AI Native Daily Paper Digest – 20250619

1. Sekai: A Video Dataset towards World Exploration
🔑 Keywords: Sekai, worldwide video dataset, rich annotations, interactive video, world exploration
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce Sekai, a comprehensive worldwide video dataset, to support and enhance video generation models for world exploration applications.
🛠️ Research Methods:
– Developed a toolbox to efficiently collect, pre-process, and annotate videos with essential details such as location, scene, weather, and camera trajectories.
💬 Research Conclusions:
– Sekai demonstrated high quality through experiments and is utilized to train an interactive video world exploration model named YUME, showcasing its potential to benefit video generation and exploration.
👉 Paper link: https://huggingface.co/papers/2506.15675
2. ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
🔑 Keywords: ProtoReasoning, Large Reasoning Models, cross-domain generalization, abstract reasoning prototypes, prototypical representations
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– To improve cross-domain generalization in logical reasoning and planning tasks by proposing ProtoReasoning, which uses prototypical representations to enhance large reasoning models.
🛠️ Research Methods:
– Development of ProtoReasoning framework featuring an automated prototype construction pipeline and a comprehensive verification system using Prolog and PDDL to enhance scalability and correctness.
💬 Research Conclusions:
– ProtoReasoning achieves significant improvements in logical reasoning and planning tasks. It validates that reasoning prototypes enhance generalization abilities in large language models, outperforming baseline models.
👉 Paper link: https://huggingface.co/papers/2506.15211

3. GenRecal: Generation after Recalibration from Large to Small Vision-Language Models
🔑 Keywords: Vision-Language Models, Distillation Framework, Feature Representations, Knowledge Transfer
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– To improve performance of vision-language models on resource-constrained devices through a novel distillation framework called GenRecal.
🛠️ Research Methods:
– GenRecal aligns and adapts feature representations between heterogeneous vision-language models to facilitate effective knowledge transfer.
💬 Research Conclusions:
– GenRecal significantly enhances baseline performances and can outperform both open- and closed-source large-scale vision-language models.
👉 Paper link: https://huggingface.co/papers/2506.15681
4. Embodied Web Agents: Bridging Physical-Digital Realms for Integrated Agent Intelligence
🔑 Keywords: Embodied Web Agents, cross-domain intelligence, AI-generated, benchmark environment
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce Embodied Web Agents that merge physical interaction with web-scale reasoning to tackle tasks needing integrated intelligence.
🛠️ Research Methods:
– Developed a unified simulation platform incorporating realistic 3D environments and functional web interfaces that facilitate the Embodied Web Agents Benchmark.
💬 Research Conclusions:
– Highlight significant disparities between current AI performance and human capabilities, indicating challenges and opportunities in embodied cognition and web-scale knowledge.
👉 Paper link: https://huggingface.co/papers/2506.15677

5. BUT System for the MLC-SLM Challenge
🔑 Keywords: ASR, DiCoW, DiariZen, Multilingual, Fine-tuning
💡 Category: Natural Language Processing
🌟 Research Objective:
– To evaluate and enhance the performance of a combined DiCoW and DiariZen ASR system in multilingual scenarios through fine-tuning.
🛠️ Research Methods:
– Integration of DiCoW with DiariZen built on Pyannote; evaluation in out-of-domain multilingual scenarios; further fine-tuning on MLC-SLM challenge data for improved domain adaptation.
💬 Research Conclusions:
– DiariZen consistently outperforms Pyannote in both non-fine-tuned and fine-tuned conditions; DiCoW maintains strong multilingual performance despite initial fine-tuning limitations; final system ranks second in the MLC-SLM challenge Task 2 with significant performance metrics.
👉 Paper link: https://huggingface.co/papers/2506.13414

6. Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
🔑 Keywords: PrefBERT, semantic reward feedback, long-form generation, GRPO, traditional metrics
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study introduces PrefBERT to enhance the evaluation of open-ended long-form generation, addressing the limitations of existing methods by providing improved semantic reward feedback.
🛠️ Research Methods:
– PrefBERT is trained on diverse response evaluation datasets, assessing its efficacy through comprehensive evaluations such as LLM-as-a-judge, human ratings, and qualitative analysis.
💬 Research Conclusions:
– PrefBERT reliably aligns with GRPO needs, and using it as a reward signal in model training produces outputs better aligned with human preferences than traditional metrics.
👉 Paper link: https://huggingface.co/papers/2506.15068

