AI Native Daily Paper Digest – 20250606

1. SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
🔑 Keywords: Video Restoration, AI-Generated, Adaptive Window Attention, Feature Matching Loss
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to develop a one-step diffusion-based video restoration model, SeedVR2, to enhance visual quality with reduced computational cost.
🛠️ Research Methods:
– Introduces an adaptive window attention mechanism adjusting window size for resolution.
– Utilizes adversarial training and integrates a feature matching loss for stability and efficiency in high-resolution video restoration.
💬 Research Conclusions:
– SeedVR2 achieves comparable or superior performance to existing video restoration methods in a single step while maintaining efficiency.
👉 Paper link: https://huggingface.co/papers/2506.05301
2. ComfyUI-Copilot: An Intelligent Assistant for Automated Workflow Development
🔑 Keywords: AI-driven art creation, large language model, multi-agent system, workflow efficiency, ComfyUI
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To enhance the usability and efficiency of ComfyUI, an open-source platform for AI-driven art creation, by addressing challenges like limited documentation and workflow complexity.
🛠️ Research Methods:
– Utilization of a large language model-powered plugin with a hierarchical multi-agent framework to provide intelligent recommendations and automated workflow construction.
💬 Research Conclusions:
– ComfyUI-Copilot effectively recommends nodes, accelerates workflow development, lowers entry barriers for beginners, and enhances workflow efficiency for experienced users.
👉 Paper link: https://huggingface.co/papers/2506.05010
3. RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
🔑 Keywords: 3D-aware VLM, Reinforcement Fine-tuning (RFT), Spatial Referring Tasks, RefSpatial, RefSpatial-Bench
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce RoboRefer, a 3D-aware vision language model designed to enhance spatial understanding and multi-step reasoning in embodied robots.
🛠️ Research Methods:
– Employ supervised fine-tuning (SFT) with a specialized depth encoder for precise spatial understanding.
– Utilize reinforcement fine-tuning (RFT) with metric-sensitive process reward functions for advanced multi-step spatial reasoning.
💬 Research Conclusions:
– Experiments show RoboRefer achieves state-of-the-art spatial understanding with an 89.6% success rate and surpasses other baselines by a significant margin in accuracy on the RefSpatial-Bench benchmark.
👉 Paper link: https://huggingface.co/papers/2506.04308

4. Diagonal Batching Unlocks Parallelism in Recurrent Memory Transformers for Long Contexts
🔑 Keywords: Diagonal Batching, Recurrent Memory Transformers, GPU inference, long-context tasks
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address the performance bottleneck in Recurrent Memory Transformers for long-context inference by introducing a new technique.
🛠️ Research Methods:
– Propose and implement a scheduling scheme named Diagonal Batching to achieve parallelism and efficient GPU inference without retraining.
💬 Research Conclusions:
– Diagonal Batching provides a 3.3x speedup over standard full-attention models and 1.8x over sequential RMT implementations, reducing inference costs and latency.
👉 Paper link: https://huggingface.co/papers/2506.05229

5. Video World Models with Long-term Spatial Memory
🔑 Keywords: world models, video frames, scene consistency, long-term spatial memory, 3D memory mechanisms
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to enhance the long-term consistency of video world models by integrating a geometry-grounded long-term spatial memory mechanism.
🛠️ Research Methods:
– The framework involves storing and retrieving information from long-term spatial memory and uses custom datasets to train and evaluate world models with explicitly stored 3D memory mechanisms.
💬 Research Conclusions:
– Evaluations demonstrate improved quality, consistency, and context length compared to relevant baselines, advancing long-term consistent world generation.
👉 Paper link: https://huggingface.co/papers/2506.05284
6. Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights
🔑 Keywords: Surfer-H, Holo1, Vision-Language Models, WebClick, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Surfer-H has been developed as a cost-efficient web agent to perform user-defined tasks using Vision-Language Models.
🛠️ Research Methods:
– The integration of Surfer-H with Holo1, a new open-weight collection of Vision-Language Models specialized in web navigation, which was trained on diverse data sources including open-access web content and synthetic examples.
💬 Research Conclusions:
– Surfer-H, powered by Holo1, achieves a state-of-the-art 92.2% performance on the WebVoyager benchmark, establishing a balance between accuracy and cost-efficiency. The open-sourcing of Holo1 model weights and WebClick dataset aims to advance research in agentic systems.
👉 Paper link: https://huggingface.co/papers/2506.02865

7. VideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models
🔑 Keywords: text-to-video synthesis, physics understanding, Token Relation Distillation, REPA, spatio-temporal alignment
💡 Category: Generative Models
🌟 Research Objective:
– To enhance text-to-video synthesis by integrating physics understanding into T2V models using the VideoREPA framework.
🛠️ Research Methods:
– Introduced Token Relation Distillation loss and utilized spatio-temporal alignment to finetune pre-trained T2V models.
💬 Research Conclusions:
– VideoREPA significantly improves the physics commonsense of T2V models, notably enhancing video generation fidelity in line with intuitive physics, as demonstrated on benchmarks.
👉 Paper link: https://huggingface.co/papers/2505.23656

8. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
🔑 Keywords: Qwen3 Embedding, Multilingual text understanding, Text embedding, Reranking, State-of-the-art
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce the Qwen3 Embedding series as a significant advancement in text embedding and reranking capabilities, improving upon the GTE-Qwen series.
🛠️ Research Methods:
– Implement a multi-stage training pipeline combining large-scale unsupervised pre-training with supervised fine-tuning on high-quality datasets, and employ model merging strategies.
💬 Research Conclusions:
– The Qwen3 Embedding series achieves state-of-the-art performance across multilingual and retrieval benchmarks, demonstrating effectiveness in various retrieval tasks and facilitating reproducibility under the Apache 2.0 license.
👉 Paper link: https://huggingface.co/papers/2506.05176

9. The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
🔑 Keywords: AI Native, Large Language Models, Openly Licensed Text, Common Pile v0.1, 7 Billion Parameter LLMs
💡 Category: Natural Language Processing
🌟 Research Objective:
– Address issues of intellectual property infringement and ethical concerns by using the openly licensed Common Pile v0.1 dataset for training LLMs.
🛠️ Research Methods:
– Develop and curate a high-quality, eight-terabyte dataset from 30 diverse sources for LLM pretraining.
– Train two competitive 7 billion parameter LLMs (Comma v0.1-1T and Comma v0.1-2T) using 1 and 2 trillion tokens of the dataset.
💬 Research Conclusions:
– The Comma LLMs attain competitive performance compared to other LLMs trained on unlicensed text, affirming the viability of the Common Pile dataset for training high-quality LLMs.
– Released the dataset, associated code, training mixture, and model checkpoints for further research and development.
👉 Paper link: https://huggingface.co/papers/2506.05209

10. VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
🔑 Keywords: VideoMathQA, cross-modal reasoning, mathematical reasoning, structured visual content, multi-step reasoning
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study introduces VideoMathQA, a benchmark to evaluate models’ ability to perform temporally extended cross-modal reasoning in various mathematical domains within video settings.
🛠️ Research Methods:
– The benchmark encompasses 10 mathematical domains with videos from 10 seconds to over 1 hour, requiring models to integrate visual, audio, and textual modalities.
– Graduate-level experts conducted over 920 man-hours of annotations to ensure quality.
💬 Research Conclusions:
– VideoMathQA highlights existing limitations in models and establishes an evaluation framework for reasoning across temporally extended, modality-rich mathematical scenarios.
– The benchmark aims to push models beyond mere perception towards reasoning capabilities.
👉 Paper link: https://huggingface.co/papers/2506.05349
11. Aligning Latent Spaces with Flow Priors
🔑 Keywords: Flow-based generative models, Learnable latent spaces, Alignment loss, Log-likelihood maximization, ImageNet
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces a framework to align learnable latent spaces with target distributions using flow-based generative models to optimize computational efficiency and improve log-likelihood maximization.
🛠️ Research Methods:
– The method involves pretraining a flow model on target features and using an alignment loss to regularize the latent space, providing a surrogate objective to maximize the variational lower bound of log-likelihood.
💬 Research Conclusions:
– The approach is computationally efficient, demonstrated in image generation experiments on ImageNet, effectively approximating the target distribution’s negative log-likelihood and validated through theoretical and empirical means.
👉 Paper link: https://huggingface.co/papers/2506.05240

12. AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs
🔑 Keywords: CG-AV-Counting, Multimodal, AV-Reasoner, Reinforcement Learning, Out-of-Domain
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce CG-AV-Counting, a new benchmark for video counting incorporating multimodal questions and annotated clues, to improve MLLMs in counting tasks.
🛠️ Research Methods:
– Developed AV-Reasoner, a model utilizing GRPO and curriculum learning, to generalize counting ability from related tasks.
💬 Research Conclusions:
– AV-Reasoner achieves state-of-the-art results on various benchmarks utilizing reinforcement learning but struggles with performance on out-of-domain tasks.
👉 Paper link: https://huggingface.co/papers/2506.05328

13. Inference-Time Hyper-Scaling with KV Cache Compression
🔑 Keywords: Dynamic Memory Sparsification, Inference-time hyper-scaling, Transformer LLMs, KV cache, token generation
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to enhance token generation efficiency and reasoning accuracy in Transformer LLMs by compressing the KV cache through inference-time hyper-scaling.
🛠️ Research Methods:
– Introduced Dynamic Memory Sparsification (DMS) as a novel method to compress KV caches effectively, achieving up to 8 times compression with only 1K training steps, while retaining accuracy.
💬 Research Conclusions:
– Demonstrated that DMS significantly boosts accuracy across various models like Qwen-R1 32B, with notable improvements in benchmark scores, maintaining competitive inference runtime and memory efficiency.
👉 Paper link: https://huggingface.co/papers/2506.05345

