov encourage exploration and help prevent entropy collapse, leading to better downstream performance.
👉 Paper link: https://huggingface.co/papers/2505.22617

2. SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents
🔑 Keywords: SWE-rebench, Reinforcement Learning, LLM-based agents, contamination-free benchmark, GitHub
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to improve the evaluation of reinforcement learning models by introducing a novel pipeline to extract real-world software engineering tasks from GitHub, creating a diverse and dynamic dataset called SWE-rebench.
🛠️ Research Methods:
– Develop an automated and scalable process to continuously extract interactive SWE tasks from GitHub, resulting in a benchmark free from contamination issues.
💬 Research Conclusions:
– The study demonstrates that certain language models may show inflated performance on traditional benchmarks, and it emphasizes the importance of fresh, interactive SWE tasks to accurately evaluate the rapidly advancing LLMs.
👉 Paper link: https://huggingface.co/papers/2505.20411

3. R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing
🔑 Keywords: Large Language Models, Small Language Models, neural token routing, token generation, Pareto frontier
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance efficiency and performance in Small Language Models by leveraging Large Language Models selectively for critical reasoning tasks using the Roads to Rome (R2R) framework.
🛠️ Research Methods:
– Developed a neural token routing method that applies LLMs selectively for path-divergent tokens, with automatic data generation to identify these tokens and train a lightweight routing model.
– Combined R1-1.5B and R1-32B models within the R2R framework and evaluated the setup on math, coding, and QA benchmarks.
💬 Research Conclusions:
– R2R achieves notable improvements in efficiency and accuracy, with a significant wall-clock speedup compared to R1-32B while maintaining comparable performance. The method advances the efficiency of test-time scaling.
👉 Paper link: https://huggingface.co/papers/2505.21600
4. Skywork Open Reasoner 1 Technical Report
🔑 Keywords: Reinforcement Learning, Chain-of-Thought, Entropy Collapse, AI-generated summary, Skywork-OR1
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce Skywork-OR1, a reinforcement learning approach that enhances the accuracy of long Chain-of-Thought models by addressing entropy collapse.
🛠️ Research Methods:
– Implementing a scalable RL model called Skywork-OR1, conducting comprehensive ablation studies, and investigating entropy dynamics.
💬 Research Conclusions:
– Skywork-OR1 improves performance over previous models like DeepSeek-R1 and Qwen3 across benchmarks such as AIME24, AIME25, and LiveCodeBench, with notable accuracy gains and competitive reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2505.22312

5. Sherlock: Self-Correcting Reasoning in Vision-Language Models
🔑 Keywords: self-correction, reasoning VLMs, Visual Perturbation, Llama3.2-Vision-11B
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study explores the enhancement of reasoning vision-language models (VLMs) through self-correction to improve accuracy with limited annotated data.
🛠️ Research Methods:
– Introduces a self-correction and self-improvement framework called Sherlock, featuring trajectory-level self-correction and a visual perturbation-based preference data construction method.
💬 Research Conclusions:
– Sherlock achieves significant results across benchmarks, outperforming several models while utilizing less than 20% annotated data, reaching an average accuracy of 65.4% after self-correction.
👉 Paper link: https://huggingface.co/papers/2505.22651

6. Unsupervised Post-Training for Multi-Modal LLM Reasoning via GRPO
🔑 Keywords: MM-UPT, GRPO, unsupervised post-training, self-rewarding mechanism, multi-modal large language models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance Multi-modal Large Language Models (MLLMs) through unsupervised continual learning without manual annotations by employing a stable online RL algorithm, GRPO.
🛠️ Research Methods:
– Developed the MM-UPT framework which builds upon GRPO and uses a self-rewarding mechanism with majority voting to replace traditional reward signals for unsupervised post-training of MLLMs.
💬 Research Conclusions:
– MM-UPT significantly improves reasoning abilities in MLLMs like Qwen2.5-VL-7B, outperforming prior unsupervised methods and nearing supervised GRPO results, while also demonstrating potential for scalable self-improvement by integrating synthetic questions.
👉 Paper link: https://huggingface.co/papers/2505.22453

7. SageAttention2++: A More Efficient Implementation of SageAttention2
🔑 Keywords: SageAttention2, FP8 Matmul, FlashAttention, Attention Efficiency, Quantization
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To improve attention efficiency and speed up matrix multiplication without losing accuracy by utilizing FP8 Matmul in FP16.
🛠️ Research Methods:
– Utilization of FP8 Matmul instructions accumulated in FP16 which are 2x faster than previously used implementations, enhancing the speed of attention mechanisms in various models.
💬 Research Conclusions:
– SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same accuracy, proving to be an effective method for accelerating models in language, image, and video generation with negligible loss in end-to-end metrics.
👉 Paper link: https://huggingface.co/papers/2505.21136

8. Advancing Multimodal Reasoning via Reinforcement Learning with Cold Start
🔑 Keywords: Multimodal reasoning, Large language models, Supervised fine-tuning, Reinforcement learning, Chain-of-thought reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance multimodal reasoning capabilities in large language models through a two-stage approach that combines supervised fine-tuning and reinforcement learning.
🛠️ Research Methods:
– Implement a two-stage approach comprising of supervised fine-tuning as a cold start and reinforcement learning via GRPO to refine multimodal reasoning abilities.
💬 Research Conclusions:
– The combined approach of supervised fine-tuning and reinforcement learning outperforms methods that utilize either technique alone in multimodal reasoning benchmarks, achieving state-of-the-art performance with models of 3B and 7B scales.
👉 Paper link: https://huggingface.co/papers/2505.22334

