AI Native Daily Paper Digest – 20250530
1. Table-R1: Inference-Time Scaling for Table Reasoning
🔑 Keywords: Table Reasoning, Distillation, RLVR, Generalization, LLMs
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To explore inference-time scaling on table reasoning tasks using post-training strategies.
🛠️ Research Methods:
– Developed two strategies: distillation from reasoning traces and reinforcement learning with verifiable rewards (RLVR).
– Introduced a large-scale dataset and applied the GRPO algorithm.
💬 Research Conclusions:
– The Table-R1-Zero model matches or exceeds the performance of GPT-4.1 and demonstrates strong generalization using significantly fewer parameters.
👉 Paper link: https://huggingface.co/papers/2505.23621

2. Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
🔑 Keywords: Spatial-MLLM, AI-generated, semantic features, spatial understanding, 3D structure features
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance spatial reasoning in multimodal large language models (MLLMs) using a framework based on purely 2D observations.
🛠️ Research Methods:
– Implemented a dual-encoder architecture with a pretrained 2D visual encoder for semantic features and a spatial encoder for 3D structure features.
– Proposed a space-aware frame sampling strategy for improved spatial reasoning and trained the model with a Spatial-MLLM-120k dataset using supervised fine-tuning and GRPO.
💬 Research Conclusions:
– The novel Spatial-MLLM framework achieves state-of-the-art performance in visual-based spatial understanding and reasoning tasks.
👉 Paper link: https://huggingface.co/papers/2505.23747
3. VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos
🔑 Keywords: VF-Eval, MLLMs, AI-generated content, AIGC, RePrompt
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VF-Eval as a benchmark for evaluating MLLMs in interpreting AI-generated content videos across four specific tasks.
🛠️ Research Methods:
– Proposed four tasks to assess MLLMs: coherence validation, error awareness, error type detection, and reasoning evaluation.
– Evaluated the performance of 13 MLLMs, including GPT-4.1, using the VF-Eval benchmark.
💬 Research Conclusions:
– The benchmark reveals that even top MLLMs like GPT-4.1 face challenges in consistently performing well across all tasks.
– Demonstrates the benefits of aligning MLLMs more closely with human feedback through the RePrompt experiment to enhance video generation capabilities.
👉 Paper link: https://huggingface.co/papers/2505.23693

4. The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason
🔑 Keywords: LLMs, reward noise, RPR, reinforcement learning, rapid convergence
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Investigate the impact of reward noise on the post-training of large language models (LLMs).
🛠️ Research Methods:
– Utilized reasoning pattern rewards (RPR) and test robustness with substantial reward noise, including manual reward flipping.
💬 Research Conclusions:
– LLMs show strong resilience to reward noise and achieve high performance without strict correctness verification, demonstrating the importance of calibrating noisy reward models using RPR for enhanced performance.
👉 Paper link: https://huggingface.co/papers/2505.22653

5. ZeroGUI: Automating Online GUI Learning at Zero Human Cost
🔑 Keywords: Vision-Language Models, GUI Agents, Online Learning, Reinforcement Learning
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The research aims to overcome the limitations of offline learning in GUI Agents by developing ZeroGUI, an online learning framework that minimizes human intervention.
🛠️ Research Methods:
– ZeroGUI employs Vision-Language Models for automatic task generation and reward estimation. It uses a two-stage online reinforcement learning approach for training GUI Agents.
💬 Research Conclusions:
– Experiments on advanced GUI Agents like UI-TARS and Aguvis show that ZeroGUI significantly improves performance in OSWorld and AndroidLab environments.
👉 Paper link: https://huggingface.co/papers/2505.23762

6. VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
🔑 Keywords: VideoReasonBench, video reasoning, vision-centric, large language models, latent state
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary aim is to introduce VideoReasonBench as a benchmark for evaluating complex vision-centric video reasoning, addressing the limitations of current video understanding benchmarks.
🛠️ Research Methods:
– VideoReasonBench assesses models on three levels of video reasoning: recalling visual information, inferring latent states, and predicting beyond visible content. It distinctly requires models to process fine-grained video operations.
💬 Research Conclusions:
– The study finds that many state-of-the-art multimodal LLMs struggle with complex video reasoning, with GPT-4o only achieving 6.9% accuracy, while Gemini-2.5-Pro reaches 56.0%. An extended thinking budget is critical for enhancing performance on VideoReasonBench.
👉 Paper link: https://huggingface.co/papers/2505.23359
7. Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
🔑 Keywords: EvoScale, reinforcement learning, evolutionary process, test-time scaling, small language models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance the performance of small language models on real-world software engineering tasks using an evolutionary and reinforcement learning-based method.
🛠️ Research Methods:
– Introduce EvoScale, a method that treats generation as an evolutionary process, using selection and mutation to improve output distribution.
– Implement reinforcement learning to enable the model to self-evolve and self-improve its scoring without relying on external verifiers.
💬 Research Conclusions:
– The EvoScale method enabled a 32B parameter model to match or surpass the performance of models with over 100B parameters on the SWE-Bench-Verified task, using fewer samples.
– The approach reduces costs associated with extensive data curation and verifies during real-world applications.
👉 Paper link: https://huggingface.co/papers/2505.23604