14. Unfolding Spatial Cognition: Evaluating Multimodal Models on Visual Simulations
🔑 Keywords: Spatial cognition, Visual simulations, STARE, Multimodal large language models, Geometric transformations
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce the STARE benchmark to evaluate multimodal models on multi-step visual simulation tasks, reflecting practical cognitive challenges.
🛠️ Research Methods:
– Evaluation on 4,000 tasks involving 2D and 3D transformations, spatial reasoning tasks like cube net folding and tangram puzzles, and real-world reasoning to mimic everyday cognitive challenges.
💬 Research Conclusions:
– Models perform well on simpler 2D transformations but struggle with complex tasks requiring visual simulations. Despite gains with intermediary visual simulations, models show inconsistent improvements, indicating difficulty in leveraging visual information effectively as compared to humans.
👉 Paper link: https://huggingface.co/papers/2506.04633

15. StreamBP: Memory-Efficient Exact Backpropagation for Long Sequence Training of LLMs
🔑 Keywords: StreamBP, memory-efficient, exact BP, language models, gradient checkpointing
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce StreamBP, a memory-efficient and exact backpropagation method, that reduces memory costs and enhances training speeds for language models with long sequence data.
🛠️ Research Methods:
– Utilizes a linear decomposition of the chain rule in a layer-wise manner to significantly reduce memory costs and leverage causal structures for efficient computation.
💬 Research Conclusions:
– StreamBP allows larger sequence lengths by 2.8-5.5 times compared to gradient checkpointing while maintaining comparable or even reduced processing time.
– Easily integrates with transformer models, supports multi-GPU training, and enhances batch size scaling for accelerated training.
👉 Paper link: https://huggingface.co/papers/2506.03077

16. SparseMM: Head Sparsity Emerges from Visual Concept Responses in MLLMs
🔑 Keywords: SparseMM, KV-Cache optimization, visual heads, attention mechanisms, Multimodal Large Language Models
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To investigate how Multimodal Large Language Models (MLLMs) process visual inputs and analyze their attention mechanisms to identify visual heads.
🛠️ Research Methods:
– Developed a training-free framework to quantify head-level visual relevance using targeted response analysis, leading to the creation of the SparseMM strategy for KV-Cache optimization.
💬 Research Conclusions:
– SparseMM provides significant real-time acceleration (1.38x) and memory reduction (52%) while maintaining performance parity, validating its efficiency on mainstream multimodal benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.05344

17. EOC-Bench: Can MLLMs Identify, Recall, and Forecast Objects in an Egocentric World?
🔑 Keywords: EOC-Bench, Egocentric Vision, Multimodal Large Language Models, Object-Centric Cognition
💡 Category: Computer Vision
🌟 Research Objective:
– The introduction of EOC-Bench to systematically evaluate object-centric embodied cognition in dynamic egocentric scenarios.
🛠️ Research Methods:
– Development of a human-in-the-loop annotation framework with four question types and a multi-scale temporal accuracy metric for temporal evaluation.
💬 Research Conclusions:
– EOC-Bench significantly contributes to advancing the embodied object cognitive capabilities of MLLMs, providing a solid foundation for creating core models for embodied systems.
👉 Paper link: https://huggingface.co/papers/2506.05287

18. MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning
🔑 Keywords: MINT-CoT, Chain-of-Thought, Multimodal mathematical reasoning, Vision encoders, Visual tokens
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper aims to enhance multimodal mathematical reasoning by introducing MINT-CoT, which interleaves visual tokens with textual Chain-of-Thought reasoning steps.
🛠️ Research Methods:
– Developed MINT-CoT dataset, including 54K math problems aligning reasoning with visual regions.
– Implemented a three-stage training strategy involving text-only CoT SFT, interleaved CoT SFT, and interleaved CoT RL.
💬 Research Conclusions:
– The MINT-CoT-7B model significantly outperforms baseline models, showcasing improvements in mathematical visual reasoning tasks by +34.08% on MathVista, +28.78% on GeoQA, and +23.2% on MMStar.
👉 Paper link: https://huggingface.co/papers/2506.05331

19. Revisiting Depth Representations for Feed-Forward 3D Gaussian Splatting
🔑 Keywords: PM-Loss, 3D Gaussian Splatting, Depth Maps, Pointmap, Pre-trained Transformer
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce PM-Loss, a regularization technique to enhance the accuracy of depth maps and rendering quality in 3D Gaussian Splatting.
🛠️ Research Methods:
– Utilize a pointmap predicted by a pre-trained transformer to enforce geometric smoothness around object boundaries.
💬 Research Conclusions:
– The proposed method significantly improves rendering results in various architectures and scenes by addressing depth discontinuities and enhancing depth map accuracy.
👉 Paper link: https://huggingface.co/papers/2506.05327

