AI Native Daily Paper Digest – 20250624

1. Light of Normals: Unified Feature Representation for Universal Photometric Stereo
🔑 Keywords: Photometric Stereo, Surface Normals, Illumination-Surface Normal Coupling, High-Frequency Geometric Details, AI-generated Summary
💡 Category: Computer Vision
🌟 Research Objective:
– The objective is to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models.
🛠️ Research Methods:
– The research addresses the challenges of deep coupling between varying illumination and surface normal features, and the preservation of high-frequency geometric details in complex surfaces.
💬 Research Conclusions:
– Despite advances like SDM-UniPS and Uni MS-PS, challenges remain due to ambiguity in intensity variations and difficulties in capturing intricate geometries accurately.
👉 Paper link: https://huggingface.co/papers/2506.18882
2. OmniGen2: Exploration to Advanced Multimodal Generation
🔑 Keywords: OmniGen2, Generative Model, Dual Decoding Pathways, OmniContext, State-of-the-Art Performance
💡 Category: Generative Models
🌟 Research Objective:
– Introduce OmniGen2, a versatile generative model for various generation tasks such as text-to-image, image editing, and in-context generation.
🛠️ Research Methods:
– Develop dual decoding pathways for text and images, utilizing unshared parameters and a decoupled image tokenizer.
– Establish comprehensive data construction pipelines and introduce a reflection mechanism for image generation.
💬 Research Conclusions:
– OmniGen2 achieves competitive results with a relatively modest parameter size.
– It achieves state-of-the-art performance among open-source models for consistency, supported by the introduction of a new benchmark, OmniContext.
– All models, codes, datasets, and pipelines will be released to support future research.
👉 Paper link: https://huggingface.co/papers/2506.18871

3. LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
🔑 Keywords: Ultra-long generation, Large language models, Reinforcement learning, Writing quality, Length control
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a large language model capable of generating ultra-long, high-quality text without synthetic data or supervised fine-tuning.
🛠️ Research Methods:
– Employing an incentivization-based reinforcement learning approach from scratch, leveraging specialized reward models for improved length control, writing quality, and structural formatting.
💬 Research Conclusions:
– The LongWriter-Zero model outperforms traditional methods and achieves state-of-the-art results on long-form writing tasks, even surpassing models with over 100B parameters.
👉 Paper link: https://huggingface.co/papers/2506.18841

4. ViDAR: Video Diffusion-Aware 4D Reconstruction From Monocular Inputs
🔑 Keywords: ViDAR, diffusion-aware reconstruction, monocular video, AI-generated summary, Gaussian splatting
💡 Category: Computer Vision
🌟 Research Objective:
– The study aims to generate high-quality novel views of dynamic scenes using monocular video through the innovative ViDAR framework.
🛠️ Research Methods:
– ViDAR leverages personalised diffusion models to synthesize a pseudo multi-view supervision signal and uses a diffusion-aware loss function with camera pose optimization for better alignment with scene geometry.
💬 Research Conclusions:
– Experiments reveal that ViDAR surpasses current state-of-the-art methods in terms of visual quality and geometric consistency, particularly excelling in dynamic regions and providing a new benchmark for reconstructing motion-rich scene parts.
👉 Paper link: https://huggingface.co/papers/2506.18792

5. Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
🔑 Keywords: Phantom-Data, subject-to-video generation, copy-paste problem, identity consistency, prompt alignment
💡 Category: Generative Models
🌟 Research Objective:
– To introduce Phantom-Data to improve subject-to-video generation by addressing the copy-paste problem and enhancing identity consistency.
🛠️ Research Methods:
– Development of a three-stage pipeline including subject detection, large-scale subject retrieval, and prior-guided identity verification.
💬 Research Conclusions:
– Phantom-Data significantly enhances prompt alignment and visual quality while maintaining identity consistency compared to traditional in-pair training models.
👉 Paper link: https://huggingface.co/papers/2506.18851

