AI Native Daily Paper Digest – 20250604

1. UniWorld: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
🔑 Keywords: Unified Generative Framework, Visual-Language Models, Image Perception, Image Manipulation
💡 Category: Generative Models
🌟 Research Objective:
– To develop a unified generative framework leveraging semantic features from visual-language models for improved image perception and manipulation.
🛠️ Research Methods:
– Utilized semantic encoders instead of VAEs, and integrated visual-language models with contrastive semantic encoders to create UniWorld framework.
💬 Research Conclusions:
– UniWorld outperforms the BAGEL model in image editing tasks with only 1% of the data required by BAGEL and maintains competitive image understanding and generation capabilities. The models and associated resources are fully open-sourced.
👉 Paper link: https://huggingface.co/papers/2506.03147

2. OThink-R1: Intrinsic Fast/Slow Thinking Mode Switching for Over-Reasoning Mitigation
🔑 Keywords: OThink-R1, Redundant Reasoning, Fast-Thinking, Slow-Thinking
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The paper introduces OThink-R1 to minimize reasoning redundancy in complex problem-solving by categorizing reasoning steps as essential or redundant.
🛠️ Research Methods:
– A systematic analysis of reasoning trajectories of large reasoning models (LRMs) was conducted, with the introduction of LLM-Judge to classify reasoning steps. OThink-R1 utilizes fast-thinking for simple tasks and slow-thinking for complex tasks.
💬 Research Conclusions:
– OThink-R1 reduces reasoning redundancy by about 23% on average while maintaining accuracy, providing practical guidelines for efficient reasoning models.
👉 Paper link: https://huggingface.co/papers/2506.02397

3. VS-Bench: Evaluating VLMs for Strategic Reasoning and Decision-Making in Multi-Agent Environments
🔑 Keywords: Vision Language Models, VS-Bench, strategic reasoning, decision-making, multi-agent environments
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce VS-Bench to evaluate Vision Language Models’ strategic reasoning and decision-making in complex multi-agent scenarios.
🛠️ Research Methods:
– Utilize eight vision-grounded environments to assess VLMs through cooperative, competitive, and mixed-motive interactions with both offline and online evaluation metrics.
💬 Research Conclusions:
– Significant performance gap exists between current models and optimal VLM performance, highlighting areas for future improvements and research on strategic multimodal agents.
👉 Paper link: https://huggingface.co/papers/2506.02387

4. CSVQA: A Chinese Multimodal Benchmark for Evaluating STEM Reasoning Capabilities of VLMs
🔑 Keywords: Vision-Language Models, scientific reasoning, domain-specific knowledge, visual question answering, evaluation protocol
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper presents CSVQA, a new benchmark to evaluate scientific reasoning in Vision-Language Models through domain-specific visual question answering.
🛠️ Research Methods:
– The benchmark includes 1,378 question-answer pairs across STEM disciplines, evaluating the integration of domain knowledge and visual evidence, with an evaluation protocol to assess model predictions and reasoning steps.
💬 Research Conclusions:
– Evaluations of 15 Vision-Language Models on CSVQA highlight significant performance disparities, with the top model achieving only 49.6% accuracy, indicating a critical need for improving scientific reasoning capabilities in these models.
👉 Paper link: https://huggingface.co/papers/2505.24120

5. Visual Embodied Brain: Let Multimodal Large Language Models See, Think, and Control in Spaces
🔑 Keywords: VeBrain, Multimodal Large Language Models, Visual-Spatial Reasoning, Physical Interaction, Compositional Capabilities
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce VeBrain, a unified framework that integrates multimodal understanding, visual-spatial reasoning, and physical interaction for legged robots.
🛠️ Research Methods:
– Reformulate robotic control into text-based MLLM tasks and propose a robotic adapter to convert control signals to motion policies.
💬 Research Conclusions:
– VeBrain demonstrates superior adaptability, flexibility, and performance in real-world robotic tasks compared to existing models such as Qwen2.5-VL, with significant performance gains across various benchmarks and robotics tasks.
👉 Paper link: https://huggingface.co/papers/2506.00123

6. OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models
🔑 Keywords: OmniSpatial, Vision-Language Models, Spatial Reasoning, Cognitive Psychology, Perspective-Taking
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce OmniSpatial, a comprehensive benchmark to evaluate the spatial reasoning of vision-language models based on cognitive psychology.
🛠️ Research Methods:
– Development of over 1.5K question-answer pairs through Internet data crawling and careful manual annotation, focused on dynamic reasoning, complex spatial logic, spatial interaction, and perspective-taking.
💬 Research Conclusions:
– Extensive experiments reveal significant limitations in current vision-language models’ spatial understanding, suggesting potential directions for future research.
👉 Paper link: https://huggingface.co/papers/2506.03135
7. MotionSight: Boosting Fine-Grained Motion Understanding in Multimodal LLMs
🔑 Keywords: Zero-shot method, Object-centric visual spotlight, Motion blur, MotionVid-QA, Fine-grained video motion understanding
💡 Category: Computer Vision
🌟 Research Objective:
– To enhance fine-grained video motion understanding using MotionSight, a zero-shot method with object-centric visual spotlight and motion blur as prompts.
🛠️ Research Methods:
– Introduced a novel zero-shot technique employing visual prompting to improve motion perception without training.
– Curated a large-scale dataset, MotionVid-QA, comprising hierarchical annotations and extensive video clips and QAs.
💬 Research Conclusions:
– MotionSight achieved state-of-the-art performance on MotionVid-QA, showcasing competitiveness with commercial models in fine-grained video motion understanding.
– All related code and annotations will be made publicly accessible for further research and development.
👉 Paper link: https://huggingface.co/papers/2506.01674