20. FlexPainter: Flexible and Multi-View Consistent Texture Generation
🔑 Keywords: FlexPainter, texture generation, image diffusion prior, conditional embedding space, multi-modal guidance
💡 Category: Generative Models
🌟 Research Objective:
– Introduce FlexPainter, a novel pipeline for generating high-quality texture maps with enhanced flexibility and consistency.
🛠️ Research Methods:
– Utilizes a shared conditional embedding space for flexible aggregation of different input modalities and proposes an image-based CFG method for stylization.
– Leverages 3D knowledge within image diffusion priors and employs a view synchronization and adaptive weighting module to ensure consistency.
💬 Research Conclusions:
– FlexPainter significantly outperforms existing state-of-the-art methods in terms of flexibility and generation quality, producing seamless, high-resolution textures.
👉 Paper link: https://huggingface.co/papers/2506.02620

21. Language-Image Alignment with Fixed Text Encoders
🔑 Keywords: LIFT, Language-Image alignment, pre-trained fixed large language model, compositional understanding, CLIP
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To explore whether a pre-trained fixed large language model can effectively guide visual representation learning without the need for costly joint training methods like CLIP.
🛠️ Research Methods:
– Benchmarking and ablation studies to evaluate the performance of the proposed LIFT framework in scenarios requiring compositional understanding and long captions.
💬 Research Conclusions:
– The LIFT framework, utilizing a pre-trained fixed text encoder, outperforms the CLIP method in most scenarios while also improving computational efficiency, offering an alternative design for language-aligned visual representation learning.
👉 Paper link: https://huggingface.co/papers/2506.04209

22. Search Arena: Analyzing Search-Augmented LLMs
🔑 Keywords: Search-augmented language models, human-preference, user interactions, citations, credibility
💡 Category: Human-AI Interaction
🌟 Research Objective:
– To introduce and analyze Search Arena, a large-scale, human-preference dataset focusing on user interactions with search-augmented language models.
🛠️ Research Methods:
– The dataset includes over 24,000 paired multi-turn user interactions and 12,000 human preference votes, coupled with cross-arena analyses in various environments to assess model performance.
💬 Research Conclusions:
– User preferences are significantly influenced by the number and source of citations.
– Community-driven platforms are generally preferred over static encyclopedic sources.
– Web search integration does not degrade performance in non-search settings and may enhance it; however, search-intensive environments suffer if only relying on the model’s parametric knowledge.
👉 Paper link: https://huggingface.co/papers/2506.05334

23. Autoregressive Images Watermarking through Lexical Biasing: An Approach Resistant to Regeneration Attack
🔑 Keywords: Lexical Bias Watermarking, Autoregressive models, Watermark detection, Regeneration attacks
💡 Category: Generative Models
🌟 Research Objective:
– Enhance the security of autoregressive image generation models by embedding robust watermarks.
🛠️ Research Methods:
– Introduce Lexical Bias Watermarking (LBW) to bias token selection and embed watermarks directly into token maps.
💬 Research Conclusions:
– LBW demonstrates superior robustness, particularly in resisting regeneration attacks through statistical analysis and quantization.
👉 Paper link: https://huggingface.co/papers/2506.01011

24. Evaluation is All You Need: Strategic Overclaiming of LLM Reasoning Capabilities Through Evaluation Design
🔑 Keywords: Deepseek-R1-Distill, benchmark evaluation, open-source inference models, model performance evaluation, QwQ-32B model
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To assess the reliability of benchmark evaluation results of Deepseek-R1-Distill models and advocate for a more rigorous evaluation paradigm.
🛠️ Research Methods:
– Conducting empirical assessments to reveal fluctuations in benchmark evaluation caused by various factors.
💬 Research Conclusions:
– Significant fluctuations in evaluation results question the reliability of claimed performance improvements, highlighting the need for a more rigorous evaluation standard.
👉 Paper link: https://huggingface.co/papers/2506.04734

25. FreeTimeGS: Free Gaussians at Anytime and Anywhere for Dynamic Scene Reconstruction
🔑 Keywords: 4D representation, Gaussian primitives, dynamic 3D scenes, motion function, temporal redundancy
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to enhance the modeling of dynamic 3D scenes with complex motions by introducing a novel 4D representation called FreeTimeGS.
🛠️ Research Methods:
– Utilizing FreeTimeGS, the approach allows for Gaussian primitives to appear at arbitrary times and locations, and assigns a motion function to each primitive to enable movement and reduce temporal redundancy.
💬 Research Conclusions:
– The proposed method, FreeTimeGS, significantly improves rendering quality over existing methods, effectively handling complex motions in dynamic 3D scene reconstruction.
👉 Paper link: https://huggingface.co/papers/2506.05348

26. Geometry-Editable and Appearance-Preserving Object Compositon
🔑 Keywords: Disentangled Geometry-editable, Appearance-preserving Diffusion, semantic embeddings, cross-attention retrieval
💡 Category: Generative Models
🌟 Research Objective:
– The research aims to integrate target objects into background scenes while preserving their geometric properties and fine-grained appearance details through the Disentangled Geometry-editable and Appearance-preserving Diffusion (DGAD) model.
🛠️ Research Methods:
– Utilization of semantic embeddings for capturing geometric transformations and a cross-attention mechanism for aligning appearance features with geometry-edited representations.
💬 Research Conclusions:
– Demonstrated the DGAD model’s effectiveness through extensive experiments on public benchmarks, showcasing its capability in precise geometry editing and maintaining faithful appearance in object compositions.
👉 Paper link: https://huggingface.co/papers/2505.20914