9. Fostering Video Reasoning via Next-Event Prediction
🔑 Keywords: Next-event prediction, MLLMs, temporal reasoning, future video segments, self-supervised learning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose next-event prediction (NEP) as a learning task that enables MLLMs to perform temporal reasoning over video inputs using self-supervised learning.
🛠️ Research Methods:
– Implement NEP by segmenting videos into past and future frames, using the future segments as signals for temporal reasoning.
– Curate the V1-33K dataset with 33,000 video segments to support the NEP task.
– Explore video instruction-tuning strategies and introduce FutureBench to evaluate predictive coherence.
💬 Research Conclusions:
– NEP serves as a scalable and effective training paradigm for enhancing temporal reasoning capabilities in MLLMs.
👉 Paper link: https://huggingface.co/papers/2505.22457

10. RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination
🔑 Keywords: RenderFormer, neural rendering, transformer architecture, global illumination, sequence-to-sequence transformation
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce RenderFormer, a transformer-based neural rendering pipeline capable of rendering images from triangle representations without the need for per-scene training.
🛠️ Research Methods:
– Utilize a two-stage pipeline involving a view-independent stage for modeling triangle-to-triangle light transport and a view-dependent stage for converting tokens representing rays into pixel values using the transformer architecture.
💬 Research Conclusions:
– Demonstrations show RenderFormer is effective across scenes of varying complexity in shape and light transport, optimizing the rendering process with minimal prior constraints.
👉 Paper link: https://huggingface.co/papers/2505.21925

11. Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and Preference Alignment
🔑 Keywords: Chain-of-Zoom, single-image super-resolution, autoregressive chain, backbone SR model, multi-scale-aware text prompts
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to enhance single-image super-resolution (SISR) models to achieve extreme magnification with high quality using the Chain-of-Zoom (CoZ) framework.
🛠️ Research Methods:
– Utilizes an autoregressive chain of intermediate scale-states and multi-scale-aware prompts.
– Employs a vision-language model (VLM) for generating multi-scale-aware text prompts.
– Fine-tunes the prompt extractor using Generalized Reward Policy Optimization (GRPO) for better alignment with human preferences.
💬 Research Conclusions:
– The Chain-of-Zoom framework enables a standard 4x diffusion SR model to achieve more than 256x enlargement with high perceptual quality and fidelity without additional training.
👉 Paper link: https://huggingface.co/papers/2505.18600

12. DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
🔑 Keywords: DeepResearchGym, reproducibility, search API, LLM-as-a-judge, open-source
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce DeepResearchGym, an open-source framework to evaluate deep research systems with a reproducible search API.
🛠️ Research Methods:
– Combines a reproducible search API indexing large web corpora with a dense retriever and approximate nearest neighbor search.
– Uses LLM-as-a-judge assessments for evaluating deep research systems.
💬 Research Conclusions:
– DeepResearchGym performs comparably to commercial APIs, maintaining consistent performance rankings across metrics, and aligns with human evaluation preferences.
👉 Paper link: https://huggingface.co/papers/2505.19253

13. Universal Reasoner: A Single, Composable Plug-and-Play Reasoner for Frozen LLMs
🔑 Keywords: Large Language Models, Parameter-Efficient Fine-Tuning, UniR, Modular Composition, Cost-Efficient
💡 Category: Natural Language Processing
🌟 Research Objective:
– The aim of the research is to introduce UniR, a lightweight, composable reasoning module, enhancing reasoning capabilities of Large Language Models without high computational demands.
🛠️ Research Methods:
– UniR is a standalone module trained independently and added to frozen LLMs for inference, enabling modular composition and application across various tasks like mathematical reasoning and machine translation.
💬 Research Conclusions:
– UniR significantly outperforms existing baseline methods by enhancing LLM reasoning skills cost-effectively and adaptably, ensuring strong generalization and maintaining core capabilities.
👉 Paper link: https://huggingface.co/papers/2505.19075

14. Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
🔑 Keywords: JQL, multilingual embeddings, heuristic filtering methods, cross-lingual transferability
💡 Category: Natural Language Processing
🌟 Research Objective:
– The primary goal is to curate high-quality multilingual training data using pretrained multilingual embeddings, aimed at outperforming heuristic methods for improved model training.
🛠️ Research Methods:
– The paper introduces JQL, a systematic approach utilizing lightweight annotators based on pretrained multilingual embeddings for efficient data curation across diverse languages.
💬 Research Conclusions:
– JQL substantially outperforms current heuristic filtering methods and enhances downstream model training quality as well as data retention rates, providing valuable insights for multilingual dataset development.
👉 Paper link: https://huggingface.co/papers/2505.22232

15. SVRPBench: A Realistic Benchmark for Stochastic Vehicle Routing Problem
🔑 Keywords: vehicle routing, robust routing, state-of-the-art RL solvers, distributional shift, uncertain urban conditions
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to introduce SVRPBench, a benchmark for vehicle routing under uncertain urban conditions to simulate realistic delivery scenarios.
🛠️ Research Methods:
– This benchmark encompasses over 500 instances, featuring elements such as time-dependent congestion and probabilistic accidents, incorporating multi-depot and multi-vehicle setups.
💬 Research Conclusions:
– State-of-the-art RL solvers are found to degrade over 20% under distributional shift, whereas classical and metaheuristic methods remain more robust.
– The release of the dataset and evaluation suite encourages the design of solvers that better adapt to real-world uncertainty.
👉 Paper link: https://huggingface.co/papers/2505.21887