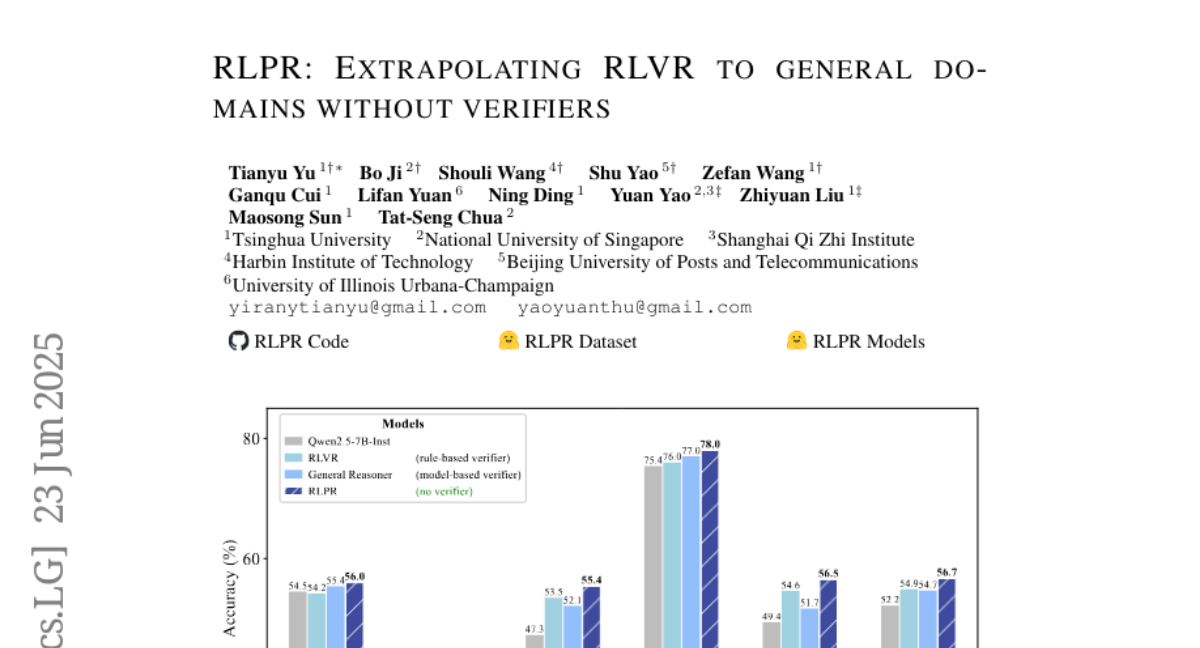
6. RLPR: Extrapolating RLVR to General Domains without Verifiers
🔑 Keywords: RLPR, LLM, token probability scores, reasoning capabilities
💡 Category: Reinforcement Learning
🌟 Research Objective:
– Introduce RLPR, a verifier-free framework using LLM’s token probability scores to enhance reasoning in general and mathematical domains.
🛠️ Research Methods:
– Use LLM’s intrinsic token probability scores as reward signals and implement stabilization methods to manage high variance in probability rewards.
💬 Research Conclusions:
– RLPR consistently improves reasoning capabilities in various benchmarks, outperforming other methods such as VeriFree and General-Reasoner.
👉 Paper link: https://huggingface.co/papers/2506.18254
7. ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
🔑 Keywords: ReasonFlux-PRM, Process Reward Models, Reinforcement Learning, trajectory-level supervision, model distillation
💡 Category: Knowledge Representation and Reasoning
🌟 Research Objective:
– Introduce ReasonFlux-PRM, a novel trajectory-aware Process Reward Model designed to evaluate trajectory-response reasoning traces with both step-level and trajectory-level supervision.
🛠️ Research Methods:
– Adaptation of ReasonFlux-PRM for reward supervision under offline and online settings, including model distillation, reinforcement learning policy optimization, and Best-of-N test-time scaling.
💬 Research Conclusions:
– Empirical results show ReasonFlux-PRM-7B achieves higher quality data selection and consistent performance improvements over baseline models, with average gains of 12.1% in supervised fine-tuning, 4.5% in reinforcement learning, and 6.3% in test-time scaling.
– ReasonFlux-PRM-1.5B being released for resource-constrained applications.
👉 Paper link: https://huggingface.co/papers/2506.18896

8. OAgents: An Empirical Study of Building Effective Agents
🔑 Keywords: Agentic AI, GAIA benchmark, OAgents
💡 Category: Foundations of AI
🌟 Research Objective:
– To examine the impact of design choices in agent frameworks using GAIA benchmark and BrowseComp.
🛠️ Research Methods:
– Conducting a systematic empirical study and introducing a robust evaluation protocol.
💬 Research Conclusions:
– Identification of crucial agent components and designs, leading to the creation of OAgents, a high-performance, modular agent framework.
👉 Paper link: https://huggingface.co/papers/2506.15741

9. Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations
🔑 Keywords: Multimodal Framework, Text-Aligned Tokenizer, Generative De-tokenizer, Autoregressive Model, Diffusion-based Model
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to unify visual understanding and generation within a shared discrete semantic representation by integrating vision and text into a unified space.
🛠️ Research Methods:
– Utilization of a Text-Aligned Tokenizer (TA-Tok) to convert images into discrete tokens using a text-aligned codebook and two complementary de-tokenizers (autoregressive and diffusion-based models) for efficient and high-fidelity visual outputs.
💬 Research Conclusions:
– The proposed framework, including Tar, matches or surpasses existing multimodal models, achieving faster convergence and greater training efficiency.
👉 Paper link: https://huggingface.co/papers/2506.18898

10. VMem: Consistent Interactive Video Scene Generation with Surfel-Indexed View Memory
🔑 Keywords: Surfel-Indexed View Memory, video generation, 3D geometry, scene coherence, computational cost
💡 Category: Generative Models
🌟 Research Objective:
– Introduce the Surfel-Indexed View Memory mechanism to enhance video generation by efficiently remembering and retrieving relevant past views.
🛠️ Research Methods:
– Utilize surfels to geometrically index past views for efficient retrieval in generating new ones, improving long-term scene coherence and reducing computational costs.
💬 Research Conclusions:
– Demonstrated superior performance in maintaining scene coherence and camera control compared to existing methods in long-term scene synthesis benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.18903
11. DIP: Unsupervised Dense In-Context Post-training of Visual Representations
🔑 Keywords: Unsupervised post-training, Dense image representations, In-context scene understanding, Diffusion model, Meta-learning
💡 Category: Computer Vision
🌟 Research Objective:
– The research introduces DIP, an unsupervised post-training method aimed at enhancing dense image representations for in-context scene understanding.
🛠️ Research Methods:
– The method employs pseudo-tasks inspired by meta-learning principles and leverages a pretrained diffusion model, allowing automatic generation of in-context tasks for post-training.
💬 Research Conclusions:
– DIP is shown to be computationally efficient, simple, and unsupervised, delivering strong performance and outperforming existing methods and the original vision encoder in various real-world tasks.
👉 Paper link: https://huggingface.co/papers/2506.18463

12. LettinGo: Explore User Profile Generation for Recommendation System
🔑 Keywords: User Profiling, Recommendation Systems, LLMs, Direct Preference Optimization, Adaptive Profiles
💡 Category: Machine Learning
🌟 Research Objective:
– The research aims to improve the accuracy and flexibility of recommendation systems by enhancing user profiling with diverse and adaptive profiles generated using LLMs and Direct Preference Optimization.
🛠️ Research Methods:
– Introduced LettinGo framework, which operates in three stages: exploring diverse user profiles using multiple LLMs, evaluating profile quality in recommendation systems, and aligning profile generation with task-specific performance using pairwise preference data.
💬 Research Conclusions:
– The experimental results indicate that the LettinGo framework significantly enhances recommendation accuracy, flexibility, and contextual awareness, making it a key innovation for next-generation recommendation systems.
👉 Paper link: https://huggingface.co/papers/2506.18309

13. 4Real-Video-V2: Fused View-Time Attention and Feedforward Reconstruction for 4D Scene Generation
🔑 Keywords: 4D spatio-temporal grid, feed-forward architecture, 4D video model, temporal attention, sparse attention pattern
💡 Category: Computer Vision
🌟 Research Objective:
– The research aims to develop a new framework combining 4D video modeling and 3D reconstruction to achieve superior visual quality and reconstruction capability.
🛠️ Research Methods:
– A fused architecture performing spatial and temporal attention within a single layer using sparse attention patterns, focusing on tokens in the same frame, timestamp, or viewpoint.
– Extending existing 3D reconstruction algorithms with innovations like a Gaussian head, camera token replacement, and dynamic layers.
💬 Research Conclusions:
– The study establishes a new state of the art for 4D generation, enhancing both visual quality and reconstruction abilities.
👉 Paper link: https://huggingface.co/papers/2506.18839