27. Contextual Integrity in LLMs via Reasoning and Reinforcement Learning
🔑 Keywords: Contextual Integrity, LLMs, Reinforcement Learning, Information Disclosure, Privacy Leakage
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Enhance contextual integrity in LLMs by reducing inappropriate information disclosure and maintaining task performance.
🛠️ Research Methods:
– Implement a reinforcement learning framework that encourages LLMs to reason about contextual integrity while using a synthetic dataset with various contexts.
💬 Research Conclusions:
– The framework effectively reduces inappropriate information disclosure while preserving performance across different model sizes and is validated on CI benchmarks like PrivacyLens.
👉 Paper link: https://huggingface.co/papers/2506.04245

28. MedAgentGym: Training LLM Agents for Code-Based Medical Reasoning at Scale
🔑 Keywords: MedAgentGYM, Large Language Models, Supervised Fine-Tuning, Reinforcement Learning, Biomedical Research
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study introduces MedAgentGYM, a publicly available training environment aimed at enhancing coding-based medical reasoning capabilities in large language model (LLM) agents.
🛠️ Research Methods:
– Employing a massive dataset of 72,413 task instances from real-world biomedical scenarios, the research uses supervised fine-tuning and reinforcement learning to train LLMs.
💬 Research Conclusions:
– MedAgentGYM highlights performance disparities between commercial API-based models and open-source counterparts and achieves notable performance improvements for Med-Copilot-7B, presenting itself as a competitive alternative to gpt-4o in developing LLM-based coding assistants.
👉 Paper link: https://huggingface.co/papers/2506.04405

29. Scaling Laws for Robust Comparison of Open Foundation Language-Vision Models and Datasets
🔑 Keywords: AI-generated summary, Scaling laws, CLIP, MaMMUT, Dataset comparison
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Derive scaling laws for CLIP and MaMMUT to compare their performance and sample efficiency across different scales and datasets.
🛠️ Research Methods:
– Utilizing dense measurements and deriving full scaling laws for language-vision learning models using contrastive and captioning text generative loss.
– Implementing a constant learning rate schedule to perform accurate scaling law derivations across model and dataset comparisons.
💬 Research Conclusions:
– MaMMUT demonstrates stronger improvement with scale and superior sample efficiency compared to CLIP.
– Scaling law comparisons reveal consistent trends across multiple downstream tasks and open datasets, leading to more systematic model and dataset evaluations.
– Pre-trained models, including openMaMMUT-L/14 achieving 80.3% zero-shot ImageNet-1k accuracy, are released with intermediate checkpoints and code for reproducing experiments.
👉 Paper link: https://huggingface.co/papers/2506.04598

30. SkyReels-Audio: Omni Audio-Conditioned Talking Portraits in Video Diffusion Transformers
🔑 Keywords: AI Native, multimodal inputs, video diffusion transformers, lip-sync accuracy
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to develop SkyReels-Audio, a framework for synthesizing high-fidelity, temporally coherent audio-conditioned talking portrait videos using multimodal inputs.
🛠️ Research Methods:
– The framework utilizes pretrained video diffusion transformers and employs a hybrid curriculum learning strategy to align audio with facial motions for fine-grained control. It also introduces facial mask loss and an audio-guided classifier-free guidance mechanism.
💬 Research Conclusions:
– SkyReels-Audio demonstrates superior performance in lip-sync accuracy, identity consistency, and realistic facial dynamics across diverse conditions through comprehensive benchmark evaluations.
👉 Paper link: https://huggingface.co/papers/2506.00830

31. RobustSplat: Decoupling Densification and Dynamics for Transient-Free 3DGS
🔑 Keywords: 3D Gaussian Splatting, novel-view synthesis, transient objects, Gaussian growth, mask prediction
💡 Category: Computer Vision
🌟 Research Objective:
– To address artifacts in 3D Gaussian Splatting caused by transient objects with robust solutions.
🛠️ Research Methods:
– Introduction of delayed Gaussian growth to prevent overfitting to transient objects initially.
– Development of scale-cascaded mask bootstrapping for accurate mask prediction.
💬 Research Conclusions:
– RobustSplat outperforms existing methods, demonstrating robustness and effectiveness against artifacts in complex datasets.
👉 Paper link: https://huggingface.co/papers/2506.02751
32. FEAT: Full-Dimensional Efficient Attention Transformer for Medical Video Generation
🔑 Keywords: Efficient Attention Transformer, Spatial-Temporal-Channel Attention, Linear-Complexity Design, Residual Value Guidance, AI in Healthcare
💡 Category: AI in Healthcare
🌟 Research Objective:
– The aim is to address challenges in synthesizing high-quality dynamic medical videos by improving upon current Transformer-based methods.
🛠️ Research Methods:
– Implementation of a unified attention paradigm using spatial-temporal-channel mechanisms.
– Development of a linear-complexity design for efficient attention operations.
💬 Research Conclusions:
– FEAT significantly reduces parameters compared to leading models while demonstrating comparable or superior performance.
– It shows superior effectiveness and scalability across multiple datasets.
👉 Paper link: https://huggingface.co/papers/2506.04956

