AI Native Daily Paper Digest – 20250617
1. MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
🔑 Keywords: MiniMax-M1, Mixture-of-Experts, Reinforcement Learning, AI Native, CISPO
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce MiniMax-M1, a hybrid-attention reasoning model for efficient long-input processing and reinforcement learning.
🛠️ Research Methods:
– Utilizes a Mixture-of-Experts architecture combined with a lightning attention mechanism and large-scale reinforcement learning (RL) for diverse tasks.
💬 Research Conclusions:
– MiniMax-M1 shows superior efficiency in complex tasks with long context processing, compared to models like DeepSeek-R1 and Qwen3-235B, and is publicly available on GitHub.
👉 Paper link: https://huggingface.co/papers/2506.13585

2. Scientists’ First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
🔑 Keywords: Multimodal Large Language Models, scientific cognitive capacities, perception, understanding, comparative reasoning, AI-enhanced scientific discoveries
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The primary objective is to assess the scientific cognitive capacities of Multimodal Large Language Models (MLLMs) through perception, understanding, and comparative reasoning using the Scientists’ First Exam (SFE) benchmark.
🛠️ Research Methods:
– The SFE benchmark consists of 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines to evaluate MLLMs’ capabilities.
💬 Research Conclusions:
– Experiments with state-of-the-art models like GPT-o3 and InternVL-3 show scores of 34.08% and 26.52% on SFE, respectively, indicating considerable potential for improvement in MLLMs for scientific applications.
👉 Paper link: https://huggingface.co/papers/2506.10521

3. DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
🔑 Keywords: DeepResearch Bench, Deep Research Agents, LLM-based agents, benchmark, AI-generated summary
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To provide a comprehensive benchmark framework for systematically evaluating the capabilities of Deep Research Agents in terms of research quality and information retrieval accuracy across multiple fields.
🛠️ Research Methods:
– Introduced a benchmark called DeepResearch Bench with 100 PhD-level research tasks crafted by domain experts across 22 fields.
– Developed two novel methodologies: a reference-based method with adaptive criteria for assessing research report quality and a framework to evaluate information retrieval through effective citation count and accuracy.
💬 Research Conclusions:
– DeepResearch Bench and its key components have been open-sourced to accelerate the development of practical LLM-based agents.
👉 Paper link: https://huggingface.co/papers/2506.11763

