AI Native Daily Paper Digest – 20250626

1. ShareGPT-4o-Image: Aligning Multimodal Models with GPT-4o-Level Image Generation
🔑 Keywords: ShareGPT-4o-Image, Janus-4o, text-to-image, photorealistic, dataset
💡 Category: Generative Models
🌟 Research Objective:
– The objective is to democratize photorealistic, instruction-aligned image generation by introducing ShareGPT-4o-Image and Janus-4o.
🛠️ Research Methods:
– Utilization of a large dataset comprising 45K text-to-image and 46K text-and-image-to-image data synthesized using GPT-4o’s capabilities.
💬 Research Conclusions:
– Development of Janus-4o as a multimodal large language model capable of improved text-to-image and new text-and-image-to-image generation with high performance from limited synthetic samples and training time.
👉 Paper link: https://huggingface.co/papers/2506.18095

2. Inverse-and-Edit: Effective and Fast Image Editing by Cycle Consistency Models
🔑 Keywords: Consistency Models, Image Inversion, Image Editing, Diffusion Models, Reconstruction Accuracy
💡 Category: Computer Vision
🌟 Research Objective:
– Introduce a novel framework using consistency models to enhance image inversion, achieving high-quality editing with fewer steps.
🛠️ Research Methods:
– Proposed a cycle-consistency optimization strategy to improve reconstruction accuracy and balance editability with content preservation.
💬 Research Conclusions:
– Demonstrated state-of-the-art performance in image editing tasks and datasets, surpassing the efficiency of full-step diffusion models.
👉 Paper link: https://huggingface.co/papers/2506.19103

3. Outlier-Safe Pre-Training for Robust 4-Bit Quantization of Large Language Models
🔑 Keywords: Outlier-Safe Pre-Training, Large Language Models, Quantization Performance, AI-generated summary, AI Systems and Tools
💡 Category: Natural Language Processing
🌟 Research Objective:
– To improve quantization performance of large language models by addressing extreme activation outliers using Outlier-Safe Pre-Training.
🛠️ Research Methods:
– Introduction of Outlier-Safe Pre-Training (OSP) using the Muon optimizer, Single-Scale RMSNorm, and a learnable embedding projection, trained on a 1.4B-parameter model over 1 trillion tokens.
💬 Research Conclusions:
– Demonstrated improved quantization performance with a 35.7 average score on benchmarks, achieved near-zero excess kurtosis, and highlighted that activation outliers result from training strategies rather than being inherent to LLMs.
👉 Paper link: https://huggingface.co/papers/2506.19697

4. OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling
🔑 Keywords: Reinforcement Learning, OctoThinker, Chain-of-Thought, Base Language Model, MegaMath-Web-Pro
💡 Category: Reinforcement Learning
🌟 Research Objective:
– To explore how mid-training strategies can enhance reinforcement learning performance in language models and develop next-generation RL-scalable foundation models.
🛠️ Research Methods:
– Investigated mid-training strategies for two model families (Qwen and Llama) with enhancements using high-quality mathematical corpora and chain-of-thought reasoning examples.
– Implemented a Stable-then-Decay mid-training strategy and used QA-style data and instruction data to improve outcomes.
💬 Research Conclusions:
– Models using high-quality mathematical corpora like MegaMath-Web-Pro exhibit superior performance.
– Long CoT reasoning examples improve reasoning depth but can also increase verbosity and instability, highlighting the importance of data formatting.
– Scaling mid-training enhances RL performance, leading to the OctoThinker model family, bridging gaps with traditionally RL-friendly models like Qwen.
– The release of open-source models and a curated math reasoning corpus aims to further future research.
👉 Paper link: https://huggingface.co/papers/2506.20512

5. DualTHOR: A Dual-Arm Humanoid Simulation Platform for Contingency-Aware Planning
🔑 Keywords: DualTHOR, Vision Language Models, physics-based simulation, real-world robot assets, dual-arm humanoid robots
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Present a physics-based simulation platform, DualTHOR, designed for training dual-arm humanoid robots, aiming to improve the robustness and generalization of Vision Language Models (VLMs) in real-world scenarios.
🛠️ Research Methods:
– Developed a simulator with real-world robot assets and a task suite for dual-arm collaboration, including inverse kinematics solvers and a contingency mechanism for handling potential failures in physics-based low-level execution.
💬 Research Conclusions:
– Current VLMs struggle with dual-arm coordination and robustness in realistic environments, underscoring the necessity of platforms like DualTHOR to develop more capable VLMs for embodied tasks.
👉 Paper link: https://huggingface.co/papers/2506.16012