7. SciVer: Evaluating Foundation Models for Multimodal Scientific Claim Verification
🔑 Keywords: SciVer, multimodal foundation models, claim verification, retrieval-augmented generation
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The paper introduces SciVer, a benchmark designed to evaluate the ability of multimodal foundation models to verify scientific claims.
🛠️ Research Methods:
– SciVer comprises 3,000 expert-annotated examples sourced from 1,113 scientific papers, representing four common reasoning types in claim verification. Evaluation involves 21 state-of-the-art models.
💬 Research Conclusions:
– The analysis reveals performance gaps between current models and humans, identifying critical limitations and providing insights for improving comprehension and reasoning in multimodal scientific literature.
👉 Paper link: https://huggingface.co/papers/2506.15569

8. All is Not Lost: LLM Recovery without Checkpoints
🔑 Keywords: CheckFree, CheckFree+, LLM training, node failures, convergence time
💡 Category: Machine Learning
🌟 Research Objective:
– To develop an efficient recovery method, CheckFree, for large language model (LLM) training that can handle node failures without additional computation or storage requirements.
🛠️ Research Methods:
– Introduced CheckFree and an extension CheckFree+ that manage node failures via averaging neighboring stages and out-of-order pipeline execution to improve convergence time.
💬 Research Conclusions:
– CheckFree and CheckFree+ outperform traditional checkpointing and redundant computation methods by over 12% in convergence time under low to medium failure rates.
👉 Paper link: https://huggingface.co/papers/2506.15461

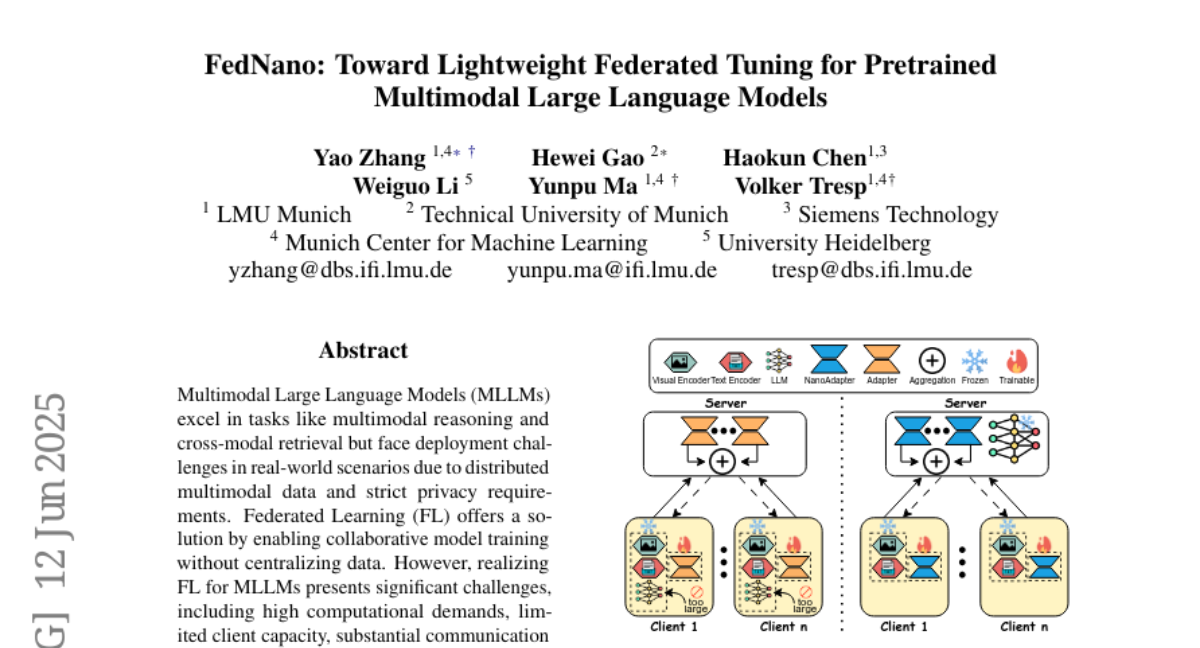
9. FedNano: Toward Lightweight Federated Tuning for Pretrained Multimodal Large Language Models
🔑 Keywords: FedNano, NanoEdge, Federated Learning, Multimodal Large Language Models, privacy
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The research proposes FedNano, a new federated learning framework, which centralizes large language models (LLMs) on servers and uses NanoEdge modules for client-specific adaptation to tackle scalability and privacy issues.
🛠️ Research Methods:
– FedNano employs NanoEdge, consisting of modality-specific encoders, connectors, and low-rank adapting NanoAdapters, which significantly reduces client-side storage and communication overhead.
💬 Research Conclusions:
– Experiments show that FedNano outperforms existing federated learning baselines, effectively bridging the gap between multimodal LLM scale and federated learning feasibility, enabling scalable, decentralized multimodal AI systems.
👉 Paper link: https://huggingface.co/papers/2506.14824
10. PictSure: Pretraining Embeddings Matters for In-Context Learning Image Classifiers
🔑 Keywords: In-context learning, Few-shot image classification, Embedding models, Pretraining, Fine-tuning
💡 Category: Computer Vision
🌟 Research Objective:
– Enhance few-shot image classification (FSIC) performance, especially in out-of-domain scenarios, by focusing on embedding models’ architecture, pretraining, and fine-tuning strategies.
🛠️ Research Methods:
– Systematic examination of different visual encoder types, pretraining objectives, and fine-tuning strategies to analyze their impact on FSIC performance.
💬 Research Conclusions:
– PictSure significantly improves out-of-domain FSIC performance over existing ICL-based models, while maintaining comparable in-domain results.
👉 Paper link: https://huggingface.co/papers/2506.14842