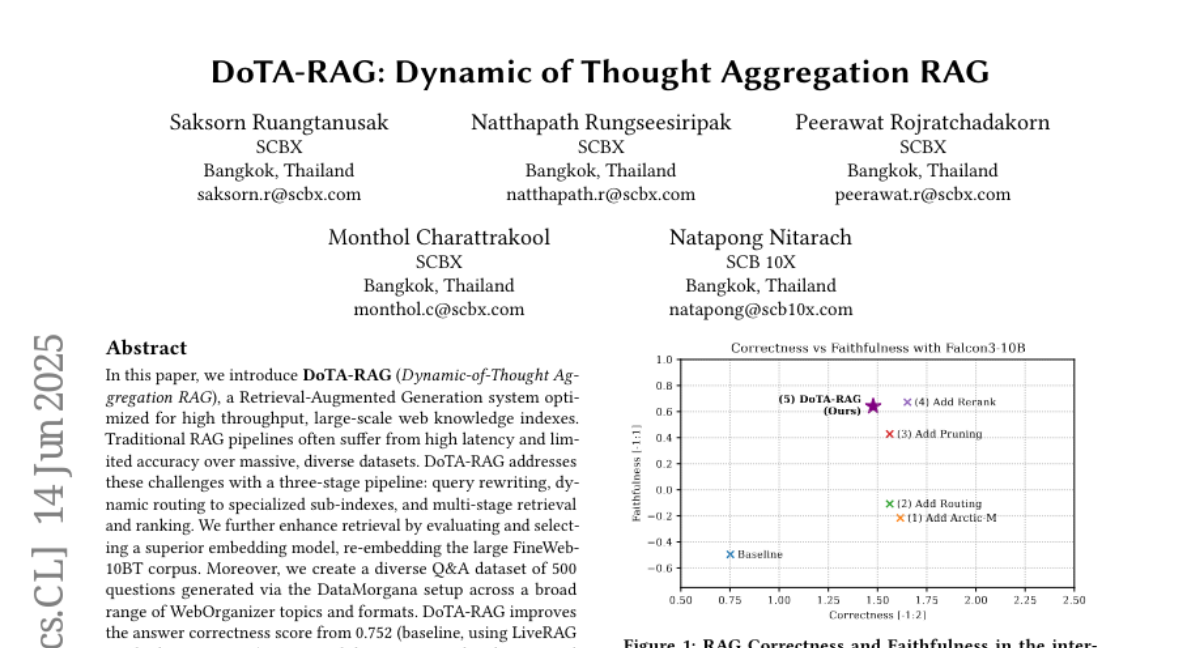
4. DoTA-RAG: Dynamic of Thought Aggregation RAG
🔑 Keywords: AI-generated summary, DoTA-RAG, retrieval-augmented generation, dynamic routing, embedding models
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve retrieval and generation accuracy over massive web datasets through a system called DoTA-RAG.
🛠️ Research Methods:
– Utilizes a three-stage pipeline including query rewriting, dynamic routing to specialized sub-indexes, and multi-stage retrieval and ranking.
– Enhances retrieval by selecting a superior embedding model and re-embedding the FineWeb-10BT corpus.
💬 Research Conclusions:
– DoTA-RAG achieved a correctness score improvement from 0.752 to 1.478 while maintaining low latency, demonstrating its potential for practical deployment in fast, reliable access to large and evolving knowledge sources.
👉 Paper link: https://huggingface.co/papers/2506.12571
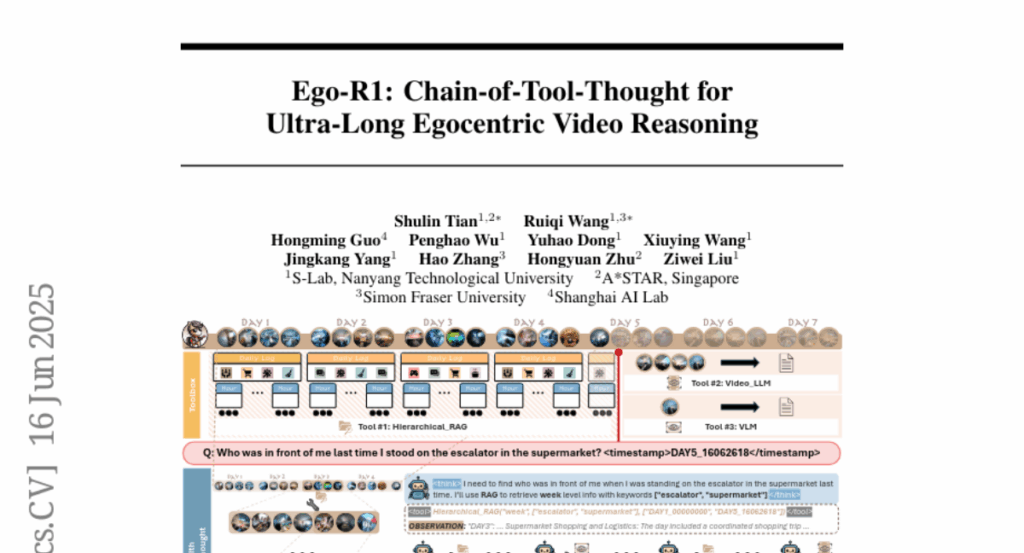
5. Ego-R1: Chain-of-Tool-Thought for Ultra-Long Egocentric Video Reasoning
🔑 Keywords: Ego-R1, reinforcement learning, Chain-of-Tool-Thought, ultra-long egocentric videos, video QA
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The introduction of the Ego-R1 framework for reasoning over ultra-long egocentric videos extending time coverage to a week.
🛠️ Research Methods:
– Employing a structured Chain-of-Tool-Thought process within a reinforcement learning-based agent.
– A two-stage training paradigm using supervised finetuning and reinforcement learning on a specially constructed dataset.
💬 Research Conclusions:
– The dynamic, tool-augmented chain-of-thought reasoning enables effective understanding of ultra-long egocentric videos, outperforming existing methods by significantly extending temporal coverage.
👉 Paper link: https://huggingface.co/papers/2506.13654