8. Sparse-vDiT: Unleashing the Power of Sparse Attention to Accelerate Video Diffusion Transformers
🔑 Keywords: Sparse-vDiT, Diffusion Transformers, sparsity patterns, inference speedups, FLOP reduction
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to accelerate Video Diffusion Transformer (vDiT) by identifying and leveraging sparsity patterns in attention maps to reduce FLOPs and improve inference speed without compromising visual quality.
🛠️ Research Methods:
– Researchers conducted a detailed analysis of attention maps in vDiT to identify recurring sparsity patterns: diagonal, multi-diagonal, and vertical-stripe structures.
– They developed a sparsity acceleration framework called Sparse-vDiT, incorporating pattern-optimized sparse kernels and an offline sparse diffusion search algorithm with hardware-aware cost modeling.
💬 Research Conclusions:
– Sparse-vDiT demonstrated significant improvements in theoretical FLOP reduction and inference speed while maintaining high visual fidelity when integrated into state-of-the-art vDiT models.
– The study proves that exploiting latent structural sparsity in vDiTs can be systematically beneficial for long video synthesis.
👉 Paper link: https://huggingface.co/papers/2506.03065

9. SynthRL: Scaling Visual Reasoning with Verifiable Data Synthesis
🔑 Keywords: SynthRL, Reinforcement Learning, Verifiable Rewards, Vision-language Models
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To investigate how synthesized reinforcement learning data can enhance reinforcement learning with verifiable rewards (RLVR).
🛠️ Research Methods:
– Introduced SynthRL, a scalable pipeline with three stages: selecting seed questions, augmenting them while preserving answers, and a verification stage for correctness and difficulty.
💬 Research Conclusions:
– SynthRL demonstrated scalability and effectiveness by synthesizing over 3.3K verifiable questions, showing consistent gains across benchmarks, particularly on challenging samples.
👉 Paper link: https://huggingface.co/papers/2506.02096

10. Native-Resolution Image Synthesis
🔑 Keywords: Native-resolution image synthesis, Diffusion Transformer, zero-shot generalization, aspect ratios
💡 Category: Generative Models
🌟 Research Objective:
– Introduce a new generative modeling paradigm, Native-resolution image synthesis, to enable image synthesis at arbitrary resolutions and aspect ratios.
🛠️ Research Methods:
– Development of the Native-resolution diffusion Transformer (NiT) architecture to model varying resolutions and aspect ratios effectively.
💬 Research Conclusions:
– NiT demonstrates state-of-the-art performance on ImageNet benchmarks and excellent zero-shot generalization, generating high-fidelity images across diverse resolutions and aspect ratios.
👉 Paper link: https://huggingface.co/papers/2506.03131

11. DINGO: Constrained Inference for Diffusion LLMs
🔑 Keywords: Diffusion LLMs, constrained decoding, structured outputs, regular expressions, JSON generation
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to enhance diffusion language models by enforcing structured output constraints to improve performance in tasks requiring such outputs.
🛠️ Research Methods:
– Introduction of DINGO, a dynamic programming-based decoding strategy that maintains distribution while enforcing user-specified constraints efficiently.
💬 Research Conclusions:
– DINGO significantly boosts performance on symbolic math and JSON generation tasks, indicating up to a 68 percentage point improvement over unconstrained inference.
👉 Paper link: https://huggingface.co/papers/2505.23061

12. Robot-R1: Reinforcement Learning for Enhanced Embodied Reasoning in Robotics
🔑 Keywords: Reinforcement Learning, Embodied Reasoning, Robot Control, GPT-4o, Keypoint State
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce Robot-R1 to enhance embodied reasoning for robot control using reinforcement learning, aiming to outperform existing methods like supervised fine-tuning and surpass GPT-4o in specific tasks.
🛠️ Research Methods:
– Utilization of reinforcement learning in Robot-R1 to predict keypoint states from scene images and environment metadata, inspired by the DeepSeek-R1 approach.
💬 Research Conclusions:
– Robot-R1 models outperform supervised fine-tuning methods and even GPT-4o in low-level action control tasks, with better generalization performance and avoiding issues like catastrophic forgetting.
👉 Paper link: https://huggingface.co/papers/2506.00070

13. GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents
🔑 Keywords: GUI-Actor, visual grounding, attention-based action head, grounding verifier, Vision Transformers
💡 Category: Computer Vision
🌟 Research Objective:
– To develop a method that improves the generalization and fine-tuning efficiency of GUI agents through coordinate-free GUI grounding using a VLM-based approach.
🛠️ Research Methods:
– Introduction of an attention-based action head and a grounding verifier to align relevant visual patches and select plausible action regions.
💬 Research Conclusions:
– GUI-Actor outperforms state-of-the-art methods on GUI action grounding benchmarks, generalizing better to new screen resolutions and layouts while achieving efficient fine-tuning.
👉 Paper link: https://huggingface.co/papers/2506.03143

14. FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
🔑 Keywords: FinMME, FinScore, GPT-4o, Multimodal Large Language Models, financial research
💡 Category: AI in Finance
🌟 Research Objective:
– Introduction of FinMME, a multimodal dataset for financial research to advance Multimodal Large Language Models in the finance domain.
– Development of FinScore, an evaluation system designed to assess the challenges in applying advanced models like GPT-4o in finance.
🛠️ Research Methods:
– Compilation of over 11,000 high-quality financial samples across 18 domains, involving 6 asset classes and 10 major chart types from 21 subtypes.
– The use of 20 annotators and validation mechanisms to ensure data quality.
– Implementation of FinScore with hallucination penalties and multi-dimensional capability assessment for unbiased evaluation.
💬 Research Conclusions:
– Despite the advancements in models like GPT-4o, their performance on FinMME is unsatisfactory, emphasizing the challenge of the dataset.
– The benchmark demonstrates high robustness, with prediction variations under different prompts remaining below 1%, indicating superior reliability.
– The dataset and evaluation protocol are publicly available, facilitating further research in the area.
👉 Paper link: https://huggingface.co/papers/2505.24714

15. Co-Evolving LLM Coder and Unit Tester via Reinforcement Learning
🔑 Keywords: Reinforcement Learning, Reward Design, ReasonFlux-Coder, Unit Test Generation, Inference Efficiency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce CURE, a reinforcement learning framework, to improve code and unit test generation accuracy without relying on ground-truth supervision.
🛠️ Research Methods:
– Utilize a novel reward design that co-evolves the coding and unit test generation capabilities through their interactions.
💬 Research Conclusions:
– CURE enhances code generation accuracy significantly, achieving a 5.3% improvement in standard accuracy and a 9.0% improvement in Best-of-N accuracy. Additionally, it extends naturally to downstream tasks, showing an 8.1% enhancement and achieving 64.8% inference efficiency in unit test generation.
👉 Paper link: https://huggingface.co/papers/2506.03136

16. RelationAdapter: Learning and Transferring Visual Relation with Diffusion Transformers
🔑 Keywords: RelationAdapter, Diffusion Transformer, content-aware editing intent, generation quality, visual prompt-based image editing
💡 Category: Computer Vision
🌟 Research Objective:
– Enhance Diffusion Transformer models using RelationAdapter to improve visual transformations and generalize across diverse tasks.
🛠️ Research Methods:
– Developed a lightweight module, RelationAdapter, and introduced the Relation252K dataset with 218 diverse editing tasks to evaluate performance.
💬 Research Conclusions:
– RelationAdapter significantly boosts generation quality and editing performance by effectively transferring editing intent to novel images.
👉 Paper link: https://huggingface.co/papers/2506.02528

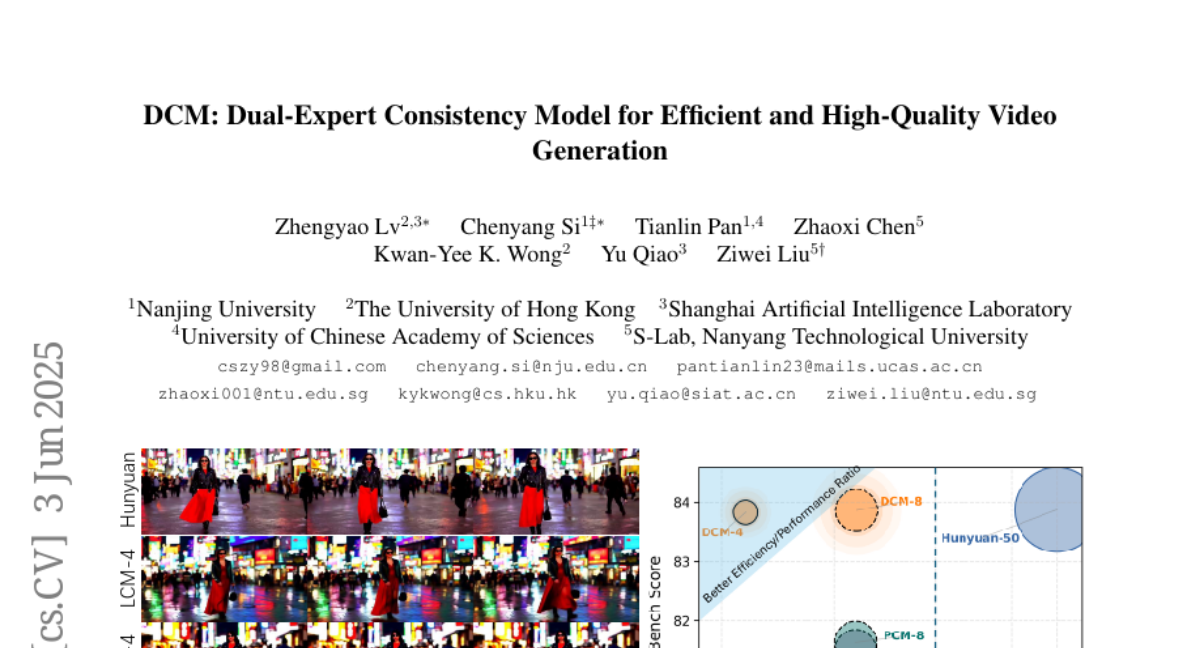
17. DCM: Dual-Expert Consistency Model for Efficient and High-Quality Video Generation
🔑 Keywords: Dual-Expert, Consistency Models, Temporal Coherence Loss, GAN, Expert Specialization
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to enhance the effectiveness of video diffusion model distillation by addressing learning dynamics inconsistencies.
🛠️ Research Methods:
– Introduction of a parameter-efficient Dual-Expert Consistency Model focusing on semantic and detail refinement.
– Implementation of Temporal Coherence Loss for improving motion consistency and application of GAN and Feature Matching Loss for detail enhancement.
💬 Research Conclusions:
– The approach achieves state-of-the-art visual quality with reduced sampling steps, demonstrating the strength of expert specialization in video diffusion models.
👉 Paper link: https://huggingface.co/papers/2506.03123
18. Training Language Models to Generate Quality Code with Program Analysis Feedback
🔑 Keywords: reinforcement learning, large language models, program analysis, code quality, unit tests
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance code quality in large language models by using a reinforcement learning framework that leverages automated feedback from program analysis and unit tests.
🛠️ Research Methods:
– Introduction of REAL, a reinforcement learning framework using program analysis and unit tests as automated feedback to guide code generation.
💬 Research Conclusions:
– REAL significantly improves both the functionality and code quality of generated code, outperforming state-of-the-art methods and addressing gaps between prototyping and production-ready code.
👉 Paper link: https://huggingface.co/papers/2505.22704