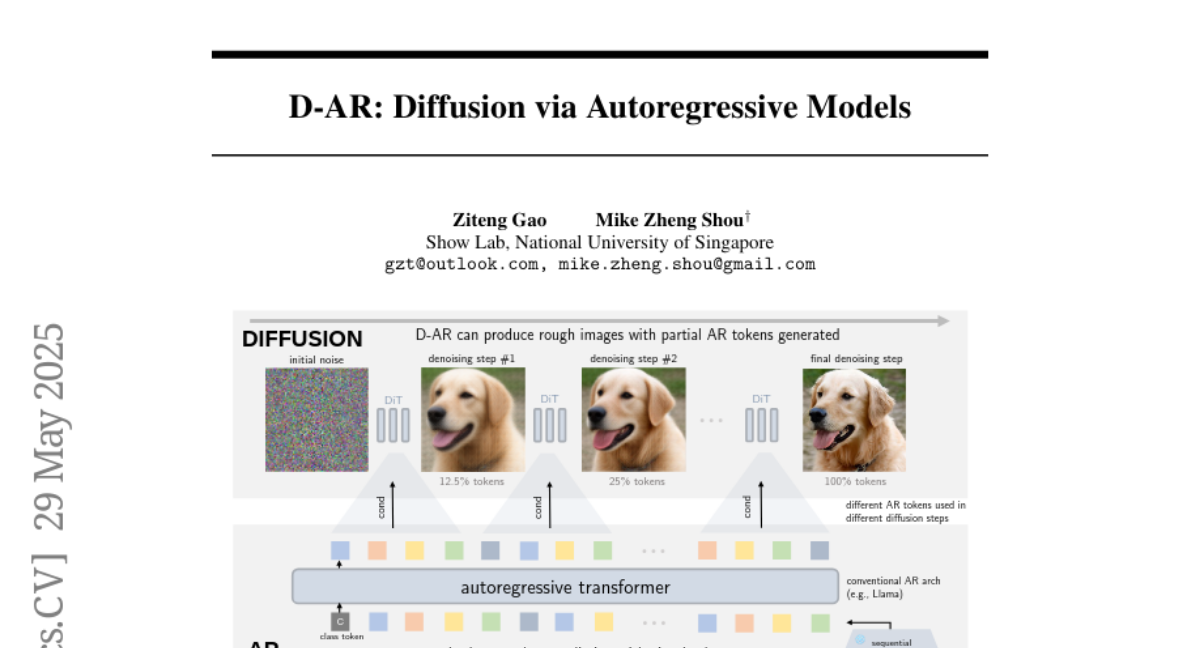
8. D-AR: Diffusion via Autoregressive Models
🔑 Keywords: Diffusion via Autoregressive Models, Autoregressive Modeling, Large Language Model, Discrete Tokens, Image Generation
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to redefine image diffusion as an autoregressive task, utilizing a large language model backbone to achieve high-quality image generation with layout control.
🛠️ Research Methods:
– The paper employs a tokenizer that converts images into sequences of discrete tokens. These tokens follow a coarse-to-fine order, aligning with autoregressive modeling, to mirror the diffusion process in image space.
💬 Research Conclusions:
– The authors report achieving a 2.09 FID on the ImageNet benchmark using their proposed method, showcasing the capability for consistent image previews and zero-shot layout-controlled synthesis.
👉 Paper link: https://huggingface.co/papers/2505.23660
9. cadrille: Multi-modal CAD Reconstruction with Online Reinforcement Learning
🔑 Keywords: Multi-modal, CAD Reconstruction, Vision-Language Models, Reinforcement Learning, State-of-the-Art
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to propose a multi-modal CAD reconstruction model that integrates vision-language models to enhance the accuracy and accessibility of CAD systems by utilizing multiple data input modalities.
🛠️ Research Methods:
– The study employs a two-stage pipeline: supervised fine-tuning on large-scale procedurally generated data followed by reinforcement learning fine-tuning using online feedback.
💬 Research Conclusions:
– The proposed model sets new state-of-the-art performance benchmarks across multiple challenging datasets, including real-world scenarios, demonstrating enhanced robustness and generalizability over single-modal methods.
👉 Paper link: https://huggingface.co/papers/2505.22914

10. UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning
🔑 Keywords: Multimodal Large Language Models, Self-Improving Post-Training, Generated Images, Supervised Fine-Tuning, Group Relative Policy Optimization
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce UniRL, a self-improving post-training method for unified multimodal large language models that enhances generation and understanding tasks without external data.
🛠️ Research Methods:
– Utilize generated images as training data, employ Supervised Fine-Tuning (SFT), and Group Relative Policy Optimization (GRPO) for model optimization.
💬 Research Conclusions:
– UniRL requires no external image data, improves task performance, reduces imbalance between generation and understanding, and is efficient in training steps.
👉 Paper link: https://huggingface.co/papers/2505.23380

11. Are Reasoning Models More Prone to Hallucination?
🔑 Keywords: Large Reasoning Models, Hallucination, Post-Training, Cognitive Behaviors, Model Uncertainty
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To investigate the susceptibility of large reasoning models to hallucination and the factors contributing to it.
🛠️ Research Methods:
– Conducted a holistic evaluation of hallucination in large reasoning models, analyzing post-training pipelines and cognitive behaviors.
– Analyzed the impact of cold start supervised fine-tuning and verifiable reward RL vs. distillation and RL training without fine-tuning.
💬 Research Conclusions:
– Findings indicate that cold start supervised fine-tuning and verifiable reward RL can alleviate hallucinations in large reasoning models, whereas other methods might introduce more nuanced hallucinations.
– Discrepancies in model behavior are characterized by flaw repetition and think-answer mismatch.
– Modeled increased hallucination is linked with the misalignment between model uncertainty and factual accuracy.
👉 Paper link: https://huggingface.co/papers/2505.23646

12. Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
🔑 Keywords: Diffusion LLMs, KV Cache, Parallel Decoding, Confidence-aware, Non-autoregressive text generation
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to improve the inference speed of diffusion-based large language models (Diffusion LLMs) without significant quality loss.
🛠️ Research Methods:
– Introduces a novel block-wise approximate KV Cache mechanism and a confidence-aware parallel decoding strategy to enhance the performance of Diffusion LLMs.
💬 Research Conclusions:
– The proposed methods achieved up to 27.6 times throughput improvement with minimal accuracy loss, making Diffusion LLMs more comparable to autoregressive models and suitable for practical deployment.
👉 Paper link: https://huggingface.co/papers/2505.22618

13. SWE-bench Goes Live!
🔑 Keywords: AI-generated summary, live-updatable benchmark, automated curation pipeline, reproducible execution, SWE-bench-Live
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The primary purpose is to introduce SWE-bench-Live, a continuously updatable benchmark designed to improve upon existing benchmarks by addressing issues like scalability, overfitting, and data contamination in evaluating large language models (LLMs).
🛠️ Research Methods:
– Implementation of an automated curation pipeline (\method) that streamlines task instance creation and environment setup, along with the evaluation of agent frameworks and LLMs on the SWE-bench-Live benchmark.
💬 Research Conclusions:
– Results show that SWE-bench-Live, with its dynamic and real-world approach, reveals substantial performance gaps compared to static benchmarks and facilitates more rigorous and contamination-resistant evaluation in software development settings.
👉 Paper link: https://huggingface.co/papers/2505.23419

14. Multi-Domain Explainability of Preferences
🔑 Keywords: AI Native, large language models, concept-based explanations, preference prediction, explainability
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop an automated method for generating concept-based explanations and improving preference predictions in large language models (LLMs).
🛠️ Research Methods:
– Utilizes concept-based vectors and a Hierarchical Multi-Domain Regression model to capture domain-general and domain-specific effects.
– Curates a dataset across diverse domains to evaluate preference predictions and explanations.
💬 Research Conclusions:
– The proposed method outperforms baseline models in preference prediction and provides enhanced explainability.
– Introduces a new paradigm for explainability in LLMs, aligning responses to human preferences and improving prediction accuracy in application-driven settings.
👉 Paper link: https://huggingface.co/papers/2505.20088

15. AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
🔑 Keywords: AnySplat, Novel View Synthesis, 3D Gaussian Primitives, Camera Intrinsics, Zero Shot Evaluations
💡 Category: Computer Vision
🌟 Research Objective:
– To introduce AnySplat, a feed forward network capable of performing novel view synthesis from uncalibrated image collections without the need for known camera poses or per scene optimization.
🛠️ Research Methods:
– Developed a unified design using 3D Gaussian primitives to encode scene geometry and appearance, aligning them with camera intrinsics and extrinsics in a single forward pass.
💬 Research Conclusions:
– AnySplat matches or surpasses traditional pose-aware baselines in both sparse and dense scenarios, while reducing rendering latency compared to optimization-based approaches, enabling real-time novel view synthesis in unconstrained settings.
👉 Paper link: https://huggingface.co/papers/2505.23716

16. Train Sparse Autoencoders Efficiently by Utilizing Features Correlation
🔑 Keywords: Sparse Autoencoders, Kronecker product decomposition, latent representation, mAND, differentiable activation function
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance the training efficiency of Sparse Autoencoders at scale using Kronecker product decomposition and to improve interpretability and performance with the mAND function.
🛠️ Research Methods:
– Introducing KronSAE, a novel architecture that factorizes the latent representation via Kronecker product decomposition.
– Developing mAND, a differentiable binary AND function, to assist with interpretability and performance.
💬 Research Conclusions:
– KronSAE effectively reduces memory and computational overhead for Sparse Autoencoders.
– The mAND function enhances the interpretability and performance within the proposed factorized framework.
👉 Paper link: https://huggingface.co/papers/2505.22255

17. FAMA: The First Large-Scale Open-Science Speech Foundation Model for English and Italian
🔑 Keywords: FAMA, open science, speech foundation models, pseudo-labeled speech, open-source
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce FAMA, a family of open science speech foundation models, aiming to address transparency and reproducibility issues in speech processing.
🛠️ Research Methods:
– FAMA is trained using 150k+ hours of open-source speech data in English and Italian, supplemented by a new dataset of 16k hours of cleaned and pseudo-labeled speech.
💬 Research Conclusions:
– FAMA demonstrates competitive performance, being up to 8 times faster than existing speech foundation models, and promotes openness by releasing all models, datasets, and code under open-source licenses.
👉 Paper link: https://huggingface.co/papers/2505.22759

18. Towards Safety Reasoning in LLMs: AI-agentic Deliberation for Policy-embedded CoT Data Creation
🔑 Keywords: AI-generated summary, Safety reasoning, LLMs, CoT, Safety generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance safety in LLMs by using AIDSAFE to create high-quality safety policy datasets.
🛠️ Research Methods:
– Implement multi-agent deliberation and data refiner stages to generate and refine policy-embedded CoT datasets.
💬 Research Conclusions:
– AIDSAFE-generated CoT datasets improve policy adherence and reasoning quality, enhancing LLM safety generalization and jailbreak robustness while maintaining utility.
👉 Paper link: https://huggingface.co/papers/2505.21784

19. ATLAS: Learning to Optimally Memorize the Context at Test Time
🔑 Keywords: Transformers, long-term memory module, ATLAS, DeepTransformers, long-context understanding
💡 Category: Natural Language Processing
🌟 Research Objective:
– To address limitations of Transformers in handling long contexts by introducing a new long-term memory module called ATLAS.
🛠️ Research Methods:
– Developed ATLAS to optimize memory based on current and past inputs, creating a new family of Transformer-like architectures named DeepTransformers.
💬 Research Conclusions:
– ATLAS outperforms traditional Transformers and recent linear recurrent models in long-context understanding tasks, achieving significant improvements in benchmarks such as BABILong.
👉 Paper link: https://huggingface.co/papers/2505.23735

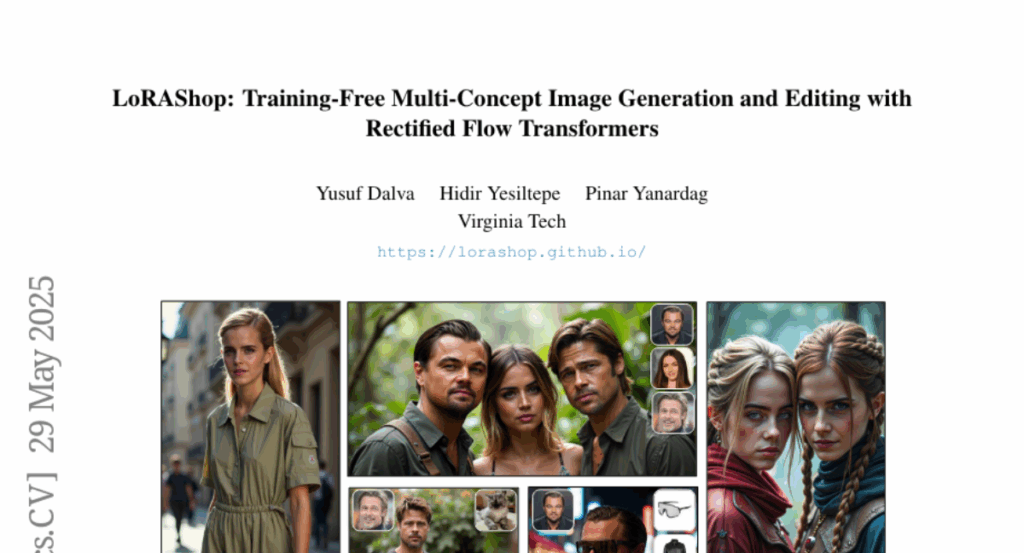
20. LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers
🔑 Keywords: LoRA models, Flux-style diffusion transformers, identity preservation, compositional visual storytelling, personalized diffusion models
💡 Category: Generative Models
🌟 Research Objective:
– Introduce LoRAShop, a framework for multi-concept image editing using LoRA models to seamlessly integrate multiple subjects or styles while preserving global context and identity.
🛠️ Research Methods:
– Utilized feature interaction patterns in Flux-style diffusion transformers to activate spatially coherent regions for deriving disentangled latent masks.
💬 Research Conclusions:
– LoRAShop provides better identity preservation compared to baselines and eliminates the need for retraining, functioning as a practical tool for creative visual storytelling.
👉 Paper link: https://huggingface.co/papers/2505.23758