6. Wait, We Don’t Need to “Wait”! Removing Thinking Tokens Improves Reasoning Efficiency
🔑 Keywords: NoWait, self-reflection, reasoning models, multimodal reasoning, tokens
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Investigate whether explicit self-reflection tokens are necessary for advanced reasoning in large models.
🛠️ Research Methods:
– Develop NoWait, which suppresses explicit self-reflection tokens during inference, and test it on ten benchmarks spanning textual, visual, and video reasoning tasks.
💬 Research Conclusions:
– NoWait reduces the chain-of-thought trajectory length by 27%-51% without compromising model utility, providing an efficient plug-and-play solution for multimodal reasoning.
👉 Paper link: https://huggingface.co/papers/2506.08343

7. Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression
🔑 Keywords: Autoregressive Transformer, diffusion models, Multi-Reference Autoregression, Fréchet Inception Distance, ImageNet
💡 Category: Generative Models
🌟 Research Objective:
– Introduction of TransDiff, a pioneering image generation model integrating Autoregressive Transformer and diffusion models to improve performance and speed.
🛠️ Research Methods:
– Encoding labels and images into high-level semantic features and using a diffusion model for estimating image distribution, with performance measured on ImageNet benchmark.
💬 Research Conclusions:
– TransDiff outperforms existing models with significant improvements in Fréchet Inception Distance and Inception Score while offering much faster inference latency. The introduction of Multi-Reference Autoregression further enhances the model’s quality and diversity.
👉 Paper link: https://huggingface.co/papers/2506.09482

8. TaskCraft: Automated Generation of Agentic Tasks
🔑 Keywords: Agentic tasks, multi-tool, prompt optimization, fine-tuning, scalable
💡 Category: Natural Language Processing
🌟 Research Objective:
– To automate the generation of scalable, multi-tool, and complex agentic tasks to improve prompt optimization and fine-tuning of agentic models.
🛠️ Research Methods:
– Introduction of TaskCraft, an automated workflow that generates difficulty-scalable and verifiable agentic tasks with execution trajectories using depth-based and width-based extensions.
💬 Research Conclusions:
– TaskCraft’s generated tasks enhance prompt optimization and improve supervised fine-tuning of agentic foundation models, supported by a large-scale synthetic dataset of approximately 36,000 tasks.
👉 Paper link: https://huggingface.co/papers/2506.10055

9. Discrete Diffusion in Large Language and Multimodal Models: A Survey
🔑 Keywords: Discrete Diffusion Language Models (dLLMs), Discrete Diffusion Multimodal Language Models (dMLLMs), Parallel Generation, Inference Speed
💡 Category: Generative Models
🌟 Research Objective:
– The paper aims to systematically survey the development and capabilities of Discrete Diffusion Language Models (dLLMs) and Discrete Diffusion Multimodal Language Models (dMLLMs).
🛠️ Research Methods:
– The study provides a historical overview, formalizes mathematical frameworks, categorizes representative models, and analyzes key techniques for training and inference.
💬 Research Conclusions:
– Discrete diffusion models achieve parallel generation, fine-grained output control, and dynamic perception, outperforming autoregressive models with up to 10x faster inference speed. The paper also discusses the ongoing research propelled by advancements in autoregressive models and discrete diffusion mathematics.
👉 Paper link: https://huggingface.co/papers/2506.13759

10. AR-RAG: Autoregressive Retrieval Augmentation for Image Generation
🔑 Keywords: Autoregressive Retrieval Augmentation, Image Generation, Patch-level Retrieval, Context-aware Retrieval
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces the Autoregressive Retrieval Augmentation (AR-RAG) framework to enhance image generation by dynamically incorporating patch-level retrievals.
🛠️ Research Methods:
– AR-RAG employs two frameworks: Distribution-Augmentation in Decoding (DAiD) and Feature-Augmentation in Decoding (FAiD), leveraging retrievals to refine image generation.
💬 Research Conclusions:
– The proposed method demonstrates significant performance improvements over state-of-the-art models on benchmarks such as Midjourney-30K and GenEval.
👉 Paper link: https://huggingface.co/papers/2506.06962