19. PCoreSet: Effective Active Learning through Knowledge Distillation from Vision-Language Models
🔑 Keywords: Knowledge distillation, Active learning, Vision-language models, Inductive bias, Probabilistic CoreSet
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to integrate active learning with knowledge distillation to efficiently select diverse, unlabeled samples for annotation using large vision-language models.
🛠️ Research Methods:
– The paper introduces ActiveKD, a framework leveraging the zero- and few-shot capabilities of vision-language models to incorporate inductive bias and proposes Probabilistic CoreSet for strategic sample selection.
💬 Research Conclusions:
– Evaluations on 11 datasets demonstrate that Probabilistic CoreSet consistently outperforms existing selection methods within the ActiveKD framework, advancing research at the intersection of active learning and knowledge distillation.
👉 Paper link: https://huggingface.co/papers/2506.00910

20. AnimeShooter: A Multi-Shot Animation Dataset for Reference-Guided Video Generation
🔑 Keywords: AnimeShooter, reference-guided, visual consistency, MLLMs, video diffusion models
💡 Category: Generative Models
🌟 Research Objective:
– The objective of this study is to create coherent animated video generation through the AnimeShooter dataset, which provides comprehensive annotations and visual consistency across shots.
🛠️ Research Methods:
– The study utilizes AnimeShooterGen, employing Multimodal Large Language Models (MLLMs) and video diffusion models to process reference images and previously generated shots, integrating reference and context-aware representations.
💬 Research Conclusions:
– Models trained on the AnimeShooter dataset demonstrate superior cross-shot visual consistency and adherence to reference visual guidance, underlining the dataset’s value in creating coherent animated videos.
👉 Paper link: https://huggingface.co/papers/2506.03126

21. FlowMo: Variance-Based Flow Guidance for Coherent Motion in Video Generation
🔑 Keywords: FlowMo, Motion Coherence, Temporal Representation, Text-to-Video Diffusion, Training-Free
💡 Category: Generative Models
🌟 Research Objective:
– To enhance motion coherence in pre-trained text-to-video diffusion models without additional training or external inputs.
🛠️ Research Methods:
– Introduced FlowMo, a training-free guidance method that utilizes the model’s own predictions to reduce patch-wise temporal variance and derive an appearance-debiased temporal representation.
💬 Research Conclusions:
– FlowMo significantly improves motion coherence in text-to-video diffusion models while maintaining visual quality and prompt alignment, providing an effective plug-and-play solution for enhancing temporal fidelity.
👉 Paper link: https://huggingface.co/papers/2506.01144
22. Self-Challenging Language Model Agents
🔑 Keywords: Self-Challenging framework, Code-as-Task, reinforcement learning, Llama-3.1-8B-Instruct
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce the Self-Challenging framework for training intelligent agents on self-generated high-quality tasks.
🛠️ Research Methods:
– Employ reinforcement learning where the agent plays both challenger and executor roles, generating and training on tasks defined as Code-as-Task.
💬 Research Conclusions:
– The Self-Challenging framework significantly improves tool-use performance, achieving over two-fold improvement in Llama-3.1-8B-Instruct evaluations.
👉 Paper link: https://huggingface.co/papers/2506.01716

23. LumosFlow: Motion-Guided Long Video Generation
🔑 Keywords: Long video generation, Key frames, Motion guidance, LMTV-DM, Optical flows
💡 Category: Generative Models
🌟 Research Objective:
– Address the challenge of synthesizing temporally coherent and visually compelling long video sequences.
🛠️ Research Methods:
– Utilize LMTV-DM for key frame generation and LOF-DM with MotionControlNet for smooth interpolation of frames, implementing a hierarchical pipeline with explicit motion guidance.
💬 Research Conclusions:
– Achieved 15x frame interpolation, maintaining consistent motion and appearance across long videos compared to traditional methods.
👉 Paper link: https://huggingface.co/papers/2506.02497

24. Deep Video Discovery: Agentic Search with Tool Use for Long-form Video Understanding
🔑 Keywords: Deep Video Discovery agent, Large Language Models, agentic search strategy, long-form video understanding, LVBench
💡 Category: Computer Vision
🌟 Research Objective:
– The primary objective is to address limitations in long-form video understanding by leveraging an autonomous agentic search strategy with large language models.
🛠️ Research Methods:
– The methodology involves utilizing a Deep Video Discovery agent that uses an agentic search strategy over segmented video clips, focusing on autonomous operation and strategic tool selection to enhance video analysis.
💬 Research Conclusions:
– The proposed system significantly surpasses previous methods on the LVBench dataset, achieving state-of-the-art performance in long-form video understanding. Comprehensive evaluations and ablation studies highlight the effectiveness of the system’s design and provide insights for further advancements.
👉 Paper link: https://huggingface.co/papers/2505.18079