21. On-Policy RL with Optimal Reward Baseline
🔑 Keywords: Reinforcement Learning, On-Policy Training, Optimal Reward Baseline, Gradient Variance, Large Language Model
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance training stability and performance in large language model alignment and reasoning using a novel reinforcement learning algorithm, OPO.
🛠️ Research Methods:
– Introduction of OPO, a simplified algorithm focusing on exact on-policy training and implementation of an optimal reward baseline to minimize gradient variance.
💬 Research Conclusions:
– OPO stabilizes training and boosts performance in mathematical reasoning tasks, achieving superior results without the need for additional models, while also encouraging diverse and less repetitive responses.
👉 Paper link: https://huggingface.co/papers/2505.23585

22. Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
🔑 Keywords: unified generation models, discrete diffusion, visual priors, multimodal generation, efficiency
💡 Category: Generative Models
🌟 Research Objective:
– To develop a unified discrete diffusion transformer, named Muddit, for efficient and high-quality generation across text and image modalities.
🛠️ Research Methods:
– Integration of pretrained visual priors from a text-to-image backbone with a lightweight text decoder to enable fast and parallel multimodal generation.
💬 Research Conclusions:
– Muddit demonstrates competitive or superior performance in quality and efficiency compared to larger autoregressive models, showcasing the potential of discrete diffusion with strong visual priors as a scalable backbone for unified generation.
👉 Paper link: https://huggingface.co/papers/2505.23606

23. StressTest: Can YOUR Speech LM Handle the Stress?
🔑 Keywords: Speech-Aware Language Models, Sentence Stress, Synthetic Dataset, Audio Reasoning, Benchmark
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce the StressTest benchmark and the synthetic Stress17k dataset to enhance speech-aware language models’ capability in interpreting sentence stress.
🛠️ Research Methods:
– A benchmark evaluation of sentence stress interpretation capabilities in existing models and the creation of a synthetic data generation pipeline leading to the Stress17k dataset for model training.
💬 Research Conclusions:
– The Stress17k dataset enabled the development of StresSLM, a fine-tuned model significantly surpassing existing models in both sentence stress reasoning and detection tasks.
👉 Paper link: https://huggingface.co/papers/2505.22765

24. GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control
🔑 Keywords: autonomous driving, 3D geometry, dynamic editing module, 3D representation, spatial awareness
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– GeoDrive aims to integrate robust 3D geometry into driving world models to enhance spatial understanding and action controllability in autonomous navigation.
🛠️ Research Methods:
– The method involves extracting a 3D representation from input frames and obtaining 2D rendering based on user-specified ego-car trajectories, with a dynamic editing module to enhance renderings by editing vehicle positions.
💬 Research Conclusions:
– GeoDrive significantly outperforms existing models in action accuracy and 3D spatial awareness, leading to more realistic and reliable scene modeling for safer autonomous driving.
– The model offers interactive scene editing capabilities, such as object editing and trajectory control, and can generalize to novel trajectories.
👉 Paper link: https://huggingface.co/papers/2505.22421

25. SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents
🔑 Keywords: SafeScientist, AI-driven scientific exploration, Ethical responsibility, SciSafetyBench, AI safety
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The objective is to enhance safety and ethical responsibility in AI-driven scientific research using the SafeScientist framework.
🛠️ Research Methods:
– Integrated multiple defensive mechanisms like prompt monitoring, agent-collaboration monitoring, tool-use monitoring, and ethical reviewer component. Complemented by the SciSafetyBench, a benchmark for evaluating AI safety in scientific contexts.
💬 Research Conclusions:
– SafeScientist significantly improves safety performance by 35% compared to traditional AI scientist frameworks without compromising scientific output quality and demonstrates robustness against adversarial attacks.
👉 Paper link: https://huggingface.co/papers/2505.23559

26. PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions
🔑 Keywords: PatientSim, patient personas, medical dialogue, Llama 3.3, AI Native
💡 Category: AI in Healthcare
🌟 Research Objective:
– Introduce PatientSim to generate diverse and realistic patient personas for evaluating LLMs in medical dialogue settings.
🛠️ Research Methods:
– PatientSim uses clinical profiles from real-world data and defines personas by personality, language proficiency, medical history recall, and cognitive confusion, resulting in 37 combinations.
💬 Research Conclusions:
– PatientSim is privacy-compliant and provides a scalable testbed for evaluating medical dialogue systems, with Llama 3.3 validated by clinicians as the top model.
👉 Paper link: https://huggingface.co/papers/2505.17818

27. ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind
🔑 Keywords: Theory of Mind, Large Language Models, Reinforcement Learning, opponent awareness, effective arguments
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance large language model (LLM) persuaders by integrating Theory of Mind modules to improve opponent awareness and argument quality.
🛠️ Research Methods:
– Implemented two Theory of Mind modules with a text encoder and MLP classifier for predicting opponents’ stances, combined with a reinforcement learning schema to analyze and utilize opponent-related information.
💬 Research Conclusions:
– ToMAP outperforms larger baseline models like GPT-4o by 39.4% in effectiveness, featuring opponent-aware strategies suitable for long conversations and reducing repetition with diverse and complex reasoning.
👉 Paper link: https://huggingface.co/papers/2505.22961

28. KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction
🔑 Keywords: KVzip, transformer-based LLMs, KV cache, query-agnostic, attention latency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce KVzip, a query-agnostic KV cache eviction method, aimed at reducing KV cache size and decoding latency while maintaining performance across various tasks and models.
🛠️ Research Methods:
– KVzip quantifies the importance of KV pairs using large language models (LLMs) for reconstructing original contexts and evicts pairs with lower importance. Evaluations are conducted on models such as LLaMA3.1-8B, Qwen2.5-14B, and Gemma3-12B with long context lengths.
💬 Research Conclusions:
– KVzip significantly reduces KV cache size by 3-4 times and FlashAttention decoding latency by approximately 2 times with negligible performance loss in various tasks. It outperforms existing query-aware methods, especially under multi-query scenarios.
👉 Paper link: https://huggingface.co/papers/2505.23416

29. REOrdering Patches Improves Vision Models
🔑 Keywords: Transformers, Sequence Models, Patch Ordering, REOrder, Reinforcement Learning
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to discover task-optimal patch orderings to enhance the performance of long-sequence transformers.
🛠️ Research Methods:
– The research introduces REOrder, a two-stage framework involving an information-theoretic prior to assess patch sequence compressibility and optimization of a Plackett-Luce policy using REINFORCE.
💬 Research Conclusions:
– REOrder significantly improves model accuracy over traditional patch orderings, with a noted increase of up to 3.01% on ImageNet-1K and 13.35% on the Functional Map of the World dataset.
👉 Paper link: https://huggingface.co/papers/2505.23751