11. Test3R: Learning to Reconstruct 3D at Test Time
🔑 Keywords: Test-time learning, 3D reconstruction, Geometric accuracy, Self-supervised learning
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Test3R to enhance geometric accuracy in 3D reconstruction using test-time learning.
🛠️ Research Methods:
– Utilizes self-supervised learning to optimize network consistency with image triplets.
💬 Research Conclusions:
– Test3R significantly outperforms previous state-of-the-art methods in 3D reconstruction and multi-view depth estimation, offering a universally applicable and cost-effective solution with minimal overhead.
👉 Paper link: https://huggingface.co/papers/2506.13750
12. VGR: Visual Grounded Reasoning
🔑 Keywords: Visual Reasoning, Multimodal, MLLM, AI-generated, SFT dataset
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To develop VGR, a multimodal large language model that enhances visual reasoning by detecting relevant image regions and integrating them into the reasoning process.
🛠️ Research Methods:
– Utilization of the VGR-SFT dataset containing mixed vision grounding and language deduction data.
– Implementation of a replay stage that integrates detected image regions into the reasoning pipeline.
💬 Research Conclusions:
– VGR achieves superior performance on multimodal benchmarks with a significant reduction in resource usage compared to existing models.
– Demonstrated improvements on various benchmarks such as MMStar, AI2D, and ChartQA with fewer image tokens.
👉 Paper link: https://huggingface.co/papers/2506.11991

13. PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization
🔑 Keywords: PersonaFeedback, LLM personalization, user personas, personalized responses
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduce PersonaFeedback as a benchmark to evaluate LLMs’ ability to generate personalized responses based on explicit user personas.
🛠️ Research Methods:
– Creation and categorization of 8298 human-annotated test cases into easy, medium, and hard tiers based on persona complexity and personalization challenges.
💬 Research Conclusions:
– State-of-the-art LLMs may struggle on complex personalization tasks, revealing limitations in current systems, highlighting that retrieval-augmented frameworks are not definitive solutions.
👉 Paper link: https://huggingface.co/papers/2506.12915

14. From Real to Synthetic: Synthesizing Millions of Diversified and Complicated User Instructions with Attributed Grounding
🔑 Keywords: Large Language Models, Attributed Grounding, SynthQuestions, Web Documents
💡 Category: Natural Language Processing
🌟 Research Objective:
– The paper aims to develop a method for generating diverse and complex instruction data for large language models by using attributed grounding.
🛠️ Research Methods:
– The study utilizes a top-down attribution process and a bottom-up synthesis process, leveraging web documents to create a large dataset of 1 million instructions called SynthQuestions.
💬 Research Conclusions:
– Models trained on the SynthQuestions dataset achieved leading performance on several benchmarks, showing continuous improvement with more extensive web corpora.
👉 Paper link: https://huggingface.co/papers/2506.03968

15. AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy
🔑 Keywords: supervised fine-tuning, reinforcement learning, reasoning models, sampling temperature
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Investigate the synergy between supervised fine-tuning (SFT) and reinforcement learning (RL) to enhance reasoning models, evidenced by improved performance in the AceReason-Nemotron-1.1 model.
🛠️ Research Methods:
– Employed scaling strategies in SFT training data, increasing prompt numbers and generated responses, to observe impact on reasoning performance.
– Explored determining optimal sampling temperature during RL training to balance exploration and exploitation effectively.
💬 Research Conclusions:
– Stronger SFT models lead to better final performance with effective RL training, particularly when the sampling temperature is set to maintain entropy around 0.3.
– The AceReason-Nemotron-1.1 significantly outperforms its predecessor and sets a new benchmark on challenging math and code tasks, demonstrating the efficacy of the proposed post-training approach.
👉 Paper link: https://huggingface.co/papers/2506.13284

16. Essential-Web v1.0: 24T tokens of organized web data
🔑 Keywords: Essential-Web, AI-generated summary, taxonomy, pre-training datasets
💡 Category: Natural Language Processing
🌟 Research Objective:
– To present Essential-Web v1.0, a 24-trillion-token dataset annotated with a multi-category taxonomy to improve dataset organization for language models.
🛠️ Research Methods:
– Utilization of EAI-Distill-0.5b for creating taxonomy labels and simple SQL-style filtering methods to curate datasets.
💬 Research Conclusions:
– Essential-Web v1.0 shows competitive performance in various domains such as math, web code, STEM, and medical fields, available on HuggingFace.
👉 Paper link: https://huggingface.co/papers/2506.14111

17. BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
🔑 Keywords: 3D Vision-Language-Action, AI-generated summary, 2D images, VLM backbone, 2D heatmaps
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Introduce BridgeVLA, a novel model to enhance action prediction by projecting 3D inputs to 2D images and utilizing 2D heatmaps.
🛠️ Research Methods:
– Implement a scalable pre-training method to equip VLM backbone with 2D heatmap prediction abilities.
💬 Research Conclusions:
– BridgeVLA demonstrated superior performance over state-of-the-art methods across several benchmarks, showing remarkable success rates and sample efficiency, especially in generalization and real-robot scenarios.
👉 Paper link: https://huggingface.co/papers/2506.07961
18. Language Surgery in Multilingual Large Language Models
🔑 Keywords: Large Language Models, Inference-Time Language Control, language-agnostic information
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate naturally emerging representation alignment in large language models and its implications for language-specific manipulation.
🛠️ Research Methods:
– Empirical analysis of representation alignment, comparison with explicitly designed alignment models, and introduction of Inference-Time Language Control using latent injection.
💬 Research Conclusions:
– Confirmed the existence of natural representation alignment in LLMs, proposed ITLC for enhanced cross-lingual performance without semantic degradation, and demonstrated its effectiveness in mitigating language confusion.
👉 Paper link: https://huggingface.co/papers/2506.12450

19. AI Agent Behavioral Science
🔑 Keywords: AI Agent Behavioral Science, AI agents, responsible AI, human-agent interaction, social dynamics
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– The objective is to establish a new field, AI Agent Behavioral Science, to study AI agents’ behaviors, focusing on external factors and responsible AI aspects.
🛠️ Research Methods:
– The approach emphasizes systematic behavior observation, intervention design for hypothesis testing, and theory-guided interpretation of agents’ actions and interactions over time.
💬 Research Conclusions:
– This perspective positions AI Agent Behavioral Science as a complement to traditional model-centric approaches, enhancing understanding, evaluation, and governance of autonomous AI systems’ real-world behavior.
👉 Paper link: https://huggingface.co/papers/2506.06366

20. ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering
🔑 Keywords: ALE-Bench, AI Systems, Optimization Problems, Long-Horizon Problem-Solving, Interactive Agent Architectures
💡 Category: AI Systems and Tools
🌟 Research Objective:
– Introduce ALE-Bench, a benchmark for evaluating AI systems in algorithmic contests focused on complex optimization problems.
🛠️ Research Methods:
– Utilize tasks from AtCoder Heuristic Contests to present hard optimization problems and support iterative solution refinement over long durations.
💬 Research Conclusions:
– Current LLMs exhibit strong performance on certain problems; however, they lack consistency and long-horizon solving abilities compared to humans, indicating a need for this benchmark to drive AI progress.
👉 Paper link: https://huggingface.co/papers/2506.09050

21. A Technical Study into Small Reasoning Language Models
🔑 Keywords: Small Reasoning Language Models, Supervised Fine-Tuning, Knowledge Distillation, Reinforcement Learning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Enhance performance of Small Reasoning Language Models with limited capacity using various training strategies.
🛠️ Research Methods:
– Exploration of supervised fine-tuning, knowledge distillation, and reinforcement learning, along with hybrid implementations, to improve 0.5 billion parameter models.
💬 Research Conclusions:
– Provides insights and actionable recommendations for maximizing the reasoning capabilities and efficiency of 0.5 billion parameter models through comprehensive experimental validation.
👉 Paper link: https://huggingface.co/papers/2506.13404

22. Provably Learning from Language Feedback
🔑 Keywords: Learning from Language Feedback, Large Language Models, No-Regret Algorithm, Transfer Eluder Dimension, HELiX
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To provide a formal framework and develop a no-regret algorithm for learning from language feedback with large language models.
🛠️ Research Methods:
– Introduction of the Learning from Language Feedback (LLF) problem and the transfer eluder dimension as a complexity measure.
– Development of the no-regret algorithm, HELiX, to solve LLF problems through sequential interactions.
💬 Research Conclusions:
– Demonstrated that learning from language feedback can be exponentially faster than learning from reward systems.
– Showed effective performance of HELiX across multiple domains even when large language models do not reliably respond to repeated prompts.
👉 Paper link: https://huggingface.co/papers/2506.10341