25. How Much Backtracking is Enough? Exploring the Interplay of SFT and RL in Enhancing LLM Reasoning
🔑 Keywords: Large Language Models, Reinforcement Learning, Supervised Fine-tuning, Backtracking, Chain-of-Thought
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– The study explores the interaction between supervised fine-tuning and reinforcement learning in enhancing reasoning capabilities of large language models, specifically focusing on the role of backtracking.
🛠️ Research Methods:
– Systematic investigation on eight reasoning tasks, analyzing the impact of short and long chain-of-thought sequences in SFT and RL training, and conducting controlled experiments to understand the influence of backtracking.
💬 Research Conclusions:
– Longer chain-of-thought sequences with backtracking improve and stabilize reinforcement learning training. Challenging problems require more backtracks, and RL prioritizes structural patterns over content correctness during training.
👉 Paper link: https://huggingface.co/papers/2505.24273

26. Ctrl-Crash: Controllable Diffusion for Realistic Car Crashes
🔑 Keywords: Ctrl-Crash, car crashes, video diffusion techniques, realistic and controllable accident simulations, classifier-free guidance
💡 Category: Generative Models
🌟 Research Objective:
– To develop Ctrl-Crash, a model that generates realistic and controllable car crash videos to enhance traffic safety simulations.
🛠️ Research Methods:
– Utilizes signals such as bounding boxes, crash types, and an initial image frame for counterfactual scenario generation, employing classifier-free guidance for tunable control.
💬 Research Conclusions:
– Achieves state-of-the-art performance in video quality and realism compared to existing diffusion-based methods, validated through quantitative metrics and human evaluation.
👉 Paper link: https://huggingface.co/papers/2506.00227
27. SHARE: An SLM-based Hierarchical Action CorREction Assistant for Text-to-SQL
🔑 Keywords: SLM-based, LLMs, self-correction, stepwise action trajectories, text-to-SQL
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main objective is to enhance the error detection and correction capabilities of LLMs in text-to-SQL tasks through a new approach called SHARE.
🛠️ Research Methods:
– SHARE transforms SQL queries into sequential action trajectories and uses a two-phase granular refinement process. It operates by orchestrating three specialized Small Language Models (SLMs) in sequence. Additionally, a hierarchical self-evolution strategy is introduced for efficient training.
💬 Research Conclusions:
– SHARE significantly improves self-correction capabilities and is robust across different LLMs. It performs well under low-resource conditions, which benefits text-to-SQL applications concerned with data privacy.
👉 Paper link: https://huggingface.co/papers/2506.00391

28. Motion-Aware Concept Alignment for Consistent Video Editing
🔑 Keywords: MoCA-Video, Motion-Aware Concept Alignment, semantic mixing, temporal coherence, video synthesis
💡 Category: Generative Models
🌟 Research Objective:
– Introduce MoCA-Video, a training-free framework that injects semantic features of a reference image into a video while preserving motion and visual context.
🛠️ Research Methods:
– Utilized a diagonal denoising schedule and class-agnostic segmentation for object detection and tracking in latent space. Momentum-based semantic corrections and gamma residual noise stabilization were used to ensure smooth frame transitions.
💬 Research Conclusions:
– MoCA-Video outperforms existing baselines by achieving superior spatial consistency, coherent motion, and higher CASS scores, demonstrating controllable, high-quality video synthesis without training or fine-tuning.
👉 Paper link: https://huggingface.co/papers/2506.01004

29. FuseLIP: Multimodal Embeddings via Early Fusion of Discrete Tokens
🔑 Keywords: Multimodal Embedding, Transformer Model, VQA, Early Fusion, Discrete Image Tokenizers
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To present FuseLIP, a transformer-based architecture that uses a shared vocabulary for text and image tokens, enhancing multimodal embedding to outperform existing models in tasks like VQA and text-guided image retrieval.
🛠️ Research Methods:
– Leveraging recent progress in discrete image tokenizers to use a single transformer model that operates on an extended vocabulary of text and image tokens for early fusion, allowing interaction at each encoding depth for richer representations.
💬 Research Conclusions:
– FuseLIP outperforms other methods in multimodal embedding tasks such as VQA and text-guided image retrieval, while maintaining performance on unimodal tasks, thus offering an effective alternative for handling multimodal inputs.
👉 Paper link: https://huggingface.co/papers/2506.03096

30. ReFoCUS: Reinforcement-guided Frame Optimization for Contextual Understanding
🔑 Keywords: Reinforcement learning, Frame selection policy, Video QA, Temporal coherence
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To optimize frame selection for video-LLM to enhance reasoning performance in video QA by aligning with model preferences.
🛠️ Research Methods:
– Development of ReFoCUS, a novel frame-level policy optimization framework employing reinforcement learning.
– Use of an autoregressive, conditional selection architecture to efficiently explore combinatorial frame space maintaining temporal coherence.
💬 Research Conclusions:
– ReFoCUS improves reasoning performance across multiple video QA benchmarks by aligning frame selection with model-internal utility without requiring explicit supervision at the frame level.
👉 Paper link: https://huggingface.co/papers/2506.01274