14. FinCoT: Grounding Chain-of-Thought in Expert Financial Reasoning
🔑 Keywords: FinCoT, structured chain-of-thought, Financial NLP, interpretability, domain-aligned
💡 Category: AI in Finance
🌟 Research Objective:
– The study aims to improve performance and reduce computational costs in financial natural language processing by leveraging a structured chain-of-thought prompting method.
🛠️ Research Methods:
– The paper evaluates three main prompting styles, including structured CoT, using CFA-style questions across ten financial domains to assess performance improvements.
💬 Research Conclusions:
– FinCoT improves performance significantly (from 63.2% to 80.5%), reduces inference costs, and provides more interpretable, expert-aligned reasoning traces compared to previous methods.
👉 Paper link: https://huggingface.co/papers/2506.16123

15. Enhancing Step-by-Step and Verifiable Medical Reasoning in MLLMs
🔑 Keywords: MICS, Chiron-o1, chain-of-thought, medical MLLMs, AI Native
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research aims to enhance medical multidisciplinary large language models (MLLMs) by developing a novel reasoning-path searching scheme called Mentor-Intern Collaborative Search (MICS) to generate high-quality chain-of-thought (CoT) data for improving reasoning capabilities in medical contexts.
🛠️ Research Methods:
– The MICS scheme involves using mentor models to initiate reasoning paths, with intern models subsequently tasked to continue and optimize these paths. The reasoning paths are evaluated using an MICS-Score, and the method includes constructing a multi-task medical reasoning dataset (MMRP).
💬 Research Conclusions:
– The study concludes that MICS significantly improves the reasoning and visual question-answering capabilities of medical MLLMs, as demonstrated by the state-of-the-art performance of Chiron-o1 across various medical benchmarks.
👉 Paper link: https://huggingface.co/papers/2506.16962

16. SlimMoE: Structured Compression of Large MoE Models via Expert Slimming and Distillation
🔑 Keywords: SlimMoE, MoE, structured pruning, staged distillation, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– Introduction of SlimMoE, a multi-stage compression framework designed to transform large MoE models into smaller, efficient variants without full retraining.
🛠️ Research Methods:
– Utilizes multi-stage compression to slim down experts and transfer knowledge through intermediate stages, reducing parameter counts and mitigating performance degradation.
💬 Research Conclusions:
– Compressed models, Phi-mini-MoE and Phi-tiny-MoE, outperform others of similar size and remain competitive with larger models, achieving efficient performance with less computational resources.
– Demonstrated the effectiveness of structured pruning and staged distillation in creating high-quality, compact MoE models, facilitating broader adoption of MoE architectures.
👉 Paper link: https://huggingface.co/papers/2506.18349

17. From Virtual Games to Real-World Play
🔑 Keywords: RealPlay, photorealistic, temporally consistent, control signals, interactive video generation
💡 Category: Generative Models
🌟 Research Objective:
– Introduce RealPlay, a neural network-based game engine aimed at generating photorealistic and temporally consistent video sequences from user control signals.
🛠️ Research Methods:
– Operates interactively, using iterative chunk-wise prediction and a blend of labeled game data with unlabeled real-world videos, without requiring real-world action annotations.
💬 Research Conclusions:
– Demonstrates two generalization capabilities: control transfer, mapping control signals from virtual to real-world, and entity transfer, enabling control over various real-world entities beyond training data.
👉 Paper link: https://huggingface.co/papers/2506.18901

18. Robust Reward Modeling via Causal Rubrics
🔑 Keywords: Crome, Reward Hacking, Causal Augmentations, Large Language Models, Reward Models
💡 Category: Natural Language Processing
🌟 Research Objective:
– The research introduces Crome, a novel framework aimed at improving the robustness and accuracy of reward models by mitigating reward hacking through causal and neutral augmentations.
🛠️ Research Methods:
– Crome utilizes targeted synthetic augmentations during training, including Causal Augmentations to enforce sensitivity on specific causal attributes, and Neutral Augmentations to enforce invariance on spurious attributes.
– The augmentations are generated using interventions along causal rubrics identified by querying an oracle LLM.
💬 Research Conclusions:
– Empirical results demonstrate that Crome significantly outperforms standard baselines, achieving notable accuracy improvements and consistent robustness across various benchmarks, including RewardBench, WildGuardTest, and GSM8k.
👉 Paper link: https://huggingface.co/papers/2506.16507