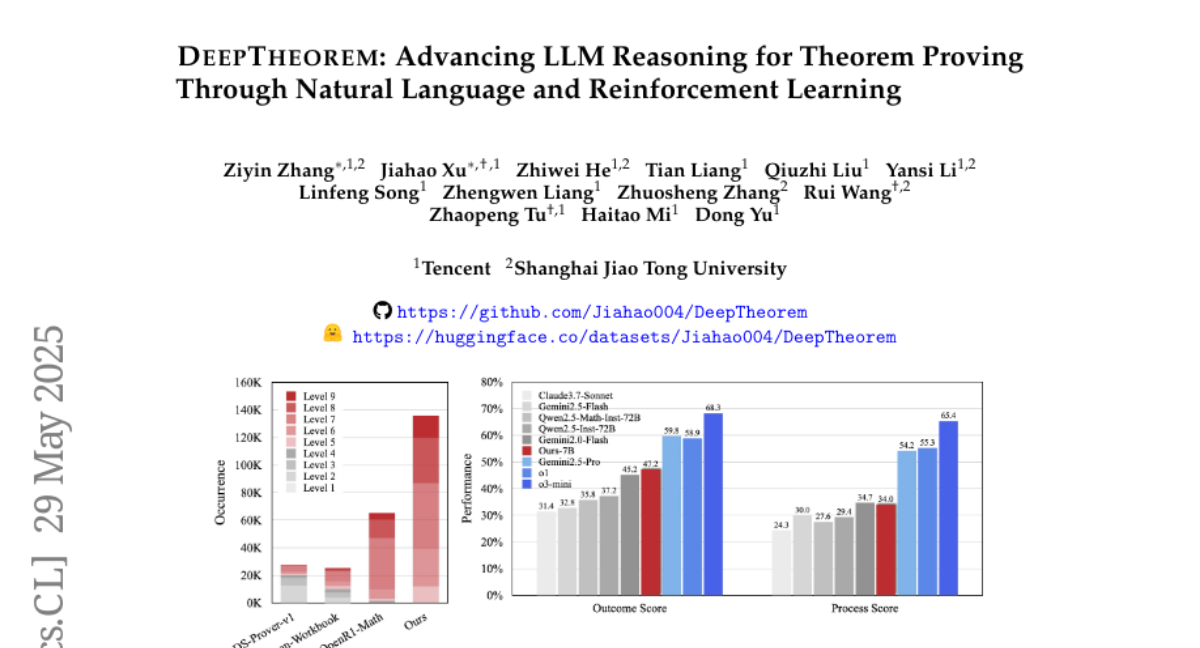
30. DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning
🔑 Keywords: DeepTheorem, Natural Language, Informal Theorem-Proving, Reinforcement Learning, Reasoning Quality
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance large language models’ (LLMs) theorem-proving capabilities using a natural language dataset and reinforcement learning strategy.
🛠️ Research Methods:
– A comprehensive framework, DeepTheorem, was developed, which includes a large-scale dataset with 121K high-quality informal theorems and a specialized reinforcement learning strategy (RL-Zero).
💬 Research Conclusions:
– DeepTheorem significantly improves LLM theorem-proving performance, achieving state-of-the-art accuracy and reasoning quality, indicating its potential to advance automated informal theorem-proving.
👉 Paper link: https://huggingface.co/papers/2505.23754
31. Breaking Down Video LLM Benchmarks: Knowledge, Spatial Perception, or True Temporal Understanding?
🔑 Keywords: VBenchComp, Video Understanding, Temporal Reasoning, AI-generated summary, LLM-Answerable
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces VBenchComp, an automated pipeline designed to categorize video LLM questions into different domains for assessing temporal reasoning and addressing model weaknesses beyond overall scores.
🛠️ Research Methods:
– The pipeline categorizes questions into LLM-Answerable, Semantic, and Temporal domains to provide a fine-grained evaluation of video LLM capabilities.
💬 Research Conclusions:
– The analysis highlights model weaknesses obscured by traditional overall scores and provides insights and recommendations for designing future benchmarks to assess video LLMs more accurately.
👉 Paper link: https://huggingface.co/papers/2505.14321

32. VidText: Towards Comprehensive Evaluation for Video Text Understanding
🔑 Keywords: VidText, video text understanding, multimodal models, Chain-of-Thought reasoning, Large Multimodal Models (LMMs)
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VidText, a comprehensive benchmark for evaluating video text understanding across various tasks, to address the current limitations in existing benchmarks.
🛠️ Research Methods:
– Develop a hierarchical evaluation framework for assessing global summarization and local retrieval capabilities in video text understanding.
– Conduct experiments on 18 state-of-the-art Large Multimodal Models (LMMs) to evaluate their performance and identify areas for improvement.
💬 Research Conclusions:
– Current multimodal models show significant room for improvement in video text understanding tasks, highlighting the influence of both intrinsic and external factors like input resolution, OCR capability, and auxiliary information use.
👉 Paper link: https://huggingface.co/papers/2505.22810

33. Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction
🔑 Keywords: Uni-Instruct, diffusion expansion theory, one-step diffusion models, f-divergence, text-to-3D generation
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to unify and enhance one-step diffusion distillation methods using a novel framework called Uni-Instruct.
🛠️ Research Methods:
– Uni-Instruct leverages a new diffusion expansion theory to address the intractability of the f-divergence family, resulting in an effective training approach for one-step diffusion models.
💬 Research Conclusions:
– Uni-Instruct achieves state-of-the-art performance in image generation benchmarks like CIFAR10 and ImageNet-64×64 with record-breaking Frechet Inception Distance values.
– It also shows promising results in text-to-3D generation, slightly outperforming previous methods in quality and diversity.
👉 Paper link: https://huggingface.co/papers/2505.20755

34. Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization
🔑 Keywords: Large Language Models, Reinforcement Learning, code efficiency, execution feedback
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce a novel test-time iterative optimization framework to enhance code efficiency generated by Large Language Models.
🛠️ Research Methods:
– Utilize a closed-loop system for LLMs to iteratively refine code using empirical performance feedback.
– Explore training strategies: Supervised Fine-Tuning, Direct Preference Optimization, and Group Relative Policy Optimization leveraging reinforcement learning.
💬 Research Conclusions:
– Demonstrates significant improvements in code efficiency by applying Reinforcement Learning, notably boosting pass@1 and outperforming human submissions.
👉 Paper link: https://huggingface.co/papers/2505.23387