16. WebDancer: Towards Autonomous Information Seeking Agency
🔑 Keywords: AI Native, Reinforcement Learning, Agentic Systems, Multi-step Reasoning
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a framework for end-to-end agentic information-seeking agents using a data-centric and training-stage perspective.
🛠️ Research Methods:
– Implementing a four-stage process: data construction, trajectory sampling, supervised fine-tuning, and reinforcement learning.
💬 Research Conclusions:
– Empirical evaluations with benchmarks demonstrated strong performance, showcasing the effectiveness and potential of the proposed training paradigm.
👉 Paper link: https://huggingface.co/papers/2505.22648
17. What Makes for Text to 360-degree Panorama Generation with Stable Diffusion?
🔑 Keywords: AI Native, pre-trained diffusion models, attention modules, panoramic image generation, UniPano
💡 Category: Generative Models
🌟 Research Objective:
– To analyze the roles of attention module matrices in fine-tuning diffusion models for panoramic image generation and introduce the UniPano framework.
🛠️ Research Methods:
– Hypothesize and examine distinct behaviors of trainable diffusion model components when adapted to panoramic data, focusing on the attention mechanisms.
💬 Research Conclusions:
– Query and key matrices handle shared information between domains and are less crucial for panorama generation, while value and output matrices are vital for adapting pre-trained knowledge to panoramic domains.
– The UniPano framework enhances speed and memory efficiency in generating high-resolution panoramic images, outperforming existing methods.
👉 Paper link: https://huggingface.co/papers/2505.22129

18. Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment
🔑 Keywords: Large Language Model, Reinforcement Learning, Multi-turn Tool-use, Turn-level Credit Assignment, Markov Decision Processes
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The paper aims to enhance the reasoning capabilities of Large Language Model agents in multi-turn tool-use scenarios using Reinforcement Learning.
🛠️ Research Methods:
– Introduces a fine-grained turn-level advantage estimation strategy for precise credit assignment in multi-turn interactions, integrating it into various RL algorithms like Group Relative Preference Optimization.
💬 Research Conclusions:
– Implementations demonstrate the effectiveness of the MDP framework and turn-level credit assignment in multi-turn reasoning, achieving 100% success in tool execution and 50% exact answer match accuracy, surpassing baseline performances.
👉 Paper link: https://huggingface.co/papers/2505.11821

19. Towards Dynamic Theory of Mind: Evaluating LLM Adaptation to Temporal Evolution of Human States
🔑 Keywords: Large Language Models (LLMs), Theory of Mind (ToM), dynamic mental states, DynToM, performance gap
💡 Category: Human-AI Interaction
🌟 Research Objective:
– Evaluate LLMs’ ability to track and understand the temporal progression of mental states.
🛠️ Research Methods:
– Introduction of DynToM benchmark, using a systematic four-step framework with 1,100 social contexts, 5,500 scenarios, and 78,100 validated questions.
💬 Research Conclusions:
– LLMs perform 44.7% worse than humans on average in tracking and reasoning about dynamic mental states, highlighting significant limitations in modeling dynamic human mental states.
👉 Paper link: https://huggingface.co/papers/2505.17663
20. Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach
🔑 Keywords: personalized safety, PENGUIN, RAISE, safety scores, user-specific information
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the personalized safety of Large Language Models (LLMs) without retraining them by using user-specific information.
🛠️ Research Methods:
– Introduced PENGUIN, a benchmark comprising 14,000 scenarios across seven sensitive domains.
– Developed RAISE, a training-free, two-stage framework for strategic acquisition of user-specific background information.
💬 Research Conclusions:
– Personalization improved safety scores by 43.2% and demonstrated the importance of selective information gathering.
– RAISE framework improves safety scores by 31.6% with a low interaction cost of 2.7 user queries on average.
👉 Paper link: https://huggingface.co/papers/2505.18882

21. LIMOPro: Reasoning Refinement for Efficient and Effective Test-time Scaling
🔑 Keywords: Large Language Models, Chain-of-Thought, Perplexity-based Importance Refinement, Reasoning Benchmarks, Token Usage
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces a framework called PIR that optimizes reasoning steps in large language models by pruning low-importance functional elements to achieve concise reasoning chains with enhanced accuracy and reduced computational demands.
🛠️ Research Methods:
– The PIR framework quantitatively evaluates the importance of reasoning steps based on their impact on answer prediction confidence, systematically pruning only low-importance functional elements while preserving the progressive reasoning components.
💬 Research Conclusions:
– Models fine-tuned on PIR-optimized data demonstrate improved accuracy (+0.9% to +6.6%) with reduced token usage (-3% to -41%), and the approach shows strong generalizability across various model sizes, data sources, and token budgets, offering a practical solution for efficient deployment of reasoning-capable LLMs.
👉 Paper link: https://huggingface.co/papers/2505.19187