23. LETS Forecast: Learning Embedology for Time Series Forecasting
🔑 Keywords: DeepEDM, Time Series Forecasting, Empirical Dynamic Modeling, Latent Space, Nonlinear Dynamics
💡 Category: Machine Learning
🌟 Research Objective:
– To introduce DeepEDM, a framework integrating empirical dynamic modeling with deep neural networks for improving time series forecasting.
🛠️ Research Methods:
– DeepEDM leverages nonlinear dynamical systems modeling with techniques such as time-delayed embeddings and kernel regression, incorporating softmax attention for efficient dynamic approximation.
💬 Research Conclusions:
– DeepEDM shows robustness to input noise and achieves superior forecasting accuracy compared to state-of-the-art methods, validated through comprehensive experiments on synthetic and real-world time series.
👉 Paper link: https://huggingface.co/papers/2506.06454

24. Supernova Event Dataset: Interpreting Large Language Model’s Personality through Critical Event Analysis
🔑 Keywords: LLMs, Supernova Event Dataset, model interpretability, reasoning, personality traits
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate various LLMs on diverse text tasks and interpret model personality traits using the novel Supernova Event Dataset.
🛠️ Research Methods:
– Employed the Supernova Event Dataset consisting of diverse articles to benchmark both small and large LLMs, using another LLM as a judge to infer model personality.
💬 Research Conclusions:
– The study revealed distinct personality traits in different LLMs, enhancing interpretability and usability across a wide range of applications.
👉 Paper link: https://huggingface.co/papers/2506.12189

25. Incorporating Domain Knowledge into Materials Tokenization
🔑 Keywords: MATTER, tokenization, material knowledge, semantic integrity, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– To propose MATTER, a novel tokenization approach that incorporates material knowledge to improve scientific text processing by maintaining the structural and semantic integrity of material concepts.
🛠️ Research Methods:
– Utilized a materials knowledge base and MatDetector for training, alongside a re-ranking method that prioritizes material concepts during token merging to prevent fragmentation.
💬 Research Conclusions:
– MATTER outperforms existing tokenization methods, achieving a performance gain of 4% in generation tasks and 2% in classification tasks, emphasizing the importance of domain knowledge in tokenization strategies.
👉 Paper link: https://huggingface.co/papers/2506.11115
26. SRLAgent: Enhancing Self-Regulated Learning Skills through Gamification and LLM Assistance
🔑 Keywords: SRLAgent, self-regulated learning, gamification, LLM-assisted system, AI feedback
💡 Category: AI in Education
🌟 Research Objective:
– To enhance self-regulated learning skills among college students through a gamified LLM-assisted system.
🛠️ Research Methods:
– A formative study involving 59 college students and a comparative analysis using a between-subjects design.
💬 Research Conclusions:
– SRLAgent significantly improves SRL skills and student engagement compared to traditional learning methods.
👉 Paper link: https://huggingface.co/papers/2506.09968

27. Profiling News Media for Factuality and Bias Using LLMs and the Fact-Checking Methodology of Human Experts
🔑 Keywords: Large Language Models, Political Bias, Fact-checking, Media Outlet Factuality
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to improve predictions of media outlet factuality and political bias using large language models with curated prompts.
🛠️ Research Methods:
– The researchers designed a methodology that uses prompts based on professional fact-checker criteria, aggregating responses from multiple large language models.
💬 Research Conclusions:
– The methodology shows significant improvements over strong baselines and includes an error analysis of media popularity and region effects. The dataset and code have been released for further research.
👉 Paper link: https://huggingface.co/papers/2506.12552

28. MS4UI: A Dataset for Multi-modal Summarization of User Interface Instructional Videos
🔑 Keywords: multi-modal summarization, UI instructional videos, video summarization, MS4UI dataset
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To propose a novel benchmark for multi-modal summarization specifically designed for UI instructional videos, aiming to provide step-by-step executable instructions and key video frames.
🛠️ Research Methods:
– Collection and annotation of a dataset consisting of 2,413 UI instructional videos, totaling over 167 hours, with a focus on video segmentation, text summarization, and video summarization to enable comprehensive evaluations.
💬 Research Conclusions:
– Findings suggest that current state-of-the-art multi-modal summarization methods struggle with UI video summarization, emphasizing the need for developing new methods tailored for summarizing UI instructional videos.
👉 Paper link: https://huggingface.co/papers/2506.12623