35. MAGREF: Masked Guidance for Any-Reference Video Generation
🔑 Keywords: MAGREF, masked guidance, multi-subject consistency, video generation, pixel-wise channel concatenation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce MAGREF, a unified framework for generating videos from diverse references and text prompts while maintaining consistent multi-subject synthesis.
🛠️ Research Methods:
– Implement a region-aware dynamic masking mechanism and a pixel-wise channel concatenation to preserve appearance features and allow flexible handling of various subjects.
💬 Research Conclusions:
– MAGREF delivers state-of-the-art quality in video generation, outperforming existing methods with scalable and controllable synthesis capabilities. It also introduces a comprehensive multi-subject video benchmark for evaluation.
👉 Paper link: https://huggingface.co/papers/2505.23742

36. CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays
🔑 Keywords: Large Vision-Language Models, AI-generated summary, healthcare, diagnostic reasoning
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to evaluate Large Vision-Language Models (LVLMs) in clinical diagnosis by assessing their structured reasoning, visual grounding, and generalization capabilities using the MIMIC-CXR-JPG dataset.
🛠️ Research Methods:
– Introduction of CheXStruct and CXReasonBench, a structured pipeline and benchmark designed to derive intermediate reasoning steps from chest X-rays and evaluate models through clinical tasks using 18,988 QA pairs.
💬 Research Conclusions:
– Even the strongest LVLMs struggle with linking abstract knowledge to visually grounded anatomical interpretation, highlighting challenges in structured reasoning and generalization in clinical settings.
👉 Paper link: https://huggingface.co/papers/2505.18087

37. System-1.5 Reasoning: Traversal in Language and Latent Spaces with Dynamic Shortcuts
🔑 Keywords: System-1.5 Reasoning, adaptive reasoning framework, latent space, model depth shortcut, step shortcut
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to enhance the efficiency and performance of large language models by proposing System-1.5 Reasoning, which dynamically allocates computation through adaptive shortcuts in latent space for faster inference and reduced token generation.
🛠️ Research Methods:
– The study introduces an adaptive reasoning framework with dynamic shortcuts: the model depth shortcut for managing critical tokens in deeper layers, and the step shortcut for reusing hidden states across decoding steps. It involves a two-stage self-distillation process to train the model.
💬 Research Conclusions:
– Experiments demonstrate that System-1.5 Reasoning achieves comparable reasoning performance to traditional Chain-of-thought fine-tuning methods, while significantly accelerating inference (over 20 times) and reducing token generation by 92.31% on average.
👉 Paper link: https://huggingface.co/papers/2505.18962

38. Differentiable Solver Search for Fast Diffusion Sampling
🔑 Keywords: Diffusion models, ODE-based solvers, differentiable solver search algorithm, FID scores, rectified-flow models
💡 Category: Generative Models
🌟 Research Objective:
– To propose a novel differentiable solver search algorithm aimed at optimizing the computational efficiency and generation quality of diffusion models for image generation tasks.
🛠️ Research Methods:
– A compact search space was identified consisting of time steps and solver coefficients, utilizing a novel differentiable solver search algorithm that surpasses traditional solvers in efficiency and performance.
💬 Research Conclusions:
– The newly identified solver facilitates achieving FID scores of 2.40 and 2.35 with rectified-flow models and 2.33 with the DDPM model across various architectures and resolutions, all within only 10 steps, showcasing significant improvement over existing solvers.
👉 Paper link: https://huggingface.co/papers/2505.21114

39. Re-ttention: Ultra Sparse Visual Generation via Attention Statistical Reshape
🔑 Keywords: Re-ttention, sparse attention, Diffusion Models, visual generation, latency reduction
💡 Category: Generative Models
🌟 Research Objective:
– The research introduces Re-ttention, a method leveraging temporal redundancy to facilitate high sparse attention in visual generation, maintaining visual quality with minimal computational overhead.
🛠️ Research Methods:
– Re-ttention reshapes attention scores using the history of prior softmax distribution to overcome normalization shift issues while retaining quality at high sparsity levels.
💬 Research Conclusions:
– Experimental results on T2V/T2I models like CogVideoX and PixArt DiTs show that Re-ttention can operate with as low as 3.1% token usage during inference, exceeding the performance of methods like FastDiTAttn, Sparse VideoGen, and MInference. It achieves significant latency reduction on the H100 GPU.
👉 Paper link: https://huggingface.co/papers/2505.22918

40. UniTEX: Universal High Fidelity Generative Texturing for 3D Shapes
🔑 Keywords: 3D texture generation, Texture Functions, transformer-based Large Texturing Model, Diffusion Transformers
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to introduce UniTEX, a novel two-stage framework for generating high-quality and consistent 3D textures without relying on UV mapping.
🛠️ Research Methods:
– The research involves using Texture Functions (TFs) to represent textures in a continuous 3D functional space and predicting these directly from images and geometry using a transformer-based Large Texturing Model (LTM).
💬 Research Conclusions:
– Extensive experiments demonstrate UniTEX’s superior visual quality and texture integrity over existing methods, providing a scalable solution for 3D texture generation.
👉 Paper link: https://huggingface.co/papers/2505.23253

41. Concise Reasoning, Big Gains: Pruning Long Reasoning Trace with Difficulty-Aware Prompting
🔑 Keywords: difficulty-aware prompting, reasoning traces, LiteCoT, inference costs, Qwen2.5 architecture
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The aim is to enhance base models’ reasoning efficiency while maintaining performance by introducing a method to dynamically shorten reasoning traces based on problem difficulty.
🛠️ Research Methods:
– The authors developed a difficulty-aware prompting (DAP) approach to adjust reasoning trace lengths, creating a distilled dataset named LiteCoT. From this, they built a new family of reasoning models called Liter using the Qwen2.5 architecture.
💬 Research Conclusions:
– The difficulty-aware CoTs outperform the traditionally long reasoning chains in accuracy while using significantly fewer tokens, as demonstrated across 11 benchmarks. An instance includes achieving 74.2% accuracy on the AIME24 exam with only 5K inference tokens.
👉 Paper link: https://huggingface.co/papers/2505.19716

42. One-shot Entropy Minimization
🔑 Keywords: Entropy Minimization, Large Language Models, Unlabeled Data, Optimization, Post-Training Paradigms
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aimed to investigate the impact of entropy minimization using a single unlabeled data point on large language model performance.
🛠️ Research Methods:
– Trained 13,440 large language models, utilizing a method involving entropy minimization that required only a single unlabeled data point and 10 steps of optimization.
💬 Research Conclusions:
– Entropy minimization with minimal data and optimization steps can achieve performance improvements comparable to or even surpassing those obtained through rule-based reinforcement learning using large datasets.
– The findings suggest a potential shift in the post-training paradigms for large language models.
👉 Paper link: https://huggingface.co/papers/2505.20282