31. Datasheets Aren’t Enough: DataRubrics for Automated Quality Metrics and Accountability
🔑 Keywords: Dataset Quality, Human Annotations, LLM-based Evaluation, DataRubrics
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To promote the integration of systematic, rubric-based evaluation metrics in the dataset review process to address quality control shortcomings.
🛠️ Research Methods:
– Exploration of scalable and cost-effective methods for synthetic data generation and evaluation, including the use of LLM-as-a-judge approaches.
– Introduction of DataRubrics, a structured framework that utilizes recent advances in LLM-based evaluation to assess the quality of datasets.
💬 Research Conclusions:
– DataRubrics provides a reproducible, scalable, and actionable solution for maintaining high standards in data-centric research, supporting both authors and reviewers in upholding data quality.
– Code is released to ensure reproducibility of LLM-based evaluations at https://github.com/datarubrics/datarubrics.
👉 Paper link: https://huggingface.co/papers/2506.01789

32. Hanfu-Bench: A Multimodal Benchmark on Cross-Temporal Cultural Understanding and Transcreation
🔑 Keywords: Hanfu-Bench, vision-language models, multimodal dataset, cultural understanding, cultural image transcreation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce Hanfu-Bench, a novel expert-curated multimodal dataset addressing temporal aspects of cultural understanding and creative adaptation using vision-language models.
🛠️ Research Methods:
– Two core tasks in the dataset: cultural visual understanding and cultural image transcreation to test the capabilities of VLMs in recognizing temporal-cultural features and transforming traditional attire into modern designs.
💬 Research Conclusions:
– Closed VLMs perform comparably to non-experts in visual cultural understanding but are 10% less effective than human experts. Open VLMs underperform further. For image transcreation, the best model only achieves a 42% success rate, highlighting major challenges in temporal cultural understanding and adaptation.
👉 Paper link: https://huggingface.co/papers/2506.01565

33. QARI-OCR: High-Fidelity Arabic Text Recognition through Multimodal Large Language Model Adaptation
🔑 Keywords: Arabic OCR, AI Native, iterative fine-tuning, specialized datasets, diacritics
💡 Category: Computer Vision
🌟 Research Objective:
– To develop and refine vision-language models specifically for Arabic OCR, addressing challenges like script complexity and diacritics.
🛠️ Research Methods:
– Utilized iterative fine-tuning on specialized synthetic datasets to optimize models for Arabic OCR.
💬 Research Conclusions:
– Qari-OCR achieved state-of-the-art performance with significant improvements in handling Arabic script complexities, yielding low Word Error Rate (0.160) and Character Error Rate (0.061).
– The release of models and datasets aims to encourage further research and advancements in Arabic OCR accuracy and efficiency.
👉 Paper link: https://huggingface.co/papers/2506.02295

34. TL;DR: Too Long, Do Re-weighting for Effcient LLM Reasoning Compression
🔑 Keywords: Large Language Models, Reinforcement Learning, dynamic ratio-based training, reasoning accuracy
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a dynamic ratio-based training pipeline that reduces output tokens in large language models while preserving reasoning accuracy.
🛠️ Research Methods:
– Implementation of a training pipeline that balances weights between System-1 and System-2 data, validated on DeepSeek-R1-Distill-7B and DeepSeek-R1-Distill-14B models across various benchmarks.
💬 Research Conclusions:
– The proposed method reduces the number of output tokens by nearly 40% without sacrificing the reasoning accuracy of the models.
👉 Paper link: https://huggingface.co/papers/2506.02678

35. Controllable Human-centric Keyframe Interpolation with Generative Prior
🔑 Keywords: PoseFuse3D-KI, 3D human guidance, Controllable Human-centric Keyframe Interpolation, SMPL-X encoder, video frame interpolation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce PoseFuse3D-KI to integrate 3D human guidance into diffusion models for more accurate and controllable video frame interpolation.
🛠️ Research Methods:
– Utilize a novel SMPL-X encoder that transforms 3D geometry and shape into the 2D latent conditioning space and a fusion network for integration of 3D cues with 2D pose embeddings. Develop CHKI-Video dataset for evaluation.
💬 Research Conclusions:
– PoseFuse3D-KI outperforms state-of-the-art baselines with a 9% improvement in PSNR and a 38% reduction in LPIPS, demonstrating improved interpolation fidelity.
👉 Paper link: https://huggingface.co/papers/2506.03119

36. R^2ec: Towards Large Recommender Models with Reasoning
🔑 Keywords: Unified Recommender Model, Intrinsic Reasoning, Reinforcement Learning, RecPO
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces a unified recommender model aiming to integrate reasoning capabilities intrinsically within the recommendation process using reinforcement learning.
🛠️ Research Methods:
– A novel model architecture facilitating interleaved reasoning and recommendation through an autoregressive process is proposed, alongside RecPO, a reinforcement learning framework utilizing a fused reward scheme.
💬 Research Conclusions:
– The proposed approach significantly improves recommendation performance, achieving impressive results with 68.67% relative improvement in Hit@5 and 45.21% in NDCG@20 when tested on three datasets.
👉 Paper link: https://huggingface.co/papers/2505.16994

37. Accelerating Diffusion LLMs via Adaptive Parallel Decoding
🔑 Keywords: Adaptive parallel decoding, diffusion large language models, autoregressive decoding, throughput, quality
💡 Category: Generative Models
🌟 Research Objective:
– To introduce Adaptive parallel decoding (APD) to enhance the throughput of diffusion large language models (dLLMs) without compromising quality.
🛠️ Research Methods:
– APD dynamically adjusts the number of tokens generated in parallel by defining a multiplicative mixture between dLLM marginal probabilities and the joint probability of sequences with a small auxiliary autoregressive model.
– Optimizes APD with KV caching and by limiting the size of the masked input.
💬 Research Conclusions:
– APD dramatically increases throughput with minimal quality degradation on downstream benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.00413