19. ReDit: Reward Dithering for Improved LLM Policy Optimization
🔑 Keywords: ReDit, reward dithering, gradient anomaly, AI-generated summary, performance improvement
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To address issues in discrete reward systems such as gradient anomaly and slow convergence by introducing a reward dithering method called ReDit.
🛠️ Research Methods:
– Introducing random noise into discrete reward signals to provide continuous exploratory gradients, enhance optimization stability, and accelerate convergence.
💬 Research Conclusions:
– ReDit achieves smoother gradient updates and significant performance improvements, achieving similar or better performance with fewer training steps compared to vanilla GRPO.
👉 Paper link: https://huggingface.co/papers/2506.18631

20. TC-Light: Temporally Consistent Relighting for Dynamic Long Videos
🔑 Keywords: TC-Light, temporal coherence, computational cost, appearance embedding, Unique Video Tensor
💡 Category: Computer Vision
🌟 Research Objective:
– Develop a novel two-stage video relighting model that enhances illumination editing in long and dynamic videos, addressing temporal consistency and computational efficiency.
🛠️ Research Methods:
– Implement a two-stage optimization mechanism starting with appearance embedding to align global illumination, followed by optimizing the Unique Video Tensor for fine-grained texture and lighting alignment.
💬 Research Conclusions:
– TC-Light achieves physically plausible relighting with superior temporal coherence and reduced computational cost, supported by extensive experiments and a new dynamic video benchmark.
👉 Paper link: https://huggingface.co/papers/2506.18904

21. ConsumerBench: Benchmarking Generative AI Applications on End-User Devices
🔑 Keywords: ConsumerBench, Generative AI, benchmarking framework, system efficiency, response time
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To evaluate the system efficiency and response time of Generative AI models running on end-user devices using the ConsumerBench framework.
🛠️ Research Methods:
– Simulation of realistic multi-application scenarios on constrained hardware with customizable workflows to evaluate application and system-level metrics.
💬 Research Conclusions:
– The study highlights inefficiencies in resource sharing and scheduling, and emphasizes the advantages of custom kernels and SLO-aware scheduling strategies for improved GenAI model performance.
👉 Paper link: https://huggingface.co/papers/2506.17538

22. Auto-Regressively Generating Multi-View Consistent Images
🔑 Keywords: Multi-View Auto-Regressive, auto-regressive model, multi-view images, data augmentation
💡 Category: Generative Models
🌟 Research Objective:
– Develop a method to generate consistent multi-view images from arbitrary prompts, addressing challenges in shape and texture synthesis under varying conditions.
🛠️ Research Methods:
– Utilizes an auto-regressive model with next-token prediction to enhance multi-view synthesis.
– Incorporates condition injection modules and a progressive training strategy to manage multi-modal conditions.
💬 Research Conclusions:
– The proposed MV-AR method effectively generates consistent multi-view images in various conditions and shows competitive performance compared to leading diffusion-based models.
👉 Paper link: https://huggingface.co/papers/2506.18527

23. I Know Which LLM Wrote Your Code Last Summer: LLM generated Code Stylometry for Authorship Attribution
🔑 Keywords: CodeT5-Authorship, LLMs, Authorship Attribution, Binary Classification, AI-generated Code
💡 Category: Natural Language Processing
🌟 Research Objective:
– The main objective is to attribute authorship to C programs generated by Large Language Models (LLMs) using the CodeT5-Authorship model.
🛠️ Research Methods:
– Developed CodeT5-Authorship, a model using only encoder layers from the original CodeT5 architecture, accompanied by a two-layer classification head with GELU activation and dropout.
– Introduced LLM-AuthorBench, a benchmark of 32,000 C programs generated by various LLMs.
– Compared performance with seven traditional ML classifiers and eight fine-tuned transformer models.
💬 Research Conclusions:
– CodeT5-Authorship achieved high accuracy in classifying C programs, with 97.56% accuracy in binary classification among closely related LLMs and 95.40% accuracy for multi-class attribution among five leading LLMs.
– Released CodeT5-Authorship architecture and LLM-AuthorBench benchmark in support of open science on GitHub.
👉 Paper link: https://huggingface.co/papers/2506.17323

24. FaithfulSAE: Towards Capturing Faithful Features with Sparse Autoencoders without External Dataset Dependencies
🔑 Keywords: FaithfulSAE, Sparse Autoencoders, interpretability, synthetic dataset, Fake Features
💡 Category: Machine Learning
🌟 Research Objective:
– To enhance the stability and interpretability of Sparse Autoencoders by training them on synthetic datasets generated by the model itself, reducing the incidence of fake features and out-of-distribution data issues.
🛠️ Research Methods:
– Implemented FaithfulSAE to train Sparse Autoencoders on synthetic datasets, focusing on minimizing out-of-distribution data by avoiding external datasets.
💬 Research Conclusions:
– FaithfulSAEs improve stability across initialization seeds and outperform traditional SAEs on web-based datasets in probing tasks, demonstrating a lower Fake Feature Ratio in the majority of tested models. This approach advances the interpretability of model-internal features by eliminating reliance on external datasets.
👉 Paper link: https://huggingface.co/papers/2506.17673

