AI Native Daily Paper Digest – 20250603

1. Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
🔑 Keywords: RLVR, token entropy patterns, high-entropy tokens, Chain-of-Thought, Qwen3-8B
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore how token entropy patterns impact reasoning performance in Reinforcement Learning with Verifiable Rewards (RLVR), focusing on their influence on large language models.
🛠️ Research Methods:
– Comprehensive analysis of token entropy patterns in Chain-of-Thought reasoning to understand their role in guiding reasoning pathways and model optimization.
💬 Research Conclusions:
– High-entropy tokens are critical in RLVR, effectively steering reasoning paths. Optimizing these tokens enhances performance, demonstrated by improved results when policy gradient updates target only forking tokens, achieving efficiency comparable to full-gradient updates and surpassing them in specific models like Qwen3-32B and Qwen3-14B.
👉 Paper link: https://huggingface.co/papers/2506.01939

2. REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards
🔑 Keywords: Reasoning Gym, Reinforcement Learning, Verifiable Rewards, Procedural Generation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To introduce the Reasoning Gym library for reinforcement learning, which offers reasoning environments with verifiable rewards and procedural data generation.
🛠️ Research Methods:
– Development of over 100 data generators and verifiers across diverse domains, allowing infinite training data generation with adjustable complexity.
💬 Research Conclusions:
– Experimental results highlight Reasoning Gym’s efficacy in evaluating and training reasoning models at various difficulty levels.
👉 Paper link: https://huggingface.co/papers/2505.24760

3. SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
🔑 Keywords: SmolVLA, Vision-Language-Action (VLA), Computational Costs, Asynchronous Inference, Consumer-Grade Hardware
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The objective of the research is to develop SmolVLA, a compact and efficient vision-language-action model, that reduces both training and inference costs while achieving competitive performance.
🛠️ Research Methods:
– The research involves presenting SmolVLA as a smaller VLA model designed to be trained on a single GPU and deployed on consumer-grade GPUs or CPUs. It introduces an asynchronous inference stack to improve responsiveness and control rates.
💬 Research Conclusions:
– SmolVLA achieves performance comparable to much larger models by reducing computational resources, demonstrating its effectiveness on simulated and real-world robotic benchmarks. Additionally, all code, pretrained models, and training data are released for further exploration and use.
👉 Paper link: https://huggingface.co/papers/2506.01844

4. Taming LLMs by Scaling Learning Rates with Gradient Grouping
🔑 Keywords: Large Language Models, Adaptive Optimizers, Parameter-wise Learning Rate Estimation, SGG, Convergence
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to enhance the efficiency and effectiveness of adaptive learning rate estimation for large language models by introducing Scaling with Gradient Grouping (SGG).
🛠️ Research Methods:
– The method involves dynamically grouping gradient statistics by layer and applying cluster-specific scaling to refine learning rates for each parameter.
💬 Research Conclusions:
– SGG shows improved integration with existing optimizers, leading to consistent gains, faster convergence, and stability across varying batch sizes and learning rates, proving itself as a robust tool for optimizing large language models.
👉 Paper link: https://huggingface.co/papers/2506.01049

5. ARIA: Training Language Agents with Intention-Driven Reward Aggregation
🔑 Keywords: AI Native, Intention space, reinforcement learning, reward sparsity, policy optimization
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The objective is to address reward sparsity and improve policy optimization in language-based reinforcement learning tasks by aggregating rewards in an intention space.
🛠️ Research Methods:
– The proposed method, ARIA, projects natural language actions from a high-dimensional joint token distribution space into a low-dimensional intention space, clustering semantically similar actions and assigning them shared rewards.
💬 Research Conclusions:
– ARIA significantly reduces policy gradient variance and yields an average performance gain of 9.95% across four downstream tasks, outperforming both offline and online RL baselines.
👉 Paper link: https://huggingface.co/papers/2506.00539