33. Micro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
🔑 Keywords: Retrieval-Augmented Generation, Knowledge Conflicts, large language models, QA accuracy, benchmark datasets
💡 Category: Natural Language Processing
🌟 Research Objective:
– Develop a framework, Micro-Act, to address Knowledge Conflicts in Retrieval-Augmented Generation by adaptively decomposing knowledge sources to improve question answering accuracy.
🛠️ Research Methods:
– Implement a hierarchical action space that perceives context complexity and decomposes each knowledge source into fine-grained comparisons, allowing for enhanced reasoning.
💬 Research Conclusions:
– Micro-Act boosts QA accuracy across five benchmark datasets and outperforms state-of-the-art baselines, particularly in temporal and semantic conflict types. It also performs effectively on non-conflict questions, showcasing its practical applicability in real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2506.05278

34. Rectified Point Flow: Generic Point Cloud Pose Estimation
🔑 Keywords: Rectified Point Flow, pairwise point cloud registration, multi-part shape assembly, continuous point-wise velocity field, AI-generated summary
💡 Category: Generative Models
🌟 Research Objective:
– To unify the processes of pairwise point cloud registration and multi-part shape assembly through a unified parameterization, addressing these tasks as a singular conditional generative problem.
🛠️ Research Methods:
– Developing a continuous point-wise velocity field to transport unposed noisy points toward their target positions, intrinsically learning assembly symmetries without symmetry labels, and incorporating a self-supervised encoder focused on overlapping points.
💬 Research Conclusions:
– The introduced method, Rectified Point Flow, achieves state-of-the-art performance on multiple benchmarks, demonstrating the benefits of a unified formulation that allows joint training on diverse datasets to enhance accuracy through shared geometric priors.
👉 Paper link: https://huggingface.co/papers/2506.05282

35. Diffusion-Based Generative Models for 3D Occupancy Prediction in Autonomous Driving
🔑 Keywords: 3D occupancy prediction, autonomous driving, diffusion models, noise robustness, 3D scene priors
💡 Category: Generative Models
🌟 Research Objective:
– The study aims to enhance 3D occupancy prediction accuracy and robustness for autonomous driving by using diffusion models to address issues with noisy data and complex 3D scenes.
🛠️ Research Methods:
– The authors employ generative modeling through diffusion models, integrating 3D scene priors to improve prediction consistency and handle intricacies in 3D spatial structures.
💬 Research Conclusions:
– Extensive experiments demonstrate that diffusion-based generative models outperform current state-of-the-art discriminative methods, providing more realistic and accurate occupancy predictions, particularly in occluded or low-visibility areas, thus benefiting downstream planning tasks in real-world autonomous driving applications.
👉 Paper link: https://huggingface.co/papers/2505.23115

36. BEVCALIB: LiDAR-Camera Calibration via Geometry-Guided Bird’s-Eye View Representations
🔑 Keywords: BEVCALIB, Bird’s-eye view, LiDAR-camera calibration, Autonomous Driving, Robotic Systems
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– The primary objective is to leverage bird’s-eye view (BEV) features for accurate LiDAR-camera calibration directly from raw data in autonomous driving and robotic systems.
🛠️ Research Methods:
– The method involves extracting separate camera BEV features and LiDAR BEV features, and then fusing them into a shared BEV feature space. A novel feature selector is introduced to optimize the transformation decoding process.
💬 Research Conclusions:
– BEVCALIB demonstrates a new state of the art in LiDAR-camera calibration under various noise conditions, with significant performance improvements over existing baselines in KITTI and NuScenes datasets. It achieves an order of magnitude better results in the open-source domain.
👉 Paper link: https://huggingface.co/papers/2506.02587

37. Images are Worth Variable Length of Representations
🔑 Keywords: Dynamic Vision Encoder, Visual Tokens, Reconstruction Quality, Query-Conditioned Tokenization
💡 Category: Computer Vision
🌟 Research Objective:
– The study introduces DOVE, a dynamic vision encoder designed to produce a variable number of visual tokens for images, optimizing reconstruction quality and efficacy in multimodal tasks.
🛠️ Research Methods:
– Implementation involves generating continuous representation vectors varying with the information content of images, enhancing semantic feature extraction with query-conditioned tokenization.
💬 Research Conclusions:
– DOVE significantly reduces the average number of tokens necessary while maintaining high reconstruction quality, outperforming existing methods by capturing more expressive semantic features with fewer tokens.
👉 Paper link: https://huggingface.co/papers/2506.03643