22. Let’s Predict Sentence by Sentence
🔑 Keywords: pretrained language models, semantic embeddings, contextual embeddings, continuous inference
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate whether pretrained language models can transition to reasoning over structured semantic units.
🛠️ Research Methods:
– Developed a framework to adapt pretrained token-level language models to operate in sentence space using semantic and contextual embeddings.
– Evaluated two types of embeddings under discrete and continuous inference regimes.
💬 Research Conclusions:
– Contextual embeddings under continuous inference showed competitive performance with Chain-of-Thought while significantly reducing inference-time FLOPs.
– Demonstrated early scalability and modular adaptation with the introduction of SentenceLens for visualizing latent trajectories.
👉 Paper link: https://huggingface.co/papers/2505.22202

23. Token Reduction Should Go Beyond Efficiency in Generative Models — From Vision, Language to Multimodality
🔑 Keywords: Transformer architectures, token reduction, generative modeling, multimodal integration, hallucinations
💡 Category: Generative Models
🌟 Research Objective:
– Position token reduction as a fundamental principle influencing model architecture and applications in generative modeling, beyond efficiency.
🛠️ Research Methods:
– Analyze token reduction’s role across vision, language, and multimodal systems, highlighting potential improvements in model architecture and learning strategies.
💬 Research Conclusions:
– Token reduction can enhance multimodal integration, mitigate hallucinations, maintain coherence, and improve training stability. It can drive new model architectures and learning strategies, improving robustness and interpretability.
👉 Paper link: https://huggingface.co/papers/2505.18227

24. VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning
🔑 Keywords: VRAG-RL, Reinforcement Learning, Visually Rich Information, Visual Perception Tokens, Model-based Reward
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance reasoning and visual information handling in retrieval-augmented generation (RAG) methods using reinforcement learning, specifically tailored for complex reasoning across visually rich information.
🛠️ Research Methods:
– Integration of visual perception tokens in RAG methods and utilization of specialized action spaces, such as cropping and scaling, alongside model-based reward systems for optimized retrieval performance.
💬 Research Conclusions:
– The VRAG-RL framework addresses key limitations of existing multi-modal RAG approaches by allowing for more effective reasoning trajectories and optimization, highlighting improved real-world application alignment.
👉 Paper link: https://huggingface.co/papers/2505.22019

25. CHIMERA: A Knowledge Base of Idea Recombination in Scientific Literature
🔑 Keywords: Recombination, Knowledge Base, AI Domain, LLM-based Extraction Model, Creative Directions
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Build a large-scale knowledge base (CHIMERA) from scientific paper abstracts to analyze recombination examples and inspire new creative directions in AI.
🛠️ Research Methods:
– Utilize an LLM-based extraction model on a manually annotated corpus to extract recombination examples from AI research papers.
💬 Research Conclusions:
– The resulting knowledge base, CHIMERA, includes over 28K examples and aids in predicting new recombination directions that may inspire researchers.
👉 Paper link: https://huggingface.co/papers/2505.20779

26. EPiC: Efficient Video Camera Control Learning with Precise Anchor-Video Guidance
🔑 Keywords: EPiC, 3D camera control, anchor videos, ControlNet, video diffusion models
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces EPiC, a framework aimed at achieving efficient and precise 3D camera control in video diffusion models without relying on costly camera trajectory annotations.
🛠️ Research Methods:
– EPiC leverages first-frame visibility masking to construct high-quality anchor videos and integrates these using a lightweight ControlNet module, maintaining low resource consumption.
💬 Research Conclusions:
– EPiC achieves state-of-the-art performance on I2V tasks, demonstrating robust performance both quantitatively and qualitatively, with strong zero-shot generalization capabilities in video-to-video scenarios.
👉 Paper link: https://huggingface.co/papers/2505.21876

27. Thinking with Generated Images
🔑 Keywords: AI-generated images, vision generation, visual reasoning, self-critique, chain-of-thought
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce a novel paradigm called Thinking with Generated Images that transforms how large multimodal models engage in visual reasoning by integrating text and vision modalities through the spontaneous generation of intermediate visual steps.
🛠️ Research Methods:
– Implement two complementary mechanisms: vision generation with intermediate visual subgoals to decompose and integrate complex tasks, and vision generation with self-critique to generate, critique, and refine visual hypotheses.
💬 Research Conclusions:
– Demonstrated effectiveness with substantial improvements over baseline approaches in complex scenarios, achieving up to 50% relative improvement. The approach enables models to engage in visual imagination and iterative refinement similar to human creative and analytical thinking.
👉 Paper link: https://huggingface.co/papers/2505.22525

28. Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems
🔑 Keywords: hard-negative mining, enterprise search, re-ranking models, embedding models, domain-specific enterprise data
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance domain-specific enterprise search by addressing semantic mismatches through a scalable hard-negative mining framework.
🛠️ Research Methods:
– The proposed method dynamically selects semantically challenging irrelevant documents and integrates diverse embedding models to improve re-ranking models’ performance.
💬 Research Conclusions:
– Implementation in a cloud services domain showed a 15% improvement in MRR@3 and 19% in MRR@10, demonstrating its effectiveness over current techniques.
👉 Paper link: https://huggingface.co/papers/2505.18366

29. Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction
🔑 Keywords: Protein Prediction, Autoregressive Decoder, Multi-task Learning, Self-supervised Decoder Pre-training, AI-generated Summary
💡 Category: Machine Learning
🌟 Research Objective:
– To develop Prot2Token, a unified framework that enhances efficiency and accuracy in diverse protein prediction tasks using an autoregressive decoder and task tokens.
🛠️ Research Methods:
– Utilizes Prot2Token’s autoregressive decoder conditioned on pre-trained protein encoders and guided by learnable task tokens for multi-task learning.
💬 Research Conclusions:
– Demonstrated significant speedups and matching or exceeding performance compared to specialized models, offering a versatile, high-throughput approach for protein modeling.
👉 Paper link: https://huggingface.co/papers/2505.20589

30. Pitfalls of Rule- and Model-based Verifiers — A Case Study on Mathematical Reasoning
🔑 Keywords: Reinforcement Learning, Verifiable Reward, Rule-based Verifiers, Model-based Verifiers, Mathematical Reasoning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Examine the effectiveness and reliability of rule-based and model-based verifiers in reinforcement learning with verifiable reward.
🛠️ Research Methods:
– Conducted a comprehensive analysis of various verifiers in both static evaluation and reinforcement learning training scenarios within mathematical reasoning domains.
💬 Research Conclusions:
– Rule-based verifiers show high false negative rates due to format variance which affects reinforcement learning performance as the policy model becomes stronger.
– Model-based verifiers, while showing higher static evaluation accuracy, are vulnerable to exploitation, leading to false positives and inflated rewards.
👉 Paper link: https://huggingface.co/papers/2505.22203

31. Text2Grad: Reinforcement Learning from Natural Language Feedback
🔑 Keywords: Text2Grad, Reinforcement Learning, span-level gradients, free-form textual feedback, token spans
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces Text2Grad, a paradigm aimed at converting human textual feedback into span-level gradients to optimize language models efficiently and precisely.
🛠️ Research Methods:
– Text2Grad consists of three components: a feedback-annotation pipeline that pairs critiques with token spans, a fine-grained reward model for predicting span-level rewards, and a span-level policy optimizer for back-propagating natural-language gradients.
💬 Research Conclusions:
– Text2Grad outperforms scalar-reward reinforcement learning and prompt-only baselines in tasks like summarization, code generation, and question answering, offering improved task metrics and richer interpretability.
👉 Paper link: https://huggingface.co/papers/2505.22338

32. RICO: Improving Accuracy and Completeness in Image Recaptioning via Visual Reconstruction
🔑 Keywords: RICO, Image Recaptioning, Text-to-Image Model, MLLM, DPO
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to enhance the accuracy and completeness of image captions by introducing a new framework called RICO, which uses visual reconstruction to refine discrepancies in captions.
🛠️ Research Methods:
– The method involves reconstructing captions into reference images using a text-to-image model and identifying discrepancies through a multimodal large language model (MLLM). An iterative process refines the captioning focus, while RICO-Flash employs DPO to improve efficiency.
💬 Research Conclusions:
– The proposed RICO framework significantly enhances caption accuracy, outperforming most baselines by approximately 10% on the CapsBench and CompreCap datasets.
👉 Paper link: https://huggingface.co/papers/2505.22613

33. FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding
🔑 Keywords: FS-DAG, Few-Shot Learning, Visually Rich Document Understanding, Information Extraction, Computational Efficiency
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce FS-DAG, a modular model architecture designed for few-shot learning in visually rich document understanding under resource-constrained conditions.
🛠️ Research Methods:
– Utilizes a modular framework with domain-specific and language/vision specific backbones to adapt to various document types, effectively handling OCR errors, misspellings, and domain shifts.
💬 Research Conclusions:
– Demonstrates FS-DAG’s high performance with fewer than 90M parameters, achieving substantial improvements in convergence speed and performance for information extraction tasks compared to state-of-the-art methods.
👉 Paper link: https://huggingface.co/papers/2505.17330