6. Jigsaw-R1: A Study of Rule-based Visual Reinforcement Learning with Jigsaw Puzzles
🔑 Keywords: Rule-based Reinforcement Learning, Multimodal Large Language Models, Visual Tasks, Generalization, Supervised Fine-Tuning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study investigates the application of rule-based reinforcement learning to multimodal large language models, focusing on their generalization abilities in visual tasks using jigsaw puzzles.
🛠️ Research Methods:
– Utilized jigsaw puzzles as a structured experimental framework to test the performance and generalization abilities of multimodal large language models.
💬 Research Conclusions:
– MLLMs significantly improved from random guessing to achieving high accuracy in complex visual tasks through fine-tuning.
– MLLMs can generalize to various visual tasks with varying effectiveness based on task configurations, often bypassing explicit reasoning.
– Rule-based RL demonstrates more effective generalization than supervised fine-tuning, though the initial SFT can impede subsequent RL performance.
👉 Paper link: https://huggingface.co/papers/2505.23590

7. LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks
🔑 Keywords: LoHoVLA, long-horizon tasks, vision language model, hierarchical control, embodied intelligence
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop a unified vision language action framework, LoHoVLA, that enhances performance in long-horizon embodied tasks by combining vision language models with hierarchical closed-loop control.
🛠️ Research Methods:
– LoHoVLA integrates a large pretrained vision language model to generate language and action tokens for sub-task generation and robot action prediction.
– It introduces a hierarchical closed-loop control mechanism to address errors in high-level planning and low-level control.
– The model is trained using LoHoSet, a dataset featuring 20 long-horizon tasks with expert demonstrations in the Ravens simulator.
💬 Research Conclusions:
– LoHoVLA significantly outperforms existing hierarchical and standard VLA models for long-horizon embodied tasks, highlighting the potential of unified architectures to advance embodied intelligence.
👉 Paper link: https://huggingface.co/papers/2506.00411

8. ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding
🔑 Keywords: AI Native, 3D-native AI, Multimodal Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop ShapeLLM-Omni, a native 3D large language model capable of understanding and generating 3D assets and text.
🛠️ Research Methods:
– Utilization of a 3D vector-quantized variational autoencoder (VQVAE) to map 3D objects into a discrete latent space.
– Construction of a large-scale continuous training dataset named 3D-Alpaca for generation, comprehension, and editing.
💬 Research Conclusions:
– The research presents an effective extension of multimodal models with basic 3D capabilities, opening avenues for future research in 3D-native AI.
👉 Paper link: https://huggingface.co/papers/2506.01853
9. Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models
🔑 Keywords: AI-generated summary, Temporal In-Context Fine-Tuning, pretrained video diffusion models, conditional generation
💡 Category: Generative Models
🌟 Research Objective:
– To enhance pretrained video diffusion models for diverse conditional generation tasks with minimal data and without architectural changes.
🛠️ Research Methods:
– Introduced Temporal In-Context Fine-Tuning (TIC-FT), which adapts pretrained models by concatenating condition and target frames along the temporal axis and inserting buffer frames with increasing noise levels.
💬 Research Conclusions:
– TIC-FT achieves strong performance with limited training data and outperforms existing baselines in both condition fidelity and visual quality while maintaining training and inference efficiency.
👉 Paper link: https://huggingface.co/papers/2506.00996
10. SRPO: Enhancing Multimodal LLM Reasoning via Reflection-Aware Reinforcement Learning
🔑 Keywords: Multimodal Large Language Models, Reinforcement Learning, Self-Reflection, Reasoning Tasks, GRPO Framework
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance reasoning and self-reflection in multimodal large language models using a two-stage reinforcement learning framework called SRPO.
🛠️ Research Methods:
– A high-quality, reflection-focused dataset is constructed to help the policy model learn reasoning and self-reflection.
– Introduces a novel reward mechanism in the GRPO framework to encourage concise and meaningful reflection without redundancy.
💬 Research Conclusions:
– The proposed SRPO framework significantly outperforms state-of-the-art models, showing notable improvements in reasoning accuracy and reflection quality across multiple multimodal reasoning benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.01713