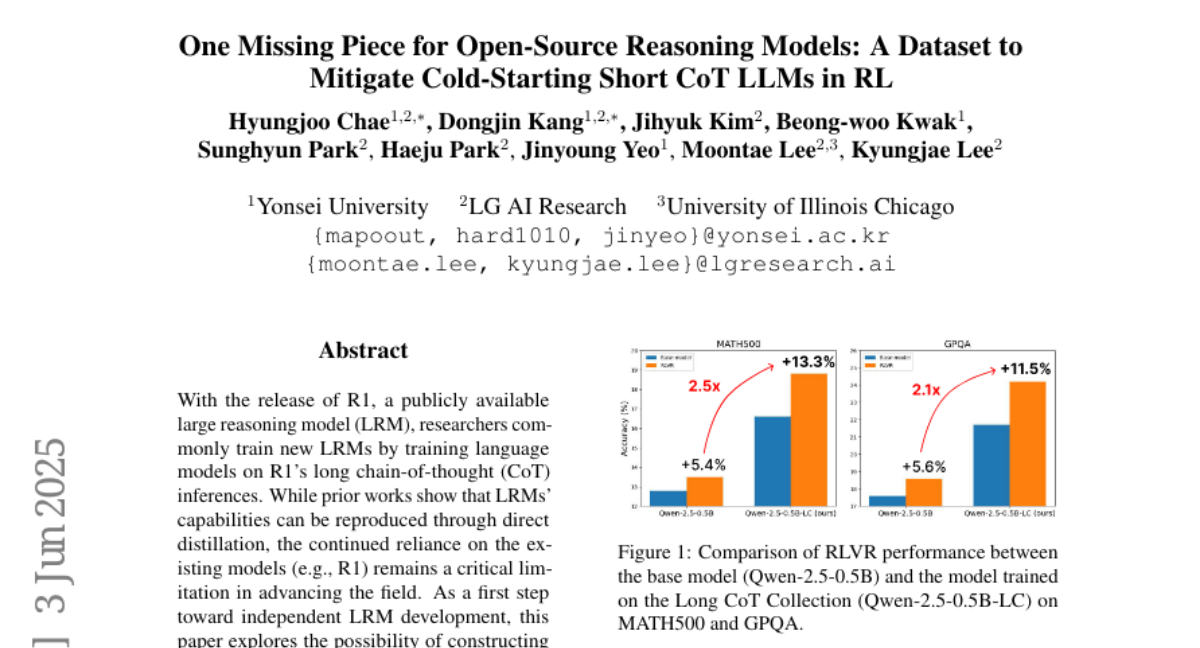
38. One Missing Piece for Open-Source Reasoning Models: A Dataset to Mitigate Cold-Starting Short CoT LLMs in RL
🔑 Keywords: Long CoT Collection, reinforcement learning, reasoning skills, short CoT LLMs, AI-generated summary
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To construct a long CoT dataset with short CoT LLMs to enhance reasoning skills and establish a foundation for reinforcement learning without relying on existing large reasoning models like R1.
🛠️ Research Methods:
– Development of the Long CoT Collection dataset, consisting of 100K CoT rationales annotated by short CoT LLMs. This includes a pipeline that integrates novel reasoning strategies and makes reasoning processes controllable.
💬 Research Conclusions:
– The Long CoT Collection dataset achieves quality comparable to, or slightly below, that of the R1 model. It not only strengthens general reasoning skills but also enhances reinforcement learning significantly with models initialized on this dataset showing considerable improvements with RLVR.
👉 Paper link: https://huggingface.co/papers/2506.02338
39. ORV: 4D Occupancy-centric Robot Video Generation
🔑 Keywords: Occupancy-centric, Robot Video generation, Video generation, Photorealistic robot videos, Temporal consistency
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The paper introduces ORV, an Occupancy-centric Robot Video generation framework, designed to enhance the precision and generalization of robot video simulations using 4D semantic occupancy sequences.
🛠️ Research Methods:
– ORV leverages occupancy-based representations to provide accurate semantic and geometric guidance, enabling photorealistic and temporally consistent video generation with controllable parameters.
💬 Research Conclusions:
– ORV demonstrates superior performance compared to existing methods, particularly in generating multi-view videos of robot gripping operations, which benefits various robotic learning tasks.
👉 Paper link: https://huggingface.co/papers/2506.03079

40. Knowing Before Saying: LLM Representations Encode Information About Chain-of-Thought Success Before Completion
🔑 Keywords: zero-shot Chain-of-Thought, LLM representations, early stopping, BERT-based baseline
💡 Category: Natural Language Processing
🌟 Research Objective:
– Examine whether zero-shot Chain-of-Thought (CoT) success can be predicted before completion.
🛠️ Research Methods:
– Utilizing a probing classifier based on LLM representations to assess prediction capabilities without token generation.
💬 Research Conclusions:
– Early reasoning steps effectively capture key information, enabling improved performance with early stopping.
– BERT-based baseline underperforms due to reliance on shallow cues, whereas early LLM representations encode deeper reasoning.
– Early stopping can enhance CoT efficiency; however, supervised or reinforcement learning could further refine this process.
👉 Paper link: https://huggingface.co/papers/2505.24362