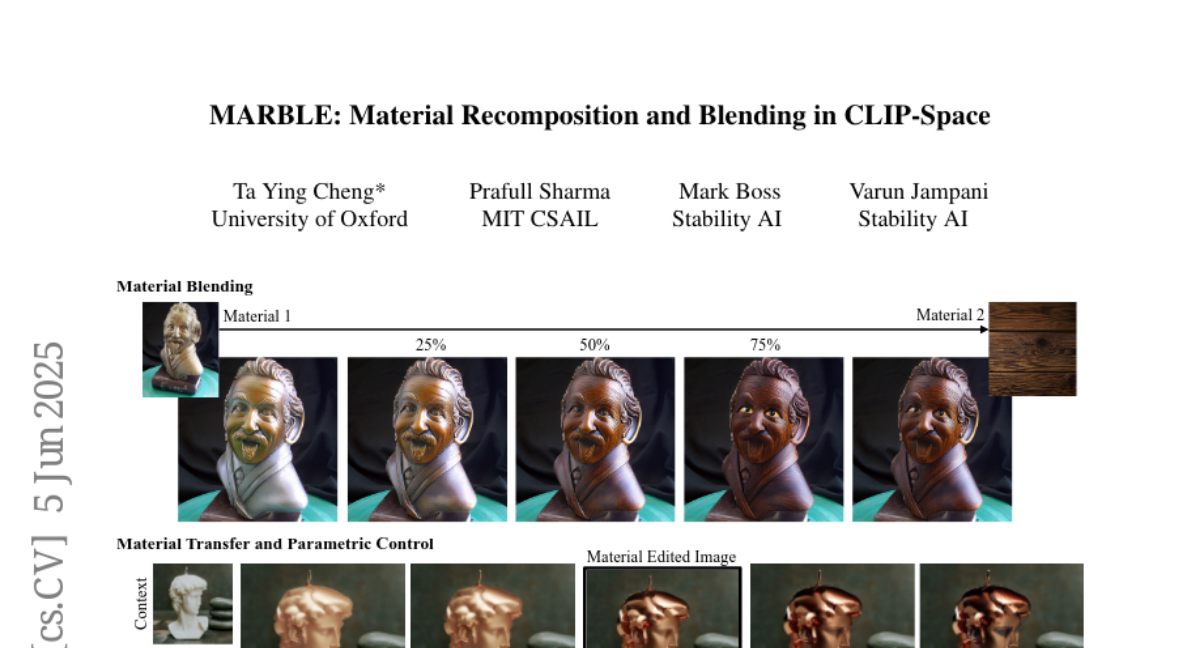
38. MARBLE: Material Recomposition and Blending in CLIP-Space
🔑 Keywords: MARBLE, material embeddings, CLIP-space, text-to-image models, denoising UNet
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to develop MARBLE, a method to control text-to-image models for blending and recomposing material properties with parametric control.
🛠️ Research Methods:
– The method involves utilizing material embeddings in CLIP-space and identifying a block in the denoising UNet for material attribution.
– Parametric control over fine-grained material attributes is achieved using a shallow network.
💬 Research Conclusions:
– The method demonstrates efficacy in material blending with qualitative and quantitative analysis and allows multiple edits in a single pass, applicable to painting.
👉 Paper link: https://huggingface.co/papers/2506.05313
39. Kinetics: Rethinking Test-Time Scaling Laws
🔑 Keywords: Kinetics Scaling Law, sparse attention, memory access costs, test-time scaling, AI-generated summary
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to rethink test-time scaling laws by revealing the overestimation of smaller model effectiveness due to memory bottlenecks and introducing a new Kinetics Scaling Law.
🛠️ Research Methods:
– Conducted a holistic analysis of models ranging from 0.6B to 32B parameters, emphasizing the role of sparse attention in improving test-time performance.
💬 Research Conclusions:
– Kinetics Scaling Law effectively guides resource allocation, emphasizing sparse attention over parameter count as a dominant factor in test-time efficiency. Sparse attention models show substantial performance gains, highlighting its importance in test-time scaling.
👉 Paper link: https://huggingface.co/papers/2506.05333

40. What do self-supervised speech models know about Dutch? Analyzing advantages of language-specific pre-training
🔑 Keywords: Self-supervised Wav2Vec2, Dutch linguistic features, Automatic Speech Recognition
💡 Category: Natural Language Processing
🌟 Research Objective:
– To assess the effectiveness of pre-training self-supervised Wav2Vec2 models on Dutch data for improving Dutch linguistic feature encoding compared to English or multilingual data.
🛠️ Research Methods:
– Utilization of clustering and classification probes to evaluate the encoding of Dutch phonetic and lexical information.
💬 Research Conclusions:
– Pre-training on Dutch data enhances the representation of language-specific linguistic features, leading to better Automatic Speech Recognition performance.
👉 Paper link: https://huggingface.co/papers/2506.00981