11. Learning Video Generation for Robotic Manipulation with Collaborative Trajectory Control
🔑 Keywords: RoboMaster, trajectory-controlled video generation, robotic manipulation, multi-object interaction, state-of-the-art performance
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To enhance trajectory-controlled video generation for robotic manipulation by modeling inter-object dynamics through a collaborative trajectory formulation.
🛠️ Research Methods:
– Decomposition of the interaction process into three sub-stages (pre-interaction, interaction, and post-interaction) and modeling each with the feature of the dominant object.
– Integration of appearance- and shape-aware latent representations to ensure semantic consistency.
💬 Research Conclusions:
– RoboMaster outperforms existing approaches on the Bridge V2 dataset, achieving new state-of-the-art performance in trajectory-controlled video generation for robotic manipulation.
👉 Paper link: https://huggingface.co/papers/2506.01943
12. EarthMind: Towards Multi-Granular and Multi-Sensor Earth Observation with Large Multimodal Models
🔑 Keywords: EarthMind, Spatial Attention Prompting, Cross-modal Fusion, multi-granular, multi-sensor
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The objective is to enhance the understanding of multi-granular and multi-sensor Earth Observation data using the EarthMind vision-language framework.
🛠️ Research Methods:
– Implementation of Spatial Attention Prompting to improve pixel-level understanding.
– Utilization of Cross-modal Fusion for integrating heterogeneous modalities into a shared space and adapting token weights based on information density.
💬 Research Conclusions:
– EarthMind achieves state-of-the-art performance on EarthMind-Bench and surpasses larger models like GPT-4o, demonstrating its effectiveness in handling multi-granular and multi-sensor challenges.
👉 Paper link: https://huggingface.co/papers/2506.01667

13. AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
🔑 Keywords: AReaL, Reinforcement Learning, Large Language Models, GPU Utilization, Asynchronous Training
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to improve the efficiency and speed of training large language models on reasoning tasks through a novel asynchronous reinforcement learning system called AReaL.
🛠️ Research Methods:
– Implementation of a fully asynchronous system where generation and training are decoupled, featuring continuous generation by rollout workers and optimized GPU utilization.
– Incorporation of system-level optimizations and staleness-enhanced PPO to stabilize reinforcement learning training.
💬 Research Conclusions:
– AReaL significantly boosts training speed by up to 2.57 times compared to synchronous systems, with improved or matched performance on math and code reasoning benchmarks.
– The approach ensures higher GPU utilization and addresses system inefficiency by balancing workload and controlling data staleness.
👉 Paper link: https://huggingface.co/papers/2505.24298

14. MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
🔑 Keywords: Personalized Preference Learning, Large Language Models, Reward Modeling, Context-aware Mixture Modeling, Reinforcement Learning from Human Feedback
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve personalized preference learning in large language models by addressing limitations of existing reward modeling techniques and leveraging binary preference datasets.
🛠️ Research Methods:
– Introduces a two-stage framework named MiCRo that consists of context-aware mixture modeling and an online routing strategy for dynamically adapting mixture weights based on context.
💬 Research Conclusions:
– MiCRo captures diverse human preferences and enhances downstream personalization significantly, demonstrating its efficacy on multiple preference datasets.
👉 Paper link: https://huggingface.co/papers/2505.24846

15. Unified Scaling Laws for Compressed Representations
🔑 Keywords: Scaling laws, model compression, quantization, sparsification, parameter efficiency
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to explore the relationship between scaling laws and various compression formats, assessing the unified capacity metric to predict model performance across these formats.
🛠️ Research Methods:
– The investigation involves theoretical and empirical validation of a general scaling law formulation applied across different compressed representations like sparse-quantized and vector-quantized formats.
💬 Research Conclusions:
– The research concludes that a simple “capacity” metric can reliably predict parameter efficiency across multiple compressed representations. Additionally, it enables the direct comparison of accuracy potential between different compressed formats and leads to improved training algorithms for sparse-quantized formats.
👉 Paper link: https://huggingface.co/papers/2506.01863

16. Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models
🔑 Keywords: Large Language Models, Complex Instructions, Reinforcement Learning, Chain-of-Thought
💡 Category: Natural Language Processing
🌟 Research Objective:
– This research aims to enhance large language models (LLMs) in handling complex instructions by using incentivized reasoning and reinforcement learning to improve performance and reduce computational load.
🛠️ Research Methods:
– The study proposes a method that begins with the decomposition of complex instructions and employs reinforcement learning with rule-centric reward signals to cultivate reasoning in LLMs for instruction following.
– It utilizes behavior cloning of experts to assist in the transition from fast-thinking LLMs to skillful reasoning tools.
💬 Research Conclusions:
– The proposed method demonstrates a significant improvement in performance, with a 1.5B LLM achieving gains comparable to an 8B LLM as confirmed by evaluations on comprehensive benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.01413