43. ZeroSep: Separate Anything in Audio with Zero Training
🔑 Keywords: Zero-shot source separation, text-guided audio diffusion model, generative diffusion model, pre-trained models, open-set scenarios
💡 Category: Generative Models
🌟 Research Objective:
– To explore the potential of pre-trained text-guided audio diffusion models to achieve zero-shot source separation, overcoming the limitations of current supervised deep learning approaches.
🛠️ Research Methods:
– Utilization of a pre-trained text-guided audio diffusion model, specifically inverting mixed audio into the model’s latent space and employing text conditioning to guide the denoising process for separation tasks.
💬 Research Conclusions:
– ZeroSep, the proposed method, achieves zero-shot source separation effectively, surpassing supervised methods across various benchmarks without the necessity for task-specific training or fine-tuning, and supports open-set scenarios through its textual priors.
👉 Paper link: https://huggingface.co/papers/2505.23625

44. To Trust Or Not To Trust Your Vision-Language Model’s Prediction
🔑 Keywords: Vision-Language Models, TrustVLM, modality gap, misclassification detection
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance the reliability of Vision-Language Models (VLMs) by estimating prediction trustworthiness without retraining, specifically addressing misclassification risks in safety-critical domains.
🛠️ Research Methods:
– Introduced TrustVLM, a training-free framework with a novel confidence-scoring function that utilizes the image embedding space to improve misclassification detection. Evaluated across 17 datasets, 4 architectures, and 2 VLMs.
💬 Research Conclusions:
– TrustVLM demonstrated state-of-the-art performance with significant improvements in key metrics such as AURC, AUROC, and FPR95, making VLMs safer for real-world application deployments without the need for retraining.
👉 Paper link: https://huggingface.co/papers/2505.23745

45. Puzzled by Puzzles: When Vision-Language Models Can’t Take a Hint
🔑 Keywords: Vision-language models, rebus puzzles, multi-modal abstraction, symbolic reasoning, visual metaphors
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate the capacity of contemporary vision-language models to interpret and solve rebus puzzles by constructing a hand-generated and annotated benchmark of diverse English-language rebus puzzles.
🛠️ Research Methods:
– A benchmark of annotated rebus puzzles was constructed, ranging from simple pictographic substitutions to spatially-dependent cues, to evaluate the performance of different vision-language models.
💬 Research Conclusions:
– While vision-language models exhibit some surprising capabilities in decoding simple visual clues, they struggle significantly with tasks requiring abstract reasoning, lateral thinking, and understanding visual metaphors.
👉 Paper link: https://huggingface.co/papers/2505.23759

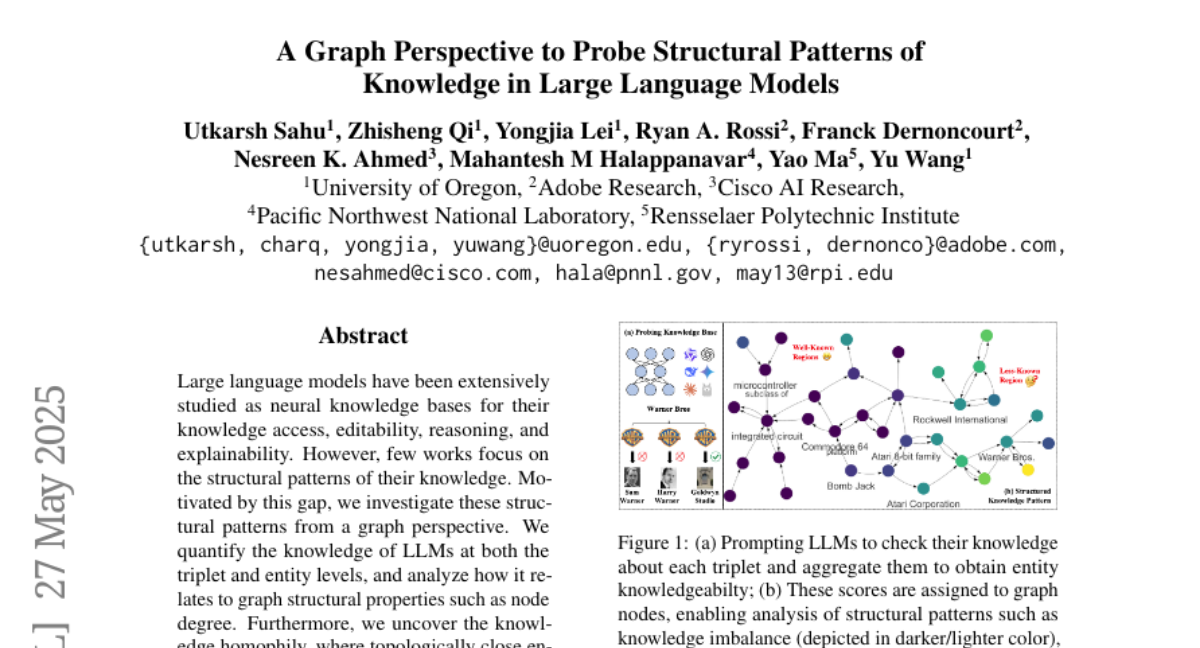
46. A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models
🔑 Keywords: Large language models, Graph perspective, Knowledge homophily, Graph machine learning, Entity knowledge
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study explores the structural patterns of knowledge in large language models from a graph perspective, focusing on knowledge homophily.
🛠️ Research Methods:
– Quantifying knowledge at the triplet and entity levels and analyzing it in relation to graph structural properties.
– Developing graph machine learning models to estimate entity knowledge based on local neighbors.
💬 Research Conclusions:
– Discovering knowledge homophily among topologically close entities.
– Enhancing knowledge checking by identifying triplets less known to large language models.
– Fine-tuning with selected triplets leads to improved model performance.
👉 Paper link: https://huggingface.co/papers/2505.19286
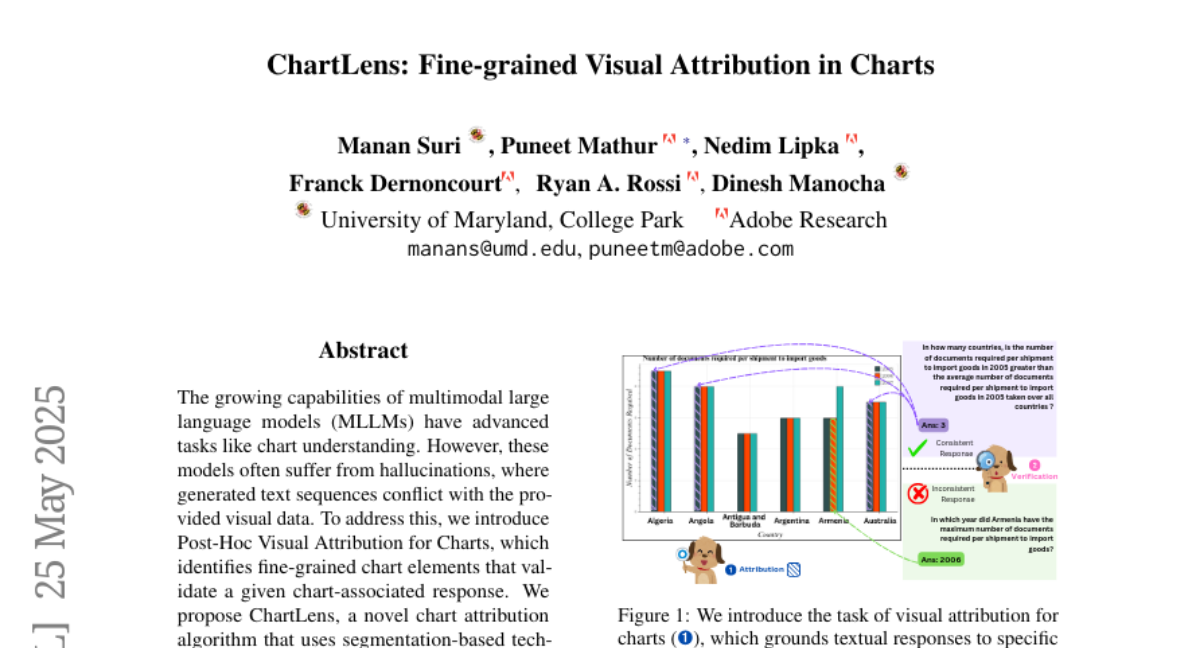
47. ChartLens: Fine-grained Visual Attribution in Charts
🔑 Keywords: ChartLens, Post-Hoc Visual Attribution, Multimodal Large Language Models, Fine-Grained Visual Attribution, Segmentation-Based Techniques
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Enhance the accuracy of chart understanding by integrating fine-grained visual attributions into multimodal language models.
🛠️ Research Methods:
– Introduce ChartLens, using segmentation-based techniques and set-of-marks prompting for fine-grained visual attribution.
– Develop the ChartVA-Eval benchmark with both synthetic and real-world charts featuring fine-grained annotations.
💬 Research Conclusions:
– ChartLens improves the accuracy of fine-grained attributions in chart understanding by 26-66%.
👉 Paper link: https://huggingface.co/papers/2505.19360
48. SridBench: Benchmark of Scientific Research Illustration Drawing of Image Generation Model
🔑 Keywords: SridBench, GPT-4o-image, Multimodal Models, Semantic Fidelity, Structural Accuracy
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce SridBench, a benchmark for evaluating scientific figure generation by AI models.
🛠️ Research Methods:
– Collection of 1,120 instances from scientific papers across 13 disciplines, evaluated on six dimensions by human experts and MLLMs.
💬 Research Conclusions:
– Top-tier AI models like GPT-4o-image underperform humans in semantic and structural accuracy, underscoring the need for advanced multimodal reasoning in visual generation.
👉 Paper link: https://huggingface.co/papers/2505.22126