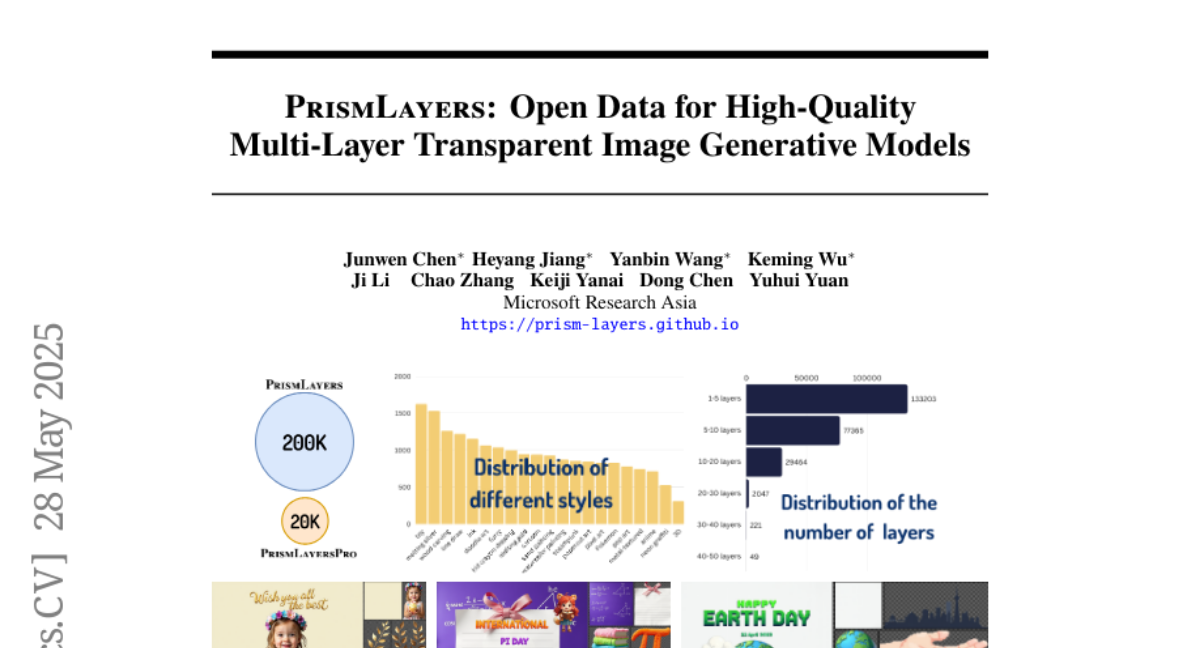
34. PrismLayers: Open Data for High-Quality Multi-Layer Transparent Image Generative Models
🔑 Keywords: AI-generated summary, PrismLayers, diffusion models, ART+, MultiLayerFLUX
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a dataset and model for generating high-quality, multi-layer transparent images, addressing the lack of existing multi-layer transparent data.
🛠️ Research Methods:
– Released the PrismLayers dataset and a training-free synthesis pipeline using diffusion models, along with presenting a multi-layer generation model, ART+.
💬 Research Conclusions:
– ART+ outperforms the original ART model in user studies, matching the visual quality of modern text-to-image generation models and providing a foundation for multi-layer transparent image generation research.
👉 Paper link: https://huggingface.co/papers/2505.22523
35. Just as Humans Need Vaccines, So Do Models: Model Immunization to Combat Falsehoods
🔑 Keywords: Generative AI, immunization, misinformation, labeled falsehoods, supervised vaccine
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to reduce misinformation generation by fine-tuning Generative AI models with labeled falsehoods, akin to biological immunization.
🛠️ Research Methods:
– Fine-tuning generative models using small, curated sets of explicitly labeled falsehoods as a “vaccine,” designed to improve the model’s ability to identify and dismiss misinformation.
💬 Research Conclusions:
– The models treated with this immunization approach exhibit a significant decrease in misinformation generation compared to baseline models, showcasing the effectiveness of using fact-checked falsehoods as a defensive mechanism.
👉 Paper link: https://huggingface.co/papers/2505.17870

36. GRE Suite: Geo-localization Inference via Fine-Tuned Vision-Language Models and Enhanced Reasoning Chains
🔑 Keywords: Visual Language Models, geo-localization, structured reasoning, multi-stage strategy, explainability
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective of this research is to enhance geo-localization tasks by integrating structured reasoning chains into Visual Language Models to achieve accurate and interpretable location inference.
🛠️ Research Methods:
– The study introduces the GRE Suite, which includes a detailed dataset (GRE30K), a model with multi-stage reasoning capabilities, and a comprehensive evaluation benchmark (GREval-Bench) to improve reasoning and precision in geo-localization tasks.
💬 Research Conclusions:
– The GRE Suite significantly improves performance in geo-localization tasks across all levels of granularity, highlighting the effectiveness of reasoning-augmented Visual Language Models in complex geographic inference tasks.
👉 Paper link: https://huggingface.co/papers/2505.18700

37. One-Way Ticket:Time-Independent Unified Encoder for Distilling Text-to-Image Diffusion Models
🔑 Keywords: Time-independent Unified Encoder TiUE, Text-to-Image diffusion models, UNet encoders, semantic information, perceptual realism
💡 Category: Generative Models
🌟 Research Objective:
– To reduce inference time and improve diversity and quality in Text-to-Image diffusion models by optimizing the use of encoder features across decoder time steps.
🛠️ Research Methods:
– Introduced the Time-independent Unified Encoder TiUE in a loop-free image generation approach, utilizing a one-pass scheme to share encoder features and incorporating a KL divergence term for noise prediction regularization.
💬 Research Conclusions:
– TiUE outperforms state-of-the-art methods, producing more diverse and realistic images while maintaining computational efficiency.
👉 Paper link: https://huggingface.co/papers/2505.21960

38. Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
🔑 Keywords: Safe-Sora, AI-generated content, generative watermarking, Mamba architecture
💡 Category: Generative Models
🌟 Research Objective:
– To develop Safe-Sora, a framework for embedding graphical watermarks directly into the AI video generation process, enhancing quality, fidelity, and robustness.
🛠️ Research Methods:
– Introduces a hierarchical coarse-to-fine adaptive matching mechanism and uses a 3D wavelet transform-enhanced Mamba architecture to embed watermarks.
– Implements a novel spatiotemporal local scanning strategy and applies state space models to watermarking for the first time.
💬 Research Conclusions:
– Safe-Sora demonstrates state-of-the-art performance in video quality, watermark fidelity, and robustness, attributed to its innovative methodologies.
👉 Paper link: https://huggingface.co/papers/2505.12667