17. Cora: Correspondence-aware image editing using few step diffusion
🔑 Keywords: Cora framework, image editing, correspondence-aware noise correction, interpolated attention maps, texture transfer
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces Cora, a framework designed to enhance image editing, addressing limitations in existing methods by focusing on preserving structures and textures during significant structural changes.
🛠️ Research Methods:
– Cora utilizes correspondence-aware noise correction and interpolated attention maps to align textures and structures between source and target images, facilitating accurate texture transfer and balancing content generation and preservation.
💬 Research Conclusions:
– Extensive experiments indicate that Cora performs excellently in maintaining structure, textures, and identity across various edits and outperforms existing alternatives, as confirmed by user studies.
👉 Paper link: https://huggingface.co/papers/2505.23907
18. Reasoning Like an Economist: Post-Training on Economic Problems Induces Strategic Generalization in LLMs
🔑 Keywords: Large Language Models, Multi-Agent Systems, Supervised Fine-Tuning, Reinforcement Learning with Verifiable Rewards, economic reasoning
💡 Category: Foundations of AI
🌟 Research Objective:
– Investigate the effectiveness of post-training techniques such as Supervised Fine-Tuning and Reinforcement Learning with Verifiable Rewards in generalizing Large Language Models to multi-agent scenarios.
🛠️ Research Methods:
– Implemented economic reasoning as a testbed and introduced Recon, an open-source LLM post-trained with economic reasoning problems, to evaluate structured reasoning and economic rationality.
💬 Research Conclusions:
– Demonstrated improvements in structured reasoning and economic rationality in multi-agent games, highlighting the promise of domain-aligned post-training techniques for enhancing reasoning and agent alignment.
👉 Paper link: https://huggingface.co/papers/2506.00577

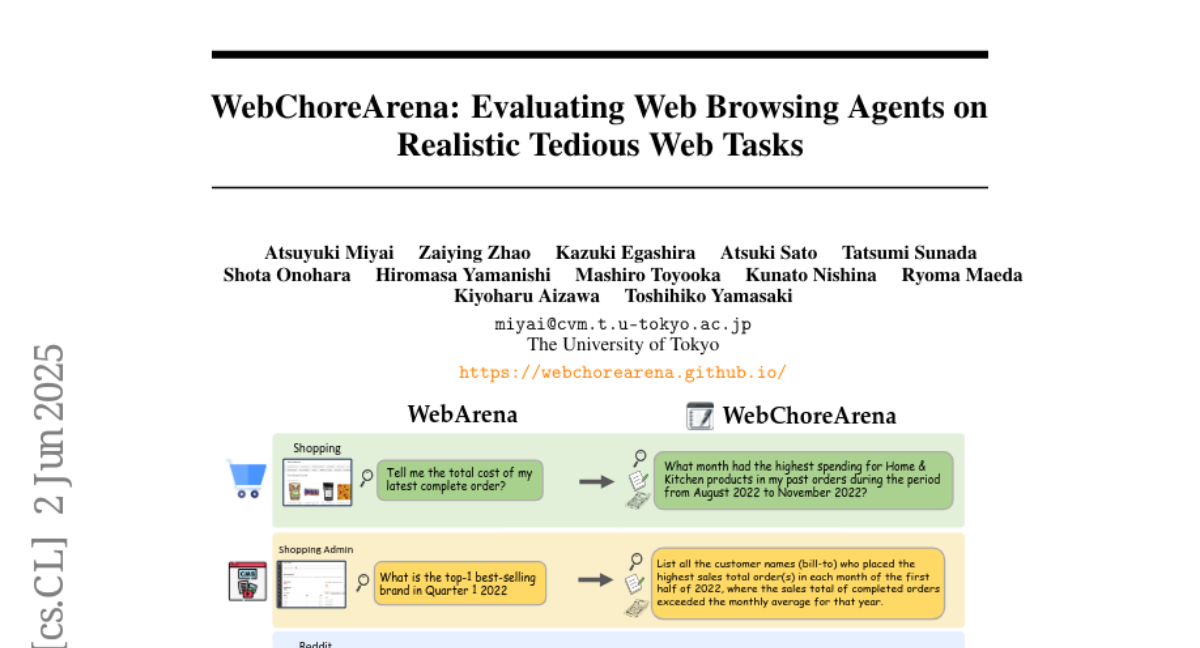
19. WebChoreArena: Evaluating Web Browsing Agents on Realistic Tedious Web Tasks
🔑 Keywords: WebChoreArena, LLM, web browsing agent, benchmark, WebArena
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To introduce WebChoreArena, a new benchmark comprising 532 tasks, designed to extend the scope of existing benchmarks to more complex web browsing tasks and measure advancements in LLM capabilities.
🛠️ Research Methods:
– Systematic integration of tasks into WebChoreArena involving Massive Memory, Calculation, and Long-Term Memory challenges, built on top of WebArena simulation environments for reproducibility and fair comparison.
💬 Research Conclusions:
– Experiments demonstrate significant improvements in LLM performance, represented by models like GPT-4o, within the WebChoreArena benchmark, yet highlight the increased complexity and challenge compared to previous benchmarks such as WebArena.
👉 Paper link: https://huggingface.co/papers/2506.01952
20. DyePack: Provably Flagging Test Set Contamination in LLMs Using Backdoors
🔑 Keywords: DyePack, backdoor attacks, false positive rate, test set contamination, AI Native
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce DyePack, a framework to detect models that improperly used benchmark test sets for training by using backdoor attacks.
🛠️ Research Methods:
– Employ backdoor samples integrated with test data, incorporating multiple backdoors with stochastic targets to precisely calculate false positive rates without needing internal model access.
💬 Research Conclusions:
– DyePack effectively flags contaminated models across multiple-choice and open-ended generation tasks, reporting extremely low false positive rates and demonstrating robustness in identifying test set contamination.
👉 Paper link: https://huggingface.co/papers/2505.23001