49. CLIPGaussian: Universal and Multimodal Style Transfer Based on Gaussian Splatting
🔑 Keywords: CLIPGaussians, style transfer, Gaussian primitives, temporal coherence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce CLIPGaussians, a unified framework for text- and image-guided style transfer across multiple modalities including 2D images, videos, 3D objects, and 4D scenes.
🛠️ Research Methods:
– Operate directly on Gaussian primitives and integrate into existing Gaussian Splatting pipelines without additional generative models or retraining.
💬 Research Conclusions:
– Demonstrated superior style fidelity and consistency with joint optimization of color and geometry and achieved temporal coherence in videos.
👉 Paper link: https://huggingface.co/papers/2505.22854
50. Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates
🔑 Keywords: Multimodal Adversarial Compositionality, large language models (LLMs), zero-shot methods, rejection-sampling fine-tuning, diversity-promoting filtering
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces Multimodal Adversarial Compositionality (MAC), a benchmark for exploiting and evaluating compositional vulnerabilities in multimodal representations using deceptive text samples.
🛠️ Research Methods:
– A self-training approach is proposed to improve zero-shot methods by employing rejection-sampling fine-tuning coupled with diversity-promoting filtering, enhancing attack success and sample diversity.
💬 Research Conclusions:
– The approach, utilizing smaller language models like Llama-3.1-8B, effectively reveals compositional vulnerabilities across multimedia formats, including images, videos, and audios, by enhancing both attack success rate and sample diversity.
👉 Paper link: https://huggingface.co/papers/2505.22943

51. ATI: Any Trajectory Instruction for Controllable Video Generation
🔑 Keywords: trajectory-based inputs, latent space, lightweight motion injector, video motion control, motion sequences
💡 Category: Generative Models
🌟 Research Objective:
– To propose a unified framework for video motion control that combines camera movement, object-level translation, and local motion with trajectory-based inputs for improved controllability and visual quality.
🛠️ Research Methods:
– Utilizes trajectory-based inputs projected into the latent space of pre-trained image-to-video models via a lightweight motion injector, allowing users to define keypoints and motion paths for seamless integration of different motion types.
💬 Research Conclusions:
– The proposed framework achieves superior performance in video motion control tasks, offering better controllability and visual quality compared to previous methods and commercial solutions, while being compatible with various state-of-the-art video generation backbones.
👉 Paper link: https://huggingface.co/papers/2505.22944
52. Differential Information: An Information-Theoretic Perspective on Preference Optimization
🔑 Keywords: Direct Preference Optimization, Differential Information Distribution, target policy, preference optimization, entropy
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To theoretically justify the log-ratio reward parameterization in Direct Preference Optimization (DPO) for learning target policy via preference optimization.
🛠️ Research Methods:
– Analyzing Differential Information Distribution (DID) as a tool to capture information gained during policy updates, and examining the relation with log-margin ordered policies.
💬 Research Conclusions:
– Log-ratio reward parameterization is optimal and naturally leads to a closed-form expression for sampling distribution over rejected responses.
– Differential information encoding of preferences is linked to an inductive bias of log-margin ordered policies.
– Learning high-entropy differential information is crucial for general instruction-following, while low-entropy benefits knowledge-intensive question answering.
👉 Paper link: https://huggingface.co/papers/2505.23761