41. Beyond In-Context Learning: Aligning Long-form Generation of Large Language Models via Task-Inherent Attribute Guidelines
🔑 Keywords: AI-generated summary, In-context learning, pre-trained large language models, LongGuide
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to improve the performance of pre-trained large language models (LLMs) in long-form generation tasks by introducing guidelines for metric and output constraints.
🛠️ Research Methods:
– The study introduces LongGuide, which generates metric and output constraint guidelines to enhance task language and format properties, thereby improving LLM performance in zero- and few-shot settings.
💬 Research Conclusions:
– LongGuide effectively improves both open- and closed-source LLMs by over 5% and demonstrates generalizability, allowing weak models to learn from and enhance stronger models. It also works well with automatic prompt optimizers.
👉 Paper link: https://huggingface.co/papers/2506.01265

42. Angles Don’t Lie: Unlocking Training-Efficient RL Through the Model’s Own Signals
🔑 Keywords: GAIN-RL, Reinforcement Fine-tuning, Large Language Models, angle concentration, training efficiency
💡 Category: Reinforcement Learning
🌟 Research Objective:
– This study aims to address the sample inefficiency in Reinforcement Fine-tuning of Large Language Models by leveraging angle concentration signals.
🛠️ Research Methods:
– A Gradient-driven Angle-Informed Navigated RL (GAIN-RL) framework is applied, utilizing the intrinsic angle concentration signal to dynamically select training data, enhancing gradient updates.
💬 Research Conclusions:
– GAIN-RL achieves over a 2.5x acceleration in training efficiency for diverse tasks and scales, offering data-efficient training by achieving superior performance with reduced data compared to conventional methods.
👉 Paper link: https://huggingface.co/papers/2506.02281

43. MERIT: Multilingual Semantic Retrieval with Interleaved Multi-Condition Query
🔑 Keywords: multilingual dataset, interleaved multi-condition semantic retrieval, embedding reconstruction, contrastive learning, pre-trained MLLMs
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce the MERIT dataset for interleaved multi-condition semantic retrieval, addressing the limitations of existing models and datasets.
🛠️ Research Methods:
– Develop Coral, a fine-tuning framework that uses embedding reconstruction and contrastive learning to improve retrieval performance, specifically for multilingual and multi-condition scenarios.
💬 Research Conclusions:
– Coral framework significantly enhances retrieval performance, achieving a 45.9% improvement over conventional methods on the MERIT dataset, with strong generalization capabilities across eight established retrieval benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.03144

44. Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning
🔑 Keywords: self-reflection, reinforcement learning, large language models, performance gains
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To enhance the performance of large language models through self-reflection and reinforcement learning using limited external feedback.
🛠️ Research Methods:
– Implementing a two-stage approach where models are prompted to self-reflect on incorrect answers and are subsequently retested, with successful self-reflections rewarded.
💬 Research Conclusions:
– The method shows significant performance improvements, with smaller fine-tuned models notably outperforming larger counterparts in tasks such as math equation writing and function calling.
👉 Paper link: https://huggingface.co/papers/2505.24726

45. Multimodal DeepResearcher: Generating Text-Chart Interleaved Reports From Scratch with Agentic Framework
🔑 Keywords: Multimodal DeepResearcher, Large Language Models, Visualizations, Multimodal Reports
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop a framework called Multimodal DeepResearcher that enables Large Language Models to generate high-quality multimodal reports by integrating text and visualizations.
🛠️ Research Methods:
– Introduced the Formal Description of Visualization, a structured textual representation to facilitate the generation of diverse visualizations.
– Decomposed the task into four stages: researching, exemplar report textualization, planning, and multimodal report generation.
💬 Research Conclusions:
– Multimodal DeepResearcher demonstrated effectiveness by achieving an 82% win rate over baseline methods using the same Claude 3.7 Sonnet model.
– Developed the MultimodalReportBench for evaluating generated multimodal reports by using 100 diverse topics and 5 metrics.
👉 Paper link: https://huggingface.co/papers/2506.02454
46. M^3FinMeeting: A Multilingual, Multi-Sector, and Multi-Task Financial Meeting Understanding Evaluation Dataset
🔑 Keywords: AI-generated summary, M^3FinMeeting, multilingual, multi-sector, multi-task
💡 Category: AI in Finance
🌟 Research Objective:
– The study aims to introduce M^3FinMeeting, a new benchmark designed to evaluate large language models’ performance in understanding financial meetings across different languages and industries.
🛠️ Research Methods:
– M^3FinMeeting is developed as a multilingual dataset supporting English, Chinese, and Japanese, encompasses various industry sectors, and includes three tasks: summarization, question-answer pair extraction, and question answering.
💬 Research Conclusions:
– Experimental results show that even advanced long-context language models require improvement, proving M^3FinMeeting’s effectiveness in assessing language models’ financial meeting comprehension skills.
👉 Paper link: https://huggingface.co/papers/2506.02510

47. Revisiting LRP: Positional Attribution as the Missing Ingredient for Transformer Explainability
🔑 Keywords: AI-generated, Transformer explainability, Layer-wise Relevance Propagation (LRP), positional encoding (PE), NLP explainability tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance Transformer explainability by incorporating positional encoding into Layer-wise Relevance Propagation (LRP) methods, thereby addressing limitations in existing approaches.
🛠️ Research Methods:
– Reformulation of the input space as position-token pairs to propose specialized LRP rules for various positional encoding methods, including Rotary, Learnable, and Absolute PE.
💬 Research Conclusions:
– The specialized LRP method significantly outperforms state-of-the-art explainability techniques in vision and NLP tasks, demonstrating improved relevance propagation by accounting for positional encoding.
👉 Paper link: https://huggingface.co/papers/2506.02138

48.