21. From Token to Action: State Machine Reasoning to Mitigate Overthinking in Information Retrieval
🔑 Keywords: State Machine Reasoning, Chain-of-Thought, Information Retrieval, Early Stopping
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The objective is to enhance information retrieval performance and reduce token usage in large language models by addressing overthinking through a discrete action framework called State Machine Reasoning (SMR).
🛠️ Research Methods:
– Introduced SMR, a transition-based reasoning framework with discrete actions (Refine, Rerank, Stop) to enable early stopping and fine-grained control, generalizing across LLMs and retrievers without task-specific tuning.
💬 Research Conclusions:
– Experiments on BEIR and BRIGHT benchmarks demonstrate that SMR improves retrieval performance by 3.4% and reduces token usage by 74.4%, offering a practical alternative to conventional Chain-of-Thought reasoning.
👉 Paper link: https://huggingface.co/papers/2505.23059

22. VisualSphinx: Large-Scale Synthetic Vision Logic Puzzles for RL
🔑 Keywords: Vision language models, Multimodal reasoning, Logical reasoning, Image synthesis
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To introduce VisualSphinx, a large-scale synthetic dataset aimed at enhancing logical reasoning capabilities in vision language models (VLMs).
🛠️ Research Methods:
– Developed a rule-to-image synthesis pipeline that uses puzzle rules to generate visually grounded synthetic images for training.
💬 Research Conclusions:
– VLMs trained with VisualSphinx show improved performance on logical reasoning tasks, benefiting areas such as algebraic, arithmetic, and geometry reasoning.
👉 Paper link: https://huggingface.co/papers/2505.23977

23. Stress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool Detectors
🔑 Keywords: AI Native, Generative AI, Large Language Models, Machine-Generated Text, Direct Preference Optimization
💡 Category: Natural Language Processing
🌟 Research Objective:
– To test the resilience of state-of-the-art MGT detectors against linguistically informed adversarial attacks using Direct Preference Optimization to mimic human-written text.
🛠️ Research Methods:
– Fine-tuning language models with Direct Preference Optimization to adjust the style of MGT towards human-written text, challenging the reliance of detectors on stylistic clues.
💬 Research Conclusions:
– Detectors can be easily deceived with limited examples, causing a significant drop in detection performance, underscoring the necessity to strengthen detection methods to handle unseen in-domain texts.
👉 Paper link: https://huggingface.co/papers/2505.24523