29. Forecasting Time Series with LLMs via Patch-Based Prompting and Decomposition
🔑 Keywords: PatchInstruct, Large Language Models, prompt-based strategies, time series decomposition, patch-based tokenization
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance the forecasting quality of Large Language Models (LLMs) for time series analysis without extensive retraining or complex external architecture.
🛠️ Research Methods:
– Utilization of specialized prompting methods including time series decomposition, patch-based tokenization, and similarity-based neighbor augmentation.
💬 Research Conclusions:
– The proposed method, PatchInstruct, can improve the prediction accuracy of LLMs while maintaining methodological simplicity and minimal data preprocessing.
👉 Paper link: https://huggingface.co/papers/2506.12953

30. Steering LLM Thinking with Budget Guidance
🔑 Keywords: Budget guidance, LLM, thinking budget, Gamma distribution, token efficiency
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a method, budget guidance, that optimizes the reasoning process of Large Language Models (LLMs) within a specified budget without the need for fine-tuning.
🛠️ Research Methods:
– A lightweight predictor is introduced to model a Gamma distribution over remaining thinking length, guiding next-token generation in a soft manner to adhere to the thinking budget.
💬 Research Conclusions:
– Budget guidance significantly enhances token efficiency and maintains competitive accuracy, achieving up to a 26% accuracy increase on math benchmarks like MATH-500 under tight budgets.
– The method is generalizable to broader task domains and demonstrates emergent capabilities, such as estimating question difficulty.
👉 Paper link: https://huggingface.co/papers/2506.13752

31. DiffusionBlocks: Blockwise Training for Generative Models via Score-Based Diffusion
🔑 Keywords: DiffusionBlocks, denoising operations, continuous-time diffusion process, generative tasks, memory efficiency
💡 Category: Generative Models
🌟 Research Objective:
– To propose DiffusionBlocks as a novel training framework for optimizing neural network blocks in generative tasks.
🛠️ Research Methods:
– Partitioning networks into independently trainable blocks and optimizing noise level assignments based on equal cumulative probability mass.
💬 Research Conclusions:
– The framework achieves significant memory efficiency and maintains competitive performance compared to traditional backpropagation in generative tasks, with experiments showing superior performance in image generation and language modeling.
👉 Paper link: https://huggingface.co/papers/2506.14202

32. EgoPrivacy: What Your First-Person Camera Says About You?
🔑 Keywords: EgoPrivacy, Egocentric Vision, Privacy Risks, Foundation Models, Zero-shot Settings
💡 Category: Computer Vision
🌟 Research Objective:
– Investigate how much private information can be inferred from first-person view videos, assessing privacy threats specific to camera wearers.
🛠️ Research Methods:
– Introduced the EgoPrivacy benchmark for a comprehensive evaluation of privacy risks, defining tasks for demographic, individual, and situational privacy.
– Proposed the Retrieval-Augmented Attack strategy using ego-to-exo retrieval from exocentric videos to enhance demographic privacy attacks.
💬 Research Conclusions:
– Foundation models can infer private information about camera wearers with high accuracy in zero-shot settings, recovering attributes like identity, gender, and race with 70-80% accuracy.
👉 Paper link: https://huggingface.co/papers/2506.12258

33. QGuard:Question-based Zero-shot Guard for Multi-modal LLM Safety
🔑 Keywords: QGuard, Large Language Models, harmful prompts, multi-modal, question prompting
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop QGuard, a method to defend Large Language Models (LLMs) from harmful and multi-modal malicious prompts without requiring fine-tuning.
🛠️ Research Methods:
– Utilized question prompting in a zero-shot fashion to block harmful prompts across text-based and multi-modal formats.
💬 Research Conclusions:
– QGuard effectively blocks harmful prompts and remains robust against the latest attacks by diversifying guard questions, providing insights for mitigating security risks in LLM services.
👉 Paper link: https://huggingface.co/papers/2506.12299