39. Meta-Learning an In-Context Transformer Model of Human Higher Visual Cortex
🔑 Keywords: BraInCoRL, higher visual cortex, in-context learning, transformer architecture, interpretability
💡 Category: Machine Learning
🌟 Research Objective:
– To improve the modeling of higher visual cortex neural responses using a transformer-based in-context learning approach.
🛠️ Research Methods:
– Utilized few-shot examples and a flexible transformer architecture to predict voxelwise neural responses without additional finetuning.
– Optimized the model for in-context learning by conditioning on image features and voxel activations.
💬 Research Conclusions:
– BraInCoRL consistently outperformed existing voxelwise encoder designs in low-data scenarios and demonstrated strong generalizability to new subjects and stimuli.
– The framework enhances interpretability of neural signals and allows for interpretable mappings from natural language queries to voxel selectivity.
👉 Paper link: https://huggingface.co/papers/2505.15813

40. Benchmarking Recommendation, Classification, and Tracing Based on Hugging Face Knowledge Graph
🔑 Keywords: HuggingKG, Knowledge Graph, Hugging Face, ML Resource Management, HuggingBench
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The creation of HuggingKG, a large-scale knowledge graph, to enhance open-source machine learning resource management and enable advanced queries and analyses.
🛠️ Research Methods:
– Construction of a knowledge graph with 2.6 million nodes and 6.2 million edges, capturing domain-specific relations and attributes.
💬 Research Conclusions:
– HuggingKG and HuggingBench are expected to advance research in open source resource sharing and management by revealing unique characteristics and providing publicly available resources.
👉 Paper link: https://huggingface.co/papers/2505.17507

41. Efficient Data Selection at Scale via Influence Distillation
🔑 Keywords: Influence Distillation, LLM fine-tuning, second-order information, landmark-based approximation, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce Influence Distillation for optimal training data selection to enhance LLM fine-tuning performance using second-order information.
🛠️ Research Methods:
– Develop a framework using a landmark-based approximation to assign model-specific weights, derived for Gradient Descent and Adam optimizers.
💬 Research Conclusions:
– Influence Distillation achieves competitive or superior results compared to state-of-the-art methods, improving speed by up to 3.5 times.
👉 Paper link: https://huggingface.co/papers/2505.19051

42. MangaVQA and MangaLMM: A Benchmark and Specialized Model for Multimodal Manga Understanding
🔑 Keywords: MangaOCR, MangaVQA, MangaLMM, Multimodal Models, Visual Question Answering
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research aims to evaluate and advance large multimodal models in understanding manga narratives by introducing new benchmarks and a specialized model.
🛠️ Research Methods:
– Introduction of two benchmarks: MangaOCR for in-page text recognition and MangaVQA for evaluating contextual understanding via visual question answering.
– Development of MangaLMM, a manga-specialized model finetuned from open-source LMM Qwen2.5-VL.
💬 Research Conclusions:
– The benchmarks and MangaLMM provide a comprehensive foundation for assessing and improving multimodal models’ understanding of richly narrative manga domains.
👉 Paper link: https://huggingface.co/papers/2505.20298

43. Styl3R: Instant 3D Stylized Reconstruction for Arbitrary Scenes and Styles
🔑 Keywords: 3D stylization, multi-view consistency, feed-forward reconstruction, sparse-view images
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to achieve rapid 3D stylization with sparse-view images, ensuring multi-view consistency and high-quality style transfer while maintaining reconstruction accuracy.
🛠️ Research Methods:
– Introduces a novel feed-forward model with a branched architecture to decouple structure modeling and appearance shading, leveraging an identity loss for pre-training and fine-tuning.
💬 Research Conclusions:
– The approach enables efficient, high-quality stylized 3D content creation, outperforming existing methods in multi-view consistency and efficiency on both in-domain and out-of-domain datasets.
👉 Paper link: https://huggingface.co/papers/2505.21060

44. HoPE: Hybrid of Position Embedding for Length Generalization in Vision-Language Models
🔑 Keywords: HoPE, Vision-Language Models, frequency allocation, dynamic temporal scaling, long-context
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance the long-context performance of Vision-Language Models (VLMs) in videos by proposing HoPE, a hybrid of position embedding.
🛠️ Research Methods:
– The study explores the impact of different frequency allocation strategies on VLMs and introduces a hybrid frequency allocation strategy along with dynamic temporal scaling to improve semantic modeling in long-context scenarios.
💬 Research Conclusions:
– HoPE demonstrates superior performance in long video understanding and retrieval tasks, consistently outperforming existing methods across four video benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.20444

45. MUSEG: Reinforcing Video Temporal Understanding via Timestamp-Aware Multi-Segment Grounding
🔑 Keywords: MUSEG, Reinforcement Learning, Temporal Understanding, Multi-segment Grounding
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to enhance the temporal understanding of large language models in multimodal settings, focusing on improving alignment with video segments and excelling in temporal reasoning tasks.
🛠️ Research Methods:
– Developed MUSEG, an RL-based method introducing timestamp-aware multi-segment grounding for better temporal alignment and reasoning, with a customized RL training recipe and phased rewards.
💬 Research Conclusions:
– MUSEG significantly outperforms existing methods in temporal grounding and time-sensitive video QA tasks, generalizing well across diverse temporal understanding scenarios.
👉 Paper link: https://huggingface.co/papers/2505.20715