41. SViMo: Synchronized Diffusion for Video and Motion Generation in Hand-object Interaction Scenarios
🔑 Keywords: HOI video and motion generation, synchronized diffusion process, visual priors, dynamic constraints, 3D full-attention
💡 Category: Generative Models
🌟 Research Objective:
– To develop a novel framework that combines visual priors and dynamic constraints to generate HOI video and motion simultaneously, enhancing video-motion consistency and generalization.
🛠️ Research Methods:
– The framework implements tri-modal adaptive modulation for feature alignment and uses 3D full-attention to model dependencies. It introduces a vision-aware 3D interaction diffusion model to generate 3D interaction sequences, establishing a closed-loop feedback cycle.
💬 Research Conclusions:
– The proposed method significantly outperforms state-of-the-art approaches in generating high-fidelity, dynamically plausible HOI sequences, showcasing enhanced generalization capabilities in unseen real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2506.02444

42. Rethinking Whole-Body CT Image Interpretation: An Abnormality-Centric Approach
🔑 Keywords: Automated interpretation, CT images, AI-generated summary, Abnormal findings, OminiAbnorm-CT
💡 Category: AI in Healthcare
🌟 Research Objective:
– The study aims to address the challenge of automated interpretation of CT images by localizing and describing abnormal findings across multi-plane and whole-body scans.
🛠️ Research Methods:
– It involves developing a comprehensive hierarchical classification system for abnormal findings through collaboration with senior radiologists and creating a dataset of over 14.5K CT images with detailed annotations.
– The OminiAbnorm-CT model allows automatic grounding and description of abnormalities using text queries and visual prompts.
💬 Research Conclusions:
– The OminiAbnorm-CT model significantly outperforms existing methods in localizing and describing abnormalities in CT images, demonstrated through three representative evaluation tasks based on real clinical scenarios.
👉 Paper link: https://huggingface.co/papers/2506.03238

43. Perceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning
🔑 Keywords: Multi-modal language models, Reinforcement learning, Captions, Visual grounding
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Enhance visual representations in multi-modal large language models by optimizing captions for reasoning tasks.
🛠️ Research Methods:
– Utilizes a reinforcement learning strategy named RACRO to align captioning behavior with reasoning objectives.
💬 Research Conclusions:
– RACRO significantly improves visual grounding and reasoning-optimized representations, achieving state-of-the-art performance on math and science benchmarks. It supports scalability and adaptation to advanced reasoning models without costly realignments.
👉 Paper link: https://huggingface.co/papers/2506.04559

44. PATS: Proficiency-Aware Temporal Sampling for Multi-View Sports Skill Assessment
🔑 Keywords: AI-generated summary, Proficiency-Aware Temporal Sampling, EgoExo4D benchmark, SkillFormer, Temporal Continuity
💡 Category: Computer Vision
🌟 Research Objective:
– The main goal is to enhance video analysis of athletic skills by capturing complete movement patterns for proficient evaluation, distinguishing expert performance from novice.
🛠️ Research Methods:
– Introduction of Proficiency-Aware Temporal Sampling (PATS), a strategy that adaptively segments videos to maintain temporal coherence, ensuring full execution of critical components in multi-view skill assessment.
💬 Research Conclusions:
– PATS surpasses state-of-the-art accuracy on the EgoExo4D benchmark, showing remarkable performance gains across various domains, proving effective for dynamic sports and sequential skills.
👉 Paper link: https://huggingface.co/papers/2506.04996

45. FlowDirector: Training-Free Flow Steering for Precise Text-to-Video Editing
🔑 Keywords: FlowDirector, ODEs, attention-guided masking, semantic alignment, video editing
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce FlowDirector, a novel inversion-free framework for video editing that preserves temporal coherence and structural details.
🛠️ Research Methods:
– Utilize Ordinary Differential Equations (ODEs) for smooth transition and spatiotemporal coherence.
– Implement an attention-guided masking mechanism for localized control in video editing.
💬 Research Conclusions:
– FlowDirector demonstrates state-of-the-art performance in adhering to instructions, maintaining temporal consistency, and preserving backgrounds, setting a new standard for video editing efficiency and coherence.
👉 Paper link: https://huggingface.co/papers/2506.05046

46. Watermarking Degrades Alignment in Language Models: Analysis and Mitigation
🔑 Keywords: Watermarking, Large Language Models, Alignment Resampling, Gumbel, KGW
💡 Category: Natural Language Processing
🌟 Research Objective:
– To systematically analyze the impact of watermarking techniques like Gumbel and KGW on the truthfulness, safety, and helpfulness of large language models (LLMs).
🛠️ Research Methods:
– Conducting experiments to identify degradation patterns when applying watermarking and proposing Alignment Resampling (AR) as a method to restore alignment using an external reward model.
💬 Research Conclusions:
– Watermarking can cause guard attenuation and guard amplification, affecting LLM alignment. Alignment Resampling effectively restores baseline alignment while maintaining watermark detectability, indicating a balance between watermark strength and model alignment.
👉 Paper link: https://huggingface.co/papers/2506.04462

47.