25. How Alignment Shrinks the Generative Horizon
🔑 Keywords: Branching Factor, Aligned Large Language Models, Output Distribution, Aligned Chain-of-Thought, Token-Invariant
💡 Category: Natural Language Processing
🌟 Research Objective:
– To investigate the phenomenon of stability in aligned large language models (LLMs) by examining probability concentration in the models’ output.
🛠️ Research Methods:
– Introduces the Branching Factor (BF) as a token-invariant metric to quantify the variability and predictability in the output distribution of LLMs during generation.
💬 Research Conclusions:
– Findings reveal that BF decreases as the generation progresses, indicating increased predictability in aligned LLMs. Alignment tuning significantly narrows the model’s output distribution, thus reducing variability and explaining stable outputs, especially in Aligned Chain-of-Thought models.
👉 Paper link: https://huggingface.co/papers/2506.17871
26. 3D Arena: An Open Platform for Generative 3D Evaluation
🔑 Keywords: Generative 3D models, human preference, AI-generated summary, Gaussian splat, textured models
💡 Category: Generative Models
🌟 Research Objective:
– The primary goal is to evaluate Generative 3D models by aligning automated metrics with human perception through the 3D Arena platform.
🛠️ Research Methods:
– Conducting large-scale human preference collection using pairwise comparisons.
– Implementation of statistical fraud detection to ensure quality control.
– Utilizing an ELO-based ranking system to assess model performance.
💬 Research Conclusions:
– Analysis demonstrates a strong human preference for visual presentations with textured models gaining significant advantages.
– Recommendations include advancements in evaluation methods such as multi-criteria assessment and task-oriented evaluation.
👉 Paper link: https://huggingface.co/papers/2506.18787
27. CommVQ: Commutative Vector Quantization for KV Cache Compression
🔑 Keywords: Commutative Vector Quantization, LLM, KV cache, additive quantization, GPU
💡 Category: Natural Language Processing
🌟 Research Objective:
– To reduce memory usage for long-context inference in Large Language Models (LLMs) by compressing the key-value (KV) cache.
🛠️ Research Methods:
– Introduction of Commutative Vector Quantization (CommVQ) with a lightweight encoder and codebook for KV cache compression.
– Utilization of additive quantization and integration with Rotary Position Embedding (RoPE) using an Expectation-Maximization (EM) algorithm.
💬 Research Conclusions:
– CommVQ significantly reduces the FP16 KV cache size by 87.5% with 2-bit quantization.
– The method supports 1-bit KV cache quantization with minimal accuracy loss, allowing efficient LLaMA-3.1 model execution on standard GPUs.
👉 Paper link: https://huggingface.co/papers/2506.18879

28. Steering Conceptual Bias via Transformer Latent-Subspace Activation
🔑 Keywords: LLMs, scientific code generation, gradient-refined, activation steering, concept-level control
💡 Category: Natural Language Processing
🌟 Research Objective:
– To determine whether activating latent subspaces in language models can effectively steer scientific code generation towards a specific programming language, enhancing targeted language biases.
🛠️ Research Methods:
– Development of a gradient-refined adaptive activation steering framework (G-ACT) that clusters activation differences into steering directions and utilizes lightweight per-layer probes trained online to select appropriate steering vectors.
💬 Research Conclusions:
– The G-ACT framework successfully increases the reliability of LLaMA-3.2 3B models in favoring the CPP language, improves probe classification accuracy significantly, and provides a scalable, interpretable mechanism for concept-level control in LLM-driven systems.
👉 Paper link: https://huggingface.co/papers/2506.18887