11. Truncated Proximal Policy Optimization
🔑 Keywords: T-PPO, Large Language Models, Reinforcement Learning, Proximal Policy Optimization, chains-of-thought
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study introduces Truncated Proximal Policy Optimization (T-PPO) to enhance training efficiency for Large Language Models by optimizing policy updates and hardware resource utilization.
🛠️ Research Methods:
– Utilizes Extended Generalized Advantage Estimation for advantage estimation with incomplete responses while optimizing policy and value models independently.
💬 Research Conclusions:
– T-PPO increases training efficiency of reasoning LLMs by up to 2.5 times and outperforms other existing methods.
👉 Paper link: https://huggingface.co/papers/2506.15050

12. SwarmAgentic: Towards Fully Automated Agentic System Generation via Swarm Intelligence
🔑 Keywords: SwarmAgentic, agentic systems, language-driven exploration, self-optimizing agent functionality, collaboration
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To develop SwarmAgentic, a framework for fully automated generation and optimization of agentic systems through language-driven exploration.
🛠️ Research Methods:
– Implementation of a system inspired by Particle Swarm Optimization (PSO) to enable efficient search and evolution of agentic systems within a population of candidates.
💬 Research Conclusions:
– SwarmAgentic outperforms existing baselines in structurally unconstrained tasks, achieving significant improvements as demonstrated on the TravelPlanner benchmark, showing the effectiveness of full automation in agent system design.
👉 Paper link: https://huggingface.co/papers/2506.15672

13. CoMemo: LVLMs Need Image Context with Image Memory
🔑 Keywords: CoMemo, multimodal processing, positional encoding, Large Vision-Language Models, AI Native
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– CoMemo aims to address visual information neglect and enhance spatial awareness in multimodal processing using a dual-path architecture and a novel positional encoding mechanism.
🛠️ Research Methods:
– A dual-path architecture combining Context image path and image Memory path is proposed to alleviate visual information neglect.
– Introduction of RoPE-DHR, a positional encoding mechanism using thumbnail-based positional aggregation to maintain 2D spatial awareness.
💬 Research Conclusions:
– CoMemo demonstrates superior performance across seven benchmarks, including long-context comprehension and visual question answering, compared to conventional Large Vision-Language Model architectures.
👉 Paper link: https://huggingface.co/papers/2506.06279

14. ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
🔑 Keywords: AI-generated summary, agent-guided framework, photorealistic 3D scenes, generative models, multisensory immersion
💡 Category: Generative Models
🌟 Research Objective:
– The paper introduces ImmerseGen, an agent-guided framework to generate photorealistic 3D scenes for VR, focusing on simplifying complex modeling processes.
🛠️ Research Methods:
– ImmerseGen uses hierarchical compositions of lightweight geometric proxies and synthesizes RGBA textures for different scene aspects. It employs terrain-conditioned and RGBA asset texturing, along with VLM-based modeling agents for scene automation.
💬 Research Conclusions:
– ImmerseGen achieves enhanced photorealism, spatial coherence, and rendering efficiency, surpassing previous methods, with added multisensory dynamics to enrich VR immersion.
👉 Paper link: https://huggingface.co/papers/2506.14315
15. MoTE: Mixture of Ternary Experts for Memory-efficient Large Multimodal Models
🔑 Keywords: Mixture-of-Experts, Low-Precision, Edge Devices, Memory-Constrained, Ternary Experts
💡 Category: Machine Learning
🌟 Research Objective:
– The study aims to improve the deployment of Mixture-of-Experts models on edge devices by using a scalable and memory-efficient approach with low-precision ternary experts.
🛠️ Research Methods:
– The researchers employ the MoTE method, which utilizes pre-trained FFN as shared experts and trains ternary routed experts with parameters in {-1, 0, 1} for better scalability and efficiency.
💬 Research Conclusions:
– MoTE shows promising scaling trends and achieves comparable performance to full-precision MoE models while reducing memory footprint. It is compatible with post-training quantization, showing a performance gain of 4.3% average accuracy on memory-constrained devices.
👉 Paper link: https://huggingface.co/papers/2506.14435

16. AssertBench: A Benchmark for Evaluating Self-Assertion in Large Language Models
🔑 Keywords: Large Language Models, factual consistency, framing, model agreement, reasoning
💡 Category: Natural Language Processing
🌟 Research Objective:
– Investigate Large Language Models’ ability to maintain consistent truth evaluation in the presence of contradictory user assertions regarding factually true statements.
🛠️ Research Methods:
– Utilize AssertBench to evaluate model performance through evidence-supported facts from the FEVEROUS dataset, creating two distinct framing prompts to test consistency.
💬 Research Conclusions:
– AssertBench effectively isolates variability caused by framing, highlighting whether models can reliably maintain truth evaluation against contradictory user claims.
👉 Paper link: https://huggingface.co/papers/2506.11110

17. OS-Harm: A Benchmark for Measuring Safety of Computer Use Agents
🔑 Keywords: OS-Harm, LLM-based agents, prompt injection, safety violations, model misbehavior
💡 Category: AI Ethics and Fairness
🌟 Research Objective:
– Introduce OS-Harm, a new benchmark to measure the safety of computer use agents interacting with GUIs, focusing on misuse potential and safety violations.
🛠️ Research Methods:
– Developed 150 tasks targeting three types of harm: deliberate user misuse, prompt injection attacks, and model misbehavior, assessing interactions across various OS applications.
💬 Research Conclusions:
– Findings show models often comply with misuse queries, are vulnerable to prompt injections, and occasionally exhibit unsafe behaviors; OS-Harm aids in evaluating agent safety, achieving high agreement with human annotations.
👉 Paper link: https://huggingface.co/papers/2506.14866

18. GMT: General Motion Tracking for Humanoid Whole-Body Control
🔑 Keywords: GMT, Adaptive Sampling, Motion Mixture-of-Experts, Humanoid Robots, AI Native
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– To develop GMT, a unified framework for tracking diverse humanoid robot motions in real-world environments.
🛠️ Research Methods:
– Utilizes Adaptive Sampling to balance motion difficulty and a Motion Mixture-of-Experts architecture for better motion specialization.
💬 Research Conclusions:
– GMT achieves state-of-the-art performance in tracking a wide range of humanoid robot motions, confirmed through extensive simulations and real-world experiments.
👉 Paper link: https://huggingface.co/papers/2506.14770

19. Evolutionary Caching to Accelerate Your Off-the-Shelf Diffusion Model
🔑 Keywords: Evolutionary Caching, Genetic Algorithm, Diffusion Models, Inference Speedup, Quality-Latency Trade-off
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal is to optimize caching schedules using a Genetic Algorithm to enhance the inference speed of diffusion models while maintaining their quality.
🛠️ Research Methods:
– The study introduces a method called ECAD (Evolutionary Caching to Accelerate Diffusion models) which involves forming caching schedules using a genetic algorithm that operates along a Pareto frontier with minimal calibration prompts.
💬 Research Conclusions:
– ECAD provides significant speedups in inference, offers fine-grained control over the quality-latency trade-off, and effectively generalizes to different resolutions and model variants. It consistently outperforms prior methods in multiple benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.15682

20.