6. RoboTwin 2.0: A Scalable Data Generator and Benchmark with Strong Domain Randomization for Robust Bimanual Robotic Manipulation
🔑 Keywords: RoboTwin 2.0, bimanual manipulation, sim-to-real transfer, structured domain randomization, multimodal large language models
💡 Category: Robotics and Autonomous Systems
🌟 Research Objective:
– Present RoboTwin 2.0, a scalable simulation framework to enhance bimanual robotic manipulation with diverse and realistic synthetic data.
🛠️ Research Methods:
– Developed a structured domain randomization and expert data synthesis pipeline using multimodal large language models and simulation-in-the-loop refinement.
💬 Research Conclusions:
– Achieved a significant improvement in task execution code generation and generalization to real-world scenarios, with a released data generator, benchmark, dataset, and code to support research in robust bimanual manipulation.
👉 Paper link: https://huggingface.co/papers/2506.18088

7. Use Property-Based Testing to Bridge LLM Code Generation and Validation
🔑 Keywords: Large Language Models, code generation, Property-Based Testing, collaborative LLM-based agents, Test-Driven Development
💡 Category: AI Systems and Tools
🌟 Research Objective:
– The paper introduces a new framework, Property-Generated Solver, designed to enhance code generation correctness and generalization using Property-Based Testing and collaborative LLM-based agents.
🛠️ Research Methods:
– Property-Generated Solver uses two collaborative LLM-based agents: a Generator for code generation and iterative refinement, and a Tester for managing the Property-Based Testing life-cycle and formulating feedback based on property violations.
💬 Research Conclusions:
– The Property-Generated Solver framework significantly improves pass@1 performance in code generation benchmarks, achieving gains of 23.1% to 37.3% over traditional Test-Driven Development methods.
👉 Paper link: https://huggingface.co/papers/2506.18315

8. HiWave: Training-Free High-Resolution Image Generation via Wavelet-Based Diffusion Sampling
🔑 Keywords: Diffusion models, image synthesis, zero-shot generation, DDIM inversion, wavelet-based detail enhancer
💡 Category: Generative Models
🌟 Research Objective:
– The study introduces a training-free, zero-shot approach named HiWave, aiming to enhance visual fidelity and structural coherence in ultra-high-resolution image synthesis using pretrained diffusion models.
🛠️ Research Methods:
– HiWave employs a two-stage pipeline involving the generation of a base image using pretrained models, followed by a patch-wise DDIM inversion and a novel wavelet-based detail enhancer module to improve image details.
💬 Research Conclusions:
– Extensive evaluations with Stable Diffusion XL show that HiWave effectively reduces visual artifacts, achieving superior perceptual quality. A user study confirmed HiWave’s preference over state-of-the-art alternatives in over 80% of comparisons, underscoring its effectiveness without retraining or architectural changes.
👉 Paper link: https://huggingface.co/papers/2506.20452

9. When Life Gives You Samples: The Benefits of Scaling up Inference Compute for Multilingual LLMs
🔑 Keywords: AI-generated summary, large language models, multilingual, multi-task, inference-time compute
💡 Category: Natural Language Processing
🌟 Research Objective:
– The study aims to propose new sampling and selection strategies to enhance inference-time compute efficiency for multilingual and multi-task large language models, seeking to generalize across diverse domains and languages.
🛠️ Research Methods:
– The research evaluates and proposes novel sampling and selection strategies specifically adapted for multilingual and multi-task scenarios, underscoring the need for strategies that are language- and task-aware.
💬 Research Conclusions:
– The combined sampling and selection methods result in significant improvements in win-rates across various languages and tasks, with enhancements seen in benchmarks like m-ArenaHard-v2.0 and Command-A, thus emphasizing the importance of democratizing performance improvements in underrepresented languages.
👉 Paper link: https://huggingface.co/papers/2506.20544

10. Is There a Case for Conversation Optimized Tokenizers in Large Language Models?
🔑 Keywords: Large Language Models, tokenization efficiency, chatbots, energy savings, AI-generated summary
💡 Category: Natural Language Processing
🌟 Research Objective:
– Explore the potential benefits of optimizing tokenizers specifically for chatbot conversations.
🛠️ Research Methods:
– Utilize a publicly available corpus of chatbot conversations to redesign tokenizer vocabularies and evaluate tokenization performance in this domain.
💬 Research Conclusions:
– Conversation-optimized tokenizers reduce the number of tokens in dialogues, leading to 5% to 10% energy savings with minimal or slightly positive impact on the tokenization efficiency of the original training corpus.
👉 Paper link: https://huggingface.co/papers/2506.18674