24. Normalized Attention Guidance: Universal Negative Guidance for Diffusion Model
🔑 Keywords: Normalized Attention Guidance, diffusion models, negative guidance, Classifier-Free Guidance, attention space
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Normalized Attention Guidance (NAG) to enhance diffusion models by providing effective negative guidance across different architectures and modalities without the need for retraining.
🛠️ Research Methods:
– Application of L1-based normalization and refinement in the attention space to enable a training-free mechanism that functions as a universal plug-in.
💬 Research Conclusions:
– NAG improves text alignment, fidelity, and human-perceived quality across various diffusion frameworks, validated through extensive experimentation and user studies.
👉 Paper link: https://huggingface.co/papers/2505.21179
25. CodeV-R1: Reasoning-Enhanced Verilog Generation
🔑 Keywords: RLVR, Verilog, Electronic Design Automation, Testbench Generator, Distillation
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce CodeV-R1, a framework to improve Verilog generation in electronic design automation using RLVR.
🛠️ Research Methods:
– Development of a rule-based testbench generator for robust equivalence checking.
– Implementation of a round-trip data synthesis to ensure high-quality NL-code pairs.
– Utilization of a two-stage “distill-then-RL” training pipeline to enhance training efficiency and reasoning capabilities.
💬 Research Conclusions:
– CodeV-R1-7B model outperforms state-of-the-art by achieving significant gains in pass rates on VerilogEval and RTLLM benchmarks.
– The advancements facilitate future research in the EDA and LLM communities with plans for releasing the model, training pipeline, and dataset.
👉 Paper link: https://huggingface.co/papers/2505.24183

26. Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors
🔑 Keywords: Video-3D Geometry Large Language Model, MLLMs, 3D scene understanding, spatial reasoning, video sequences
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To enhance the capability of Multimodal Large Language Models (MLLMs) for 3D scene understanding and spatial reasoning directly from video data without additional 3D inputs.
🛠️ Research Methods:
– Proposed a Video-3D Geometry Large Language Model (VG LLM) using a 3D visual geometry encoder that extracts 3D prior information from video sequences and integrates it with visual tokens.
💬 Research Conclusions:
– The VG LLM achieved substantial improvements in tasks related to 3D scene understanding and showed competitive results compared to current state-of-the-art methods, surpassing the Gemini-1.5-Pro in VSI-Bench evaluations.
👉 Paper link: https://huggingface.co/papers/2505.24625

27. Cascading Adversarial Bias from Injection to Distillation in Language Models
🔑 Keywords: Model distillation, adversarial manipulation, data poisoning, Untargeted Propagation, Targeted Propagation
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– To investigate the vulnerability of distilled AI models to adversarial injection of biased content during training.
🛠️ Research Methods:
– Analyzing how adversaries inject biases into teacher models, which propagate to student models, using minimal data poisoning techniques.
– Examining two propagation modes: Untargeted Propagation affecting multiple tasks and Targeted Propagation focusing on specific tasks.
💬 Research Conclusions:
– Student models show higher frequency of biased responses compared to teacher models when subjected to adversarial bias.
– Current defenses like perplexity filtering and bias detection systems are insufficient against these attacks.
– Highlights the need for effective adversarial bias mitigation strategies and proposes practical design principles to address these vulnerabilities.
👉 Paper link: https://huggingface.co/papers/2505.24842

28. OWSM v4: Improving Open Whisper-Style Speech Models via Data Scaling and Cleaning
🔑 Keywords: OWSM, Multilingual Speech Models, Data-Cleaning Pipeline, AI-generated Summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance OWSM project by integrating a large-scale web-crawled dataset to improve multilingual speech models.
🛠️ Research Methods:
– Developed a scalable data-cleaning pipeline using public toolkits to curate a dataset from the YODAS web-crawled data.
💬 Research Conclusions:
– The new series of OWSM v4 models outperform previous versions and match or surpass industrial models like Whisper and MMS on multilingual benchmarks. The cleaned dataset and models will be publicly released.
👉 Paper link: https://huggingface.co/papers/2506.00338

29. WHEN TO ACT, WHEN TO WAIT: Modeling Structural Trajectories for Intent Triggerability in Task-Oriented Dialogue
🔑 Keywords: Task-oriented dialogue systems, UserLLM, AgentLLM, Asymmetric information dynamics, Collaborative intent formation
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To facilitate collaborative intent formation in task-oriented dialogue systems by modeling asymmetric information dynamics between UserLLM and AgentLLM.
🛠️ Research Methods:
– The STORM framework models conversations between UserLLM and AgentLLM to understand asymmetric information dynamics and captures expression trajectories and latent cognitive transitions.
💬 Research Conclusions:
– Experiments show moderate uncertainty can outperform complete transparency, suggesting a reconsideration of optimal information completeness in human-AI collaboration, contributing to understanding asymmetric reasoning dynamics and dialogue system design.
👉 Paper link: https://huggingface.co/papers/2506.01881