29. Demystifying the Visual Quality Paradox in Multimodal Large Language Models
🔑 Keywords: Visual-Quality Test-Time Tuning, Multimodal Large Language Models, vision-language tasks, adaptive imagery
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study investigates how input visual quality impacts the performance of Multimodal Large Language Models (MLLMs) on vision-language tasks and introduces a method to adaptively adjust images to align with model preferences.
🛠️ Research Methods:
– Conducts a systematic study using leading MLLMs across various vision-language benchmarks, applying controlled degradations and stylistic changes to images to observe effects on model understanding.
💬 Research Conclusions:
– Introduces Visual-Quality Test-Time Tuning (VQ-TTT), which improves model accuracy by dynamically adjusting input images to meet task-specific model preferences without the need for external models, cached features, or additional training data.
– Highlights the importance of adaptive imagery over universally high-quality images for enhancing MLLMs’ performance.
👉 Paper link: https://huggingface.co/papers/2506.15645

30. CultureMERT: Continual Pre-Training for Cross-Cultural Music Representation Learning
🔑 Keywords: CultureMERT-95M, cross-cultural music representation, multi-cultural adaptation, two-stage continual pre-training, music foundation models
💡 Category: Machine Learning
🌟 Research Objective:
– Develop a multi-culturally adapted foundation model to enhance cross-cultural music representation learning using a two-stage continual pre-training strategy.
🛠️ Research Methods:
– Implement a two-stage continual pre-training strategy integrating learning rate re-warming and re-decaying on a 650-hour multi-cultural data mix, including Greek, Turkish, and Indian music traditions.
💬 Research Conclusions:
– CultureMERT-95M achieves superior performance in non-Western music auto-tagging tasks, with a 4.9% average improvement in ROC-AUC and AP, while maintaining performance on Western-centric benchmarks. Task arithmetic is demonstrated as an alternative approach with comparable results.
👉 Paper link: https://huggingface.co/papers/2506.17818

31. 4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
🔑 Keywords: 4D-LRM, space-time representation, Gaussian primitives, 4D reconstruction
💡 Category: Computer Vision
🌟 Research Objective:
– The paper aims to scale 4D pretraining to learn general space-time representation for reconstructing objects from a few views at specific times into any view-time combination.
🛠️ Research Methods:
– The study introduces 4D-LRM, the first large-scale 4D reconstruction model that uses space-time representations and predicts per-pixel 4D Gaussian primitives from posed image tokens.
💬 Research Conclusions:
– 4D-LRM efficiently reconstructs objects with high-quality rendering at potentially infinite frame rates, generalizes to novel objects, interpolates over time, and adapts to various camera setups, achieving efficient 24-frame sequence reconstruction in under 1.5 seconds on a single A100 GPU.
👉 Paper link: https://huggingface.co/papers/2506.18890

32. SoK: Evaluating Jailbreak Guardrails for Large Language Models
🔑 Keywords: Large Language Models, jailbreak attacks, guardrails, multi-dimensional taxonomy, Security-Efficiency-Utility
💡 Category: Natural Language Processing
🌟 Research Objective:
– Present a systematic analysis and evaluation framework for guardrails in Large Language Models to tackle jailbreak attacks.
🛠️ Research Methods:
– Introduction of a multi-dimensional taxonomy categorizing guardrails along six dimensions.
– Use of a Security-Efficiency-Utility evaluation framework to assess guardrail effectiveness.
💬 Research Conclusions:
– Identified strengths and limitations of existing guardrails and their universality across attack types.
– Provided insights into optimizing defense combinations for future robust LLM guardrail development.
👉 Paper link: https://huggingface.co/papers/2506.10597

33. Spec2RTL-Agent: Automated Hardware Code Generation from Complex Specifications Using LLM Agent Systems
🔑 Keywords: Spec2RTL-Agent, LLM, RTL code generation, multi-agent collaboration framework, synthesizable C++ code
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The objective is to automate the generation of RTL code from complex specifications using a multi-agent system, Spec2RTL-Agent, to improve code correctness and minimize human intervention.
🛠️ Research Methods:
– Spec2RTL-Agent incorporates a multi-agent collaboration framework that includes a reasoning and understanding module for translating specifications, a progressive coding and prompt optimization module for refining code, and an adaptive reflection module to trace and correct errors.
💬 Research Conclusions:
– Spec2RTL-Agent demonstrates its capability to generate accurate RTL code with significantly less human intervention, approximately reducing the need by 75% compared to existing methods, marking a significant step towards fully automated RTL code generation.
👉 Paper link: https://huggingface.co/papers/2506.13905