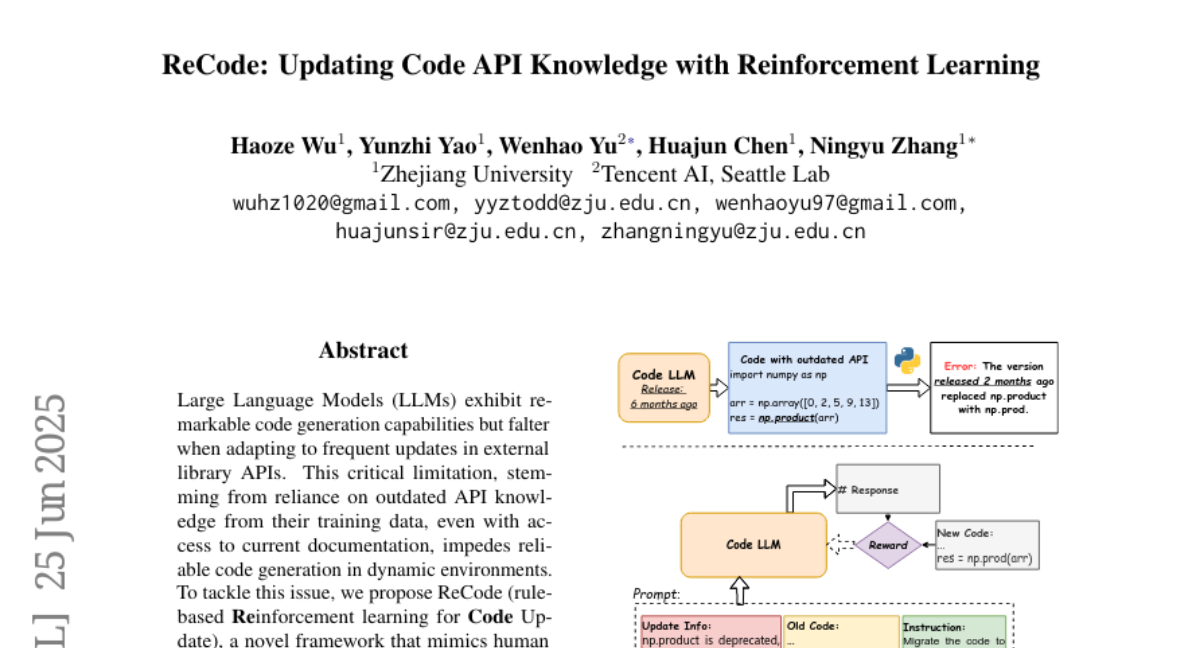
11. ReCode: Updating Code API Knowledge with Reinforcement Learning
🔑 Keywords: ReCode, Reinforcement Learning, Large Language Models, Code Generation, API Updates
💡 Category: Reinforcement Learning
🌟 Research Objective:
– The study aims to enhance Large Language Models’ adaptation to API updates while preserving their general code generation capabilities through a new framework called ReCode.
🛠️ Research Methods:
– ReCode, a rule-based reinforcement learning framework, is developed to train LLMs using a dataset of approximately 2,000 entries for version migration. A modified string similarity metric is introduced to evaluate code as a reward for reinforcement learning.
💬 Research Conclusions:
– ReCode significantly improves LLMs’ performance in dynamic API environments, outperforming other models like the 32B parameter code instruction-tuned model and maintaining general code generation abilities better than supervised fine-tuning methods.
👉 Paper link: https://huggingface.co/papers/2506.20495
12. Biomed-Enriched: A Biomedical Dataset Enriched with LLMs for Pretraining and Extracting Rare and Hidden Content
🔑 Keywords: Biomed-Enriched, PubMed, Clinical NLP, Educational Quality
💡 Category: AI in Healthcare
🌟 Research Objective:
– To create Biomed-Enriched, a biomedical text dataset from PubMed, to enhance pretraining efficiency and performance for clinical NLP.
🛠️ Research Methods:
– Utilization of a two-stage annotation process involving both large and small language models to fine-tune and extract valuable clinical text data.
💬 Research Conclusions:
– The curated dataset provides an alternative large-scale, openly available collection of clinical cases, improving MMLU ProfMed and MedQA performance, and offering efficient biomedical pretraining strategies.
👉 Paper link: https://huggingface.co/papers/2506.20331