30. VAU-R1: Advancing Video Anomaly Understanding via Reinforcement Fine-Tuning
🔑 Keywords: VAU-R1, Multimodal Large Language Models, Reinforcement Fine-Tuning, Chain-of-Thought, Video Anomaly Understanding
💡 Category: Computer Vision
🌟 Research Objective:
– The paper introduces VAU-R1, which aims to enhance video anomaly reasoning and interpretability in applications like smart cities and security surveillance.
🛠️ Research Methods:
– Utilizes Multimodal Large Language Models with Reinforcement Fine-Tuning and proposes a new benchmark called VAU-Bench for evaluating anomaly reasoning.
💬 Research Conclusions:
– VAU-R1 significantly improves question answering accuracy, temporal grounding, and reasoning coherence in anomaly understanding.
👉 Paper link: https://huggingface.co/papers/2505.23504

31. Stepsize anything: A unified learning rate schedule for budgeted-iteration training
🔑 Keywords: budgeted-iteration training, learning rate schedules, Unified Budget-Aware (UBA), condition number, convergence
💡 Category: Machine Learning
🌟 Research Objective:
– Introduce a Unified Budget-Aware (UBA) learning rate schedule to optimize training within limited iteration budgets, aiming to outperform traditional schedules.
🛠️ Research Methods:
– Develop a training budget-aware optimization framework that bridges landscape curvature variations.
– Derive the UBA schedule controlled by a single hyper-parameter varphi, highlighting its connection to the condition number.
💬 Research Conclusions:
– Extensive experiments demonstrate UBA consistently outperforms common schedules across diverse vision and language tasks and network architectures under various training budgets.
👉 Paper link: https://huggingface.co/papers/2505.24452

32. Pro3D-Editor : A Progressive-Views Perspective for Consistent and Precise 3D Editing
🔑 Keywords: AI-generated summary, 3D editing, text-guided, Pro3D-Editor, semantic propagation
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to achieve consistent 3D editing by propagating semantics from key views to less edited ones.
🛠️ Research Methods:
– Introduction of a novel framework called Pro3D-Editor, which includes Primary-view Sampler, Key-view Render using MoVE-LoRA, and Full-view Refiner to dynamically sample, render, and refine 3D objects.
💬 Research Conclusions:
– The proposed method demonstrates improved editing accuracy and spatial consistency compared to existing methods.
👉 Paper link: https://huggingface.co/papers/2506.00512

33. zip2zip: Inference-Time Adaptive Vocabularies for Language Models via Token Compression
🔑 Keywords: Tokenization, LLMs, LZW Compression, Hypertokens, Inference Speed
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce a dynamic vocabulary adjustment framework called zip2zip for improving inference speed in large language models using LZW compression.
🛠️ Research Methods:
– Implement a tokenizer based on Lempel-Ziv-Welch (LZW) compression to create reusable “hypertokens.”
– Utilize an embedding layer to compute embeddings for these hypertokens.
– Adapt a causal language modeling variant for working with compressed sequences.
💬 Research Conclusions:
– The zip2zip framework reduces input and output token sequence lengths by 20-60%, significantly enhancing inference latency.
👉 Paper link: https://huggingface.co/papers/2506.01084

34. Esoteric Language Models
🔑 Keywords: Eso-LMs, KV caching, diffusion models, parallel generation, inference efficiency
💡 Category: Generative Models
🌟 Research Objective:
– Introduce Eso-LMs, a fusion of autoregressive (AR) and Masked Diffusion Models (MDMs), to improve language modeling benchmarks.
🛠️ Research Methods:
– Implement KV caching for MDMs, while enabling parallel generation and optimizing the sampling schedule to enhance inference efficiency.
💬 Research Conclusions:
– Eso-LMs achieve up to 65x faster inference compared to standard MDMs and 4x faster than previous semi-autoregressive methods, setting a new standard in language modeling.
👉 Paper link: https://huggingface.co/papers/2506.01928