46. AITEE — Agentic Tutor for Electrical Engineering
🔑 Keywords: Agent-based tutoring system, Electrical engineering, AI-generated summary, Graph-based similarity measure, Socratic dialogue
💡 Category: AI in Education
🌟 Research Objective:
– To develop and assess AITEE, an agent-based tutoring system designed to enhance learning in electrical engineering through natural circuit interaction and guided questioning.
🛠️ Research Methods:
– Implementation of an adapted circuit reconstruction process and retrieval augmented generation approach, utilizing a graph-based similarity measure and parallel Spice simulations to improve accuracy.
💬 Research Conclusions:
– AITEE demonstrates superior performance in domain-specific knowledge application, fostering scalable, personalized, and effective learning environments in electrical engineering education.
👉 Paper link: https://huggingface.co/papers/2505.21582

47. Unveiling Instruction-Specific Neurons & Experts: An Analytical Framework for LLM’s Instruction-Following Capabilities
🔑 Keywords: Sparse components, Large Language Models, Instruction-following, Fine-tuning, HexaInst
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study investigates the impact of sparse computational components on the instruction-following capabilities of Large Language Models (LLMs).
🛠️ Research Methods:
– Introduction of HexaInst, an instructional dataset spanning six categories, and SPARCOM, a framework for identifying and evaluating sparse components in LLMs.
💬 Research Conclusions:
– Demonstrated the functional generality and uniqueness of sparse components in LLMs, highlighting their crucial role in instruction execution and providing insights into how LLMs internalize instruction-following behavior.
👉 Paper link: https://huggingface.co/papers/2505.21191

48. Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese
🔑 Keywords: LLM biases, Simplified Chinese, Traditional Chinese, AI Ethics, decision-making
💡 Category: Natural Language Processing
🌟 Research Objective:
– To examine whether Large Language Models (LLMs) show performance biases between Simplified and Traditional Chinese in regional term and name choice tasks.
🛠️ Research Methods:
– Two benchmark tasks designed to reflect real-world scenarios: regional term choice and regional name choice, with performance audits of 11 leading commercial LLM services and open-source models.
💬 Research Conclusions:
– LLMs tended to favor Simplified Chinese in regional term choice tasks and favored Traditional Chinese names in regional name choice tasks, with biases linked to training data representation and tokenization differences.
– A need for further analysis of LLM biases is highlighted, and an open-sourced benchmark dataset is provided for future evaluations.
👉 Paper link: https://huggingface.co/papers/2505.22645

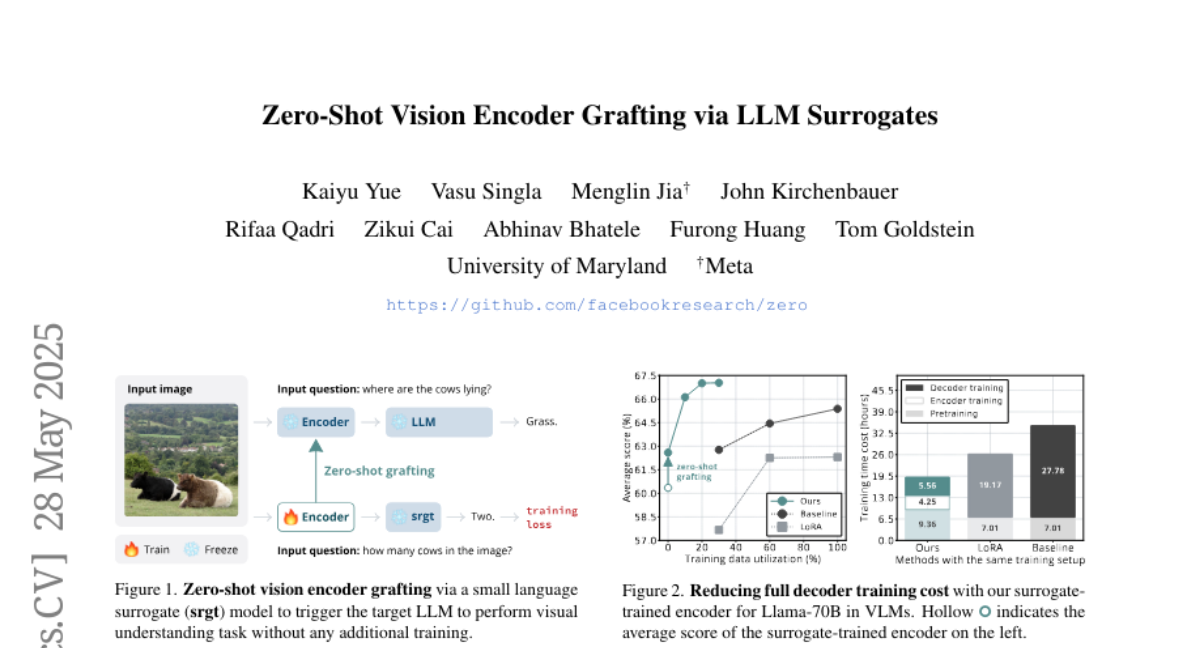
49. Zero-Shot Vision Encoder Grafting via LLM Surrogates
🔑 Keywords: Vision language models, Vision encoder, Large language model, Zero-shot grafting, Embedding space
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to reduce training costs while enhancing the performance of Vision language models by leveraging small surrogate models before transferring to large language models.
🛠️ Research Methods:
– Training vision encoders with small surrogate models that share the same embedding space and representation language as the large target language models, facilitating a seamless transfer through zero-shot grafting.
💬 Research Conclusions:
– The surrogate training approach significantly reduces overall VLM training costs by approximately 45% and achieves performance comparable to full decoder training in certain benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.22664