13. GPTailor: Large Language Model Pruning Through Layer Cutting and Stitching
🔑 Keywords: Large language models, structured pruning, zero-order optimization, Llama2-13B, compression
💡 Category: Natural Language Processing
🌟 Research Objective:
– To develop a novel strategy for compressing large language models by merging layers from fine-tuned model variants, with minimal performance loss.
🛠️ Research Methods:
– Implementation of a zero-order optimization approach, utilizing a search space for layer removal, layer selection, and layer merging from different candidate models.
💬 Research Conclusions:
– The proposed approach effectively compresses models like Llama2-13B, maintaining approximately 97.3% of original performance while significantly reducing parameters. This outperforms previous methods.
👉 Paper link: https://huggingface.co/papers/2506.20480

14. The Debugging Decay Index: Rethinking Debugging Strategies for Code LLMs
🔑 Keywords: Debugging Decay Index, AI debugging, iterative debugging, intervention points, code generation
💡 Category: AI Systems and Tools
🌟 Research Objective:
– To quantify and optimize the effectiveness of iterative AI debugging by predicting intervention points using the Debugging Decay Index.
🛠️ Research Methods:
– The use of a mathematical framework to identify when AI debugging becomes ineffective and to strategize timely interventions that enhance debugging capability.
💬 Research Conclusions:
– The Debugging Decay Index demonstrates a predictable exponential decay pattern in AI debugging effectiveness and introduces the first quantitative framework for optimizing iterative code generation strategies.
👉 Paper link: https://huggingface.co/papers/2506.18403

15. MATE: LLM-Powered Multi-Agent Translation Environment for Accessibility Applications
🔑 Keywords: Multi-agent system, Accessibility, Modality conversions, AI-generated, Custom machine learning classifiers
💡 Category: Multi-Modal Learning
🌟 Research Objective:
– Introduce MATE, a multimodal accessibility multi-agent system that converts data into understandable formats tailored to the user needs, aimed at assisting people with disabilities.
🛠️ Research Methods:
– Utilizes various models, including LLM API calling and custom machine learning classifiers, to ensure adaptability and compatibility with diverse hardware.
– Introduces ModCon-Task-Identifier for precise modality conversion task extraction from user input.
💬 Research Conclusions:
– MATE enhances accessibility by supporting modality conversion based on user needs across multiple domains like healthcare.
– The system ensures privacy and compatibility with institutional technologies for real-time assistance, surpassing other large language models in effectiveness.
👉 Paper link: https://huggingface.co/papers/2506.19502

16. FineWeb2: One Pipeline to Scale Them All — Adapting Pre-Training Data Processing to Every Language
🔑 Keywords: FineWeb, multilingual LLMs, pre-training datasets, filtering, deduplication
💡 Category: Natural Language Processing
🌟 Research Objective:
– The objective of this research is to introduce a new pre-training dataset curation pipeline based on FineWeb that supports multilingual LLMs, with the ability to automatically adapt to any language, thereby improving model performance and balancing dataset quality.
🛠️ Research Methods:
– The researchers extensively ablated their pipeline design choices using a set of nine diverse languages, guided by a set of novel evaluation tasks chosen through measurable criteria. They also scaled the pipeline to over 1000 languages using almost 100 Common Crawl snapshots to create the FineWeb2 dataset.
💬 Research Conclusions:
– The study concludes that the proposed pipeline can generate non-English corpora that yield better-performing models than prior datasets. Additionally, the authors introduce a principled approach to rebalance datasets considering duplication count and quality, resulting in further performance improvements. The FineWeb2 dataset, along with the pipeline and codebases, is released as part of this work.
👉 Paper link: https://huggingface.co/papers/2506.20920

17. Thought Anchors: Which LLM Reasoning Steps Matter?
🔑 Keywords: Large Language Models, Chain-of-Thought Reasoning, Interpretability, Attention Patterns, Thought Anchors
💡 Category: Natural Language Processing
🌟 Research Objective:
– To enhance interpretability of large language models by analyzing reasoning processes at the sentence level.
🛠️ Research Methods:
– Utilized three complementary attribution methods: a black-box method for evaluating sentence counterfactual importance, a white-box method focusing on attention patterns, and a causal attribution method for measuring logical connections between sentences.
💬 Research Conclusions:
– Discovered that thought anchors, critical reasoning steps such as planning or backtracking sentences, significantly influence subsequent reasoning. Also, introduced an open-source tool to visualize these outputs, showcasing the consistency across methods for a deeper understanding of reasoning models.
👉 Paper link: https://huggingface.co/papers/2506.19143

18.