34. SeqPE: Transformer with Sequential Position Encoding
🔑 Keywords: SeqPE, Position Encoding, Transformers, Context Length Extrapolation, Multi-dimensional Generalization
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research aims to introduce SeqPE, a fully learnable position encoding framework that enhances positional encoding adaptability and scalability in Transformers.
🛠️ Research Methods:
– The study employs a sequential position encoder to learn n-dimensional position embeddings, utilizing a contrastive objective and knowledge distillation loss to improve extrapolation capabilities.
💬 Research Conclusions:
– SeqPE demonstrates superior performance over existing baselines in various tasks such as language modeling and 2D image classification, particularly under context length extrapolation, by enabling seamless multi-dimensional generalization.
👉 Paper link: https://huggingface.co/papers/2506.13277

35. BOW: Bottlenecked Next Word Exploration
🔑 Keywords: BOW, Reinforcement Learning, next-word prediction, reasoning bottleneck, policy model
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance the reasoning capabilities of language models by introducing a reasoning bottleneck in next-word prediction.
🛠️ Research Methods:
– Utilization of a novel RL framework named BOW, leveraging a reasoning path generated by a policy model and evaluated by a frozen judge model for next-word prediction.
💬 Research Conclusions:
– BOW demonstrates improved general and next-word reasoning capabilities compared to traditional continual pretraining methods, serving as a scalable alternative.
👉 Paper link: https://huggingface.co/papers/2506.13502

36. Hatevolution: What Static Benchmarks Don’t Tell Us
🔑 Keywords: AI-generated summary, language evolution, hate speech benchmarks, temporal misalignment, language models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective is to highlight the importance of time-sensitive linguistic assessments to evaluate the robustness of language models on evolving hate speech benchmarks.
🛠️ Research Methods:
– Conduct an empirical evaluation of 20 language models across two evolving hate speech experiments to examine temporal misalignment in their robustness.
💬 Research Conclusions:
– It identifies a temporal misalignment between static and time-sensitive evaluations, emphasizing the need for dynamic benchmarks to ensure model safety in the hate speech domain.
👉 Paper link: https://huggingface.co/papers/2506.12148

37. Personalizable Long-Context Symbolic Music Infilling with MIDI-RWKV
🔑 Keywords: MIDI-RWKV, RWKV-7, symbolic music infilling, musical cocreation, computer-assisted composition
💡 Category: Generative Models
🌟 Research Objective:
– To enhance computer-assisted composition by addressing personalized and controllable symbolic music infilling using MIDI-RWKV.
🛠️ Research Methods:
– Development of MIDI-RWKV based on RWKV-7 linear architecture to enable efficient music infilling on edge devices and finetuning its initial state for personalization.
💬 Research Conclusions:
– MIDI-RWKV facilitates effective musical cocreation on edge devices, with model weights and code made available for public use.
👉 Paper link: https://huggingface.co/papers/2506.13001

38. Ai-Facilitated Analysis of Abstracts and Conclusions: Flagging Unsubstantiated Claims and Ambiguous Pronouns
🔑 Keywords: Hierarchical Reasoning, Large Language Models, Informational Integrity, Textual Analysis
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate structured workflow prompts designed for hierarchical reasoning in LLMs when analyzing scholarly manuscripts.
🛠️ Research Methods:
– Conducted a systematic, multi-run evaluation with two models, Gemini Pro 2.5 Pro and ChatGPT Plus o3, on tasks targeting informational integrity and linguistic clarity.
💬 Research Conclusions:
– Found significant differences in model performance based on task type and context, suggesting that structured prompting is viable for complex textual analysis but requires model-specific testing.
👉 Paper link: https://huggingface.co/papers/2506.13172

39. Uncertainty-Aware Remaining Lifespan Prediction from Images
🔑 Keywords: Vision Transformer, AI-generated summary, Gaussian Distribution, Mean Absolute Error, Calibration
💡 Category: AI in Healthcare
🌟 Research Objective:
– Develop a method using vision transformer models to predict remaining lifespan from facial and whole-body images with accurate uncertainty estimates.
🛠️ Research Methods:
– Utilize pretrained vision transformer foundation models and model uncertainty using Gaussian distribution for each sample.
💬 Research Conclusions:
– Achieved state-of-the-art mean absolute error on both established and new datasets, showcasing potential for image-based medical signaling while providing calibrated uncertainty estimates.
👉 Paper link: https://huggingface.co/papers/2506.13430

40.