34. A deep learning and machine learning approach to predict neonatal death in the context of São Paulo
🔑 Keywords: Deep learning, LSTM, Neonatal mortality, AI-generated summary, Machine learning
💡 Category: AI in Healthcare
🌟 Research Objective:
– To early predict neonatal mortality using machine learning techniques, enabling timely precautionary measures.
🛠️ Research Methods:
– Employed a dataset of 1.4 million newborns and implemented various algorithms, including Logical Regression, K-nearest neighbor, Random forest classifier, Extreme gradient boosting (XGBoost), Convolutional Neural Network, and LSTM.
💬 Research Conclusions:
– LSTM demonstrated the highest prediction accuracy at 99%, indicating its suitability for predicting neonatal mortality compared to other machine learning techniques.
👉 Paper link: https://huggingface.co/papers/2506.16929

35. GEMeX-ThinkVG: Towards Thinking with Visual Grounding in Medical VQA via Reinforcement Learning
🔑 Keywords: Explainability, Medical Visual Question Answering, Reinforcement Learning, Intermediate Reasoning
💡 Category: AI in Healthcare
🌟 Research Objective:
– The research aims to enhance the explainability and efficiency of medical visual question answering models by introducing a novel dataset and a verifiable reward mechanism.
🛠️ Research Methods:
– A new dataset called “Thinking with Visual Grounding” (ThinkVG) is proposed, which decomposes answer generation into intermediate reasoning steps, grounding relevant visual regions.
– A novel verifiable reward mechanism for reinforcement learning is introduced to improve the alignment of the model’s reasoning process and the final answer.
💬 Research Conclusions:
– The method achieves comparable performance using only one-eighth of the training data, demonstrating the proposal’s efficiency and effectiveness.
– The dataset is available at the provided link, offering resources for further research advancements.
👉 Paper link: https://huggingface.co/papers/2506.17939

36. RePIC: Reinforced Post-Training for Personalizing Multi-Modal Language Models
🔑 Keywords: reinforcement learning, personalized image captions, multi-modal large language models, supervised fine-tuning, AI-generated summary
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– The study aims to enhance the personalized image captioning capabilities of multi-modal large language models (MLLMs) using a reinforcement learning-based post-training framework.
🛠️ Research Methods:
– The research introduces a novel reinforcement learning approach for post-training MLLMs, which addresses the limitations of supervised fine-tuning approaches, particularly in generating multi-concept image captions.
💬 Research Conclusions:
– The proposed reinforcement learning framework significantly improves the visual recognition and personalized generation capabilities of MLLMs, outperforming traditional supervised fine-tuning baselines in complex real-world scenarios.
👉 Paper link: https://huggingface.co/papers/2506.18369

37. Audit & Repair: An Agentic Framework for Consistent Story Visualization in Text-to-Image Diffusion Models
🔑 Keywords: Story visualization, Visual consistency, Collaborative multi-agent framework, Diffusion models, Stable Diffusion
💡 Category: Generative Models
🌟 Research Objective:
– To improve consistency in multi-panel story visualizations through a collaborative multi-agent framework that addresses inconsistencies using diffusion models.
🛠️ Research Methods:
– Implementation of a collaborative multi-agent framework that autonomously identifies, corrects, and refines inconsistencies across panels using an iterative loop.
– Integration of the framework with various diffusion models like Flux and Stable Diffusion to allow flexible, fine-grained updates.
💬 Research Conclusions:
– The proposed framework enhances the consistency of story visualizations across multiple panels and outperforms prior methods in maintaining visual coherence.
👉 Paper link: https://huggingface.co/papers/2506.18900

38. TPTT: Transforming Pretrained Transformer into Titans
🔑 Keywords: large language models, long-context inference, TPTT, linearized attention, Hugging Face Transformers
💡 Category: Natural Language Processing
🌟 Research Objective:
– To introduce TPTT, a novel framework enhancing pretrained transformer models for long-context inference by improving efficiency and accuracy.
🛠️ Research Methods:
– Utilization of linearized attention mechanisms and advanced memory management techniques like Memory as Gate (MaG) and mixed linearized attention (LiZA).
– Compatible with Hugging Face Transformers for parameter-efficient fine-tuning without full retraining.
💬 Research Conclusions:
– Significant improvements in efficiency and accuracy on the MMLU benchmark, showing a 20% Exact Match increase with Titans-Llama-3.2-1B.
– Statistical analyses and comparisons demonstrate TPTT’s scalability and robustness.
👉 Paper link: https://huggingface.co/papers/2506.17671

39.
